车牌识别(字符切割)大作业
车牌的定位与字符分割 报告

车牌的定位与分割实验报告一实验目的针对交通智能系统所拍摄的汽车图片,利用设定的算法流程,完成对汽车车牌部分的定位,分割车牌部分,并完成字符的分割,以便于系统的后续分析及处理。
二实验原理详见《车牌的定位与字符分割》论文。
三概述1一般流程车牌自动识别技术大体可分为四个步骤:图像预处理、车牌定位与分割、车牌字符的分割和车牌字符识别。
而这四个步骤又可归结为两大部分:车牌分割和车牌字符识别。
图1-1为车牌自动识别技术的一般流程图。
2本实验的流程(1)图像预处理:图像去噪(2)车牌的定位:垂直边缘检测(多次)形态学处理的粗定位合并邻近区域结合车牌先验知识的精确定位(3)车牌预处理:车牌直方图均衡化倾斜校正判定(蓝底白字或者黄底黑字)归一化、二值化(4)字符的分割:垂直投影取分割阈值确定各个字符的左右界限(结合字符宽度、间隔等先验知识)分割字符四实验过程4.1图像预处理4.1.1图像去噪一般的去噪方法有:空间域上的均值滤波和中值滤波;频率域上的巴特沃斯滤波器。
图4-1是各滤波器处理椒盐噪声的效果。
a.被椒盐噪声污染的图片 b.均值滤波的效果图 c.中值滤波的效果图 d.BLPF的效果图图4-1 各滤波器处理椒盐噪声的仿真可见,中值滤波对椒盐噪声的处理效果极好,而一般所拍摄的图片上最多的便是孤立的污点,所以此处以中值滤波为主进行去噪。
图4-2是采用中值滤波处理实际汽车图片的效果。
a.原始图像b.灰度图像c.中值滤波后的图像图4-2 中值滤波处理实际汽车图片的效果很显然,经过中值滤波后去除了原图上的部分污点。
4.1.2图像复原由于通常情况下都不知道点扩展函数,所以我们采用基于盲解卷积的图像复原策略。
图4-3~4-7图是函数进行盲解卷积的实验结果,其中图4-3是图像cameraman 的模糊图像。
图4-3 模糊图像在盲解卷积处理中,选择适当大小的矩阵对恢复图像的效果很重要。
PSF的大小比PSF的值更重要,所以首先指定一个有代表性的全1矩阵作为初始PSF。
【车牌识别】-车牌中字符分割代码详解

【车牌识别】-车牌中字符分割代码详解车牌识别项⽬中,关于字符分割的实现:思路: 1. 读取图⽚,使⽤ cv2 。
2. 将 BGR 图像转为灰度图,使⽤ cv2.cvtColor( img,cv2.COLOR_RGB2GRAY) 函数。
3. 车牌原图尺⼨(170, 722) ,使⽤阈值处理灰度图,将像素值⼤于175的像素点的像素设置为 255 ,不⼤于175的像素点的像素设置为0 。
4.观察车牌中字符,可以看到每个字符块中的每列像素值的和都不为 0 ,这⾥做了假设,将左右结构的省份简写的字也看作是由连续相邻的列组成的,如 “ 桂 ” 。
5. 对于经过阈值处理的车牌中的字符进⾏按列求像素值的和,如果⼀列像素值的和为 0,则表明该列不含有字符为空⽩区域。
反之,则该列属于字符中的⼀列。
判断直到⼜出现⼀列像素点的值的和为0,则这这两列中间的列构成⼀个字符,保存到字典character_dict 中,字典的 key 值为第⼏个字符 ( 下标从0开始 ),字典的value值为起始列的下标和终⽌列的下标。
character_dict 是字典,每⼀个元素中的value 是⼀个列表记录了夹住⼀个字符的起始列下标和终⽌列下标。
6. 之后再对字符进⾏填充,填充为170*170⼤⼩的灰度图(第三个字符为⼀个点,不需要处理,跳过即可。
有可能列数不⾜170,这影响不⼤)。
7. 对填充之后的字符进⾏resize,处理成20*20的灰度图,然后对字符分别进⾏存储。
代码实现:1### 对车牌图⽚进⾏处理,分割出车牌中的每⼀个字符并保存2# 在本地读取图⽚的时候,如果路径中包含中⽂,会导致读取失败。
34import cv25import paddle6import numpy as np7import matplotlib.pyplot as plt8#以下两⾏实现了在plt画图时,可以输出中⽂字符9 plt.rcParams['font.sans-serif']=['SimHei']10 plt.rcParams['axes.unicode_minus'] = False111213# cv2.imread() 读进来直接是BGR 格式数据,数值范围在 0~255 。
车牌识别中字符分割算法的研究与实现毕业答辩PPT课件

LOGO
2021
一:论文的背景意义
背景和意义:车牌识别是现代智能交通系统中的重要组成
部分之一,可用于公路电子收费、出入控制和交通监控等众多 场合。它以数字图像处理、模式识别、计算机视觉等技术为基 础,对摄像机所拍摄的车辆图像或视频序列进行分析,得到每 一辆汽车唯一的车牌号码,从而完成识别过程。它主要包括三 个关键部分:车牌区域定位、车牌字符分割、车牌字符识别, 其中车牌字符分割的好坏直接影响到车牌识别的正确率,因此 本文对字符分割的算法进行了深入的研究。
车牌灰度图像 车牌二值化图像
车牌膨胀或腐蚀处理后图像
2021
LOGO
四:车牌分割
本文所采用的车牌字符分割方法为:
车牌像素和模板匹配相结合的车牌字符分割方法
(1)通过车牌字符串的高度H,构建符合实际车牌的
模板。
(2)将车牌模板在字符串上从左向右滑动,同时分
别求取当前位置的M1和N1。其中
, 6 bi
车牌图像分割结果
2021
LOGO
车牌字符分割结果的例证续:
车牌原图像
车牌灰度图像
车牌边缘检测图像
2021
车牌腐蚀后图像
LOGO
车牌平滑图像的轮廓
从对象中移除小对象
车牌图像定位结果
2021
LOGO
车牌图像预处理结果
车牌图像分割结果2021Fra bibliotekLOGO
总结:
本文对其中的车牌分割技术做了深入的研究,主要探讨了车牌定位、预处理以 及字符分割的算法。
LOGO
2021
论文研究步骤:
车牌图像的字符分割
由于有些 车牌 是两 行的形 式,所 以首 先 分割出各行文字的上下边界。从 上向下描标 记 像素点和不为零的行第一个像 素点和不为零的 行为第一行字符的上边界;接着向下扫描标记 像素点和再次变为零的行为第 一
行 字 符 的 下 边 界 ; 接 着 向 下 扫 捕 重 复 以 上操作知道全部扫描完毕。
( 3 ) 同样 利 用 me a n函 数 求 出 竖 直 投 影
具体算法流程图如图 4所示。
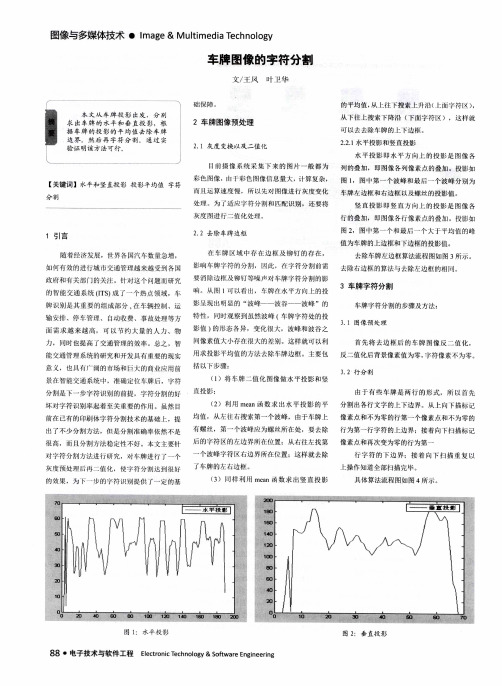
图 1 : 水 平 投 影
图2 :垂 直投 影
8 8 ・电子技 术与软 件工 程
E l e c t r o n i c T e c h n o l o g y &S o f t w a r e E n g i n e e r i n g
处 理 。 为 了 适 应 字 符 分 割 和 匹 配 识 别 , 还 要将 竖 直 投 影 即 竖 直 方 向 上 的 投 影 是 图 像 各
灰度图进 行二值 化处理 。
行的叠加 ,即图像 行像 素点 的叠加 。投影如 图2 ,图中第一个和最后一个 大 于平均值的峰 值 为车牌 的上边框和下边框的投影值 。
影值 ) 的形态各异 ,变化 很大,波峰和波谷之 间像素值大小存在很大 的差别 这样就可 以利 用求投影平均值 的方法 去除车牌边框 。主要包
括 以下 步 骤 :
首先 将去边 框后 的车 牌 图像反 二值化 , 反二值化后背景像 素值 为零 , 字符像素不为零。
3 . 2 行 分 割
景在智能交通 系统 中,准确 定位车牌 后,字符 分割是下一步字符识别 的前提 ,字符分割的好 坏对字符识别率起着至关重要的作用 。虽然 目 前在 已有的印刷体字符分割技术的基础上 .提
车牌的字符分割和字符识别的研究与实现

nu mbe fp cu e r m ho e t e r c n z d w t h e t r e t ro o r s o i e pae b ro it r sfo t s o b e og ie h t e fau e v co ft c rep ndng tm lt y i he
Hale Waihona Puke v rcl r et no ewht p e ia gs T e eont no m e o e yuigte e i o co fh i i li bnr i e. h c g io f u b r id n s tap j i t e x sn y ma r i n ss b n h
v corw h c m e cas d a he ihet s i rt e pae Ex rm e s h w ha t ee e t ih w b lse s t h g s i li y tm lt . m a pei nt s o t t h s m eho s t d rs l n h e e r e o e o n t n a d b te fe t e uti i rd g e fr c g ii o n e tre c .
一
项 重要研 究课题 , 是实 现交通 管理智 能化 的重要 环节 。它是 以数 字 图像 处理 、 式识 别 、 算 机 视觉 等技 模 计
术 为基础 的智能识 别系统 。它利 用每一 辆汽 车都有 唯一 的车牌号 码 , 过摄像 机所拍 摄 的车辆 图像 , 通 在不 影
响汽车状态的情况下 , 计算机 自动完成车牌的识别 , 从而可降低交通管理工作的复杂度。 由于车 牌识别 涉及到很 多复 杂因素 , 现有理 论和 方法还存 在识别 速度 慢 、 度低 、 干扰性 能差 等问题 , 精 抗 因此 有必要 进一步研 究 。本 文提 出 了一种 基 于模 板 匹配 的车牌 识别 方 法 ¨ , J 能有效 地 完成 不 同解析 度 和不
python中超简单的字符分割算法记录(车牌识别、仪表识别等)

python中超简单的字符分割算法记录(车牌识别、仪表识别等)背景在诸如车牌识别,数字仪表识别等问题中,最关键的就是将单个的字符分割开来再分别进⾏识别,如下图。
最近刚好⽤到,就⾃⼰写了⼀个简单地算法进⾏字符分割,来记录⼀下。
图像预处理彩图⼆值化以减⼩参数量,再进⾏腐蚀膨胀去除噪点。
image = cv2.imread('F://demo.jpg', 0) # 读取为灰度图_, image = cv2.threshold(image, 50, 255, cv2.THRESH_BINARY) # ⼆值化kernel1 = cv2.getStructuringElement(cv2.MORPH_RECT, (7, 7)) # 腐蚀膨胀核kernel2 = cv2.getStructuringElement(cv2.MORPH_RECT, (5, 5)) # 腐蚀膨胀核image = cv2.erode(image, kernel=kernel1) # 腐蚀image = cv2.dilate(image, kernel=kernel2) # 膨胀确定字符区域考虑最理想的情况,图中的字符是端正没有倾斜歪曲的。
将像素灰度矩阵分别进⾏列相加、⾏相加,则在得到的列和、⾏和数组中第⼀个⾮ 0 元素索引到最后⼀个⾮ 0 元素索引包裹的区间即就是字符区域。
h, w = image.shape # 原图的⾼和宽list1 = [] # 列和list2 = [] # ⾏和for i in range(w):list1.append(1 if image[:, i].sum() != 0 else 0) # 列求和,不为0置1for i in range(h):list2.append(1 if image[i, :].sum() != 0 else 0) # ⾏求和,不为0置1# 裁剪字符区域# 求⾏的范围flag = 0for i, e in enumerate(list1):if e != 0:if flag == 0: # 第⼀个不为0的位置记录start_w = iflag = 1else: # 最后⼀个不为0的位置end_w = i# 求列的范围flag = 0for i, e in enumerate(list2):if e != 0:if flag == 0: # 第⼀个不为0的位置记录start_h = ielse: # 最后⼀个不为0的位置end_h = iprint(start_w, end_w) # ⾏索引范围print(start_h, end_h) # 列索引范围分割单个字符与分割全部字符区域同理,在⾏和数组中⾮ 0 元素索引的范围即是单个字符的区域。
《数字图像处理》大作业:车牌识别

将图中字符分割出来 将每个字符单独分割出来进行操作方便字 符识别 用d=bwareaopen(d,150);将第二个 和第三个字符中间的点去除点。
分割第一个字符的程序
wide1 = 0 while sum(d(:,wide1+1))<3 && wide1 <= n-2 wide1 = wide1 + 1; end wide2 = wide1; while sum(d(:,wide2+1))>2 && wide2 <= n-2 wide2 = wide2 + 1; end % temp = imcrop(d, [wide1 1 wide2-wide1 m]); % figure;imshow(temp); % tp=3;bottm=m-5; while sum(d(tp,wide1:wide2))==0 tp = tp + 1; end while sum(d(bottm,wide1:wide2))==0 bottm = bottm - 1; end e1 = imcrop(d, [wide1 tp wide2-wide1 bottm-tp]);
%求出一列中满足蓝色区域点的个数
%找出车牌区域左右边界
车牌字符处理
首先要对定位好的车牌图像进行处理,再将车牌 上的字符分割出来,方便后续识别操作。ຫໍສະໝຸດ 图像灰度化图像二值化
图像滤波处理
车牌图像处理
图像处理部分程序
X = im2bw(Plate); 像 [H, L] = size(X); X = imcrop(X, [5 5 L-10 H-10]); %im2bw使用阈值变换法把灰度图 转换成二值图像。
车牌字符分割

图像处理包括图像二值化、车牌定位、字符分隔、字符识别。
每一步都关系系统成功与否以及好坏。
如果图片二值化不好就不方便车牌定位,如果定位的车牌图片不准确就谈不上字符的切割,字符图片切割不好就难以识别。
这些应该很好理解,可见成员之间需要很好的默契。
而我负责了图像处理中的字符分隔模块,起初我不知道位图形式以及如何读取位图,可见我获取信息的主动性和能力并不好。
非常感谢其他组员提供了读取位图像素数据的相关方法,才能使我能放心去思考切割的算法,而不必去担心如何获取数据的问题。
我使用了一种字符像素横向和纵向扫描的算法,得到字符在横向和纵向的像素分布波形,通常是缓慢的连续变化,车牌越模糊,变化越缓慢。
自然,波峰是字符区,波谷是字符间的空隙区。
它们的分界点并不明显,必然需要找到介于波峰与波谷之间的一个阀值,将波形变成01直方波形。
那么阀值自然是个关键,如果定得不准,就可能切不出所有字符,这是我之前遇到的问题,那时我固定了阀值,使它介于平均波峰值和平均波谷值之间的某个固定点,但这通常只能切割出模糊图片的部分字符,因为有些波峰和波谷并没有被切分开来。
于是我采用了另一种策略,即使用动态扫描,从最小的波谷扫到最大的波峰,并不断计算切得的波峰数量(实际就是字符数量)。
然后判断这个切割数是否符合实际车牌上的字符数量,如果符合,可以停止扫描,切割位置可以明确定在波峰和波谷的变化点上。
当然,我进行了各种优化,比如更多判断来排除各种车牌边框等干扰。
在DOS窗口上经过反复的数据显示测试,终于得到了非常不错的字————————————————————————————————————————————(1)利用字符像素XY方向扫描;(2)分析波形;(3)动态指定阀值;(4)获得01分布;(5)判断波形变化次数;(6)去干扰;(7)获得切割位置;时间有限,有不完善之处可以去本人博客提问:/flashforyou#pragma once#include <cstring>#include <cmath> //数学函数库#include <cstdio>#include <cstdlib>#include <cmalloc>#include "stdafx.h"#include <complex>#define WIDTHBYTES(bits) (((bits)+31)/32*4)/////////////////////////////////////typedef unsigned char BYTE;typedef unsigned short WORD;typedef unsigned long DWORD;typedef long LONG;///////////////////////////////////////***位图文件头信息结构定义//其中不包含文件类型信息(由于结构体的内存结构决定,要是加了的话将不能正确读取文件信息)typedef struct tagBITMAPFILEHEADER {DWORD bfSize; //文件大小WORD bfReserved1; //保留字,不考虑WORD bfReserved2; //保留字,同上DWORD bfOffBits; //实际位图数据的偏移字节数,即前三个部分长度之和} BITMAPFILEHEADER;///////////////////////////////////////***信息头BITMAPINFOHEADER结构,其定义如下:typedef struct tagBITMAPINFOHEADER{//public:DWORD biSize; //指定此结构体的长度,为40LONG biWidth; //位图宽LONG biHeight; //位图高WORD biPlanes; //平面数,为1WORD biBitCount; //采用颜色位数,可以是1,2,4,8,16,24,新的可以是32 DWORD biCompression; //压缩方式,可以是0,1,2,其中0表示不压缩DWORD biSizeImage; //实际位图数据占用的字节数LONG biXPelsPerMeter; //X方向分辨率LONG biYPelsPerMeter; //Y方向分辨率DWORD biClrUsed; //使用的颜色数,如果为0,则表示默认值(2^颜色位数)DWORD biClrImportant; //重要颜色数,如果为0,则表示所有颜色都是重要的} BITMAPINFOHEADER;/////////////////////////////////////////***调色板Palette,当然,这里是对那些需要调色板的位图文件而言的。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
图像处理技术
目录一.引言 (1)
二.目的和意义 (1)
三.设计原理 (1)
四.字符分割程序 (2)
五.结果 (4)
六.测试代码 (5)
七.系统的不足 (5)
八.总结 (5)
九.心得体会 (5)
十.致谢 (6)
十一.参考文献 (6)
一.引言
随着人们生活水平的不断提高,机动车辆数量大幅度增加,与之相配套的高速公路,城市路网及停车场越来越多,显著提高了人们对交通控制方面的要求。
由于计算机技术的发展,信息处理水平的提高使智能交通系统成为世界交通领域研究的重要课题。
其中车牌识别是智能交通系统的重要组成部分。
车牌识别系统能够自动、实时地检测车辆、识别汽车车牌,从而监控车辆的收费、闯关、欠费以及各种舞弊现象。
本系统为基于蓝色车牌的车牌识别系统,它能够识别非蓝色车辆的蓝底白字车牌。
该系统通过车牌提取、车牌定位、预处理、字符分割、字符识别五个模块组成车牌识别系统。
二.目的和意义
通过对车牌识别系统的研究,自己开发小型车牌识别系统,虽有一定的局限性与不完整性,但可以使自己更加的熟悉MATLAB语言,激发对研究的兴趣,拓宽知识面,为自己以后的研究打下基础。
在提升自身科研能力的同时,还能提高团队合作精神,清楚团队成员的分工,协调成员间的工作,为今后的团队合作研究积累经验。
三.设计原理
字符分割在此系统中有着承前启后的作用。
它在前期车牌定位的基础上进行字符的分割,然后利用分割的结果进行字符的识别。
字符识别的算法很多,应为车牌字符间间隔较大,不会出现字符粘连的情况,所以此处采用的方法为寻找连续有文字的块,若长度大于某阈值,则认为组成该块有两个字符,需要分割。
一般分割出来的字符要进行进
一步的处理,以满足下一步字符识别的需要。
但是对于车牌的识别,并不需要太多的处理就可以达到正确的目的。
在此系统中只进行了归一化处理,然后进行后期处理。
四.字符分割程序
function Img_cat(I)
% 寻找连续有文字的块,若长度大于某阈值,则认为该块有两个字符组成,需要分割
d=qiege(I);
[m,n]=size(d);
k1=1;k2=1;s=sum(d);j=1;
while j~=n
while s(j)==0
j=j+1;
end
k1=j;
while s(j)~=0 && j<=n-1
j=j+1;
end
k2=j-1;
if k2-k1>=round(n/6.5)
[val,num]=min(sum(d(:,[k1+5:k2-5])));
d(:,k1+num+5)=0; % 分割
end
end
% 再切割
d=qiege(d);
% 切割出7 个字符,首先对车牌图像自左向右逐列扫描,寻找连续有文字的区间块,将该区间块的有效宽度与某一固定阈值(本文设定的阈值为10,可更改)进行比较,若小于该设定阈值,则认为是左侧干扰,裁剪干扰区域;反之,分割出该模糊字符块
y1=10;y2=0.25;flag=0;word1=[];
while flag==0 %flag为自定义,用作标记循环
[m,n]=size(d); %返回矩阵d的尺寸信息,并存储在m,n中。
其中m中存储的是行数,n中存储的是列数
left=1;wide=0;
while sum(d(:,wide+1))~=0
wide=wide+1;
end
if wide<y1 % 认为是左侧干扰
d(:,[1:wide])=0;%将字符区域设置为黑色
d=qiege(d);%处理干扰后切割出该黑色区域
else
temp=qiege(imcrop(d,[1 1 wide m]));%分割出该模糊字符块
[m,n]=size(temp);
all=sum(sum(temp));
two_thirds=sum(sum(temp([round(m/3):2*round(m/3)],:)));
if two_thirds/all>y2 图像归一化处理
flag=1;word1=temp;
end
d(:,1:wide)=0;d=qiege(d);
end
end
% 分割出第2~7个字符
[word2,d]=getword(d);
[word3,d]=getword(d);
[word4,d]=getword(d);
[word5,d]=getword(d);
[word6,d]=getword(d);
[word7,d]=getword(d);
[m,n]=size(word1);
% 商用系统程序中归一化大小为40*20,此处演示word1=imresize(word1,[40 20]);
word2=imresize(word2,[40 20]);
word3=imresize(word3,[40 20]);
word4=imresize(word4,[40 20]);
word5=imresize(word5,[40 20]);
word6=imresize(word6,[40 20]); word7=imresize(word7,[40 20]);
imwrite(word1,'save\1.jpg'); imwrite(word2,'save\2.jpg'); imwrite(word3,'save\3.jpg'); imwrite(word4,'save\4.jpg'); imwrite(word5,'save\5.jpg'); imwrite(word6,'save\6.jpg'); imwrite(word7,'save\7.jpg'); End
五.结果
六.测试代码
function zln_Main()
a=imread('save\dw.jpg');
[d]=Img_process(a);
Img_cat(d);
figure
subplot(1,7,1),imshow(imread('save\1.jpg')),title('word1');
subplot(1,7,2),imshow(imread('save\2.jpg')),title('word2');
subplot(1,7,3),imshow(imread('save\3.jpg')),title('word3');
subplot(1,7,4),imshow(imread('save\4.jpg')),title('word4');
subplot(1,7,5),imshow(imread('save\5.jpg')),title('word5');
subplot(1,7,6),imshow(imread('save\6.jpg')),title('word6');
subplot(1,7,7),imshow(imread('save\7.jpg')),title('word7');
end
七.系统的不足
基于蓝色车牌的车牌识别系统无法识别蓝色车身的车牌和其他颜色的车牌;以提取的无倾斜车牌为研究对象,忽略了车牌的倾斜问题;提取车牌模板时的光照问题;车牌边框、柳丁以及车牌亮度不均等不利因素;车牌背景的限制(不能有大面积的蓝色障碍物)。
八.总结
在车牌识别系统的字符分割部分实现,通常有间距、间隙切分法,投影法,识别切分法。
本系统采用的是投影法,利用垂直投影(即一列
一列的统计像素)来进行字符分割,计算每一列中心黑色像素的总和,这种切分虽然速度快,但对不规范的字符会出现误分割的情况。
字符分割的具体算法:在图像的大致高度中(在qiege程序实现)自左向右的逐列扫描,遇到第一个黑色像素则是字符分割的起始位置,继续扫描,直至有一列没有黑色像素,则认为分割结束,继续这种方法直至图像最右端,这样则找到每个字符的稍精确的宽度范围。
在一直每个字符的范围内,再自上而下和自下而上逐行扫描。
九.心得体会
本车牌识别系统主要包括车牌提取、车牌定位、预处理、字符分割、字符识别。
本人负责车牌的字符分割,本文主要探讨了字符分割的方法及算法分析。
在字符分割过程中,我们用的是垂直投影法,这种方法的主要优点是在二值化很好的情况下,可以很好的把字符分割出来,但是在二值化并预处理后仍有字符粘连的情况字符无法分割。
在此系统的完成过程中,我发现好多系统项目都有相似之处,我相信在钻研本系统中所得到的收获对以后的其他课题研究有很大帮助。
而且增强团队之间的团结协作的能力,我更喜欢组织的探讨问题的氛围,学习到了他人的长处明白了自己的不足。
十.致谢
组长:xxx。
在他的帮助下我能系统的掌握设计一个项目的流程及应该注意的事项。
他帮助我解决了自己解决不了的许多问题。
十一.参考文献
张德丰.详解MATLAB数字图像处理
杨为民.王世文.车牌自动识别技术及应用邹永星.车牌字符分割方法的研究
白建华.车牌字符分割及识别算法研究。