自底向上语法分析
编译原理第6节课第二章

为一先天二义性语言。 为一先天二义性语言。 • CFL的先天二义性也是不可判定的。 的先天二义性也是不可判定的。 的先天二义性也是不可判定的
2.3.3 短语和句柄
• 问题:在自底向上 问题: 的语法分析中, 的语法分析中,对 于每一步直接归约, 于每一步直接归约, 应如何正确地确定 当前句型中应被归 约的最左子串 约的最左子串? 最左子串 F i E T + T F i T * F i E
E(2) + T(2)
• 但是 对一句型而言,其直接短语可能不唯一。 但是,对一句型而言,其直接短语可能不唯一。 对一句型而言 为了让分析能够机械地进行,我们只考虑最左 为了让分析能够机械地进行,我们只考虑最左 归约。 归约。 E E T F i + T F i T * F i E + T F i
* +
归约时被替换子串的选择
• 从句型 η=E+T*F+i 的语法树可知 E+T 绝不是 的语法树可知, 它的一个直接短语 因为虽然 它的一个直接短语,因为虽然 E→E+T 是 G2[E] 直接短语 的一个产生式,但不存在从 的推导。 的一个产生式 但不存在从 E 到 E*F+i 的推导。 E E(1) E(2) + T(3) T(2) * F(3) + T(1) F(1) i
E + T F T * F i
i • 对一语法树而言,其构造过程不同对应了不 对一语法树而言, 同的推导(归约)过程。 同的推导(归约)过程。 推导
文法的二义性
• 存在这样的文法 ,其某个句子 w ∈ L(G) , 存在这样的文法G, 可对应结构不同的语法树, 可对应结构不同的语法树,即 w 对应了多个 不同的最左(右)推导,这类文法称为二义 不同的最左* +
简述 slr(1)和 lr(1)文法的定义(一)

简述 slr(1)和 lr(1)文法的定义(一)简述 SLR(1) 和 LR(1) 文法SLR(1)和LR(1)是两种常见的自底向上的语法分析算法。
它们都可以用于语法分析器生成过程中,帮助开发者构建和验证语法分析器。
下面将对SLR(1)和LR(1)的相关定义进行列举,并阐述理由和书籍简介。
SLR(1)文法•定义:SLR(1)(Simple LR)文法是一种自底向上的语法分析方法,它使用LR(0)项目集作为状态,具有一定的限制,只能处理一些相对简单的文法。
SLR(1)文法通过构造LR(0)自动机,然后结合First集和Follow集来进行分析。
•理由:SLR(1)文法的优势是在实现过程中相对简单,并且可以处理一些常见的文法,例如算术表达式、条件语句等。
由于SLR(1)文法的限制较多,相比其他更复杂的LR分析方法,其文法设计要求相对低,因此更适合初学者理解和使用。
•书籍简介:《编译原理》(作者:龙书)是一本经典的编译原理教材,其中涵盖了SLR(1)文法的相关内容。
这本书详细介绍了语法分析的各种方法,从简单的自底向上方法到更复杂的自顶向下方法,包括SLR(1)文法的构造和应用。
《编译原理》对于初学者来说是一本很好的参考书,可以帮助读者理解SLR(1)文法及其在语法分析中的应用。
LR(1)文法•定义:LR(1) 文法是一种更强大的自底向上语法分析方法,通过考虑下一个输入符号的展望符号(look-ahead)来解决由于有多个项目具有相同的前缀而导致的归约冲突。
LR(1) 文法通过构造 LR(1) 项目集来构建 LR(1) 分析表。
•理由:相比 SLR(1) 文法,LR(1) 文法可以处理更复杂的文法,具有更强的表达能力。
通过展望符号的引入,LR(1)文法能够更准确地分析语法,解决冲突。
在实际的编译器设计中,LR(1) 文法更为常用,可以处理包括C、Java等语言中的大部分语法规则。
•书籍简介:《编译原理与设计》(作者: Aho, Lam, R. Sethi, Ullman)是一本经典的编译原理教材,其中详细介绍了LR(1)文法及其相关内容。
第讲LR分析法

第讲LR分析法LR分析法是一种常用的语法分析方法,可以用于生成语法树,它是自底向上的语法分析方法。
在LR分析法中,L表示“自左向右扫描输入串的方式”,R表示“反向构建和规约的方式”。
LR分析法包括以下几个步骤:1.构造LR(0)项目集规范族:LR(0)项目集是指在一些语法分析的过程中,每个项目表示对应的产生式的哪一部分已经被扫描过了,哪一部分还没有被扫描过。
根据给定的文法,构造出所有可能的项目集,并将它们进行编号,得到项目集规范族。
2.构造LR(0)项目集规范族的DFA:根据构造出的LR(0)项目集规范族,可以构造出一个DFA(确定性有限自动机)来表示LR(0)语法分析的过程。
DFA的每个状态表示一个项目集,每个转移表示在一个状态下扫描一些符号后转移到另一个状态。
3.构造LR(0)分析表:根据构造出的LR(0)项目集规范族的DFA,可以构造出一个分析表,即LR(0)分析表。
分析表的行表示当前状态,列表示当前输入符号,表格中的每个元素表示下一步应该做的动作,可以是移进一些符号,也可以是规约一些项目。
4.进行LR(0)分析:根据构造出的LR(0)分析表,可以进行LR(0)语法分析。
分析的过程是根据当前状态和输入符号,在分析表中查找对应的动作,并执行该动作。
如果遇到移进动作,就将符号加入到解析栈中,同时移动输入指针;如果遇到规约动作,就从解析栈中弹出一些符号,然后根据规约产生式将新的非终结符加入到解析栈中。
5.构造SLR(1)分析表:LR(0)分析表中存在冲突的情况,无法完全正确地进行语法分析。
为了解决这个问题,需要对LR(0)分析表进行优化,得到SLR(1)分析表。
SLR(1)分析表与LR(0)分析表的结构类似,只是在一些冲突的情况下给出更加具体的动作指令。
6.进行SLR(1)分析:根据构造出的SLR(1)分析表,可以进行SLR(1)语法分析。
与LR(0)分析类似,根据当前状态和输入符号,在分析表中查找对应的动作,并执行该动作。
编译原理 语法分析(2)_ LL(1)分析法1
自底向上分析法
LR分析法的概念 LR分析法的概念 LR(0)项目族的构造 LR(0)项目族的构造 SLR分析法 SLR分析法 LALR分析法 LALR分析法
概述
功能:根据文法规则 文法规则, 源程序单词符号串 单词符号串中 功能:根据文法规则,从源程序单词符号串中
识别出语法成分,并进行语法检查。 识别出语法成分,并进行语法检查。
9
【例】文法G[E] 文法G[E] E→ E +T | T 消除左递归 T→ T * F | F F→(E)|i 请用自顶向下的方法分析是否字 分析表 符串i+i*i∈L(G[E])。 符串i+i*i∈L(G[E])。
E→TE’ E’→+TE’|ε T →FT’ T’→*FT’|ε F→(E)|i
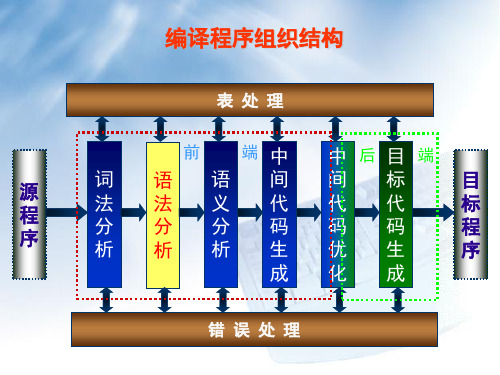
编译程序组织结构
表 处 理
前
端 中
源 程 序
词 法 分 析
语 法 分 析
语 义 分 析
间 代 码 生 成
中 后 目 端 间 标 代 代 码 码 优 生 化 成
目 标 程 序
错 误 处 理
第4章 语法分析
自顶向下分析法
递归子程序法(递归下降分析法) 递归子程序法(递归下降分析法) LL(1)分析法 LL(1)分析法
通常把按LL(1)方法完成语法分析任务的程序叫LL(1)分析程序或者LL(1)分析器。 通常把按LL(1)方法完成语法分析任务的程序叫LL(1)分析程序或者LL(1)分析器。 LL(1)方法完成语法分析任务的程序叫LL(1)分析程序或者LL(1)分析器
输入串
一、分析过程
#
此过程有三部分组成: 此过程有三部分组成: 分析表 总控程序) 执行程序 (总控程序) 分析栈) 符号栈 (分析栈)
自底向上的语法分析解读

程序4-4 简单优先分析驱动程序
int parser(void){ int i=0,k=0,r;stack[0]='#'; r=a[k++]; do{ int j,LeftSide; while(!IsHigherThan(stack[i],r)) {stack[++i]=r;r=a[k++];} j=i; while(! IsLowerThan (stack[j-1], stack[j])) j--; LeftSide= RightSideOfAProduction (stack[j],stack[i],i-j+1); if(LeftSide){ /*LeftSide!=0 means the production exists */ i=j;stack[i]=LeftSide; }else /* There is no production which matches the right side */ if(i==2 && r=='#' && stack[i] == STARTSYSBOL) return SUCCESS; else return ERROR; } while (1); } /* end of parser */
与的句柄之间的关系必有下述情况之一: A A
A
… … s t ... … … s t … ... … … s t … ... 1. s在句柄中, 3. s不在句柄中,而t 2. s与t均在句 而t不在句柄中 在句柄中 柄中 对于上述情况,我们规定, 情况1: s>t; 情况2: s=t; 情况3: s<t 另外,还有一种情况,就是s和t均不在句柄中,那么一定存在某句 型使得它们进入上述三种情况之一.
编译原理大题

五、语法分析——自底向上分析法已知文法G:EE+TE TTT*FTFF(E)Fi(1)求文法G中每个非终结符的First集和Follow集。
(2)构造文法G的SLR(1)预测分析表。
(20分)首先构造增广文法:SEEE+TE TTT*FTFF(E)FiFirst(S)=First(E)=First(T)=First(F)={(,I)Follow(S)={#} Follow(E)={+,#,}}Follow(T)={+,},#,*} Follow(F)={+,},#,*}状态Action Gotoi + * ( ) # E T F0 S5 S4 1 2 31 S6 Acc2 r 2 S7 r 2 r 23 r4 r 4 r 4 r44 S5 S4 8 2 35 r6 r 66 S5 9 37 S5 108 S6 S119 r 1 S7 r 1 r 110 r 3 r 3 r 3 r 311 r 5 r 5 r 5 r 5注:识别可归前缀的DFA共12项。
词法分析——确定性有穷自动机为以下字符集编写正规表达式,并构造与之等价的最简DFA(写出详细的具体过程):在字母表{a,b}上的包含偶数个a且含有任意数目b的所有字符串。
(15分)(b*ab*ab*)*b a b1a状态Action GOTOa b d e f $ S R T0 S3 11 acc2 r2 S3 r2 r2 53 S6 S4 24 r4 r4 r4 r45 S10 96 77 S88 r3 r3 r3 r39 r1 r1 r110 r6 S6 S4 r6 r6 1111 S1212 r5 r5 r5五、语法分析——自底向上分析法已知文法G:S’SS bRSTS bRRdSaR eTfRaTf(1)求文法G中每个非终结符的First集和Follow集。
(2)构造文法G的SLR(1)预测分析表。
(20分)frist(s’)={b} follow(s’)={$}frist(s)={b} follow(s)={f,a, $}frist(R) ={d,e} follow( R )={a,b,f, $}frist(T)={t} follow (T)={a,f,#}五、对下面的文法(15分)S->UTa|TbT->S|Sc|dU->US|e判断是否为LR(0),SLR(1),说明理由,并构造相应的分析表。
编译技术-第4章-语法分析(一)

自顶向下分析 自底向上分析
自顶向下分析算法的基本思想为:
若Z + S 则 S L(G[Z]) 否则 S L(G[Z])
G[Z]
主要问题: ➢ 左递归问题 ➢ 回溯问题
▪ 主要方法: • 递归子程序法 • LL分析法
自底向上分析算法的基本思想为:
第四章 语法分析
• 语法分析的功能、基本任务 • 自顶向下分析法> • 自底向上分析法>
复习:第一章 概述
编译过程是指将高级语言程序翻译为等价的目标程 序的过程。 习惯上是将编译过程划分为5个基本阶段:
词法分析 语法分析 语义分析、生成中间代码 代码优化 生成目标程序
4.1 语法分析概述
功能:根据文法规则,从源程序单词符号串中识别出语法 成分,并进行语法检查。
若有规则:U∷=x|xy 则可以改写为:U∷=x(y|ε) 注意:不应写成U∷=x(ε|y)
使用提因子法,不仅有助于消除直接左递归,而且有 助于压缩文件的长度,使我们能更有效地分析句子。
规则二
若有文法规则:U∷=x|y|……|z|Uv
其特点是:具有一个直接左递归的右部并位于最后, 这表明该语法类U是由x或y……或z其后随有零个 或多个v组成。
若Z + S
G[Z]
则 S L(G[Z]) 否则 S L(G[Z])
主要问题: ➢ 句柄的识别问题
▪ 主要方法: • 算符优先分析法 • LR分析法
4.2 自顶向下分析
4.2.1 自顶向下分析的一般过程
给定符号串S,若预测是某一语法成分,则可根据该 语法成分的文法,设法为S构造一棵语法树, 若成功,则S最终被识别为某一语法成分,即
句子语法分析

句子语法分析语法分析是自然语言处理中的一个重要环节,通过对句子的结构和语法规则进行分析,可以帮助我们理解句子的语义和意图。
句子的语法结构牵涉到词汇、短语和句子之间的关系,下面将介绍常见的句子语法分析方法。
一、基于规则的语法分析方法基于规则的语法分析方法是最早也是最经典的方法之一。
它使用一组语法规则和转换规则来对句子进行分析。
其中,语法规则描述了句子中不同部分的语法关系和格式要求,而转换规则则指定如何将一个句子转换为另一个句子。
常见的基于规则的语法分析方法有自顶向下分析和自底向上分析。
1. 自顶向下分析自顶向下分析又称为预测分析,是从句子的最高层次开始逐步向下分析的过程。
它从句子的起始符号开始,根据语法规则一步一步地向下进行推导,直到得到具体的句子结构。
自顶向下分析的优点是简单易懂,但由于其自上而下的分析方式,可能会造成冗余的分析和回溯,导致效率低下。
2. 自底向上分析自底向上分析又称为移进规约分析,是从句子的底层开始逐步向上分析的过程。
它从句子的词汇项开始,不断将相邻的词汇项合并为更大的短语,直到最终得到整个句子的结构。
自底向上分析的优点是能够更好地处理复杂的语法结构,但也存在分析歧义性和效率低下的问题。
二、基于统计的语法分析方法基于统计的语法分析方法是近年来受到广泛应用的方法之一。
它利用大规模的语料库数据进行训练,通过统计分析句子中词汇和短语的共现关系,来预测句子的语法结构。
常见的基于统计的语法分析方法有基于PCFG(Probabilistic Context-Free Grammar)的方法和基于依存关系的方法。
1. 基于PCFG的方法基于PCFG的方法是一种基于上下文无关文法的句法分析方法。
它通过对语法规则和转换规则进行统计建模,来计算句子中各个语法成分的概率分布。
然后,利用维特比算法或者基于图的算法来寻找最可能的句子结构。
2. 基于依存关系的方法基于依存关系的方法是一种基于句子中单词之间依存关系的句法分析方法。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
分析栈 # #b #b( #b(a #b(M #b(Ma #b(Ma) #b(L #bM #bMb #Z
关系
输入流 b(aa)b#
(aa)b# aa)b#
a)b# a)b#
)b# b# b M
Z
停
6.3 算符优先方法
算符优先文法的定义 算符优先关系表的构造 算符优先分析算法 算符优先分析法的局限性
例子:ZabCDc a b C D e 则bCD是句柄。
分析句子b( a a )b(文法G[Z])的过程:
ZML b ( a ) Z M L b ( a )
移进项目的处理
分析栈 # # #b
关系
输入流 b(aa)b# b(aa)b#
(aa)b#
归约符
移进项目的处理
#b(a #b(a #b(M
a)b# a)b# M a)b#
G[S]: S→aAcBe A→b A→Ab B→d
对输入串abbcde的最右推导是: SaAcBeaAcdeaAbcdeabbcde SaAcBeaAcdeaAbcdeabbcde
所以移进-归约方法的分析过程如下:
步骤 符号栈 1# 2 #a 3 #ab 4 #aA 5 #aAb 6 #aA 7 #aAc 8 #aAcd 9 #aAcB 10 #aAcBe 11 #S
第6章 自底向上语法分析
6.1 自底向上语法分析
一、自底向上方法概述 自底向上方法:从给定终极符串进行
归约,并归约成文法的初始符。
移进-归约方法的四个动作: ➢ 移进:输入流头符读到分析栈中 ➢ 归约:分析栈句柄归约非终极符 ➢ 接受:分析成功 ➢ 报错:处理错误
例子:对输入串abbcde进行分析,检查该 串是否是G[S]的句子。
E +T
+T +T
T *F
下面文法均不为简单优先文法
❖ G1:B→a D→a (有两个相同的右部)
❖ G2:E→E+T|T T→T*F|F F→(E)|i (其中( E,( E)
定理3.10 设S1S2Sn是简单优先文法的 规范句型,其子串SiSi+1Sj满足条件:
Si-1 Si,Si Si+1 Sj , Sj Sj+1,则SiSi+1Sj定为句柄。
输入串
Action
abbcde# 移进
bbcde# 移进
bcde# 归约(A→b)
bcde# 移进
cde# 归约(A→Ab)
cde# 移进
de# 移进
e# 归约(B→d)
e# 移进
# 归约(S→aAcBe)
# 接受
例:考虑文法 G(E): E→T|E+T T→F|T*F F→i|(E)
并假定已给定终极符串(i+i)*i。下面是 对该串的移入─归约过程:
例子:假设有文法 G[Z]: Z→bMb M→a|( L L→M a )
第一步: ① Z→b M b b M
②Z→b M b
b (
(… a…
ba
第二步: ① Z→b M b
M b
②Z→b M b
…) …L …a
) b L b a b
ZML b ( a ) Z M L b ( a )
所以对G[Z]: Z→bMb M→a|( L L→M a )
的运算符,小于括号内的运算符, 内括号的优先性大于外括号 (5)#的优先性低于与其相邻的算符
6.3.1 直观算符优先分析法
• 自下而上分析算法 模型----移进归约 • 算符优先分析不是规范归约
分析程序模型
输入串#
总控程序
输出
# 算符优先关系表 产生式
如何确定算符优先关系?
文法G[E]:E→E+E|E-E|E*E|E/E|EE|(E)|i
人为确定:
(1)i的优先级最高 (1) 优先级次于i,右结合 (2)*和/优先级次之,左结合 (3)+和-优先级最低,左结合 (4)括号‘(’,‘)’的优先级大于括号外
=归=>(T , *i) 14 =移=>(T* , i) 15 =移=>(T*i , ) 16 =归=>(T*F , ) 17 =归=>(T , ) 18 =归=>(E , ) 19
6.2 简单优先方法
设Si和Sj是文法的任意两个符号,那 么它们在句型中相邻出现的充要条件是
必须满足下列条件之一:
•US→i …SSji:W当…,且且仅有当W存+ 在S如j…下…)产生式
例子:A→abABc B→bcd,其中A与b相邻 A b
•US→i …SVj:W当…,且且仅有当V+存在Si如和下W*产S生j…式…)
例子:A→abABc A→ccd B→bcb,其中d与b相邻 d b
优先关系可用矩阵来表示,称这种矩 阵为优先关系矩阵。
有:FRIST(M)={ (,a } LAST(M)={ ),L,a } 有下表:
Z FIRST b
LAST b
M (a
)La
L M(a
)
定义3.13 满足下面两个条件的文法称为 简单优先文法。
1.任意两个符号至多成立一种关系 2.任意两个产生式具有不同右部
例子:G[Z]: E→E+T|T E T→T*F|F F→(E)|i
1.有形如U→SiSj 2.有形如U→SiW
的产生式 且W+ Sj的产生式
3.有形如U→VSj 且V +Si的产生式的
产生式
4.有形如U→VW 且V+ Si和W+ Sj的
产生式的产生式
定义了三种优先关系( , , )其定义 如下:
• Si Sj:当且仅当存在如下的产生式 U→…SiSj…
例子:A→abABc,其中b与A相邻 b A
具体定义如下图:
M[si,sj]
当 Si Sj 当 Si Sj 当 Si Sj
空 否则
构造优先关系矩阵步骤:
* STEP1:对每个非终极符号W求下面
两种集合
➢ ➢
FIRST(W)={S|W+ LAST(W)={S|W+
S,S(Vn∪Vt)} S,S(Vn∪Vt)}
* STEP2:对每个符号对Si,Sj填写优 先关系矩阵。
( ,(i+i)*i) 1 =移=>(( , i+i)*i) 2 =移=>((i , +i)*i) 3 =归=>((F , +i)*i) 4
=归=>((T , +i)*i) 5 =归=>((E , +i)*i) 6 =移=>((E+ , i)*i) 7 =移=>((E+i , )*i) 8 =归=>((E+F , )*i) 9 =归=>((E+T , )*i) 10 =归=>((E , )*i) 11 =移=>((E) , *i) 12 =归=>(F , *i) 13