编译原理 第5章语法制导的翻译
合集下载
编译原理课件语法制导翻译__SDD_定义__例__表达式的解释执行
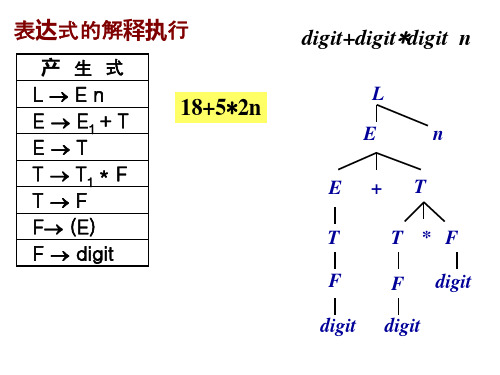
表达式的解释执行
产 生 式 LEn E E1 + T ET T T1 * F TF F (E) F digit
digit+digit*digit n
L E E T F digit +
18+5*2n
n T
T * F F digit digit
语法制导定义 SDD Syntax-Directed Definition
F.val := digit.lexval
E .val = 8
T.val = 8 F.val = 8
+
T .val = 10 T .val = 5 *
F.val = 5 F .val = 2 digit .lexval = 2
digit .lexval = 8
digit .lexval = 5
SDD与属性文法
• 副作用 • 引用透明
LEn
print (E.val)
E E1 + T E.val := E1 .val + T.val
ET
T T1 * F TF
E.val := T.val
T.val := T1.val * F.val T.val := F.val
F (E)
F digit
F.val := E.val
TF
F(E) Fdigit
翻译输入 3*5+4n 所作的动作
L E n { print (statck[top-1].val ); top = top -1; } EE1 + T { statck[top-2].val = statck[top-2].val + statck[top].val; top = top -2; } TT1 * F { statck[top-2].val = statck[top-2].val * statck[top].val; top = top -2; } { statck[top-2].val = F(E) statck[top-1].val top = top -2; }
产 生 式 LEn E E1 + T ET T T1 * F TF F (E) F digit
digit+digit*digit n
L E E T F digit +
18+5*2n
n T
T * F F digit digit
语法制导定义 SDD Syntax-Directed Definition
F.val := digit.lexval
E .val = 8
T.val = 8 F.val = 8
+
T .val = 10 T .val = 5 *
F.val = 5 F .val = 2 digit .lexval = 2
digit .lexval = 8
digit .lexval = 5
SDD与属性文法
• 副作用 • 引用透明
LEn
print (E.val)
E E1 + T E.val := E1 .val + T.val
ET
T T1 * F TF
E.val := T.val
T.val := T1.val * F.val T.val := F.val
F (E)
F digit
F.val := E.val
TF
F(E) Fdigit
翻译输入 3*5+4n 所作的动作
L E n { print (statck[top-1].val ); top = top -1; } EE1 + T { statck[top-2].val = statck[top-2].val + statck[top].val; top = top -2; } TT1 * F { statck[top-2].val = statck[top-2].val * statck[top].val; top = top -2; } { statck[top-2].val = F(E) statck[top-1].val top = top -2; }
编译原理课件05语法制导翻译技术和中间代码生成

5.4 中间代码
四元式的特点: 1. 四元式出现的顺序和语法成份的计值 顺序相一致. 2. 四元式之间的联系是通过临时变量实 现的,这样易于调整和变动四元式. 3. 便于优化处理.
5.4 中间代码
编译系统中,有时将四元式表示成另一 种更直观,更易理解的形式——三地址代 码或三地址语句. 三地址代码形式定义为: result := arg1 OP arg2 三地址语句:语句中是三个量的赋值语句, 三地址语句 每个量占一个地址.
5.5 自下而上的语法制导翻译
例3 简单算术表达式翻译到四元式的 语义描述 例如,设有简单算术表达式的文法: E→E+E | E*E | (E) | i
T R / S T
c S a c
c R S
输入是bR / bTc / bSc /ac 输出为: 1 4 5 314 24 31 给出相应语义动作(翻 译方案) S→bTc { print "1"} { print "2"} S→a R T→R { print "3"} R→R/S { print "4"} R→S { print "5"}
5.1 概述
例如: 表达式 A+B*C 对运算对象进行类型检查, 对变 量进行先定义后使用检查 执行真正的翻译 如果静态语义正确, 语义处理则要执 行真正的翻译, 即生成程序的某种中间 代码的形式或直接生成目标代码.
5.1 概述
目前多数编译程序进行语义分析的方 法是采用语法制导翻译法 .它不是一种 采用语法制导翻译法 形式系统, 但它比较接近形式化. 语法制导翻译法使用属性文法为工具 来描述程序设计语言的语义.
5.4 中间代码
编译原理第五章 语法制导翻译及中间代码生成

① ② ③ ④ (U_minus, b, - ) ( + , c, d ) ( * , ①, ② ) ( := , ③, a )
式①中的运算符U_minus表示一元减运算。
翻译程序中使用的辅助函数
⒈int LookUp(char *Name)—以Name查 符号表,若查到则返回相应登记项的序号 (≥1),否则返回0。 ⒉int Enter(char* Name)—以Name为名 字在符号表中登录新的一项,返回值为该项 的序号。 ⒊int Entry(char *Name)—以Name为名 字查、填符号表:
定义 5.3 对每个产生式p:X0→X1X2…Xn , 设属性定义性出现的集合为 AF(p)={Xi.a|Xi.a=f(Xk1.ak1,…,Xkm.ak m) ∈R(p), 0≤kj≤n} 若Xi 是产生式左部的非终结符(即i=0),则称 属 性 Xi.a 是 综 合 属 性 (Synthesized Synthesized Attributes);若Xi 出现在产生式的右部(即 Attributes 1≤i≤n),则称Xi.a是继承属性(Inherited Inherited Attributes)。 Attributes
逆波兰表示
每一运算符都置于其运算对象之后,故称 为后缀表示。 特点: 特点:表达式中各个运算 运算是按运算符出现的 运算符出现的 顺序进行的,无须使用括号来指示运算顺 顺序进行的 序,因而又称为无括号式 无括号式。
逆波兰表示逆波兰表示-例子
中缀表示 后缀表示
A+B AB+ A+B*C ABC*+ (A+B)*(C+D) AB+CD+* x/y^z-d*e xyz^/de*(a=0∧b>3)∨(e∧x<>y) 思考:能否表示if e then s1 else s2这样的语句? a0=b3>∧exy<>∧∨ ∧ ∧∨ 将后缀式的符号存放在POST[n]中,
式①中的运算符U_minus表示一元减运算。
翻译程序中使用的辅助函数
⒈int LookUp(char *Name)—以Name查 符号表,若查到则返回相应登记项的序号 (≥1),否则返回0。 ⒉int Enter(char* Name)—以Name为名 字在符号表中登录新的一项,返回值为该项 的序号。 ⒊int Entry(char *Name)—以Name为名 字查、填符号表:
定义 5.3 对每个产生式p:X0→X1X2…Xn , 设属性定义性出现的集合为 AF(p)={Xi.a|Xi.a=f(Xk1.ak1,…,Xkm.ak m) ∈R(p), 0≤kj≤n} 若Xi 是产生式左部的非终结符(即i=0),则称 属 性 Xi.a 是 综 合 属 性 (Synthesized Synthesized Attributes);若Xi 出现在产生式的右部(即 Attributes 1≤i≤n),则称Xi.a是继承属性(Inherited Inherited Attributes)。 Attributes
逆波兰表示
每一运算符都置于其运算对象之后,故称 为后缀表示。 特点: 特点:表达式中各个运算 运算是按运算符出现的 运算符出现的 顺序进行的,无须使用括号来指示运算顺 顺序进行的 序,因而又称为无括号式 无括号式。
逆波兰表示逆波兰表示-例子
中缀表示 后缀表示
A+B AB+ A+B*C ABC*+ (A+B)*(C+D) AB+CD+* x/y^z-d*e xyz^/de*(a=0∧b>3)∨(e∧x<>y) 思考:能否表示if e then s1 else s2这样的语句? a0=b3>∧exy<>∧∨ ∧ ∧∨ 将后缀式的符号存放在POST[n]中,
编译原理第五章语法制导翻译

状态 0 1 2 3 4 5 6 7 8
+
s5 r4 r3 r1 r2
LR(0)分析表 action o n b # S4 S3 acc s7 r4 r4 r4 r4 r3 r3 r3 r3 s4 s3 r1 r1 r1 r1 s4 s3 r2 r2 r2 r2
GOTO E T 1 2
6 8
LR分析器的栈加入语义值。
的前缀表示法相比较,其共同的特点是: 1. 运算符的个数不变 2. 运算量的次序和个数不变 同时, 逆波兰表示法还具有两个明显的优点: 1. 无括号,形式简洁清楚 2. 运算符的顺序与运算的次序完全相同
(4)相关名字检查。有时,同一名字必须出现两 次或多次。例如,Ada 语言程序中,循环或程 序块可以有一个名字,出现在这些结构的开头 和结尾,编译程序必须检查这两个地方用的名 字是相同的。 (5)名字的作用域分析
如果语义正确,则进行中间代码的翻译。
中间代码
何谓中间代码 . Intermediate code Intermediate representation Intermediate language
第五章 语法制导翻译和 中间代码的生成
本章的主要内容
语法制导翻译的基本思想;
典型的中间代码表示法;
产生中间代码的语义子程序设计;
各种基本语言成分的自下而上分析的制导
翻译; 类型检查的基本原理。
语义分析是干什么的?
其任务是对语法分析所识别出的各类语法范畴, 分析其含义,并进行初步翻译。 包括两个方面的工作。 首先是对各种语法范畴进行静态语义检查,例 如,变量是否定义、类型是否正确等等。 如果语义正确,则进行中间代码的翻译。
语法制导的翻译

– 自底向上:
•
在构造分析树的结点的同时计算相关的属性(此时其子 结点的属性必然已经计算完毕)
– 自顶向下:
• 递 A调归用子的程其序他法过中程,(在对过应程于A子()的结最构后)计已算经A调的用属完性毕()此时
a
22
在分析树上计算SDD
• 按照后序遍历的顺序计算属性值即可
postorder(N)
第五章 语法制导的翻译
赵建华 南京大学计算机系
2010年3月
a
1
介绍
• 使用上下文无关文法引导语言的翻译
– CFG的非终结符号代表了语言的某个构造 – 程序设计语言的构造由更小的构造组合而成 – 一个构造的语义可以由小构造的含义综合而来
• 比如:表达式x+y的类型由x、y的类型和运算符+决 定。
– 也可以从附近的构造继承而来
– 规则和产生式相关联
• 对于文法符号X和属性a,我们用X.a表示分 析树中的某个标号为X的结点的值。
• 一个分析树结点和它的分支对应于一个产 生式规则,而对应的语义规则确定了这些 结点上的属性的取值。
a
4
分析树和属性值(1)
• 假设我们需要知道一个表达式的类型,以及对 应代码将它的值存放在何处,我们就需要两个
{ for(从左边开始,对N的每个子结点C)
postorder(c); //递归调用返回时,各子结点的属性计算完毕 对N的各个属性求值;
} • 在LR分析过程中,我们实际上不需要构造分析树的
结点。
a
23
L属性的SDD
• 每个属性
– 要么是综合属性,
– 要规么则是只继能承使属用性,且产生式AX1X2…Xn中计算Xi.a的
《编译原理》第5章 语法制导翻译

*
Fval:=5
digitlexval:=4
digitlexval:=5
digitlexval:=3
◆综合属性值的计算方法 对于s-属性定义,通常使用自底向上的分 析方法,在建立每一个结点处使用语义规则来 计算综合属性值,即在用哪个产生式进行归约 后,就执行那个产生式的s-属性定义计算属性 的值,从叶结点到根结点进行计算。 5.1.3 继承属性 继承属性值是由此结点的父结点和/或兄 弟结点的某些属性值来决定的。 例5 . 3 变量说明的属性定义 int a,b,c
构造表达式的语法树使用的函数 1. mknode(op,left,right) 建立一个标记为op 的运算符结点,两个域left和right是指向左右运算 对象的指针。 2.mkleaf(id,entry) 建立一个标记为id的标识 符结点,其域entry是指向该标识符在符号表中相应表 项的指针。 3. mkleaf(num,val) 建立一个标记为num的数结 点,域val用于保存该数的值。返回指向新建立结点 的指针。
语义处理
总目标:生成等价的中间代码
2. 代码结构
计算学科:对信息(数据表示)描述和变 换算法的系统研究 变换:源、目标以及源与目标的对应关系 语句的代码结构 语句分类: 说明语句——符号表的查填 可执行语句——指令代码
3. 典型处理方法
对应每一个产生式编制一个语义子程序, 当一个产生式获得匹配时,调用相应的 语义子程序实现语义检查与翻译
D T
real in 7 in 9 L 10 L , 8 id2 2 entry
4 type
in 5
L ,
6
id3 3 entry
编译原理课件语法制导翻译__翻译方案_SDD

语法制导翻译
描述一棵语法树中结点的属性之间的 相互依赖关系 词法分析 语法分析 依赖图 输入串 语法树 语义规则计算次序 ( 拓扑排序) 树遍历
一遍扫描:在语法分析的同时完成语义规则的 计算, 无需构造实际的语法树
1. 依赖图的拓扑排序
• 依赖图 • 拓扑排序
2. 树遍历的属性计算方法
练习: 以下SDD是L-属性的吗?
产生式 语义规则
ALM
AQR
L.i := l(A.i) M.i := m(L.s) A.s := f(M.s) R.i := r(A.i) Q.i := q(R.s) A.s := f(Q.s)
• 表达式2 ☆
dependencygraph edges can go from left to right
(2) 产生式 Xj 的左边符号 X1,X2,…,Xj-l 的属性
(3) Xj 自己的属性
• S-属性文法一定是L-属性文法 表达式 ☆
Example 非L-属性文法
产生式 A BC 语义规则 A.s = B.b B.i = f ( C.c , A.s )
Fig. Syntax-directed definition of a simple desk calculator
L-属性文法 D TL 和自上而下 T int 语法分析 T real
L L1, id D T .type = real real
综T.type T. type := integer T. type := real L1.in := L.in; addtype (id.entry,L.in ) addtype (id.entry,L.in )
(a)初始状态 (b)VisitNode(S)第一次调用后 (c)VisitNode(S)第二次调用后 (d)VisitNode(S)第三次调用后 的最终状态
描述一棵语法树中结点的属性之间的 相互依赖关系 词法分析 语法分析 依赖图 输入串 语法树 语义规则计算次序 ( 拓扑排序) 树遍历
一遍扫描:在语法分析的同时完成语义规则的 计算, 无需构造实际的语法树
1. 依赖图的拓扑排序
• 依赖图 • 拓扑排序
2. 树遍历的属性计算方法
练习: 以下SDD是L-属性的吗?
产生式 语义规则
ALM
AQR
L.i := l(A.i) M.i := m(L.s) A.s := f(M.s) R.i := r(A.i) Q.i := q(R.s) A.s := f(Q.s)
• 表达式2 ☆
dependencygraph edges can go from left to right
(2) 产生式 Xj 的左边符号 X1,X2,…,Xj-l 的属性
(3) Xj 自己的属性
• S-属性文法一定是L-属性文法 表达式 ☆
Example 非L-属性文法
产生式 A BC 语义规则 A.s = B.b B.i = f ( C.c , A.s )
Fig. Syntax-directed definition of a simple desk calculator
L-属性文法 D TL 和自上而下 T int 语法分析 T real
L L1, id D T .type = real real
综T.type T. type := integer T. type := real L1.in := L.in; addtype (id.entry,L.in ) addtype (id.entry,L.in )
(a)初始状态 (b)VisitNode(S)第一次调用后 (c)VisitNode(S)第二次调用后 (d)VisitNode(S)第三次调用后 的最终状态
编译原理--语法制导的翻译 ppt课件

(2)设code 为综合属性,代表各非终结符 的代码属性
type为综合属性,代表各非终结符的类型属 性
inttoreal把整型值转换为相等的实型值 vtochar将数值转换为字符串
5.3.3 给出一个SDD对x*(3*x+x*x)这样的表达式求 微分。表达式中涉及运算符+和*,变量x和常 量。假设不进行任何简化,也就是说,比如 3*x将被翻译为3*1+0*x。
ST z , R4
8.2.6 确定下列指令序列的代价。
1)
LD R0 , y
2
LD R1 , z
2
ADD R0 , R0 , R1 1
ST x , R0
2
总代价:7
3)
LD R0 , c
2
LD R1 , i
2
MUL R1 , R2 , 8 2
ST a(R1) , R0 2
总代价:8
8.3.3 假设使用栈式分配,且假设a和b都是元素大小为4字节 的数组,为下面的三地址语句生成代码。
的位数次幂值(2 length of L)
S L1.L2 S.val = L1.val +L2.val / L2.b; S L S.val = L.val; L L1 B L.val = L1.val *2 + B.val;
L.b = L1.b*2; L B L.val = B.val; L.b = 2; B 0 B.val = 0; B 1 B.val = 1;
2)三个语句序列 x = a[i] y = b[i] z = x*y
LD R1 , i MUL R1 , R1 , 4 ADD R1 , R1 , SP LD R2 , a(R1) ST x(SP) , R2 LD R3 , i MUL R3 , R3 , 4 ADD R3 , R3 , SP LD R4 , b(R3) ST y(SP) , R4 LD R5 , x(SP) LD R6 , y(SP) MUL R5 , R5 , R6 ST z(SP) ,R5
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
属性和文法符号相关联 规则和产生式相关联
根据需要,将文法符号和某些属性相关联, 并通过语义规则来描述如何计算属性的值
E→E1+T E.code=E1.code || T.code || ‘+’ code表示了我们关心的表达式的逆波兰表示,规则说明 加法表达式的逆波兰表示由两个分量的逆波兰表示并置, 然后加上‘+’得到。
digitlexval=3
18
适用于自顶向下分析的SDD
前面的表达式文法存在直接左递归,因 此无法直接用自顶向下方法处理。 消除左递归之后,无法直接使用属性val 进行处理:
比如规则:T→FT’ T’→*FT’ T对应的项中,第一个因子对应于F, 而运算符在T’中。
19
相同表达式的不同文法的比较
38
例5.15 分析栈实现的例子
假设语法分析栈存放在一个被称为stack 的记录数组中,下标top指向栈顶;
stack[top]指向这个栈的栈顶;stack[top-1] 指向栈顶下一个位置; 如果不同的文法符号有不同的属性集合,我 们可以使用union来保存这些属性值。(归 约时,我们知道栈顶向下的各个符号分别是 什么)
语义翻译的流程
输 入 符 号 串 分 析 树 依 赖 图
语
义
规
则
的 计
实际上,编译中语义翻译的实现并不是 按图中的流程处理的;而是随语法分析 的进展,识别出一个语法结构,就对它 的语义进行分析和翻译。
算
9
5.1 语法制导定义
4.什么是语法制导定义(SDD) 上下文无关文法和属性/规则的结合;
12
5.1.1 继承属性和综合属性
不允许N的继承属性通过N的子结点上的属性来定 义,但是允许N的综合属性依赖于N本身的继承属 性。 终结符号有综合属性(由词法分析获得),但是 没有继承属性。
13
语法制导定义(SDD)的例子
目标: 计算表达式L的值 (属性val) 计算L的val值需要 E的val值 E的val值又依赖于 E和T的val值 … 终结符号digit有综 合属性lexval。
37
2 后缀SDT的语法分析栈实现
可以在LR语法分析的过程中实现
归约时执行相应的语义动作 定义可以记录各个文法符号的属性的union结构 栈中的每个文法符号(或者状态)的附带一个 这样的结构的值; 在按照产生式A→XYZ归约时,Z的属性可以在 栈顶找到,Y的属性可以在下一个位置找到,X 的属性可以在再下一个位置找到。
32
受控的副作用
受控副作用的例子
L→En
变量声明的SDD中的副作用
通过副作用打印出E的值 总是在最后执行,且不会影响其它属性的求值 addType将标识符的类型信息加入到标识符表中。 只要标识符不被重复声明,标识符的类型信息总是正确的。
print(E.val)
33
5.3 语法制导的翻译方案
D → T { L.in := T.type } L T → int { T.type := integer }
T → real { T.type := real }
L → { L1.in := L.in }L1,id{…} 语义——可以看成是相应文法符号的属性
8
适宜在进行推导时完成
S属性的SDD
27
5.2.3 S属性的SDD
每个属性都是综合属性 都是根据子构造的属性计算整个构造的属性。 在依赖图中,总是通过子结点的属性值来计 算父结点的属性值。可以和自顶向下、自底 向上的语法分析过程一起计算
自底向上:关的属性 递归子程序法中,在过程A()的最后计算A的属性
30
带有继承属性L.inh的语法制导定义 产生式 DTL T int T float L L1,id L id 语义规则 Linh:=T type T type :=integer T type :=float L1 inh :=L inh addtype(id entry,L inh) addtype(id entry,L inh)
第5章 语法制导的翻译
1
本章重点
语法制导定义
S属性定义 L属性定义 语法制导定义和翻译方案的关系
语法制导的翻译方案设计
自底向上实现L属性的SDD
2
语法制导的翻译
5.1 语法制导定义 5.2 SDD的求值顺序 5.3 语法制导的翻译方案
3
第五章 语法制导的翻译
翻译的任务
首先是语义分析和正确性检查,若正确,则翻译成 中间代码或目标代码。 语法结构具有规定的语义 根据翻译的需要设置文法符号的属性,以描述语法 结构的语义。 例如,一个变量的属性有类型,层次,存储地 址等。表达式的属性有类型,值等。
E→E1 + T T→T1 * F F →id
E.val:=E1.val+T.val T.val:=T1.val*F.val F.val:=id.val
7
适宜在完成归约的时候进行
5.1 语法制导定义
3. 典型处理方法(2) 在产生式的右部的适当位置,插入相应的语义动 作,按照分析的进程,执行遇到的语义动作
14
5.1.2 翻译方案的可视化
注释语法分析树
在分析树上求值有助于翻译方案的可视化,便 于理解。 包含了各个结点的各属性值的语法分析树
15
注释语法分析树
构造注释语法分析树步骤:
对于任意的输入串,首先构造出相应的分析树。 根据结点上的文法符号,每个结点都有相应的属 性值 按照分析树中的分支对应的文法产生式,应用相 应的语义规则计算属性值。
语法制导的翻译方案(SDT)是在产生 式体中嵌入程序片断(语义动作)的上 下文无关文法 SDT的基本实现方法:
建立语法分析树; 从左到右、深度优先地执行这些动作 基本文法是LR的,SDD是S属性的 基本文法是LL的,SDD是L属性的
34
用SDT实现两类重要的SDD
可在语法分析过程中实现的 SDT
28
自顶向下:
在分析树上计算SDD
按照后序遍历的顺序计算属性值即可 postorder(N) { for(从左边开始,对N的每个子结点C) postorder(c); 对N的各个属性求值; } 在LR分析过程中,我们实际上不需要构造 分析树的结点。
29
5.2.4 L属性的SDD
每个属性要么是
25
例5.5 依赖图的例子
3*2的注释分析树; T→FT’ {T.val = T’.syn; T’.inh = F.val;}
可能的计算顺序:
边e1、e2。
1,2,3,4,5,6,7,8.9 1,3,5,2,4,6,7,8,9
26
属性值的计算顺序
可以按照依赖图的拓扑排序计算各个属性的 值。 如果图中存在环,那么这个计算过程就无法 进行。 给定一个SDD,很难判定是否存在一棵分析 树,其对应的依赖图包含环。 但是特定类型的SDD一定不包含环,且有固 定的排序模式。
31
5.2.5具有受控副作用的语义规则
属性文法没有副作用,但是会增加描述的复 杂度
比如语法分析时如果没有副作用,符号表就必 须作为属性传递。 可以把符号表作为全局变量,然后通过副作用 函数来添加新标识符; 不会对属性求值产生约束,即可以按照任何拓 扑属性求值,不会影响最终结果。 添加部分简单的约束。
23
5.2.1 依赖图
依赖图描述了某棵特定的分析树上的各个属 性实例之间的信息流(计算顺序)
从实例a1到实例a2的有向边表示计算a2时需要 a1的值。(必须先计算a2,再计算a1)
24
5.2.1 依赖图
依赖图的构造方法 for 分析树中的每个结点n do for 与结点n对应的文法符号的每个属性a do 在依赖图中为a构造一个结点; for 分析树的每个结点n do for 结点n所用产生式对应的每条 语义规则 b:=f(c1,c2,…,ck ) do for i:=1 to k do 从结点ci到结点b构造一条有向边;
注意:T’的属性inh实际上是继承了相应的* 号的左运算分量。
21
例5.3 3*5的注释分析树
请观察inh属性是如何传递的。
22
5.2 SDD的求值顺序
在对SDD的求值过程中,如果结点N的属 性a依赖于结点M1的属性a1,M2的属性 a2,…。那么必须先计算出Mi的属性, 才能计算N的属性a。 显然,这些值的计算顺序应该形成一个 偏序关系。
实际实现SDT时,并不会真的构造语法分析 树,而是在分析过程中执行语义动作 判断是否可在分析过程中实现
将每个语义动作替换为一个独有的标记非终结符 号;每个标记非终结符号M的产生式为M→ε。 如果新的文法可以由某种方法进行分析,那么这 个SDT就可以在这个分析过程中实现。 注意:这个断言没有考虑变量值的传递等要求。
综合属性,要么是 继承属性,且产生式A→X1X2…Xn中计算Xi.a的 规则只能使用
特点:
A的继承属性 Xi左边的文法符号Xj的继承属性或综合属性。 Xi自身的继承或综合属性。且这些属性的依赖关系不 形成环。