Stata门限模型地操作和结果详细解读汇报汇报
STATA面板数据模型操作命令讲解
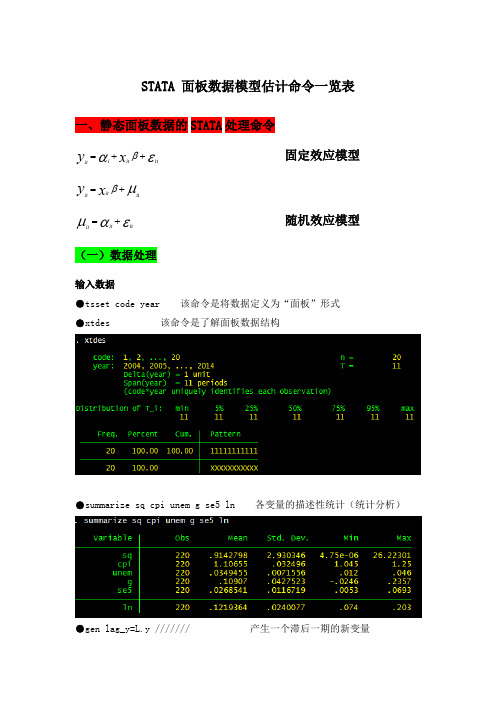
STATA 面板数据模型估计命令一览表一、静态面板数据的STATA 处理命令固定效应模型εαβit ++=x y it i it μβit +=x y it it随机效应模型εαμit +=it it (一)数据处理输入数据●tsset code year 该命令是将数据定义为“面板”形式●xtdes 该命令是了解面板数据结构●summarize sq cpi unem g se5 ln 各变量的描述性统计(统计分析)●gen lag_y=L.y /////// 产生一个滞后一期的新变量gen F_y=F.y /////// 产生一个超前项的新变量gen D_y=D.y /////// 产生一个一阶差分的新变量gen D2_y=D2.y /////// 产生一个二阶差分的新变量(二)模型的筛选和检验●1、检验个体效应(混合效应还是固定效应)(原假设:使用OLS混合模型)●xtreg sq cpi unem g se5 ln,fe对于固定效应模型而言,回归结果中最后一行汇报的F统计量便在于检验所有的个体效应整体上显著。
在我们这个例子中发现F统计量的概率为0.0000,检验结果表明固定效应模型优于混合OLS模型。
●2、检验时间效应(混合效应还是随机效应)(检验方法:LM统计量)(原假设:使用OLS混合模型)●qui xtreg sq cpi unem g se5 ln,re (加上“qui”之后第一幅图将不会呈现)xttest0可以看出,LM检验得到的P值为0.0000,表明随机效应非常显著。
可见,随机效应模型也优于混合OLS模型。
●3、检验固定效应模型or随机效应模型(检验方法:Hausman检验)原假设:使用随机效应模型(个体效应与解释变量无关)通过上面分析,可以发现当模型加入了个体效应的时候,将显著优于截距项为常数假设条件下的混合OLS模型。
但是无法明确区分FE or RE的优劣,这需要进行接下来的检验,如下:Step1:估计固定效应模型,存储估计结果Step2:估计随机效应模型,存储估计结果Step3:进行Hausman检验●qui xtreg sq cpi unem g se5 ln,feest store fequi xtreg sq cpi unem g se5 ln,reest store rehausman fe (或者更优的是hausman fe,sigmamore/ sigmaless)可以看出,hausman检验的P值为0.0000,拒绝了原假设,认为随机效应模型的基本假设得不到满足。
STATA面板数据模型操作命令讲解

STATA面板数据模型操作命令讲解编辑整理:尊敬的读者朋友们:这里是精品文档编辑中心,本文档内容是由我和我的同事精心编辑整理后发布的,发布之前我们对文中内容进行仔细校对,但是难免会有疏漏的地方,但是任然希望(STATA面板数据模型操作命令讲解)的内容能够给您的工作和学习带来便利。
同时也真诚的希望收到您的建议和反馈,这将是我们进步的源泉,前进的动力。
本文可编辑可修改,如果觉得对您有帮助请收藏以便随时查阅,最后祝您生活愉快业绩进步,以下为STATA面板数据模型操作命令讲解的全部内容。
STATA 面板数据模型估计命令一览表一、静态面板数据的STATA 处理命令固定效应模型 随机效应模型 (一)数据处理输入数据●tsset code year 该命令是将数据定义为“面板”形式●xtdes 该命令是了解面板数据结构●summarize sq cpi unem g se5 ln 各变量的描述性统计(统计分析)●gen lag_y=L.y /////// 产生一个滞后一期的新变量εαβit++=x y it i it μβit+=x y it it εαμit+=ititgen F_y=F。
y /////// 产生一个超前项的新变量gen D_y=D.y /////// 产生一个一阶差分的新变量gen D2_y=D2。
y /////// 产生一个二阶差分的新变量(二)模型的筛选和检验●1、检验个体效应(混合效应还是固定效应)(原假设:使用OLS混合模型)●xtreg sq cpi unem g se5 ln,fe对于固定效应模型而言,回归结果中最后一行汇报的F统计量便在于检验所有的个体效应整体上显著。
在我们这个例子中发现F统计量的概率为0。
0000,检验结果表明固定效应模型优于混合OLS模型。
●2、检验时间效应(混合效应还是随机效应)(检验方法:LM统计量)(原假设:使用OLS混合模型)●qui xtreg sq cpi unem g se5 ln,re (加上“qui"之后第一幅图将不会呈现)xttest0可以看出,LM检验得到的P值为0.0000,表明随机效应非常显著。
STATA面板数据模型操作命令讲解(word文档良心出品)

STATA 面板数据模型估计命令一览表一、静态面板数据的STATA 处理命令εαβit ++=x y it i it 固定效应模型μβit +=x y it itεαμit +=it it 随机效应模型(一)数据处理输入数据●tsset code year 该命令是将数据定义为“面板”形式●xtdes 该命令是了解面板数据结构●summarize sq cpi unem g se5 ln 各变量的描述性统计(统计分析)●gen lag_y=L.y /////// 产生一个滞后一期的新变量gen F_y=F.y /////// 产生一个超前项的新变量gen D_y=D.y /////// 产生一个一阶差分的新变量gen D2_y=D2.y /////// 产生一个二阶差分的新变量(二)模型的筛选和检验●1、检验个体效应(混合效应还是固定效应)(原假设:使用OLS混合模型)●xtreg sq cpi unem g se5 ln,fe对于固定效应模型而言,回归结果中最后一行汇报的F统计量便在于检验所有的个体效应整体上显著。
在我们这个例子中发现F统计量的概率为0.0000,检验结果表明固定效应模型优于混合OLS模型。
●2、检验时间效应(混合效应还是随机效应)(检验方法:LM统计量)(原假设:使用OLS混合模型)●qui xtreg sq cpi unem g se5 ln,re (加上“qui”之后第一幅图将不会呈现) xttest0可以看出,LM检验得到的P值为0.0000,表明随机效应非常显著。
可见,随机效应模型也优于混合OLS模型。
●3、检验固定效应模型or随机效应模型(检验方法:Hausman检验)原假设:使用随机效应模型(个体效应与解释变量无关)通过上面分析,可以发现当模型加入了个体效应的时候,将显著优于截距项为常数假设条件下的混合OLS模型。
但是无法明确区分FE or RE的优劣,这需要进行接下来的检验,如下:Step1:估计固定效应模型,存储估计结果Step2:估计随机效应模型,存储估计结果Step3:进行Hausman检验●qui xtreg sq cpi unem g se5 ln,feest store fequi xtreg sq cpi unem g se5 ln,reest store rehausman fe (或者更优的是hausman fe,sigmamore/ sigmaless)可以看出,hausman检验的P值为0.0000,拒绝了原假设,认为随机效应模型的基本假设得不到满足。
(完整word版)STATA面板数据模型操作命令讲解

STATA 面板数据模型估计命令一览表 一、静态面板数据的STATA 处理命令εαβit ++=x y it i it 固定效应模型μβit +=x y it itεαμit +=it it 随机效应模型(一)数据处理输入数据●tsset code year 该命令是将数据定义为“面板”形式●xtdes 该命令是了解面板数据结构●summarize sq cpi unem g se5 ln 各变量的描述性统计(统计分析)●gen lag_y=L.y /////// 产生一个滞后一期的新变量gen F_y=F.y /////// 产生一个超前项的新变量gen D_y=D.y /////// 产生一个一阶差分的新变量gen D2_y=D2.y /////// 产生一个二阶差分的新变量(二)模型的筛选和检验●1、检验个体效应(混合效应还是固定效应)(原假设:使用OLS混合模型)●xtreg sq cpi unem g se5 ln,fe对于固定效应模型而言,回归结果中最后一行汇报的F统计量便在于检验所有的个体效应整体上显著。
在我们这个例子中发现F统计量的概率为0.0000,检验结果表明固定效应模型优于混合OLS模型。
●2、检验时间效应(混合效应还是随机效应)(检验方法:LM统计量)(原假设:使用OLS混合模型)●qui xtreg sq cpi unem g se5 ln,re (加上“qui”之后第一幅图将不会呈现) xttest0可以看出,LM检验得到的P值为0.0000,表明随机效应非常显著。
可见,随机效应模型也优于混合OLS模型。
●3、检验固定效应模型or随机效应模型(检验方法:Hausman检验)原假设:使用随机效应模型(个体效应与解释变量无关)通过上面分析,可以发现当模型加入了个体效应的时候,将显著优于截距项为常数假设条件下的混合OLS模型。
但是无法明确区分FE or RE的优劣,这需要进行接下来的检验,如下:Step1:估计固定效应模型,存储估计结果Step2:估计随机效应模型,存储估计结果Step3:进行Hausman检验●qui xtreg sq cpi unem g se5 ln,feest store fequi xtreg sq cpi unem g se5 ln,reest store rehausman fe (或者更优的是hausman fe,sigmamore/ sigmaless)可以看出,hausman检验的P值为0.0000,拒绝了原假设,认为随机效应模型的基本假设得不到满足。
Stata运行结果及分析

log: e:\赵耐青\统计分析结果.loglog type: textopened on: 20 Jul 2002, 10:47:03.. /* 调用数据库*/. use "E:\赵耐青\clinical trial data(Chenfeng).dta", clear.. /* 描述数据库*/. describeContains data from E:\赵耐青\clinical trial data(Chenfeng).dta obs: 240vars: 60 7 Feb 2002 21:41size: 35,760 (87.5% of memory free)------------------------------------------------------------------------------- storage display valuevariable name type format label variable label------------------------------------------------------------------------------- No int %8.0g 编号Center byte %8.0g 中心编号Name str3 %9s 姓名Gender byte %8.0g sex 性别Age byte %8.0g 年龄(岁)Hight int %8.0g 身高(cm)Weight float %9.0g 体重(kg)Base1 byte %8.0g 糖尿病病程(年)Base2 byte %8.0g 神经病病变病程(年) mdns0 byte %8.0g 疗前MDNSmdns1 byte %8.0g 疗后1月MDNSmdns2 byte %8.0g 疗后2月MDNSmdns3 byte %8.0g 疗后3月MDNSmdns4 byte %8.0g 疗后4月MDNSmdns5 byte %8.0g 疗后5月MDNSmdns6 byte %8.0g 疗后6月MDNSfell0 byte %8.0g 疗前感觉障碍得分fell1 byte %8.0g 疗后1月感觉障碍得分fell2 byte %8.0g 疗后2月感觉障碍得分fell3 byte %8.0g 疗后3月感觉障碍得分fell4 byte %8.0g 疗后4月感觉障碍得分fell5 byte %8.0g 疗后5月感觉障碍得分fell6 byte %8.0g 疗后6月感觉障碍得分gca0 float %9.0g 疗前正中感觉N传导速度gca1 float %9.0g 疗后正中感觉N传导速度gcb0 float %9.0g 疗前尺感觉N传导速gcb1 float %9.0g 疗后尺感觉N传导速gcc0 float %9.0g 疗前腓感觉N传导速度gcc1 float %9.0g 疗后腓感觉N传导速度yca0 float %9.0g 疗前正中运动N传导速度yca1 float %9.0g 疗后正中运动N传导速度ycb0 float %9.0g 疗前腓总运动N传导速度ycb1 float %9.0g 疗后腓总运动N传导速度HbA1c0 float %9.0g 疗前糖化血红蛋白HbA1c1 float %9.0g 疗后糖化血红蛋白RBC0 float %9.0g 疗前红细胞数RBC1 float %9.0g 疗后红细胞数WBC0 float %9.0g 疗前白细胞数WBC1 float %9.0g 疗后白细胞数CRE0 float %9.0g 疗前肌酐CRE1 float %9.0g 疗后肌酐ALT0 float %9.0g 疗前谷丙转氨酶ALT1 float %9.0g 疗后谷丙转氨酶TG0 float %9.0g 疗前甘油三脂TG1 float %9.0g 疗后甘油三脂CHO0 float %9.0g 疗前总胆固醇CHO1 float %9.0g 疗后总胆固醇ECG0 byte %8.0g ECG 疗前心电图ECG1 byte %8.0g ECG 疗后心电图side1 byte %8.0g 不良反应之一degree1 byte %8.0g degree 程度relate1 byte %8.0g relate 与药物的关系side2 byte %8.0g 不良反应之二degree2 byte %8.0g degree 程度relate2 byte %8.0g relate 与药物的关系side3 byte %8.0g 不良反应之三degree3 byte %8.0g degree 程度relate3 byte %8.0g relate 与药物的关系Group float %9.0g group 分组变量d float %9.0g------------------------------------------------------------------------------- Sorted by:.. /* 各中心各组病例分配*/. tab Center Group| 分组变量中心编号| Treatment Placebo | Total-----------+----------------------+----------1 | 24 24 | 482 | 24 24 | 483 | 24 24 | 484 | 24 24 | 485 | 24 24 | 48-----------+----------------------+----------Total | 120 120 | 240结果显示,各中心均按方案完成了规定的入组病例数。
stata门槛效应结果解读

stata门槛效应结果解读在 Stata 中,门槛效应 (Threshold Effect) 是指某个变量的效应在达到一定阈值时才会表现出来。
在检验门槛效应时,可以使用Stata 中的 thresh 命令。
具体步骤如下:1. 使用 thresh 命令创建门槛效应模型。
例如,可以使用thresh 命令创建一个门槛效应模型,其中门槛值为 3,表示只有变量值大于等于 3 时,才能被认为是具有门槛效应的。
2. 使用 Stata 中的 econometrics 命令进行回归分析,并将门槛效应变量作为自变量之一。
3. 分析回归结果,查看门槛效应是否显著。
可以使用 Stata 中的 pvalue 命令查看回归结果的显著性,以及使用 coef 命令查看门槛效应变量的系数。
例如,假设我们想检验年龄对于教育程度的门槛效应,可以使用以下命令:```thresh age education >= 3econometrics education * age```上述命令将创建一个门槛效应模型,其中门槛值为 3,表示只有教育程度大于等于 3 时,才能被认为是具有门槛效应的。
接下来,使用 econometrics 命令进行回归分析,并将门槛效应变量作为自变量之一,查看回归结果。
在 Stata 中,可以使用 pvalue 命令查看回归结果的显著性,以及使用 coef 命令查看门槛效应变量的系数。
例如,使用 pvalue 命令可以查看回归结果是否显著:```pvalue education * age```如果回归结果不显著,则表明门槛效应不显著。
此时,可以使用thresh 命令查看门槛效应是否存在,以及门槛效应变量的系数是否显著。
STATA面板数据模型操作命令讲解(word文档良心出品)

STATA 面板数据模型估计命令一览表一、静态面板数据的 STATA 处理命令固定效应模型随机效应模型(一)数据处理输入数据• tsset code year 该命令是将数据定义为“面板”形式 • xtdes该命令是了解面板数据结构・ xtdescode: 1i 2, ■■■( 20n 工 20 year : 3004, 2005, ■…,2014T =11Delta(year) =1 unit span(year) =11 periods(code*year uniquely identifies eachobservation)Distribution of:min 8%2璃50^ 75% 95%max1111 11111111 11Freq. Percent Cum. Pattern20 100.00 100.00 1111111111120100.00XXXXXXXXXXX・ summarize sc I cpi unem gse5 InvariableObs Mean Std ・ Dev.Mi nMax sq 220 .Q142798 2.9303464.75e-0626.22301cpi2201*10655 *032496 1.045 1. 25 unem22Q .0349455 .0071556 .012 ,046 g220,10907 .0427523 0246 .2357220 .0268541 011671? .0053.0693220.1219364.0240077,074,203• summarize sq cpi unem g se5 In各变量的描述性统计(统计分析)• gen lag_y=L.y ///////产生一个滞后一期的新变量*= Xitit• ;itto U 一 if对于固定效应模型而言,回归结果中最后一行汇报的F 统计量便在于检验所 有的个体效应整体上显著。
Stata操作讲义知识讲解

Stata操作讲义知识讲解S t a t a操作讲义Stata操作讲义第一讲 Stata操作入门第一节概况Stata最初由美国计算机资源中心(Computer Resource Center)研制,现在为Stata公司的产品,其最新版本为7.0版。
它操作灵活、简单、易学易用,是一个非常有特色的统计分析软件,现在已越来越受到人们的重视和欢迎,并且和SAS、SPSS一起,被称为新的三大权威统计软件。
Stata最为突出的特点是短小精悍、功能强大,其最新的7.0版整个系统只有10M左右,但已经包含了全部的统计分析、数据管理和绘图等功能,尤其是他的统计分析功能极为全面,比起1G以上大小的SAS系统也毫不逊色。
另外,由于Stata在分析时是将数据全部读入内存,在计算全部完成后才和磁盘交换数据,因此运算速度极快。
由于Stata的用户群始终定位于专业统计分析人员,因此他的操作方式也别具一格,在Windows席卷天下的时代,他一直坚持使用命令行/程序操作方式,拒不推出菜单操作系统。
但是,Stata的命令语句极为简洁明快,而且在统计分析命令的设置上又非常有条理,它将相同类型的统计模型均归在同一个命令族下,而不同命令族又可以使用相同功能的选项,这使得用户学习时极易上手。
更为令人叹服的是,Stata语句在简洁的同时又拥有着极高的灵活性,用户可以充分发挥自己的聪明才智,熟练应用各种技巧,真正做到随心所欲。
除了操作方式简洁外,Stata的用户接口在其他方面也做得非常简洁,数据格式简单,分析结果输出简洁明快,易于阅读,这一切都使得Stata成为非常适合于进行统计教学的统计软件。
Stata的另一个特点是他的许多高级统计模块均是编程人员用其宏语言写成的程序文件(ADO文件),这些文件可以自行修改、添加和下载。
用户可随时到Stata网站寻找并下载最新的升级文件。
事实上,Stata的这一特点使得他始终处于统计分析方法发展的最前沿,用户几乎总是能很快找到最新统计算法的Stata程序版本,而这也使得Stata 自身成了几大统计软件中升级最多、最频繁的一个。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
一、门限面板模型概览
如果你不愿意看下面一堆堆的文字,更不想看计量模型的估计和检验原理,那就去《数量经济技术经济研究》上,找一篇标题带有“双门槛(或者双门限)”的文章,浏览一遍,看看文章计量部分列示的统计量和检验结果。
这样,在软件操作时,你就知道每一步得到的结果有什么意义,怎么解释了,起码心里会有点印象。
一般情况下,一个研究生花费在研究上的时间越多,他的成果越丰富,也就是说,研究成果和研究时间存在某种正向关联。
但是,这种关联是线性的吗?在最初阶段,他可能看了两三年的文献,也没有写出一篇优秀的文章,但是一旦过了这个基础期,他的能量和成果将如火山爆发一样喷涌出来,此时,他投入少量的时间,就能产出大量优质文章。
再过几年,他可能会进入另外一种境界,虽然比以前有了极大提高,但是研究进入新的瓶颈期,文章发表的数量减少。
由此可以看出,研究成果与研究年限存在一种阶段性的线性关系。
这个基础期的结点、瓶颈期的起点就像“门槛”一样把研究阶段分成三个部分,在不同部分,成果和时间的线性关系都不同。
这个效应被称为门槛效应或门限效应。
门限效应,是指当一个经济参数达到特定的数值后,引起另外一个经济参数发生突然转向其它发展形式的现象。
作为原因现象的临界值称为门限值。
在上面的例子中,成果和时间存在非线性关系,但是在每个阶段是线性关系。
有些人将这样的模型称为门槛模型,或者门限模型。
如果模型的研究对象包含多个个体多个年度,那么就是门限面板模型。
汉森(Bruce E. Hansen)在门限回归模型上做出了很多贡献。
了解门限模型最好的办法,首先就要阅读他的文章。
他的文章很有特点:条理很清晰,推导过程详细,语言简练,
语法不复杂。
有关他的论文、程序、数据可以参考Hansen的个人网站:
/~bhansen/progs/progs_subject.htm。
Hansen于1996年在《Econometrica》上发表文章《Inference when a nuisance parameter is not identified under the null hypothesis》,提出了时间序列门限自回归模型(TAR)的估计和检验。
之后,他在门限模型上连续追踪,发表了几篇经典文章,尤其是1999年的《Threshold effects in non-dynamic panels: Estimation, testing and inference》,2000年的《Sample splitting and threshold estimation》和2004年与他人合作的《Instrumental Variable Estimation of a Threshold Model》。
在这些文章中,Hansen介绍了包含个体固定效应的静态平衡面板数据门限回归模型,阐述了计量分析方法。
方法方面,首先要通过减去时间均值方程,消除个体固定效应,然后再利用OLS(最小二乘法)进行系数估计。
如果样本数量有限,那么可以使用自举法(Bootstrap)重复抽取样本,提高门限效应的显著性检验效率。
在Hansen(1999)的模型中,解释变量中不能包含内生解释变量,无法扩展应用领域。
Caner和Hansen在2004年解决了这个问题。
他们研究了带有内生变量和一个外生门限变量的面板门限模型。
与静态面板数据门限回归模型有所不同,在含有内生解释变量的面板数据门限回归模型中,需要利用简化型对内生变量进行一定的处理,然后用2SLS(两阶段最小二乘法)或者GMM(广义矩估计)对参数进行估计。
当然,有关门限回归模型的最新研究,还可以参考《Inflation and Growth: New Evidence From a Dynamic Panel Threshold Analysis》(Stephanie Kremer,Alexander Bick,Dieter Nautz,2009)。
二、计量模型的假设、估计和检验
略
三、门限面板模型回归估计stata操作指南——基于王群勇xtptm程序
有关这个程序的有效性,我们不去追究,就认为它是正确的程序。
(一)前期准备
1、拥有一台能联网的电脑;
2、电脑中有能正常运行的Stata程序,最好是Stata/SE 12,没有这个程序请自行搜索;
3、下载xtptm.zip文件包(请自行搜索),解压缩,复制到X:\Program Files\Stata12.0(full)\ado文件夹下,单独使用一个文件夹,最好直接使用xtptm文件夹。
也就是说,stata下面有文件夹ado,ado下面有文件夹xtptm,xtptm下面包含了若干文件;
4、指定门限程序文件夹(每次重新打开stata都需要指定这个路径),输入命令(可以不包含点和空格“. ”,直接使用命令):
. cd "D:\Program Files\Stata12.0(full)\ado\xtptm"
D:\Program Files (x86)\Stata12_winX86_x64\ado\xtptm
以上路径需要根据自己的实际情况指定;
5、下载相关文件,输入命令:
. findit moremata
回车,弹出帮助文件,依次将“Web resources from Stata and other users”下面的11个链接打开,点击相应安装按钮,下载安装。
其中,第六个链接安装结束后会提示安装出现问题,不用管。
因为指定了程序路径(cd那个命令),安装完成后,xtptm文件夹会增加很多文件。
至此,准备工作做完了。
(二)门限回归实例
1、到此【下载数据】。
这个数据包括29个个体(省份),21个年度(1990-2010),是一个平衡面板数据。
将数据复制粘贴到Stata数据库中。
方法是:菜单栏Data>Data Editor>Data Editor (Edit),粘贴数据,粘贴时选择“第一行设定为变量名”。
然后,在数据界面,点击保存,将数据保存到xtptm文件夹内。
这样以后每次都可以直接打开这个数据文件(仍需要用cd命令指定门限程序的路径)。
关闭数据编辑框,进行下面的操作。
2、设定个体与时间,如果个体名称是字符,还需要先将字符转化为数值:
. encode provin , gen(prov) #将字符型的变量provin转换为数值型的变量prov . xtset prov year #设定个体和时间分别由prov和year变量的数据表示最终数据列表如图所示。
3、执行门限回归,输入如下命令:
. xtptm agg trans labor market iae, rx(tax) thrvar(year) iters(1000) trim(0.05) grid(100) regime(2)
含义:
xtptm——执行门限面板回归估计
agg——被解释变量
trans、labor、market、iae——非核心解释变量(控制变量)
rx(tax)——核心解释变量设定为tax
thrvar(year)——门限变量设定为year
iters(1000)——自举抽样1000次
trim(0.05)——分组子样本异常值去除比例为百分之五
grid(100)——将样本分成100个栅格然后取100个中间参数
regime(2)——待检验的门限值数量为两个
4、转到【回归结果说明】
4、回归结果说明
这个程序只能绘制第一个门限值的检验图。
命令为:. _matplot LR, colume (1 2)
#注意:LR后面没有#号。