基于局部聚类的自适应线性近邻传递分类算法
基于近邻传播的分布式数据流聚类算法

摘
要: 针对 分布 式数据 流聚类算法存在的聚类质量 不高、 通信代价 大的 问题 , 提 出了密度和代 表点 聚类思想相
结合的分布式数据流聚类算 法。该 算法的局部站 点采用近邻传播聚 类 , 引入 了类簇代表 点的概 念来描述局 部分布 的
概 要信息 , 全局站 点采 用基 于改进的 密度聚类 算法合 并局部站 点上传 的概 要数据 结构进 而获得 全局模 型。仿真 实验
文献标志码 : A
Di s t r i b ut e d da t a s t r e a m c l us t e r i n g a l g o r i t hm b a s e d o n a i n f i t y p r o pa g a t i o n
i n t r o d u c e d i n t h e l o c a l s i t e s u s i n g a f i f n i t y p r o p a g a t i o n c l u s t e i r n g , wh i l e t h e g l o b a l s i t e g o t t h e g l o b a l mo d e l b y me r g i n g t h e
J o u na r l o f C o mp u t e r A p p l i c a t i o n s
I SS N 1 0 01 — 9 0 81
2 01 3. 09。 01
计算机应用, 2 0 1 3 , 3 3 ( 9 ) : 2 4 7 7— 2 4 8 1
基 于 近 邻 传 播 的分 布 式 数 据 流 聚 类 算 法
张 建 朋 , 金 鑫 ,陈福 才 , 陈鸿 昶 ,侯 颖
【国家自然科学基金】_近邻算法_基金支持热词逐年推荐_【万方软件创新助手】_20140803
自适应粒子分布法 自适应扰动算子 自适应开关 膜蛋白 脑电信号 脑-机接口 聚类分析 聚类 维数约减 组合方法 线性近邻传递算法 纹理特征 精确重建 类代表点 离群样本 离散源 离散增量 离散余弦变换 离子浓度预测 磁共振 相似性检索 相似性 电子商务 生理信号 特征降维 特征融合 特征空间 特征抽取 特征向量 特征值提取 牛顿插值 灰色案例推理 滤波 滑动窗口 混杂案例推理 测地线距离 水解酶 模糊隶属度 模糊线性鉴别分析 模糊支持向量机 椒盐噪声 案例检索 朴素贝叶斯 木材细胞 最近邻距离 最优阈值 早熟收敛 旅行商问题 数据流 故障诊断 故障检测 情感识别 快速映射 微粒群优化(ps0)
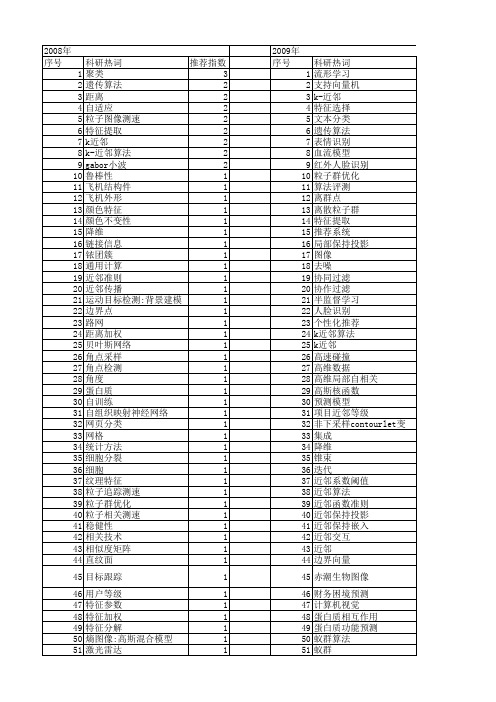
2009年 序号 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52
2008年 序号 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52
107 108 109 110 111 112 113 114 115
串行Байду номын сангаас构 sutton-chen势 nn-svm算法 mean shift算法 k近邻分类器 k-近邻 island+算法 gupta势 csift
1 1 1 1 1 1 1 1 1
近邻聚类算法

近邻聚类算法
近邻聚类(NeighborhoodAgglomerativeClustering),又称作层次聚类法(Hierarchical Clustering),通过不断的将最相似的类合并形成更大的类,最终形成一个层次结构的聚类。
其特点是可以考虑每个样本之间的相似度,常用于获得出物体在空间结构上的相互关系。
2.近邻聚类的基本思想
近邻聚类法的基本思想是:只需要考虑最邻近的样本,如果这些样本都相似,则聚为一类,直至所有样本都划分到一个类中。
因此,近邻聚类算法可以利用样本的邻近关系来构建聚类,从而可以计算出每个样本和其他样本之间的距离,据此来划分样本。
3.近邻法的优缺点
优点:
(1)简单易行,算法复杂度低;
(2)可以定义不同的样本相似度度量方式;
(3)可以分析大量数据;
缺点:
(1)需要进行大量距离的计算,计算量大;
(2)局部最优解,容易停留在局部最优的划分方案中;
(3)噪声数据影响大,容易产生聚类稀疏。
二、算法实现
1.算法步骤
(1)首先将样本数据集拆分成N份单独的簇;
(2)计算每一对簇之间的距离;
(3)找出距离最近的两个簇,将它们进行合并;
(4)重复步骤(2)和(3),直至所有的簇合并为一个;(5)根据簇内样本类别判断聚类结果是否正确。
一种基于聚类算法的网络异常检测方法研究

一种基于聚类算法的网络异常检测方法研究作者:赵明严宏举张明军安娜韩进喜来源:《计算机与网络》2020年第10期摘要:针对聚类算法普遍存在的数值震荡和计算量大以及传统异常检测中存在的分析准确率低和时效性差等问题,提出了一种改进的近邻传播聚类算法———IMAP的异常数据检测方法。
通过数据采集、数据预处理和聚类分析3个阶段实现异常数据的识别和定位,引入动态阻尼系数的聚类分析方法對标准化数据进行异常检测,为构造安全和稳定网络提供了参考。
实验结果表明,利用IMAP的异常检测方法能有效地提高异常检测的运行效率和算法的精确度,具有实际的应用价值和意义。
关键词:AP聚类;IMAP聚类;异常检测;聚类算法中图分类号:TP393文献标志码:A文章编号:1008-1739(2020)10-68-40引言近年来,随着互联网技术的发展,网络结构日益复杂,数据规模日益扩大,对网络的管理与监测越来越受到人们的重视。
物理拓扑上的网络动态级联故障将导致失效节点对周围节点产生级联失效效应[1-3]。
虚拟化技术的出现,虚拟节点与底层物理节点映射的动态性导致虚拟网络和底层物理网络的故障因果关系更加难以预测;网络运行稳定后,网络故障发生的频次低,导致异常数据收集少,进而难以覆盖异常的全部分布。
而当网络和信息系统迭代建设更新后,可能出现新的异常事件,但异常事件典型样本的缺乏将无法有效检测未知异常。
网络异常检测是指以网络流数据为输入,通过数据挖掘、统计分析和机器学习等方法,发现异常的网络数据分组和异常网络交互等信息[4-5],综合分析并借鉴上述异常检测方法的优缺点,提出一种基于改进的近邻传播(AP)聚类算法[6-10],用于进行网络异常数据检测,该AP聚类方法可以有效解决聚类算法普遍存在的数值震荡和计算量大等问题。
使用改进的AP聚类算法对网络异常进行检测,能有效提高检测效率,并能很好地适应通信网多样化的复杂数据。
1异常检测相关算法异常检测也被称为基于活动行为的入侵检测,是指能检测出区别于正常行为的所有的行为,如未知的攻击行为。
聚类算法和分类算法总结

聚类算法和分类算法总结聚类算法总结原⽂:聚类算法的种类:基于划分聚类算法(partition clustering)k-means:是⼀种典型的划分聚类算法,它⽤⼀个聚类的中⼼来代表⼀个簇,即在迭代过程中选择的聚点不⼀定是聚类中的⼀个点,该算法只能处理数值型数据k-modes:K-Means算法的扩展,采⽤简单匹配⽅法来度量分类型数据的相似度k-prototypes:结合了K-Means和K-Modes两种算法,能够处理混合型数据k-medoids:在迭代过程中选择簇中的某点作为聚点,PAM是典型的k-medoids算法CLARA:CLARA算法在PAM的基础上采⽤了抽样技术,能够处理⼤规模数据CLARANS:CLARANS算法融合了PAM和CLARA两者的优点,是第⼀个⽤于空间数据库的聚类算法FocusedCLARAN:采⽤了空间索引技术提⾼了CLARANS算法的效率PCM:模糊集合理论引⼊聚类分析中并提出了PCM模糊聚类算法基于层次聚类算法:CURE:采⽤抽样技术先对数据集D随机抽取样本,再采⽤分区技术对样本进⾏分区,然后对每个分区局部聚类,最后对局部聚类进⾏全局聚类ROCK:也采⽤了随机抽样技术,该算法在计算两个对象的相似度时,同时考虑了周围对象的影响CHEMALOEN(变⾊龙算法):⾸先由数据集构造成⼀个K-最近邻图Gk ,再通过⼀个图的划分算法将图Gk 划分成⼤量的⼦图,每个⼦图代表⼀个初始⼦簇,最后⽤⼀个凝聚的层次聚类算法反复合并⼦簇,找到真正的结果簇SBAC:SBAC算法则在计算对象间相似度时,考虑了属性特征对于体现对象本质的重要程度,对于更能体现对象本质的属性赋予较⾼的权值BIRCH:BIRCH算法利⽤树结构对数据集进⾏处理,叶结点存储⼀个聚类,⽤中⼼和半径表⽰,顺序处理每⼀个对象,并把它划分到距离最近的结点,该算法也可以作为其他聚类算法的预处理过程BUBBLE:BUBBLE算法则把BIRCH算法的中⼼和半径概念推⼴到普通的距离空间BUBBLE-FM:BUBBLE-FM算法通过减少距离的计算次数,提⾼了BUBBLE算法的效率基于密度聚类算法:DBSCAN:DBSCAN算法是⼀种典型的基于密度的聚类算法,该算法采⽤空间索引技术来搜索对象的邻域,引⼊了“核⼼对象”和“密度可达”等概念,从核⼼对象出发,把所有密度可达的对象组成⼀个簇GDBSCAN:算法通过泛化DBSCAN算法中邻域的概念,以适应空间对象的特点DBLASD:OPTICS:OPTICS算法结合了聚类的⾃动性和交互性,先⽣成聚类的次序,可以对不同的聚类设置不同的参数,来得到⽤户满意的结果FDC:FDC算法通过构造k-d tree把整个数据空间划分成若⼲个矩形空间,当空间维数较少时可以⼤⼤提⾼DBSCAN的效率基于⽹格的聚类算法:STING:利⽤⽹格单元保存数据统计信息,从⽽实现多分辨率的聚类WaveCluster:在聚类分析中引⼊了⼩波变换的原理,主要应⽤于信号处理领域。
一种基于局部异常因子(LOF)的k-means算法

一种基于局部异常因子(LOF)的k-means算法陈静;王伟【摘要】聚类分析算法是数据挖掘技术的一个重要分支,目前其研究已经广泛应用于教育、金融、零售等众多领域并取得了较好的效果。
本文结合了基于划分和密度的聚类思想,提出了一个适用于挖掘任意形状的、密度不均的、高效的聚类算法。
%Cluster analysis is an important research field in data mining,at present,the research has been applied to the financial, retail and other fields, and have achieved good results.This paper studied partition and density clustering algorithm, proposed a new algorithm which is suitable for mining arbitrary shape and uneven density.【期刊名称】《电子测试》【年(卷),期】2016(000)012【总页数】2页(P60-61)【关键词】数据挖掘;聚类算法;局部异常因子【作者】陈静;王伟【作者单位】青岛职业技术学院,山东青岛,266555;青岛职业技术学院,山东青岛,266555【正文语种】中文随着数据挖掘技术应用领域越来越广泛,聚类分析也接受着各种严峻的“考验”:处理的数据类型的多样化,对大数据集进行高效处理的迫切需求,对任意形状聚类的有效识别等等。
这些都要求聚类算法能够具体高效、灵活等特点,因此,寻求一个高效、灵活的聚类算法,是研究人员的当务之急。
聚类分析方法是数据挖掘技术应用最广泛的算法之一。
在机器学习领域,聚类分析算法属于无指导型学习算法。
给定一组对象,聚类分析自动地将其聚集成k个集群,每个集群中的对象具有极高的相似度,而属于不同集群的对象间的相似度很低。
【计算机应用研究】_k-means聚类算法_期刊发文热词逐年推荐_20140725
科研热词 聚类 遗传算法 资源查找 节点关联度 网格 维数约简 神经网络 社团结构 样本生成 数据挖掘 恢复机制 对等系统 复杂网络 协同过滤 动态模型 分类 主成分分析 不均衡数据集 k-means聚类算法 k-means聚类 k-means算法
推荐指数 4 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
2012年 序号 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52
53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77
2011年 科研热词 推荐指数 基于密度 3 聚类 2 类间距离 2 类内距离 2 k-均值聚类 2 k-均值算法 2 k-means算法 2 k-means 2 高斯性测度 1 长码直扩信号 1 迭代收敛 1 软件可靠性模型:k-means聚类 1 跳频 1 超球 1 视频检索 1 视觉词袋 1 规则化距离 1 蚁群聚类 1 自适应 1 能量均衡 1 群体智能 1 置信半径 1 粗糙集 1 粒平群优化 1 粒子群 1 粒子对 1 盲恢复 1 特征融合 1 特征基因 1 物体识别 1 点对点技术 1 游程检验 1 混合聚类 1 混合算法 1 流形学习 1 模型选择 1 极值优化算法 1 有监督的k-均值聚类算法 1 有界坐标系统 1 最大距离积 1 最大最小距离 1 显著区域 1 无线传感器网络 1 文本 1 整体相似度 1 数据挖掘 1 支撑向量机 1 支持向量机 1 形态学处理 1 属性依赖度 1 局部密度 1 局部切空间排列法 1
基于近邻传播的时间序列基因表达谱聚类算法
基于近邻传播的时间序列基因表达谱聚类算法
周运;徐久成;徐存拴
【期刊名称】《河南师范大学学报:自然科学版》
【年(卷),期】2015(0)6
【摘要】聚类是识别基因表达数据蕴含的关键基因调控模块的一种有效方法,基因表达谱的相似性度量是聚类的关键问题.然而,一般的相似性度量方法不能刻画时间序列基因表达谱数据所蕴含的时间延迟、反向相关和局部相关等复杂的基因调控关系.针对时间序列基因表达谱数据,提出一种基于近邻传播和动态规划的相似性度量方法和聚类算法.在大鼠再生肝细胞基因表达谱数据集上的聚类结果与基因功能富集分析结果高度一致,证明算法在时间序列基因表达谱数据聚类上的有效性.
【总页数】7页(P134-140)
【关键词】近邻传播;时间序列;反向相关;瞬时相关;基因表达谱
【作者】周运;徐久成;徐存拴
【作者单位】河南师范大学生命科学学院;河南师范大学省部共建细胞分化调控国家重点实验室培育基地;河南师范大学计算机与信息工程学院
【正文语种】中文
【中图分类】TP391.9
【相关文献】
1.基于粒子群算法的基因表达谱聚类分析方法 [J], 李梁;陈佳瑜
2.基于粒子群算法的基因表达谱聚类分析方法 [J], 李梁;陈佳瑜;
3.基因表达数据的分层近邻传播聚类算法 [J], 吴娱;钟诚;尹梦晓
4.基于局部密度估计和近邻关系传播的谱聚类 [J], 葛洪伟;李志伟;杨金龙
5.基于共享最近邻的密度自适应邻域谱聚类算法 [J], 葛君伟;杨广欣
因版权原因,仅展示原文概要,查看原文内容请购买。
基于网格局部密度的聚类算法
基于网格局部密度的聚类算法
马莹波
【期刊名称】《林区教学》
【年(卷),期】2011(000)003
【摘要】为了使基于网格的聚类技术适用于多密度数据集,提出一种基于局部密度的聚类算法.算法提出将数据单元格密度分类的方法,使得具有不同密度的单元格使用不同密度阈值的进行聚类.同时给出了边界单元的处理方法以提高聚类结果的精度.实验结果表明,GLD算法比其他类似算法有较高的聚类精度和效率.
【总页数】2页(P95-96)
【作者】马莹波
【作者单位】南京信息工程大学,计算机与软件学院,南京,210044
【正文语种】中文
【中图分类】TP301.6
【相关文献】
1.基于局部密度聚类算法的变压器故障状态评估 [J], 罗伟明;吴帆;黄业广;吴杰康;覃炜梅;龚杰;金尚婷
2.基于局部密度和动态生成网格聚类算法 [J], 邱保志;郑智杰
3.一种基于局部密度的网格排序聚类算法 [J], 刘建军;周廷英
4.基于改进力导向模型和局部密度的聚类算法 [J], 刘风剑; 刘向阳
5.基于局部密度的最小生成树聚类算法及其在电力大数据的应用 [J], 靳文星;王电钢;张哲敏
因版权原因,仅展示原文概要,查看原文内容请购买。
近邻聚类算法
近邻聚类算法近邻聚类算法(Nearest Neighbor Clustering)是一种常用的数据聚类方法,它基于数据点之间的相似度度量,将相似的数据点分为同一类别。
该算法的基本思想是通过计算数据点之间的距离或相似度,将距离较近的数据点划分为同一类别。
近邻聚类算法的步骤如下:1. 数据预处理:首先,需要对原始数据进行预处理,包括数据清洗、特征选择和特征缩放等。
数据预处理的目的是提高数据的质量和减少噪音的影响。
2. 计算相似度:接下来,我们需要计算数据点之间的相似度。
相似度可以通过计算数据点之间的距离或使用相似度度量方法(如余弦相似度)来获得。
常用的距离度量方法包括欧氏距离、曼哈顿距离和闵可夫斯基距离等。
3. 构建邻居图:根据相似度计算结果,我们可以构建一个邻居图。
邻居图是一个无向图,其中每个数据点作为一个节点,相似度高于一定阈值的数据点之间会存在边。
邻居图的构建可以通过设置邻居数量或相似度阈值来控制。
4. 寻找聚类中心:在邻居图中,我们可以通过寻找聚类中心来划分数据点的聚类。
聚类中心可以通过计算数据点到其他数据点的平均距离或相似度来获得。
一种常用的方法是选取邻居图中度最大的节点作为聚类中心。
5. 分配数据点:接下来,我们将每个数据点分配给距离最近的聚类中心。
这一步可以通过计算数据点与每个聚类中心的距离或相似度来完成。
数据点将被分配到与其最近的聚类中心所属的类别。
6. 聚类结果评估:最后,我们需要对聚类结果进行评估。
常用的评估指标包括紧密度(Compactness)和分离度(Separation)。
紧密度衡量了聚类内部的紧密程度,分离度衡量了不同聚类之间的分离程度。
评估指标越高,表示聚类结果越好。
近邻聚类算法的优点是简单易实现,不需要事先确定聚类数量,适用于数据集较大且聚类结构不明显的情况。
然而,该算法的效果受到数据点之间相似度计算的影响,对噪音和异常值敏感。
近邻聚类算法在实际应用中具有广泛的应用价值。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Ab s t r a c t :L i n e a r N e i g h b o r h o o d P r o p a g a t i o n( L N P )i s a g r a p h — b a s e d s e mi - s u p e r v i s e d c l ss a i i f c a t i o n me t h o d .I t c a n b e
用测地距 离和 欧氏距 离之 间的关 系来动 态确定每个点 的近邻数 。实验结果表 明 , 所提 方 法在得 到较好 的分类结果 的
同时, 也 极 大 地 缩 短 了运 行 时 间 , 提 高 了效 率 。 关键词 : 半监督 ; 图模 型 ; 局部 聚类 ; 自适 应 ; 图像 分 类 中 图分 类 号 : T P 3 9 1 . 4 1 文献 标 志 码 : A
分类结果 不精确 的问题 , 提 出了基 于局部 聚类的 自适 应 L N P分类算法 。该方法对 L N P分类算法的改进 主要体 现在 两
方 面, 首先运用 q u i c k s h i f t 进行局部 聚类 , 得到点簇 集, 以此点簇集作为建 图节 点, 达到缩 小矩 阵规模 的 目的 ; 其次 , 采
S HENG Ho n g b o . W ANG Xi l i 。
( S c h o o l o f C o m p u t e r S c i e n c e ,S h a a n x i N o r ma l U n i v e r s i t y ,X i ' a n S h a a n x i 7 1 0 0 6 2 ,C h i n a )
u s e d f o r i ma g e c l a s s i i f c a t i o n .L NP h s a h i g h c o mp u t a t i o n a l c o mp l e x i t y or f l rg a e i ma g e s .F u r t h e r mo r e ,i f t h e n u mb e r o f n e i g h b o r s i s u n s u i t a b l e , t h e c l a s s i f i c a t i o n r e s u l t s w i l l b e i n a c c u r a t e . T h e r e f o r e , a l o c a l l y c l u s t e r i n g b a s e d a d a p t i v e c l a s s i ic f a t i o n a l g o i r t h m or f L NP wa s p r o p o s e d i n t h i s p a p e r .T h e me t h o d i mp r o v e d t h e L NP c l ss a i i f c a t i o n a l g o it r h m i n t wo a s p e c t s .F i st r l y ,q u i c k s h i t f wa s u s e d f o r l o c a l c l u s t e r i n g t o g e t t h e p o i n t — c l u s t e r s .P o i n t - c l u s t e r s r e p l a c e d p i x e l s s a t h e ra g p h mo d e l n o d e s .T h e n t h e s i z e o f ma t r i x wa s r e d u c e d .S e c o n d l y ,t h e r e l a t i o n s h i p b e t we e n t h e g e o d e s i c d i s t a n c e a n d t h e E u c l i d e a n d i s t a n c e w a s u s e d t o d y n a mi c ll a y d e t e r mi n e t h e n u mb e r o f n e i g h b o r s or f e a c h p o i n t .T h e e x p e i r me n t a l r e s u l t s s h o w t h a t b e t t e r c l a s s i ic f a t i o n r e s u l t s re a o b t a i n e d b y t h e p r o p o s e d me t h o d a n d t h e r u n n i n g t i me i s l a r g e l y r e d u c e d . Ke y wo r d s :s e mi — s u p e vi r s e d ;g ra p h mo d e l ;l o c a l c l u s t e r i n g ;a d a p t i v e s e l e c t i o n ;i ma g e c l a s s i i f c a t i o n
盛洪波, 汪西莉 。
( 陕西师 范大学 计算机科学学院, 西安 7 1 0 0 6 2 ) ( 通信作者 电子邮箱 w a n g x i l i @s n n u . e d u . c n )
摘
要: 针 对线性近邻传递 ( L N P ) 分类算法 中, 由于图像 过大时计 算复杂度 高 , 以及 近邻数 目选择 不 当导致 图像
J o u r n a l i c a t i o n s
I S S N 1 0 0 1 . 9 0 8 1
2 0 1 4. O1 . 1 0
计算机应 用, 2 0 1 4 , 3 4 ( 1 ) : 2 5 5—2 5 9 文章编号 : 1 0 0 1 — 9 0 8 1 ( 2 0 1 4 ) O 1 - 0 2 5 5 - 0 5
C0 DEN J YI I D U
h t t p : / / w w w . j o c a . e n
d o i : 1 0 . 1 1 7 7 2 / j . i s s n . 1 0 0 1 - 9 0 8 1 . 2 0 1 4 . O 1 . 0 2 5 5
基 于 局 部 聚 类 的 自适 应 线 性 近 邻传 递 分 类 算 法
Lo c a l c l us t e r i ng b a s e d a da pt i v e l i ne a r ne i g hb o r h o o d
pr o pa g a t i o n a l g o r i t h m f o r i ma g e c l a s s i ic f a t i o n