判别分析实验报告模板1
2013实验报告-判别分析

2013实验报告-判别分析判别分析是一种模式识别技术,用于评估两个或多个已知分类的观测量。
该技术使用统计学方法来找出哪些变量最能区分不同的分类,以使模型能够对新的未知观测进行分类。
它可以在许多领域得到广泛应用,如医学、金融、自然科学、工业和社会科学等。
该实验使用判别分析技术来分析一个小型的数据集,以演示如何使用判别分析。
该数据集包括50个观测和两个变量,每个观测属于两种不同类型的花。
该数据集是经典的鸢尾花数据集,用于评估机器学习算法的性能。
为了进行判别分析,我们首先将数据集拆分成训练数据和测试数据。
训练数据用来创建模型,测试数据用来评估模型的性能。
使用判别分析函数fitdiscr来拟合模型,并使用测试数据来计算模型的分类准确性。
模型对测试数据集中的观测进行分类,并与实际标签进行比较,以确定模型的准确性。
在本实验中,我们使用了线性判别分析方法来分析数据。
线性判别分析是一种适用于两个或多个类别变量的判别分析方法,它将每个类别视为一个概率分布并通过计算类之间和类内差异来找到线性判别向量。
该方法基于类间方差和类内方差之间的比较来确定最佳的线性判别方向。
线性判别分析假设每个类别的协方差是相等的,并且由于可能有多个线性判别向量,因此我们需要使用额外的标准方法(如鉴别分析)来决定哪个线性判别向量最能区分不同的类别。
本实验结果表明,所构建的模型能够从花萼和花瓣长度和宽度这四个变量中提取有用的信息,并对测试数据的类别进行了准确分类。
通过将测试数据与训练数据相比较,发现模型对测试数据的分类准确性为96%,这表明该模型能够很好地对新的未知观测进行分类。
总之,判别分析是一种有用的模式识别技术,可以很好地应用于许多实际场景。
本实验演示了如何使用判别分析技术来分析数据并构建一个使用线性判别分析方法的分类模型。
《应用多元统计分析》第四章判别分析实验报告

《应用多元统计分析》第四章判别分析实验报告第四章判别分析实验报告实验环境Windows xp、Windows vista、Windows 7等,软件SPSS 11.0版本及以上。
实验结果与分析本题中记变量值CF_TD, NI_TA, CA_CL, CA_NS分别为X1,X2,X3,X4 (1)Fisher判别函数特征值EigenvaluesFunction Eigenvalue% of Variance Cumulative %CanonicalCorrelation1.940a100.0100.0.696a. First 1 canonical discriminant functions were used in the analysis.(2)Fisher判别函数有效性检验Wilks' LambdaTest ofFunction(s)Wilks' Lambda Chi-square df Sig.1.51527.8394.000(3)标准化的Fisher判别函数系数Standardized Canonical Discriminant FunctionCoefficientsFunction1CF_TD.134NI_TA.463CA_CL.715CA_NS-.220所以标准化的判别函数为:Y=0.134X1+0.463X2+0.715X3-0.220X4得出Y=0.9012(4)未标准化的Fisher判别函数系数Canonical Discriminant Function CoefficientsFunction1CF_TD.629NI_TA 4.446CA_CL.889CA_NS-1.184 (Constant)-1.327 Unstandardized coefficients所以为标准化的费希尔判别函数为:Y=-1.327+0.629X1+4.446X2+0.889X3-1.184X4得出Y=-0.1703(5)组重心处的费希尔判别函数值Functions at Group CentroidsG Function11.8692-1.035 Unstandardized canonical discriminant functions evaluated at group means各类重心在空间中的坐标位置。
【精品】多元统计分析--判别分析SPSS实验报告

【精品】多元统计分析--判别分析SPSS实验报告一、实验目的1.掌握判别分析的基本原理和应用方法;2.掌握SPSS软件进行判别分析的具体操作;3.通过一个实例,学习如何运用判别分析对指标进行判别。
二、实验内容三、实验原理1.判别分析基本原理:判别分析(Discriminant Analysis),是一种统计学中的分类技术,它是对变量进行归类的技术。
判别分析是用来确定一个对象或自变量集合属于哪一个预设类型或者组别的过程。
判别分析能够生成一个函数,将数据点映射到特定的类型上。
判别分析的应用领域非常广泛,主要应用于以下领域:(1)股票市场(预测股价的涨跌与时间、公司发展情况等因素的关系);(2)医学(区分疾病、患者状态等);(3)市场调查(确定客户类型、产品或服务喜好);(4)产业分析(区分有助于产品销售的市场决策因素);(5)经济学(预测月度或季度的经济指标)。
3.判别分析的主要应用步骤:(1)建立模型:首先选择和收集数据,将收集的数据分为训练集和测试集;(2)训练模型:使用训练数据建立模型;(3)评估模型:通过模型诊断来评估建立的模型的好坏;(4)应用模型:对新的数据建立模型并进行预测。
四、实验过程1. 上机操作:1)打开SPSS软件,加载数据文件;2)选择分类变量和连续变量;3)选择训练数据集;4)建立模型;5)预测实验数据集。
2. 操作步骤:SPSS分析的步骤如下:1)将数据输入SPSS软件,确保数据格式正确;2)选择Analyse- Classify- Discriminant;3)有两种不同的分类变量,单分类或多分类,如果你要解释一个特定的分类变量,选择单分类。
如果你不确定哪个分类变量最适合,请尝试不同的选项;4)选择两个或更个你认为与指定分类变量相关的连续变量;5)选择要用于判别分析的数据集;6)确定分类变量分类比率。
这可以在设置选项中完成;7)点击OK,开始进行分析;8)评估结果,包括汇总、判别函数、方差-方差贡献、判别矩阵;五、实验结果选取鸢尾花数据,经过训练,得到如下表所示的结果。
《多元统计实验》判别分析实验报告三

《多元统计实验》判别分析实验报告cbind(类别,newG,Z$post,Z$x)#合并原分类、回判分类回判后验概率及判别tab=table(类别,newG)#原分类和新分类列表比较tabsum(diag(prop.table(tab)))prenew=predict(ld,newdata=newdata)prenew#对三个待判样本进行判定cbind(prenew$class,prenew$post,prenew$x)#也可以按列合并在一起看二、实验结果分析5.5进行Fisher判别分析.若一位新客户的8个指标分别为(2 500, 1 500, 0,3, 2,3, 4, 1),试对该客户的信用度进行评价.以上输出结果中包括了lad()所用的公式、先验概率1、2、3、4、5 为:0.2941176 、0.1176471 、0.1764706 0.1764706 、0.2352941,各组均值向量、线性判别函数的系数。
输出所有分类组由输出结果可知第十二号样品为第四组的被误判给了第五组,且与距离判别法结果一致,最后对新客户的8个指标(2500,1500,0,3,2,3,4,1)进行判定。
说明:由$class可以看出该新用户被判入第一组,结果与距离判别法一致,对应的后验概率决定该新用户的归类组。
因此该新用户的信用度评价为一。
5.6试对表5-7中的数据进行Bayes判别分析并对8个待判样品的类别进行判定.由上结果可知,两个组别为一的被误判为第二组,第二组的三个被误判为第一组。
出现5个误判结果正确率为:0.9411765,误判错误的概率仍然较低。
Bayes判别法对八个待测样本的判定结果为:四个判给第一组,四个判给第二组,且Bayes 判别法是采用了新的后验概率,而不是先验概率。
因此判出概率相同。
判别分析实验报告SPSS

判别分析实验报告SPSS实验目的:判别分析(Discriminant Analysis)是一种经典的多元统计分析方法,用于解释和预测分类变量。
该实验旨在使用SPSS软件进行判别分析,探索一组变量对分类结果的贡献和预测能力。
实验步骤:1.数据收集:从一些公司的人力资源数据库中随机选择了200个员工作为样本,收集了以下变量:性别(男、女)、教育程度(本科、研究生、博士)、工龄(年)、绩效评分(0-5)、离职与否(是、否)。
2.数据清洗:检查数据中是否存在缺失值,并对缺失值进行处理。
删除离职与否变量中缺失值。
3.数据探索:使用SPSS进行描述性统计分析,了解样本的基本情况。
分别计算男女性别比例和各教育程度及离职状态的分布情况。
4. 变量选择:使用SPSS进行判别分析,将离职与否作为分类变量,性别、教育程度、工龄和绩效评分作为预测变量。
使用Wilks' Lambda检验选择预测变量,确定对分类结果的贡献。
5.判别函数计算:根据选择的预测变量,计算判别函数。
使用判别函数对样本进行分类,并计算分类结果的准确率。
实验结果:1.数据探索结果显示,样本中男女性别比例约为1:1,教育程度主要集中在本科和研究生,离职比例为14%。
2. 判别分析结果显示,Wilks' Lambda检验结果为0.632,p值小于0.05,说明选取的预测变量对分类结果有统计上显著的贡献。
3.计算得到的判别函数为D=-0.311(性别)+0.236(教育程度)+0.011(工龄)+0.585(绩效评分)。
4.使用判别函数对样本进行分类,分类准确率为81.5%。
其中,离职样本的分类准确率为75%,非离职样本的分类准确率为82%。
实验结论:通过判别分析实验,我们得出以下结论:1.性别、教育程度、工龄和绩效评分这四个变量对员工的离职与否有显著的预测能力。
2.预测变量中绩效评分对离职结果的贡献最大,说明绩效评分较低的员工更容易离职。
判别分析 实验报告

判别分析实验报告判别分析实验报告一、引言判别分析是一种常用的统计分析方法,广泛应用于数据挖掘、模式识别、生物信息学等领域。
本实验旨在通过对一个真实数据集的分析,探讨判别分析在实际问题中的应用效果。
二、数据集介绍本实验使用的数据集是一份关于肿瘤患者的临床数据,包括患者的年龄、性别、肿瘤大小、转移情况等多个变量。
我们的目标是根据这些变量,建立一个判别模型,能够准确地预测患者是否患有恶性肿瘤。
三、数据预处理在进行判别分析之前,我们首先对数据进行预处理。
这包括数据清洗、缺失值处理、异常值检测等步骤。
通过对数据的观察和分析,我们发现有部分数据存在缺失值,需要进行处理。
我们选择使用均值替代缺失值的方法进行处理,并对替代后的数据进行了异常值检测。
四、判别模型建立在本实验中,我们选择了线性判别分析(LDA)作为判别模型的建立方法。
LDA 是一种经典的判别分析方法,通过将数据投影到低维空间中,使得不同类别的样本在投影后的空间中能够更好地区分开来。
我们使用Python中的scikit-learn 库来实现LDA算法。
五、模型评估为了评估建立的判别模型的性能,我们将数据集划分为训练集和测试集。
使用训练集对模型进行训练,并使用测试集进行模型的评估。
我们选择了准确率、精确率、召回率和F1值等指标来评估模型的性能。
经过多次实验和交叉验证,我们得到了一个较为稳定的模型,并对其性能进行了详细的分析和解释。
六、结果与讨论经过模型评估,我们得到了一个在测试集上准确率为85%的判别模型。
该模型在预测恶性肿瘤时具有较高的精确率和召回率,说明了其在实际应用中的可行性和有效性。
但同时我们也发现,该模型在预测良性肿瘤时存在一定的误判率,可能需要进一步优化和改进。
七、结论本实验通过对一个真实数据集的判别分析,验证了判别分析方法在预测恶性肿瘤的应用效果。
通过建立判别模型,并对其性能进行评估,我们得到了一个在测试集上具有较高准确率的模型。
然而,我们也发现了该模型在预测良性肿瘤时存在一定的误判率,需要进一步的改进和优化。
多元统计判别分析实验报告
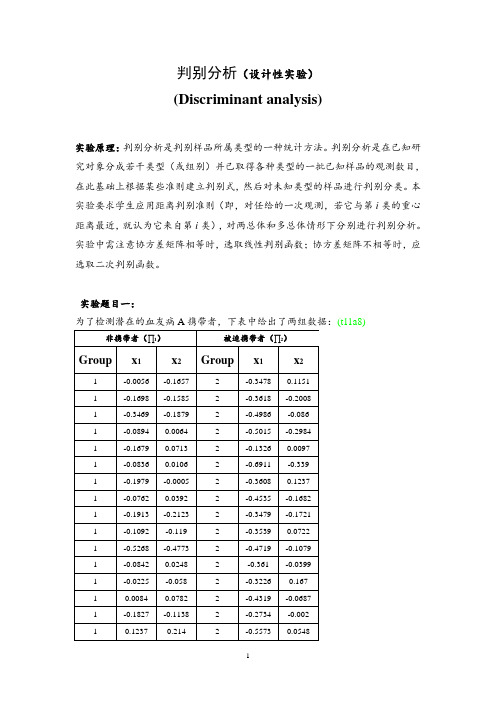
判别分析(设计性实验)(Discriminant analysis)实验原理:判别分析是判别样品所属类型的一种统计方法。
判别分析是在已知研究对象分成若干类型(或组别)并已取得各种类型的一批已知样品的观测数目,在此基础上根据某些准则建立判别式,然后对未知类型的样品进行判别分类。
本实验要求学生应用距离判别准则(即,对任给的一次观测,若它与第i类的重心距离最近,就认为它来自第i类),对两总体和多总体情形下分别进行判别分析。
实验中需注意协方差矩阵相等时,选取线性判别函数;协方差矩阵不相等时,应选取二次判别函数。
实验题目一:为了检测潜在的血友病A携带者,下表中给出了两组数据:(t11a8)其中x1=log10(AHF activity),x2=log10(AHF antigen)。
下表给出了五个新的观测,试对这些观测判别归类;(t11b8)实验要求:(1)分别检验两组数据是否大致满足二元正态性;(2)分别计算两组数据的协方差矩阵,是否可以认为两者近似相等?(3)对训练样本和新观测合并作散点图,不同的类用不同颜色标识;(4)用lda函数做判别分析,即在协方差矩阵相等的情形下作判别分析;(5)用qda函数做判别分析,即在协方差矩阵不相等的情形下作判别分析;(6)比较方法(4)和方法(5)的误判率。
实验题目二:某商学研究生院的招生官员利用指标――大学期间平均成绩GPA和研究生管理能力考试GMAT的成绩,将申请者分为三类:接受,不接受,待定。
下表中给出了三类申请者的GPA与GMAT成绩:(t11a6)GPA (x1)GMAT(x2)接受GPA(x1)GMAT(x2)不接受GPA(x1)GMAT(x2)待定2.96 596 1 2.54 446 2 2.86 494 33.14 473 1 2.43 425 2 2.85 496 3 3.22 482 1 2.2 474 2 3.14 419 3 3.29 527 1 2.36 531 2 3.28 371 3 3.69 505 1 2.57 542 2 2.89 447 3 3.46 693 1 2.35 406 2 3.15 313 3 3.03 626 1 2.51 412 2 3.5 402 3 3.19 663 1 2.51 458 2 2.89 485 3 3.63 447 1 2.36 399 2 2.8 444 3 3.59 588 1 2.36 482 2 3.13 416 3 3.3 563 1 2.66 420 2 3.01 471 3 3.4 553 1 2.68 414 2 2.79 490 33.5 572 1 2.48 533 2 2.89 431 33.78 591 1 2.46 509 2 2.91 446 33.44 692 1 2.63 504 2 2.75 546 33.48 528 1 2.44 336 2 2.73 467 33.47 552 1 2.13 408 2 3.12 463 33.35 520 1 2.41 469 2 3.08 440 33.39 543 1 2.55 538 2 3.03 419 33.28 523 1 2.31 505 2 3 509 33.21 530 1 2.41 489 2 3.03 438 33.58 564 1 2.19 411 2 3.05 399 33.33 565 1 2.35 321 2 2.85 483 33.4 431 1 2.6 394 2 3.01 453 33.38 605 1 2.55 528 2 3.03 414 33.26 664 1 2.72 399 2 3.04 446 33.6 609 1 2.85 381 23.37 559 1 2.9 384 23.8 521 13.76 646 13.24 467 1实验要求:(1)对上表中的数据作散点图,不同的类用不同的颜色标识;(2)用lda函数做判别分析,即在协方差矩阵相等的情形下作判别分析;(3)用qda函数做判别分析,即在协方差矩阵不相等的情形下作判别分析;(4)比较方法(2)和方法(3)的误判率;(5)现有一新申请者的GPA为3.21,GMAT成绩为497。
判别分析实验报告SPSS

一、实验目的及要求:1、目的用SPSS软件实现判别分析及其应用。
2、内容及要求用SPSS对实验数据利用Fisher判别法和贝叶斯判别法,建立判别函数并判定宿州、广安等13个地级市分别属于哪个管理水平类型。
二、仪器用具:三、实验方法与步骤:准备工作:把实验所用数据从Word文档复制到Excel,并进一步导入到SPSS 数据文件中,同时,由于只有当被解释变量是属性变量而解释变量是度量变量时,判别分析才适用,所以将城市管理的7个效率指数变量的变量类型改为“数值(N)”,度量标准改为“度量(S)”,以备接下来的分析。
四、实验结果与数据处理:表1 组均值的均等性的检验Wilks 的Lambda F df1 df2 Sig.综合效率标准指数.582 23.022 2 64 .000 经济效率标准指数.406 46.903 2 64 .000 结构效率标准指数.954 1.560 2 64 .218 社会效率标准指数.796 8.225 2 64 .001 人员效率标准指数.342 61.645 2 64 .000 发展效率标准指数.308 71.850 2 64 .000 环境效率标准指数.913 3.054 2 64 .054表1是对各组均值是否相等的检验,由该表可以看出,在0.05的显著性水平上我们不能拒绝结构效率标准指数和环境效率标准指数在三组的均值相等的假设,即认为除了结构效率标准指数和环境效率标准指数外,其余五个标准指数在三组的均值是有显著差异的。
表2 对数行列式group 秩对数行列式1 6 -33.4102 6 -33.1773 6 -40.584汇聚的组内 6 -32.308 打印的行列式的秩和自然对数是组协方差矩阵的秩和自然对数。
表3 检验结果箱的M 140.196F 近似。
2.498df1 42df2 1990.001Sig. .000 对相等总体协方差矩阵的零假设进行检验。
以上是对各组协方差矩阵是否相等的Box’M检验,表2反映协方差矩阵的秩和行列式的对数值。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
石家庄铁道大学
实验报告
课程名称:任课教师:实验日期:
班级:姓名:学号:
实验项目名称:判别分析
一、实验目的及要求
1. 通过上机操作使学生掌握判别分析方法在SPSS软件中的实现,了解判别方法的分类、适用条件和结果验证方法;
2. 要求学生熟悉判别分析的用途和操作,重点掌握对软件处理结果的解释(区域图、未标准化典型判别函数、标准化典型判别函数等)和如何使用分析结果对新样品进行分类;
3. 要求学生阅读一定数量的文献资料,掌握判别分析方法在写作中的应用。
二、实验环境
1.系统软件:WindowsXP
2.工具:SPSS16.0
三、实验内容
银行的贷款部门需要判别每个客户的信用好坏(是否未履行还贷责任),以决定是否给予贷款。
可以根据贷款申请人的年龄(X1)、受教育程度(X2)、现在所从事工作的年数(X3)、未变更住址的年数(X4)、收入(X5)、负债收入比例(X6)、信用卡债务(X7)、其它债务(X8)等来判断其信用情况。
文件“银行信用”包括从某银行的客户资料中抽取的部分数据。
⑴根据样本资料用Fisher判别法建立判别函数和判别规则。
⑵某客户的如上情况资料为(53,1,9,18,50,11.20,2.02,3.58),对其进行信用好坏的判别。
四、实验过程与步骤
1、使用菜单中File→Open命令,然后选中要分析的数据文件“银行信用”
2、选择Analyze→Classify→Discriminant,打开主对话框,将group移到“Grouping Variable”框中,激活Define Range,点击此按钮,进入定义范窗口,分别在“Minimum”和“Maximum”后面的矩形框中键入1与2,然后按“Continue”按钮返回主对话框。
3、在主对话框左边的矩形框中选择判别变量“贷款申请人的年龄(X1)、受教育程度(X2)、现在所从事工作的年数(X3)、未变更住址的年数(X4)、收入(X5)、负
债收入比例(X6)、信用卡债务(X7)、其它债务(X8)”,并用下面一个箭头按钮将它们移到“Independents”矩形框中。
默认系统选择判别分析的方法“Enter independent together”。
4、在主对话框中点击Statistics选项,进入统计量对话框。
在Function Coefficients框中,选择判别函数系数Fisher’s、Unstanhindardized。
然后按“Continue”按钮返回主对话框。
5、在主对话框中点击Classify选项,进入分类设置对话框。
除系统默认项外,在Display框中选中Leave-one-out classification和Summary table项,然后按“Continue”按钮返回主对话框。
6、在主对话框中点击Save选项,进入存储结果设置对话框。
选择“Predicted group membership”、“Discriminant scores”、“Probabilities of group membership”。
7、返回主对话框后按“OK”。
五、实验结果与分析
1、
(一)判别函数
表1 判别函数系数Classification Function Coefficients
分析:表1输出fisher线性判别函数:
第一组fisher判别函数:
F1=1.587*贷款申请人的年龄+22.170*受教育程度—4.379*现在所从事工作的年数—1.770*未变更住址的年数+4.673*收入(X5)+7.616*负债收入比例—46.123*信用卡债务(X7)—112.537
第二组fisher判别函数:
F2=1.656*贷款申请人的年龄+26.084*受教育程度—4.069*现在所从事工作的年数
—2.122*未变更住址的年数+4.123*收入(X5)+7.007*负债收入比例—40.968*信用卡债务(X7)—101.991
(二)交叉验证
表2 分类结果交叉表Classification Results b,c
分析:
上半部分为原始分类的结果,下半部分为交叉分类的结果。
原始数据是100%,交叉数据是66.7%。
2、
F1=1.587*53+22.170*1—4.379*9—1.770*18+4.673*50+7.616*11.2—46.123*2.02—112.537=148.25
F2=1.656*53+26.084*1—4.069*9—2.122*18+4.123*50+7.007*11.2—40.968*2.02—101.991=138.92
F1>F2 所以该人已履行还贷责任。