kettle使用经验总结
自己总结的Kettle使用方法和成果

KETTLE使用自己总结的Kettle使用方法和成果说明简介Kettle是一款国外开源的ETL工具,纯java编写,可以在Window、Linux、Unix 上运行,绿色无需安装,数据抽取高效稳定。
Kettle 中文名称叫水壶,该项目的主程序员MATT 希望把各种数据放到一个壶里,然后以一种指定的格式流出.Kettle这个ETL工具集,它允许你管理来自不同数据库的数据,通过提供一个图形化的用户环境来描述你想做什么,而不是你想怎么做.Kettle中有两种脚本文件,transformation和job,transformation完成针对数据的基础转换,job则完成整个工作流的控制。
Kettle可以在http://kettle。
pentaho。
org/网站下载到。
注:ETL,是英文Extract—Transform—Load 的缩写,用来描述将数据从来源端经过萃取(extract)、转置(transform)、加载(load)至目的端的过程.ETL一词较常用在数据仓库,但其对象并不限于数据仓库。
下载和安装首先,需要下载开源免费的pdi-ce软件压缩包,当前最新版本为5.20。
0。
下载网址:/projects/pentaho/files/Data%20Integration/然后,解压下载的软件压缩包:pdi—ce—5。
2.0.0—209.zip,解压后会在当前目录下上传一个目录,名为data—integration。
由于Kettle是使用Java开发的,所以系统环境需要安装并且配置好JDK。
žKettle可以在http:///网站下载ž下载kettle压缩包,因kettle为绿色软件,解压缩到任意本地路径即可。
运行Kettle进入到Kettle目录,如果Kettle部署在windows环境下,双击运行spoon.bat或Kettle.exe文件.Linux用户需要运行spoon。
sh文件,进入到Shell提示行窗口,进入到解压目录中执行下面的命令:# chmod +x spoon。
KETTLE使用经验总结

KETTLE使用经验总结《kettle使用经验总结》目录1. 软件安装 (1)1.1.安装说明 (1)1.2.安装JDK (1)1.3.安装PDI (1)1.4.创建资源库 (2)1.5.修改配置文件 (3)1.6.启动服务器 (6)2. 操作说明 (7)2.1.运行转换/作业 (7)2.2.转换的并行 (7)2.3.作业的并行 (9)2.4.集群的使用 (9)2.5.记录日志 (11)2.6.连接HBASE (16)2.7.读取XML文件 (26)2.8.连接HIVE2 (31)2.9.大字段处理 (35)3. 性能优化 (39)《kettle使用经验总结》3.1.利用好数据库性能 (39) 3.2.用并行或者集群解决好数据插入瓶颈 (40)3.3.增大提交的记录数及大字段数据处理 (40)3.4.全量抽取先抽取后建索引 (41)3.5.增量抽取注意去重数据量 (41)3.6.利用中间表分段处理数据 (42)3.7.聚合优先 (43)4. 常见问题解决 (43)4.1.大量数据抽取导致内存溢出 (43)4.2.字段值丢失 (43)4.3.输出记录数大于输入记录数 (43)《kettle使用经验总结》1.软件安装1.1.安装说明本文档对应的产品及版本是pdi-ce-5.4.0.1-130。
由于该产品使用java 开发,所以需要在服务器上配置java环境。
如果是linux系统,为了操作方便,可以在linux上部署服务器,Windows启动客户端。
1.2.安装jdk下载jdk1.7或以上安装包,安装成功后,配置java环境变量。
JAVA_HOME: java安装目录CLASSPATH:%JAVA_HOME%\lib\dt.jar;%JAVA_HOME%\lib\ tools.jarPATH:添加%JAVA_HOME%\bin;%JAVA_HOME%\jre\bin;LINUX下配置环境变量:进入/etc/profile(系统)或.bash_profile(用户)export JAVA_HOME=/usr/local/java/jdk1.8.0_60export PATH=$JAVA_HOME/bin:$PATHexportCLASSPATH=$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar配置完成后检查java -version 和$JAVA_HOME是否启用1.3.安装PDI地址/projects/data-integration/下载P DI二进制文件pdi-ce-5.4.0.1-130.zip到各服务器中并解压,data-integration目录里面包含了PDI所有内容。
kettle实验总结

kettle实验总结我们来了解一下kettle的基本概念和功能。
Kettle是一款基于图形化界面的工具,通过可视化的方式帮助用户构建数据整合和转换的过程。
它提供了丰富的组件和功能,用户可以通过拖拽组件、设置参数和连接组件的方式来构建数据处理流程。
Kettle支持多种数据源和格式,包括关系型数据库、文件、Web服务等,用户可以方便地从不同的数据源中提取数据,并进行预处理、转换和加载。
接下来,我们将探讨如何使用kettle进行数据整合和转换的实验。
在实验前,我们需要准备好数据源和目标数据库,并确保kettle已经正确安装和配置。
首先,我们需要创建一个kettle的工作空间,并在工作空间中创建一个转换(Transformation)。
转换是kettle 中的基本单位,它由一系列的步骤(Step)组成,每个步骤都是一个数据处理的单元。
在转换中,我们可以使用多个步骤来完成不同的数据处理任务。
例如,我们可以使用"输入"步骤从源数据库中提取数据,然后使用"过滤"步骤对数据进行筛选,再使用"转换"步骤进行数据转换,最后使用"输出"步骤将结果加载到目标数据库中。
在每个步骤中,我们可以设置相应的参数和选项,以满足具体的数据处理需求。
除了基本的数据处理步骤,kettle还提供了丰富的功能和插件,用于处理更复杂的数据转换任务。
例如,我们可以使用"维度表输入"步骤来处理维度表的数据,使用"合并记录"步骤来合并不同数据源的记录,使用"数据校验"步骤来验证数据的完整性等。
通过灵活地组合和配置这些步骤,我们可以实现各种复杂的数据整合和转换任务。
在进行实验时,我们还可以使用kettle提供的调试和监控功能,以确保数据处理流程的正确性和性能。
例如,我们可以使用"调试"功能逐步执行转换,并观察每个步骤的输入和输出结果,以及中间数据的变化情况。
kettle经验总结

Pan命令来执行转换,下面给出的是pan参数。
Kitchen 命令用于执行作业Carte 用于添加新的执行引擎Kettle的资源库和Carte的登录,密码都是用Encr加密的。
使用中遇到的问题及总结:这两个组件用之前必须先对数据进行排序,否则数据会不准确。
而且merge join会很慢,尽量要少用。
这个组件默认auto commit false,所以如果要执行一些sql,必须在后面加commit。
貌似没什么用,其实也没什么用。
Kettle讲究有进有出,如果最后的没有输出,要加上这个空操作。
实际上测试不写也没问题。
执行java script,这个组件很强大,大部分用组件实现不了的东西,都可以通过这个来转换。
而且可以调用自己写的java 类。
强大到不行~这个组件很奇怪,顾名思义调用存储过程的,但实际上不能调用不传参数的存储过程。
如果有没有参数的存储过程,现在的解决方案是用sql脚本来执行。
一个设置变量,一个获得变量。
这个本来没什么要说的,但在实际应用中发现,在一个trans中设置的变量,在当前trans中并不一定能获得到,所以设计的时候先在一个trans中设置变量,然后在后续的trans中来获得就可以了。
让人惊喜的东西,大数据量导入,事实上让人近乎绝望,研究了一天依旧不会用。
而且我怀疑确实不能用。
其实这个组件无非是实现了copy命令,目前的解决方案,sql脚本,先汗一个,不知道跟这些组件相比效率会怎样。
三个亲兄弟,功能差不多,长的也很像,看了源码感觉,性能有差异,就性能而言,文本文件输入组件很差,它不如csv file input和fixed file input组件,因为后面的两者启用了java nio技术。
顺便提一句而已。
kettle内置性能监控,通过分析能知道哪一环节出现瓶颈。
以上是trans的内容,关于job相比而言简单一些,只是调用trans而已。
值得一说的是job 以start开始,这个start只能有一个。
kettle调研手记-技巧汇总
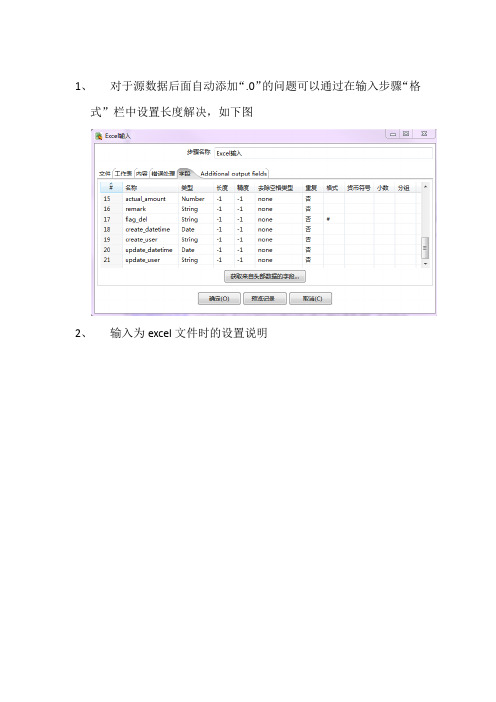
1、对于源数据后面自动添加“.0”的问题可以通过在输入步骤“格式”栏中设置长度解决,如下图2、输入为excel文件时的设置说明3、根据入库单号把明细中的金额求和后,更新到主表中,但是如果有的入库单号在主表中不存在则就会报错,这是数据问题,解决办法为,在更新步骤中设置一下”忽略查询失败”,则只对目标表中存在数据进行更新,如下图:4、使用资源库(repository)登录时,默认的用户名和密码是admin/admin5、当job是存放在资源库(一般资源库都使用数据库)中时,使用Kitchen.bat执行job时,需使用如下的命令行:Kitchen.bat /rep repository_name /user admin /pass admin /job job 名称> E:\\test.log其中repository_nameo为repository.xml中的repository,在最下面6、当job没有存放在资源库而存放在文件系统时,使用Kitchen.bat执行job时,需使用如下的命令行:Kitchen.bat /norep /file user-transfer-job.kjb7、资源名称最好不要用中文,如果程序在保持时的字符集跟系统不一致,就会造成repositories.xml文件中出现乱码,导致无法启动,解决方法是:到用户目录下找到repositories.xml。
将.kettle 文件夹删除,重写用英文名称创建后,成功启动。
8、在WINDOWS下自动执行的配置:先建一个bat文件,内容为:E:\work\kettle\pdi-ce-4.2.0-RC1\data-integration\Kitchen.bat /rep kettle_test /user admin /pass admin /job job的名称然后在windows中新建一个定时任务即可9、在LINUX下执行脚本命令:10、KETTLE所在目录/data-integration/kitchen.sh /reprepository_name /user admin /pass admin /job job名称> /opt/data_wash/log/test.log其中repository_nameo为repository.xml中的repository,在最下面11、Repository.xml在linux系统下的位置:$HOME/.kettle/repository.xml12、定义全局变量:在.kettle目录下,打开kettle.properties文件,以键值对的方式添加即可,如:变量名称=变量值,然后在kettle设置图中可以利用”Get Variables”步骤获取到13、在windows下,kettle的资源库中的数据库表名为小写,而在linux下则为大写,这一点需要注意,以移植时需要所导出表的插入sql脚本,否则会出现无法登录,找不到表的错误。
kettle使用总结

kettle使⽤总结Kettle使⽤笔记⼀、基本概念:1.1、资源库保存kettle脚本或转换、存放数据库连接的地⽅,可以建⽴多个数据库连接,使⽤时就⽆需每次重复建⽴1.2、数据库连接(db links)连接数据库的功能,需处理数据库中的数据时创建,可连接Oracle、SqlServer、MySQL、DB2等1.3、转换(trans)处理数据的ETL过程,⾥⾯存放许多处理数据的组件,完成后保存会⽣成⼀个ktl⽂件。
1.4、作业(job)⾃动、定时执⾏转换的步骤的名称,可以在⾃动执⾏转换的过程添加参数进⾏控制。
1.5、步骤(steps)转换和作⽤的每个操作都是⼀个步骤。
⼆、⼯具栏:2.1、资源库概念保存kettle脚本或转换的地⽅,相当于myeclipes的workspace,另⼀种保存kettle脚本或流程的⽅法是需要保存的时候⽤⽂件保存,点击另存为出现(PS:打开kettle的时候加载的也是资源库)2.2、资源库位置Tools -> 数据库-> 连接数据库2.3、数据库连接创建数据库连接的时候会同时创建数据库连接?右键点击新建转换-> 点击主对象树-> 右键DB连接->新建数据库连接(PS:创建数据库后可以点击Test 判断数据库连接创建成功了没!,Oracle RAC 环境下的数据库连接创建数据库连接的⽅法不同)三、基本操作:3.1、轮流发送模式和复制发送模式的区别如果获取的数据必须同时进⾏多步处理(⼀种⽅式是将数据复制后处理,⼀种是获取的数据进⾏轮流的间隔处理),设置⽅式为:选中Data Grid –> 点击右键–> 数据发送-> 选择轮流发送模式或复制发送模式下图为复制处理的⽅式:红框选中的标签为复制处理3.2、分离步骤的⽅法⽐如下图中分离出步骤”删除”的⽅法:选中”删除”->点击右键-> 点击分离步骤3.3、过滤错误数据的⽅法采集的数据保存到数据库的时候如果有错误就,整个ETL处理流程就会停⽌,可以⽤过滤错误的⽅法将错误的数据写到⽂本中,保证ETL流程继续执⾏步骤:在连接”表输出”和“⽂本⽂件输出2”的时候选择”Error Handing of step”效果如下图(PS:可以明确是哪个字段,那条数据出现的错误)3.4、查询步骤中数据详情的⽅法⽐如查看下图中”表输出”步骤的数据情况的步骤:选中”表输出” -> 点击右键-> 选择显⽰输⼊\输出字段四、转换组件介绍:4.1、核⼼对象-输⼊⽬录下组件4.1.1、表输⼊组件及属性4.1.1.1允许延迟转换像Oracled的BLOB类型字段,需要的时候开始不加载这些数据,最后输出的时候才进⾏4.1.1.2 替换SQL语句⾥的变量(只在Job⾥⾯应⽤)配置需注意的地⽅:1、SQL语句的条件必须⽤${}符合关联起来2、替换SQL语句⾥的变量必须勾选3、Job中的参数组件的设置及转换必须指明是哪个转换4.1.1.3 从步骤插⼊数据配置需注意的地⽅:1、从”获取系统信息”组件中输⼊的参数名称必须和表输⼊的字段名相同2、表输⼊的where 条件中的值⽤”?”代替3、从步骤插⼊数据必须勾选4、获取系统信息组件中的参数类型必须选“命令⾏参数1”5、执⾏JOB后,在参数输⼊栏中输⼊你的参数值4.1.1.4 表输⼊组件⾥的执⾏每⼀⾏?(必须和从步骤插⼊数据选项⼀起使⽤)配置需注意的地⽅:1、从”DataGrid”组件中输⼊的参数名称必须和表输⼊的字段名相同.且该字段有多个值2、表输⼊的where 条件中的值⽤”?”代替3、从步骤插⼊数据、执⾏每⼀⾏?两个选项必须勾选4.1.1.5 记录数量限制如果查询的数据有多条,可选择”记录数量限制”选项进⾏查询数据的数量进⾏限制,⽐如只取100条。
KETTLE使用经验总结

KETTLE使用经验总结1.熟悉KETTLE的基本概念和操作在开始使用KETTLE之前,建议先花一些时间了解KETTLE的基本概念和操作。
KETTLE的核心概念包括转换(Transformation)、作业(Job)、步骤(Step)、输入(Input)和输出(Output)等。
了解这些基本概念可以帮助你更好地理解和使用KETTLE。
2.认真设计转换和作业在使用KETTLE进行数据转换和加载之前,我们需要先认真设计转换和作业。
转换和作业的设计应该考虑到实际需求和数据流程,避免设计不合理或冗余的步骤。
同时,还需要考虑数据的质量和稳定性,以确保转换和作业的可靠性。
3.使用合适的步骤和功能KETTLE提供了很多不同的步骤和功能,我们需要选择和使用合适的步骤和功能来实现实际需求。
比如,如果需要从数据库中抽取数据,可以使用“表输入”步骤;如果需要将数据写入到数据库中,可以使用“表输出”步骤。
熟悉并正确使用这些步骤和功能,可以提高工作效率。
4.合理使用转换和作业参数KETTLE提供了转换和作业参数的功能,可以方便地传递参数和配置信息。
合理使用转换和作业参数可以使转换和作业更具灵活性和可重复性。
比如,可以使用作业参数来配置文件路径和数据库连接等信息,这样可以只修改参数值而不需要修改转换和作业的配置。
5.使用调试和日志功能在进行复杂的数据转换和加载时,很可能遇到问题和错误。
KETTLE 提供了调试和日志功能,可以帮助我们定位和解决问题。
比如,可以在转换和作业中插入“日志”步骤,将关键信息输出到日志文件中;还可以使用“调试”选项来跟踪转换和作业的执行过程。
6.定期备份和优化转换和作业转换和作业的备份和优化非常重要。
定期备份可以避免转换和作业的丢失和损坏;而优化转换和作业可以提高其执行性能。
比如,可以使用数据库索引来加快查询速度,可以使用缓存来减少数据库访问次数。
7.与其他工具和系统集成KETTLE可以与其他工具和系统进行集成和扩展。
kettle工具用法

kettle工具用法关于"kettle工具用法"的1500-2000字文章:Kettle工具是一款功能强大的开源数据集成工具,旨在简化和自动化数据导入、转换和输出的过程。
它拥有直观而强大的用户界面,可让用户通过图形化界面创建和管理数据管道。
本文将逐步回答Kettle工具的用法,涵盖安装、界面介绍、数据导入和转换、数据输出等方面。
一、安装Kettle工具首先,访问Kettle官方网站并下载最新版本的Kettle工具。
下载完成后,运行安装程序,并按照提示进行安装。
安装完成后,打开Kettle工具。
二、界面介绍打开Kettle工具后,你将看到一个主界面,其中包含了工具栏、转换面板和作业面板等。
工具栏上有各种按钮,用于打开、保存和运行数据转换和作业。
转换面板用于创建、编辑和管理数据转换,而作业面板用于创建和管理作业。
你可以通过拖放组件和连接器来建立转换和作业的流程。
三、数据导入数据导入是Kettle工具的一个重要功能,它允许将数据从各种来源导入到目标数据库或文件中。
在Kettle中,你可以通过以下步骤导入数据:1. 创建新的数据转换:在转换面板上右键单击,选择“新建转换”来创建一个新的数据转换。
2. 添加数据输入组件:在工具栏上选择“输入”,然后拖放数据源到转换面板上。
根据需要选择适当的输入类型,如CSV文件、数据库、Excel文件等。
3. 配置数据输入组件:选择添加到转换面板的数据输入组件,右键单击并选择“编辑”。
在配置窗口中,设置数据源的连接信息、查询语句和字段映射等。
4. 添加目标组件:与添加数据输入组件类似,选择“输出”按钮并拖放目标数据库或文件组件到转换面板上。
5. 配置目标组件:选择添加到转换面板的目标组件,右键单击并选择“编辑”。
在配置窗口中,设置目标数据库的连接信息、目标表或文件的格式等。
6. 连接输入和目标组件:在转换面板上,拖动鼠标从数据输入组件的输出连接器到目标组件的输入连接器上,建立数据流。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Kettle使用经验总结
一、关于变量的使用
在etl过程中难免不使用变量,所以就先介绍变量的使用。
其中可以使用kettle已经定义好的变量。
个人感觉最有用的就是“Internal.Job.Filename.Directory”。
这个变量为运行时变量,含义为启动的当前job的目录,是个相对路径。
可以在job中的作业转换名、日志文件名、转换文件名等任何可以使用到文件路径的地方使用。
这样很方便移植,不用每次当文件更改目录后或者移植到不同系统下需要一一更改每个步骤的路径,节省了许多不必要的时间。
还可以在Kettle的属性文件kettle.properties中设置环境变量。
此文件所在目录如下:$HOME/.kettle (Unix/Linux/OSX)
C:\Documents and Settings\<username>\.kettle\kettle.properties (Windows) 使用变量的方法可以如下指定:${V ARIABLE}。
还可以设置运行时变量。
关于命令行启动job/trans直接设置动态变量还没有验证。
待验证后补充。
现在使用的是将参数输入到文本中,然后从文本取得变量的值再在各个trans中使用。
包含设置变量的trans里不能放置使用此变量的步骤,此变量只能在之后的trans/Job中才能使用。
使用的时候直接${varName}即可。
还有一种是使用局部变量可以直接用?代替。
这个需要注意的是在使用变量的步骤中有一个“从步骤插入数据”下拉列表,需要从中选择之前的变量。
对于全量提取和每天增量提取,可以将提取的过程作为一个通用的job,前面根据提取方式的不同连接不同的时间变量,后面提取的sql写为between…and…。
这样既实现了功能,又实现了代码复用。
但是需要注意的是格式问题,获取系统信息取到的时间格式形如“2009/08/10 00:00:00.000”。
如果将此时间使用js截断后再设置,格式会变成类似“Sat Aug 10 00:00:00 CST 2009”。
可以在sql中使用substr,例如“to_date(substr('${BEGINTIME}',1,10),'yyyy/MM/dd')”。
当然也可能会有更好的解决方案。
二、命令行执行job
Linux下:sh kitchen.sh /norep /file [path]/JobName.kjb
其中/norep /file代表不使用资源库,使用文件系统。
如果使用资源库的话改为/rep kettle /user admin /pass admin。
用命令行可以执行后就可以使用windows或linux下的任务调度来定时执行任务了。
三、序列的使用
在“转换”里有一个步骤是“增加序列”。
很多时候我们都需要用一个序列做为表中的一个字段。
值的名称:为序列的字段名称;
获取途径默认是“使用计数器来计算sequence”,这个特点就是每次运行trans的时候都会从1开始,相当于每次都先drop掉原先的序列,重新建立序列再使用;
如果想要使用的是连续的序列,就选择“使用DB来获取sequence”。
数据库连接选择为建立序列的数据库,sequence名称指定为要使用的序列名称。
四、定时执行Job
在linux下设置任务调度过程:
在linux命令行下输入crontab –l 即可查看定时调度列表。
crontab –e 修改定时计划列表内容
10 3 * * * nohup sh /home/test/cript.sh &>/home/test/no.log
格式:
10 3 * * *
10代表分钟,取值范围为0~59;3代表小时,取值范围为0~23。
此命令含义为在每天的凌晨3点10分运行cript.sh脚本的内容,可以修改这2个位置的时间自定义每日ETL工作的开始时间。
后面的命令为运行脚本文件,脚本文件位于/home/test/目录下,内容为:
#!/bin/bash
. /etc/profile
sh /home/test/data-integration/kitchen.sh /norep /file [path]/JobName.kjb > /home/test/ JobName.log
其含义:启动kettle的job,JobName.kjb为每日增量提取的job名称。
五、邮件通知
在job中加入邮件通知,当etl过程出现问题后,将日志发送到指定邮箱。
在“附件”选项卡中,选中“带附件”,文件类型为“日志”,将之前出错的job及其中的trans输出日志级别改为“错误日志”,即可将出错的内容以附件形式发送到指定邮箱。
这里需要将连线改变种类,黑色代表完成当前任务后无条件的进行下一个工作,绿色表示当前任务成功后转向下一个工作,红色则表示当前任务出现问题后发生转向。
后记
因为水平有限,可能以上内容不是最合适的,还有待优化。
以及很多组件没有用到,很多功能没有发现。
待之后有空或项目中用到的时候都会持续更新补充。
欢迎大家指正批评。