中科大研究生高级数据库实验报告,用LRU算法实现buffermanager,模拟数据库对记录的处理过程
LRU页面置换算法的设计实验报告

return-1;
}
intfindReplace(intBsize)
{//查找应予置换的页面
intpos = 0;
for(inti=0; i<Bsize; i++)
if(block[i].timer >= block[pos].timer)
for(i=0;i<20;i++)
{
QString[i] = rand()%10 ;
}
cout<<"页面号引用串: ";
for(i=0;i<20;i++)
{
cout<<QString[i]<<" ";
}
cout<<endl<<"------------------------------------------------------"<<endl;
四、实验结果(含程序、数据记录及分析和实验总结等)
#include<iostream>
#include<string>
#include<stdlib.h>
#include<ctime>
usingnamespacestd;
constintBsize=10;
constintPsize=20;
structp
Bsize = 3;
Init(QString,Bsize);
cout<<"LRU算法结果如下:<<endl;
LRU缓存淘汰算法实现及应用场景解析

LRU缓存淘汰算法实现及应用场景解析LRU缓存淘汰算法是一种常见的缓存淘汰策略,LRU全称为Least Recently Used,即最近最少使用。
LRU算法的思想是根据数据项的访问时间进行淘汰,最近访问的数据项会被保留,而较少被访问的数据项会被淘汰。
实现LRU缓存淘汰算法有多种方式,下面介绍一种基于哈希表和双向链表的实现方法。
1.数据结构:2.缓存访问操作:当访问一个数据项时,首先在哈希表中查找该数据项是否已存在。
如果存在,将该数据项从双向链表中删除,并将其移动到链表头部。
如果不存在,根据缓存的容量判断是否需要淘汰数据项,如果容量已满,则淘汰链表尾部的数据项。
然后将新的数据项添加到双向链表的头部,并在哈希表中插入该数据项。
3.淘汰策略:当缓存容量已满时,需要选择一个数据项进行淘汰。
由于LRU算法要淘汰最近最少使用的数据项,所以选择双向链表的尾部节点作为被淘汰的节点。
1.数据库查询缓存:在数据库查询过程中,为了提高查询性能,常常使用缓存来缓存查询的结果。
LRU缓存淘汰算法可以用于在缓存容量达到上限时淘汰最近不常访问的查询结果。
2.网页缓存:在web服务器中,为了提高网页的访问速度,通常会使用缓存来缓存网页。
LRU缓存淘汰算法可以用于在缓存容量限制下淘汰最近不常被访问的网页。
3.图片缓存:在移动应用或网页中,图片是非常常见的资源。
为了减少网络请求,常常会使用缓存来缓存图片。
LRU缓存淘汰算法可以用于在缓存容量限制下淘汰最近不常被访问的图片。
4.CPU缓存淘汰:在计算机体系结构中,CPU缓存是提高计算机性能的关键因素之一、由于CPU缓存容量有限,LRU缓存淘汰算法可以用于在缓存容量限制下淘汰最近不常被访问的数据。
总之,LRU缓存淘汰算法是一种简单而高效的缓存淘汰策略。
它基于数据项的访问时间来进行淘汰,能够较好地保留最近常被访问的数据,适用于多种不同的应用场景。
在实际开发中,可以根据具体的需求和性能要求选择合适的缓存淘汰策略。
LRU缓存替换算法介绍与编程实现

LRU缓存替换算法介绍与编程实现LRU(Least Recently Used)缓存替换算法是一种常用的缓存替换算法之一、它基于一种简单的原理:如果一个数据最近被访问过,那么将来它被访问的概率更高。
因此,LRU算法会优先替换最近最少使用的数据。
LRU算法的实现可以使用双向链表和哈希表来实现。
双向链表用于维护数据项的访问顺序,而哈希表用于快速查找数据项。
下面将详细介绍LRU缓存替换算法的实现。
1.数据结构定义:首先,我们需要定义双向链表节点的数据结构,包含key和value两个属性,以及prev和next两个指针用于维护双向链表顺序。
然后,我们还需要定义一个哈希表,用于快速查找节点。
```pythonclass Node:def __init__(self, key, value):self.key = keyself.value = valueself.prev = Noneself.next = Noneclass LRUCache:def __init__(self, capacity):self.capacity = capacityself.hashmap = {}self.head = Node(0, 0) # 头节点self.tail = Node(0, 0) # 尾节点self.head.next = self.tail # 初始化双向链表self.tail.prev = self.head```2. get操作:当调用get(key)方法时,我们首先需要判断key是否存在于哈希表中。
如果存在,说明数据已经被访问过,我们需要将该节点移到链表头部,并返回对应的值。
如果不存在,说明数据不存在缓存中,我们直接返回-1 ```pythondef get(self, key):if key in self.hashmap:node = self.hashmap[key]self._remove(node)self._add(node)return node.valueelse:return -1def _remove(self, node):node.prev.next = node.nextnode.next.prev = node.prevdef _add(self, node):node.prev = self.headnode.next = self.head.nextself.head.next.prev = nodeself.head.next = node```3. put操作:当调用put(key, value)方法时,我们首先需要判断key是否存在于哈希表中。
lru算法实验报告

lru算法实验报告LRU算法实验报告摘要:本实验旨在通过实验和数据分析,验证LRU(Least Recently Used)算法在缓存替换策略中的有效性和性能表现。
通过模拟不同的缓存大小和访问模式,我们对LRU算法进行了测试,并分析了其命中率、缺失率以及性能表现。
1. 算法介绍LRU算法是一种常用的缓存替换策略,它根据数据的最近访问时间来进行替换决策。
当缓存空间不足时,LRU算法会淘汰最长时间未被访问的数据,以保证缓存中的数据是最近被使用的。
LRU算法的实现通常使用链表或者哈希表来记录数据的访问顺序,并且在每次访问数据时更新其在链表或哈希表中的位置。
2. 实验设计为了验证LRU算法的有效性和性能表现,我们设计了以下实验:- 实验一:不同缓存大小下的LRU算法性能对比- 实验二:不同访问模式下的LRU算法性能对比在实验一中,我们分别使用LRU算法对不同大小的缓存进行测试,并记录其命中率和缺失率。
在实验二中,我们模拟了随机访问、顺序访问和局部性访问等不同访问模式,并对比LRU算法的性能表现。
3. 实验结果实验结果显示,随着缓存大小的增加,LRU算法的命中率呈现出逐渐增加的趋势,而缺失率则相应减少。
在不同的访问模式下,LRU算法的性能表现也有所差异,其中局部性访问模式下LRU算法表现最佳,而随机访问模式下表现最差。
4. 结论与讨论通过实验结果的分析,我们得出结论:LRU算法在缓存替换策略中具有较好的性能表现,尤其适用于局部性访问模式。
然而,随着数据规模的增大和访问模式的复杂化,LRU算法的性能也会受到一定的影响。
因此,在实际应用中,我们需要根据具体情况选择合适的缓存替换策略,或者结合其他算法进行优化。
总之,本实验验证了LRU算法在缓存替换策略中的有效性和性能表现,为进一步研究和应用LRU算法提供了参考和借鉴。
同时,我们也意识到LRU算法在特定情况下可能存在一定的局限性,需要进一步优化和改进。
lru缓存算法范文

lru缓存算法范文LRU(Least Recently Used)缓存算法是一种常见的缓存淘汰算法,它的核心思想是将最近最少使用的数据从缓存中淘汰出去,从而保持缓存中的数据始终是最常用的数据。
LRU缓存算法的实现通常使用一个哈希表和一个双向链表来完成。
哈希表用于快速查找一些key是否存在于缓存中,同时也可以保存每个key对应的value。
双向链表用来维护数据的访问顺序,链表的头部表示最近访问的数据,链表的尾部表示最久未访问的数据。
具体实现步骤如下:1. 在初始化LRU缓存时,需要指定缓存的容量,也就是能够存放的key-value对的最大数量。
同时生成一个空的双向链表和一个空的哈希表。
2. 当向缓存中添加新的key-value对时,先查找哈希表中是否存在该key。
若存在,则需要将其从双向链表中删除,再重新插入到链表的头部。
如果不存在,则需要判断当前缓存容量是否已经达到上限,如果达到上限,将链表尾部的最久未使用数据删除,并从哈希表中删除对应的key。
然后将新的key-value对插入到链表的头部,并在哈希表中添加该key。
3. 当从缓存中获取一些key对应的value时,首先在哈希表中查找该key是否存在。
如果存在,则需要将该key对应的节点从链表中删除,并重新插入到链表的头部。
然后返回该value。
如果不存在,则返回null。
4. 当需要从缓存中删除一些key时,首先在哈希表中查找该key是否存在。
如果存在,则需要将该key对应的节点从链表中删除,并从哈希表中删除该key。
LRU缓存算法的时间复杂度为O(1),因为所有操作都可以在常数时间内完成。
同时,通过利用哈希表和双向链表,能够快速查找和插入数据,保证了LRU算法的高效性。
总结起来,LRU缓存算法通过维护一个访问顺序链表,将新访问的数据插入到链表的头部,同时将最久未访问的数据从链表尾部删除,从而保持链表的头部数据始终是最近访问的数据。
这样能够有效地提高缓存的命中率,减少缓存淘汰带来的性能损耗。
lru算法及例题讲解

lru算法及例题讲解
摘要:
1.LRU算法简介
2.LRU算法原理
3.LRU算法应用
4.例题讲解
5.总结与拓展
正文:
一、LRU算法简介
最近最少使用(Least Recently Used,简称LRU)算法是一种缓存置换策略,用于决定在内存有限的情况下,如何淘汰已失效的缓存数据。
LRU算法基于一个假设:最近访问过的数据很可能会在不久的将来再次被访问。
因此,当内存有限且需要腾出空间时,优先淘汰最近访问过的数据。
二、LRU算法原理
LRU算法通过维护一个访问顺序来实现。
当一个数据被访问时,将其放入一个队列(或栈)中,并按照访问顺序进行排序。
当需要淘汰缓存时,从队尾(或栈顶)移除最近访问过的数据。
三、LRU算法应用
LRU算法广泛应用于计算机科学领域,如操作系统、浏览器缓存、数据库等领域。
通过使用LRU算法,可以有效提高缓存利用率,提高系统性能。
四、例题讲解
题目:一个含有n个元素的缓存,采用LRU算法进行缓存置换,求第k个访问的元素在缓存中的位置。
解题思路:
1.初始化一个长度为n的数组,表示每个元素在缓存中的位置。
2.模拟访问过程,每次访问一个元素,按照LRU算法进行置换,并记录访问顺序。
3.当访问第k个元素时,找到其在访问顺序中的位置,即为在缓存中的位置。
五、总结与拓展
LRU算法作为一种高效的缓存置换策略,在实际应用中具有重要意义。
了解LRU算法的原理和应用,可以帮助我们更好地解决实际问题。
LRU算法实现策略概述

LRU算法实现策略概述LRU(Least Recently Used)算法是一种用于缓存替换的常见策略。
在计算机科学中,缓存是指将数据存储在更快的媒介中,以提高数据访问速度。
LRU算法通过淘汰最近最少使用的数据,以保持缓存的最新和最热数据。
实现LRU算法的关键在于如何判断数据是否被访问过以及如何确定最近最少使用的数据。
以下是一种常见的实现策略概述。
一、LRU缓存数据结构为了实现LRU算法,我们首先需要设计一个数据结构用于保存缓存数据。
一种常见的设计是使用双向链表和哈希表的结合。
双向链表用于按顺序保存数据的访问顺序,最近访问的数据在链表的头部,最久未访问的数据在链表的尾部。
哈希表用于快速查找数据在链表中的位置。
二、缓存数据访问操作1. 数据访问时的缓存命中:当访问一个数据时,首先在哈希表中查找数据是否存在。
- 若数据不存在,表示缓存未命中,需要将数据从磁盘或其他慢速存储中读取,并将数据添加到缓存中。
- 若数据存在,在双向链表中找到数据对应的节点,并将该节点移动到链表的头部,表示该数据最近被访问过。
2. 缓存数据淘汰:当缓存已满时,需要选择最近最少使用的数据进行替换。
- 直接选择链表尾部的数据淘汰是一种简单的策略,但在实际应用中可能不够高效。
因此,结合哈希表,可以快速查找链表尾部数据对应的节点,并将其淘汰。
三、LRU算法的优化LRU算法的实现可以进一步优化,以提高性能和效率。
以下是两种常见的优化策略:1. 使用伪最近使用算法:在实际应用中,我们可以通过记录数据的访问时间戳来近似判断数据的访问顺序。
当缓存满时,将最老的数据淘汰。
2. 使用多级缓存:为了提高访问速度,可以将缓存分为多级,每一级缓存的大小和替换策略可以不同。
常用的分级缓存包括L1缓存、L2缓存等。
四、LRU算法的应用LRU算法广泛应用于各种缓存系统中,如操作系统的页缓存、数据库的查询缓存、Web服务器的页面缓存等。
通过保持最热数据在缓存中,可以有效提高系统的访问速度和性能。
LRU算法实现
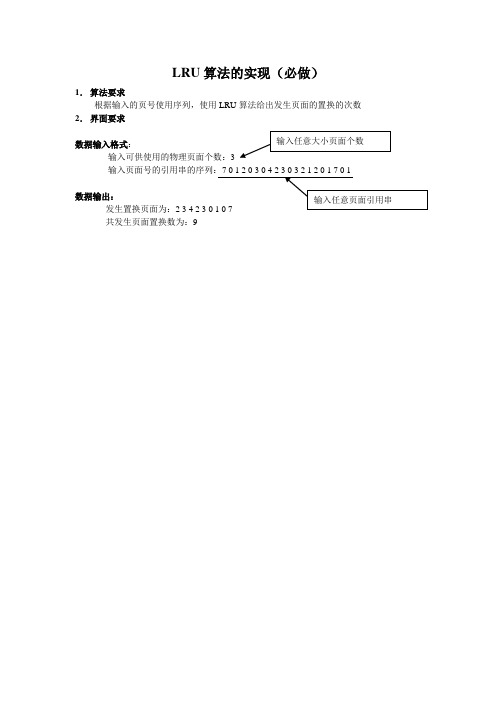
LRU算法的实现(必做)1.算法要求根据输入的页号使用序列,使用LRU算法给出发生页面的置换的次数2.界面要求输入可供使用的物理页面个数:3数据输出:发生置换页面为:共发生页面置换数为:9分页存储管理(选做)1. 作业描述对指定长度的内存区域使用分页进行存储管理,能够将用户进程中的内容使用分页机制进行存储,能够在内存区域不足时,使用LRU 算法,将制定的页面置换到外部存储空间中,如果访问的内容不在内存中,则要将外部存储空间中的相应内容调入到主存中。
2. 关键数据结构使用数组memory[…]来表示可用的物理内存页面,storage[…]来表示外存中存储的相应内容。
如memory[5]={1.1, 1.2, 2.2, 3.2, 1.4} 表示目前内存中存放着进程1中的第1、2和4部分的内容,进程2中的第2部分内容和进程3中第2部分的内容,同理storage[10]={1.3, 2.1, 2.3, 2.4, 2.5, 3.1 ,3.3, 3.4, 3.5, 4.1}在实现中要求数组storage 的长度为memory 长度的两倍.3. 界面要求数据输入:内存memory 中页面的个数:5内存中每个页面的大小:4操作(i 读入/o输入进程内容:2 184 13 15N //按‘N ’表示输入结束打印出memory 和storage 中相应的数据内容:memory[5]={1.1, 1.2, 2.2, 3.2, 1.4}storage[10]={1.3, 2.1, 2.3, 2.4, 2.5, 3.1 ,3.3, 3.4, 3.5, 4.1} i 读入/o 输出): o: 1 13 //表示1进程中的第13地址中的内容 输出这个地址所在页面信息: memory 5 //表示在memory 中的第5个页面中 操作(i 读入/o 输出): o//表示1进程中的第8地址中的内容//表示在storage 中的第1个页面中<-> memory 3 //storage 1和memory 3中的内容发生置换//表示要访问的内容在memory 3 中。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
数据库实现技术实验报告
SC11011042吴**源代码获取请联系:email:wude_yun@
wdyun@
一、实验目的
为了了解数据库buffer管理器的工作原理,对数据库底层结构有更进一步的了解,我们将实现一个简单的存储和缓冲管理器。
该实验涉及的存储和缓冲管理器,缓冲技术,散列技术,文件存储结构,磁盘空间和缓冲模块的接口功能。
二、实验环境
硬件平台:LENOVO ThinkPad E425
软件平台:开发系统:win7
开发工具:eclipse
开发语言:java
JDK版本jdk1.6
三、实验内容
1、相关数据结构描述
BCB类
1)1)BCB
BCB类的属性如下所示:
public class BCB{
private int page_id;//文件号
private int frame_id;//存放文件号的buffer地址的下标
private int latch;//锁
private int count;//计数器
private int dirty;//是否脏,修改过
private BCB next;//下一个bcb链
……
}
BCB类主要是实现快速的查找功能,既查找给定的文件号是否在缓存中。
查找给定的文件号是否在缓存中,一种比较简单的方法是遍历整个buffer,但是这样势必浪费时间。
因为整个记录的数目为50万条,buffer空间为1024。
那么对所有的记录查找是否在buffer中就需要50万×1024≈5亿次。
如果用BCB数组(类似一个十字链表的结构)Hash划分对每个文件号查找平均次数1(假设是平均划分,即使不是平均划分其平均查找次数远远小于1024
次),对所有的记录的查找只要5万次,明显要快。
BCB类具体包含的属性及方法的UML如图1所示。
图1BCB的UML结构
2)BufferManager与LRU类
BufferManager类的属性如下所示:
public class BufferManager{
public static final int DEFBUFSIZE=1024;
private int[]ftop;//对应buffer的号中存放frame_id
private BCB[]ptof;//Hash Table
private LRU lru;//lru类管理替换规则
private int freeBuffer;//用于表示空闲的buffer的下标
public BufferManager(){
super();
this.ftop=new int[this.DEFBUFSIZE];
this.ptof=new BCB[this.DEFBUFSIZE];
this.initialFtop();
this.intialPtof();
lru.intial();
}
……
}
其中LRU类为实现当buffer满了时,使用LRU算法替换buffer。
LRU类的属性如下所示:
public class LRU{
private Note head;
class Note{
private int bufNumber;//buffer的下标
private Note next;//后驱
private Note front;//前驱
}
public Note intial(){
//只申请1个空间
head=new Note();
head.front=head;
head.next=head;
return head;
}
……
}
LRU类包含一个head引用(类似c语言的指针)指示LRU链表的头,表示当前刚刚使用过的buffer地址。
Note类是LRU的内部类,其实就相当于实现c语言的结构体,用于表示LRU链表的内部节点,将链表表示成一个双向循环链表。
用双向循环链表实现LRU算法的好处是算法实现很简单。
head引用所指向的节点是当前刚刚使用的节点,head的next 指向的节点是将要替换的节点。
LRU类包含一个初始化函数intial()初始化LRU类,LRU类只有一个节点。
这里需要指出不一次性生成1024个节点(或者说是buffersize大小的节点数)好处在于当buffer 未满时,如果page_id在buffer中既已命中,这时需要调整更新LRU链表,将命中的存有page_id的buffer调到head指向的节点的前面,调换两个节点的次序即可;否则如果生成1024个节点,由于此时buffer未满,则肯定有空的LRU节点,因此将命中的存有page_id的buffer 调到head指向的节点的前面,势必要调整整个链表。
BufferManager与LRU类及其之间的关系的UML如图2所示。
图2BufferManager与LRU类及其之间的关系的UML
DataStorageManager类
3)3)DataStorageManager
DataStorageManager类的属性如下所示:
public class DataStorageManager{
private BufferManager buffer;
private int ioCount;//io次数
private int hitCount;//lru命中次数
……
}
DataStorageManager类主要要是实现读取文件记录实现整个buffer管理。
包含一个BufferManager类的成员变量buffer用于实现缓存的管理,ioCount表示整个I/O的次数,hitCount记录命中次数。
DataStorageManager类的UML与其他类之间的关系如图3所示。
图3DataStorageManager类的UML与其他类之间的关系
2、算法描述及流程图
先依次读入所给测试文档里面的数据,然后按行依次处理每个命令,循环执行如下:判断是文件号是否已存在于缓存中,是则在ptob数组中修改该页对应的BCB参数,并同时找出该页在双向链表head中的位置,插到首位。
读下一条记录。
若不存在I/O次数加1。
并判断buffer是否已满,如果未满,在双向链表head首部插入新节点,并同时在ftop数组添加该页映射;如果满用LRU算法选择一个替换的buffer地址(将head移到下一个节点),在ftop数组中找到替换的oldpage_id,删除ptob数组中旧的oldpage_id节点,在ftop数组添加该页映射。
最后将该页相关信息插入ptob数组中(不管是buffer否满)。
并读下一条记录。
算法流程图如图3所示。
四、实验结果
更改buffer的大小,观察结果
1)当buffersize=1024时的结果为,如图4所示:
共用时间:1.447秒,LRU命中次数:169565,总共I/O次数:575225,命中率:33.913%
图4buffersize=1024时的结果
2)当buffersize=2048时的结果为,如图5所示:
共用时间:1.638秒,LRU命中次数:209569,总共I/O次数:535221,命中率:41.9138%
图5buffersize=2048时的结果
3)当buffersize=10000时的结果为,如图6所示:
共用时间:7.114秒,LRU命中次数:325557,总共I/O次数:419233,命中率:65.1114%
图6buffersize=10000时的结果
结论:随着buffersize的增加命中次数不断增大,I/O次数不断减小,命中率也不断增大。
五、实验总结
本次实验最难的地方是对整个程序流程的把握,其次是各个数据结构(类)之间的关系如何组织。
LRU双向循环链表的使用大大简化了LRU替换算法的实现,Java语言没有指针使得编程变得相对简单。
通过本次实验,我对于数据库的buffer管理器的工作原理有了更进一步的了解,对于整个数据缓存技术也有了清晰的认识,收获颇多。