ARIMA预测原理以及SAS实现代码
基于ARIMA模型的网络流时间序列预测

基于ARIMA模型的网络流时间序列预测网络流量的时间序列预测在当今信息化社会中具有重要的意义。
准确地预测网络流量的变化趋势可以帮助网络管理员更好地规划网络资源分配,提供良好的用户体验和服务质量。
近年来,自回归综合移动平均模型(ARIMA)已成为网络流时间序列预测的一种常用方法。
本文将重点讨论基于ARIMA模型的网络流时间序列预测。
一、ARIMA模型的基本原理ARIMA模型是一种常用的时间序列预测模型,适用于具有确定性趋势和具有自回归和移动平均性质的时间序列数据。
ARIMA模型可以拆解时间序列数据的趋势、季节性和随机性等元素,从而进行准确的预测。
ARIMA模型有三个参数:自回归阶数(p)、差分阶数(d)和移动平均阶数(q)。
其中,p代表自回归项的数量,d代表差分的数量(用于消除非平稳性),q代表移动平均项的数量。
通过分析时间序列数据的自相关图(ACF图)和偏自相关图(PACF图),可以确定ARIMA模型的参数。
二、网络流时间序列预测步骤网络流时间序列预测主要包括以下步骤:1. 数据收集与预处理:收集网络流量的历史数据并进行预处理,包括去除异常值和缺失值的处理。
2. 模型拟合与参数估计:通过分析ACF图和PACF图,确定ARIMA模型的参数,并利用历史数据进行模型的拟合和参数的估计。
3. 模型诊断:对拟合后的ARIMA模型进行残差分析,检验模型是否符合预测要求。
4. 模型预测与评估:利用已确定的ARIMA模型进行未来网络流量的预测,并利用预测结果进行模型的评估。
三、实验结果与讨论本文选取某企业网络流量数据作为实验对象,利用ARIMA模型对未来一周的网络流量进行预测。
通过拟合ARIMA模型,得到了最优的模型参数,并根据历史数据进行了预测。
结果显示,ARIMA模型对网络流量数据的预测效果良好。
预测结果与实际观测值之间的误差较小,预测趋势与实际趋势基本一致。
这表明基于ARIMA模型的网络流时间序列预测方法具有一定的准确性和可行性。
ARIMA模型原理以及代码实现案例

ARIMA模型原理以及代码实现案例⼀、时间序列分析北京每年每个⽉旅客的⼈数,上海飞往北京每年的游客⼈数等类似这种顾客数、访问量、股价等都是时间序列数据。
这些数据会随着时间变化⽽变化。
时间序列数据的特点是数据会随时间的变化⽽变化。
随机过程的特征值有均值、⽅差、协⽅差等。
如果随机过程的特征随时间变化⽽变化,那么数据是⾮平稳的,相反,如果随机过程的特征随时间变化⽽不变化,则此过程是平稳的。
如图所⽰:⾮平稳时间序列分析时,若导致⾮平稳的原因是确定的,可以⽤的⽅法主要有趋势拟合模型、季节调整模型、移动平均、指数平滑等。
若导致⾮平稳的原因是随机的,⽅法主要有ARIMA,以及⾃回归条件异⽅差模型等。
⼆、ARIMA1、简介ARIMA通常⽤于需求预测和规划中。
可以⽤来对付随机过程的特征随着时间变化⽽⾮固定。
并且导致时间序列⾮平稳的原因是随机⽽⾮确定的。
不过,如果从⼀个⾮平稳的时间序列开始,⾸先需要做差分,直到得到⼀个平稳的序列。
模型的思想就是从历史的数据中学习到随时间变化的模式,学到了就⽤这个规律去预测未来。
ARIMA(p,d,q)d是差分的步长(差分的阶数指的是进⾏多少次差分。
⽐如步长为n的⼀阶差分diff(x) = f(x) - f(x - n),⽽⼆阶步长为n的差分: diff(x) = f(x) - f(x-n), diff(x-n) = f(x-n) - f(x - n - n), diff⼆阶差分(x - n) = diff(x) - diff(x-n)),⽤来得到平稳序列p为相应的⾃回归项q是移动平均项数2、⾃回归模型AR⾃回归模型描述当前值与历史值之间的关系,⽤变量⾃⾝的历史时间数据对⾃⾝进⾏预测。
⾃回归模型必须满⾜平稳性。
⾃回归模型需要先确定⼀个阶数p,表⽰⽤⼏期的历史值来预测当前值。
p阶⾃回归模型可以表⽰为:y t是当前值,u是常数项,p是阶数,r是⾃相关系数,e是误差AR的限制:⾃回归模型是⾃⾝的数据进⾏预测必须具有平稳性必须具有相关性如果⾃相关系数⼩⾬0.5,则不宜采⽤⾃回归只适⽤于预测与⾃⾝前期相关的现象3、移动平均模型MA移动平均模型关注的⾃回归模型中的误差项的累加,q阶⾃回归过程的公式定义如下:移动平均模型能有效地消除预测中的随机波动4、⾃回归移动平均模型ARMA⾃回归模型AR和移动平均模型MA模型相结合,我们就得到了⾃回归移动平均模型ARMA(p,q),计算公式如下:5、p、q的确定 (1) (2)结合最终的预测误差来确定p、q的阶数,在相同的预测误差情况下,根据奥斯卡姆剃⼑准则,模型越⼩越好。
SAS学习系列39. 时间序列分析Ⅲ—ARIMA模型

39. 时间序列分析Ⅱ——ARIMA 模型随着对时间序列分析方法的深入研究,人们发现非平稳序列的确定性因素分解方法(如季节模型、趋势模型、移动平均、指数平滑等)只能提取显著的确定性信息,对随机性信息浪费严重,同时也无法对确定性因素之间的关系进行分析。
而非平稳序列随机分析的发展就是为了弥补确定性因素分解方法的不足。
时间序列数据分析的第一步都是要通过有效手段提取序列中所蕴藏的确定性信息。
Box 和Jenkins 使用大量的案例分析证明差分方法是一种非常简便有效的确定性信息的提取方法。
而Gramer 分解定理则在理论上保证了适当阶数的差分一定可以充分提取确定性信息。
(一)ARMA 模型即自回归移动平均移动模型,是最常用的拟合平稳时间序列的模型,分为三类:AR 模型、MA 模型和ARMA 模型。
一、AR(p )模型——p 阶自回归模型 1. 模型:011t t p t p t x x x φφφε--=+++其中,0p φ≠,随机干扰序列εt 为0均值、2εσ方差的白噪声序列(()0t s E εε=, t ≠s ),且当期的干扰与过去的序列值无关,即E(x t εt )=0.由于是平稳序列,可推得均值011pφμφφ=---. 若00φ=,称为中心化的AR (p )模型,对于非中心化的平稳时间序列,可以令01(1)p φμφφ=---,*t t x x μ=-转化为中心化。
记B 为延迟算子,1()p p p B I B B φφΦ=---称为p 阶自回归多项式,则AR (p )模型可表示为:()p t t B x εΦ=.2. 格林函数用来描述系统记忆扰动程度的函数,反映了影响效应衰减的快慢程度(回到平衡位置的速度),G j 表示扰动εt -j 对系统现在行为影响的权数。
例如,AR(1)模型(一阶非齐次差分方程),1, 0,1,2,j j G j φ==模型解为0t j t j j x G ε∞-==∑.3. 模型的方差对于AR(1)模型,2221()()1t jt j j Var x G Var εσεφ∞-===-∑. 4. 模型的自协方差对中心化的平稳模型,可推得自协方差函数的递推公式:用格林函数显示表示:200()()i j t j t k j j kj i j j k G G E GG γεεσ∞∞∞---+=====∑∑∑对于AR(1)模型,21121()(0)1k k k εσγφγφφ==- 5. 模型的自相关函数 递推公式:对于AR(1)模型,11()(0)k k k ρφρφ==.平稳AR(p )模型的自相关函数有两个显著的性质: (1)拖尾性指自相关函数ρ(k)始终有非零取值,不会在k 大于某个常数之后就恒等于零;(2)负指数衰减随着时间的推移,自相关函数ρ(k)会迅速衰减,且以负指数k iλ(其中i λ为自相关函数差分方程的特征根)的速度在减小。
ARIMA模型预测【范本模板】

ARIMA模型预测一、模型选择预测是重要的统计技术,对于领导层进行科学决策具有不可替代的支撑作用.常用的预测方法包括定性预测法、传统时间序列预测(如移动平均预测、指数平滑预测)、现代时间序列预测(如ARIMA模型)、灰色预测(GM)、线性回归预测、非线性曲线预测、马尔可夫预测等方法。
综合考量方法简捷性、科学性原则,我选择ARIMA模型预测、GM(1,1)模型预测两种方法进行预测,并将结果相互比对,权衡取舍,从而选择最佳的预测结果。
二ARIMA模型预测(一)预测软件选择-—--R软件ARIMA模型预测,可实现的软件较多,如SPSS、SAS、Eviews、R等。
使用R 软件建模预测的优点是:第一,R是世最强大、最有前景的软件,已经成为美国的主流。
第二,R是免费软件。
而SPSS、SAS、Eviews正版软件极为昂贵,盗版存在侵权问题,可以引起法律纠纷.第三、R软件可以将程序保存为一个程序文件,略加修改便可用于其它数据的建模预测,便于方法的推广。
(二)指标和数据指标是销售量(x),样本区间是1964-2013年,保存文本文件data。
txt中.(三)预测的具体步骤1、准备工作(1)下载安装R软件目前最新版本是R3。
1.2,发布日期是2014-10—31,下载地址是http://www。
r—/.我使用的是R3。
1.1。
(2)把数据文件data.txt文件复制“我的文档"①。
(3)把data.txt文件读入R软件,并起个名字。
具体操作是:打开R软件,输入(输入每一行后,回车):①我的文档是默认的工作目录,也可以修改自定义工作目录。
data=read.table("data.txt",header=T)data #查看数据①回车表示执行。
完成上面操作后,R窗口会显示:(4)把销售额(x)转化为时间序列格式x=ts(x,start=1964)x结果:2、对x进行平稳性检验ARMA模型的一个前提条件是,要求数列是平稳时间序列。
ARIMA模型在汽车销量预测中的应用及SAS实现

J AN1 1
J AN1 2
图 1 汽 车 销 量 时 间 序 列 曲 线 图
二 、 处 理 预
A I A 建 模 方 法 是 以序 列 的 平 稳 性 为 前 提 的 .因此 首 RM 先 要 把 非 平 稳 序 列 转 换 为平 稳序 列 针 对 原 始 时 间 序 列具 有 季 节 性 变 化 同 时 有 增 大 的趋 势 . 用 对 数 变 换 消 除增 幅越 来 先
6 34 04 8 59 02 1 .3 l .8 1 .7 .0l
1 1 .11 .6 8 59 0 1 8 5 - 2 73 00 7 1 .2 .01 731
< .o 1 00 O
经 过 拟 合 后 比 较 发 现 , R(, )MA(,2 通 过 了 检 A 11 , 2 1 ) 1
JN6 A 0
d t ae
J 0 AN 7
JN8 A 0
JN9 A 0
J N1 A 0
J Nl A 1
J 1 AN 2
圈圃 囡 2  ̄ 0 1 0 4 1 1 2
管 理 荟
一
l l
萃
詈
( ) KI 二 A MA( ,,) (, Q) pdq x pD, z
由于 存 在 季 节 性 . 短 期 相 关 性 和季 节性 之 间 具有 乘 积 且 效 应 , 试 使 用 乘 积 模 型 来 拟合 序列 的发 展 。 尝
差 范 围 . 明差 分 中仍 蕴 含 着 非 常 显 著 的 季 节 效 应 。延 迟 1 说 步 的 自相 关 系 数 也 大 于 2倍 标 准 差 . 说 明 差分 后 序 列 还 具 这 有 短 期 相 关 性
( ) KI 一 A MA(,, pdq )
ARIMA模型的参数估计与预测

ARIMA模型的参数估计与预测ARIMA模型是一种常用于时间序列分析和预测的统计模型。
它可以通过对历史时间序列数据的分析来估计未来的趋势和周期性。
在进行ARIMA模型的参数估计和预测之前,我们首先需要了解ARIMA模型的组成和基本原理。
ARIMA模型是由自回归(AR)、差分(I)、移动平均(MA)这三个部分组成的。
自回归部分表示当前值与一些过去值的相关关系,差分部分对时间序列进行平稳化处理,移动平均部分则表示当前值与过去观测误差的相关关系。
这三个部分的组合可以通过ARIMA(p,d,q)进行表示,其中p、d和q分别代表AR部分的阶数、差分部分的阶数和MA部分的阶数。
在进行ARIMA模型的参数估计时,我们首先需要确定模型的阶数。
一种常用的方法是通过观察自相关图(ACF)和偏自相关图(PACF)来选择合适的阶数。
ACF表示观测值与滞后值之间的相关性,PACF表示观测值与滞后值之间的纯相关性。
根据ACF和PACF的图形特征,我们可以识别出模型中的AR和MA部分的阶数。
确定模型阶数后,我们可以使用最大似然估计(MLE)方法对模型的参数进行估计。
MLE方法是一种常用的参数估计方法,通过最大化在观测值给定情况下参数的可能性来估计参数值。
在ARIMA模型中,MLE方法可以用来估计AR和MA模型中的系数。
通过最大似然估计,我们可以得到ARIMA模型的最佳参数估计值。
在进行ARIMA模型的预测时,我们可以使用模型的参数估计值和历史观测值来预测未来的值。
预测方法可以采用递归方式,即使用已知的观测值和模型参数来计算未知的观测值。
这样,我们可以根据已知的历史观测值来预测未来的趋势和周期性。
ARIMA模型的参数估计和预测可以应用于各种领域的时间序列数据分析,包括股票价格预测、经济指标分析、气象数据预测等。
通过对时间序列数据的建模和分析,我们可以预测未来的趋势和变化,为决策提供参考。
除了ARIMA模型,还有其他一些时间序列分析和预测的方法和模型,如指数平滑法、回归模型等。
ARIMA预测原理以及SAS实现代码
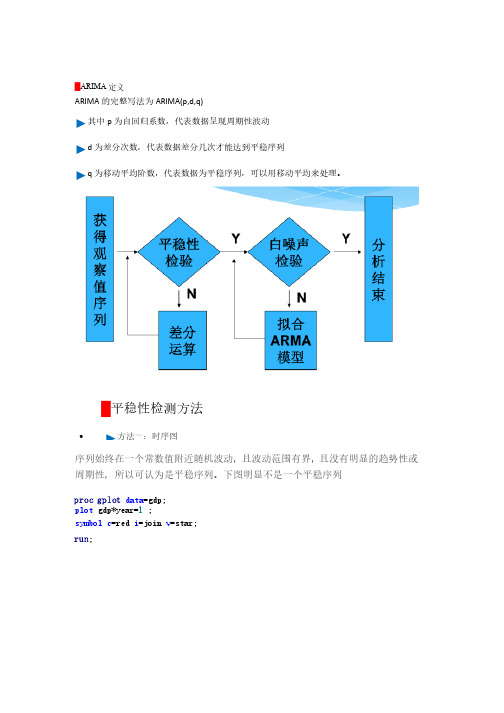
█ARIMA定义ARIMA的完整写法为ARIMA(p,d,q) ►其中p为自回归系数,代表数据呈现周期性波动►d为差分次数,代表数据差分几次才能达到平稳序列►q为移动平均阶数,代表数据为平稳序列,可以用移动平均来处理。
█平稳性检测方法·►方法一:时序图序列始终在一个常数值附近随机波动,且波动范围有界,且没有明显的趋势性或周期性,所以可认为是平稳序列。
下图明显不是一个平稳序列proc gplot data=gdp;plot gdp*year=1 ;=join v v=star;=red i i=joinsymbol c=redrun;·►方法二:自相关图自相关系数会很快衰减向0,所以可认为是平稳序列。
proc arima data= gdp;identify var=gdp=gdp stationaritystationarity =(adf=3)) nlagnlag=12; run;·►ADF单位根检验(精确判断)三个检验中只要有一个Pr<Rho小于0.05即可认定为平稳序列,主要是stationarity =(adf=3) 起作用起作用proc arima data= gdp;) nlagnlag=12;=gdp stationaritystationarity =(adf=3)identify var=gdprun;█白噪声检验白噪声检验Pr>卡方<0.05即可认定为通过白噪声检验。
proc arima data= gdp;) nlagnlag=12;stationarity =(adf=3)identify var=gdp=gdp stationarityrun;█非平稳序列转换为平稳序列方法一:将数据取对数。
方法一:将数据取对数。
函数 方法二:对数据取差分dif函数data gdp_log;set gdp;loggdp=log(gdp);cfloggdp=dif(loggdp);run;/**对数数据散点图**/proc gplot;plot loggdp*year=1 ;symbol c=black=join v v=star;=black i i=joinrun;/* 一阶差分对数数据散点图*/ proc gplot;plot cfloggdp*year=1;=dot i i=join; symbol c=green=green v v=dotrun;从上图中可以看出,一阶差分后序列已经变成平稳的了,因此,数列需要做一阶差分█转换完毕后再验证下面代码中的(1)就代表1阶差分,adf=3则代表平稳性检验0-3,/* 一阶差分对数数据的自相关图、偏自相关图、纯随机性检验、单位根检验 */ proc arima data=gdp_log;identify var=loggdp(1) ) stationaritynlag=12;stationarity =(adf=3) ) nlagrun;用Q LB 统计量作的c 2检验结果表明:对数差分后的GDP 序列的Q LB 统计量的P 值为0.0045(<0.05),故序列为非白噪声序列。
商 情 预 测 ARIMA (含SAS程序实例)

商情预测[ARIMA] 2012.11.16 廖崇廷整理以过去的观察值及干扰项(WHITE NOISE)来预测未来数值之方法一.ARIMA(p,d,q) = 连续性ARIMA= ARMA + 一般转移函数(或干预转移函数)EX:今年12月需考虑今年11月二.开列变数/回归式1. 决定符号±股价=F(货币供给,利率,汇率,开征证所税)+etY = F ( X, X, X,…. X) + e t反应变量自变量2. CHECK变量不重复(无共线性) 变量间相关系数矩阵之角对角在线下之值均< 0.8三.将序列数据绘图四.设定BOX-COX转换(直线/指数)1. 直线关系式: Y=f(X) 设定BOX-COX转换(直线/指数)因μ→1 直线型式可不必宣告λ→1 直线型式2. Log 关系式 :Log(Y)=Log(X)(1) 设定μ→0 指数型式μ= 0.01Xμ -1X0.01 -1X 作BOX-COX (即Log)转换X(μ)=-------- = ------------ = ㏒(X)μ0.01(2) 设定λ→0 指数型式λ= 0.01Yλ -1Y0.01 -1 Y 作BOX-COX (即Log)转换Y(λ)=-------- = ------------ = ㏒(Y)Λ 0.013. 进入ARIMA PROC*FILE 'C:\SAS\ARIMAT\STK;LIBNAME SAVE 'C:\SAS\ARIMAT\SASDATA';OPTION NONOTES NODATA LS=76 PS=60;%LET U=0.01;%LET L=0.01;%LET X=MS;%LET Y=SP;DATA D1;SET SAVE.STOCK;KEEP WEEK &X1 &X2 &X3 &Y;DATA D2;SET D1;&X=(&X**&U-1)/&U;&Y=(&Y**&L-1)/&L;PROC ARIMA;五.设定差分阶数及滤出AR/MA特质[找出序列之白噪音过程]IDENTIFY VAR=&Y(1) CROSSCORR=(&X(1)) NLAG=10;SAS程序撰写例:CHECK 残差项:自我相关P值> 0.05 表模式已消除虚假相关为平稳之白噪音序列可作ARIMA交互自我相关P值> 0.05六.设定结构转移函数Transfer Function (X,Y 关系式)1.一般转移函数型式( 略去下式中form4 , num4 )2.干预转移函数型式七.用Y[ARMA特质]+[一般转移函数(或干预转移函数)]──>预测八.预测期数Log(Y) 作反BOX-COX 转换(直线式则可不必做此转换)FORECAST LEAD=5 OUT=FORECAST NOPRINT;DATA FORECAST;MERGE D1 FORECAST;FORECAST=(&L*FORECAST+1)**(1/&L);STD=SQRT((FORECAST**(&L-1)**(-1)*(STD*2)));RESIDUAL=Y-FORECAST;L95=FORECAST-1.96*STD;U95=FORECAST+1.96*STD;PROC CORR NOSIMLE NOPROB;VAR &Y FORECAST;九.模式提报及检定1.2.SAS 报表提报ARIMA(p,d,q)模式: 设NUM1=X1 NUM2=X2NUM3=DUMMY十.解释模式(NUM1 - NUM1,1 B - NUM1,2 B2 - …)X1 λ(1)X1对Y之弹性系数=[X1 1%--> Y ?%]= -------------------------------------------------------- --------( 1 - DEN1,1 B - DEN1,2 B2 - …)Y(2)X2对Y之弹性系数=....(3)X3对Y之弹性系数=....( NUM3 - NUM1,1 B - NUM1,1 B2 - …)X1 1-λ(4)冲击乘数=干预函数对Y当期之影响= ------------------------------------------------------- ------( 1 - DEN1,1 B - DEN1,2 B2 - …)Y( NUM3 - NUM1,1 B - NUM1,1 B2 - …)X1 1-λ(5)长期乘数=干预函数对Y长期之影响= -------------------------------------------------------- ----( 1 - DEN1,1 B - DEN1,2 B2 - …)Y十一.摘要(SUMMRY)SAS程序范例解说Log(Y)=Log(X) %LET U=0.01%LET L=0.01BOX-COX转换&X1=(&X1**&U-1)/&U&X2=(&X2**&U-1)/&U&Y=(&Y**&L-1)/&LX1 差分阶数d=1 IDENTIFY VAR=&X1(1)滤出AR特质ESTIMATE P=(1,2)X2 差分阶数d=1 IDENTIFY VAR=&X2(1)滤出AR特质ESTIMATE P=(4)X3 差分阶数d=1 IDENTIFY VAR=&X3(1)滤出AR特质ESTIMATE P=(4,8)Y 差分阶数d=1 IDENTIFY VAR=&Y(1)CROSSCOR=(&X1(1) &X2(1) &X3(1))一般转移函数ESTIMATEINPUT=(4$(2)/&X1 &X2 1$(1)/&X3)设定AR1,1+MA1,1特质ESTIMATE P=(1) Q=(1) INPUT=(&X1 &X2 &X3)预测8期FORECAST LEAD=8[例一] 应用实务(DECODE 步骤):参考周文贤老师着[市场调查与营销策略研拟] 一书之例5.模式解释(1)弹性系数(2)成长率(3)生命周期(4)干预乘数:冲击/期间/长期[例二] 消费财产品预测3.预测流程:(5) POP=f(POP) POP--->ARIMA(p,1,q) --->POP Fcst(6) BBC Fcst = BBCP Fcst * POP Fcst(7) MOBIL Fcst = WLC Fcst - BBC Fcst(8) 产品预测= MOBIL Fcst * 市场占有率[例三]工业财产品预测1.变量说明: YEAR 年份GDP 每千家生产毛额EPP 静电式绘图机BUS 厂商数(千家)EPPP 每千家静电式绘图机2.关系式:EPPP=EPP/BUS3.预测流程:(2) BUS=f(BUS) BUS ---> ARIMA(p,1,q) --> BUS Fcst(3) EPP Fcst = EPPP Fcst * BUS Fcst[例四]民生财(所得弹性=0)产品预测。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
█ARIMA定义ARIMA的完整写法为ARIMA(p,d,q)►其中p为自回归系数,代表数据呈现周期性波动►d为差分次数,代表数据差分几次才能达到平稳序列►q为移动平均阶数,代表数据为平稳序列,可以用移动平均来处理。
█平稳性检测方法•►方法一:时序图序列始终在一个常数值附近随机波动,且波动范围有界,且没有明显的趋势性或周期性,所以可认为是平稳序列。
下图明显不是一个平稳序列proc gplot data=gdp;plot gdp*year=1 ;symbol c=red i=join v=star;run;•►方法二:自相关图自相关系数会很快衰减向0,所以可认为是平稳序列。
proc arima data= gdp;identify var=gdp stationarity =(adf=3) nlag=12;run;•►ADF单位根检验(精确判断)三个检验中只要有一个Pr<Rho小于0.05即可认定为平稳序列,主要是stationarity=(adf=3) 起作用proc arima data= gdp;identify var=gdp stationarity =(adf=3) nlag=12; run;█白噪声检验Pr>卡方<0.05即可认定为通过白噪声检验。
proc arima data= gdp;identify var=gdp stationarity =(adf=3) nlag=12; run;█非平稳序列转换为平稳序列方法一:将数据取对数。
方法二:对数据取差分dif函数data gdp_log;set gdp;loggdp=log(gdp);cfloggdp=dif(loggdp);run;/**对数数据散点图**/proc gplot;plot loggdp*year=1 ;symbol c=black i=join v=star; run;/* 一阶差分对数数据散点图*/ proc gplot;plot cfloggdp*year=1;symbol c=green v=dot i=join;run;从上图中可以看出,一阶差分后序列已经变成平稳的了,因此,数列需要做一阶差分█转换完毕后再验证下面代码中的(1)就代表1阶差分,adf=3则代表平稳性检验0-3,/* 一阶差分对数数据的自相关图、偏自相关图、纯随机性检验、单位根检验 */ proc arima data=gdp_log;identify var=loggdp(1) stationarity =(adf=3) nlag=12;run;用Q LB统计量作的 2检验结果表明:对数差分后的GDP序列的Q LB统计量的P值为0.0045(<0.05),故序列为非白噪声序列。
单位根检验结果表明:对数差分后的GDP序列有常数均值、无趋势的二阶自回归模型的Tau统计量的P值小于0.0573,故序列基本可以确定为平稳序列,并可初步考虑用ARMA (2,q)模型对它们进行拟合。
█模型定阶/** 定阶 **/proc arima data=gdp_log;identify var=loggdp(1) nlag=6minic p=(0:2) q=(0:4);run;/* minic为一定范围模型定阶——相对最优模型识别 */采用相对最优模型识别,根据上述分析及序列的自相关和偏自相关图,适当选择m = 4,n = 2,使用indentify命令中的minic p = (0: n) q = (0: m)短语进行相对最优模型定阶。
结果显示(图6.10),在p = 1,q = 4时,BIC函数值最小。
执行ARIMA过程的Estimate p = 1 q = 4命令做参数检验,结果未能通过参数检验。
让q在0~3之间取值,通过反复测试,只有ARMA(1, 3)模型与ARMA(1, 0)模型通过参数检验及模型检验,其检验结果及参数估计如图6.11所示。
█参数估计/** 参数估计 **/proc arima data=gdp_log;identify var=loggdp(1);estimate p=1q=4;run;/* SAS支持三种估计,默认为条件最小二乘估计,要制定可增加选项:METHOD=ML 极大似然估计METHOD=ULS 最小二乘估计METHOD=CLS 条件最小二乘估计输出项的含义见王燕 P104*/;从上面可以看出,在p=1q=4时,通不过检验。
p =1 q =3 和p=1 q=0时能通过检验从上面2个模型的检验结果可以看到,它们均为有效模型,但ARMA(1, 0)模型的AIC 为-67,SBC 为-65均比ARMA(1, 3)的AIC 与SBC 小,根据AIC 准则和SBC 准则,ARMA(1, 0)应该更有效,所以应选择前者作为预测模型。
GDP 对数序列模型的口径为:Bx tt 49853.01155955.0log -+=∇ε其中,x t 表示GDP 序列,模型可写为:t t t t x x x ε++-=--078207.0log 49853.0log 49853.1log 21█预测/**参数估计及预测**/proc arima data=gdp_log;identify var=loggdp(1) nlag=16;estimate p=1q=0;forecast lead=4id=year out=results;run;█还原预测数值并画图/**绘制预测图**/data results;set results;y=exp(loggdp);estimate1=exp(forecast);el95=exp(l95);eu95=exp(u95);run;proc gplot data=results;plot y*year=1 estimate1*year=2 el95*year=3 eu95*year=3/overlay; symbol1c=black i=none v=star;symbol2c=red i=join v=none;symbol3c=green i=join v=none l=2;run;█另一种确定p、q的方式proc arima data= gdp;identify var=gdp stationarity =(adf=3) ;run;直接对gdp求arima模型,可已看出acf是拖尾,而pacf是1阶截尾,所以最好是p=1,q=0█确定p 、q 的方式理论由于),(q p ARMA 模型可以转化为无穷阶移动平均模型,所以),(q p ARMA 模型的自相关系数不截尾。
同理,由于),(q p ARMA 模型也可以转化为无穷阶自回归模型,所以),(q p ARMA 模型的偏自相关系数也不截尾。
总结)(p AR 模型、)(q MA 模型和),(q p ARMA█模型优化指标当一个拟合模型在指定的置信水平α下通过了检验,说明了在这个置信水平α下该拟合模型能有效地拟合时间序列观察值的波动。
但是这种有效的拟合模型并不是惟一的。
如果同一个时间序列可以构造两个拟合模型,且两个模型都显著有效,那么应该选择哪个拟合模型用于统计推断呢?通常采用AIC 和SBC 信息准则来进行模型优化。
1. AIC 准则AIC 准则是由日本统计学家赤池弘次(Akaike )于1973年提出,AIC 全称是最小信息量准则(an information criterion )。
AIC 准则是一种考评综合最优配置的指标,它是拟合精度和参数未知个数的加权函数:AIC =-2ln(模型中极大似然函数值)+2(模型中未知参数个数) (6.68) 使AIC 函数达到最小值的模型被认为是最优模型。
2. BIC 准则AIC 准则也有不足之处:如果时间序列很长,相关信息就越分散,需要多自变量复杂拟合模型才能使拟合精度比较高。
在AIC 准则中拟合误差等于)ˆln(2εσn ,即拟合误差随样本容量n放大。
但是模型参数个数的惩罚因子却与n 无关,权重始终为常数2。
因此在样本容量n 趋于无穷大时,由AIC 准则选择的拟合模型不收敛于真实模型,它通常比真实模型所含的未知参数个数要多。
为了弥补AIC 准则的不足,Akaike 于1976年提出BIC 准则。
而Schwartz 在1978年根据Bays 理论也得出同样的判别准则,称为SBC 准则。
SBC 准则定义为:SBC =-2ln(模型中极大似然函数值)+ln(n)(模型中未知参数个数) (6.69) 它对AIC 的改进就是将未知参数个数的惩罚权重由常数2变成了样本容量n 的对数)ln(n 。
在所有通过检验的模型中使得AIC 或SBC 函数达到最小的模型为相对最优模型。
之所以称为相对最优模型是因为不可能比较所有模型。
表6.2 河南省历年国民生产总值数据█附:完整代码data gdp;infile datalines;input year gdp pgdp;format gdp BEST12.2 pgdp BEST12.2; datalines;1978 162.92 232.31979 190.09 266.71980 229.16 316.71981 249.69 340.11982 263.30 3531983 327.95 432.91984 370.04 481.61985 451.74 579.71986 502.91 635.31987 609.60 755.81988 749.09 909.91989 850.71 1012.31990 934.65 1090.61991 1045.73 1201.21992 1279.75 1452.31993 1662.76 1867.41994 2224.43 2475.21995 3002.74 3312.81996 3661.18 4007.41997 4079.26 4430.11998 4356.60 4695.11999 4576.10 4893.72000 5137.66 54442001 5640.11 5923.62002 6168.73 6436.52003 7048.59 7570.22004 8815.09 9469.9;run;/** 原始数据散点图 **/proc gplot data=gdp;plot gdp*year=1 ;symbol c=red i=join v=star;run;/*注 symbol常用参数C—图形颜色,red_红色,black_黑色,green_绿色,blue_蓝色,pink_洋红等 */ /* V—观测值的图形,star_*, dot_., cicle_圆圈,diamond_菱形,none_不标 */ /* I—观察值的链接方式,join_线连,spline_光滑连接,needle_作观察值到横轴悬垂线,none_不连 */proc arima data= gdp;identify var=gdp stationarity =(adf=3) ;run;/** 原始数据对数、差分变换 **/data gdp_log;set gdp;loggdp=log(gdp);cfloggdp=dif(loggdp);run;/**对数数据散点图**/proc gplot;plot loggdp*year=1 ;symbol c=black i=join v=star;run;/* 一阶差分对数数据散点图*/proc gplot;plot cfloggdp*year=1;symbol c=green v=dot i=join;run;/* 一阶差分对数数据的自相关图、偏自相关图、纯随机性检验、单位根检验 */proc arima data=gdp_log;identify var=loggdp(1) stationarity =(adf=3) nlag=12;run;/* loggdp(1)这里的数1为差分阶数 *//** 定阶 **/proc arima data=gdp_log;identify var=loggdp(1) nlag=6minic p=(0:2) q=(0:4);run;/* minic为一定范围模型定阶——相对最优模型识别 *//** 参数估计 **/proc arima data=gdp_log;identify var=loggdp(1);estimate p=1q=0OUTEST=b outstat=c;run;/* SAS支持三种估计,默认为条件最小二乘估计,要制定可增加选项:METHOD=ML 极大似然估计METHOD=ULS 最小二乘估计METHOD=CLS 条件最小二乘估计输出项的含义见王燕 P104*/;/**参数估计及预测**/proc arima data=gdp_log;identify var=loggdp(1) nlag=16;estimate p=1q=0;forecast lead=4id=year out=results;run;/**绘制预测图**/data results;set results;y=exp(loggdp);estimate1=exp(forecast);el95=exp(l95);eu95=exp(u95);run;proc gplot data=results;plot y*year=1 estimate1*year=2 el95*year=3 eu95*year=3/overlay; symbol1c=black i=none v=star;symbol2c=red i=join v=none;symbol3c=green i=join v=none l=2;run;。