基于决策树算法的数据分类与分析研究
决策树算法介绍(DOC)
决策树算法介绍(DOC)3.1 分类与决策树概述3.1.1 分类与预测分类是⼀种应⽤⾮常⼴泛的数据挖掘技术,应⽤的例⼦也很多。
例如,根据信⽤卡⽀付历史记录,来判断具备哪些特征的⽤户往往具有良好的信⽤;根据某种病症的诊断记录,来分析哪些药物组合可以带来良好的治疗效果。
这些过程的⼀个共同特点是:根据数据的某些属性,来估计⼀个特定属性的值。
例如在信⽤分析案例中,根据⽤户的“年龄”、“性别”、“收⼊⽔平”、“职业”等属性的值,来估计该⽤户“信⽤度”属性的值应该取“好”还是“差”,在这个例⼦中,所研究的属性“信⽤度”是⼀个离散属性,它的取值是⼀个类别值,这种问题在数据挖掘中被称为分类。
还有⼀种问题,例如根据股市交易的历史数据估计下⼀个交易⽇的⼤盘指数,这⾥所研究的属性“⼤盘指数”是⼀个连续属性,它的取值是⼀个实数。
那么这种问题在数据挖掘中被称为预测。
总之,当估计的属性值是离散值时,这就是分类;当估计的属性值是连续值时,这就是预测。
3.1.2 决策树的基本原理1.构建决策树通过⼀个实际的例⼦,来了解⼀些与决策树有关的基本概念。
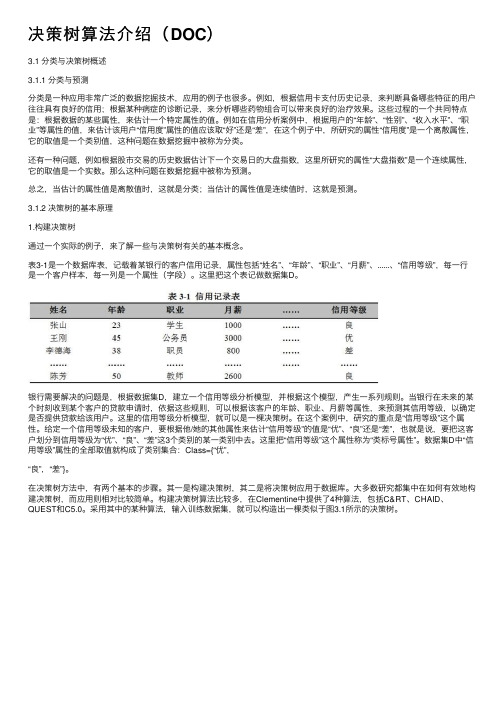
表3-1是⼀个数据库表,记载着某银⾏的客户信⽤记录,属性包括“姓名”、“年龄”、“职业”、“⽉薪”、......、“信⽤等级”,每⼀⾏是⼀个客户样本,每⼀列是⼀个属性(字段)。
这⾥把这个表记做数据集D。
银⾏需要解决的问题是,根据数据集D,建⽴⼀个信⽤等级分析模型,并根据这个模型,产⽣⼀系列规则。
当银⾏在未来的某个时刻收到某个客户的贷款申请时,依据这些规则,可以根据该客户的年龄、职业、⽉薪等属性,来预测其信⽤等级,以确定是否提供贷款给该⽤户。
这⾥的信⽤等级分析模型,就可以是⼀棵决策树。
在这个案例中,研究的重点是“信⽤等级”这个属性。
给定⼀个信⽤等级未知的客户,要根据他/她的其他属性来估计“信⽤等级”的值是“优”、“良”还是“差”,也就是说,要把这客户划分到信⽤等级为“优”、“良”、“差”这3个类别的某⼀类别中去。
决策树分析方法

客户流失的预测
总结词
采用决策树分析方法对客户流失进行预测,帮助企业了解可能导致客户流失的关键因素,从而制定相应的客户 保持策略。
详细描述
通过对企业历史数据的深入挖掘和分析,利用决策树算法构建一个客户流失预测模型。该模型可以识别出那些 具有较高流失风险的客户,并为企业提供相应的解决策略,如针对这些客户提供更加个性化的服务和优惠,加 强客户关系维护等。
集成学习方法
深度学习
将决策树与其他机器学习方法集成,如随机 森林、梯度提升等,可以提高预测性能和可 解释性。
利用深度学习技术改进决策树的训练和优化 过程,提高模型的表示能力和预测精度。
特征选择和表示学习
可解释性和透明度
发展更有效的特征选择和表示学习方法,以 更好地捕捉数据中的复杂模式和关系。
研究提高决策树可解释性的方法,如决策树 剪枝、可视化技术等,以满足用户对模型透 明度的需求。
决策树在回归问题中的应用
适用场景
决策树在回归问题中也有广泛应用,如预测房屋售价、股票价格等连续值。
实例
在预测房屋售价场景中,决策树可以通过对房屋属性进行划分,并赋予各个属性 不同的权重,最终得出房屋售价的预测值。
决策树在时间序列预测中的应用
适用场景
决策树可以应用于时间序列预测问题中,如股票价格、气候 预测等。
决策树的计算过程
数据准备
收集和准备需要分析的数据集 ,对数据进行清洗、预处理和 规范化等操作,使其符合决策
树算法的要求。
特征选择
选择与目标变量相关性较高的 特征作为节点,并计算每个特 征的信息增益、基尼指数等指 标,为决策树的建立提供依据
。
树的建立
根据选择出的特征,从根节点 开始,按照一定的顺序将数据 集划分成若干个子集,然后为 每个子集生成新的分支,如此 递归地构建出整个决策树。
分类分析--决策树(经典决策树、条件推断树)

分类分析--决策树(经典决策树、条件推断树)分类分析--决策树决策树是数据挖掘领域中的常⽤模型。
其基本思想是对预测变量进⾏⼆元分离,从⽽构造⼀棵可⽤于预测新样本单元所属类别的树。
两类决策树:经典树和条件推断树。
1 经典决策树经典决策树以⼀个⼆元输出变量(对应威斯康星州乳腺癌数据集中的良性/恶性)和⼀组预测变量(对应九个细胞特征)为基础。
具体算法如下:(1) 选定⼀个最佳预测变量将全部样本单元分为两类,实现两类中的纯度最⼤化(即⼀类中良性样本单元尽可能多,另⼀类中恶性样本单元尽可能多)。
如果预测变量连续,则选定⼀个分割点进⾏分类,使得两类纯度最⼤化;如果预测变量为分类变量(本例中未体现),则对各类别进⾏合并再分类。
(2) 对每⼀个⼦类别继续执⾏步骤(1)。
(3) 重复步骤(1)~(2),直到⼦类别中所含的样本单元数过少,或者没有分类法能将不纯度下降到⼀个给定阈值以下。
最终集中的⼦类别即终端节点(terminal node)。
根据每⼀个终端节点中样本单元的类别数众数来判别这⼀终端节点的所属类别。
(4) 对任⼀样本单元执⾏决策树,得到其终端节点,即可根据步骤3得到模型预测的所属类别。
上述算法通常会得到⼀棵过⼤的树,从⽽出现过拟合现象。
结果就是,对于训练集外单元的分类性能较差。
为解决这⼀问题,可采⽤10折交叉验证法选择预测误差最⼩的树。
这⼀剪枝后的树即可⽤于预测。
R中的rpart包⽀持rpart()函数构造决策树,prune()函数对决策树进⾏剪枝。
下⾯给出判别细胞为良性或恶性的决策树算法实现。
(1)使⽤rpart()函数创建分类决策树:#⽣成树:rpart()函数可⽤于⽣成决策树library(rpart)set.seed(1234)dtree <- rpart(class ~ ., data=df.train, method="class",parms=list(split="information"))#rpart() 返回的cptable值中包括不同⼤⼩的树对应的预测误差,因此可⽤于辅助设定最终的树的⼤⼩。
基于MODIS数据的决策树分类方法研究与应用

基于MODIS数据的决策树分类方法研究与应用刘勇洪;牛铮;王长耀【期刊名称】《遥感学报》【年(卷),期】2005(009)004【摘要】介绍了目前国际上流行的两种决策树算法--CART算法与C4.5算法,并引入了两种机器学习领域里的分类新技术--boosting和bagging技术,为探究这些决策树分类算法与新技术在遥感影像分类方面的潜力,以中国华北地区MODIS250m分辨率影像进行了土地覆盖决策树分类试验与分析.研究结果表明决策树在满足充分训练样本的条件下,相对于传统方法如最大似然法(MLC)能明显提高分类精度,而在样本量不足下决策树分类表现差于MLC;并发现在单一决策树生成中,分类回归树CART算法表现较C4.5算法具有分类精度和树结构优势,分类精度的提高取决于树结构的合理构建与剪枝处理;另外在决策树CART中引入boosting 技术,能明显提高那些较难识别类别的分类准确率18.5%到25.6%.【总页数】8页(P405-412)【作者】刘勇洪;牛铮;王长耀【作者单位】中国科学院,遥感应用研究所,遥感科学国家重点实验室,北京,100101;中国科学院,遥感应用研究所,遥感科学国家重点实验室,北京,100101;中国科学院,遥感应用研究所,遥感科学国家重点实验室,北京,100101【正文语种】中文【中图分类】TN911.73【相关文献】1.基于MODIS影像的森林类型决策树分类方法研究 [J], 吴梓尚;林辉;孙华;林欣2.基于MERSI和MODIS数据的2种监督分类方法比较研究 [J], 王馨凝;李国春3.基于 CART 决策树方法的 MODIS 数据海冰反演 [J], 张娜;张庆河4.基于MODIS时序数据的Landsat8影像选取及面向对象分类方法的农作物分类[J], 刘明月;王宗明;满卫东;毛德华;贾明明;张柏;张淼5.基于MODIS时序数据的Landsat8影像选取及面向对象分类方法的农作物分类[J], 刘明月;王宗明;满卫东;毛德华;贾明明;张柏;张淼;;;;;;;;;因版权原因,仅展示原文概要,查看原文内容请购买。
基于决策树模型的医疗设施可达性影响因素分析——以苏州市为例

40 | 人工智能时代的技术进步与城乡发展Analysis of Influencing Factors of Medical Facility Accessibility Based on Decision Tree Model: A Case Study of Suzhou City基于决策树模型的医疗设施可达性影响因素分析*——以苏州市为例吕 飞 陈明洁 魏晓芳 LYU Fei, CHEN Mingjie, WEI Xiaofang精准衡量城市医疗设施的空间配置情况、合理规划医疗公共空间,是实现城市稳定健康发展的重要保障。
以江苏省苏州市为例,运用两步移动搜索法,以街道为最小单元测算医疗设施的空间可达性,并基于决策树模型探讨影响苏州市医疗设施可达性空间格局的主要因素。
分析结果表明:苏州市医疗设施可达性自中心城区向郊区逐渐递减;且人口密度对医疗设施可达性影响显著,住宅区密度、容积率对医疗设施可达性影响较显著,人均GDP、路网密度和老龄化程度对医疗设施可达性作用较弱。
据此提出改善苏州市医疗设施分布均衡性和公平性的政策建议,以期为其他城市医疗设施建设提供借鉴。
Accurately measuring the spatial configuration of urban medical facilities and rationally planning medical public space areimportant guarantees for the realization of stable and healthy urban development. Taking Suzhou City as an example, the study uses the two-step mobile search method to measure the spatial accessibility of medical facilities with streets as the smallest unit, and discusses the main factors affecting the spatial pattern of medical facilities accessibility in Suzhou City based on a decision tree model. The research shows that the accessibility of medical facilities in Suzhou gradually decreases from the central urban area to the suburbs. The population density has a significant impact on the accessibility of medical facilities, and the density of residential areas and plot ratio have a significant impact on the accessibility of medical facilities. The network density and the degree of aging have a weak effect on the accessibility of medical facilities. Based on this, the study puts forward policy recommendations to improve the distribution balance and fairness of medical facilities in Suzhou, and provides references for the construction of medical facilities in other cities.医疗设施可达性;两步移动搜索法;决策树模型;苏州medical facility accessibility; two-step mobile search method; decision tree model; Suzhou文章编号 1673-8985(2022)05-0040-05 中图分类号 TU984 文献标志码 A DOI 10.11982/j.supr.20220507摘 要Abstract 关 键 词Key words 作者简介吕 飞苏州科技大学建筑学院教授,博士生导师,************.CN 陈明洁苏州科技大学建筑学院 硕士研究生魏晓芳苏州科技大学建筑学院副教授0 引言随着经济的发展,居民对公共服务设施建设提出更高的要求,而医疗设施作为公共服务设施的重要组成部分,也是城市居民日常公共服务消费的主要类型[1]。
基于决策树的鸢尾花分类

科技论坛0 引言图像识别技术,要运用目前流行的机器学习算法,而目前流行的机器学习算法就有十几种,比如支持向量机、神经网络、决策树。
机器学习是人工智能发展的重要一部分,它涉及的学科很多,应用也相当广泛,它通过分析、研究、设计让计算机学习知识,从而提高完善自身的性能。
但是神经网络学习的速度较慢,传统的支持向量机则不能解决分类多的问题。
本文针对鸢尾花的特征类别少以及种类少的特点,采用决策树算法对课题进行展开,对比与其他人利用支持向量机、神经元网络模型来进行研究,该系统具有模型简单、便于理解、计算方便、消耗资源少的优点。
1 决策树模型和学习本文采用决策树算法对鸢尾花进行分类,先建立决策树的模型并进行学习训练,在决策树的训练过程中采用是信息论的知识进行特征选择,对选定的特征采用分支的处理,然后再对分支过后的数据集如此反复的递归生成决策树,在一颗决策树生成完后对决策树进行剪枝,以减小决策树的拟合度,来达到一个对鸢尾花较高的分类准确率。
要对鸢尾花进行分类首先需要大量的鸢尾花数据集作为本文的实验数据,本文采用的数据集是来自加州大学欧文分校UCI数据库中的鸢尾花数据集。
该数据集中鸢尾花的属性有四个,分别是花萼长度、花萼宽度、花瓣长度和花瓣宽度,鸢尾花的类别则有三种,分别是Iris Setosa,Iris Versicolour,Iris Virginica,用简写Se、Ve和Vi表示这三种花,具体数据如图1所示。
■1.1 信息论美贝尔电话研究所的数学家香农是信息论的创始人,1948年香农发表了《通讯的数学理论》,成为信息论诞生的标志。
信息论的诞生对信息技术革命以及科学技术的发展起到重要作用。
信息论中有两个概念信息增益及信息增益率,都是用于衡量原始数据集在按照某一属性特征分裂之后整体信息量的变化值。
这样,本文就可以通过这种指标寻找出最优的划分属性,数据集在经过划分之后,节点的“纯度”越来越高,这里的纯度值得是花朵的类别,当某一节点中花朵全为一类时,该节点已经达到最纯状态,无需再进行划分,反之继续划分。
决策树分类算法的研究及其在电力营销中的应用

决策树分类算法的研究及其在电力营销中的应用随着科技的发展,大数据时代已经来临。
在这个时代,数据被认为是新的石油,而数据挖掘和机器学习则是挖掘数据价值的利器。
决策树分类算法作为一种常用的机器学习算法,因其简单易懂、易于实现等特点,在各个领域都得到了广泛的应用。
本文将从理论和实践两个方面,对决策树分类算法进行深入研究,并探讨其在电力营销中的应用。
一、决策树分类算法的理论基础1.1 决策树的定义与构造决策树是一种监督学习算法,主要用于分类问题。
它通过递归地分割数据集,将数据集划分为不同的子集,从而构建出一个决策树。
决策树的每个内部节点表示一个特征属性上的判断条件,每个分支代表一个判断结果,最后每个叶节点代表一个类别。
1.2 决策树的优点与缺点决策树具有以下优点:(1)易于理解和解释:决策树的结构清晰,可以通过查看决策树来直观地了解数据的分布特点和分类规律。
(2)易于实现和调整:决策树的算法实现相对简单,可以通过调整参数来优化决策树的性能。
(3)适用于大规模数据:决策树可以处理大量的数据,只要内存允许,就可以构建出非常庞大的决策树。
决策树也存在一些缺点:(1)容易过拟合:当训练数据集中的特征数量较多时,决策树可能会过度关注训练数据中的噪声,导致对新数据的泛化能力较差。
(2)不适用于高维数据:当数据集的维度较高时,决策树的性能可能会下降。
(3)需要预先设定特征属性的选择策略:如何选择最佳的特征属性进行分裂是一个复杂的问题,需要根据实际情况进行调整。
二、决策树分类算法在电力营销中的应用2.1 电力需求预测电力需求预测是电力营销的重要环节。
通过对历史用电数据的分析,可以预测未来一段时间内的用电量。
决策树分类算法可以用于构建电力需求预测模型,通过对不同特征属性的综合考虑,实现对用电量的准确预测。
2.2 负荷预测负荷预测是指对未来一段时间内电网负荷的预测。
负荷预测可以帮助电力公司合理安排发电计划,提高电力系统的运行效率。
如何使用决策树算法进行分类

如何使用决策树算法进行分类决策树算法是一种常用的机器学习算法,被广泛用于分类问题。
它通过将数据集划分为不同的子集,基于特征的不同取值进行决策,并最终生成一棵树结构来实现分类。
在本文中,我们将探讨如何使用决策树算法进行分类。
首先,我们需要了解决策树算法的工作原理。
决策树以树的形式表示,由根节点、内部节点和叶节点组成。
根节点表示最重要的特征,内部节点表示其他重要特征,而叶节点表示最终分类结果。
决策树的构建过程通过递归地选择最佳特征对数据进行划分,直到满足停止条件。
以下是使用决策树算法进行分类的步骤:1. 数据预处理:首先,我们需要对数据进行预处理。
这包括处理缺失值、异常值和重复值,以及对连续特征进行离散化等。
预处理是数据挖掘过程中的关键步骤,能够提高模型的准确性和鲁棒性。
2. 特征选择:选择合适的特征对分类结果有至关重要的影响。
可以使用相关性分析、信息增益等指标来评估特征的重要性。
选择具有较高信息增益或相关性的特征作为决策树的划分依据。
3. 决策树构建:决策树的构建是递归进行的过程。
从根节点开始,根据选定的特征将数据集划分成不同的子集。
可以使用多种划分准则,如基尼指数和信息增益等。
重复此过程,直到满足停止条件。
4. 停止条件:决策树构建的停止条件是根据实际需求进行定义的。
可以根据树的深度、节点的样本数或其他指标来进行判断。
过拟合是常见的问题,所以需要合理设置停止条件以避免过拟合。
5. 决策树剪枝:决策树构建完成后,可能出现过拟合的情况。
剪枝是通过裁剪决策树的一些子树来减少过拟合。
剪枝可以通过预剪枝或后剪枝来实现。
预剪枝是在构建树的过程中进行剪枝,而后剪枝是在构建完成后再进行剪枝。
6. 分类预测:完成决策树的构建和剪枝后,我们可以使用分类预测来对新样本进行分类。
从根节点开始,根据特征的取值进行递归判断,直到达到叶节点。
叶节点的分类结果即为预测结果。
决策树算法的优点在于易于理解和解释,而且可以处理非线性关系。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
基于决策树算法的数据分类与分析研究
近年来,随着信息技术的不断发展,数据产生的速度越来越快,数据量也越来
越大。
这就给数据的分类和分析带来了巨大的挑战。
为了更好地应对这个问题,现如今的数据处理往往采用机器学习等相关的技术。
其中,决策树算法是一个非常重要的算法之一。
决策树算法,简单来说,就是将数据集分成基本相同的组,最后把这些组分成
能够尽量区分出不同类别的几个大的类别。
在过程当中,决策树不停地根据数据集对特征进行选择,将特征中重要的特征放在树的顶端,以便更好地将数据分隔开来。
这里所说的“特征”可以指一些定量和定性的数据,例如温度、湿度、气压或者是文本、图片等数据信息。
那么,决策树算法在数据分类与分析中的作用又是什么呢?
1. 决策树可以自动化地分类和分析数据
相对于其他算法,决策树的特别之处在于,它不需要对数据进行太多的数据预
处理。
决策树算法在输入原始数据后可以自动学习出数据之间的联系,实现了自动化分类和数据分析的功能。
2. 决策树算法可以实现精准分类
在分类过程中,决策树算法能够将输入数据非常精准地分类。
这就意味着,在
数据分析过程中可以有效识别出各类别的数据,从而提高分类的精度。
3. 决策树算法提供了数据可视化
在决策树分类的过程中,不仅仅是会得出分类结果,而且能对分类结果进行可
视化处理。
这样,在分析数据时可以用图形的方式呈现出分类结果,使得数据分析更加简单直观。
4. 决策树算法可以快速处理海量数据
随着数据的增加,数据处理的难度也随之增加。
但是,决策树算法在面对大量数据时也能够快速处理,并得出相应的分类结果。
因此,在处理海量数据时,决策树算法可以提供更为高效的处理方式,提高数据分析和分类的效率。
总的来说,在分类和分析数据的过程中,决策树算法是一种十分有效的算法。
通过机器学习,它能够自主学习并识别数据之间的联系,呈现出数据的结构特征。
同时,在数据分析的过程中,决策树算法也具有物种类别定义清晰,分类准确,可视化效果佳以及处理效率高等优点。