第六章练习题及参考解答(第四版)
互换性与测量技术基础第四版答案

(3)Φ30 Xmax=0.019mmYmax=-0.015mm基轴制、过渡配合
(4)Φ140 Ymax=-0.126mmYmin=0mm基孔制、过盈配合
(5)Φ180 Xmax=-0.235mmYmin=-0.170mm基孔制、过盈配合
(10)Φ50 Xmax=0.023mmYmax=-0.018mm基轴制、过渡配合
4. (1) Φ60 (2) Φ30 (3) Φ50 (4) Φ30 (5) Φ50
5.∵Xmin=0.025mm, Xmax=0.066mm.∴配合公差Tf=| 0.066 –0.025| =0.041mm,
∵Tf= Th+ Ts,选基孔制.查表,孔为7级,轴为6级Th=0.025mm Ts= 0.016mm符合要求.∴选Φ40 。
5. =30.741mm, =1.464μm, δlim=±3σ'=±4.392µm
6. L=20.0005mm =0.5µm L=L±3 =20.0015±0.0015mm
7. L= L1+L2+L3=20+1.005+1.485=22.485mm
= ±0.5µm∴L=22.485±0.0005mm
(2)上验收极限 =29.98-0.0021=29.9779mm ,下验收极限 = 29.959+0.0021=29.9611mm。选分度值0.002比较仪。
+0.012
-0.009
0.021
Φ30
轴: Φ40
39.95
39.888
-0.050
-0.112
0.062
Φ40
(完整版)化工原理(第四版)习题解第六章蒸馏
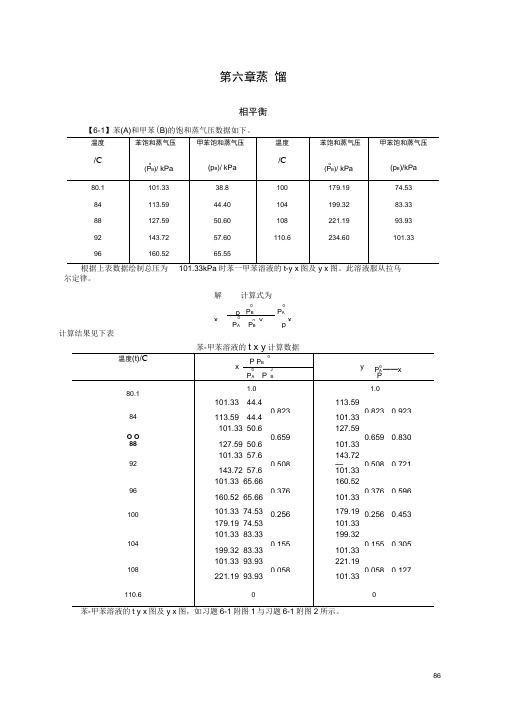
第六章蒸馏相平衡【6-1】苯(A)和甲苯(B)的饱和蒸气压数据如下。
尔定律。
解计算式为0 0p P B P Ax 0 0, y xP A P B p计算结果见下表苯-甲苯溶液的t x y计算数据温度(t)/CxP P By 0P A ——xP 0P A PJB80.11.0 1.0101.33 44.4 113.590.823 0.823 0.92384 113.59 44.4 101.33101.33 50.6 127.59O O0.659 0.659 0.83088127.59 50.6 101.33101.33 57.6 143.7292 0.508 —0.508 0.721143.72 57.6 101.33101.33 65.66 160.5296 0.376 0.376 0.596160.52 65.66 101.33100101.33 74.53 0.256 179.19 0.256 0.453179.19 74.53 101.33101.33 83.33 199.32104 0.155 0.155 0.305199.32 83.33 101.33101.33 93.93 221.19108 0.058 0.058 0.127221.19 93.93 101.33110.6 0 0苯-甲苯溶液的t y x图及y x图,如习题6-1附图1与习题6-1附图2所示。
习题6-1附图1 苯-甲苯t-y-x 图习题6-1附图2 苯-甲苯y-x 图【6-2】在总压101.325kPa 下,正庚烷-正辛烷的汽液平衡数据如下。
试求:(1)在总压101.325kPa 下,溶液中正庚烷为 0.35 (摩尔分数)时的泡点及平衡汽相的瞬 间组成;⑵在总压101.325kPa 下,组成x 0.35的溶液,加热到117C ,处于什么状态?溶液加热 到什么温度,全部汽化为饱和蒸气?解 用汽液相平衡数据绘制t y x 图。
统计分析与SPSS的应用薛薇第四版的第六章课后习题:第一题
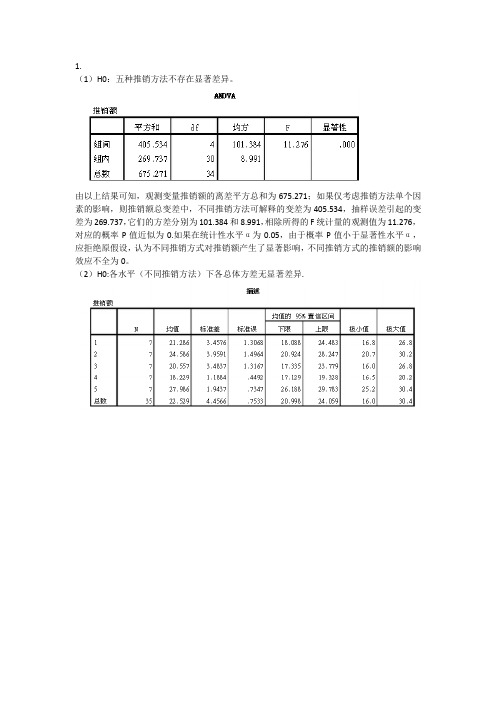
1.
(1)H0:五种推销方法不存在显著差异。
由以上结果可知,观测变量推销额的离差平方总和为675.271;如果仅考虑推销方法单个因素的影响,则推销额总变差中,不同推销方法可解释的变差为405.534,抽样误差引起的变差为269.737,它们的方差分别为101.384和8.991,相除所得的F统计量的观测值为11.276,对应的概率P值近似为0.如果在统计性水平α为0.05,由于概率P值小于显著性水平α,应拒绝原假设,认为不同推销方式对推销额产生了显著影响,不同推销方式的推销额的影响效应不全为0。
(2)H0:各水平(不同推销方法)下各总体方差无显著差异.
上表是推销方法对推销额的单因素方差分析结果。
可以看到:不同推销方法下推销额的方差齐性检验值为2.048,概率P-值为0.113大于显著性水平0.05,不应拒绝原假设,认为不同推销方法下推销额的总体方差无显著差异,满足方差分析的前提要求。
H0:不同推销方式没有对推销额产生显著影响,即:不同水平下控制因素的影响不显著。
由第一题可得:
在此之后检验:
在LSD方法中,第一组和第三组的效果没有明显的差异(概率P值为0.653),第一组和第四组的效果没有明显的差异(概率P值为0.066);与第二组和第五组有明显的差异(概率P 值分别为0.048,接近0)。
传热学第四版课后题答案第六章.

第六章复习题1、什么叫做两个现象相似,它们有什么共性?答:指那些用相同形式并具有相同内容的微分方程式所描述的现象,如果在相应的时刻与相应的地点上与现象有关的物理量一一对于成比例,则称为两个现象相似。
凡相似的现象,都有一个十分重要的特性,即描述该现象的同名特征数(准则)对应相等。
(1) 初始条件。
指非稳态问题中初始时刻的物理量分布。
(2) 边界条件。
所研究系统边界上的温度(或热六密度)、速度分布等条件。
(3) 几何条件。
换热表面的几何形状、位置、以及表面的粗糙度等。
(4) 物理条件。
物体的种类与物性。
2.试举出工程技术中应用相似原理的两个例子.3.当一个由若干个物理量所组成的试验数据转换成数目较少的无量纲以后,这个试验数据的性质起了什么变化?4.外掠单管与管内流动这两个流动现象在本质上有什么不同?5、对于外接管束的换热,整个管束的平均表面传热系数只有在流动方向管排数大于一定值后才与排数无关,试分析原因。
答:因后排管受到前排管尾流的影响(扰动)作用对平均表面传热系数的影响直到10排管子以上的管子才能消失。
6、试简述充分发展的管内流动与换热这一概念的含义。
答:由于流体由大空间进入管内时,管内形成的边界层由零开始发展直到管子的中心线位置,这种影响才不发生变法,同样在此时对流换热系数才不受局部对流换热系数的影响。
7、什么叫大空间自然对流换热?什么叫有限自然对流换热?这与强制对流中的外部流动和内部流动有什么异同?答:大空间作自然对流时,流体的冷却过程与加热过程互不影响,当其流动时形成的边界层相互干扰时,称为有限空间自然对流。
这与外部流动和内部流动的划分有类似的地方,但流动的动因不同,一个由外在因素引起的流动,一个是由流体的温度不同而引起的流动。
8.简述射流冲击传热时被冲击表面上局部表面传热系数的分布规律.9.简述数数,数,Gr Nu Pr 的物理意义.Bi Nu 数与数有什么区别? 10.对于新遇到的一种对流传热现象,在从参考资料中寻找换热的特征数方程时要注意什么?相似原理与量纲分析6-1 、在一台缩小成为实物1/8的模型中,用200C 的空气来模拟实物中平均温度为2000C 空气的加热过程。
高等代数第6章习题参考答案

第六章 线性空间1.设,N M ⊂证明:,M N M M N N ==I U 。
证 任取,M ∈α由,N M ⊂得,N ∈α所以,N M I ∈α即证M N M ∈I 。
又因,M N M ⊂I 故M N M =I 。
再证第二式,任取M ∈α或,N ∈α但,N M ⊂因此无论哪 一种情形,都有,N ∈α此即。
但,N M N Y ⊂所以M N N =U 。
2.证明)()()(L M N M L N M I Y I Y I =,)()()(L M N M L N M Y I Y I Y =。
证 ),(L N M x Y I ∈∀则.L N x M x Y ∈∈且在后一情形,于是.L M x N M x I I ∈∈或所以)()(L M N M x I Y I ∈,由此得)()()(L M N M L N M I Y I Y I =。
反之,若)()(L M N M x I Y I ∈,则.L M x N M x I I ∈∈或 在前一情形,,,N x M x ∈∈因此.L N x Y ∈故得),(L N M x Y I ∈在后一情形,因而,,L x M x ∈∈x N L ∈U ,得),(L N M x Y I ∈故),()()(L N M L M N M Y I I Y I ⊂于是)()()(L M N M L N M I Y I Y I =。
若x M N L M N L ∈∈∈UI I (),则x ,x 。
在前一情形X x M N ∈U , X M L ∈U 且,x M N ∈U 因而()I U (M L )。
,,N L x M N X M L M N M M N M N ∈∈∈∈∈⊂U U U I U U I U U U U I U I U 在后一情形,x ,x 因而且,即X (M N )(M L )所以 ()(M L )(N L )故 (L )=()(M L )即证。
3、检验以下集合对于所指的线性运算是否构成实数域上的线性空间:1) 次数等于n (n ≥1)的实系数多项式的全体,对于多项式的加法和数量乘法;2) 设A 是一个n ×n 实数矩阵,A 的实系数多项式f (A )的全体,对于矩阵的加法和数量乘法;3) 全体实对称(反对称,上三角)矩阵,对于矩阵的加法和数量乘法; 4) 平面上不平行于某一向量所成的集合,对于向量的加法和数量乘法; 5) 全体实数的二元数列,对于下面定义的运算:212121121112b a b a a b b a a k k b a ⊕+=+++-1111(a ,)((,)()k 。
电磁场与电磁波(第4版)第6章部分习题参考解答

G
G E(z)
G
=
eGx100e− j(β z+90D )
+
G ey
200e− jβ z
由 ∇ × E = − jωμ0H 得
G H
(z)
=
−
1 jωμ0
∇×
G E(z)
=
−
1 jωμ0
⎡ ⎢
G ex
⎢∂
⎢ ⎢
∂x
G ey ∂ ∂y
G ez ∂ ∂zຫໍສະໝຸດ ⎤ ⎥ ⎥ ⎥ ⎥=
−
1 jωμ0
G (−ex
∂Ey ∂z
G (1) 电场 E = 0 的位置;(2) 聚苯乙烯中 Emax 和 Hmax 的比值。
解:(1)
令
z
'
=
z
−
0.82
,设电场振动方向为
G ex
,则在聚苯乙烯中的电场为
G E1 ( z
')
=
G Ei
(z
')
+
G Er
(z
')
=
G −ex
j2Eim
sin
β
z
'
G 故 E1(z ') = 0 的位置为 β z ' = −nπ, (n = 0,1, 2,")
G ex
G × Ei (x)
G = ez
1
− j2 πx
e3
12π
A/m
G
G
(2) 反射波电场 Er 和磁场 Hr 的复矢量分别为
G Er (x) =
G
j2 πx
−ey10e 3
G V/m , Hr (x)
概率论与数理统计(理工类_第四版)吴赣昌主编课后习题答案第六章

第六章参数估计6.1 点估计问题概述习题1总体X在区间[0,θ]上均匀分布,X1,X2,?,Xn是它的样本,则下列估计量θ是θ的一致估计是().(A)θ=Xn; (B)θ=2Xn;(C)θ=Xˉ=1n∑i=1nXi; (D)θ=Max{X1,X2,?,Xn}.解答:应选(D).由一致估计的定义,对任意?>0,P(∣Max{X1,X2,?,Xn}-θ∣<?)=P(-?+θ<Max{X1,X2,?,Xn}<?+θ)=F(?+θ)-F(-?+θ).因为FX(x)={0,x<0xθ,0≤x≤θ1,x>θ, 及F(x)=FMax{X1,X2,?,Xn}(x)=FX1(x)FX2(x)?FXn(x),所以F(?+θ)=1, F(-?+θ)=P(Max{X1,X2,?,Xn}<-?+θ)=(1-xθ)n,故P(∣Max{X1,X2,?,Xn}-θ∣<?)=1-(1-xθ)n→1(n→+∞).习题2设σ是总体X的标准差,X1,X2,?,Xn是它的样本,则样本标准差S是总体标准差σ的().(A)矩估计量; (B)最大似然估计量; (C)无偏估计量; (D)相合估计量.解答:应选(D).因为,总体标准差σ的矩估计量和最大似然估计量都是未修正的样本标准差;样本方差是总体方差的无偏估计,但是样本标准差不是总体标准差的无偏估计.可见,样本标准差S是总体标准差σ的相合估计量.习题3设总体X的数学期望为μ,X1,X2,?,Xn是来自X的样本,a1,a2,?,an是任意常数,验证(∑i=1naiXi)/∑i=1nai(∑i=1nai≠0)是μ的无偏估计量.解答:E(X)=μ,E(∑i=1naiXi∑i=1nai)=1∑i=1nai?∑i=1naiE(Xi) (E(Xi)=E(X)=μ)=μ∑i=1nai∑i=1n=μ,综上所证,可知∑i=1naiXi∑i=1nai是μ的无偏估计量.习题4设θ是参数θ的无偏估计,且有D(θ)>0, 试证θ2=(θ)2不是θ2的无偏估计. 解答:因为D(θ)=E(θ2)-[E(θ)]2, 所以E(θ2)=D(θ)+[E(θ)]2=θ2+D(θ)>θ2,故(θ)2不是θ2的无偏估计.习题5设X1,X2,?,Xn是来自参数为λ的泊松分布的简单随机样本,试求λ2的无偏估计量.解答:因X服从参数为λ的泊松分布,故D(X)=λ, E(X2)=D(X)+[E(X)]2=λ+λ2=E(X)+λ2,于是E(X2)-E(X)=λ2, 即E(X2-X)=λ2.用样本矩A2=1n∑i=1nXi2,A1=Xˉ代替相应的总体矩E(X2),E(X), 便得λ2的无偏估计量λ2=A2-A1=1n∑i=1nXi2-Xˉ.习题6设X1,X2,?,Xn为来自参数为n,p的二项分布总体,试求p2的无偏估计量.解答:因总体X~b(n,p), 故E(X)=np,E(X2)=D(X)+[E(X)]2=np(1-p)+n2p2=np+n(n-1)p2=E(X)+n(n-1)p2,E(X2)-E(X)n(-1)=E[1n(n-1)(X2-X)]=p2,于是,用样本矩A2,A1分别代替相应的总体矩E(X2),E(X),便得p2的无偏估计量p2=A2-A1n(n-1)=1n2(n-1)∑i=1n(Xi2-Xi).习题7设总体X服从均值为θ的指数分布,其概率密度为f(x;θ)={1θe-xθ,x>00,x≤0,其中参数θ>0未知. 又设X1,X2,?,Xn是来自该总体的样本,试证:Xˉ和n(min(X1,X2,?,Xn))都是θ的无偏估计量,并比较哪个更有效.解答:因为E(X)=θ, 而E(Xˉ)=E(X),所以E(Xˉ)=θ, Xˉ是θ的无偏估计量.设Z=min(X1,X2,?,Xn),因为FX(x)={0,x≤01-e-xθ,x>0,FZ(x)=1-[1-FX(x)]n={1-e-nxθ,x>00,x≤0,所以fZ(x)={nθe-nxθ,x>00,x≤0,这是参数为nθ的指数分布,故知E(Z)=θn, 而E(nZ)=E[n(min(X1,X2,?,Xn)]=θ,所以nZ也是θ的无偏估计.现比较它们的方差大小.由于D(X)=θ2, 故D(Xˉ)=θ2n.又由于D(Z)=(θn)2, 故有D(nZ)=n2D(Z)=n2?θ2n2=θ2.当n>1时,D(nZ)>D(Xˉ),故Xˉ较nZ有效.习题8设总体X服从正态分布N(m,1),X1,X2是总体X的子样,试验证m1=23X1+13X2, m2=14X1+34X2, m3=12X1+12X2,都是m的无偏估计量;并问哪一个估计量的方差最小?解答:因为X服从N(m,1), 有E(Xi)=m,D(Xi)=1(i=1,2),得E(m1)=E(23X1+13X2)=23E(X1)+13E(X2)=23m+13m=m,D(m1)=D(23X1+13X2)=49D(X1)+19D(X2)=49+19=59,同理可得:E(m2)=m,D(m2)=58, E(m3)=m,D(m3)=12.所以,m1,m2,m3都是m的无偏估计量,并且在m1,m2,m3中,以m3的方差为最小.习题9设有k台仪器. 已知用第i台仪器测量时,测定值总体的标准差为σi(i=1,2,?,k), 用这些仪器独立地对某一物理量θ各观察一次,分别得到X1,X2,?,Xk. 设仪器都没有系统误差,即E(Xi)=θ(i=1,2,?,k), 问a1,a2,?,ak应取何值,方能使用θ=∑i=1kaiXi估计θ时,θ是无偏的,并且D(θ)最小?解答:因为E(Xi)=θ(i=1,2,?,k), 故E(θ)=E(∑i=1kaiXi)=∑i=1kaiE(Xi)=θ∑i=1kai,欲使E(θ)=θ, 则要∑i=1kai=1.因此,当∑i=1kai=1时,θ=∑i=1kaiXi为θ的无偏估计, D(θ)=∑i=1kai2σi2, 要在∑i=1kai=1的条件下D(θ)最小,采用拉格朗日乘数法.令L(a1,a2,?,ak)=D(θ)+λ(1-∑i=1kai)=∑i=1kai2σi2+λ(1-∑i=1kai),{?L?ai=0,i=1,2,?,k∑i=1kai=1,即2aiσi2-λ=0,ai=λ2i2;又因∑i=1kai=1,所以λ∑i=1k12σi2=1, 记∑i=1k1σi2=1σ02, 所以λ=2σ02, 于是ai=σ02σi2 (i=1,2,?,k),故当ai=σ02σi2(i=1,2,?,k)时,θ=∑i=1kaiXi是θ的无偏估计,且方差最小.习题6.2 点估计的常用方法习题1设X1,X2,?,Xn为总体的一个样本,x1,x2,?,xn为一相应的样本值,求下述各总体的密度函数或分布律中的未知参数的矩估计量和估计值及最大似然估计量.(1)f(x)={θcθx-(θ+1),x>c0,其它, 其中c>0为已知,θ>1,θ为未知参数.(2)f(x)={θxθ-1,0≤x≤10,其它, 其中θ>0,θ为未知参数.(3)P{X=x}=(mx)px(1-p)m-x, 其中x=0,1,2,?,m,0<p<1,p为未知参数.解答:(1)E(X)=∫c+∞x?θcθx-(θ+1)dx=θcθ∫c+∞x-θdx=θcθ-1,解出θ=E(X)E(X)-c,令Xˉ=E(X),于是θ=XˉXˉ-c为矩估计量,θ的矩估计值为θ=xˉxˉ-c,其中xˉ=1n∑i=1nxi.另外,似然函数为L(θ)=∏i=1nf(xi;θ)=θncnθ(∏i=1nxi)-(θ+1),xi>c,对数似然函数为lnL(θ)=nlnθ+nθlnc-(θ+1)∑i=1nlnxi,对lnL(θ)求导,并令其为零,得dlnL(θ)dθ=nθ+nlnc-∑i=1nlnxi=0,解方程得θ=n∑i=1nlnxi-nlnc,故参数的最大似然估计量为θ=n∑i=1nlnXi-nlnc.(2)E(X)=∫01x?θxθ-1dx=θθ+1,以Xˉ作为E(X)的矩估计,则θ的矩估计由Xˉ=θθ+1解出,得θ=(Xˉ1-Xˉ)2,θ的矩估计值为θ=(xˉ1-xˉ)2,其中xˉ=1n∑i=1nxi为样本均值的观测值.另外,似然函数为L(θ)=∏i=1nf(xi;θ)=θn/2(∏i=1nxi)θ-1,0≤xi≤1,对数似然函数为lnL(θ)=n2lnθ+(θ-1)∑i=1nlnxi,对lnL(θ)求导,并令其为零,得dlnL(θ)dθ=n2θ+12θ∑i=1nlnxi=0,解方程得θ=(-n∑i=1nlnxi)2,故参数的最大似然估计量为θ=(n∑i=1nlnXi)2.(3)X~b(m,p),E(X)=mp,以Xˉ作为E(X)的矩估计,即Xˉ=E(X),则参数p的矩估计为p=1mXˉ=1m?1n∑i=1nXi,p的矩估计值为p=1mxˉ=1m?1n∑i=1nxi.另外,似然函数为L(θ)=∏i=1nf(xi;θ)=(∏i=1nCmxi)p∑i=1nxi(1-p)∑i=1n(m-xi),xi=0,1,?,m,对数似然函数为lnL(θ)=∑i=1nlnCmxi+(∑i=1nxi)lnp+(∑i=1n(m-xi))ln(1-p),对lnL(θ)求导,并令其为零,得dlnL(θ)dθ=1p∑i=1nxi-11-p∑i=1n(m-xi)=0,解方程得p=1mn∑i=1nxi,故参数的最大似然估计量为p=1mn∑i=1nXi=1mXˉ.习题2设总体X服从均匀分布U[0,θ],它的密度函数为f(x;θ)={1θ,0≤x≤θ0,其它,(1)求未知参数θ的矩估计量;(2)当样本观察值为0.3,0.8,0.27,0.35,0.62,0.55时,求θ的矩估计值.解答:(1)因为E(X)=∫-∞+∞xf(x;θ)dx=1θ∫0θxdx=θ2,令E(X)=1n∑i=1nXi,即θ2=Xˉ,所以θ=2Xˉ.(2)由所给样本的观察值算得xˉ=16∑i=16xi=16(0.3+0.8+0.27+0.35+0.62+0.55)=0.4817,所以θ=2xˉ=0.9634.习题3设总体X以等概率1θ取值1,2,?,θ, 求未知参数θ的矩估计量.解答:由E(X)=1×1θ+2×1θ+?+θ×1θ=1+θ2=1n∑i=1nXi=Xˉ,得θ的矩估计为θ=2Xˉ-1.习题4一批产品中含有废品,从中随机地抽取60件,发现废品4件,试用矩估计法估计这批产品的废品率.解答:设p为抽得废品的概率,1-p为抽得正品的概率(放回抽取). 为了估计p,引入随机变量Xi={1,第i次抽取到的是废品0,第i次抽取到的是正品,于是P{Xi=1}=p,P{Xi=0}=1-p=q, 其中i=1,2,?,60,且E(Xi)=p, 故对于样本X1,X2,?,X60的一个观测值x1,x2,?,x60, 由矩估计法得p的估计值为p=160∑i=160xi=460=115,即这批产品的废品率为115.习题5设总体X具有分布律X 1 2 3pi θ2 2θ(1-θ) (1-θ)2其中θ(0<θ<1)为未知参数. 已知取得了样本值x1=1,x2=2,x3=1, 试求θ的矩估计值和最大似然估计值.解答:E(X)=1×θ2+2×2θ(1-θ)+3×(1-θ)2=3-2θ,xˉ=1/3×(1+2+1)=4/3.因为E(X)=Xˉ,所以θ=(3-xˉ)/2=5/6为矩估计值,L(θ)=∏i=13P{Xi=xi}=P{X1=1}P{X2=2}P{X3=1}=θ4?2θ?(1-θ)=2θ5(1-θ),lnL(θ)=ln2+5lnθ+ln(1-θ),对θ求导,并令导数为零dlnLdθ=5θ-11-θ=0,得θL=56.习题6(1)设X1,X2,?,Xn来自总体X的一个样本, 且X~π(λ), 求P{X=0}的最大似然估计.(2)某铁路局证实一个扳道员五年内所引起的严重事故的次数服从泊松分布,求一个扳道员在五年内未引起严重事故的概率 p的最大似然估计,使用下面122个观察值统计情况. 下表中,r表示一扳道员某五年中引起严重事故的次数,s表示观察到的扳道员人数.r 012345sr 444221942解答:(1)已知,λ的最大似然估计为λL=Xˉ.因此?P{X=0}=e-λL=e-Xˉ.(2)设X为一个扳道员在五年内引起的严重事故的次数,X服从参数为λ的泊松分布,样本容量n=122.算得样本均值为xˉ=1122×∑r=05r?r=1122×(0×44+1×42+2×21+3×9+4×4+5×2)≈1.123,因此P{X=0}=e-xˉ=e-1.123≈0.3253.习题6.3 置信区间习题1对参数的一种区间估计及一组观察值(x1,x2,?,xn)来说,下列结论中正确的是().(A)置信度越大,对参数取值范围估计越准确;(B)置信度越大,置信区间越长;(C)置信度越大,置信区间越短;(D)置信度大小与置信区间有长度无关.解答:应选(B).置信度越大,置信区间包含真值的概率就越大,置信区间的长度就越大,对未知参数的估计精度越低.反之,对参数的估计精度越高,置信区间的长度越小,它包含真值的概率就越低,置信度就越小.习题2设(θ1,θ2)是参数θ的置信度为1-α的区间估计,则以下结论正确的是().(A)参数θ落在区间(θ1,θ2)之内的概率为1-α;(B)参数θ落在区间(θ1,θ2)之外的概率为α;(C)区间(θ1,θ2)包含参数θ的概率为1-α;(D)对不同的样本观察值,区间(θ1,θ2)的长度相同.解答:应先(C).由于θ1,θ2都是统计量,即(θ1,θ2)是随机区间,而θ是一个客观存在的未知常数,故(A),(B)不正确.习题3设总体的期望μ和方差σ2均存在,如何求μ的置信度为1-α的置信区间?解答:先从总体中抽取一容量为n的样本X1,X2,?,Xn.根据中心极限定理,知U=Xˉ-μσ/n→N(0,1)(n→∞).(1)当σ2已知时,则近似得到μ的置信度为1-α的置信区间为(Xˉ-uα/2σn,Xˉ+uα/2σn).(2)当σ2未知时,用σ2的无偏估计S2代替σ2, 这里仍有Xˉ-μS/n→N(0,1)(n→∞),于是得到μ的1-α的置信区间为(Xˉ-uα/2Sn,Xˉ+uα/2Sn),一般要求n≥30才能使用上述公式,称为大样本区间估计.习题4某总体的标准差σ=3cm, 从中抽取40个个体,其样本平均数xˉ=642cm,试给出总体期望值μ的95%的置信上、下限(即置信区间的上、下限).解答:因为n=40属于大样本情形,所以Xˉ近似服从N(μ,σ2n)的正态分布,于是μ的95%的置信区间近似为(Xˉ±σnuα/2),这里xˉ=642,σ=3,n=40≈6.32,uα/2=1.96, 从而(xˉ±σnuα/2)=(642±340×1.96)≈(642±0.93),故μ的95%的置信上限为642.93, 下限为641.07.习题5某商店为了了解居民对某种商品的需要,调查了100家住户,得出每户每月平均需求量为10kg, 方差为9,如果这个商店供应10000户,试就居民对该种商品的平均需求量进行区间估计(α=0.01), 并依此考虑最少要准备多少这种商品才能以0.99的概率满足需求?解答:因为n=100属于大样本问题,所以Xˉ近似服从N(μ,σ2/n),于是μ的99%的置信区间近似为(Xˉ±Snuα/2), 而xˉ=10,s=3,n=100, uα/2=2.58,所以(xˉ±snuα/2)=(10±3100×2.58)=(10±0.774)=(9.226,10.774).由此可知最少要准备10.774×10000=107740(kg)这种商品,才能以0.99的概率满足需求.习题6观测了100棵“豫农一号”玉米穗位,经整理后得下表(组限不包括上限):分组编号 12345组限组中值频数70~8080~9090~100100~110110~12075859510511539131626分组编号 6789组限组中值频数120~130130~140140~150150~16012513514515520742试以95%的置信度,求出该品种玉米平均穗位的置信区间.解答:因为n=100属于大样本情形,所以μ的置信度为95%的置信区间上、下限近似为Xˉ±snuα/2, 这里n=100,uα/2=1.96, 还需计算出xˉ和s.取a=115,c=10, 令zi=(xi-a)/c=(xi-115)/10, 用简单算公式,(1)xˉ=a+czˉ;(2)sx2=c2sz2.编号 123456789组中值xi zi=xi-11510 组频率mi mizizi2mizi2 758595105115125135145155 -4-3-2-1012343913162620742-12-27-26-160201412816941014916123456789zˉ=1100∑i=19mizi=1100×(-27)=-0.27,xˉ=10×(-27)+115=112.3,sz2=199∑i=19mizi2=199×313≈3.161616,sx2=102×3.161616=316.1616, sx≈17.78.于是(xˉ±snuα)≈(112.3±17.7810×1.96)≈(112.3±3.485) =(108.815,115.785).习题7某城镇抽样调查的500名应就业的人中,有13名待业者,试求该城镇的待业率p的置信度为0.95置信区间.解答:这是(0-1)分布参数的区间估计问题. 待业率p的0.95置信区间为(p1,p2)=(-b-b2-4ac2a,-b+b2-4ac2a).其中a=n+uα/22,b=-2nXˉ-(uα/2)2, c=nXˉ2,n=500,xˉ=13500,uα/2=1.96.则(p1,p2)=(0.015,0.044).习题8设X1,X2,?,Xn为来自正态总体N(μ,σ2)的一个样本,求μ的置信度为1-α的单侧置信限.解答:这是一个正态总体在方差未知的条件下,对μ的区间估计问题,应选取统计量:T=Xˉ-μS/n~t(n-1).因为只需作单边估计,注意到t分布的对称性,故令P{T<tα(n-1)}=1-α和P{T>tα(n-1)}=1-α.由给定的置信度1-α, 查自由度为n-1的t分布表可得单侧临界值tα(n-1). 将不等式T<tα(n-1)和T>tα(n-1), 即Xˉ-μS/n<tα(n-1)和Xˉ-μS/n>tα(n-1)分别变形,求出μ即得μ的1-α的置信下限为Xˉ-tα(n-1)Sn.μ的1-α的置信上限为Xˉ+tα(n-1)Sn,μ的1-α的双侧置信限(Xˉ-tα/2(n-1)Sn,Xˉ+tα/2(n-1)Sn).习题6.4 正态总体的置信区间习题1已知灯泡寿命的标准差σ=50小时,抽出25个灯泡检验,得平均寿命xˉ=500小时,试以95%的可靠性对灯泡的平均寿命进行区间估计(假设灯泡寿命服从正态分布).解答:由于X~N(μ,502), 所以μ的置信度为95%的置信区间为(Xˉ±uα/2σn),这里xˉ=500,n=25,σ=50,uα/2=1.96, 所以灯泡的平均寿命的置信区间为(xˉ±uα/2σn)=(500±5025×1.96)=(500±19.6)=(480.4,519.6).习题2一个随机样本来自正态总体X,总体标准差σ=1.5, 抽样前希望有95%的置信水平使得μ的估计的置信区间长度为L=1.7, 试问应抽取多大的一个样本?解答:因方差已知,μ的置信区间长度为L=2uα/2?σn,于是n=(2σLuα/2)2.由题设知,1-α=0.95,α=0.05,α2=0.025. 查标准正态分布表得u0.025=1.96,σ=1.5,L=1.7,所以,样本容量n=(2×1.5×1.961.7)2≈11.96.向上取整数得n=12, 于是欲使估计的区间长度为 1.7的置信水平为95%, 所以需样本容量为n=12.习题3设某种电子管的使用寿命服从正态分布. 从中随机抽取15个进行检验,得平均使用寿命为1950小时,标准差s为300小时,以95%的可靠性估计整批电子管平均使用寿命的置信上、下限.解答:由X~N(μ,σ2), 知μ的95%的置信区间为(Xˉ±Sntα/2(n-1)),这里xˉ=1950,s=300,n=15,tα/2(14)=2.145, 于是(xˉ±sntα/2(n-1))=(1950±30015×2.145)≈(1950±166.151)=(1783.85,2116.15).即整批电子管平均使用寿命的置信上限为2116.15, 下限为1783.85.习题4人的身高服从正态分布,从初一女生中随机抽取6名,测其身高如下(单位:cm):149 158.5 152.5 165 157 142求初一女生平均身高的置信区间(α=0.05).解答:X~N(μ,σ2),μ的置信度为95%的置信区间为(Xˉ±Sntα/2(n-1)),这里xˉ=154,s=8.0187, t0.025(5)=2.571, 于是(xˉ±sntα/2(n-1))=(154±8.01876×2.571)≈(154±8.416)≈(145.58,162.42).习题5某大学数学测验,抽得20个学生的分数平均数xˉ=72,样本方差s2=16, 假设分数服从正态分布,求σ2的置信度为98%的置信区间.解答:先取χ2分布变量,构造出1-α的σ2的置信区间为((n-1)S2χα/22(n-1),(n-1)S2χ1-α/22(n-1)).已知1-α=0.98,α=0.02,α2=0.01,n=20, S2=16.查χ2分布表得χ0.012(19)=36.191,χ0.992(19)=7.633,于是得σ2的98%的置信区间为(19×1636.191,19×167.633),即(8.400,39.827).习题6随机地取某种炮弹9发做试验,得炮口速度的样本标准差s=11(m/s).设炮口速度服从正态分布,求这种炮弹的炮口速度的标准差σ的置信度为0.95的置信区间.解答:已知n=9,s=11(m/s),1-α=0.95.查表得χ0.0252(8)=17.535, χ0.9752(8)=2.180,σ的0.95的置信区间为(8sχ0.0252(8),8sχ0.9752(8)), 即(7.4,21.1).习题7设来自总体N(μ1,16)的一容量为15的样本,其样本均值x1ˉ=14.6;来自总体N(μ2,9)的一容量为20的样本,其样本均值x2ˉ=13.2;并且两样本是相互独立的,试求μ1-μ2的90%的置信区间.解答:1-α=0.9,α=0.1, 由Φ(uα/2)=1-α2=0.95, 查表,得uα/2=1.645,再由n1=15,n2=20, 得σ12n1+σ22n2=1615+920=9160≈1.232,uα/2σ12n1+σ22n2=1.645×1.232≈2.03,xˉ1-xˉ2=14.6-13.2=1.4,所以,μ1-μ2的90%的置信区间为(1.4-2.03,1.4+2.03)=(-0.63,3.43).习题8物理系学生可选择一学期3学分没有实验课,也可选一学期4学分有实验的课. 期未考试每一章节都考得一样,若有上实验课的12个学生平均考分为84,标准差为4,没上实验课的18个学生平均考分为77,标准差为6,假设总体均为正态分布且其方差相等,求两种课程平均分数差的置信度为99%的置信区间.解答:设有实验课的考分总体X1~N(μ1,σ2), 无实验课的考分总体X2~N(μ2,σ2). 两方差相等但均未知,求μ1-μ2的99%的置信区间,应选t分布变量,T=X1ˉ-X2ˉ-(μ1-μ2)SW1n1+1n2~t(n1+n2-2),其中SW=(n1-1)S12+(n2-1)S22n1+n2-2.μ1-μ2的1-α的置信区间为(X1ˉ-X2ˉ±tα/2(n1+n2-2)SW1n1+1n2).由已知,x1ˉ-x2ˉ=84-77=7, 且sW=(12-1)×42+(18-1)×6212+18-2≈5.305,112+118≈0.373, 1-α=0.99, α2=0.005,查t分布表得t0.005(28)=2.763.于是,μ1-μ2的0.99的置信区间为(7±2.763×5.305×0.373),即(7±5.467),亦即(1.53,12.47).习题9随机地从A批导线中抽取4根,又从B批导线中抽取5根,测得电阻(欧)为A批导线 0.1430.1420.1430.137B批导线 0.1400.1420.1360.1380.140设测定数据分别来自分布N(μ1,σ2),N(μ2,σ2), 且两样本相互独立,又μ1,μ2,σ2均为未知,试求μ1-μ2的置信水平为0.95的置信区间.解答:对于1-α=0.95, 查表得t0.025(7)=2.3646, 算得xˉ=0.141,yˉ=0.139; s12=8.25×10-6, s1≈0.0029.s22=5.2×10-6, s2=0.0023, sW≈0.0026, 15+14=0.6708,故得μ1-μ2的0.95置信区间为(0.141-0.139±2.3646×0.0026×0.6708),即(-0.002,0.006).习题10设两位化验员A,B独立地对某种聚合物含氯量用相同的方法各作10次测定,其测定值的样本方差依次为 sA2=0.5419,sB2=0.6065. 设σA2,σB2分别为A,B所测定的测定值的总体方差,又设总体均为正态的,两样本独立,求方差比σA2/σB2的置信水平为0.95的置信区间.解答:选用随机变量F=SA2σA2/SB2σB2~F(n1-1,n2-1),依题意,已知sA2=0.5419, sB2=0.6065, n1=n2=10.对于1-α=0.95, 查F分布表得F0.025(9,9)=1F0.025(9,9)=14.03, 于是得σA2σB2的0.95的置信区间为(sA2sB21Fα/2(9,9),sA2sB2Fα/2(9,9))≈(0.222,3.601).总习题解答习题1设总体X服从参数为λ(λ>0)的指数分布,X1,X2,?,Xn为一随机样本,令Y=min{X1,X2,?,Xn}, 问常数c为何值时,才能使cY是λ的无偏估计量.解答:关键是求出E(Y). 为此要求Y的密度fY(y).因Xi的密度函数为fX(x)={λe-λx,x>00,x<0;Xi的分布函数为FX(x)={1-e-λx,x>00,x≤0,于是FY(y)=1-[1-FX(y)]n={1-e-nλy,y>00,y≤0.两边对y求导得fY(y)=ddyFY(y)={nλe-nλy,y>00,y≤0,即Y服从参数为nλ的指数分布,故E(Y)=nλ.为使cY成为λ的无偏估计量,需且只需E(cY)=λ, 即cnλ=λ, 故c=1n.习题2设X1,X2,?,Xn是来自总体X的一个样本,已知E(X)=μ, D(X)=σ2.(1)确定常数c, 使c∑i=1n-1(Xi+1-Xi)2为σ2的无偏估计;(2)确定常数c, 使(Xˉ)2-cS2是μ2的无偏估计(Xˉ,S2分别是样本均值和样本方差).解答:(1)E(c∑i=1n-1(Xi+1-Xi)2)=c∑i=1n-1E(Xi+12-2XiXi+1+Xi2)=c∑i=1n-1{D(Xi+1)+[E(Xi+1)]2-2E(Xi)E(Xi+1)+D(Xi)+[E(Xi)+[E(Xi)]2}=c(n-1)(σ2+μ2-2μ2+σ2+μ2)=2(n-1)σ2c.令2(n-1)σ2c=σ2, 所以c=12(n-1).(2)E[(Xˉ)2-cS2]=E(Xˉ2)-cE(S2)=D(Xˉ)+[E(Xˉ)]2-cσ2=σ2n+μ2-cσ2.令σ2n+μ2-cσ2=μ2, 则得c=1n.习题3设X1,X2,X3,X4是来自均值为θ的指数分布总体的样本,其中θ未知. 设有估计量T1=16(X1+X2)+13(X3+X4),T2=X1+2X2+3X3+4X45,T3=X1+X2+X3+X44.(1)指出T1,T2,T3中哪几个是θ的无偏估计量;(2)在上述θ的无偏估计中指出一个较为有效的.解答:(1)θ=E(X),E(Xi)=E(X)=θ,D(X)=θ2=D(Xi),i=1,2,3,4.E(T1)=E(16(X1+X2)+13(X3+X4))=(26+23)θ=θ,E(T2)=15E(X1+2X2+3X3+4X4)=15(1+2+3+4)θ=2θ,E(T3)=14E(X1+X2+X3+X4)=θ,因此,T1,T3是θ的无偏估计量.(2)D(T1)=236θ2+29θ2=1036θ2, D(T3)=116?4θ2=14θ2=936θ2,所以D(T3)<D(T1), 作为θ的无偏估计量,T3更为有效.习题4设从均值为μ, 方差为σ2(σ>0)的总体中,分别抽取容量为n1,n2的两独立样本,X1ˉ和X2ˉ分别是两样本的均值,试证:对于任意常数a,b(a+b=1),Y=aX1ˉ+bX2ˉ都是μ的无偏估计;并确定常数a,b, 使D(Y)达到最小.解答:E(Y)=E(aX1ˉ+bX2ˉ)=aE(X1ˉ)+bE(X2ˉ)=(a+b)μ.因为a+b=1, 所以E(Y)=μ.因此,对于常数a,b(a+b=1),Y都是μ的无偏估计,D(Y)=a2D(X1ˉ)+b2D(X2ˉ)=a2σ2n1+b2σ2n2.因a+b=1, 所以D(Y)=σ2[a2n1+1n2(1-a)2], 令dD(Y)da=0, 即2σ2(an1-1-an2)=0, 解得a=n1n1+n2,b=n2n1+n2是惟一驻点.又因为d2D(Y)da2=2σ2(1n1+1n2)>0, 故取此a,b二值时,D(Y)达到最小.习题5设有一批产品,为估计其废品率p, 随机取一样本X1,X2,?,Xn, 其中Xi={1,取得废品0,取得合格品, i=1,2,?,n,证明:p=Xˉ=1n∑i=1nXi是p的一致无偏估计量.解答:由题设条件E(Xi)=p?1+(1-p)?0=p,D(Xi)=E(Xi2)-[E(Xi)]2=p?12+(1-p)02-p2=p(1-p),E(p)=E(Xˉ)=E(1n∑i=1nE(Xi))=1n∑i=1nE(Xi)=1n∑i=1np=p.由定义,p是p的无偏估计量,又D(p)=D(Xˉ)=D(1n∑i=1nXi)=1n2∑i=1nD(Xi)=1n2∑i=1np(1-p)=1n2np(1-p)=pqn.由切比雪夫不等式,任给?>0P{∣p-p∣≥?}=P{∣Xˉ-p∣≥?}≤1?2D(Xˉ)=1?2p(1-p)n→0,n→∞所以limn→∞P{∣p-p∣≥?}=0, 故p=Xˉ是废品率p的一致无偏估计量.习题6设总体X~b(k,p), k是正整数,0<p<1,k,p都未知,X1,X2,?,Xn是一样本,试求k和p的矩估计.解答:因总体X服从二项分布b(k,p), 故{a1=E(X)=kpa2=E(X2)=D(X)+[E(X)]2=kp(1-p)+(kp)2,解此方程组得p=a1+a12-a2a1,k=a12a1+a12-a2.用A1=1n∑i=1nXi=Xˉ,A2=1n∑i=1nXi2分别代替a1,a2, 即得p,k的矩估计为p=Xˉ-S2Xˉ,k=[Xˉ2Xˉ-S2],其中S2=1n∑i=1n(Xi-Xˉ)2,[x]表示x的最大整数部分.习题7求泊松分布中参数λ的最大似然估计.解答:总体的概率函数为P{X=k}=λkk!e-λ,k=0,1,2,?.设x1,x2,?,xn为从总体中抽取的容量为n的样本,则似然函数为L(x1,x2,?,xn;λ)=∏i=1nf(xi;λ)=∏i=1nλxixi!e-λ=λ∑i=1nxi∏i=1nxi!e-nλ,lnL=(∑i=1nxi)lnλ-nλ-∑i=1nlnxi!,令dlnLdλ=1λ∑i=1nxi-n=0, 得λ的最大是然估计为λ=1n∑i=1nxi=xˉ,即xˉ=1n∑i=1nxi就是参数λ的最大似然估计.习题8已知总体X的概率分布P{X=k}=C2k(1-θ)kθ2-k,k=0,1,2,求参数的矩估计.解答:总体X为离散型分布,且只含一个未知参数θ, 因此,只要先求离散型随机变量的数学期望E(X), 然后解出θ并用样本均值Xˉ代替E(X)即可得θ的矩估计θ.由E(X)=∑k=02kC2k(1-θ)kθ2-k=1×2(1-θ)θ+2(1-θ)2=2-2θ, 即有θ=1-E(X)2.用样本均值Xˉ代替上式的E(X), 得矩估计为θ=1-Xˉ2.习题9设总体X的概率密度为f(x)={(θ+1)xθ,0<x<10,其它,其中θ>-1是未知参数,X1,X2,?,Xn为一个样本,试求参数θ的矩估计和最大似然估计量. 解答:因E(X)=∫01(θ+1)xθ+1dx=θ+1θ+2. 令E(X)=1n∑i=1nXi=Xˉ, 得θ+1θ+2=Xˉ, 解得θ的矩估计量为θ=2Xˉ-11-Xˉ.设x1,x2,?,xn是样本X1,X2,?,Xn的观察值,则似然函数L(x1,x2,?,xn,θ)=∏i=1n(θ+1)xiθ=(θ+1)n(x1x2?xn)θ(0<xi<1,i=1,2,?,n),取对数得lnL=nln(θ+1)+θ∑i=1nlnxi, 从而得对数似然方程dlnLdθ=nθ+1+∑i=1nlnxi=0,解出θ, 得θ的最大似然估计量为θ=-n∑i=1nlnXi.由此可知,θ的矩估计和最大似然估计是不相同的.习题10设X具有分布密度f(x,θ)={θxe-θx!,x=0,1,2,?0,其它,0<θ<+∞,X1,X2,?,Xn是X的一个样本,求θ的最大似然估计量.解答:似然函数L(θ)=∏i=1nθxie-θxi!=e-nθ∏i=1nθxixi!,lnL(θ)=-nθ+∑i=1nxilnθ-∑i=1nln(xi!),ddθ(lnL(θ))=-n+1θ∑i=1nxi,令ddθ(lnL(θ))=0, 即-n+1θ∑i=1nxi=0?θ=1n∑i=1nxi,故θ最大似然估计量为θ=Xˉ=1n∑i=1nXi.习题11设使用了某种仪器对同一量进行了12次独立的测量,其数据(单位:毫米)如下:232.50 232.48 232.15 232.53 232.45 232.30232.48 232.05 232.45 232.60 232.47 232.30试用矩估计法估计测量值的均值与方差(设仪器无系统误差).解答:设测量值的均值与方差分别为μ与σ2,因为仪器无系统误差,所以θ=μ=Xˉ=1n∑i=1nXi=232+112∑i=1n(Xi-232)=232+1/12×4.76≈232.3967.用样本二阶中心矩B2估计方差σ2, 有σ2=1n∑i=1n(Xi-Xˉ)2=1n∑i=1n(Xi-a)2-(Xˉ-a)2=112∑i=112(Xi-232)2-(232.3967-232)2=0.1819-0.1574=0.0245.习题12设随机变量X服从二项分布P{X=k}=Cnkpk(1-p)n-k,k=0,1,2,?,n,X1为其一个样本,试求p2的无偏估计量.解答:\becauseX~b(n,p),∴E(X)=np, D(X)=np(1-p)=E(X)-np2?p2=1n[E(X)-D(X)]=1n[E(X)-E(X2)+(EX)2]?p2=1n[E(X(1-X))]+1nn2p2=1nE(X(1-X))]+np2?p2=E[X(X-1)]n(n-1), 由于E[X(X-1)]=E[X1(X1-1)],故p2=X1(X1-1)n(n-1).习题13设X1,X2,?,Xn是来自总体X的随机样本,试证估计量Xˉ=1n∑i=1nXi和Y=∑i=1nCiXi(Ci≥0为常数,∑i=1nCi=1)都是总体期望E(X)的无偏估计,但Xˉ比Y有效.解答:依题设可得E(Xˉ)=1n∑i=1nE(Xi)=1n×nE(X)=E(X),E(Y)=∑i=1nCiE(Xi)=E(X)∑i=1nCi=E(X).从而Xˉ,Y均为E(X)的无偏估计量,由于D(Xˉ)=1n2∑i=1nD(Xi)=1nD(X),D(Y)=D(∑i=1nCiXi)=∑i=1nCi2D(Xi)=D(X)∑i=1nCi2.应用柯西—施瓦茨不等式可知1=(∑i=1nCi)2≤(∑i=1nCi2)(∑i=1n12)=n∑i=1nCi2, ?1n≤∑i=1nCi2,所以D(Y)≥D(Xˉ), 故Xˉ比Y有效.习题14设X1,X2,?,Xn是总体X~U(0,θ)的一个样本,证明:θ1=2Xˉ和θ2=n+1nX(n)是θ的一致估计.解答:因E(θ1)=θ, D(θ1)=θ23n; E(θ2)=θ,D(θ2)=θn(n+2),X(n)=max{Xi}.依切比雪夫不等式,对任给的?>0, 当n→∞时,有P{∣θ1-θ∣≥?}≤D(θ1)?2=θ23n?2→0,(n→∞)P{∣θ2-θ∣≥?}≤D(θ2)?2=θ2n(n+1)?2→0,(n→∞)所以,θ1和θ2都是θ的一致估计量.习题15某面粉厂接到许多顾客的订货,厂内采用自动流水线灌装面粉,按每袋25千克出售. 现从中随机地抽取50袋,其结果如下:25.8, 24.7, 25.0, 24.9, 25.1, 25.0, 25.2,24.8, 25.4, 25.3, 23.1, 25.4, 24.9, 25.0,24.6, 25.0, 25.1, 25.3, 24.9, 24.8, 24.6,21.1, 25.4, 24.9, 24.8, 25.3, 25.0, 25.1,24.7, 25.0, 24.7, 25.3, 25.2, 24.8, 25.1,25.1, 24.7, 25.0, 25.3, 24.9, 25.0, 25.3,25.0, 25.1, 24.7, 25.3, 25.1, 24.9, 25.2,25.1,试求该厂自动流水线灌装袋重总体X的期望的点估计值和期望的置信区间(置信度为0.95).解答:设X为袋重总体,则E(X)的点估计为E(X)=Xˉ=150(25.8+24.7+?+25.1)=24.92kg.因为样本容量n=50, 可作为大样本处理,由样本值算得xˉ=24.92, s2≈0.4376, s=0.6615, 则E(X)的置信度为0.95的置信区间近似为(Xˉ-uα/2Sn,Xˉ+uα/2Sn),查标准正态分布表得uα/2=u0.025=1.96, 故所求之置信区间为(24.92- 1.96×0.661550,24.92+1.96×0.661550)=(24.737,25.103),即有95%的把握,保证该厂生产的面粉平均每袋重量在24.737千克至25.103千克之间. 习题16在一批货物的容量为100的样本中,经检验发现有16只次品,试求这批货物次品率的置信度为0.95的置信区间.解答:这是(0-1)分布参数区间的估计问题.这批货物次品率p的1-α的置信区间为(p1,p2)=(12a(-b-b2-4ac),12a(-b+b2-4ac)).其中a=n+uα/22,b=-(2nXˉ+uα/22), c=nXˉ2.由题意,xˉ=16100=0.16,n=100,1-α=0.95,u0.025=1.96. 算得a=100+1.962=103.842,b=-(2×100×0.16+1.962)=-35.842,c=100×0.162=2.56.p的0.95的置信区间为(p1,p2)=(12a(-b±b2-4ac)), 即(12×103.842(35.8416±221.2823)),亦即(0.101,0.244).习题17在某校的一个班体检记录中,随意抄录25名男生的身高数据,测得平均身高为170厘米,标准差为12厘米,试求该班男生的平均身高μ和身高的标准差σ的置信度为0.95的置信区间(假设测身高近似服从正态分布).解答:由题设身高X~N(μ,σ2), n=25, xˉ=170, s=12,α=0.05.(1)先求μ置信区间(σ2未知),取U=Xˉ-μS/n~t(n-1),tα/2(n-1)=t0.025(24)=2.06.故μ的0.95的置信区间为(170-1225×2.06,170+1225×2.06)=(170-4.94,170+4.94)=(165.06,174,94).(2)σ2的置信区间(μ未知),取U=(n-1)S2σ2~χ2(n-1),χα/22(n-1)=χ0.0252(24)=39.364, χ1-α/22(n-1)=χ0.9752(24)=12.401,故σ2的0.95的置信区间为(24×12239.364,24×12212.401)≈(87.80,278.69), σ的0.95的置信区间为(87.80,278.69)≈(9.34,16.69).习题18为研究某种汽车轮胎的磨损特性,随机地选择16只轮胎,每只轮胎行驶到磨坏为止. 记录所行驶的路程(以千米计)如下:41250 40187 43175 41010 39265 41872 42654 4128738970 40200 42550 41095 40680 43500 39775 40440假设这些数据来自正态总体N(μ,σ2). 其中μ,σ2未知,试求μ的置信水平为0.95的单侧置信下限.解答:由P{μ>Xˉ-Sntα(n-1)=1-α, 得μ的1-α的单侧置信下限为μˉ=Xˉ-Sntα(n-1).由所给数据算得xˉ≈41119.38,s≈1345.46,n=16.查t分布表得t0.05(15)=1.7531, 则有μ的0.95的单侧置信下限为μˉ=41119.38-1345.464×1.7531≈40529.73.习题19某车间生产钢丝,设钢丝折断力服从正态分布,现随机在抽取10根,检查折断力,得数据如下(单位:N):578,572,570,568,572,570,570,572,596,584.试求钢丝折断力方差的置信区间和置信上限(置信度为0.95).解答:(1)这是一个正态总体,期望未知,对方差作双侧置信限的估计问题,应选统计量χ2=(n-1)S2σ2~χ2(n-1).σ2的1-α的置信区间是((n-1)S2χα/22(n-1),(n-1)S2χ1-α/22(n-1)).由所给样本值得xˉ=575.2, (n-1)s2=∑1=110(xi-xˉ)2=681.6;根据给定的置信度1-α=0.95(即α=0.05).查自由度为10-1=9的χ2分布表,得双侧临界值χα/22(n-1)=χ0.0252(9)=19.0, χ1-α/22(n-1)=χ0.9752(9)=2.7,代入上公式得σ2的95%的置信区间为(681.619.0,681,62.70)=(35.87,232.44),即区间(35.87,232.44)包含σ2的可靠程度为0.95.(2)这是一个正态总体期望未知时,σ2的单侧区间估计问题,σ2的置信度为1-α=95%(α=0.05)的单侧置信上限为(n-1)S2χ1-α2(n-1)=∑i=110(xi-xˉ)2χ1-α2(n-1),已算得(n-1)S2=∑i=110(xi-xˉ)2=681.6, 根据自由度1-α=0.95.查自由度10-1=9的χ2分布表得单侧临界值χ1-α2(n-1)=χ0.952(9)=3.325,代入上式便得σ2的0.95的置信上限为681.63.325=205, 即有95%的把握,保证σ2包含在区间(0,205)之内,当然也可能碰上σ2超过上限值205的情形,但出现这种情况的可能性很小,不超过5%.习题20设某批铝材料比重X服从正态分布N(μ,σ2),现测量它的比重16次,算得xˉ=2.705,s=0.029,分别求μ和σ2的置信度为0.95的置信区间。
《市场调查与预测》第四版(6-13章)习题参考答案

《市场调查与预测》第四版(6-13章)习题参考答案第6章实地调查1.什么是观察法?它有何优缺点?举例说明观察法在市场调查中的具体应用。
观察法是指市场调查者深入调查现场,以旁观者的身份对具体事件、人物、行为模式等特征、演变过程进行记录来收集有关信息资料的方法。
优点:被调查者的活动可以不受外在因素的影响,处于自然的活动状态;被调查者不愿意用语言表达的情感或实际感觉,也可以通过观察其实际行为而获得,因而取得的资料会更加真实地反映实际情况。
缺点:作为现场观察来说,记录往往只限于表面的东西,难以了解调查者内在的思想行为,如人们的动机、态度等是无法通过观察获悉的。
而且,在有些情况下,如果被调查者意识到自己被调查的时候,可能会出现不正常的表现,从而导致结果失真;在对一些不常发生的行为或持续时间较长的事物观察时,花费时间较长,成本很高。
另外,由于调查者是身临其境观察,这就要求观察人员有良好的记忆、判断能力和敏锐的观察力,同时应具备丰富的经验,把握观察法的要领。
详细例子参考案例6-1。
2.什么是小组访谈法?小组访谈策划的基本环节有哪些?小组访谈法,又称焦点小组座谈会、焦点访谈法,具体做法是选取一组具有代表性的消费者和客户,在一个装有单向镜或录音录像设备的房间里,在主持人的组织下,就某个专题进行深入讨论。
小组访谈策划的基本环节有:(1)确定访谈主题,设计详细的访谈提纲。
(2)甄选访谈主持人。
(3)甄选小组参加人员。
(4)确定小组组数。
(5)确定访谈的场所和时间。
(6)准备好所需的物品。
3.询问法有几种形式?各种形式有何优缺点?(1)人员访谈法优点:具有直接和灵活的特点,能够根据被调查者的具体情况进行深入的询问,从而获得较多的第一手资料。
人员访问法可以使调查者对被调查者进行直接观察,有利于判断被调查者回答问题的实事求是的程度,以及问题回答的可靠程度。
另外,通过面谈调查了解的问题回收率高,有助于提高调查结果的可信水平。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
第六章练习题及参考解答表是中国1985-2016年货物进出口贸易总额()与国内生产总值()的数据。
表中国进出口贸易总额和国内生产总值单位:亿元年份货物进出口贸易总额(Y)国内生产总值(X)年份货物进出口贸易总额(Y)国内生产总值(X)198 5200 1198 6200 2198 7200 3198 8200 4198 9200 5199 0200 6199 1200 7199 2200 8199 3200 9199 4201 0199 5201 1199 6201 2199 7 199 8 199 9 200 0201 3 201 4 201 5 201 6资料来源:《中国统计年鉴2017》(1)建立货物进出口贸易总额的对数对国内生产总值的对数的回归方程;(2)检测模型的自相关性;(3)采用广义差分法处理模型中的自相关问题。
【练习题参考解答】回归结果自相关检验①图示法图1、2 与的散点图以及模型残差图由上面两个图可以发现模型残差存在惯性表现,很可能存在正自相关。
②DW检验由回归结果可知DW统计量为,同时,在的显著性水平下,,因而模型中存在正相关。
③BG检验阶数5432AICSIC滞后阶数从5阶减小到2阶,AIC及SIC达到最小时,滞后阶数为2阶,此时,已知,,同时P值为,在的显著性水平下拒绝原假设,即存在自相关。
表2 BG检验2阶回归结果自相关补救①DW反算法求由,可知,可得广义差分方程:表3 广义差分结果-DW反算法DW检验:由回归结果可知DW统计量为,同时,在的显著性水平下,,即已消除自相关。
BG检验:阶数5432AICSIC滞后阶数从5阶减小到2阶,AIC及SIC达到最小时,滞后阶数为2阶,此时,已知,,同时P值为,在的显著性水平下不拒绝原假设,即已消除自相关。
表4 广义差分BG检验2阶回归结果则可知,最终模型为:②残差过原点回归求Dependent Variable: EMethod: Least SquaresDate: 02/07/18 Time: 20:48Sample (adjusted): 1986 2016Included observations: 31 after adjustmentsVariable CoefficientStd.Errort-StatisticProb.E(-1)R-squaredMean dependent varAdjusted R-squared. dependent var. of regressionAkaike info criterionSum squared residSchwarz criterionLog likelihoodHannan-Quinn criter.Durbin-Watsonstat表5 残差序列过原点回归结果回归结果为:,可知。
进而得广义差分方程:lnDependent Variable: *LNY(-1)Method: Least SquaresDate: 02/07/18 Time: 20:51Sample (adjusted): 1986 2016Included observations: 31 after adjustmentsVariable CoefficientStd.Errort-StatisticProb.C*LNX(-1)R-squaredMean dependent varAdjusted R-squared. dependent var. of regressionAkaike info criterionSum squared residSchwarz criterionLog likelihoodHannan-Quinn criter.F-statisticDurbin-Watson statProb(F-statistic)表6 广义差分-残差序列过原点回归结果DW检验:由回归结果可知DW统计量为,同时,在的显著性水平下,,因而模型已不存在自相关。
BG检验:阶数5432AICSIC滞后阶数从5阶减小到2阶,AIC及SIC达到最小时,滞后阶数为2阶,此时,已知,,同时P值为,在的显著性水平下不拒绝原假设,即已消除自相关。
Breusch-Godfrey Serial Correlation LM Test:F-statistic Prob. F(2,27)Obs*R-squaredProb. Chi-Square(2)Test Equation:Dependent Variable: RESIDMethod: Least SquaresDate: 02/07/18 Time: 21:30Sample: 1986 2016Included observations: 31Presample missing value lagged residuals set to zero.Variable CoefficientStd.Errort-StatisticProb.C*LNX(-1) RESID(-1) RESID(-2)R-squaredMean dependent varAdjusted R-squared. dependent var. of regressionAkaike info criterionSum squared residSchwarz criterionLog likelihoodHannan-Quinn criter.F-statisticDurbin-Watson statProb(F-statistic)广义差分BG检验2阶回归结果则可知,最终模型为:③德宾两步法求构建模型Dependent Variable: LNYMethod: Least SquaresDate: 02/07/18 Time: 21:43Sample (adjusted): 1986 2016Included observations: 31 after adjustmentsVariable CoefficientStd.Errort-StatisticProb.CLNX LNX(-1) LNY(-1)R-squaredMean dependent varAdjusted R-squared. dependent var. of regressionAkaike info criterionSum squared residSchwarz criterionLog likelihoodHannan-Quinn criter.F-statisticDurbin-Watson statProb(F-statistic)德宾两步法回归结果由此可知,,进而得广义差分方程:lnDependent Variable: *LNY(-1)Method: Least SquaresDate: 02/07/18 Time: 22:03Sample (adjusted): 1986 2016Included observations: 31 after adjustmentsVariable CoefficientStd.Errort-StatisticProb.C*LNX(-1)R-squaredMean dependent varAdjusted R-squared. dependent var. of regressionAkaike info criterionSum squared residSchwarz criterionLog likelihoodHannan-Quinn criter.F-statisticDurbin-Watson statProb(F-statistic)广义差分-德宾两步法回归结果DW检验:由回归结果可知DW统计量为,同时,在的显著性水平下,,因而模型已不存在自相关。
BG检验:阶数5432AICSIC滞后阶数从5阶减小到2阶,AIC及SIC达到最小时,滞后阶数为2阶,此时,已知,,同时P值为,在的显著性水平下不拒绝原假设,即已消除自相关。
Breusch-Godfrey Serial Correlation LM Test:F-statistic Prob. F(2,27)Obs*R-squaredProb. Chi-Square(2)Test Equation:Dependent Variable: RESIDMethod: Least SquaresDate: 02/07/18 Time: 22:16Sample: 1986 2016Included observations: 31Presample missing value lagged residuals set to zero.Variable CoefficientStd.Errort-StatisticProb.C*LNX(-1) RESID(-1) RESID(-2)R-squaredMean dependent varAdjusted R-squared. dependent var. of regressionAkaike info criterionSum squared residSchwarz criterionLog likelihoodHannan-Quinn criter.F-statisticDurbin-Watson statProb(F-statistic)广义差分BG检验2阶回归结果则可知,最终模型为:④科克兰·奥科特迭代法Dependent Variable: LNYMethod: Least SquaresDate: 02/07/18 Time: 22:38Sample (adjusted): 1986 2016Included observations: 31 after adjustmentsConvergence achieved after 16 iterationsVariable CoefficientStd.Errort-StatisticProb.C LNX AR(1)R-squaredMean dependent varAdjusted R-squared. dependent var. of regressionAkaike info criterionSum squared residSchwarz criterionLog likelihood Hannan-Quinncriter.F-statisticDurbin-Watson statProb(F-statistic)Inverted AR Roots.88科克兰·奥科特迭代法回归结果DW检验:由回归结果可知DW统计量为,同时,在的显著性水平下,,因而模型已不存在自相关。