Hadoop系统操作安装手册
hadoop2.0安装

Hadoop2.0配置SSH安装在线安装ssh #sudo apt-get install openssh-serveropenssh-client手工安装ssh存储ssh密码#ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa#cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys#sudo chmod go-w $HOME $HOME/.ssh#sudo chmod 600 $HOME/.ssh/authorized_keys#sudo chown `whoami` $HOME/.ssh/authorized_keys测试连接本地服务,无密码登陆,则说明ssh服务安装配置正确#ssh localhost#exit安装JDK安装必须1.6或者1.6以上版本。
#sudo mkdir /usr/java#cd /usr/java#sudo wget/otn-pub/java/jdk/6u31-b04/jdk-6u31-linux-i586.bin #sudo chmod o+w jdk-6u31-linux-i586.bin#sudo chmod +x jdk-6u31-linux-i586.bin#sudo ./jdk-6u31-linux-i586.bin修改环境变量/etc/profile文件中增加如下代码export JA V A_HOME=/usr/java/jdk1.6.0_24export PATH=$PATH:/usr/java/jdk1.6.0_24/binexport CLASSPA TH=/usr/java/jdk1.6.0_24/lib/dt.jar:/usr/java/jdk1.6.0_24/lib/tools.jar#source /etc/profile测试# java -version显示java版本,则证明安装配置正确安装hadoop选择一个linux系统,下载并解压hadoop2.0.x并解压到/home/hadoop-2.0.0-alpha。
Hadoop安装部署手册

1.1软件环境1)CentOS6.5x642)Jdk1.7x643)Hadoop2.6.2x644)Hbase-0.98.95)Zookeeper-3.4.61.2集群环境集群中包括 3个节点:1个Master, 2个Slave2安装前的准备2.1下载JDK2.2下载Hadoop2.3下载Zookeeper2.4下载Hbase3开始安装3.1 CentOS安装配置1)安装3台CentOS6.5x64 (使用BasicServer模式,其他使用默认配置,安装过程略)2)Master.Hadoop 配置a)配置网络修改为:保存,退出(esc+:wq+enter ),使配置生效b) 配置主机名修改为:c)配置 hosts修改为:修改为:在最后增加如下内容以上调整,需要重启系统才能生效g) 配置用户新建hadoop用户和组,设置 hadoop用户密码id_rsa.pub ,默认存储在"/home/hadoop/.ssh" 目录下。
a) 把id_rsa.pub 追加到授权的 key 里面去b) 修改.ssh 目录的权限以及 authorized_keys 的权限c) 用root 用户登录服务器修改SSH 配置文件"/etc/ssh/sshd_config"的下列内容3) Slavel.Hadoop 、Slavel.Hadoop 配置及用户密码等等操作3.2无密码登陆配置1)配置Master 无密码登录所有 Slave a)使用 hadoop 用户登陆 Master.Hadoopb)把公钥复制所有的 Slave 机器上。
使用下面的命令格式进行复制公钥2) 配置Slave 无密码登录Mastera) 使用hadoop 用户登陆Slaveb)把公钥复制Master 机器上。
使用下面的命令格式进行复制公钥id_rsa 和相同的方式配置 Slavel 和Slave2的IP 地址,主机名和 hosts 文件,新建hadoop 用户和组c) 在Master机器上将公钥追加到authorized_keys 中3.3安装JDK所有的机器上都要安装 JDK ,先在Master服务器安装,然后其他服务器按照步骤重复进行即可。
在linux中安装Hadoop教程-伪分布式配置-Hadoop2.6.0-Ubuntu14.04

在linux中安装Hadoop教程-伪分布式配置-Hadoop2.6.0-Ubuntu14.04注:该教程转⾃厦门⼤学⼤数据课程学习总结装好了 Ubuntu 系统之后,在安装 Hadoop 前还需要做⼀些必备⼯作。
创建hadoop⽤户如果你安装 Ubuntu 的时候不是⽤的 “hadoop” ⽤户,那么需要增加⼀个名为 hadoop 的⽤户。
⾸先按 ctrl+alt+t 打开终端窗⼝,输⼊如下命令创建新⽤户 : sudo useradd -m hadoop -s /bin/bash这条命令创建了可以登陆的 hadoop ⽤户,并使⽤ /bin/bash 作为 shell。
sudo命令 本⽂中会⼤量使⽤到sudo命令。
sudo是ubuntu中⼀种权限管理机制,管理员可以授权给⼀些普通⽤户去执⾏⼀些需要root权限执⾏的操作。
当使⽤sudo命令时,就需要输⼊您当前⽤户的密码.密码 在Linux的终端中输⼊密码,终端是不会显⽰任何你当前输⼊的密码,也不会提⽰你已经输⼊了多少字符密码。
⽽在windows系统中,输⼊密码⼀般都会以“*”表⽰你输⼊的密码字符 接着使⽤如下命令设置密码,可简单设置为 hadoop,按提⽰输⼊两次密码: sudo passwd hadoop可为 hadoop ⽤户增加管理员权限,⽅便部署,避免⼀些对新⼿来说⽐较棘⼿的权限问题: sudo adduser hadoop sudo最后注销当前⽤户(点击屏幕右上⾓的齿轮,选择注销),返回登陆界⾯。
在登陆界⾯中选择刚创建的 hadoop ⽤户进⾏登陆。
更新apt⽤ hadoop ⽤户登录后,我们先更新⼀下 apt,后续我们使⽤ apt 安装软件,如果没更新可能有⼀些软件安装不了。
按 ctrl+alt+t 打开终端窗⼝,执⾏如下命令: sudo apt-get update后续需要更改⼀些配置⽂件,我⽐较喜欢⽤的是 vim(vi增强版,基本⽤法相同) sudo apt-get install vim安装SSH、配置SSH⽆密码登陆集群、单节点模式都需要⽤到 SSH 登陆(类似于远程登陆,你可以登录某台 Linux 主机,并且在上⾯运⾏命令),Ubuntu 默认已安装了SSH client,此外还需要安装 SSH server: sudo apt-get install openssh-server安装后,配置SSH⽆密码登陆利⽤ ssh-keygen ⽣成密钥,并将密钥加⼊到授权中: exit # 退出刚才的 ssh localhost cd ~/.ssh/ # 若没有该⽬录,请先执⾏⼀次ssh localhost ssh-keygen -t rsa # 会有提⽰,都按回车就可以 cat ./id_rsa.pub >> ./authorized_keys # 加⼊授权此时再⽤ssh localhost命令,⽆需输⼊密码就可以直接登陆了。
Hadoop的安装与配置及示例wordcount的运行

Hadoop的安装与配置及示例程序wordcount的运行目录前言 (1)1 机器配置说明 (2)2 查看机器间是否能相互通信(使用ping命令) (2)3 ssh设置及关闭防火墙 (2)1)fedora装好后默认启动sshd服务,如果不确定的话可以查一下[garon@hzau01 ~]$ service sshd status (3)2)关闭防火墙(NameNode和DataNode都必须关闭) (3)4 安装jdk1.6(集群中机子都一样) (3)5 安装hadoop(集群中机子都一样) (4)6 配置hadoop (4)1)配置JA V A环境 (4)2)配置conf/core-site.xml、conf/hdfs-site.xml、conf/mapred-site.xml文件 (5)3)将NameNode上完整的hadoop拷贝到DataNode上,可先将其进行压缩后直接scp 过去或是用盘拷贝过去 (7)4)配置NameNode上的conf/masters和conf/slaves (7)7 运行hadoop (7)1)格式化文件系统 (7)2)启动hadoop (7)3)用jps命令查看进程,NameNode上的结果如下: (8)4)查看集群状态 (8)8 运行Wordcount.java程序 (8)1)先在本地磁盘上建立两个文件f1和f2 (8)2)在hdfs上建立一个input目录 (9)3)将f1和f2拷贝到hdfs的input目录下 (9)4)查看hdfs上有没有f1,f2 (9)5)执行wordcount(确保hdfs上没有output目录) (9)6)运行完成,查看结果 (9)前言最近在学习Hadoop,文章只是记录我的学习过程,难免有不足甚至是错误之处,请大家谅解并指正!Hadoop版本是最新发布的Hadoop-0.21.0版本,其中一些Hadoop命令已发生变化,为方便以后学习,这里均采用最新命令。
Hadoop的安装与配置

Hadoop的安装与配置建立一个三台电脑的群组,操作系统均为Ubuntu,三个主机名分别为wjs1、wjs2、wjs3。
1、环境准备:所需要的软件及我使用的版本分别为:Hadoop版本为0.19.2,JDK版本为jdk-6u13-linux-i586.bin。
由于Hadoop要求所有机器上hadoop的部署目录结构要相同,并且都有一个相同的用户名的帐户。
所以在三台主机上都设置一个用户名为“wjs”的账户,主目录为/home/wjs。
a、配置三台机器的网络文件分别在三台机器上执行:sudo gedit /etc/network/interfaceswjs1机器上执行:在文件尾添加:auto eth0iface eth0 inet staticaddress 192.168.137.2gateway 192.168.137.1netmask 255.255.255.0wjs2和wjs3机器上分别执行:在文件尾添加:auto eth1iface eth1 inet staticaddress 192.168.137.3(wjs3上是address 192.168.137.4)gateway 192.168.137.1netmask 255.255.255.0b、重启网络:sudo /etc/init.d/networking restart查看ip是否配置成功:ifconfig{注:为了便于“wjs”用户能够修改系统设置访问系统文件,最好把“wjs”用户设为sudoers(有root权限的用户),具体做法:用已有的sudoer登录系统,执行sudo visudo -f /etc/sudoers,并在此文件中添加以下一行:wjsALL=(ALL)ALL,保存并退出。
}c、修改三台机器的/etc/hosts,让彼此的主机名称和ip都能顺利解析,在/etc/hosts中添加:192.168.137.2 wjs1192.168.137.3 wjs2192.168.137.4 wjs3d、由于Hadoop需要通过ssh服务在各个节点之间登陆并运行服务,因此必须确保安装Hadoop的各个节点之间网络的畅通,网络畅通的标准是每台机器的主机名和IP地址能够被所有机器正确解析(包括它自己)。
Hadoop2.4、Hbase0.98、Hive集群安装配置手册

Hadoop、Zookeeper、Hbase、Hive集群安装配置手册运行环境机器配置虚机CPU E5504*2 (4核心)、内存 4G、硬盘25G进程说明QuorumPeerMain ZooKeeper ensemble member DFSZKFailoverController Hadoop HA进程,维持NameNode高可用 JournalNode Hadoop HA进程,JournalNode存储EditLog,每次写数据操作有大多数(>=N+1)返回成功时即认为该次写成功,保证数据高可用 NameNode Hadoop HDFS进程,名字节点DataNode HadoopHDFS进程, serves blocks NodeManager Hadoop YARN进程,负责 Container 状态的维护,并向 RM 保持心跳。
ResourceManager Hadoop YARN进程,资源管理 JobTracker Hadoop MR1进程,管理哪些程序应该跑在哪些机器上,需要管理所有 job 失败、重启等操作。
TaskTracker Hadoop MR1进程,manages the local Childs RunJar Hive进程HMaster HBase主节点HRegionServer HBase RegionServer, serves regions JobHistoryServer 可以通过该服务查看已经运行完的mapreduce作业记录应用 服务进程 主机/hostname 系统版本mysql mysqld10.12.34.14/ Centos5.810.12.34.15/h15 Centos5.8 HadoopZookeeperHbaseHiveQuorumPeerMainDFSZKFailoverControllerNameNodeNodeManagerRunJarHMasterJournalNodeJobHistoryServerResourceManagerDataNodeHRegionServer10.12.34.16/h16 Centos5.8 HadoopZookeeperHbaseHiveDFSZKFailoverControllerQuorumPeerMainHMasterJournalNodeNameNodeResourceManagerDataNodeHRegionServerNodeManager10.12.34.17/h17 Centos5.8 HadoopZookeeperHbaseHiveNodeManagerDataNodeQuorumPeerMainJournalNodeHRegionServer环境准备1.关闭防火墙15、16、17主机:# service iptables stop2.配置主机名a) 15、16、17主机:# vi /etc/hosts添加如下内容:10.12.34.15 h1510.12.34.16 h1610.12.34.17 h17b) 立即生效15主机:# /bin/hostname h1516主机:# /bin/hostname h1617主机:# /bin/hostname h173. 创建用户15、16、17主机:# useraddhduser密码为hduser# chown -R hduser:hduser /usr/local/4.配置SSH无密码登录a)修改SSH配置文件15、16、17主机:# vi /etc/ssh/sshd_config打开以下注释内容:#RSAAuthentication yes#PubkeyAuthentication yes#AuthorizedKeysFile .ssh/authorized_keysb)重启SSHD服务15、16、17主机:# service sshd restartc)切换用户15、16、17主机:# su hduserd)生成证书公私钥15、16、17主机:$ ssh‐keygen ‐t rsae)拷贝公钥到文件(先把各主机上生成的SSHD公钥拷贝到15上的authorized_keys文件,再把包含所有主机的SSHD公钥文件authorized_keys拷贝到其它主机上)15主机:$cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys16主机:$cat ~/.ssh/id_rsa.pub | ssh hduser@h15 'cat >> ~/.ssh/authorized_keys'17主机:$cat ~/.ssh/id_rsa.pub | ssh hduser@h15 'cat >> ~/.ssh/authorized_keys'15主机:# cat ~/.ssh/authorized_keys | ssh hduser@h16 'cat >> ~/.ssh/authorized_keys'# cat ~/.ssh/authorized_keys | ssh hduser@h17 'cat >> ~/.ssh/authorized_keys'5.Mysqla) Host10.12.34.14:3306b) username、passwordhduser@hduserZookeeper使用hduser用户# su hduser安装(在15主机上)1.下载/apache/zookeeper/2.解压缩$ tar ‐zxvf /zookeeper‐3.4.6.tar.gz ‐C /usr/local/配置(在15主机上)1.将zoo_sample.cfg重命名为zoo.cfg$ mv /usr/local/zookeeper‐3.4.6/conf/zoo_sample.cfg /usr/local/zookeeper‐3.4.6/conf/zoo.cfg2.编辑配置文件$ vi /usr/local/zookeeper‐3.4.6/conf/zoo.cfga)修改数据目录dataDir=/tmp/zookeeper修改为dataDir=/usr/local/zookeeper‐3.4.6/datab)配置server添加如下内容:server.1=h15:2888:3888server.2=h16:2888:3888server.3=h17:2888:3888server.X=A:B:C说明:X:表示这是第几号serverA:该server hostname/所在IP地址B:该server和集群中的leader交换消息时所使用的端口C:配置选举leader时所使用的端口3.创建数据目录$ mkdir /usr/local/zookeeper‐3.4.6/data4.创建、编辑文件$ vi /usr/local/zookeeper‐3.4.6/data/myid添加内容(与zoo.cfg中server号码对应):1在16、17主机上安装、配置1.拷贝目录$ scp ‐r /usr/local/zookeeper‐3.4.6/ hduser@10.12.34.16:/usr/local/$ scp ‐r /usr/local/zookeeper‐3.4.6/ hduser@10.12.34.17:/usr/local/2.修改myida)16主机$ vi /usr/local/zookeeper‐3.4.6/data/myid1 修改为2b)17主机$ vi /usr/local/zookeeper‐3.4.6/data/myid1修改为3启动$ cd /usr/local/zookeeper‐3.4.6/$./bin/zkServer.sh start查看状态:$./bin/zkServer.sh statusHadoop使用hduser用户# su hduser安装(在15主机上)一、安装Hadoop1.下载/apache/hadoop/common/2.解压缩$ tar ‐zxvf /hadoop‐2.4.0.tar.gz ‐C /usr/local/二、 编译本地库,主机必须可以访问internet。
Hadoop2.2.0+Hbase0.98.1+Sqoop1.4.4+Hive0.13完全安装手册
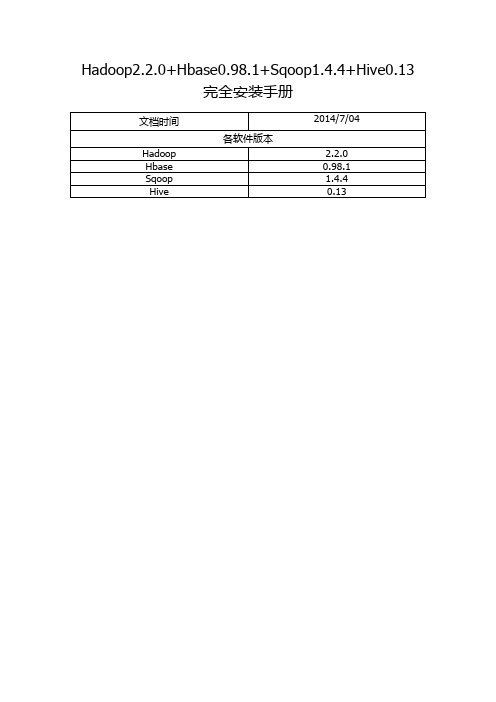
Hadoop2.2.0+Hbase0.98.1+Sqoop1.4.4+Hive0.13完全安装手册前言: (3)一. Hadoop安装(伪分布式) (4)1. 操作系统 (4)2. 安装JDK (4)1> 下载并解压JDK (4)2> 配置环境变量 (4)3> 检测JDK环境 (5)3. 安装SSH (5)1> 检验ssh是否已经安装 (5)2> 安装ssh (5)3> 配置ssh免密码登录 (5)4. 安装Hadoop (6)1> 下载并解压 (6)2> 配置环境变量 (6)3> 配置Hadoop (6)4> 启动并验证 (8)前言:网络上充斥着大量Hadoop1的教程,版本老旧,Hadoop2的中文资料相对较少,本教程的宗旨在于从Hadoop2出发,结合作者在实际工作中的经验,提供一套最新版本的Hadoop2相关教程。
为什么是Hadoop2.2.0,而不是Hadoop2.4.0本文写作时,Hadoop的最新版本已经是2.4.0,但是最新版本的Hbase0.98.1仅支持到Hadoop2.2.0,且Hadoop2.2.0已经相对稳定,所以我们依然采用2.2.0版本。
一. Hadoop安装(伪分布式)1. 操作系统Hadoop一定要运行在Linux系统环境下,网上有windows下模拟linux环境部署的教程,放弃这个吧,莫名其妙的问题多如牛毛。
2. 安装JDK1> 下载并解压JDK我的目录为:/home/apple/jdk1.82> 配置环境变量打开/etc/profile,添加以下内容:export JAVA_HOME=/home/apple/jdk1.8export PATH=$PATH:$JAVA_HOME/binexport CLASSPATH=.:$JAVA_HOME/lib/tools.jar:$JAVA_HOME/lib/dt.jar执行source /etc/profile ,使更改后的profile生效。
Hadoop完全分布式详细安装过程

Hadoop详细安装过程一、本文思路1、安装虚拟化PC工具VMware,用于支撑Linux系统。
2、在VMware上安装Ubuntu系统。
3、安装Hadoop前的准备工作:安装JDK和SSH服务。
4、配置Hadoop。
5、为了方便开发过程,需安装eclipse。
6、运行一个简单的Hadoop程序:WordCount.java注:在win7系统上,利用虚拟工具VMware建立若干个Linux系统,每个系统为一个节点,构建Hadoop集群。
先在一个虚拟机上将所有需要配置的东西全部完成,然后再利用VMware 的克隆功能,直接生成其他虚拟机,这样做的目的是简单。
二、所需软件1、VMware:VMware Workstation,直接百度下载(在百度软件中心下载即可)。
2、Ubuntu系统:ubuntu-15.04-desktop-amd64.iso,百度网盘:/s/1qWxfxso注:使用15.04版本的Ubuntu(其他版本也可以),是64位系统。
3、jdk:jdk-8u60-linux-x64.tar.gz,网址:/technetwork/java/javase/downloads/jdk8-downloads-2133151.html注:下载64位的Linux版本的jdk。
4、Hadoop:hadoop-1.2.1-bin.tar.gz,网址:/apache/hadoop/common/hadoop-1.2.1/注:选择1.2.1版本的Hadoop。
5、eclipse:eclipse-java-mars-1-linux-gtk-x86_64.tar.gz,网址:/downloads/?osType=linux注:要选择Linux版本的,64位,如下:6、hadoop-eclipse-plugin-1.2.1.jar,这是eclipse的一个插件,用于Hadoop的开发,直接百度下载即可。
三、安装过程1、安装VMware。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
基于网络音乐云Hadoop系统及MapReduce模型管理平台V1.0操作手册北京华康嘉合科技有限公司目录一、服务器基础配置 (2)二、实现Linux的ssh无密码验证配置 (2)三、修改Linux机器名 (2)四、安装JDK,并配置环境变量 (3)五、安装Hadoop,并修改文件的配置 (3)六、创建Hadoop备份的目录 (5)七、将Hadoop的bin加入环境变量 (6)八、修改部分运行文件的权限 (6)九、格式化Hadoop,启动Hadoop (6)十、新加datanode的安装步骤 (7)一、服务器基础配置首先,需要将服务器IP进行固定。
本文采用主机IP:10.0.0.30,分机:10.0.0.31;主机名称:namenode,分机名称:datanode;本文红色字体为终端命令或需修改添加部分。
二、实现Linux的ssh无密码验证配置1.生成密钥:在namenode(主机)上,使用终端输入ssh-keygen –trsa,一直回车,生成密钥;2.在namenode上使用命令cd /root/.ssh进入文件夹,使用ls可查看两个文件:id_rsa.pub,id_rsa;3.然后执行cp id_rsa.pub authorized_keys;使用ssh localhost验证是否成功,第一次需要输入登录密码,以后就不需要输入密码;4.拷贝密钥:[root@namenode .ssh] #scp authorized_keys 10.0.0.31:/root/.ssh这是拷贝命令,将namenode上的authorized_keys 拷贝到datanode的/root/.ssh 上;5.验证是否成功,在namenode上输入ssh 10.0.0.31,第一次连接需要输入yes,就可以连接到datanode上了,无需使用密码即为成功;此时,系统已登录至datanode下,不在namenode上了,可输入命令exit返回至namenode;三、修改Linux机器名1.查看主机名:在命令行输入:hostname[root@namenode ~]# hostnamenamenode//这是你的主机名。
2.修改机器名执行cd /etc/sysconfig ,进如sysconfig目录下执行vi network,修改network文件(文件修改方法,键盘点击Insert键进入输入模式,修改好文件后,按Esc键退出输入模式,直接输入:w进行文件保存,:q退出编辑模式;也可在文件夹内选择需修改文件直接打开进行文件修改)NETWORKING=yesHOSTNAME=namenode(修改成你需要的)执行cd /etc,进入etc目录执行vi hosts要加入的datanode,把IP地址和机器名加在后面。
这一步是让主机记住datanode的名字。
所以在修改datanode的hosts时,只需写入namenode和你需要加入hadoop机器的datanode的IP 地址及机器名就好。
[root@namenode etc]# vi hosts127.0.0.1 localhost.localdomain localhost10.0.0.30 namenode namenode10.0.0.31 datanode datanode重启电脑后输入hostname检查主机名。
四、安装JDK,并配置环境变量1.安装JDK将jdk-7u79-linux-x64.rpm保存在服务器硬盘内,双击进行安装;2.配置环境变量执行cd /etc,进入etc目录执行vi profile,修改profile文件文件中加入如下部分:export JAVA_HOME=/usr/java/jdk1.7.0_79export PATH=$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$PATHexport CLASSPATH=.:$JAVA_HOME/lib:$JAVA_HOME/jre/lib执行chmod +x profile,把profile变为可执行文件;执行source profile,把profile内容执行生效;执行java、javac、java –version查看是否安装成功;五、安装Hadoop,并修改文件的配置1.将hadoop-2.7.1.tar.gz文件解压,本文解压至根目录下(/hadoop-2.7.1);2.输入cd /hadoop-2.7.1/etc/hadoop,进入hadoop目录1)修改core-site.xml文件<configuration><property><name>hadoop.tmp.dir</name><value>/usr/local/hadoop/hadooptmp</value> (hadoop运行临时文件目录,需手动创建)</property><property><name>dfs.datanode.data.dir</name><value>/usr/local/hadoop/datanodetmp</value></property><property><name>hadoop.native.lib</name><value>true</value><description>Should native hadoop libraries, if present, be used.</description></property><property><name></name><value>hdfs://10.0.0.30:9000</value> (namenode的IP)</property></configuration>2)修改hadoop-env.sh文件修改export JAVA_HOME=/usr/java/jdk1.7.0_79#export HADOOP_OPTS="$HADOOP_OPTS .preferIPv4Stack=true" (注释此行)export HADOOP_OPTS="$HADOOP_OPTS -Djava.library.path=/hadoop-2.7.1/lib/" export HADOOP_COMMON_LIB_NATIVE_DIR="/hadoop-2.7.1/lib/native/"3)修改hdfs-site.xml文件<configuration><property><name>dfs.replication</name><value>2</value>(数字为总服务器数量,本文为主、副2台)</property><property><name>dfs.datanode.max.transfer.threads</name><value>8192</value></property></configuration>4)mapred-site.xml文件(将mapred-site.xml.template原文件复制并粘贴改名为mapred-site.xml)<configuration><property><name>mapred.job.tracker</name><value>10.0.0.30:9001</value> (改成namenode的IP) </property><property><name>mapreduce.jobtracker.staging.root.dir</name><value>/user</value></property><property><name></name><value>yarn</value></property></configuration>5)修改masters文件10.0.0.30 (namenode的IP)6)修改slaves文件10.0.0.31 (datanode的IP)7)修改yarn-site.xml文件<configuration><!-- Site specific YARN configuration properties --><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><property><name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name><value>org.apache.hadoop.mapred.ShuffleHandler</value></property></configuration>六、创建Hadoop备份的目录步骤四中,core-site.xml文件已配置目录位置,需在配置对应位置新建文件夹 /usr/local/hadoop,hadooptmp文件夹在启动hadoop时会自动生成,在启动前不能存在。
七、将Hadoop的bin加入环境变量1.执行cd /etc ,进入etc目录2.执行vi profile,修改profile文件添加:export HADOOP_HOME=/hadoop-2.7.1(Hadoop解压后目录/为根目录)export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbinexportCLASSPATH=$CLASSPATH:$HADOOP_HOME/share/hadoop/common/hadoop-commo n-2.7.1.jarexport JAVA_LIBRARY_PATH=$HADOOP_HOME/lib/native执行chmod +x profile,把profile变为可执行文件;执行source profile,把profile内容执行生效;(我们不管是装hadoop和JDK都修改了环境变量,都是在/etc/profile上vi修改的,所以我们做完第一步和第二部之后,可以把profile整个拷贝到你需要增加的datanode节点上。