Tiny语言的词法分析器C版课程设计报告
词法分析的实验报告

《词法分析》实验报告目录目录 (1)1 实验目的 (2)2 实验容 (2)2.1 TINY计算机语言描述 (2)2.2 实验要求 (2)3 此法分析器的程序实现 (3)3.1 状态转换图 (3)3.2 程序源码 (4)3.3 实验运行效果截图 (9)4 实验体会 (10)1实验目的1、学会针对DFA转换图实现相应的高级语言源程序。
2、深刻领会状态转换图的含义,逐步理解有限自动机。
3、掌握手工生成词法分析器的方法,了解词法分析器的部工作原理。
2实验容2.1TINY计算机语言描述TINY计算机语言的编译程序的词法分析部分实现。
从左到右扫描每行该语言源程序的符号,拼成单词,换成统一的部表示(token)送给语法分析程序。
为了简化程序的编写,有具体的要求如下:1、数仅仅是整数。
2、空白符仅仅是空格、回车符、制表符。
3、代码是自由格式。
4、注释应放在花括号之,并且不允许嵌套TINY语言的单词2.2实验要求要现编译器的以下功能1、按规则拼单词,并转换成二元式形式2、删除注释行3、删除空白符 (空格、回车符、制表符)4、列表打印源程序,按照源程序的行打印,在每行的前面加上行号,并且打印出每行包含的记号的二元形式5、发现并定位错误词法分析进行具体的要求1、记号的二元式形式中种类采用枚举方法定义;其中保留字和特殊字符是每个都一个种类,标示符自己是一类,数字是一类;单词的属性就是表示的字符串值。
2、词法分析的具体功能实现是一个函数GetToken(),每次调用都对剩余的字符串分析得到一个单词或记号识别其种类,收集该记号的符号串属性,当识别一个单词完毕,采用返回值的形式返回符号的种类,同时采用程序变量的形式提供当前识别出记号的属性值。
这样配合语法分析程序的分析需要的记号及其属性,生成一个语法树。
3、标示符和保留字的词法构成相同,为了更好的实现,把语言的保留字建立一个表格存储,这样可以把保留字的识别放在标示符之后,用识别出的标示符对比该表格,如果存在该表格中则是保留字,否则是一般标示符。
c词法分析器实验报告

c词法分析器实验报告篇一:词法分析器设计实验报告计算机与信息学院(信息工程系)编译原理实验报告专业班级课程教学班任课教实验指导教师实验地点XX ~XX学年第一学期实验一词法分析器设计一、实验目的通过本实验的编程实践,使学生了解词法分析的任务,掌握词法分析程序设计的原理和构造方法,使学生对编译的基本概念、原理和方法有完整的和清楚的理解,并能正确地、熟练地运用。
二、实验内容用 VC++/VB/JAVA 语言实现对 C 语言子集的源程序进行词法分析。
通过输入源程序从左到右对字符串进行扫描和分解,依次输出各个单词的内部编码及单词符号自身值;若遇到错误则显示“Error”,然后跳过错误部分继续显示;同时进行标识符登记符号表的管理。
以下是实现词法分析设计的主要工作:(1)从源程序文件中读入字符。
(2 (3 (4(属性值——token 的机内表示)(5)如果发现错误则报告出错 7(6三、实验流程图四、实验步骤12、编制好源程序后,设计若干用例对系统进行全面的上机测试,并通过所设计的词法分析程序;直至能够得到完全满意的结果。
3、书写实验报告;实验报告正文的内容:五、实验结果篇二:C语言词法分析器实验报告计算机科学与工程系编译原理课程设计实验报告姓名:__ ******__ 学号_ *******__ 年级专业及班级___08计算机科学与技术成绩- 1 -- 2 -- 3 -- 4 -- 5 -篇三:词法分析器实验报告实验报告实验题目:词法分析器院系班级:计科系0901班姓名学号: XX210603实验时间:XX-10-21设计。
编制并调试一个词法分析程序,加深对词法分析原理的理解。
实验要求设计出一个简单的词法分析程序,能够识别关键字(包含begin、if、end、 while、else、 then)、标识符、数字及数种符号(+、-、*、/、(、)、:、=、:=、#、>、、=、;)。
返回并打印各类字符所对应的种类编码及该字符所组成的二元组。
实验一词法分析器实验报告示例
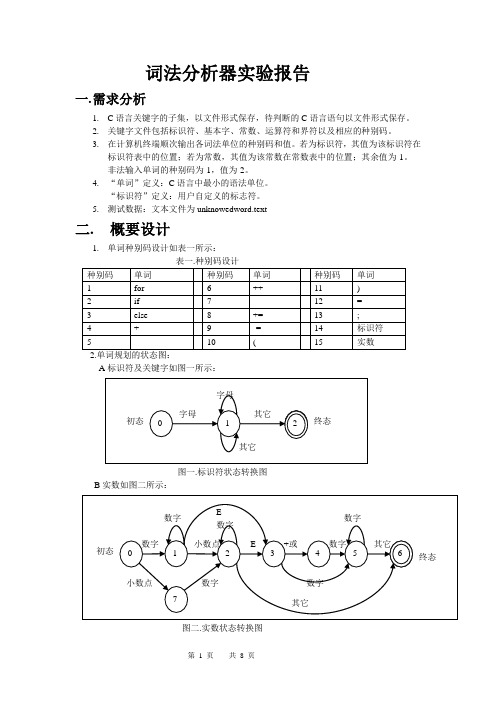
词法分析器实验报告一.需求分析1.C语言关键字的子集,以文件形式保存,待判断的C语言语句以文件形式保存。
2.关键字文件包括标识符、基本字、常数、运算符和界符以及相应的种别码。
3.在计算机终端顺次输出各词法单位的种别码和值。
若为标识符,其值为该标识符在标识符表中的位置;若为常数,其值为该常数在常数表中的位置;其余值为-1。
非法输入单词的种别码为-1,值为-2。
4.“单词”定义:C语言中最小的语法单位。
“标识符”定义:用户自定义的标志符。
5.测试数据:文本文件为unknowedword.text二.概要设计1.单词种别码设计如表一所示:A标识符及关键字如图一所示:图一.标识符状态转换图B实数如图二所示:图二.实数状态转换图C图三.运算符状态转换图D其它与运算符雷同,此处略3. 数据结构know[N] 用来存放构成单词符号的字符串;unknow[N]用来存放待辨别的字符串;chartab[T][N] 用来存放识别出的标识符;keytab[M][N] 用来存放从文件中读入的基本字;consttab[T] 用来存放识别出的实数。
以上均设为全局变量。
4.基本操作Getchar()初始条件:unknow中读入了一串待辨别的字符串。
操作结果:从unknow读入一个字符到ch中,指向unknow的指针加1。
Getbc()初始条件:unknow中读入了一串待辨别的字符串。
操作结果:从unknow中读入不是空格的下一个字符。
Concat()初始条件:know中为字母且ch中为字母,或know中为数字(包括小数点)ch中也为数字。
操作结果:将ch中的字符连接到know中。
Isletter()初始条件:ch中已经读入了一个新的字符。
操作结果:判断ch中的字符是否字母。
Isdigit()初始条件:ch中已经读入了一个新的字符。
操作结果:判断ch中的字符是否数字。
Keyword()初始条件:已判断出know中的字符串为标识符。
TINY-C编译器的设计与实现-词法分析器的设计与实现

目录摘要: (1)一前言 (3)1.1编译系统概述 (3)1.2编译器的概述 (3)1.3TINY语言的概述 (4)二需求分析 (6)2.1 词法分析目的 (6)2.2 词法分析中的定义 (6)2.3 词法分析概述 (6)2.4 词法分析功能 (6)2.5词法分析的要求 (7)2.6 外部接口要求 (7)2.7 数据流程图 (7)2.7.1 顶层数据流程图 (7)2.7.2 第二层数据流程图 (7)三概要设计 (9)3.1概要设计分析 (9)3.1.1 目的 (9)3.1.2 定义 (9)3.1.3 参考资料 (9)3.2 任务概述 (9)3.2.1 目标 (9)3.2.2 需求概述 (10)3.3 总体设计 (10)3.3.1 词法分析的目标和作用 (10)3.3.2词法分析的数学基础和算法: (10)3.3.3 TINY编译器的词法分析的实现: (12)3.3.4词法分析器的总体结构和外部模块 (14)四详细设计与编码 (15)4.1 引言 (15)4.1.1 根本目的 (15)4.1.2 要求 (15)4.1.3 参考资料 (15)4.2 任务概述 (15)4.2.1 目标 (15)4.2.2 需求概述 (15)4.3 总体设计 (15)4.3.1 需求概述 (15)4.3.2 词法分析器的结构 (15)4.4 程序设计说明 (16)4.4.1 全局模块 (19)4.4.2 词法分析模块 (22)五测试分析 (31)5.1 引言 (31)5.1.1编写目的: (31)5.1.2项目背景: (31)5.1.3定义: (31)5.2 任务概述 (31)5.2.1目标: (31)5.2.2运行环境: (31)5.2.3需求概述: (32)5.2.4条件与限制: (32)5.3 计划 (32)5.3.1测试方案: (32)5.3.2测试项目 (32)5.4 测试项目说明 (32)5.4.1 测试项目名称及测试内容(1) (32)5.4.2测试项目名称及测试内容(2) (33)5.5 评价 (34)5.5.1 软件能力 (34)5.5.2 缺陷和限制 (34)5.6 测试结论 (34)六总结与心得 (35)参考文献 (36)致谢........................................ 错误!未定义书签。
TINY-C编译器的设计与实现-语法分析器的设计与实现

目录摘要 (3)1。
前言 (4)2。
语法分析器的设计原理 (6)2.1 语法分析器的功能 (6)2。
2 语法分析的目标和作用 (6)2.3 构造语法分析器的步骤 (6)2。
4 上下文无关文法及分析 (7)2。
5 常用的语法分析方法和几种算法的比较 (9)2.5.1自上而下分析法 (9)2.5。
2自下而上分析法 (11)3. 语法分析器的设计和实现 (14)3。
1 TINY语言的介绍 (14)3。
2 TINY的文法生成 (14)3.3 TINY语法分析器算法的选择 (17)3。
4 TINY语言的递归下降分析程序 (20)3.5 TINY语法分析的输出 (22)3。
5.1 语法分析的输出结果 (22)3.5.2 抽象语法树的节点声明 (23)3.5。
3 语法树结构 (24)3。
6 语法分析的主要函数与核心代码 (28)3。
6。
1 语法分析器的主要文件和函数 (28)3.6.2 语法分析模块 (29)4. 测试分析 (39)4。
1 测试方法 (39)4。
2 测试计划 (39)4.3 测试项目说明 (39)4.4 测试结论 (43)5. 结论与心得 (44)参考文献 (45)致谢................................... 错误!未定义书签。
附录................................... 错误!未定义书签。
ContentsAbstract (4)1。
Preface (6)2。
Syntax analyzer principle of design (7)2。
1 Function of parsing (7)2。
2 Purpose and function of parsing (7)2.3 The of parsing analyzer structure (7)2。
4 Context—free grammar and analysis (8)2。
TINY部分源码分析报告

TINY部分源码分析报告TINY是一种简单的编程语言,用于教学目的。
它的语法规则非常简单,只有几个基本的关键字和语句。
在这篇报告中,我将对TINY的部分源码进行分析。
首先,让我们来看一下TINY的词法分析器部分的源码。
TINY的词法分析使用了一种基于有限自动机的方法。
源码中定义了几个关键字和运算符的正则表达式模式,并使用这些模式进行匹配。
如果匹配成功,就返回对应的记号。
接下来是语法分析器部分的源码。
TINY的语法分析使用了递归下降的方法。
源码中定义了几个非终结符的函数,每个函数对应语法中的一个产生式。
函数根据当前输入的记号,选择适当的产生式,并继续递归下降,直到匹配整个输入。
TINY的语法规则非常简单,只有if语句、while语句、表达式、赋值语句等几个基本的语法结构。
在语法分析器的源码中,每个函数都对应一个语法规则。
例如,函数parseStatement用于解析语句,它根据当前输入的记号,选择适当的产生式,例如if语句的产生式或赋值语句的产生式。
为了简化语法分析过程,TINY使用了LL(1)文法。
LL(1)文法是指,对于任意一个非终结符X和一个记号a,最多只有一个产生式可以选择。
这样可以使得语法分析过程更加简单和高效。
除了词法分析器和语法分析器,TINY还包括了一个解释器部分的源码。
解释器使用了递归下降的方法,根据语法分析的结果进行解释执行。
解释器遵循TINY的语义规则,例如执行赋值语句将变量的值更新为表达式的值。
总结起来,TINY是一种简单的编程语言,它的源码包括词法分析器、语法分析器和解释器部分。
词法分析器负责将源代码转化为记号序列,语法分析器负责根据记号序列生成抽象语法树,解释器负责执行抽象语法树中的操作。
TINY的源码采用了有限自动机和递归下降的方法,通过正则表达式模式和LL(1)文法来进行匹配和选择。
整个源码非常简洁,适合用于教学和学习。
[汇编]C_minus语言词法分析器的设计
![[汇编]C_minus语言词法分析器的设计](https://img.taocdn.com/s3/m/63ed05bfd0f34693daef5ef7ba0d4a7302766c49.png)
实验一:词法分析程序的设计与实现姓名:专业班级:学号:一、实验目的设计一个简单的词法分析器,从而进一步加深对词法分析器工作原理的理解。
二.、实验内容编制一个能够分析三种整数、标识符、主要运算符和主要关键字的词法分析程序。
三、实验要求根据PL/0语言文法,编制词法分析程序GETSYM完成以下功能:1)从键盘读入数据,分析出一个单词。
2)返回单词种别(用整数表示),3)返回单词属性(不同的属性可以放在不同的全局变量中)。
四.、实验步骤1. 采用C语言,设计GETSYM ,实现该算法2. 编制测试程序(主函数main)。
3. 调试程序:输入一组单词,检查输出结果。
五.、实验设计分析1.词法的正规式描述S=aA|aA=(aA|dA)}(a|d)2.变换后的正规文法S→aAS→aA→aAA→dAA→aA→d3.词法分析程序的程序代码#include "stdafx.h"#include <iostream>#include<string>using namespace std;#define MAX 17char ch =' ';stringkey[17]={"const","long","float","double","void","main","if","else","then","break","int","char","in clude","for","while","printf","scanf"};int Iskey(string c){ //关键字判断int i;for(i=0;i<MAX;i++){if(key[i].compare(c)==0) return 1;}return 0;}int IsLetter(char c){ //判断是否为字母if(((c<='z')&&(c>='a'))||((c<='Z')&&(c>='A'))) return 1;else return 0;}int IsLetter1(char c){ //判断是否为a~f字母if(((c<='f')&&(c>='a'))||((c<='F')&&(c>='A'))) return 1;else return 0;}int IsDigit(char c){ //判断是否为数字if(c>='0'&&c<='9') return 1;else return 0;}void scan(FILE *fpin){string arr="";while((ch=fgetc(fpin))!=EOF){arr="";if(ch==' '||ch=='\t'||ch=='\n'){}else if(IsLetter(ch)||ch=='_'){arr=arr+ch;ch=fgetc(fpin);while(IsLetter(ch)||IsDigit(ch)){if((ch<='Z')&&(ch>='A')) ch=ch+32;arr=arr+ch;ch=fgetc(fpin);}fseek(fpin,-1L,SEEK_CUR);if (Iskey(arr)){cout<<arr<<"\t关键字"<<endl;}else cout<<arr<<"\t普通标识符"<<endl;}else if(IsDigit(ch)){int flag=0;if(ch=='0'){arr=arr+ch;ch=fgetc(fpin);if(ch>='0'&&ch<='7'){while(ch>='0'&&ch<='7'){flag=1;arr=arr+ch;ch=fgetc(fpin);}}else if(ch=='x'||ch=='X'){flag=2;arr=arr+ch;ch=fgetc(fpin);while(IsDigit(ch)||IsLetter1(ch)){arr=arr+ch;ch=fgetc(fpin);}}else if(ch==' '||ch==','||ch==';' ){cout<<arr<<"\t整数0"<<endl;}fseek(fpin,-1L,SEEK_CUR);if(flag==1) cout<<arr<<"\t八进制整数"<<endl;else if(flag==2) cout<<arr<<"\t十六进制整数"<<endl;}else{arr=arr+ch;ch=fgetc(fpin);while(IsDigit(ch)){arr=arr+ch;ch=fgetc(fpin);}fseek(fpin,-1L,SEEK_CUR);cout<<arr<<"\t十进制整数"<<endl;}}else switch(ch){case'+':case'-' :case'*' :case'=' :case'|' :case'/' :cout<<ch<<"\t运算符"<<endl;break;case'(' :case')' :case'[' :case']' :case';' :case'.' :case',' :case'{' :case'}' :cout<<ch<<"\t界符"<<endl;break;case':' :{ch=fgetc(fpin);if(ch=='=') cout<<":="<<"\t运算符"<<endl;else{cout<<"::"<<"\t界符"<<endl;;fseek(fpin,-1L,SEEK_CUR);}}break;case'>' :{ch=fgetc(fpin);if(ch=='=') cout<<">="<<"\t运算符"<<endl;if(ch=='>')cout<<">>"<<"\t输入控制符"<<endl;else {cout<<">"<<"\t运算符"<<endl;fseek(fpin,-1L,SEEK_CUR);}}break;case'<' :{ch=fgetc(fpin);if(ch=='=')cout<<"<="<<"\t运算符"<<endl;else if(ch=='<')cout<<"<<"<<"\t输出控制符"<<endl;else if(ch=='>') cout<<"<>"<<"\t运算符"<<endl;else{cout<<"<"<<"\t运算符"<<endl;fseek(fpin,-1L,SEEK_CUR);}}break;default : cout<<ch<<"\t无法识别字符"<<endl;}}}void main(){char in_fn[30];FILE * fpin;cout<<"请输入源文件名(包括路径和后缀名):";for(;;){cin>>in_fn;if((fpin=fopen(in_fn,"r"))!=NULL) break;else cout<<"文件路径错误!请输入源文件名(包括路径和后缀名):";}cout<<"\n分析如下:\n"<<endl;scan(fpin);fclose(fpin);}七.实验测试:输入数据及运行结果:int a=3;double b=4;int c;if(a>b)c=a;elsec=b;。
C_minus语言词法分析器的设计

实验一:词法分析程序的设计与实现姓名:专业班级:学号:一、实验目的设计一个简单的词法分析器,从而进一步加深对词法分析器工作原理的理解。
二.、实验内容编制一个能够分析三种整数、标识符、主要运算符和主要关键字的词法分析程序。
三、实验要求根据PL/0语言文法,编制词法分析程序GETSYM完成以下功能:1)从键盘读入数据,分析出一个单词。
2)返回单词种别(用整数表示),3)返回单词属性(不同的属性可以放在不同的全局变量中)。
四.、实验步骤1. 采用C语言,设计GETSYM ,实现该算法2. 编制测试程序(主函数main)。
3. 调试程序:输入一组单词,检查输出结果。
五.、实验设计分析1.词法的正规式描述S=aA|aA=(aA|dA)}(a|d)2.变换后的正规文法S→aAS→aA→aAA→dAA→aA→d3.词法分析程序的程序代码#include "stdafx.h"#include <iostream>#include<string>using namespace std;#define MAX 17char ch =' ';stringkey[17]={"const","long","float","double","void","main","if","else","then","break","int","char","in clude","for","while","printf","scanf"};int Iskey(string c){ //关键字判断int i;for(i=0;i<MAX;i++){if(key[i].compare(c)==0) return 1;}return 0;}int IsLetter(char c){ //判断是否为字母if(((c<='z')&&(c>='a'))||((c<='Z')&&(c>='A'))) return 1;else return 0;}int IsLetter1(char c){ //判断是否为a~f字母if(((c<='f')&&(c>='a'))||((c<='F')&&(c>='A'))) return 1;else return 0;}int IsDigit(char c){ //判断是否为数字if(c>='0'&&c<='9') return 1;else return 0;}void scan(FILE *fpin){string arr="";while((ch=fgetc(fpin))!=EOF){arr="";if(ch==' '||ch=='\t'||ch=='\n'){}else if(IsLetter(ch)||ch=='_'){arr=arr+ch;ch=fgetc(fpin);while(IsLetter(ch)||IsDigit(ch)){if((ch<='Z')&&(ch>='A')) ch=ch+32;arr=arr+ch;ch=fgetc(fpin);}fseek(fpin,-1L,SEEK_CUR);if (Iskey(arr)){cout<<arr<<"\t关键字"<<endl;}else cout<<arr<<"\t普通标识符"<<endl;}else if(IsDigit(ch)){int flag=0;if(ch=='0'){arr=arr+ch;ch=fgetc(fpin);if(ch>='0'&&ch<='7'){while(ch>='0'&&ch<='7'){flag=1;arr=arr+ch;ch=fgetc(fpin);}}else if(ch=='x'||ch=='X'){flag=2;arr=arr+ch;ch=fgetc(fpin);while(IsDigit(ch)||IsLetter1(ch)){arr=arr+ch;ch=fgetc(fpin);}}else if(ch==' '||ch==','||ch==';' ){cout<<arr<<"\t整数0"<<endl;}fseek(fpin,-1L,SEEK_CUR);if(flag==1) cout<<arr<<"\t八进制整数"<<endl;else if(flag==2) cout<<arr<<"\t十六进制整数"<<endl;}else{arr=arr+ch;ch=fgetc(fpin);while(IsDigit(ch)){arr=arr+ch;ch=fgetc(fpin);}fseek(fpin,-1L,SEEK_CUR);cout<<arr<<"\t十进制整数"<<endl;}}else switch(ch){case'+':case'-' :case'*' :case'=' :case'|' :case'/' :cout<<ch<<"\t运算符"<<endl;break;case'(' :case')' :case'[' :case']' :case';' :case'.' :case',' :case'{' :case'}' :cout<<ch<<"\t界符"<<endl;break;case':' :{ch=fgetc(fpin);if(ch=='=') cout<<":="<<"\t运算符"<<endl;else{cout<<"::"<<"\t界符"<<endl;;fseek(fpin,-1L,SEEK_CUR);}}break;case'>' :{ch=fgetc(fpin);if(ch=='=') cout<<">="<<"\t运算符"<<endl;if(ch=='>')cout<<">>"<<"\t输入控制符"<<endl;else {cout<<">"<<"\t运算符"<<endl;fseek(fpin,-1L,SEEK_CUR);}}break;case'<' :{ch=fgetc(fpin);if(ch=='=')cout<<"<="<<"\t运算符"<<endl;else if(ch=='<')cout<<"<<"<<"\t输出控制符"<<endl;else if(ch=='>') cout<<"<>"<<"\t运算符"<<endl;else{cout<<"<"<<"\t运算符"<<endl;fseek(fpin,-1L,SEEK_CUR);}}break;default : cout<<ch<<"\t无法识别字符"<<endl;}}}void main(){char in_fn[30];FILE * fpin;cout<<"请输入源文件名(包括路径和后缀名):";for(;;){cin>>in_fn;if((fpin=fopen(in_fn,"r"))!=NULL) break;else cout<<"文件路径错误!请输入源文件名(包括路径和后缀名):";}cout<<"\n分析如下:\n"<<endl;scan(fpin);fclose(fpin);}七.实验测试:输入数据及运行结果:int a=3;double b=4;int c;if(a>b)c=a;elsec=b;。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
实验报告学号:姓名:专业:计算机科学与技术班级:2班第9周#include<fstream>#include<string>#include<iostream>using namespace std;static int rowCounter = 1;//静态变量,用于存储行数static bool bracketExist = false;//判断注释存在与否,false为不存在class Lex{public:ofstream output;string line = "";Lex(string inputLine){line = inputLine;scan(Trim(line));rowCounter++;}string Trim(string &str)//函数用于去除每行前后空格{int s = str.find_first_not_of(" \t");int e = str.find_last_not_of(" \t");str = str.substr(s, e - s + 1);str += "\0";return str;}void scan(string inputLine){ofstream output;output.open("SampleOutput.txt", ios::app);string line = inputLine;int i = 0;string str = "";int temp;string token = "";output << rowCounter << ": " << line << endl;//输出每行while (line[i] != '\0')//根据DFA扫描并判断{if (line[i] == '{')//注释{bracketExist = true;}if (bracketExist == true){output << "\t" << rowCounter << ": ";while (line[i] != '}'){output << line[i];//不处理,直接输出if (line[i + 1] != NULL){i++;}elsebreak;}if (line[i] == '}')//注释结束{output << line[i]<<endl;bracketExist = false;}}if (bracketExist == false){//数字while (isdigit(line[i])){temp = temp * 10 + line[i];if (!isdigit(line[i + 1])){output << "\t" << rowCounter << ": " << "NUM, val= " << temp - '0' << endl;}if (line[i + 1] != NULL&&isdigit(line[i + 1]))i++;elsebreak;}temp = 0;//符号while (!(isdigit(line[i]) || (line[i] >= 'a'&&line[i] <= 'z') ||(line[i] >= 'A'&&line[i] <= 'Z') || line[i] == ' ' || line[i] == '{' || line[i] == '}')) {token = token + line[i];if (isdigit(line[i + 1]) || (line[i + 1] >= 'a'&&line[i + 1] <= 'z') || (line[i + 1] >= 'A'&&line[i + 1] <= 'Z') || line[i + 1] == ' ' || line[i + 1] == '{' || line[i + 1] == '}' || line[i + 1] == NULL){if (isToken(token)){output << "\t" << rowCounter << ": " << token << endl;}else{int j = 0;while (token[j] != '\0'){output << "\t" << rowCounter << ": " << token[j] << endl;j++;}}}else{i++;continue;}if (line[i + 1] != NULL)i++;elsebreak;}token = "";//字母while ((line[i] >= 'a'&&line[i] <= 'z') || (line[i] >= 'A'&&line[i] <= 'Z')){str = str + line[i];if (!((line[i + 1] >= 'a'&&line[i + 1] <= 'z') || (line[i + 1] >= 'A'&&line[i + 1] <= 'Z'))){if (isResearvedWord(str)) //判断是否是保留字{output << "\t" << rowCounter << ": " << "Reversed Word: " << str << endl;break;}else{output << "\t" << rowCounter << ": " << "ID, name= " << str << endl;break;}}if (line[i + 1] != NULL)i++;}str = "";if (line[i + 1] != NULL){i++;}elsebreak;}if (line[i + 1] == NULL){if (line[i] == ';')output << "\t" << rowCounter << ": " << line[i];break;}}//清空,以备下一行读取line = "";str = "";temp = 0;token = "";output << endl;output.close();}bool isResearvedWord(string s)//存储保留字,并判断{string reservedWord[8] = { "if", "then", "else", "end", "repeat", "until", "read", "write" };bool judge = false;for (int i = 0; i < 8; i++){if (s == reservedWord[i]){judge = true;break;}}return judge;}bool isToken(string s)//存储符号,并判断{string token[10] = { "+", "-", "*", "/", "=", "<", "(", ")", ";", ":=" };bool judge = false;for (int i = 0; i < 10; i++){if (s == token[i]){judge = true;break;}}return judge;}};int main(){ifstream input;input.open("SampleInput.tny");string line[50];int i = 0;while (getline(input, line[i])){//cout << line[i] << endl;i++;}input.close();cout << endl << endl << "Reading source file completed!!" << endl;int j = 0;remove("SampleOutput.txt");for (j = 0; j < i; j++){Lex lex(line[j]);}cout << endl << endl << "Writing file completed!!" << endl << endl << endl;return 0;}四、重要数据结构string line[]:用于存储每一行的字符,并逐个读取分析。