SPSS典型相关分析结果解读
《SPSS统计分析》第10章 相关分析

12.990 16.290 17.990 19.290
12.500 15.800 17.500 18.800
11.500 14.800 16.500 17.800
2.200 5.500 7.200 8.500
3.300 5.000 6.300
3.300
1.700 3.000
5.000 1.700
1.300
3.分析两个变量间线性关系的程度。往往因为第三个变量的作用,使相关系数不能真正反映两个 变量间的线性程度。 这是应该控制一个变量的变化求另两个变量间的相关系数,也就是说, 在第三个变量不变的情况下,两个变量的线性程度。
CORRELATIONS /VARIABLES=VCP with HEIGHT WEIGHT /PRINT=TWOTAIL NOSIG /MISSING=PAIRWISE .
6.300 3.000 1.300
1.800 1.500 3.200 4.500
2.700 6.000 7.700 9.000
5.000 8.300 10.000 11.300
12.000 15.300 17.000 18.300
9: 9 14.790 14.300 13.300
4.000 1.800 1.500 3.200 4.500
返回
典型相关分析
返回
典型相关分析概念
典型相关分析是用来描述两组随机变量间关 系的统计分析方法。
通过线性组合,可以将一组变量组合成一个 新的综合变量。虽然每组变量间的线性组合有无 数多个,但通过对其施加一些条件约束,能使其 具有确定性。
典型相关分析就是要找到使得这两个由线性 组合生成的变量之间的相关系数最大的系数。
学习通过编程解决偏相关问题
【SPSS数据分析】SPSS聚类分析的软件操作与结果解读
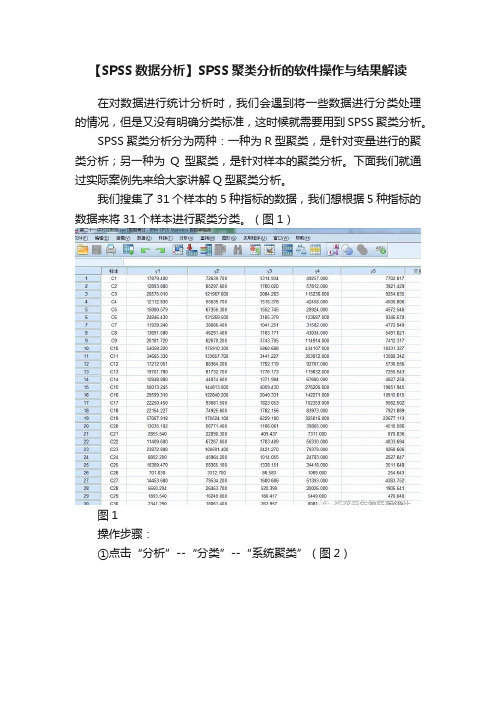
【SPSS数据分析】SPSS聚类分析的软件操作与结果解读
在对数据进行统计分析时,我们会遇到将一些数据进行分类处理的情况,但是又没有明确分类标准,这时候就需要用到SPSS聚类分析。
SPSS聚类分析分为两种:一种为R型聚类,是针对变量进行的聚类分析;另一种为Q型聚类,是针对样本的聚类分析。
下面我们就通过实际案例先来给大家讲解Q型聚类分析。
我们搜集了31个样本的5种指标的数据,我们想根据5种指标的数据来将31个样本进行聚类分类。
(图1)
图1
操作步骤:
①点击“分析”--“分类”--“系统聚类”(图2)
图2
③将“样本”选入个案标注依据,将γ1-5选入变量,并勾选下方“个案”标签(图3)
图3
④点击右侧“统计”按钮,将解的范围设置为2-4,意思为分聚为2,3,4类,这里可根据自己分类需求设置(图4)
图4
⑤点击右侧“图”,勾选“谱系图”(图5),点击右侧“方法”,将聚类方法设置为“组间联接”,将区间设置为“平方欧氏距离”(图6)
图5
图6
⑥点击“保存”,将解的范围设置为2-4(图7)
图7
⑦分析结果
图8
由上图(图8)可以看出,第一列为31个样本聚为4类的结果,第二列为31个样本聚为3类的结果,第三列为31个样本聚为2类的结果。
至于冰柱图和谱系图都是用图形化来进一步表达这个些结果,这里就不再赘述,想学习的朋友可以关注我们公众号进行深入学习。
以上就是今天所讲解的SPSS聚类分析的软件操作与分析结果详解,回顾一下重点,Q型聚类是根据变量数据针对样本进行的聚类。
然而还有R型聚类我们将在下一期中进行详细的讲解和分析。
敬请大家的关注!。
SPSS典型相关分析结果解读

Correlations for Set-1Y1Y2Y3Y1 1.0000.9983.5012Y2.9983 1.0000.5176Y3.5012.5176 1.0000第一组变量间的简单相关系数Correlations for Set-2X1X2X3X4X5X6X7X8X9X10X11X12X13 X1 1.0000-.3079-.7700-.7068-.6762-.7411-.7466-.5922-.1948-.1285-.2650-.9070-.6874 X2-.3079 1.0000-.0117.0103-.0613-.0283-.0140.3333.4161.3810.3831.1098-.0640 X3-.7700-.0117 1.0000.9905.9860.9973.9990.5892.0421-.0196.2492.9515.9903 X4-.7068.0103.9905 1.0000.9910.9935.9952.5634.0249-.0367.2476.9120.9953 X5-.6762-.0613.9860.9910 1.0000.9887.9912.5717.0363-.0277.2475.8972.9926 X6-.7411-.0283.9973.9935.9887 1.0000.9985.5563.0142-.0453.2210.9355.9950 X7-.7466-.0140.9990.9952.9912.9985 1.0000.5795.0319-.0298.2441.9390.9945 X8-.5922.3333.5892.5634.5717.5563.5795 1.0000.7097.6540.8990.6619.5138 X9-.1948.4161.0421.0249.0363.0142.0319.7097 1.0000.9922.8520.1350-.0228 X10-.1285.3810-.0196-.0367-.0277-.0453-.0298.6540.9922 1.0000.8184.0752-.0801 X11-.2650.3831.2492.2476.2475.2210.2441.8990.8520.8184 1.0000.3093.1840 X12-.9070.1098.9515.9120.8972.9355.9390.6619.1350.0752.3093 1.0000.9040 X13-.6874-.0640.9903.9953.9926.9950.9945.5138-.0228-.0801.1840.9040 1.0000Correlations Between Set-1and Set-2X1X2X3X4X5X6X7X8X9X10X11X12X13 Y1-.7542-.0147.9995.9940.9892.9989.9998.5788.0334-.0280.2426.9430.9937 Y2-.7280-.0234.9965.9958.9954.9977.9988.5859.0485-.0136.2573.9285.9949 Y3-.4485.2952.5096.4955.5230.4760.5048.9695.7610.7071.9073.5449.4500Canonical Correlations1 1.0002 1.0003 1.000第一对典型变量的典型相关系数为CR1=1.....二三Test that remaining correlations are zero:维度递减检验结果降维检验Wilk's Chi-SQ DF Sig.1.000.000.000.0002.000.00024.000.0003.000103.48911.000.000此为检验相关系数是否显著的检验,原假设:相关系数为0,每行的检验都是对此行及以后各行所对应的典型相关系数的多元检验。
典型相关分析报告SPSS例析

典型相关分析典型相关分析(Canonical correlation )又称规则相关分析,用以分析两组变量间关系的一种方法;两个变量组均包含多个变量,所以简单相关和多元回归的解惑都是规则相关的特例。
典型相关将各组变量作为整体对待,描述的是两个变量组之间整体的相关,而不是两个变量组个别变量之间的相关。
典型相关与主成分相关有类似,不过主成分考虑的是一组变量,而典型相关考虑的是两组变量间的关系,有学者将规则相关视为双管的主成分分析;因为它主要在寻找一组变量的成分使之与另一组的成分具有最大的线性关系。
典型相关模型的基本假设:两组变量间是线性关系,每对典型变量之间是线性关系,每个典型变量与本组变量之间也是线性关系;典型相关还要求各组内变量间不能有高度的复共线性。
典型相关两组变量地位相等,如有隐含的因果关系,可令一组为自变量,另一组为因变量。
典型相关会找出一组变量的线性组合X* ax i与Y*= dy j ,称为典型变量;以使两个典型变量之间所能获得相关系数达到最大,这一相关系数称为典型相关系数。
a i和bj称为典型系数。
如果对变量进行标准化后再进行上述操作,得到的是标准化的典型系数。
典型变量的性质每个典型变量智慧与对应的另一组典型变量相关,而不与其他典型变量相关;原来所有变量的总方差通过典型变量而成为几个相互独立的维度。
一个典型相关系数只是两个典型变量之间的相关,不能代表两个变量组的相关;各对典型变量构成的多维典型相关,共同代表两组变量间的整体相关。
典型负荷系数和交叉负荷系数典型负荷系数也称结构相关系数,指的是一个典型变量与本组所有变量的简单相关系数,交叉负荷系数指的是一个典型变量与另一组变量组各个变量的简单相关系数。
典型系数隐含着偏相关的意思,而典型负荷系数代表的是典型变量与变量间的简单相关, 两者有很大区别。
重叠指数如果一组变量的部分方差可以又另一个变量的方差来解释和预测, 就可以说这部分方差与另一个变量的方差之间相重叠, 或可由另一变量所解释。
SPSS相关分析报告案例讲解

相关分析一、两个变量的相关分析:Bivariate 1.相关系数的含义相关分析是研究变量间密切程度的一种常用统计方法。
相关系数是描述相关关系强弱程度和方向的统计量,通常用r 表示。
①相关系数的取值范围在-1和+1之间,即:–1≤r ≤ 1。
②计算结果,若r 为正,则表明两变量为正相关;若r 为负,则表明两变量为负相关。
③相关系数r 的数值越接近于1(–1或+1),表示相关系数越强;越接近于0,表示相关系数越弱。
如果r=1或–1,则表示两个现象完全直线性相关。
如果=0,则表示两个现象完全不相关(不是直线相关)。
④3.0<r ,称为微弱相关、5.03.0<≤r ,称为低度相关、8.05.0<≤r ,称为显著(中度)相关、18.0<≤r ,称为高度相关⑤r 值很小,说明X 与Y 之间没有线性相关关系,但并不意味着X 与Y 之间没有其它关系,如很强的非线性关系。
⑥直线相关系数一般只适用与测定变量间的线性相关关系,若要衡量非线性相关时,一般应采用相关指数R 。
2.常用的简单相关系数(1)皮尔逊(Pearson )相关系数皮尔逊相关系数亦称积矩相关系数,1890年由英国统计学家卡尔•皮尔逊提出。
定距变量之间的相关关系测量常用Pearson 系数法。
计算公式如下:∑∑∑===----=ni ni i ini i iy y x xy y x xr 11221)()())(( (1)(1)式是样本的相关系数。
计算皮尔逊相关系数的数据要求:变量都是服从正态分布,相互独立的连续数据;两个变量在散点图上有线性相关趋势;样本容量30≥n 。
(2)斯皮尔曼(Spearman )等级相关系数Spearman 相关系数又称秩相关系数,是用来测度两个定序数据之间的线性相关程度的指标。
当两组变量值以等级次序表示时,可以用斯皮尔曼等级相关系数反映变量间的关系密切程度。
它是根据数据的秩而不是原始数据来计算相关系数的,其计算过程包括:对连续数据的排秩、对离散数据的排序,利用每对数据等级的差额及差额平方,通过公式计算得到相关系数。
SPSS典型相关分析

表6
第18页/共23页
表7
从这两个表中可以看出,V1主要和变量hed相关 (0.99329),而V2主要和led(0.92484)及net (0.75305)相关;W1主要和变量arti(0.99696)及 man(0.92221)相关,而W2主要和com(0.81123) 相关;这和它们的典型系数是一致的。
表1 相关性的若干检验
第12页/共23页
表2给出了特征根(Eigenvalue),特征根所占的百分比 (Pct)和累积百分比(Cum. Pct)和典型相关系数(Canon Cor)及其平方(Sq. Cor)。看来,头两对典型变量(V, W) 的累积特征根已经占了总量的99.427%。它们的典型相 关系数也都在0.95之上。
第14页/共23页
表3 未标准化系数 表4 标准化系数
第15页/共23页
可以看出,头一个典型变量V1相应于前面第一个(也是最 重要的)特征值,主要代表高学历变量hed;而相应于前面 第二个(次要的)特征值的第二个典型变量V2主要代表低 学历变量led和部分的网民变量net,但高学历变量在这里起 负面作用。 从表4中可以得到第一变量的头三个典型变量V1、 V2、V3中的V1 和V2的表达式:
12.3 典型相关分析的实例分析
例12.1为研究业内人士和观众对于一些电视节目的观点 的关系,对某地方30个电视节目做了问卷调查并给出 了平均评分。观众评分来自低学历(led)、高学历(hed) 和网络(net)调查三种,它们形成第一组变量;而业内人 士分评分来自包括演员和导演在内的艺术家(arti)、发 行(com)与业内各部门主管(man)三种,形成第二组变 量。参加图12.1,数据间TV.Sav。
SPSS典型相关分析结果解读

SPSS典型相关分析结果解读
典型相关分析是SPSS的一种统计分析方法,用于检验两变量之间的线性关系。
它的结果包括Pearson积差相关系数、Spearman等级相关系数以及Kendall tau-b相关系数。
a. Pearson积差相关系数:Pearson积差相关系数是最常用的相关分析指标,该系数介于-1~+1之间,表示两个变量之间的线性关系强度。
当其值接近1时,表明两个变量之间呈正相关;当其值接近-1时,表明两个变量之间呈负相关;而当其值接近0时,表明两个变量之间没有显著相关性。
b. Spearman等级相关系数:Spearman等级相关系数也是一种常用的相关分析指标,用于检验两个变量之间的非线性关系,通常情况下,该指标的取值范围在-1~+1之间,其余与Pearson积差相关系数的解释原理相同。
c. Kendall tau-b相关系数:Kendall tau-b相关系数也是一种常用的相关分析指标,用于检验两个变量之间的非线性关系,其取值范围也是-1~+1,当取值为正时,表明两个变量之间存在正相关性;当取值为负时,表明两个变量之间存在负相关性;而当取值为0时,表明两个变量之间没有显著相关性。
用SPSS进行相关分析的典型案例

数据预处理
缺失值处理
对于缺失值,可以采用删除缺失样本、均值插补、多重插补等方法进行处理。在本案例中,由于缺失值较少,采用删 除缺失样本的方法进行处理。
异常值处理
对于异常值,可以采用箱线图、散点图等方法进行识别和处理。在本案例中,通过箱线图发现存在少数极端异常值, 采用删除异常样本的方法进行处理。
数据标准化
06
典型案例三:经济学领域 应用
案例背景介绍
研究目的
探讨某国经济增长与失业率之间的关系 。
VS
数据来源
采用某国统计局发布的年度经济数据,包 括GDP增长率、失业率等指标。
SPSS操作步骤详解
1. 数据导入与整理 将原始数据导入SPSS软件。 对数据进行清洗和整理,确保数据质量和准确性。
SPSS操作步骤详解
显著性检验
观察相关系数旁边的显著性水平 (p值),判断相关关系是否具有 统计显著性。通常情况下,p值小 于0.05被认为具有统计显著性。
结果讨论
结合相关系数和显著性检验结果 ,讨论社会经济地位与心理健康 之间的关系。例如,可以探讨不 同教育水平或职业对心理健康的 影响,以及这种关系在不同人群 中的差异。
关注SPSS输出的显著性检验结果。如 果P值小于设定的显著性水平(如 0.05),则认为药物剂量与症状改善 程度之间的相关性是显著的,即两变 量之间存在统计学意义的关联。
结合专业背景和实际情境,对结果进 行解释和讨论。例如,如果药物剂量 与症状改善程度呈正相关且相关性显 著,可以认为增加药物剂量有助于改 善患者症状。同时,需要注意结果的 局限性和可能的影响因素,以便为医 学实践提供有价值的参考信息。
提出政策建议或未来研究方向,以促进经济增长和降 低失业率。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Correlations for Set-1
Y1Y2Y3
Y1 1.0000.9983.5012
Y2.9983 1.0000.5176
Y3.5012.5176 1.0000
第一组变量间的简单相关系数
Correlations for Set-2
X1X2X3X4X5X6X7X8X9X10X11X12X13 X1 1.0000-.3079-.7700-.7068-.6762-.7411-.7466-.5922-.1948-.1285-.2650-.9070-.6874 X2-.3079 1.0000-.0117.0103-.0613-.0283-.0140.3333.4161.3810.3831.1098-.0640 X3-.7700-.0117 1.0000.9905.9860.9973.9990.5892.0421-.0196.2492.9515.9903 X4-.7068.0103.9905 1.0000.9910.9935.9952.5634.0249-.0367.2476.9120.9953 X5-.6762-.0613.9860.9910 1.0000.9887.9912.5717.0363-.0277.2475.8972.9926 X6-.7411-.0283.9973.9935.9887 1.0000.9985.5563.0142-.0453.2210.9355.9950 X7-.7466-.0140.9990.9952.9912.9985 1.0000.5795.0319-.0298.2441.9390.9945 X8-.5922.3333.5892.5634.5717.5563.5795 1.0000.7097.6540.8990.6619.5138 X9-.1948.4161.0421.0249.0363.0142.0319.7097 1.0000.9922.8520.1350-.0228 X10-.1285.3810-.0196-.0367-.0277-.0453-.0298.6540.9922 1.0000.8184.0752-.0801 X11-.2650.3831.2492.2476.2475.2210.2441.8990.8520.8184 1.0000.3093.1840 X12-.9070.1098.9515.9120.8972.9355.9390.6619.1350.0752.3093 1.0000.9040 X13-.6874-.0640.9903.9953.9926.9950.9945.5138-.0228-.0801.1840.9040 1.0000
Correlations Between Set-1and Set-2
X1X2X3X4X5X6X7X8X9X10X11X12X13 Y1-.7542-.0147.9995.9940.9892.9989.9998.5788.0334-.0280.2426.9430.9937 Y2-.7280-.0234.9965.9958.9954.9977.9988.5859.0485-.0136.2573.9285.9949 Y3-.4485.2952.5096.4955.5230.4760.5048.9695.7610.7071.9073.5449.4500
Canonical Correlations
1 1.000
2 1.000
3 1.000
第一对典型变量的典型相关系数为CR1=1.....二三
Test that remaining correlations are zero:维度递减检验结果降维检验
Wilk's Chi-SQ DF Sig.
1.000.000.000.000
2.000.00024.000.000
3.000103.48911.000.000
此为检验相关系数是否显著的检验,原假设:相关系数为0,每行的检验都是对此行及以后各行所对应的典型相关系数的多元检验。
第一行看出,第一对典型变量的典型相关系数不是0的,相关性显著。
第二行sig值P=0.000>0.05,在5%显著性水平显著。
第三同二。
Standardized Canonical Coefficients for Set-1(标准化变量的典型相关的换算系数)123
Y112.146-1.52712.981
Y2-11.461 2.051-13.787
Y3-.422.599.986
Raw Canonical Coefficients for Set-1(原始变量的典型相关变量的换算系数)
123
Y1.002.000.002
Y2.000.000.000
Y3-.196.279.458
第一个典型变量的标准化典型系数为12.146和-11.461、-0.422。
Cv1-1=12.146Y1-11.461Y2-0.422Y3.同上
Standardized Canonical Coefficients for Set-2(典型负载系数)(结构相关系数:典型变量与原始变量之间的相关系数)
123
X1-.503-.350-1.854
X2.323.172 1.051
X3.991 1.263 3.796
X4-6.342-1.593-15.640
X5-1.616 3.256 6.526
X6-3.593-1.138-10.125
X78.644-2.0308.132
X8-2.506-.024-4.343
X9-2.187-1.566-8.282
X10 1.476 1.387 6.546
X11 2.048.667 5.396
X12.464-.195.207
X13 2.623.9597.123
Raw Canonical Coefficients for Set-2
123
X1-6.480-4.504-23.879
X28.591 4.58627.983
X3.000.000.001
X4-.008-.002-.020
X5-.008.016.031
X6-.002-.001-.006
X7.001.000.001
X8-1.013-.010-1.756
X9-.571-.409-2.162
X10.253.237 1.121
X11.677.221 1.784
X12.000.000.000
X13.000.000.000
Cv2-1=-0.503x1+0.323x2...........-2,-3同上
Canonical Loadings for Set-1
123
Y1.493.821-.288
Y2.445.837-.318
Y3-.267.896.355
Cross Loadings for Set-1
123
Y1.493.821-.288
Y2.445.837-.318
Y3-.267.896.355
Canonical Loadings for Set-2
123
X1-.627-.610-.195
X2-.035.151.423
X3.504.823-.262
X4.450.822-.338
X5.386.845-.367
X6.497.806-.319
X7.483.825-.294
X8-.094.899.392
X9-.472.504.515
X10-.482.439.522
X11-.385.701.497
X12.582.791-.023
X13.476.793-.375
Cross Loadings for Set-2
123
X1-.627-.610-.195
X2-.035.151.423
X3.504.823-.262
X4.450.822-.338
X5.386.845-.367
X6.497.806-.319
X7.483.825-.294
X8-.094.899.392
X9-.472.504.515
X10-.482.439.522
X11-.385.701.497
X12.582.791-.023
X13.476.793-.375
典型负荷系数和交叉负荷系数表
重叠系数分析
Redundancy Analysis:
Proportion of Variance of Set-1Explained by Its Own Can.Var.
Prop Var
CV1-1.171
CV1-2.726
CV1-3.103
Proportion of Variance of Set-1Explained by Opposite Can.Var.
Prop Var
CV2-1.171
CV2-2.726
CV2-3.103
Proportion of Variance of Set-2Explained by Its Own Can.Var.
Prop Var
CV2-1.204
CV2-2.523
CV2-3.139
Proportion of Variance of Set-2Explained by Opposite Can.Var.
Prop Var
CV1-1.204
CV1-2.523
CV1-3.139
0.171=CR1^2*0.171=1^2*0.171 0.204=CR1^2*0.204=1^2*0.204 ------END MATRIX-----。