数据采集系统数据库.
分布式数据系统的数据采集方法及分布式数据系统

分布式数据系统的数据采集方法及分布式数据系统一、引言分布式数据系统是指将数据分散存储在多个节点上的系统,它可以提供高可用性、高性能和可扩展性。
数据采集是分布式数据系统的关键环节,它涉及到从各个数据源采集数据并将其存储到分布式数据系统中。
本文将详细介绍分布式数据系统的数据采集方法及分布式数据系统的相关内容。
二、数据采集方法1. 批量数据采集批量数据采集是指定时定量地从数据源中采集数据。
常见的批量数据采集方法包括定时任务、ETL工具等。
定时任务可以通过设置定时器,在指定时间点触发数据采集任务;ETL工具可以通过配置数据源和目标数据集,实现数据的抽取、转换和加载。
2. 实时数据采集实时数据采集是指数据在产生的同时进行采集和处理。
实时数据采集通常采用流式处理技术,如Apache Kafka、Apache Flink等。
流式处理技术可以实时接收和处理数据流,保证数据的实时性和准确性。
3. 增量数据采集增量数据采集是指只采集发生变化的数据,而不是全量数据。
增量数据采集可以减少数据传输和存储的成本。
常见的增量数据采集方法包括使用数据库的触发器、轮询等。
触发器可以在数据发生变化时触发采集任务;轮询可以定时查询数据源,判断是否有新的数据产生。
4. 分布式数据采集分布式数据采集是指在分布式环境下进行数据采集。
分布式数据采集需要考虑数据的一致性和并发性。
常见的分布式数据采集方法包括数据分片、数据复制等。
数据分片可以将数据分散存储在多个节点上,提高系统的并发性;数据复制可以将数据复制到多个节点上,提高系统的可用性。
三、分布式数据系统分布式数据系统是由多个节点组成的系统,每一个节点都可以存储和处理数据。
分布式数据系统可以提供高可用性、高性能和可扩展性。
常见的分布式数据系统包括Hadoop、Spark等。
1. HadoopHadoop是一个开源的分布式数据存储和处理框架,它基于Google的MapReduce和Google File System(GFS)论文。
His数据采集查询系统数据字典(表名更改)
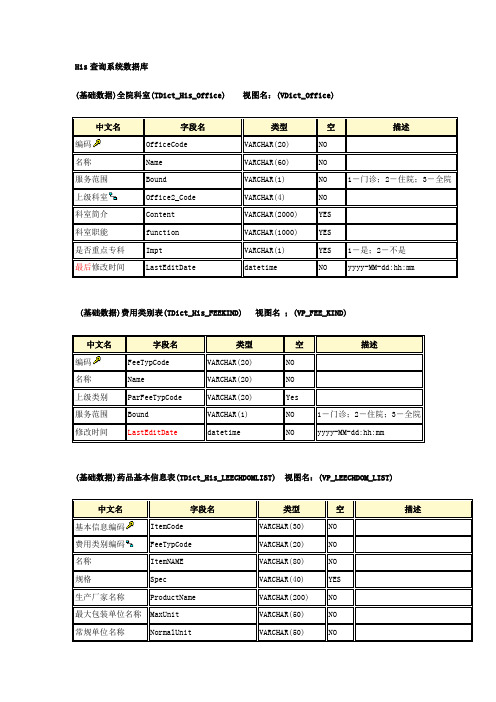
His查询系统数据库(基础数据)全院科室(TDict_His_Office) 视图名:(VDict_Office)中文名字段名类型空描述编码OfficeCode VARCHAR(20) NO名称Name VARCHAR(60) NO服务范围Bound VARCHAR(1) NO 1-门诊;2-住院;3-全院上级科室Office2_Code VARCHAR(4) NO科室简介Content VARCHAR(2000) YES科室职能function VARCHAR(1000) YES是否重点专科Impt VARCHAR(1) YES 1-是;2-不是最后修改时间LastEditDate datetime NO yyyy-MM-dd:hh:mm(基础数据)费用类别表(TDict_His_FEEKIND) 视图名;(VP_FEE_KIND)中文名字段名类型空描述编码FeeTypCode VARCHAR(20) NO名称Name VARCHAR(20) NO上级类别ParFeeTypCode VARCHAR(20) Yes服务范围Bound VARCHAR(1) NO 1-门诊;2-住院;3-全院修改时间LastEditDate datetime NO yyyy-MM-dd:hh:mm(基础数据)药品基本信息表(TDict_His_LEECHDOMLIST) 视图名:(VP_LEECHDOM_LIST)中文名字段名类型空描述基本信息编码ItemCode VARCHAR(30) NO费用类别编码FeeTypCode VARCHAR(20) NO名称ItemNAME VARCHAR(80) NO规格Spec VARCHAR(40) YES生产厂家名称ProductName VARCHAR(200) NO最大包装单位名称MaxUnit VARCHAR(50) NO常规单位名称NormalUnit VARCHAR(50) NO最小单位名称MinUnit VARCHAR(50) NO剂量单位名称DosageUnit VARCHAR(50) NO是否有毒Indicat1 VARCHAR(1) NO 1-是;2-不是是否麻醉Indicat2 VARCHAR(1) NO 1-是;2-不是是否放射Indicat3 VARCHAR(1) NO 1-是;2-不是是否精神Indicat4 VARCHAR(1) NO 1-是;2-不是是否贵重Indicat5 VARCHAR(1) NO 1-是;2-不是是否可拆分Indicat6 VARCHAR(1) NO 1-是;2-否货源情况GoogsSource VARCHAR(1) YES 1-充足;2-紧张;3-缺货批准文号PassNum VARCHAR(40) YES生产来源ProSource VARCHAR(1) YES 1-国产;2-进口;3-自制;4-招标药品类型MidKind VARCHAR(1) NO 1-西;2-成;3-草;4-检查治疗项目;9-其他医保类型MEDICARE_KIND_CODE VARCHAR(20) YES修改时间LastEditDate datetime NO yyyy-MM-dd:hh:mm(基础数据)全院职工表(TDict_His_EMPLOYEE) 视图名:(VP_EMPLOYEE)中文名字段名类型空描述编码DocID VARCHAR(20) NO名称DocName VARCHAR(30) NO性别SexCode VARCHAR(1) NO 1-男;2-女出生日期Birthday DATE NO所属科室OfficCode VARCHAR(4) YES卫生机构类型代码OrgTypCode Varchar(20) A100 综合医院C210中心卫生院C220乡卫生院J400预防保健中心K100卫生监督所(局)P939其他身份证件种类CartifTyp Varchar(10) 1 身份证2 军官证学历名称GRADEName VARCHAR(0、6) YES人员类型EmploueeType VARCHAR(2) YES 01-医生;02-护士;03-药剂师;04-技师;05-行政;06-后勤;专家简介Content VARCHAR(3000) YES个人照片Pic image YES是否推荐专家IS_TOP VARCHAR(1) NO 是否推荐专家1-是推荐专家;2-专家;3-非专家修改时间LastEditDate datetime NO yyyy-MM-dd:hh:mm(业务数据)门诊病人就诊主表(TData_His_PatOPDMat) 视图名:(VData_PatOPDMat)中文名字段名类型空描述POPDID VARCHAR(18) NO病人就诊流水号ID号医疗卡号CardID VARCHAR(18) YES农合证号CoopMedCode Varchar(20) Yes家庭序号FamNo Varchar(10) Yes姓名Name VARCHAR(20) NO性别Sex VARCHAR(1) NO 1-男;2-女;9-不定出生日期Brithday DATE YES家庭住址ADDRESS VARCHAR(40) YES籍贯NATIVE_PLACE VARCHAR(40) YES在职情况WORK_TYPE VARCHAR(1) YES 1-退养;2-离休;3-退休;4-在职;5-在校大学生;9-其他身份证号IDCARD VARCHAR(18) YES门诊病历号CASEHISTORY_ID VARCHAR(10) YES婚姻状况MARRiageCODE VARCHAR(6) YES就诊时间VisDate VARCHAR(18) YES总金额TotalFee Numeric(18,4) YES自费金额SelfFee Numeric(18,4) YES报销金额FreeFee Numeric(18,4) YES精度额RoFee Numeric(18,4) Yes疾病编码IllCode Varchar(20) Yes 编码为ICD-10编码疾病名称IllName Varchar(60) Yes报销类型FreeType Varchar(1) Yes 1—新农合 2-职工医保 3-居民医保 4-全自费为空默认为全自费修改时间LastEditDate datetime NO yyyy-MM-dd:hh:mm(业务数据)门诊病人就诊明细表(TData_His_PatOPDDet) 视图名;(VData_PatOPDDet)中文名字段名类型空描述POPDID VARCHAR(18) NO病人就诊流水号ID号序号SeqNum Varchar(18) No项目编号ItemCode VARCHAR(18) YES项目名称ItemName Varchar(50) YES规格GG VARCHAR(40) YES数量ItemNum Numeric(18,4) YES单位Unit Varchar (40) YES单价Price Numeric(18,4) YES金额Fee Numeric(18,4) YES医生编码DocCode VARCHAR(20) Yes医生名称DocName Varchar(30) Yes修改时间LastEditDate datetime NO yyyy-MM-dd:hh:mm(业务数据)住院病人基本信息(TData_His_PatHosClinMat) 视图名: (VData_PatHosClinMat)中文名字段名类型空描述PHOCID VARCHAR(18) NO病人住院流水号ID号住院号PATIENT_NO VARCHAR(10) NO医疗卡号CardID VARCHAR(18) YES农合证号CoopMedCode Varchar(20) Yes家庭序号FamNo Varchar(10) Yes报销类型FreeType Varchar(1) Yes 1—新农合 2-职工医保 3-居民医保 4-全自费为空默认为全自费住院病案号CASEHISTORY_NO VARCHAR(8) YES 后四位是住院次数,前面的是住院病案号住院次数IN_ORDER NUMERIC(2, 0) NO姓名NAME VARCHAR(20) NO性别SEX VARCHAR(1) NO 1-男,2-女,9-未知年龄AGE NUMERIC(3, 0) YES 出生到28天以内计为D,28天:12个月计为M,一岁以上计为Y年龄单位AGE_UNIT VARCHAR(1) YES Y:岁;M:月; D:天出生日期BIRTHDAY DATE YES婚姻状况MARRAGEName VARCHAR(50) YES职业JOBName VARCHAR(50) YES出生地NATIVATE_CODE VARCHAR(50) YES国籍COUNTRYName VARCHAR(50) YES民族NATIONName VARCHAR(50) YES籍贯NATIVEName VARCHAR(50) YES 籍贯,到县一级身份证号ID_CARD VARCHAR(18) YES工作单位、地址ADDRESS1 VARCHAR(40) YES电话(工作单位) PHONE1 VARCHAR(20) YESZIP1 VARCHAR(6) YES邮政编码(工作单位)户口地址ADDRESS2 VARCHAR(40) YES电话(户口) PHONE2 VARCHAR(20) YES入院日期IN_DAY_DATE DATE NO入院科室IN_OFFICE_CODE VARCHAR(20) YES入院病区IN_WARD_CODE VARCHAR(20) YES当前科室CURR_OFFICE_CODE VARCHAR(20) YES当前病区CURR_WARD_CODE VARCHAR(20) YES出院日期OUT_DAY_DATE DATE YES出院科室OUT_OFFICE_CODE VARCHAR(20) YES出院病区OUT_WARD_CODE VARCHAR(20) YES转科科室CHANGE_OFFICE_CODE VARCHAR(20) YES住院天数AT_HOSPTIAL_DAY_AMOUNT NUMERIC(6, 0) YES门诊诊断MZ_ICD10VARCHAR(10) YES门诊诊断名称MZ_ICD10Name Varchar(60) Yes入院时情况STYLE_IN VARCHAR(1) YES 1:危;2:急;3:一般入院诊断RY_ICD10VARCHAR(20) YES入院诊断名称RY_ICD10Name Varchar(60) Yes确诊日期DIAGNOSE_DATE DATE YES主要诊断MOSTLY_ICD10VARCHAR(10) YES主诊断附加编码MOSTLY_SICD10 VARCHAR(10) YES出院转归OUT_STATUS VARCHAR(1) YES 1-治愈;2:好转;3:未愈;4:死亡;5:其它科主任OFFICE_DIRECTOR_CODE VARCHAR(20) YES主任(副)医师DIRECTOR_DOCTOR_CODE VARCHAR(20) YES主治医师LEADING_DOCTOR_CODE VARCHAR(20) YESVARCHAR(20) YES住院医师HOSPITALZATION_DOCTOR_CODE费用总额SUM_FEE NUMERIC(12, 2) NO自费费用总额SUM_MUST_FEE NUMERIC(12, 2) NO其它费用总额SUM_OTHER_FEE NUMERIC(12, 2) NO当前费用总额CURR_FEE NUMERIC(12, 2) NO当前自费费用CURR_MUST_FEE NUMERIC(12, 2) NO当前其它费用CURR_OTHER_FEE NUMERIC(12, 2) NO入院途径IN_TYPE VARCHAR(1) YES 1:门诊;2:急诊;3:转院外院治疗IS_OTHER_THERAPY VARCHAR(1) YES 1:有;2:无出院方式OUT_TYPE VARCHAR(1) YES 1:常规;2:自动;3:转院治疗类别THERAPY_TYPE VARCHAR(10) YES 1:中;2:西;3:中西门诊中医病症MZ_CCD_BZ VARCHAR(10) YES门诊中医症候MZ_CCD_ZH VARCHAR(10) YES门诊中医诊断医生MZ_DOCTOR_CODE_CHINESE VARCHAR(8) YES入院中医病症RY_CCD_ZH VARCHAR(10) YES主要病症MOSTLY_CCD_BZ VARCHAR(10) YES主要症候MOSTLY_CCD_ZH VARCHAR(10) YES中医出院转归OUT_STATUS_CHINESE VARCHAR(1) YES 1-治愈;2:好转;3:未愈;4:死亡;5:其它出院标志OUT_FLAG VARCHAR(1) YES 1:在院;2:护士通知出院;3:已出院修改时间LastEditDate datetime NO yyyy-MM-dd:hh:mm(业务数据)住院病人就诊明细表(TData_His_PatHosClinDet) 视图名:(VData_PatHosClinDet)中文名字段名类型空描述PHOCID VARCHAR(18) NO病人就诊流水号ID号序号SeqNum Varchar(18) No执行时间ExecDate DateTime Yes项目编号ItemCode VARCHAR(18) YES项目名称ItemName Varchar(50) YES规格GG VARCHAR(40) YES数量ItemNum Numeric(18,4) YES单位Unit Varchar (40) YES单价Price Numeric(18,4) YES金额Fee Numeric(18,4) YES医生编码DocCode VARCHAR(18) NO医生名称DocName Varchar(30)修改时间LastEditDate datetime NO yyyy-MM-dd:hh:mm注:以上信息视图如果没有(TIMEFLAG)修改时间,那么TIMEFLAG取值为录入时间.(业务统计)医院接诊统计表(TData_His_Stat_SerPerTrip) 视图名:(VStat_SerPerTrip) 中文名字段名类型空描述接诊科室OfficeCode VARCHAR(20) NO接诊日期VisDate Date No门诊接诊数量OPDNum Numer(18,0) Yes入院接诊数量OutHosNum Numer(18,0) Yes在院病人数量InHosNum Numer(18,0) Yes出院患者数OutPerNUm Numer(18,0) Yes(业务统计)门诊收入统计表(TData_His_Stat_SerFee) 视图名: (VStat_SerFee)中文名字段名类型空描述接诊编码OfficeCode VARCHAR(20) NO接诊日期VisDate Date No费用类别FeeTypCode VARCHAR(20) No门诊金额OPDFee Numer(18,4) Yes住院金额OutHosFee Numer(18,4) Yes。
数据采集系统原理

数据采集系统原理
数据采集系统是一种用于收集和记录各种数据的系统。
其原理是通过各种传感器、设备和计算机程序来获取数据,并将其存储和处理以供后续分析和应用。
数据采集系统的工作原理包括以下几个步骤:
1. 传感器选择和安装:根据所需采集的数据类型,选择适当的传感器并安装在被监测的对象或环境中。
常见的传感器包括温度传感器、湿度传感器、压力传感器、光传感器等。
2. 信号转换和处理:传感器将物理量转换为电信号,然后经过放大、滤波和模数转换等处理,将信号转换为数字形式以方便后续处理。
这一步骤还可以进行数据校验和纠错等操作,以提高数据的准确性和可靠性。
3. 数据存储和传输:采集到的数据可以通过有线或无线通信方式传输给数据采集系统的中央处理单元。
中央处理单元将数据存储在数据库中,以便后续的查询和分析。
数据存储可以采用关系型数据库或者分布式文件系统等方式。
4. 数据处理和分析:数据采集系统可以对采集到的数据进行实时处理和分析,以提取有用的信息并进行决策支持。
常见的数据处理方法包括数据清洗、数据挖掘、统计分析和机器学习等。
5. 数据可视化和报表生成:将数据处理结果以可视化的方式展示出来,可以通过图表、图形和报表等形式展示给用户。
数据
可视化可以帮助用户更直观地理解和分析数据,从而做出相应的决策。
总之,数据采集系统通过传感器获取数据,经过信号转换和处理后存储和传输数据,然后通过数据处理和分析提取有用的信息,并通过数据可视化展示给用户。
这样的系统在许多领域,如工业监控、环境监测和物联网等方面具有广泛的应用。
数据采集系统设计方案

数据采集系统设计方案1. 引言在当前信息爆炸的时代,数据已成为企业决策和业务发展的重要支撑。
为了能够获得准确、及时、完整的数据,建立一个高效的数据采集系统至关重要。
本文将介绍一个数据采集系统的设计方案,旨在帮助企业快速搭建一个可靠的数据采集系统。
2. 系统架构数据采集系统主要由以下几个模块组成:2.1 数据源模块数据源模块负责与各个数据源进行连接,并提供数据抓取的功能。
根据具体需求,可以包括数据库、文件系统、API等各种数据源。
2.2 数据处理模块数据处理模块负责对采集到的原始数据进行清洗、去重、转换等处理操作,以便后续分析和存储。
2.3 数据存储模块数据存储模块负责将处理后的数据存储到数据库、数据仓库或数据湖等存储介质中,以便后续的数据分析和挖掘。
2.4 监控和日志模块监控和日志模块负责监控系统的运行状态,并记录系统的运行日志,以便后续的故障排查和系统性能优化。
2.5 定时任务模块定时任务模块负责定期执行数据采集任务,可以使用定时调度工具来实现。
3. 系统设计与实现3.1 数据源模块的设计数据源模块可以使用不同的技术栈来实现,例如使用Python的Requests库连接API,使用JDBC或ORM框架连接数据库,使用文件操作库连接文件系统。
3.2 数据处理模块的设计数据处理模块的设计需要根据具体的业务需求来确定。
常见的处理操作包括数据清洗(去除重复数据、缺失值处理等)、数据转换(格式转换、字段合并等)等。
3.3 数据存储模块的设计数据存储模块可以选择合适的数据库或数据仓库来存储处理后的数据。
常见的选择包括关系型数据库(如MySQL、PostgreSQL)和大数据存储系统(如Hadoop、Spark)等。
3.4 监控和日志模块的设计监控和日志模块可以使用监控工具和日志框架来实现。
监控工具可以监控系统的资源使用情况,例如CPU、内存、磁盘等。
日志框架可以记录系统的运行日志,有助于故障排查和系统性能优化。
AO系统采集天大天财数据库数据方法与技巧

AO系统采集天大天财数据库数据方法与技巧近日,我市开展了某高校领导人经济责任审计。
该校使用的财务软件为天大天财财务软件,但我们将其财务软件备份后导入AO时发现,该备份数据与天大天财转换模板均不匹配。
总是出现“数据源不匹配”错误提示。
不能成功的导入AO。
因此,我们采用了数据库数据采集方法来加以实现。
鉴于天大天财财务软件已广泛应用于高等院校和中小学校,笔者将其采集转换过程加以整理,供审计同仁参考。
一、取得原始数据库数据通过调查了解得知,天大天财财务软件后台数据库为SQLServer2000,财务数据分年度存储,每年年末单独建立一个数据库,以“cw_2011”等命名。
我们通过数据库备份方式取得了该校2008-2011年四个年度的数据库数据备份文件。
二、数据分析与整理取得原始数据后,我们通过还原数据库方法在审计人员计算机设备上利用SQL2008进行数据库还原,并进行数据分析。
通过分析,我们发现该校凭证表由”凭证主表”和”凭证分录表”组成。
由此,我们确定了本次数据采集所需的四张表,即“zwkmzd-科目表”、“zwkmje-科目余额表”、“zwpzfl-凭证分录表”、“zwpzb-凭证主表”。
(一)各表所需字段zwkmzd-科目表,所需字段:kmbh-科目编码,kmmc-科目名称,yefx-余额方向;zwkmje-科目余额表,所需字段:kmbh-科目编码,ncye-年初余额;zwpzb-凭证主表,所需字段:pzrq-凭证日期,pzbh-凭证编号;zwpzfl-凭证分录表,所需字段:kmbh-科目编号,zy-摘要,jje-借方发生额,dje-贷方发生额。
(二)各表之间关系1、通过科目表与科目余额表中的“科目编码”关联,将“余额方向”字段引入科目余额表中生成新的科目余额表;2、通过凭证主表与凭证分录表中的“pznm-凭证内码”字段关联,将“凭证日期”和“凭证编号”字段引入凭证分录表中生成新的凭证库表。
(三)数据整理1、科目表处理:会计科目表可以通过“科目”表直接查询生成。
数据采集系统方案

数据采集系统方案1. 引言数据采集是指通过各种手段收集、整理和记录各种类型的数据。
对于企业和组织来说,数据采集是非常重要的,它能够帮助企业做出准确的决策、分析市场趋势和优化业务流程等。
本文将介绍一个数据采集系统方案,该方案可以帮助企业高效、准确地采集和管理数据。
2. 方案概述本方案基于云计算平台,采用分布式架构实现数据采集和存储,并通过前端界面展示数据。
具体方案如下:•使用云服务器作为计算和存储资源,实现数据的采集和处理。
•采用分布式系统架构,将数据分散存储在不同的节点上,提高系统的可靠性和可扩展性。
•使用数据库管理系统存储和管理数据。
•通过前端界面展示数据,提供交互操作和数据分析功能。
3. 系统组成本系统包含以下几个组成部分:3.1 数据采集模块数据采集模块负责从各种数据源采集数据,并进行预处理和清洗。
具体功能包括:•支持多种数据源,如传感器设备、日志文件、数据库等。
•提供数据预处理和清洗功能,包括数据去重、数据格式转换等。
•支持自定义采集规则,可根据需求定制采集策略。
3.2 数据存储模块数据存储模块负责将采集到的数据存储到数据库中,并提供数据管理功能。
具体功能包括:•使用分布式数据库管理系统,实现数据的高可用和可扩展性。
•提供数据的存储和读取接口,支持对数据的增删改查操作。
•支持备份和恢复数据,保证数据的安全性和可靠性。
3.3 数据展示模块数据展示模块负责将存储在数据库中的数据展示给用户,并提供交互操作和数据分析功能。
具体功能包括:•设计用户友好的前端界面,展示数据表格、图表等形式。
•支持数据的搜索、过滤和排序功能,方便用户查找和分析数据。
•提供数据分析和统计功能,帮助用户做出准确的决策。
4. 技术实现本方案使用以下技术和工具实现:•云服务器:使用云计算平台提供的虚拟服务器,满足计算和存储需求。
•分布式数据库:使用开源的分布式数据库管理系统,如Cassandra、HBase等。
•数据采集工具:使用Python等编程语言编写数据采集脚本,实现数据采集和预处理功能。
实时数据库及数据采集

实时数据库及数据采集在当今数字化的时代,数据如同血液一般在企业和组织的运营中流淌。
而实时数据库和数据采集技术,则是确保这一血液能够新鲜、快速、准确地输送到各个关键部位的重要手段。
实时数据库,简单来说,就是能够实时处理和存储数据的数据库系统。
它与传统数据库的最大区别在于其对数据的处理速度和时效性要求极高。
在一些对数据实时性要求严格的场景,如工业控制、金融交易、物联网等领域,实时数据库发挥着至关重要的作用。
想象一下一个现代化的工厂生产线,各种传感器和设备在不停地工作,产生大量的数据,包括温度、压力、速度、产量等等。
这些数据需要在瞬间被采集、处理和分析,以便及时发现生产中的问题,调整生产参数,确保产品质量和生产效率。
如果使用传统的数据库,可能会因为数据处理的延迟而导致生产故障或者效率低下。
而实时数据库能够在毫秒甚至微秒级的时间内完成数据的存储和查询,为生产的实时监控和优化提供了有力支持。
数据采集则是获取这些原始数据的过程。
它就像是数据世界的“采集者”,负责从各种数据源中收集数据,并将其传递给后续的处理环节。
数据采集的方式多种多样,常见的有传感器采集、网络爬虫、文件导入等。
传感器采集是工业领域中最为常见的数据采集方式之一。
例如,在汽车制造中,通过安装在车辆各个部位的传感器,可以实时采集车速、发动机转速、油温等数据。
这些传感器将物理量转换为电信号,再通过数据采集设备将其转换为数字信号,最终传输到实时数据库中。
网络爬虫则主要用于从互联网上获取数据。
比如,一些电商平台通过爬虫技术获取竞争对手的产品价格、销量等信息,以便制定更有竞争力的营销策略。
文件导入则适用于已经存在的大量数据文件,如Excel 表格、CSV 文件等,将这些数据一次性导入到数据库中进行处理。
在实际应用中,实时数据库和数据采集往往是紧密结合的。
一个高效的数据采集系统能够为实时数据库提供源源不断的新鲜数据,而实时数据库则能够快速处理和存储这些数据,为后续的分析和应用提供支持。
实时数据库与SCADA究竟有什么区别

引言概述:实时数据库与SCADA(监控、控制与数据采集系统)是工业自动化领域中常见的两个概念。
尽管它们都涉及到数据存储和处理,但两者之间存在明显的区别和不同的应用场景。
在本文的第一部分中,我们已经介绍了实时数据库和SCADA的基本概念及其区别。
在本文的第二部分,将更加详细地探讨实时数据库与SCADA之间的区别。
正文内容:1.实时数据库与SCADA的基本定义实时数据库是指能够提供高性能的数据存储和实时读写操作的数据库系统。
它通常用于处理需要快速响应的实时数据,例如传感器数据、监控数据等。
SCADA是一种监控、控制与数据采集系统,它通过传感器和执行器收集实时数据,并通过图形界面实时展示设备状态和操作控制。
SCADA系统通常与其他系统(如PLC)集成,用于监控和控制工业过程。
2.实时数据库与SCADA的数据模型实时数据库通常采用表格形式的数据模型,类似于传统关系型数据库。
它支持复杂的查询和事务处理,并且保证数据的可靠性和一致性。
SCADA系统通常使用标签(tag)的数据模型,每个标签代表一个变量或一个设备状态。
这种模型简单易用,适合实时监控和控制应用。
3.实时数据库与SCADA的数据存储方式实时数据库通常使用内存数据库或者混合存储(内存和磁盘)方式存储数据,以满足高速读写和实时性的要求。
SCADA系统通常将数据存储在历史数据库中,用于后续数据查询和分析。
历史数据库可以使用文件系统、关系型数据库或者时间序列数据库进行存储。
4.实时数据库与SCADA的数据采集和处理能力实时数据库具有较高的数据采集和处理能力,可以处理大量的实时数据并提供高性能的数据查询和分析。
SCADA系统在数据采集和处理方面更加强调实时性和响应性能力,通常实时读取和更新数据,并对数据进行简单的计算和转换。
5.实时数据库与SCADA的应用场景实时数据库广泛应用于工业自动化、物流、安防监控等领域,用于处理实时监控数据、传感器数据、交易数据等。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
create table treaty_table ( TID INT identity(1,1, Tname varchar(20, F-route varchar(50, period int, filename varchar(50, Type_ID INT, constraint
PK_TREATY_TABLE primary key (TID create table type_table ( Type_ID INT identity(1,1, typename varchar(20, bourse varchar(40, constraint PK_TYPE_TABLE primary key (Type_ID ; create table CY_table ( CY_ID INT identity(1,1, MF varchar(20, pt datetime, Type_ID INT, constraint PK_CY_TABLE primary key (CY_ID ; create table Time_table ( Time_ID INT identity(1,1, DATE DATETIME, constraint
PK_TIME_TABLE primary key (Time_ID ; create table K_table ( Root_ID INT identity(1,1, Type_ID INT, period INT, date datetime, rootnum INT, constraint
PK_K_TABLE primary key (Root_ID ; create table Min1_table ( Min1_ID INT identity(1,1, treaty_name varchar(20, date datetime, open money, Close money, Heigh money, low money, Vol money, OPI money, S money, constraint PK_MIN1_TABLE primary key (Min1_ID ; create table Min5_table ( Min5_ID INT identity(1,1,
treaty_name varchar(20, date datetime, open money, Close money, Heigh money, low money, Vol money, OPI money, S money, constraint PK_MIN1_TABLE primary key (Min5_ID ; create table Min15_table ( Min15_ID INT identity(1,1, treaty_name varchar(20, date datetime, open money, Close money, Heigh money, low money, Vol money, OPI money, S money, constraint PK_MIN1_TABLE primary key (Min15_ID ; create table Min30_table ( Min30_ID INT identity(1,1, treaty_name varchar(20, date datetime, open money, Close money, Heigh money, low money, Vol money, OPI money, S money, constraint PK_MIN1_TABLE primary key (Min30_ID ; create table
Hour1_table ( H
our1_ID INT identity(1,1, treaty_name varchar(20, date datetime, open money, Close money, Heigh money, low money, Vol money, OPI money, S money, constraint PK_MIN1_TABLE primary key (Hour1_ID ; create table Hour4_table ( Hour4_ID INT identity(1,1, treaty_name varchar(20, date datetime, open money, Close money, Heigh money, low money, Vol money, OPI money, S money, constraint PK_MIN1_TABLE primary key (Hour4_ID ; create table Day_table ( Day_ID INT identity(1,1, treaty_name
varchar(20, date datetime, open money, close money, heigh money, low money, OPI money, S money, constraint PK_DAY_TABLE primary key (Day_ID ; create table Week_table ( Week_ID INT identity(1,1, treaty_name varchar(20, date datetime, open money, close money, heigh money, low money, OPI money, S money, constraint
PK_DAY_TABLE primary key (Week_ID ; create table Year_table ( Year_ID INT identity(1,1, treaty_name varchar(20, date datetime, open money, close money, heigh money, low money, OPI money, S money, constraint PK_DAY_TABLE primary key (Year_ID ; create table Tick_table ( Tick_ID INT identity(1,1, treaty_name varchar(20, date datetime, VOM money, SH money, SOPI money, constraint PK_TICK_TABLE primary key (Tick_ID ; create table SEC10_table ( SEC_ID INT identity(1,1,
treaty_name varchar(20, date datetime, VOM money, SH money, SOPI money, constraint PK_TICK_TABLE primary key (SEC_ID ;。