5行代码实现1秒以内获取一次所有股票实时分笔数据
Python获取股票历史数据并分析
如上有几个简单规律
1、当跌幅超过3%的股票占比超过10%时,意味股市的调整开始了。所以大家要小心
2、上证上涨时,涨幅超过3%的股票占比变化不明显,说明上涨起来慢,不让你发现。跌起来快不让你逃跑。
curs= conn.cursor()
sql="SELECT name num FROM sqlite_master WHERE type='table' AND name='stocks'"
curs.execute(sql)
isexists=curs.fetchall()
if len(isexists)>0:
curs.execute(sql)
dates=curs.fetchall()
if len(dates)>0:
return dict(dates)
else:
return {'1000':'2000-01-01'}
if __name__=='__main__':
yes_time = datetime.datetime.now() + datetime.timedelta(days=-1)
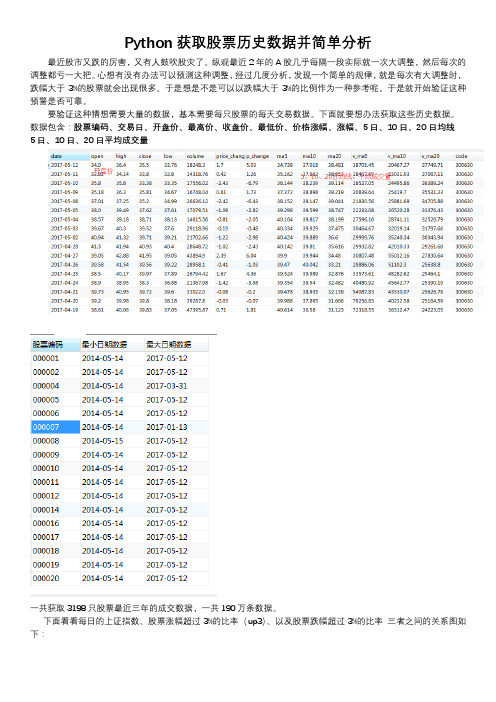
要验证这种猜想需要大量的数据,基本需要每只股票的每天交易数据。下面就要想办法获取这些历史数据。
数据包含:股票编码、交易日、开盘价、最高价、收盘价、最低价、价格涨幅、涨幅、5日、10日、20日均线
5日、10日、20日平均成交量
一共获取3198只股票最近三年的成交数据,一共190万条数据。
python获取股票数据方法

python获取股票数据方法(原创版2篇)目录(篇1)1.获取股票数据的重要性2.Python 在获取股票数据中的应用3.使用 Python 获取股票数据的常用库和 API4.获取股票数据的具体步骤和示例代码5.总结和展望正文(篇1)1.获取股票数据的重要性在金融领域,尤其是股票投资中,获取及时、准确的数据至关重要。
股票市场的变化瞬息万变,投资者需要根据各种信息来分析市场趋势,以便做出明智的投资决策。
Python 作为一种广泛应用于金融领域的编程语言,可以有效地帮助投资者获取和处理股票数据。
2.Python 在获取股票数据中的应用Python 拥有丰富的库和 API,可以轻松地从各种来源获取股票数据。
例如,可以使用 pandas 库处理数据,使用 numpy 库进行数值计算,使用 matplotlib 库绘制图表等。
此外,Python 还支持多种获取股票数据的 API,如 Yahoo Finance、Alpha Vantage、IEX Cloud 等。
3.使用 Python 获取股票数据的常用库和 API(1)pandas 库:pandas 是一个强大的数据处理库,可以轻松地处理股票数据,如读取 CSV 文件、处理缺失值、进行数据合并等。
(2)numpy 库:numpy 是一个数值计算库,可以用于处理股票数据中的数值计算问题,如计算移动平均线、涨跌幅等。
(3)matplotlib 库:matplotlib 是一个绘图库,可以用于绘制股票数据的各种图表,如 K 线图、收盘价走势图等。
(4)Yahoo Finance:Yahoo Finance 是一个提供股票数据的网站,可以通过 Python 的 requests 库获取实时股票数据。
(5)Alpha Vantage:Alpha Vantage 是一个提供免费 API 的网站,可以获取实时和历史股票数据,如收盘价、成交量、市盈率等。
(6)IEX Cloud:IEX Cloud 是一个提供免费 API 的网站,可以获取实时股票数据,如买卖盘口、成交记录等。
用Python编写爬取股票信息的代码

⽤Python编写爬取股票信息的代码北京理⼯⼤学崇天⽼师编写的⼩课件,很不完善,放进来只是为了⽅便⾃⼰⽤⼿机查看1import requests2import re3import bs44import traceback56def getHTMLText(url, code = "utf-8"):7# 获得股票页⾯8try:9 r = requests.get(url)10 r.raise_for_status()11 r.encoding = code12# r.encoding = r.apparent_encoding13# 直接⽤"utf-8"编码节省时间14return r.text15except:16return""1718def getStockList(lst, stockURL):19# 获取股票列表20 html = getHTMLText(stockURL, "GB2312")21# 东⽅财富⽹⽤"GB2312"⽅式编码22 soup = bs4.BeautifulSoup(html, "html.parser")23 a = soup. find_all("a")24for i in a:25try:26 href = i.attrs["href"]27 lst.append(re.findall(r"[s][hz]\d{6}", href)[0])28except:29continue3031def getStockInfo(lst, stockURL, fpath):3233 count = 034# 增加进度条3536# 获取个股信息37for stock in lst:38 url = stockURL + stock + ".html"39 html = getHTMLText(url)40try:41if html == "":42# 判断页⾯是否为空43continue44 infoDict = { }45# 定义⼀个字典⽤来储存股票信息46 soup = bs4.BeautifulSoup(html, "html.parser")47 stockInfo = soup.find("div", attrs={"class":"stock-bets"})48# 获得股票信息标签4950 name = stockInfo.find_all(attrs={"class":"bets-name"})[0]51# 在标签中查找股票名称52 infoDict.update({"股票名称":name.text.split()[0]})53# 将股票名称增加到字典中5455 keyList = stockInfo.find_all("dt")56# "dt"标签是股票信息键的域57 valueList = stockInfo.find_all("dd")58# "dd"标签是股票信息值的域5960for i in range(len(keyList)):61# 还原键值对并存储到列表中62 key = keyList[i].text63 val = valueList[i].text64 infoDict[key] = val6566 with open(fpath, "a", encoding="utf-8") as f:67 f.write(str(infoDict) + "\n")6869 count += 170# 增加进度条71print("\r当前进度:{:.2f}%".format(count*100/len(lst)),end = "")7273except:74 count += 175# 增加进度条76print("\r当前进度:{:.2f}%".format(count * 100 / len(lst)), end="")7778# ⽤traceback获得异常信息79#traceback.print_exc()80continue81return""8283if__name__ == '__main__':84 stock_list_url = "/stocklist.html" 85# 获得个股链接86 stock_info_url = "https:///stock/"87# 获取股票信息的主题部分88 output_file = "C:\\Users\\W419L\\Desktop\\股票爬取.txt"89# ⽂件保存地址90 slist = []91# 存储股票信息92 getStockList(slist, stock_list_url)93 getStockInfo(slist, stock_info_url, output_file)。
python 股票 统计学

python股票统计学Python是一种强大的编程语言,可以用于处理和分析股票数据。
以下是一些使用Python进行股票统计学的示例:1.计算移动平均线移动平均线是一种常用的技术分析工具,可以用于平滑股票价格波动并识别趋势。
在Python中,可以使用pandas库的rolling函数来计算移动平均线。
例如,以下代码将计算5天移动平均线:```pythonimport pandas as pd#读取股票数据data=pd.read_csv('stock_data.csv')#计算5天移动平均线data['5_day_moving_average']= data['close'].rolling(window=5).mean()#输出结果print(data)```2.计算相对强弱指数(RSI)相对强弱指数是一种动量振荡器,可以用于衡量股票的超买和超卖情况。
在Python中,可以使用pandas库的ewma 函数来计算RSI。
例如,以下代码将计算14天RSI:```pythonimport pandas as pd#读取股票数据data=pd.read_csv('stock_data.csv')#计算14天RSIdata['RSI']=data['close'].ewm(span=14, adjust=False).mean()-data['close'].ewm(span=14, adjust=False).mean().shift(1)#输出结果print(data)```3.计算布林带指标布林带指标是一种技术分析工具,可以用于衡量股票价格波动范围和波动性。
在Python中,可以使用pandas库的rolling函数来计算布林带指标。
例如,以下代码将计算布林带指标:```pythonimport pandas as pdimport numpy as np#读取股票数据data=pd.read_csv('stock_data.csv')#计算布林带指标data['Bollinger_High']=data['close']+ (data['close'].rolling(window=20).std()*2)data['Bollinger_Low']=data['close']-(data['close'].rolling(window=20).std()*2)data['Bollinger_Band']=(data['Bollinger_High']+ data['Bollinger_Low'])/2#输出结果print(data)```。
python获取股票数据方法

python获取股票数据方法
1.使用 tushare
Tushare是一个免费、开源的python财经数据接口包,它能够为用户提供便捷的获取股票数据的方法。
Tushare支持大量的股票数据,包括股票列表、股票细节数据、历史价格数据、技术行情数据等。
使用Tushare,只需要简单的函数调用即可获得数据,非常方便快捷。
使用tushare可以很容易获取各类股票数据,以下是一些核心函数的使用示例:
1.获取股票的基本信息:
ts.get_stock_basic
2.获取历史上只股票价格:
3.获取股票历史行情:
4.获取当日实时行情:
ts.get_today_all
使用tushare获取股票数据,需要先安装tushare模块,安装方法如下:
pip install tushare
安装完成后,就可以使用tushare模块来获取股票数据了。
2.使用 Wind Python
Wind Python是Wind财经研究院推出的python接口,用于获取全球财经数据信息,包括国内主板、中小板、创业板的历史价格、财务指标、市场交易数据等。
使用 Wind Python 可以方便的获取港股、美股和A股数据。
使用Wind Python获取股票数据,只需要简单的函数调用即可,以下是一些常用的核心函数的使用示例:
1.获取指定时间段只股票数据:
2.获取指定期间只股票的日收益。
【获取股票数据代码教程02】Python等五种主流语言的实例代码演示如何获取股票历史分时交易数据

近年来,股票量化分析逐渐受到广泛关注,而作为入门的首要步骤,获取股票数据显得尤为重要。
无论是实时交易数据、历史记录、财务数据还是基本面信息,这些数据都是我们进行量化分析不可或缺的基石。
我们的核心任务是从这些数据中提炼出有价值的信息,从而为我们的投资策略提供指导。
在数据探索的旅途中,我尝试了多种途径,包括自编网易股票页面爬虫、申万行业数据爬虫,以及同花顺问财的爬虫,甚至还尝试了聚宽的免费数据API。
然而,爬虫作为数据源常常显得不够稳定,给我们的量化分析带来不小的挑战。
在量化分析的世界里,实时且精确的数据接口是成功的关键。
经过多次实战检验,我已确认以下数据接口均表现出色且稳定可靠。
现在我用Python、JavaScript(Node.js)、Java、C#和Ruby五种主流语言的实例代码给大家演示一下如何获取历史分时交易数据数据:历史分时交易数据是区分分时级别的,我这里演示的都是60分钟级别的历史分时交易数据,其他级别可以参考下面的API文档自行修改参数就行了1、Pythonimport requestsurl = "http://api.mairui.club/hszbl/fsjy/000001/60m/b997d4403688d5e66a"response = requests.get(url)data = response.json()print(data)2、JavaScript (Node.js)const axios = require('axios');const url = "http://api.mairui.club/hszbl/fsjy/000001/60m/b997d4403688d5e66a";axios.get(url).then(response => {console.log(response.data);}).catch(error => {console.log(error);});3、Javaimport .URI;import .http.HttpClient;import .http.HttpRequest;import .http.HttpResponse;import java.io.IOException;public class BOLLin {public static void BOLLin(String[] args) {HttpClient client = HttpClient.newHttpClient();HttpRequest request = HttpRequest.newBuilder().uri(URI.create("http://api.mairui.club/hszbl/fsjy/000001/60m/b997d4403688d5e 66a")).build();try {HttpResponse<String> response = client.send(request, HttpResponse.BodyHandlers.ofString());System.out.println(response.body());} catch (IOException | InterruptedException e) {e.printStackTrace();}}}4、C#using System;using .Http;using System.Threading.Tasks;class Program{static async Task BOLLin(){using (HttpClient client = new HttpClient()){string url = "http://api.mairui.club/hszbl/fsjy/000001/60m/b997d4403688d5e66a";HttpResponseMessage response = await client.GetAsync(url);string responseBody = await response.Content.ReadAsStringAsync();Console.WriteLine(responseBody);}}}5、Rubyrequire 'net/http'require 'json'url = URI("http://api.mairui.club/hszbl/fsjy/000001/60m/b997d4403688d5e66a")http = Net::HTTP.new(url.host, url.port)request = Net::HTTP::Get.new(url)response = http.request(request)data = JSON.parse(response.read_body)puts data返回的数据示例:[{"d":"2024-07-1910:30","o":"10.38","h":"10.42","l":"10.30","c":"10.31","v":"317556","e":"328446466.00","zf":"1. 15","hs":"0.16","zd":"-0.96","zde":"-0.10"},{"d":"2024-07-1911:30","o":"10.31","h":"10.36","l":"10.29","c":"10.33","v":"232160","e":"239604970.00","zf":"0. 68","hs":"0.12","zd":"0.19","zde":"0.02"},{"d":"2024-07-1914:00","o":"10.32","h":"10.38","l":"10.31","c":"10.35","v":"142296","e":"147269842.00","zf":"0. 68","hs":"0.07","zd":"0.19","zde":"0.02"},{"d":"2024-07-1915:00","o":"10.34","h":"10.39","l":"10.33","c":"10.37","v":"206711","e":"214401378.00","zf":"0. 58","hs":"0.11","zd":"0.19","zde":"0.02"},{"d":"2024-07-2210:30","o":"10.36","h":"10.38","l":"10.19","c":"10.19","v":"561137","e":"575785727.00","zf":"1. 83","hs":"0.29","zd":"-1.74","zde":"-0.18"},{"d":"2024-07-2211:30","o":"10.20","h":"10.26","l":"10.19","c":"10.23","v":"123996","e":"126765735.00","zf":"0. 69","hs":"0.06","zd":"0.39","zde":"0.04"},{"d":"2024-07-2214:00","o":"10.23","h":"10.23","l":"10.19","c":"10.20","v":"150890","e":"153967494.00","zf":"0. 39","hs":"0.08","zd":"-0.29","zde":"-0.03"},{"d":"2024-07-2215:00","o":"10.20","h":"10.26","l":"10.19","c":"10.23","v":"158457","e":"162144843.00","zf":"0. 69","hs":"0.08","zd":"0.29","zde":"0.03"},{"d":"2024-07-2310:30","o":"10.25","h":"10.32","l":"10.23","c":"10.30","v":"314676","e":"323496417.00","zf":"0. 88","hs":"0.16","zd":"0.68","zde":"0.07"}]历史分时交易API接口:http://api.mairui.club/hszbl/fsjy/股票代码(如000001)/分时级别/licence 证书接口说明:根据《股票列表》得到的股票代码以及分时级别获取分时交易数据,交易时间从远到近排序。
东方财富逐笔委托函数

东方财富逐笔委托函数介绍东方财富逐笔委托函数是一种用于投资交易的函数,该函数可以实时获取股票市场的逐笔委托数据。
通过使用该函数,投资者可以更加准确地了解股票市场的交易情况,做出更加明智的投资决策。
逐笔委托数据的意义逐笔委托数据是指股票市场中每一笔交易的具体委托情况,包括买卖方向、委托价格、委托数量等信息。
这些数据对于投资者来说非常重要,因为它们可以反映出市场的交易活跃度、买卖力量以及潜在的市场趋势。
东方财富逐笔委托函数的使用方法使用东方财富逐笔委托函数可以按照以下步骤进行:步骤一:导入相关库首先,需要导入相关的库,包括东方财富的API库和其他必要的辅助库。
可以使用如下代码进行导入:import efinance as efimport pandas as pd步骤二:获取逐笔委托数据接下来,可以使用东方财富的逐笔委托函数来获取数据。
可以使用如下代码获取某只股票的逐笔委托数据:symbol = '600519.SH' # 以贵州茅台为例df = ef.stock.get_quote_history(symbol, klt='lt')步骤三:数据处理与分析获取到逐笔委托数据后,可以对数据进行处理和分析,以便更好地理解市场情况。
可以使用如下代码对数据进行简单的处理和分析:df['time'] = pd.to_datetime(df['time']) # 转换时间格式df.set_index('time', inplace=True) # 将时间列设置为索引步骤四:数据可视化最后,可以使用数据可视化的方式将逐笔委托数据呈现出来,以便更加直观地观察市场情况。
可以使用如下代码进行简单的数据可视化:import matplotlib.pyplot as pltplt.figure(figsize=(10, 6))plt.plot(df['price'], label='Price')plt.xlabel('Time')plt.ylabel('Price')plt.title('Stock Price')plt.legend()plt.show()逐笔委托数据的分析与应用逐笔委托数据可以提供丰富的信息,投资者可以根据这些数据进行分析和应用。
Python获取股票历史、实时数据与更新到数据库

Python获取股票历史、实时数据与更新到数据库要做量化投资,数据是基础,正所谓“巧妇难为⽆⽶之炊”在免费数据⽅⾯,各⼤⽹站的财经板块其实已提供相应的api,如新浪、雅虎、搜狐。
可以通过urlopen相应格式的⽹址获取数据⽽TuShare正是这么⼀个免费、开源的python财经数据接⼝包,已将各类数据整理为dataframe类型供我们使⽤。
主要⽤到的函数:1.实时⾏情获取tushare.get_today_all()⼀次性获取当前交易所有股票的⾏情数据(如果是节假⽇,即为上⼀交易⽇,结果显⽰速度取决于⽹速)2.历史数据获取tushare.get_hist_data(code, start, end,ktype, retry_count,pause)参数说明:code:股票代码,即6位数字代码,或者指数代码(sh=上证指数 sz=深圳成指 hs300=沪深300指数 sz50=上证50 zxb=中⼩板 cyb=创业板)start:开始⽇期,格式YYYY-MM-DDend:结束⽇期,格式YYYY-MM-DDktype:数据类型,D=⽇k线 W=周 M=⽉ 5=5分钟 15=15分钟 30=30分钟 60=60分钟,默认为Dretry_count:当⽹络异常后重试次数,默认为3pause:重试时停顿秒数,默认为0⽽如果要进⾏完备详细的回测,每次在线获取数据⽆疑效率偏低,因此还需要⼊库下⾯是数据库设计部分表1:stocks股票表,第⼀列为股票代码,第⼆列为名称,如果get_today_all()中存在的股票stocks表中没有,则插⼊之。
表2:hdata_date⽇线表,由于分钟线只能获取⼀周内的数据,我们先对⽇线进⾏研究。
字段和get_hist_data返回值基本⼀致,多了stock_code列,并将record_date列本来是dataframe的indexstock_code,record_date, //主键open,high,close,low, //开盘,最⾼,收盘,最低volume, //成交量price_change,p_change, //价差,涨幅ma5,ma10,ma20 //k⽇收盘均价v_ma5,v_ma10,v_ma20, //(k⽇volume均值)turnover //换⼿率python⼯程⽬前有3个⽂件,main.py(主程序),Stocks.py(“股票们”类)以及Hdata.py(历史数据类)main.pyimport psycopg2 #使⽤的是PostgreSQL数据库import tushare as tsfrom Stocks import*from HData import*import datetimestocks=Stocks("postgres","123456")hdata=HData("postgres","123456")# stocks.db_stocks_create()#如果还没有表则需要创建#print(stocks.db_stocks_update())#根据todayall的情况更新stocks表#hdata.db_hdata_date_create()nowdate=datetime.datetime.now().date()codestock_local=stocks.get_codestock_local()hdata.db_connect()#由于每次连接数据库都要耗时0.0⼏秒,故获取历史数据时统⼀连接for i in range(0,len(codestock_local)):nowcode=codestock_local[i][0]#print(hdata.get_all_hdata_of_stock(nowcode))print(i,nowcode,codestock_local[i][1])maxdate=hdata.db_get_maxdate_of_stock(nowcode)print(maxdate, nowdate)if(maxdate):if(maxdate>=nowdate):#maxdate⼩的时候说明还有最新的数据没放进去continuehist_data=ts.get_hist_data(nowcode, str(maxdate+datetime.timedelta(1)),str(nowdate), 'D', 3, 0.001)hdata.insert_perstock_hdatadate(nowcode, hist_data)else:#说明从未获取过这只股票的历史数据hist_data = ts.get_hist_data(nowcode, None, str(nowdate), 'D', 3, 0.001)hdata.insert_perstock_hdatadate(nowcode, hist_data)hdata.db_disconnect()Stocks.pyimport tushare as tsimport psycopg2class Stocks(object):#这个类表⽰"股票们"的整体(不是单元)def get_today_all(self):self.todayall=ts.get_today_all()def get_codestock_local(self):#从本地获取所有股票代号和名称conn = psycopg2.connect(database="wzj_quant", user=er, password=self.password, host="127.0.0.1",port="5432")cur = conn.cursor()# 创建stocks表cur.execute('''select * from stocks;''')rows =cur.fetchall()mit()conn.close()return rowspassdef__init__(self,user,password):# self.aaa = aaaself.todayall=[]er=userself.password=passworddef db_perstock_insertsql(self,stock_code,cns_name):#返回的是插⼊语句sql_temp="insert into stocks values("sql_temp+="\'"+stock_code+"\'"+","+"\'"+cns_name+"\'"sql_temp +=");"return sql_temppassdef db_stocks_update(self):# 根据gettodayall的情况插⼊原表中没的。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
5行代码实现1秒以内获取一次所有股票实时分笔数据
最近工作太忙了,有一个星期没有更新文章了,本来这一期打算分享一些对龙虎榜数据的分析结果,现在还没有把数据的价值很好的发掘出来,留作下一期分享吧,争取挖掘出一些有实际投资参考的结论。
前两篇文章分别简单介绍了tushare这个财经数据接口包的使用,用起来简单顺手,一两行代码就可以获取到你想的要的数据,但是有在群里经常看到说获取数据经常挂,延迟很严重等等,其实那是因为使用者没有好好去领悟和了解工具。
前面两篇文章已经对tushare如何获取股票的历史数据和实时数据有过简单的介绍,没看过的朋友可以到微信公众号【数据之佳】点击往期文章就可以查看。
前两篇文章只是向大家介绍了tushare这个工具,相信有不少对量化投资感兴趣,却不知道如何获取数据的朋友已经尝试过使用它来获取数据,但遗憾的是,如果不注意使用的技巧,你获取数据的脚本即使不经常挂,得到的数据质量也不高,尤其是实时分笔数据,上一篇文章展示的代码,获取一次所有股票的实时数据整整花了20秒的时间,遇到这种情况,可能很多人会想,是不是网速的问题,或者是数据服务器限制访问的频次导致的?所以只能退而求其次,自我安慰:有总比没有好。
其实不然,我们使用tushare来获取数据,其数据也是通过爬虫从各个数据服务器爬下来的,在代码访问数据的过程中,每一次访问都需要经过验证,就好像你需要从仓库中取一万个零件,你每一次只取一个,而仓库管理员必须遵守规定,每一次取物品都需要验证你的身份,做记录等等一系列繁杂的手续,很可能你验证身份所花的时间比你取物品的时间还要多得多,然而如果你有一辆卡车,一次可以运走一千个零件,那么你每次验证身份,就可以取走一千件,这样身无用功所花的时间要少一千倍。
道理很简单,关键在于你会不会这样去想,向服务器获取数据也一样,每次访问服务器,都需要发送请求,验证等等,这些都是无用的时间开销,如果我们能一次性获取多条数据,就可以大大节省时间开销,恰好tushare获取实时数据的接口函数提供了这样的功能,一次性可以获取多只股票的数据,但不能太多,tushare网页文档说的是最好每次不要获取超过30只股票的数据,但经过我验证,每次最多可以获取880只股票的实时数据,现在深市沪市一共有3400多只股票,我们只需要获取4次就够了,下面提供一下源代码,核心代码的确只有5行,为了验证是否获取一次数据的时间间隔,我把获取数据之前,以及之后的时间都打印出来了。
import tushare as ts
import pandas as pd
import datetime
f=open('F:\get_stocks\get_data\stocks.txt')
time1=datetime.datetime.now()
stocks=[line.strip() for line in f.readlines()]
data1=ts.get_realtime_quotes(stocks[0:880])
data2=ts.get_realtime_quotes(stocks[880:1760])
data3=ts.get_realtime_quotes(stocks[1760:2640])
data4=ts.get_realtime_quotes(stocks[2640:-1])
time2=datetime.datetime.now()
print('开始时间:'+str(time1))
print('结束时间:'+str(time2))
print(data1)
print(data2)
print(data3)
print(data4)
开始时间:2017-12-04 21:42:27.184003
结束时间:2017-12-04 21:42:27.696398
可以看到,获取数据前后的时间差,只有0.5秒多一些,准确的说,这一次实验只用了0.5123秒,当然在这里只是抛砖引玉,帮助大家打开思路,在这里还得感谢tushare的开发者,让我们可以很方便低获取一些很有价值的金融数据。
虽然不是万能的,但是却能使我们把更多的时间花在自己的模型上面。
在这里数据就不贴了,感兴趣的朋友自己动手实验一下,本次实验的电脑配置很一般,网速也算不上很好,不用担心你的网速,这个速度你一样可以达到,甚至可以更快。
如果想要把这个思路用在自己的服务器上面,用来获取一整天的实时数据,建议读者使用调度工具,最简单的是linux下面的crontab,它只支持最小单位为分钟的调度,但稍加运用,也可以用来调度我们获取实时数据的程序。
好了今天就到这里,想要获得更多优质的文章或数据请关注微信公众号【数据之佳】,我们将不定期在上面分享数据分析、机器学习、量化分析的一些思路,模型和结果,下面是微信公众号的二维码,如果你想尝试上面的代码,但是没有现成的股票代码,关注微信公众号【数据之佳】,回复【python量化】就可以得到下载链接。