16_尚硅谷大数据之MapReduce_Hadoop序列化
Hadoop数据分析与应用 MapReduce(一)

技术讲解
实践练习
实践时间: 25 分钟
1. 使用 Hadoop 内置 jar 文件进行单词计数统计
3.1.1 MapReduce 的概念
MapReduce 是一种编程模型,用于大规模数据集(大于 1TB)的并行运算。 概念 Map(映射)和 Reduce(归约)是它们的主要思想,都是从函数式和矢量
3.1.4 MapReduce 执行流程
MapReduce 执行流程是先执行 Map 后执行 Reduce 的过程
3.1.4 MapReduce 执行流程
Map 任务处理
读取 HDFS 中的文件,每一行解析成一个 <k,v>,每一个键值对调用一次 map() 方法 覆盖 map() 方法,接收上一步产生的 <k,v> 进行处理,转换为新的 <k,v> 输出 对上一步输出的 <k,v> 进行分区,并默认分为一个区 对不同分区中的数据按照 k 进行排序和分组。分组指的是相同 key 的 value 放到一个集合中 对分组后的数据进行归约(可选)
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { Configuration conf = new Configuration(); Job job = Job.getInstance(conf); job.setJarByClass(MapReduceDemo.class); job.setMapperClass(WCMap.class); job.setReducerClass(WCReduce.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(LongWritable.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(LongWritable.class); Path inputPath = new Path("/data"); Path outputPath = new Path("/output"); FileInputFormat.setInputPaths(job, inputPath); FileOutputFormat.setOutputPath(job, outputPath); boolean waitForCompletion = job.waitForCompletion(true); System.exit(waitForCompletion?0:1);
大数据培训之 hadoop序列化详解(最新版)

北京尚学堂提供初学java的人肯定对java序列化记忆犹新。
最开始很多人并不会一下子理解序列化的意义所在。
这样子是因为很多人还是对java最底层的特性不是特别理解,当你经验丰富,对java 理解更加深刻之后,你就会发现序列化这种东西的精髓。
谈hadoop序列化之前,我们再来回顾一下java的序列化,也是最底层的序列化:在面向对象程序设计中,类是个很重要的概念。
所谓“类”,可以将它想像成建筑图纸,而对象就是根据图纸盖的大楼。
类,规定了对象的一切。
根据建筑图纸造房子,盖出来的就是大楼,等同于将类进行实例化,得到的就是对象。
一开始,在源代码里,类的定义是明确的,但对象的行为有些地方是明确的,有些地方是不明确的。
对象里不明确地方,是因为对象在运行的时候,需要处理无法预测的事情,诸如用户点了下屏幕,用户点了下按钮,输入点东西,或者需要从网络发送接收数据之类的。
后来,引入了泛型的概念之后,类也开始不明确了,如果使用了泛型,直到程序运行的时候,才知道究竟是哪种对象需要处理。
对象可以很复杂,也可以跟时序相关。
一般来说,“活的”对象只生存在内存里,关机断电就没有了。
一般来说,“活的”对象只能由本地的进程使用,不能被发送到网络上的另外一台计算机。
想象一下,对象怎么出现的,一般是new出来的,new出来的对象在内存里面,另外的计算机怎么可能使用我这台机器上的对象呢?如果要的话,序列化就是你必须要使用的东西。
序列化,可以存储“活的”对象,可以将“活的”对象发送到远程计算机。
把“活的”对象序列化,就是把“活的”对象转化成一串字节,而“反序列化”,就是从一串字节里解析出“活的”对象。
于是,如果想把“活的”对象存储到文件,存储这串字节即可,如果想把“活的”对象发送到远程主机,发送这串字节即可,需要对象的时候,做一下反序列化,就能将对象“复活”了。
有例子为证:393 44 45 46 47 48}public void setAge(Integer age) {this.age = age;}public Gender getGender() {return gender;}public void setGender(Gender gender) {this.gender = gender;}@Overridepublic String toString() {return "[" + name + ", " + age + ", " + g ender + "]";}将对象序列化存储到文件,术语又叫“持久化”。
Hadoop文件的序列化

Hadoop⽂件的序列化1. 为什么要序列化 如图,⼀个活着的对象只存在于内存中,⼀旦断电就会消失。
并且,在正常情况下,⼀个或者的对象⽆法直接通过⽹络发送到其他(远程)机器上。
⽽序列化可以克服上述问题,它能存储对象,并完成其⽹络传输的任务。
2. 什么是序列化 序列化是将对象转化为字节流的⽅法,或者说⽤字节流描述对象的⽅法。
与序列化相对的是反序列化,即将字节流转化为对象的⽅法。
序列化由两个⽬的: 1)进程间通信; 2)数据持久性存储。
3. 为什么不⽤Java的序列化机制 Java的序列化机制存在开销⼤、体积⼤和和它的引⽤机制所导致的⼤⽂件不能分割的缺点。
因此,Java的序列机制不适合Hadoop,Hadoop设计了⾃⼰的序列化机制。
4. Hadoop序列化机制的特点 Hadoop采⽤RPC来实现进程间通信,RPC的序列化机制具有以下特点: 1)紧凑:紧凑的格式可以充分利⽤带宽,加快传输速度; 2)快速:能减少序列化和反序列化的开销,这会有效地较少进程间通信的时间; 3)可扩展:可以逐步改变,是客户端与服务器直接相关的,可以随时加⼊⼀个新的参数⽅法调⽤; 4)互操作性:⽀持不同语⾔编写的客户端与服务器交换数据。
5. Hadoop序列化接⼝ Hadoop的序列化机制定义了两个接⼝:Writable接⼝和Comparable接⼝,它们可以合并为WritableComparable接⼝。
5.1 Writable类 Writable是Hadoop的核⼼,Hadoop通过它定义了Hadoop中基本的数据类型及其操作。
Writable类定义了两个⽅法:package org.apache.hadoop.io;import java.io.DataOutput;import java.io.DataInput;import java.io.IOException;public interface Writable {/*** 将对象转换为字节流并写⼊到输出流out中*/void write(DataOutput out) throws IOException;/*** 从输⼊流in中读取字节流反序列化为对象*/void readFields(DataInput in) throws IOException;} 5.2 Comparable类 所有实现了Comparable的对象都可以和⾃⾝相同类型的对象⽐较⼤⼩。
简述mapreduce数据处理流程

简述mapreduce数据处理流程MapReduce是一种用于大规模数据处理的编程模型,它由Google 首次提出,并且在开源项目Apache Hadoop中得到了广泛应用。
它的核心思想是将数据处理任务分为两个阶段:Map阶段和Reduce阶段。
下面将简述MapReduce的数据处理流程,并对其进行拓展。
1. 输入数据切片:在MapReduce任务开始之前,输入数据会被分割成多个小的数据块,每个数据块称为一个输入数据切片。
这样做的目的是为了能够并行地处理这些数据块,提高处理效率。
2. Map阶段:在Map阶段,每个输入数据切片会被传递给一个Map任务进行处理。
每个Map任务都会执行用户自定义的Map函数,该函数将输入数据切片转化为<key, value>对的集合。
Map函数可以根据具体需求进行数据筛选、转换、过滤等操作,并将处理结果输出为<key, value>对。
3. Shuffle阶段:在Map阶段结束后,Map任务的输出结果会通过网络传输到Reduce任务所在的节点。
这个过程称为Shuffle,其目的是将具有相同key的<key, value>对传递给同一个Reduce任务进行处理。
4. Sort阶段:在Shuffle阶段结束后,Map任务的输出结果会按照key值进行排序。
这样做的目的是为了方便Reduce任务进行后续的处理操作。
5. Reduce阶段:在Reduce阶段,每个Reduce任务会执行用户自定义的Reduce函数,该函数将具有相同key的<key, value>对进行合并、计算、汇总等操作,并将处理结果输出为最终的结果。
6. 输出结果:最后,所有Reduce任务的输出结果会被整合成一个最终的结果,并存储到指定的位置,供后续的分析和使用。
除了上述的基本流程,MapReduce还具有一些拓展的功能和特性,例如:- Combiner函数:在Map阶段的输出结果传递给Reduce阶段之前,可以使用Combiner函数进行局部汇总操作,以减少数据传输量和提高处理效率。
尚硅谷大数据技术之 Hadoop(生产调优手册)说明书

尚硅谷大数据技术之Hadoop(生产调优手册)(作者:尚硅谷大数据研发部)版本:V3.3第1章HDFS—核心参数1.1 NameNode内存生产配置1)NameNode内存计算每个文件块大概占用150byte,一台服务器128G内存为例,能存储多少文件块呢?128 * 1024 * 1024 * 1024 / 150Byte ≈9.1亿G MB KB Byte2)Hadoop2.x系列,配置NameNode内存NameNode内存默认2000m,如果服务器内存4G,NameNode内存可以配置3g。
在hadoop-env.sh文件中配置如下。
HADOOP_NAMENODE_OPTS=-Xmx3072m3)Hadoop3.x系列,配置NameNode内存(1)hadoop-env.sh中描述Hadoop的内存是动态分配的# The maximum amount of heap to use (Java -Xmx). If no unit # is provided, it will be converted to MB. Daemons will# prefer any Xmx setting in their respective _OPT variable.# There is no default; the JVM will autoscale based upon machine # memory size.# export HADOOP_HEAPSIZE_MAX=# The minimum amount of heap to use (Java -Xms). If no unit # is provided, it will be converted to MB. Daemons will# prefer any Xms setting in their respective _OPT variable.# There is no default; the JVM will autoscale based upon machine # memory size.# export HADOOP_HEAPSIZE_MIN=HADOOP_NAMENODE_OPTS=-Xmx102400m(2)查看NameNode占用内存[atguigu@hadoop102 ~]$ jps3088 NodeManager2611 NameNode3271 JobHistoryServer2744 DataNode3579 Jps[atguigu@hadoop102 ~]$ jmap -heap 2611Heap Configuration:MaxHeapSize = 1031798784 (984.0MB)(3)查看DataNode占用内存[atguigu@hadoop102 ~]$ jmap -heap 2744Heap Configuration:MaxHeapSize = 1031798784 (984.0MB)查看发现hadoop102上的NameNode和DataNode占用内存都是自动分配的,且相等。
Hadoop MapReduce简介

Hadoop MapReduce简介本节首先简单介绍大数据批处理概念,然后介绍典型的批处理模式MapReduce,最后对Map 函数和Reduce 函数进行描述。
批处理模式批处理模式是一种最早进行大规模数据处理的模式。
批处理主要操作大规模静态数据集,并在整体数据处理完毕后返回结果。
批处理非常适合需要访问整个数据集合才能完成的计算工作。
例如,在计算总数和平均数时,必须将数据集作为一个整体加以处理,而不能将其视作多条记录的集合。
这些操作要求在计算进行过程中数据维持自己的状态。
需要处理大量数据的任务通常最适合用批处理模式进行处理,批处理系统在设计过程中就充分考虑了数据的量,可提供充足的处理资源。
由于批处理在应对大量持久数据方面的表现极为出色,因此经常被用于对历史数据进行分析。
为了提高处理效率,对大规模数据集进行批处理需要借助分布式并行程序。
传统的程序基本是以单指令、单数据流的方式按顺序执行的。
这种程序开发起来比较简单,符合人们的思维习惯,但是性能会受到单台计算机的性能的限制,很难在给定的时间内完成任务。
而分布式并行程序运行在大量计算机组成的集群上,可以同时利用多台计算机并发完成同一个数据处理任务,提高了处理效率,同时,可以通过增加新的计算机扩充集群的计算能力。
Google 最先实现了分布式并行处理模式MapReduce,并于2004 年以论文的方式对外公布了其工作原理,Hadoop MapReduce 是它的开源实现。
Hadoop MapReduce 运行在HDFS 上。
MapReduce 简释如图1 所示,如果我们想知道相当厚的一摞牌中有多少张红桃,最直观的方式就是一张张检查这些牌,并且数出有多少张是红桃。
这种方法的缺陷是速度太慢,特别是在牌的数量特别高的情况下,获取结果的时间会很长。
图1 找出有多少张红桃MapReduce 方法的规则如下。
∙把这摞牌分配给在座的所有玩家。
∙让每个玩家数自己手中的牌中有几张是红桃,然后把这个数目汇报上来。
18_尚硅谷大数据之MapReduce_Hadoop数据压缩
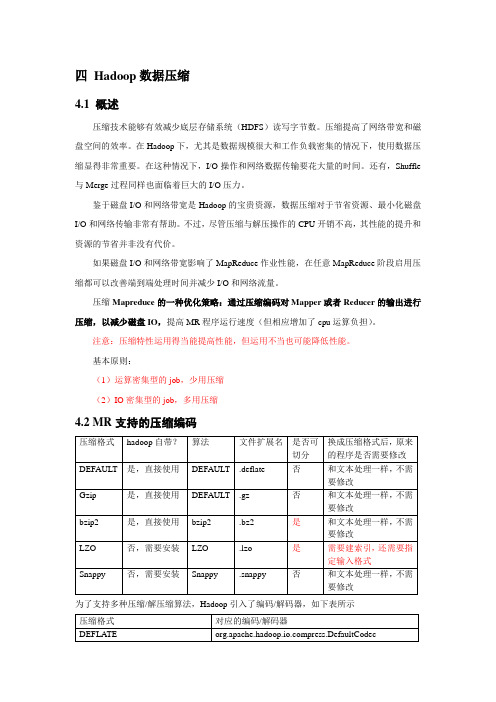
优点:支持 split;具有很高的压缩率,比 gzip 压缩率都高;hadoop 本身支持,但不支 持 native;在 linux 系统下自带 bzip2 命令,使用方便。
缺点:压缩/解压速度慢;不支持 native。 应用场景:适合对速度要求不高,但需要较高的压缩率的时候,可以作为 mapreduce 作 业的输出格式;或者输出之后的数据比较大,处理之后的数据需要压缩存档减少磁盘空间并 且以后数据用得比较少的情况;或者对单个很大的文本文件想压缩减少存储空间,同时又需 要支持 split,而且兼容之前的应用程序(即应用程序不需要修改)的情况。
注:LZO是供HMdoop压缩数 据用的通用压缩编解码器。 其设计目标是达到与硬盘读 取速度相当的压缩速度,因 此速度是优先考虑的因素, 而不是压缩率。与gzip编解码 器相比,它的压缩速度是gzip 的5倍,而解压速度是gzip的2 倍。同一个文件用LZO压缩 后比用gzip压缩后大50%,但 比压缩前小25%~50%。这对 改善性能非常有利,mMp阶段 完成时间快4倍。
而来的数据进行解 压缩,则调用 createInputStream(InputStreamin)函数, 从而获得一个
CompressionInputStream,从而ห้องสมุดไป่ตู้底层的流读取未压缩的数据。
测试一下如下压缩方式:
DEFLATE gzip bzip2
press.DefaultCodec press.GzipCodec press.BZip2Codec
4.2 MR 支持的压缩编码
压缩格式 DEFAULT Gzip bzip2 LZO Snappy
hadoop 自带? 是,直接使用 是,直接使用 是,直接使用 否,需要安装 否,需要安装
大数据之mapreduce理论

MapReduce理论篇2.1 Writable序列化序列化就是把内存中的对象,转换成字节序列(或其他数据传输协议)以便于存储(持久化)和网络传输。
反序列化就是将收到字节序列(或其他数据传输协议)或者是硬盘的持久化数据,转换成内存中的对象。
Java的序列化是一个重量级序列化框架(Serializable),一个对象被序列化后,会附带很多额外的信息(各种校验信息,header,继承体系等),不便于在网络中高效传输。
所以,hadoop自己开发了一套序列化机制(Writable),精简、高效。
2.1.1 常用数据序列化类型常用的数据类型对应的hadoop数据序列化类型2.1.2 自定义bean对象实现序列化接口1)自定义bean对象要想序列化传输,必须实现序列化接口,需要注意以下7项。
(1)必须实现Writable接口(2)反序列化时,需要反射调用空参构造函数,所以必须有空参构造(3)重写序列化方法(4)重写反序列化方法(5)注意反序列化的顺序和序列化的顺序完全一致(6)要想把结果显示在文件中,需要重写toString(),且用”\t”分开,方便后续用(7)如果需要将自定义的bean放在key中传输,则还需要实现comparable接口,因为mapreduce框中的shuffle过程一定会对key进行排序详见3.2.1统计每一个手机号耗费的总上行流量、下行流量、总流量(序列化)。
2.2 InputFormat数据切片机制2.2.1 FileInputFormat切片机制1)job提交流程源码详解waitForCompletion()submit();// 1建立连接connect();// 1)创建提交job的代理new Cluster(getConfiguration());// (1)判断是本地yarn还是远程initialize(jobTrackAddr, conf);// 2 提交jobsubmitter.submitJobInternal(Job.this, cluster)// 1)创建给集群提交数据的Stag路径Path jobStagingArea = JobSubmissionFiles.getStagingDir(cluster, conf);// 2)获取jobid ,并创建job路径JobID jobId = submitClient.getNewJobID();// 3)拷贝jar包到集群copyAndConfigureFiles(job, submitJobDir);rUploader.uploadFiles(job, jobSubmitDir);// 4)计算切片,生成切片规划文件writeSplits(job, submitJobDir);maps = writeNewSplits(job, jobSubmitDir);input.getSplits(job);// 5)向Stag路径写xml配置文件writeConf(conf, submitJobFile);conf.writeXml(out);// 6)提交job,返回提交状态status = submitClient.submitJob(jobId, submitJobDir.toString(), job.getCredentials());2)FileInputFormat源码解析(input.getSplits(job))(1)找到你数据存储的目录。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
2.1 序列化概述
1) 什么是序列化 序列化就是把内存中的对象,转换成字节序列(或其他数据传输协议)以便于存储(持 久化)和网络传输。 反序列化就是将收到字节序列(或其他数据传输协议)或者是硬盘的持久化数据,转换 成内存中的对象。 2) 为什么要序列化 一般来说, “活的”对象只生存在内存里,关机断电就没有了。而且“活的”对象只能 由本地的进程使用, 不能被发送到网络上的另外一台计算机。 然而序列化可以存储 “活的” 对象,可以将“活的”对象发送到远程计算机。 3) 为什么不用 Java 的序列化 Java 的序列化是一个重量级序列化框架(Serializable) ,一个对象被序列化后,会附带 很多额外的信息(各种校验信息,header,继承体系等) ,不便于在网络中高效传输。所以, hadoop 自己开发了一套序列化机制(Writable) ,特点如下: (1)紧凑:紧凑的格式能让我们充分利用网络带宽,而带宽是数据中心最稀缺的资 (2)快速:进程通信形成了分布式系统的骨架,所以需要尽量减少序列化和反序列化 的性能开销,这是基本的; (3)可扩展:协议为了满足新的需求变化,所以控制客户端和服务器过程中,需要直 接引进相应的协议,这些是新协议,原序列化方式能支持新的协议报文; (4)互操作:能支持不同语言写的客户端和服务端进行交互;
2.4 序列化案例实操
1)需求: 统计每一个手机号耗费的总上行流量、下行流量、总流量 2)数据准备
phone_data.txt
输入数据格式:
1363157993055 13560436666 C4-17-FE-BA-DE-D9:CMCC 120.196.100.99 18 15 1116 954 200
map array
MapWritable ArrayWritable
2.3 自定义 bean 对象实现序列化接口(Writable)
1)自定义 bean 对象要想序列化传输,必须实现序列化接口,需要注意以下 7 项。 (1)必须实现 Writable 接口 (2)反序列化时,需要反射调用空参构造函数,所以必须有空参构造 public FlowBean() { super(); } (3)重写序列化方法 @Override public void write(DataOutput out) throws IOException { out.writeLong(upFlow); out.writeLong(downFlow); out.writeLong(sumFlow); } (4)重写反序列化方法 @Override public void readFields(DataInput in) throws IOException { upFlow = in.readLong(); downFlow = in.readLong(); sumFlow = in.readLong(); } (5)注意反序列化的顺序和序列化的顺序完全一致 (6)要想把结果显示在文件中,需要重写 toString(),可用”\t”分开,方便后续用。 (7)如果需要将自定义的 bean 放在 key 中传输,则还需要实现 comparable 接口,因为 mapreduce 框中的 shuffle 过程一定会对 key 进行排序。 @Override public int compareTo(FlowBean o) { // 倒序排列,从大到小 return this.sumFlow > o.getSumFlow() ? -1 : 1; }
this.upFlow = upFlow; } public long getDownFlow() { return downFlow; } public void setDownFlow(long downFlow) { this.downFlow = downFlow; } public long getSumFlow() { return sumFlow; } public void setSumFlow(long sumFlow) { this.sumFlow = sumFlow; } } (2)编写 mapper package com.atguigu.mapreduce.flowsum; import java.io.IOException; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; public class FlowCountMapper extends Mapper<LongWritable, Text, Text, FlowBean>{ FlowBean v = new FlowBean(); Text k = new Text(); @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { // 1 获取一行 String line = value.toString(); // 2 切割字段 String[] fields = line.split("\t"); // 3 封装对象 // 取出手机号码 String phoneNum = fields[1];
手机号码
上行流量 下行流量
输出数据格式
1356·0436666 1116 954 2070
手机号码
上行流量
下行流量
总流量
3)分析 基本思路: Map 阶段: (1)读取一行数据,切分字段 (2)抽取手机号、上行流量、下行流量 (3)以手机号为 key,bean 对象为 value 输出,即 context.write(手机号,bean); Reduce 阶段: (1)累加上行流量和下行流量得到总流量。 (2)实现自定义的 bean 来封装流量信息,并将 bean 作为 map 输出的 key 来传输 (3) MR 程序在处理数据的过程中会对数据排序(map 输出的 kv 对传输到 reduce 之前, 会排序),排序的依据是 map 输出的 key 所以,我们如果要实现自己需要的排序规则,则可以考虑将排序因素放到 key 中,让 key 实现接口:WritableComparable。 然后重写 key 的 compareTo 方法。 4)编写 mapreduce 程序 (1)编写流量统计的 bean 对象 package com.atguigu.mapreduce.flowsum; import java.io.DataInput; import java.io.DataOutput; import java.io.IOException; import org.apache.hadoop.io.Writable; // 1 实现 writable 接口 public class FlowBean implements Writable{
// 取出上行流量和下行流量 long upFlow = Long.parseLong(fields[fields.length - 3]); long downFlow = Long.parseLong(fields[fields.length - 2]); v.set(downFlow, upFlow); // 4 写出 context.write(new Text(phoneNum), new FlowBean(upFlow, downFlow)); } } (3)编写 reducer package com.atguigu.mapreduce.flowsum; import java.io.IOException; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; public class FlowCountReducer extends Reducer<Text, FlowBean, Text, FlowBean> { @Override protected void reduce(Text key, Iterable<FlowBean> values, Context context) throws IOException, InterruptedException { long sum_upFlow = 0; long sum_downFlow = 0; // 1 遍历所用 bean,将其中的上行流量,下行流量分别累加 for (FlowBean flowBean : values) { sum_upFlow += flowBean.getSumFlow(); sum_downFlow += flowBean.getDownFlow(); } // 2 封装对象 FlowBean resultBean = new FlowBean(sum_upFlow, sum_downFlow); // 3 写出 context.write(key, resultBean); } } (4)编写驱动 package com.atguigu.mapreduce.flowsum; import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path;
2.2 常用数据序列化类型
常用的数据类型对应的 hadoop 数据序列化类型 Java 类型 boolean byte int float long double string Hadoop Writable 类型 BooleanWritable ByteWritable IntWritable FloatWritable LongWritable DoubleWritable Text