An audio-visual approach to web video categorization
新进阶3综合unit2答案(20210109231853)
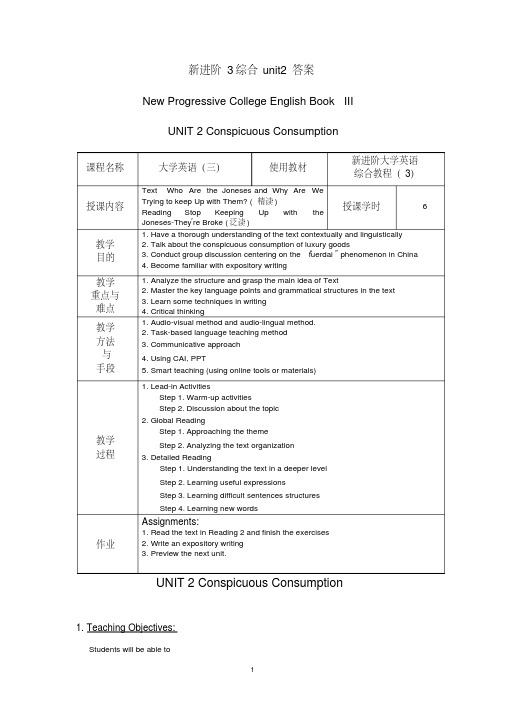
新进阶3综合unit2答案New Progressive College English Book III UNIT 2 Conspicuous Consumption课程名称大学英语(三)使用教材新进阶大学英语综合教程(3)授课内容Text Who Are the Joneses and Why Are WeTrying to keep Up with Them? (精读)Reading Stop Keeping Up with theJoneses-They’re Broke (泛读)授课学时 6教学目的1. Have a thorough understanding of the text contextually and linguistically2. Talk about the conspicuous consumption of luxury goods3. Conduct group discussion centering on the “fuerdai” phenomenon in China4. Become familiar with expository writing教学重点与难点1. Analyze the structure and grasp the main idea of Text2. Master the key language points and grammatical structures in the text3. Learn some techniques in writing4. Critical thinking教学方法与手段1. Audio-visual method and audio-lingual method.2. Task-based language teaching method3. Communicative approach4. Using CAI, PPT5. Smart teaching (using online tools or materials)教学过程1. Lead-in ActivitiesStep 1. Warm-up activitiesStep 2. Discussion about the topic2. Global ReadingStep 1. Approaching the themeStep 2. Analyzing the text organization3. Detailed ReadingStep 1. Understanding the text in a deeper level Step 2. Learning useful expressionsStep 3. Learning difficult sentences structuresStep 4. Learning new words作业Assignments:1. Read the text in Reading 2 and finish the exercises2. Write an expository writing3. Preview the next unit.UNIT 2 Conspicuous Consumption1. Teaching Objectives:Students will be able toA. Have a thorough understanding of the text contextually and linguisticallyB. Talk about the conspicuous consumption of luxury goodsC. Conduct group discussion centering on the “fuerdai” phenomenon in ChinaD. Become familiar with expository writing2. Time Allotment:1st Period: Lead-in Activities (Warm-up activities; Discussion about the topic)2nd Period: Global-reading (Text: Approaching the theme; analyzing the text organization) 3rd Period: Detailed reading (Understanding the Text A in a deeper level, analyzing difficult sentence structures)4th Period: Detailed reading Activities (Learning new words, summarizing good usage)5th Period: Comprehending Reading 1 (Skimming the text, explaining the difficult sentences of the Text, doing sentence translation))6th Period: After-reading Activities (Viewing and Listening; Speaking; Assignments)3. Teaching Procedures:3.1 Lead-in ActivitiesStep 1. Warm-up activitiesAsk Ss to listen to a song and fill in the missing words in the lyrics.Have Ss work in pairs. One student asks the other the questions in Opener, the other answers. Then switch roles.Method: PPT, communicative approach.Step 2: Discussion about the topicIntroduce the topic of the unit to Ss either in English or Chinese: Sometimes people buy things just for the purpose of showing that they are richer, or have better taste than others. Expensive brand-name goods can serve this purpose, and are often wanted precisely because they are expensive. Whether spending money in this way is good, bad or simply silly is something weare going to explore.Method: Using task-based language teaching method, communicative approach.3.2 Global readingStep 1. Approaching the themeAsk Ss to take a look at the Culture Notes, or ask them to do some further reading before class about the idiom “keep up with the Joneses”, its origins and its social impact,etc.Guide Ss to explore the text to fide the meaning and origin of the expression “keep up with the Joneses”, how this phenomenon came into being, and what we should do to rid ourselves ofthe pressure of keeping up with the Joneses.Method: PPT; communicative approach.Step.2 Analyzing the text organizationThe teacher tells students that the text can be divided into three parts which have been givenin the Text Organization. Then students should summarize the main idea of each part and compare notes with each other.Parts Paragraphs Functions Main IdeasPart One Para. 1-2Bringing up the social phenomenonof conspicuous consumptionThe meaning and origin of theexpression “keep up with theJoneses”Part Two Paras. 3-6Explaining how it occurs and why How the phenomenon of keeping upwith the Joneses came into being and why people buy into it.Part Three Paras. 7-10Exploring ways of dealing with it What we should do to free ourselvesfrom the pressure of keeping up withthe Joneses.Method: skimming and scanning, communicative approach3.3 Detailed Reading3.3.1 Procedure1) Students are asked to read the passage carefully again and for each paragraph (sometimestwo-three paragraphs), invite students to answer questions related difficult sentences andunderstanding of each paragraph.2) Help Ss find out the good usage in the text and underlined them.3) Learn new words in details.Purpose: Further understand the text and train scanning ability to learn difficult sentencestructures as well as new words and expressions.Method:Reading the text together; Using task-based language teaching method, readingapproach, communicative approach, grammar-translation approach.Step 1. Questions related difficult sentences and understanding of each paragraph.Paras.2Q. Where does the phrase “Keeping up with the Joneses” come from?A: It comes from a cartoon strip of the same title launched by Pop Momand in 1913.Para.3&4Q: Why were we not aware of what the Joneses were doing prior to the late 1880s?A: Prior to the late 1880s, mass media was not born. We were only concerned about making ourown living.Para.4Q: What was the ready solution provided by magazines in order for us to catch up with theJoneses?A: The ready solution was to buy products that were advertised.Para.9Q: Where do true happiness and joy come from, if they are not anything money can buy?A: True happiness and joy come from within.Paras.10Q: What are we supposed to do to stop keeping up with the Joneses?A: Instead of buying into the message that we’re not good enough, we should have positiveself-regard. We should realize we don’t have to buy things to impress others.3.3.2 Language Focus3.3.2.1 Difficult sentences:1) I’d love to say that need vanished when the last episode of that comic strip ran, but alas, itseems to have only gotten worse. (Para. 2)I would like to say that need disappeared when the comic strip came to an end, but it seems thatthings have turned from bad to worse instead.我多么想说,随着最后一集连环漫画的结束,这一心态也不复存在了。
英语高级视听说-答案-Unit-7-Can-Video-Games-Lead-to-Murder

4- they are considering laws that would ban the sale of violent games to those under 17.
感谢您的阅读收藏,谢谢!
911 Dispatcher
Emergency dispatchers who work in 911 centers.
Glock
it is an Australian defense contractor ( named after the founder Gaston Glock) founded in 1963 near Vienna, Austria. Glock is one of the best selling brands in the US.
While Listening
Episode 1 1- [ F ] 2- [ F ] 3- [ F ] 4- [ T ] 5- [ T ] 6- [ F ]
ห้องสมุดไป่ตู้
TASK 2
Episode 2
1- (E) 2- (C) 3 (A) 4- (D) 5- (G) 6- (B) 7- (F)
Episode 3
First Amendment Lawyer
it is a lawyer who is dedicated to protecting the human rights of the US citizens such as; freedom of speech, freedom of the press, freedom of religion, and freedom of assembly.
视听的英文及例句

视听的英文及例句关于视听的英文及例句视听的英文:audiovisualspotlight参考例句:Audio visual connection视听一体It's an audio-visual book.这是本视听图书。
The hotel offers audio - visual equipment for hire .该饭店经营对外出租视听设备的业务。
The hotel offers audio-visual equipment for hire.该饭店经营对外出租视听设备的业务。
Audio-visual aids for the classroom,eg cassette recorders,video recorders, pictures,etc 课堂视听教具(如盒式录音机,录相机,图片等).The Image Hall is equipped with a 360 degree screen.视听馆里安装了三百六十度的环形银幕。
The latest addition to its service portfolio is the iChannel .the first audio-visual channel on the Internet.CTInets之最新服务为iChannel,乃互联网上首个全动感网上视听频道。
The school's audio-visual apparatus includes a new set of multi-media device, not to mention films, records, etc.这所中学的视听设备包括一套新的多媒体装置,更不用说电影、录音等设备了。
In audiovisual aids, a projector for displaying opaque subject matter on a screen, e.g. the pages of a book 在视听教具中,一种投影仪,用于在屏幕上显示不透明的内容,如书页。
多模态教学在初中英语教学中的应用

多模态教学在初中英语教学中的应用全文共3篇示例,供读者参考篇1Title: The Application of Multimodal Teaching in Junior High School English TeachingIntroductionAs technology continues to evolve, teachers are finding new ways to engage students in the learning process. One such method is multimodal teaching, which involves using multiple modes of communication to deliver information to students. In this article, we will explore the benefits of multimodal teaching in junior high school English classrooms and provide practical examples of how it can be implemented.Benefits of Multimodal Teaching1. Enhances student engagement: By incorporating different modes of communication such as text, images, videos, and audio, multimodal teaching caters to different learning styles and keeps students actively engaged in the learning process.2. Facilitates better understanding: The use of multiple modes of communication helps students to better understand and retain information. For example, visual aids can help students to better visualize abstract concepts, while audio recordings can aid in pronunciation practice.3. Encourages creativity: Multimodal teaching encourages students to think creatively and express their ideas in different ways. Assignments that involve creating videos, podcasts, or digital presentations allow students to showcase their creativity and digital literacy skills.Practical Examples of Multimodal Teaching in Junior High School English1. Interactive whiteboards: Teachers can use interactive whiteboards to present English vocabulary words, grammar rules, and reading passages in a more engaging and interactive way. Students can also participate in interactive activities such as matching games and quizzes.2. Multimedia presentations: Students can create multimedia presentations using tools such as PowerPoint or Prezi to demonstrate their understanding of English concepts. They can incorporate text, images, videos, and audio to make their presentations more engaging.3. Digital storytelling: Students can create digital stories using tools such as Storybird or Adobe Spark to practice their writing and storytelling skills. They can incorporate images, videos, and audio to enhance their stories and make them more engaging.4. Online resources: Teachers can use online resources such as educational websites, videos, and interactive quizzes to supplement classroom instruction and provide additional practice for students. These resources can cater to different learning styles and allow students to review material at their own pace.ConclusionMultimodal teaching is a valuable tool in junior high school English classrooms as it enhances student engagement, facilitates better understanding, and encourages creativity. By incorporating various modes of communication into their lessons, teachers can cater to different learning styles and promote an interactive and dynamic learning environment. It is important for teachers to continue exploring new ways to incorporate multimodal teaching into their lessons and keep students motivated and engaged in their English studies.篇2Title: The Application of Multimodal Teaching in Junior High School English TeachingIntroductionIn recent years, with the rapid development of technology, the traditional way of teaching has been increasingly challenged. In response to this trend, educators have started to explore new teaching methods to enhance students' learning experience. One of these innovative methods is multimodal teaching, which integrates various modes of communication, such as visual, auditory, and kinesthetic, to cater to different learning styles. In this article, we will explore the application of multimodal teaching in junior high school English teaching.Benefits of Multimodal Teaching in English Education1. Enhances Engagement and InterestMultimodal teaching makes learning more interactive and engaging for students. By incorporating videos, images, and interactive activities into the lesson, students are more likely to stay focused and interested in the lesson content. This can help improve their motivation to learn English and increase their overall enjoyment of the subject.2. Accommodates Different Learning StylesEvery student has a unique learning style, and multimodal teaching allows educators to cater to these individual preferences. Some students may learn best through visual aids, while others may prefer hands-on activities or auditory cues. By incorporating various modes of communication, teachers can ensure that all students have the opportunity to learn in a way that works best for them.3. Improves Retention and ComprehensionResearch has shown that using multiple modes of communication can enhance students' retention and comprehension of information. When students are exposed to information through different sensory channels, they are more likely to remember it and understand it more deeply. This can lead to higher academic achievement and overall progress in learning English.4. Promotes Creativity and Critical ThinkingMultimodal teaching encourages students to think creatively and critically as they engage with different types of media. By analyzing and synthesizing information from various sources, students can develop important skills such as problem-solving,communication, and digital literacy. This can prepare them for success in an increasingly complex and interconnected world.Practical Applications of Multimodal Teaching in Junior High School English Classes1. Using Videos and AnimationsIncorporating videos and animations into English lessons can help students visualize concepts and improve their listening skills. For example, teachers can use short film clips or animated stories to introduce new vocabulary, grammar rules, or cultural topics. This can make the lesson more dynamic and engaging for students.2. Interactive Whiteboards and Digital ToolsInteractive whiteboards and digital tools offer a variety of ways to present information in a multimodal format. Teachers can use interactive multimedia presentations, online quizzes, or educational games to enhance student learning. These tools can also facilitate real-time feedback and assessment, allowing teachers to monitor student progress more effectively.3. Hands-On Activities and ProjectsIncorporating hands-on activities and projects into English classes can help students apply their language skills in a practicalcontext. For example, students can create multimedia presentations, perform skits, or produce podcasts to practice speaking and listening skills. This not only reinforces language learning but also encourages creativity and collaboration among students.4. Incorporating Music and SongsMusic and songs can be powerful tools for teaching English language skills. Teachers can use songs to teach vocabulary, pronunciation, and grammar rules in a fun and memorable way. Students can also create their own songs or lyrics as a creative language-building exercise. This can help improve students' fluency, communication skills, and cultural awareness.ConclusionIn conclusion, multimodal teaching offers a wide range of benefits for junior high school English education. By incorporating various modes of communication, teachers can enhance student engagement, accommodate different learning styles, improve retention and comprehension, and promote creativity and critical thinking. Practical applications of multimodal teaching in English classes include using videos and animations, interactive whiteboards and digital tools, hands-on activities and projects, and incorporating music and songs. Byembracing multimodal teaching, educators can create a more dynamic and effective learning environment that prepares students for success in the 21st century.篇3Title: The Application of Multimodal Teaching in Junior High School English TeachingIntroductionMultimodal teaching refers to the use of multiple modes of representation to facilitate learning. In the context of junior high school English teaching, multimodal teaching can enhance students' understanding, engagement, and retention of the language. This article will explore the benefits of multimodal teaching in junior high school English classes and provide examples of how it can be implemented effectively.Benefits of Multimodal Teaching1. Enhanced Understanding: By incorporating visual, auditory, and kinesthetic elements into English lessons, students can better understand and remember new vocabulary, grammar rules, and language structures. For example, using multimedia presentations, flashcards, and interactive activities can helpreinforce key concepts and promote deeper understanding of the language.2. Increased Engagement: Multimodal teaching can make English lessons more interactive and engaging for students. By incorporating videos, songs, games, and hands-on activities, teachers can capture students' interest and motivate them to participate actively in the learning process. This can lead to improved student motivation, confidence, and overall enjoyment of the English language.3. Improved Retention: Research has shown that students retain information better when it is presented in multiple formats. By using a variety of teaching strategies, such as visual aids, diagrams, storytelling, and role-playing activities, teachers can help students retain information more effectively and apply their knowledge in real-life situations.Examples of Multimodal Teaching in Junior High School English Classes1. Visual Aids: Teachers can use visual aids such as posters, charts, graphs, and images to help students understand new vocabulary words, grammar rules, and language concepts. For example, a teacher can create a word wall with pictures anddefinitions of key vocabulary words to reinforce students' understanding and memory of the words.2. Audio-Visual Presentations: Teachers can create multimedia presentations that combine audio, video, and text to present information in a more engaging and interactive way. For example, a teacher can show a short video clip or listen to a song related to a lesson topic to stimulate students' interest and facilitate comprehension of the language.3. Hands-On Activities: Teachers can incorporate hands-on activities such as role-playing, group projects, and games to promote active learning and enhance students' language skills. For example, students can play a vocabulary matching game, act out dialogues, or create a skit to practice speaking and listening skills in a fun and meaningful way.ConclusionIn conclusion, multimodal teaching can be a valuable tool for enhancing junior high school English teaching. By incorporating visual, auditory, and kinesthetic elements into English lessons, teachers can improve students' understanding, engagement, and retention of the language. It is important for teachers to be creative, flexible, and innovative in their use of multimodal teaching strategies to meet the diverse learning needs ofstudents and create a dynamic and interactive learning environment.。
视频术语汇编(中)

E1 –European digital transmission channel with a data rate of 2.048 kbps. EACEM –European Association of Consumer Electronics Manufacturers EAPROM (Electrically Alterable Programmable Read-Only Memo) –A PROM whose contents can be changed.E arth Station –Equipment used for transmitting or receiving satellite communications.EAV (End of Active Video) –A term used with component digital systems.EB (Errored Block)EBR –See Electron Beam Recording.EBU (European Broadcasting Union) –An organization of European broadcasters that,among other activities,produces technical statements and recommendations for the 625/50 line televi-sion system.Created in 1950 and headquartered in Geneva,Switzerland,the EBU is the world’s largest professional association of national broadcasters.The EBU assists its members in all areas of broadcasting,briefing them on developments in the audio-visual sector,providing advice and defending their interests via international bodies.The Union has active members in European and Mediterranean countries and associate members in countries elsewherein Africa,the Americas and Asia.EBU TECH.3267-E – a)The EBU recommendation for the serial composite and component interface of 625/50 digital video signal including embed-ded digital audio.b)The EBU recommendation for the parallel interface of 625 line digital video signal.A revision of the earlier EBU Tech.3246-E, which in turn was derived from CCIR-601 and contributed to CCIR-656 standards.EBU Timecode –The timecode system created by the EBU and based on SECAM or PAL video signals.ECC (Error Correction Code) –A type of memory that corrects errors on the fly.ECC Constraint Length –The number of sectors that are interleaved to combat bursty error characteristics of discs.16 sectors are interleaved in DVD.Interleaving takes advantage of typical disc defects such as scratch marks by spreading the error over a larger data area,thereby increasing the chance that the error correction codes can conceal the error.ECC/EDC (Error Correction Code/Error Detection Code) –Allows data that is being read or transmitted to be checked for errors and,when nec-essary,corrected on the fly.It differs from parity-checking in that errors are not only detected but also corrected.ECC is increasingly being designed into data storage and transmission hardware as data rates (and therefore error rates) increase.Eccentricity –A mathematical constant that for an ellipse is the ratio between the major and minor axis length.more points in the transmission medium,with sufficient magnitude and time difference to be perceived in some manner as a wave distinct from that of the main or primary transmission.Echoes may be either leading or lagging the primary wave and appear in the picture monitor as reflections or “ghosts”.b)Action of sending a character input from a keyboard to the printer or display.Echo Cancellation –Reduction of an echo in an audio system by estimating the incoming echo signal over a communications connection and subtracting its effects from the outgoing signal.Echo Plate –A metal plate used to create reverberation by inducing waves in it by bending the metal.E-Cinema –An HDTV film-complement format introduced by Sony in 1998.1920 x 1080,progressive scan,24 fps,4:4:4 ing a 1/2-inch tape,the small cassette (camcorder) will hold 50 minutes while the large cassette will hold 156 minutes.E-Cinema’s camcorder will use three 2/3-inch FIT CCDs and is equivalent to a film sensitivity of ISO 500. The format will compress the electronic signal somewhere in the range of 7:1.The format is based on the Sony HDCAM video format.ECL (Emitter Coupled Logic) –A variety of bipolar transistor that is noted for its extremely fast switching speeds.ECM –See Entitlement Control Message.ECMA (European Computer Manufacturers Association) –An international association founded in 1961 that is dedicated to establishing standards in the information and communications fields.ECMA-262 –An ECMA standard that specifies the core JavaScript language,which is expected to be adopted shortly by the International Standards Organization (ISO) as ISO 16262.ECMA-262 is roughly equivalent to JavaScript 1.1.ECU (Extreme Closeup)ED-Beta (Extended Definition Betamax) –A consumer/Professional videocassette format developed by Sony offering 500-line horizontal resolution and Y/C connections.Edge – a)An edge is the straight line that connects two points.b)Synonym for key ed by our competitors but not preferred by Ampex.c)A boundary in an image.The apparent sharpness of edges can be increased without increasing resolution.See also Sharpness.Edge Busyness –Distortion concentrated at the edge of objects, characterized by temporally varying sharpness or spatially varying noise.Edge Curl –Usually occurs on the outside one-sixteenth inch of the videotape.If the tape is sufficiently deformed it will not make proper tape contact with the playback heads.An upper curl (audio edge) crease may affect sound quality.A lower edge curl (control track) may result in poor picture quality.Edge Damage –Physical distortion of the top or bottom edge of the mag-netic tape,usually caused by pack problems such as popped strands or stepping.Affects audio and control track sometimes preventing playback. Edge Effect –See Following Whites or Following Blacks.Edge Enhancement –Creating hard,crisp,high-contrast edges beyond the correction of the geometric problem compensated by aperture correc-tion,frequently creates the subjective impression of increase image detail. Transversal delay lines and second-directive types of correction increase the gain at higher frequencies while introducing rather symmetrical “under-shoot followed by overshoot”at transitions.In fact,and contrary to many causal observations,image resolution is thereby decreased and fine detail becomes obscured.Creating a balance between the advantages and disad-vantages is a subjective evaluation and demands an artistic decision. Edge Enhancing –See Enhancing.Edge Filter –A filter that applies anti-aliasing to graphics created to the title tool.Edge Numbers – Numbers printed on the edge of 16 and 35 mm motion picture film every foot which allows frames to be easily identified in an edit list.Edgecode –See Edge Numbers,Key Numbers.EDH (Error Detection and Handling) –Defined by SMPTE standards RP-165 and is used for recognizing inaccuracies in the serial digital signal. It may be incorporated into serial digital equipment and employ a simple LED error indicator.This data conforms to the ancillary data formatting standard (SMPTE 291M) for SD-SDI and is located on line 9 for 525 and line 5 for 625 formats.Edit – a) The act of performing a function such as a cut,dissolve,wipe on a switcher,or a cut from VTR to VTR where the end result is recorded on another VTR.The result is an edited recording called a master.b)Any point on a video tape where the audio or video information has been added to, replaced,or otherwise altered from its original form.Edit Control –A connection on a VCR or camcorder which allows direct communication with external edit control devices.(e.g.,LANC (Control-L) and new (Panasonic) 5-pin).Thumbs Up works with both of these control formats and with machines lacking direct control.Edit Controller –An electronic device,often computer-based,that allows an editor to precisely control,play and record to various videotape machines.Edit Decision List (EDL) – a)A list of a video production’s edit points. An EDL is a record of all original videotape scene location time references, corresponding to a production’s transition events.EDLs are usually generated by computerized editing equipment and saved for later use and modification.b) Record of all edit decisions made for a video program (such as in-times,out-times,and effects) in the form of printed copy, paper tape,or floppy disk file,which is used to automatically assemble the program at a later point.Edit Display –Display used exclusively to present editing data and editor’s decision lists.Edit Master –The first generation (original) of a final edited tape.Edit Point –The location in a video where a production event occurs. (e.g.,dissolve or wipe from one scene to another).Edit Rate –In compositions,a measure of the number of editable units per second in a piece of media data (for example,30 fps for NTSC,25 fps for PAL and 24 fps for film).Edit Sequence –An assembly of clips.Editing –A process by which one or more compressed bit streams are manipulated to produce a new compressed bit stream.Conforming edited bit streams are understood to meet the requirements defined in the Digital Television Standard.Editing Control Unit (ECU) –A microprocessor that controls two or more video decks or VCRs and facilitates frame-accurate editing.Editor –A control system (usually computerized) which allows you to con-trol video tape machines,the video switcher,and other devices remotely from a single control panel.Editors enable you to produce finished video programs which combine video tape or effects from several different sources.EDL (Edit Decision List) –A list of edit decisions made during an edit session and usually saved to floppy disk.Allows an edit to be redone or modified at a later time without having to start all over again.EDO DRAM (Extended Data Out Dynamic Random Access Memory) –EDO DRAM allows read data to be held past the rising edge of CAS (Column Address Strobe) improving the fast page mode cycle time critical to graphics performance and bandwidth.EDO DRAM is less expensive than VRAM.EDTV –See Extended/Enhanced Definition Television.E-E Mode (Electronic to Electronic Mode) –The mode obtained when the VTR is set to record but the tape is not running.The VTR is processing all the signals that it would normally use during recording and playback but without actually recording on the tape.EEprom E2,E’squared Prom –An electronically-erasable,programmable read-only memory device.Data can be stored in memory and will remain there even after power is removed from the device.The memory can be erased electronically so that new data can be stored.Effect – a)One or more manipulations of the video image to produce a desired result.b)Multi-source transition,such as a wipe,dissolve or key. Effective Competition –Market status under which cable TV systems are exempt from regulation of basic tier rates by local franchising authorities, as defined in 1992 Cable Act.To claim effective competition,a cable system must compete with at least one other multi-channel provider that is available to at least 50% of an area’s households and is subscribed to by more than 15% of the households.Effects –The manipulation of an audio or video signal.Types of film or video effects include special effects (F/X) such as morphing; simple effects such as dissolves,fades,superimpositions,and wipes; complex effects such as keys and DVEs; motion effects such as freeze frame and slow motion; and title and character generation.Effects usually have to be rendered because most systems cannot accommodate multiple video streams in real time.See also Rendering.Effects (Setup) –Setup on the AVC,Century or Vista includes the status of every push-button,key setting,and transition rate.The PANEL-MEM system can store these setups in memory registers for future use.Effects Keyer (E Keyer) –The downstream keyer within an M/E,i.e.,the last layer of video.Effects System –The portion of the switcher that performs mixes,wipes and cuts between background and/or affects key video signals.The Effects System excludes the Downstream Keyer and Fade-to-Black circuitry.Also referred to as Mix Effects (M/E) system.EFM (Eight-to-Fourteen Modulation) –This low-level and very critical channel coding technique maximizes pit sizes on the disc by reducing frequent transitions from 0 to 1 or 1 to 0.CD represents 1's as Land-pit transitions along the track.The 8/14 code maps 8 user data bits into 14 channel bits in order to avoid single 1's and 0's,which would otherwise require replication to reproduce extremely small artifacts on the disc.In the 1982 compact disc standard (IEC 908 standard),3 merge bits are added to the 14 bit block to further eliminate 1-0 or 0-1 transitions between adjacent 8/14 blocks.EFM Plus –DVD’s EFM+ method is a derivative of EFM.It folds the merge bits into the main 8/16 table.EFM+ may be covered by U.S.Patent5,206,646.EGA (Enhanced Graphics Adapter) –A display technology for the IBM PC.It has been replaced by VGA.EGA pixel resolution is 640 x 350.EIA (Electronics Industries Association) –A trade organization that has created recommended standards for television systems (and other electronic products),including industrial television systems with up to 1225 scanning lines.EIA RS-170A is the current standard for NTSC studio equipment.The EIA is a charter member of ATSC.EIA RS-170A –The timing specification standard for NTSC broadcast video equipment.The Digital Video Mixer meets RS-170A.EIA/IS-702 –NTSC Copy Generation Management System – Analog (CGMS-A).This standard added copy protection capabilities to NTSC video by extending the EIA-608 standard to control the Macrovision anti-copy process.It is now included in the latest EIA-608 standard.EIA-516 –U.S.teletext standard,also called NABTS.EIA-608 –U.S.closed captioning and extended data services (XDS) stan-dard.Revision B adds Copy Generation Management System – Analog (CGMS-A),content advisory (v-chip),Internet Uniform Resource Locators (URLs) using Text-2 (T-2) service,16-bit Transmission Signal Identifier,and transmission of DTV PSIP data.EIA-708 –U.S.DTV closed captioning standard.EIA CEB-8 also provides guidance on the use and processing of EIA-608 data streams embedded within the ATSC MPEG-2 video elementary transport stream,and augments EIA-708.EIA-744 –NTSC “v-chip”operation.This standard added content advisory filtering capabilities to NTSC video by extending the EIA-608 standard.It is now included in the latest EIA-608 standard,and has been withdrawn. EIA-761 –Specifies how to convert QAM to 8-VSB,with support for OSD (on screen displays).EIA-762 –Specifies how to convert QAM to 8-VSB,with no support for OSD (on screen displays).EIA-766 –U.S.HDTV content advisory standard.EIA-770 –This specification consists of three parts (EIA-770.1,EIA-770.2, and EIA-770.3).EIA-770.1 and EIA-770.2 define the analog YPbPr video interface for 525-line interlaced and progressive SDTV systems.EIA-770.3 defines the analog YPbPr video interface for interlaced and progressive HDTV systems.EIA-805 defines how to transfer VBI data over these YPbPr video interfaces.EIA-775 –EIA-775 defines a specification for a baseband digital interface to a DTV using IEEE 1394 and provides a level of functionality that is simi-lar to the analog system.It is designed to enable interoperability between a DTV and various types of consumer digital audio/video sources,including set top boxes and DVRs or VCRs.EIA-775.1 adds mechanisms to allow a source of MPEG service to utilize the MPEG decoding and display capabili-ties in a DTV.EIA-775.2 adds information on how a digital storage device, such as a D-VHS or hard disk digital recorder,may be used by the DTVor by another source device such as a cable set-top box to record or time-shift digital television signals.This standard supports the use of such storage devices by defining Service Selection Information (SSI),methods for managing discontinuities that occur during recording and playback, and rules for management of partial transport streams.EIA-849 specifies profiles for various applications of the EIA-775 standard,including digital streams compliant with ATSC terrestrial broadcast,direct-broadcast satellite (DBS),OpenCable™,and standard definition Digital Video (DV) camcorders.EIA-805 –This standard specifies how VBI data are carried on component video interfaces,as described in EIA-770.1 (for 480p signals only),EIA-770.2 (for 480p signals only) and EIA-770.3.This standard does not apply to signals which originate in 480i,as defined in EIA-770.1 and EIA-770.2. The first VBI service defined is Copy Generation Management System (CGMS) information,including signal format and data structure when car-ried by the VBI of standard definition progressive and high definition YPbPr type component video signals.It is also intended to be usable when the YPbPr signal is converted into other component video interfaces including RGB and VGA.EIA-861 – The EIA-861 standard specifies how to include data,such as aspect ratio and format information,on DVI and HDMI.EIAJ (Electronic Industry Association of Japan) –The Japanese equivalent of the EIA.EIA-J CPR-1204 –This EIA-J recommendation specifies another widescreen signaling (WSS) standard for NTSC video signals.E-IDE (Enhanced Integrated Drive Electronics) –Extensions to the IDE standard providing faster data transfer and allowing access to larger drives,including CD-ROM and tape drives,using ATAPI.E-IDE was adopted as a standard by ANSI in 1994.ANSI calls it Advanced Technology Attachment-2 (ATA-2) or Fast ATA.EISA (Enhanced Industry Standard Architecture) –In 1988 a consor-tium of nine companies developed 32-bit EISA which was compatible with AT architecture.The basic design of EISA is the result of a compilation of the best designs of the whole computer industry rather than (in the case ofthe ISA bus) a single company.In addition to adding 16 new data linesto the AT bus,bus mastering,automated setup,interrupt sharing,and advanced transfer modes were adapted making EISA a powerful and useful expansion design.The 32-bit EISA can reach a peak transfer rate of33 MHz,over 50% faster than the Micro Channel architecture.The EISA consortium is presently developing EISA-2,a 132 MHz standard.EISA Slot –Connection slot to a type of computer expansion bus found in some computers.EISA is an extended version of the standard ISA slot design.EIT (Encoded Information Type)EIT (Event Information Table) –Contains data concerning events (a grouping of elementary broadcast data streams with a defined start and end time belonging to a common service) and programs (a concatenation of one or more events under the control of a broadcaster,such as event name,start time,duration,etc.).Part of DVB-SI.Electromagnetic Interference (EMI) –Interference caused by electrical fields.Electron Beam Recording –A technique for converting television images to film using direct stimulation of film emulsion by a very fine long focal length electronic beam.E lectronic Beam Recorder (EBR) –Exposes film directly using an electronic beam compared to recording from a CRT.Electronic Cinematography –Photographing motion pictures with television equipment.Electronic cinematography is often used as a term indicating that the ultimate product will be seen on a motion picture screen,rather than a television screen.See also HDEP and Mathias.Electronic Crossover –A crossover network which uses active filters and is used before rather than after the signal passes through the power amp.Electronic Editing –The assembly of a finished video program in which scenes are joined without physically splicing the tape.Electronic editing requires at least two decks:one for playback and the other for recording. Electronic Matting –The process of electronically creating a composite image by replacing portions of one image with another.One common,if rudimentary,form of this process is chroma-keying,where a particular color in the foreground scene (usually blue) is replaced by the background scene.Electronic matting is commonly used to create composite images where actors appear to be in places other than where they are being shot. It generally requires more chroma resolution than vision does,causing contribution schemes to be different than distribution schemes.While there is a great deal of debate about the value of ATV to viewers,there does not appear to be any dispute that HDEP can perform matting faster and better than almost any other moving image medium.Electronic Pin Register (EPR) –Stabilizes the film transport of a telecine.Reduces ride (vertical moment) and weave (horizontal movement). Operates in real time.Electrostatic Pickup –Pickup of noise generated by electrical sparks such as those caused by fluorescent lights and electrical motors. Elementary Stream (ES) – a)The raw output of a compressor carrying a single video or audio signal.b)A generic term for one of the coded video,coded audio,or other coded bit streams.One elementary stream is carried in a sequence of PES packets with one and only one stream_id.Elementary Stream Clock Reference (ESCR) –A time stamp in the PES from which decoders of PES may derive timing.Elementary Stream Descriptor –A structure contained in object descriptors that describes the encoding format,initialization information, transport channel identification,and other descriptive information about the content carried in an elementary stream.Elementary Stream Header (ES Header) –Information preceding the first data byte of an elementary stream.Contains configuration information for the access unit header and elementary stream properties.Elementary Stream Interface (ESI) –An interface modeling the exchange of elementary stream data and associated control information between the Compression Layer and the Sync Layer.Elementary Stream Layer (ES Layer) –A logical MPEG-4 Systems Layer that abstracts data exchanged between a producer and a consumer into Access units while hiding any other structure of this data.Elementary Stream User (ES User) –The MPEG-4 systems entity that creates or receives the data in an elementary stream.ELG (European Launching Group) –Now superseded by DVB.EM (Electronic Mail) –Commonly referred to as E-mail.Embedded Audio – a)Embedded digital audio is mul-tiplexed onto a seri-al digital data stream within the horizontal ancillary data region of an SDI signal.A maximum of 16 channels of audio can be carried as standardized with SMPTE 272M or ITU-R.BT.1305 for SD and SMPTE 299 for HD.b)Digital audio that is multiplexed and carried within an SDI connection –so simplifying cabling and routing.The standard (ANSI/SMPTE 272M-1994) allows up to four groups each of four mono audio channels.Embossing –An artistic effect created on AVAs and/or switchers to make characters look like they are (embossed) punched from the back of the background video.EMC (Electromagnetic Compatibility) –Refers to the use of compo-nents in electronic systems that do not electrically interfere with each other.See also EMI.EMF (Equipment Management Function) –Function connected toall the other functional blocks and providing for a local user or the Telecommunication Management Network (TMN) a mean to perform all the management functions of the cross-connect equipment.EMI (Electromagnetic Interference) –An electrical disturbance in a sys-tem due to natural phenomena,low-frequency waves from electromechani-cal devices or high-frequency waves (RFI) from chips and other electronic devices.Allowable limits are governed by the FCC.See also EMC. Emission – a)The propagation of a signal via electromagnetic radiation, frequently used as a synonym for broadcast.b) In CCIR usage:radio-frequency radiation in the case where the source is a radio transmitteror radio waves or signals produced by a radio transmitting station.c) Emission in electronic production is one mode of distribution for the completed program,as an electromagnetic signal propagated to thepoint of display.EMM –See Entitlement Management Message.E-Mode –An edit decision list (EDL) in which all effects (dissolves,wipes and graphic overlays) are performed at the end.See also A-Mode,B-Mode, C-Mode,D-Mode,Source Mode.Emphasis – a)Filtering of an audio signal before storage or transmission to improve the signal-to-noise ratio at high frequencies.b)A boost in signal level that varies with frequency,usually used to improve SNRin FM transmission and recording systems (wherein noise increaseswith frequency) by applying a pre-emphasis before transmission and a complementary de-emphasis to the receiver.See also Adaptive Emphasis. Emulate –To test the function of a DVD disc on a computer after format-ting a complete disc image.Enable –Input signal that allows the device function to occur.ENB (Equivalent Noise Bandwidth) –The bandwidth of an ideal rectan-gular filter that gives the same noise power as the actual system. Encode – a)The process of combining analog or digital video signals, e.g.,red,green and blue,into one composite signal.b)To express a single character or a message in terms of a code.To apply the rules of a code. c)To derive a composite luminance-chrominance signal from R,G,B signals.d)In the context of Indeo video,the process of converting the color space of a video clip from RGB to YUV and then compressing it.See Compress,RGB,pare Decode.Encoded Chroma Key –Synonym for Composite Chroma Key. Encoded Subcarrier –A reference system created by Grass Valley Group to provide exact color timing information.Encoder – a)A device used to form a single composite color signal (NTSC,PAL or SECAM) from a set of component signals.An encoder is used whenever a composite output is required from a source (or recording) which is in component format.b)Sometimes devices that change analog signals to digital (ADC).All NTSC cameras include an encoder.Because many of these cameras are inexpensive,their encoders omit many ofthe advanced techniques that can improve NTSC.CAV facilities canuse a single,advanced encoder prior to creating a final NTSC signal.c)An embodiment of an encoding process.Encoding (Process) –A process that reads a stream of input pictures or audio samples and produces a valid coded bit stream as defined in the Digital Television Standard.Encryption – a) The process of coding data so that a specific code or key is required to restore the original data.In broadcast,this is used to make transmission secure from unauthorized reception as is often found on satellite or cable systems.b) The rearrangement of the bit stream of a previously digitally encoded signal in a systematic fashion to make the information unrecognizable until restored on receipt of the necessary authorization key.This technique is used for securing information transmit-ted over a communication channel with the intent of excluding all other than authorized receivers from interpreting the message.Can be used for voice,video and other communications signals.END (Equivalent Noise Degradation)End Point –End of the transition in a dissolve or wipe.Energy Plot –The display of audio waveforms as a graph of the relative loudness of an audio signal.ENG (Electronic News Gathering) –Term used to describe use of video-recording instead of film in news coverage.ENG Camera (Electronic News Gathering camera) –Refers to CCD cameras in the broadcast industry.Enhancement Layer –A relative reference to a layer (above the base layer) in a scalable hierarchy.For all forms of scalability,its decoding process can be described by reference to the lower layer decoding process and the appropriate additional decoding process for the Enhancement Layer itself.Enhancing –Improving a video image by boosting the high frequency content lost during recording.There are several types of enhancement. The most common accentuates edges between light and dark images. ENRZ (Enhanced Non-Return to Zero)Entitlement Control Message (ECM) –Entitlement control messages are private conditional access information.They are program-specific and specify control and scrambling parameters.Entitlement Management Message (EMM) –Private Conditional Access information which specifies the authorization levels or the services of specific decoders.They may be addressed to individual decoder or groups of decoders.Entrophy –The average amount of information represented by a symbol in a message.It represents a lower bound for compression.Entrophy Coding –Variable-length lossless coding of the digital represen-tation of a signal to reduce redundancy.Entrophy Data –That data in the signal which is new and cannot be compressed.Entropy –In video,entropy,the average amount of information represent-ed by a symbol in a message,is a function of the model used to produce that message and can be reduced by increasing the complexity of the model so that it better reflects the actual distribution of source symbolsin the original message.Entropy is a measure of the information contained in a message,it’s the lower bound for compression.Entry –The point where an edit will start (this will normally be displayed on the editor screen in time code).Entry Point –The point in a coded bit stream after which the decoder can be initialized and begin decoding correctly.The picture that follows the entry point will be an I-picture or a P-picture.If the first transmitted picture is not an I-picture,the decoder may produce one or more pictures during acquisition.Also referred to as an Access Unit (AU).E-NTSC –A loosely applied term for receiver-compatible EDTV,used by CDL to describe its Prism 1 advanced encoder/decoder family.ENTSC –Philips ATV scheme now called HDNTSC.Envelope Delay –The term “Envelope Delay”is often used interchange-ably with Group Delay in television applications.Strictly speaking,envelope delay is measured by passing an amplitude modulated signal through the system and observing the modulation envelope.Group Delay on the other。
Audio-visual视听语言

Audio-visual Language(视听语言)一、What’s the audio-visual language?1.It’s a kind of way of thinking, it as a method of the film to reflect life’s art. It’s also a method of the imaginalthinking.2.It’s the basic stucture, narrative method, shooting script,arrangement and combination of scenes of the film’s paragraph.3.It’s a collective skill and method of the film editing. It main research: thinking method, creative method, basic language.二、What have you learnt in this course?By learning in this course, i know how to use the audio-visual language to understand what the movie saide, what the director want to express and many skills that how to make a film.The audio-visual language has several parts. The most important part is the language of the picture’s modeling.Includes: ShotDepth of field <DOF> and focal lengthAngleCompositionColor and tintLightingPoint of view<1> ShotThe basic element of the movie. The shot means distance, it suggests the screen space. As a narrative means, it can also emphasis on detailsIncludes: Extreme long shotLong shotMedium shotMedium close-upClose-upExreme close-up<2>Depth of field <DOF> and focal length.Includes: Wide angle shotMedium focal length shotFull-length shotDeep field shotIn a word, different shot means different expressive ability.<3>AngleThe angle is the expression of the creator’s attitude. It’s divided into the lens angle, shooting angle and camera angle.It can very effectively express narrative information and emotional attitude.Includes: Extremely high angleHigh levelLow angle (increase the vertical feeling)Eye level angleThe angle is the director’s expressive method.<4>Composition① accurately convey the image features and aesthetic feeling② highlight the main image③ make picture metapher effect.E.g. Location principleCentre: stable,seriousTop: powerful, control everythingEdge: not important and powerlessBottom: weakArea principleThe basic form of composition① geometric centre② visual centre <golden section><5> Color and tintThree main elements: hue, saturation, lightnessThe colo has its own emotionWarm color: red, orange, yellow, olivine <yellow green>Cold cole :light green, blueness, blue, purple.The warm color is usually standing for disturbed, violence, warm and energy The cold color is usually standing for quiet, loneliness, retreat and shrinkage.<6>Lighting① nature light source② artifical light sourceLights positionBack lightingBack-side lightingSide lightingFront-side lightingFront lightingToplighting high-key lighting: gray-whiteFootlighting low-key lighting: gray-black<7> Point of view1)objective point of view2)subjective point of view3)director’s point of view4)indirect subjective point of viewThe shot’s formFixed shot - staticMoving shot: panning —keep the picture movingTruck-up <dolly shot>Overall ↔ local environment ↔ detailRecord the character’s movement.Long take:With a single shot not pause to express some kind of intentionMise-en-scene① character - scheduling② shot - schedulingFilm editing and mentage① Film editing is an important link in film production② put the single shot to form a whole, like jigsaw puzzleFilm editing:1)Choose the required shots — time change2)Decide the length of shots — lead audience’s mood3)Arrange the shots — tell story or express ideasMentageArrange a series shots which in different locations, from different distance and angle and with different method to shoot.Example 电影实例赏析《Leon》This film tells about a girl of 12 years old and her family was killed. Then she fled to the killer leon’s home. She puts her love and hope in this man. They live together everyday. Leon also promised to teach her how to be a killer. They are together day and night. They gradually fall in love with each other. Finally in order to help her revenge, leon was dead.The begining of the film is an extreme close-up to character facial features, wearing sunglasses, simple language to show the killer-leon. The color ues the dark tone to express the dark killer wo lives in the darkness longtime. The next isn’t also forget to put a gun as a long shot to express his loneliness. It also has many close-up to express the pure and kind side of the girl. The whole film use a lot of mentage, like cross mentage to expres two person’s facial features. In the end, the film ues a gentle music to express their beautiful hope.《Titanic》It’s a one of my favorite film, mainly tell a story about the great love of life and death.It use lots of mentage.① Revers the mentageThe film begins with the old rose’s memory. In terms of time, it’s backwards.② The accumulation of mentageIn the film has many shots like see water rans into the hull and smashs glass and doors to express that the water swallows ruthless fragile life to make a kind of nervous atmosphere.③ comparative mentageWhen the see water rans into the hull, all of the people are afraid. But the violin musicians decide to play a final music ,they are so calm.As for the point of view sometimes is the subjective and objective, for example, when they dancing, the camera sometimes follow jack and sometimes as a indirect view-point.There are also so many scene transitions between old rose now and her memories.To be honest, i especially like lines: you jump i jump and the back ground music 《my heart will go on》。
英语专业综合教程3答案unit 10
Unit 10 The TransactionSection One Pre-reading Activities (1)I. Audiovisual Supplement (1)II.Cultural Background (2)Section Two Global Reading (3)I. Text Analysis (3)II. Structural Analysis (3)Section Three Detailed Reading (4)I. Text 1 (4)II. Questions (5)III.Words and Expressions (6)IV. Sentences (8)Section Four Consolidation Activities (8)Ⅰ.Vocabulary (8)Ⅲ. Translation (13)Ⅳ. Exercises for Integrated Skills (15)Ⅴ. Oral Activities (17)Ⅵ. Writing (17)Section Five Further Enhancement (19)I. Lead-in Questions (19)II. Text 2 (20)III. Memorable Quotes (22)Section One Pre-reading ActivitiesI. Audiovisual SupplementWatch the video clip and answer the following questions.Script:Mr. Keating: Go on. Rip it out. Tha nk you Mr. Dalton. Gentlemen, tell you what, don’t just tear out that page, tear out the entire introduction. I want it gone, history. Leave nothingof it. Rip it out. Rip! Begone J. Evans Pritchard, Ph.D. Rip. Shred. Tear. Rip it out! Iwant to hear nothi ng but ripping of Mr. Pritchard. We’ll perforate it, put it on a roll.It’s not the Bible. You’re not going to go to hell for this. Go on. Make a clean tear. Iwant nothing left of it.Cameron:We shouldn’t be doing this.Neil: Rip! Rip! Rip!Mr. Keating: Rip it out! Rip!McAllister: What the hell is going on here?Mr. Keating: I don’t hear enough rips.McAllister: Mr. Keating.Mr. Keating: Mr. McAllister.McAllister: I’m sorry, I—I didn’t know you were here.Mr. Keating: I am.McAllister: Ah, so you are. Excuse me.Mr. Keating: Keep ripping gentlemen. This is a battle, a war. And the casualties could be your hearts and souls. Thank you Mr. Dalton. Armies of academics going forward,measuring poetry. No, we will not have that here. No more of Mr. J. Evans Pritchard.Now in my class you will learn to think for yourselves again. You will learn to savorwords and language. No matter what anybody tells you, words and ideas can changethe world.(在每个问题下面设置按钮,点击以后出现下面的答案)1. What does Mr. Keating ask students to do?He asks students to rip the introduction part of the poetry text book.2. What is the purpose of his doing so?His intention is to develop the students’ ability of independent thinking which is quite important in literature study. He believes that words and ideas can change the world.II.Cultural BackgroundThe Importance of DialogueMany philosophers and writers would like to express their philosophic ideas through the form of dialogue. And one important theorist making great contribution in clarifying the function of dialogic thinking is Mikhail Bakhtin.1) Self-other relationship —―other‖ plays a key role in understanding:In order to understand, it is immensely important for the person who understands to be located outside the object of his or her creative understanding — in time, in space, in culture.—Mikhail Bakhtin (from New York Review of Books, June 10, 1993)2) Polyphony (many voices) — single voice is not the carrier of truth:Truth is a number of mutually addressed, albeit contradictory and logically inconsistent, statements. Truth needs a multitude of carrying voices.Section Two Global ReadingI. Text AnalysisThe text opens with two writers answering student s’ questions about how to write in dialogue, showing sharp contrasts from various aspects. By summarizing different methods in writing, the text later on points out that even with diversity and differentiation, the common ground of any writing is the same. Many renowned philosophers and writers such as Plato and Oscar Wilde expressed their philosophic ideas in the form of dialogue where different aspects of truth were better presented. Through dialogue between people on an equal footing, we get the revelation that different, sometimes even seemingly contradictory elements, can co-exist so harmoniously within the range of one truth. Human beings have an inclination to look at the world from a self-centered perspective, and it will result in an illusion far from truth. Therefore, it is important for one to try his best to train his mind from an early time in his life to tolerate other people’s opinions of the world because such different understanding of life helps one better pursue the truth.II. Structural Analysis1) In terms of organization, the article clearly falls into two main parts:The first part (Paragraphs 1-17) is devoted to answers given by two writers to the students’questions.The second part (Paragraphs 18-22) is a generalization of the essence of writing.2) In order to deliver the sharp differences in the answers of the two writers in the first part, the author uses●Short paragraphs and the repetition of ―he said …‖ and ―Then I said …‖●The rhetorical trick of contraste.g. ―The words just flowed. It was easy.‖ (Paragraph 3) vs. ―It was hard and lonely, and thewords seldom just flowed.‖ (Paragraph 4)●Advantage of such rhetoric technique: some knowledge of different and even conflictingideas helps one to gain greater thinking power and acquire a broader vision.3) The diversity of the writing methods in the second part is expressed by the parallel use of―some …‖ and ―others …‖e.g. Some people write by day, others by night. Some people need silence, others turn on the radio. (Paragraph 18)4) The transition paragraph from the specific examples to general discussion of the topic is Paragraph 17; The shift from the diversity to the commonality shared by all writers is realized with two words ―But all‖ in the beginning of Paragraph 19.Section Three Detailed ReadingI. Text 1The TransactionWilliam Zinsser1 About ten years ago a school in Connecticut held ―a day devoted to the arts,‖ and I was asked if I would come and talk about writing as a vocation. When I arrived I found that a second speaker had been invited —Dr. Brock (as I’ll call him), a surgeon who had recently begun to write and had sold some stories to national magazines. He was going to talk about writing as an avocation. That made us a panel, and we sat down to face a crowd of student newspaper editors, English teachers and parents, all eager to learn the secrets of our glamorous work.2 Dr. Brock was dressed in a bright red jacket, looking vaguely bohemian, as authors are supposed to look, and the first question went to him. What was it like to be a writer?3 He said it was tremendous fun. Coming home from an arduous day at the hospital, he would go straight to his yellow pad and write his tensions away. The words just flowed. It was easy.4 I then said that writing wasn’t easy and it wasn’t fun. It was hard and lonel y, and the words seldom just flowed.5 Next Dr. Brock was asked if it was important to rewrite. ―Absolutely not,‖ he said. ―Let it all hang out, and whatever form the sentences take will reflect the writer at his most natural.‖6 I then said that rewriting is the essence of writing. I pointed out that professional writers rewrite their sentences repeatedly and then rewrite what they have rewritten. I mentioned that E. B. White and James Thurber rewrote their pieces eight or nine times.7 ―What do you do on days when it isn’t going well?‖ Dr. Brock was asked. He said he just stopped writing and put the work aside for a day when it would go better.8 I then said that the professional writer must establish a daily schedule and stick to it. I said that writing is a craft, not an art, and that the man who runs away from his craft because he lacks inspiration is fooling himself. He is also going broke.9 ―What if you’re feeling depressed or unhappy?‖ a student asked. ―Won’t that affect your writing?‖10 Probably it will, Dr. Brock replied. Go fishing. Take a walk.11 Probably it won’t, I said. If your job is to write every day, you learn to do it like any other job.12 A student asked if we found it useful to circulate in the literary world. Dr. Brock said that he was greatly enjoying his new life as a man of letters, and he told several stories of being taken to lunch by his publisher and his agent at chic Manhattan restaurants where writers and editors gather.I said that professional writers are solitary drudges who seldom see other writers.13 ―Do you put symbolism in your writing?‖ a student asked me.14 ―Not if I can help it,‖ I replied. I have an unbroken record of missing the deeper meaning in any story, play or movie, and as for dance and mime, I have never had even a remote notion of what is being conveyed.15 ―I love symbols!‖ Dr. Brock exclaimed, and he described with gusto the joys of weaving them through his work.16 So the morning went, and it was a revelation to all of us. At the end Dr. Brock told me he was enormously interested in my answers —it had never occurred to him that writing could be hard. I told him I was just as interested in his answers —it had never occurred to me that writing could be easy. (Maybe I should take up surgery on the side.)17 As for the students, anyone might think we left them bewildered. But in fact we probably gave them a broader glimpse of the writing process than if only one of us had talked. For of course there isn’t any ―right‖ way to do such intensely personal work. There are all kinds of writers and all kinds of methods, and any method that helps people to say what they want to say is the right method for them.18 Some people write by day, others by night. Some people need silence, others turn on the radio. Some write by hand, some by typewriter or word processor, some by talking into a tape recorder. Some people write their first draft in one long burst and then revise; others can’t write the second paragraph until they have fiddled endlessly with the first.19 But all of them are vulnerable and all of them are tense. They are driven by a compulsion to put some part of themselves on paper, and yet they don’t just write what comes naturally. They sit down to commit an act of literature, and the self who emerges on paper is a far stiffer person than the one who sat down. The problem is to find the real man or woman behind all the tension.20 For ultimately the product that any writer has to sell is not the subject being written about, but who he or she is. I often find myself reading with interest about a topic I never thought would interest me —some unusual scientific quest, for instance. What holds me is the enthusiasm of the writer for his field. How was he drawn into it? What emotional baggage did he bring along? How did it change his life? It’s not necessary to want to spend a year alone at Walden Pond to become deeply involved with a writer who did.21 This is the personal transaction that’s at the heart of good nonfiction wr iting. Out of it come two of the most important qualities that this book will go in search of: humanity and warmth. Good writing has an aliveness that keeps the reader reading from one paragraph to the next, and it’s not a question of gimmicks to ―personalize‖ the author. It’s a question of using the English language in a way that will achieve the greatest strength and the least clutter.22 Can such principles be taught? Maybe not. But most of them can be learned.II. Questions1.Do you think the process of the activity is within the expectation of both the speakers and theaudience? (Paragraphs 1-17)No. Due to the differences in the background of the two speakers, different views towards the topic of writing are somewhat anticipated. But the fact that their opinions should be so conflicting to each other is a surprise to both the speakers and the audience.2.What would be the possible response of the students as suggested by the writer?(Paragraph17)The students might have a broader glimpse of the writing process. They would realize that there might be totally different writers and methods of writing and the most effective method of writing is the one that helps the writer to say what he wants to say.3.What does the writer mean when he says that all of the w riters are ―vulnerable and tense‖?(Paragraph 19)―Vulnerable‖ refers to the quality of being sensitive to all the stimulus in life, and ―tense‖ refers to the sharp awareness of expressing natural feelings in an artistic way.4.What does the writer think is the very thing that makes a piece of good writing? (Paragraph21)According to the writer, it’s the existence of the personal transaction that makes a piece of good writing. The writer should devote genuine emotion in the process of writing and only thus can he arouse the expected response in his readers.5.What does the writer mean that such principles cannot be taught but can be learned?(Paragraph 22)What can be taught in writing is the writing skills, but writing skills alone cannot make a great, or even a good, piece of writing. The genuine enthusiasm for art and sincere emotion for the world, which are essential to good writing, can only be learned by heart and through one’s life experiences.Class Activity (放在课文的末尾)Group discussion: Do you enjoy the process of writing? Do you write with the flow of thought or based on careful planning and meditation? Share your experiences with you classmates. Impromptu writing: Use ten minutes to write whatever in your mind on a piece of paper and read this writing to the class.III.Words and ExpressionsParagraphs1-17bohemian a.having or denoting the qualities of a person with artistic or literary interests who disregards conventional standards of behaviore.g. bohemian cafes frequented by artists, musicians, and actorsarduous a.involving strenuous effort, difficult and tiringe.g.After a long, hot, and arduous journey we fell asleep the moment our heads touched the pillows.The experiment was far more arduous than most of us had expected.Antonym:facilecirculate v.move around a social function to talk to different people; move continuously through a closed system or areae.g. Rumours started to circulate among the villagers about the cause of his death right after hedied.Derivation:circulation (n.)e.g. This kind of stamp is no longer in circulation.symbolism n.Symbolism is an artistic and poetic movement or style using symbolic images and indirect suggestion to express mystical ideas, emotions, and states of mind. It originated in late 19th-century France and Belgium, flourished all over Europe, had great international impact, and influenced 20th-century art and literature.e.g. poetry full of religious symbolismDerivations:symbol (n.), symbolic (a.), symbolize (v.)Practice:What does this ____ ____? (symbol, symbolize) symbolize这个符号象征着什么?bewilder v.cause sb. to become perplexed and confusede.g. He was bewildered by his daughter's reaction.Synonyms:puzzle, perplex, confoundParagraphs18-22fiddle v.tinker with sth. in an attempt to make minor adjustments or improvementse.g. She sat in the car and played the radio, fiddling with the knobs.Collocations:fiddle withe.g. Feeling nervous when facing the interviewer, she fiddled with the strings of her purse.fiddle about / arounde.g. Stop fiddling about and do some work.commit v.do sth. wrong or illegale.g.It was disclosed in the media that this senior official had committed adultery with severalfemales.Collocations:commit sb. / sth. to sth.:order sb. to be put in a hospital or prisone.g. commit a man to prisoncommit sb. / oneself (to sth. / to doing sth.):say that sb. will definitely do sth. or must do sth.e.g.He has committed himself to support his brother’s children.Derivation:commitment (n.): a promise to do sth. or to behave in a particular waye.g.the government's commitment to public servicesIV. Sentences1.Coming home from an arduous day at the hospital, he would go straight to his yellow pad and write his tensions away. (Paragraph 3)Paraphrase:After a whole day’s intense work at the hospital, he would get rid of his tensions through writing.2.“Let it all hang out, and whatever form the sentences take will reflect the writer at his most natural.” (Paragraph 5)Paraphrase:Let the writer relax completely and the sentences he writes will show the most natural state of him.3.I have an unbroken record of missing the deeper meaning in any story, play or movie, and as for dance and mime, I have never had even a remote notion of what is being conveyed. (Paragraph 14)Paraphrase:I have nearly always failed to understand the hidden, implicit meaning expressed in any story, play or movie, and I do not have the slightest idea of what is being conveyed in dance and mime.4.Maybe I should take up surgery on the side. (Paragraph 16)Paraphrase:Perhaps I should take up surgery as a hobby.5.They sit down to commit an act of literature (paragraph 19)Paraphrase:They sit down to do some literary writing.Section Four Consolidation ActivitiesⅠ.VocabularyI. Explain the underlined part in each sentence in your own words.1. unconventional2. socialize3. dramatic disclosure of something not previously known or realized4. sensitive to the stimulus in life; sharply aware of expressing their natural feelings in an artistic way5. serve the writer’s purpose most effectively and efficientlyII. Fill in the blank in each sentence with a word taken from the box in its appropriate form.1. transaction2.cluttered3. arduous4. humanitymitted6. gusto7. bewildered8. solitaryIII. Word Derivation1) drudge n. → drudge v. → drudgery n.无尽无休的﹑单调乏味的家务the endless drudgery of housework给那个公司打工无异于做苦力。
Audio-Visual Event Localization in Unconstrained V
Supplementary FileAudio-Visual Event Localization inUnconstrained VideosYapeng Tian,Jing Shi,Bochen Li,Zhiyao Duan,and Chenliang XuUniversity of Rochester,United StatesIn this material,firstly,we show how we gather the Audio-Visual Event(AVE) dataset in Sec.1.Then we describe the implementation details of our algorithms in Sec.2.Finally,we provide additional experiments in Sec.3.1A VE:The Audio-Visual Event DatasetOur Audio-Visual Event(AVE)dataset contains4143videos covering28event categories.The video data is a subset of AudioSet[1]with the given event categories,based on which the temporal boundaries of the audio-visual events are manually annotated.1.1Gathering and Preparing DatasetWith the proliferation of video content,YouTube becomes a good resource for finding unconstrained videos.The AudioSet[1]released by Google is a large-scale audio-visual dataset that contains2M10-second video clips from Youtube.Each video clip corresponds to one of the total632event labels that is manually-annotated to describe the audio event.In general,the events cover a variety of category types such as human and animal sounds,musical instruments and genres,and common everyday environmental sounds.Although the videos in AudioSet contain both audio and visual tracks,a lot of them are not suitable for the audio-visual event localization task.For example,visual and audio content can be completely unrelated(e.g.,train horn but no train appears,wind sound but no corresponding visual signals,the absence of audible sound,etc).To prepare our dataset,we select34categories including around10,000 videos from the AudioSet.Then we hire trained in-house annotators to select a subset of them as the desired videos,and further mark the start and end time at a resolution of1second as the temporal boundaries of each audio-visual event.We set a criterion that all annotators followed in the annotation process:a desired video should contain the given event category for at least a two-seconds-long segment from the whole video,in which the sound source is visible and the sound is audible.This results in total4143desired videos covering a wide range of audio-visual events(e.g.,woman speaking,dog barking,playing guitar,and frying food,etc.)from different domains e.g.,human activities,animal activities, music performances,and vehicle sounds.2Y.Tian,J.Shi,B.Li,Z.Duan,and C.Xu2Implementation DetailsVideos in AVE dataset are divided into training(3339),validation(402),and testing(402)sets.For supervised and weakly-supervised audio-visual event lo-calization tasks,we randomly sample videos from each event category to build the train/val/test datasets.For cross-modality localization,we generated syn-chronized and not synchronized training pairs based on annotations of the AVE dataset.Given a segment pair,if there is an audio-visual event,then it will be a synchronized pair;otherwise,it is not a synchronized pair.Around87%train-ing pairs are synchronized.For evaluation,we only sampled testing videos from short-event videos and around50%pairs in these videos are not synchronized. We implement our models using Pytorch[2]and Keras[3]with Tensorflow[4] as works are optimized by Adam[5].The LSTM hidden state size and contrastive loss margin are set to128and2.0,respectively.3Additional ExperimentsHere,we compare different supervised audio-visual event localization models with different features in Sec.3.1.The audio-visual event localization results with different attention mechanisms are shown in Sec.3.2.Action recognition results on a vision-oriented dataset are presented in Sec.3.3.3.1Spatio-Temporal Feature for Audio-Visual Event Localization Although2D CNNs pre-trained on ImageNet are effective in extracting high-level visual representations for static images,they fail to capture dynamic features modeling motion information in videos.To analyze whether temporal informa-tion is useful for the audio-visual event localization task,we utilize deep3D convolutional neural network(C3D)[7]to extract spatio-temporal visual fea-tures.In our experiments,we extract C3D feature maps from pool5layer of C3D network pre-trained on Sport1M[8],and obtain feature vectors by global average pooling operation.Tables1and2show supervised audio-visual event localization results of different features on AVE dataset.Table2shows the the overall accuracy on the AVE dataset.we see that A outperforms V s,both of them are better than V c3d by large margins,and AV s+c3d is only slightly better than AV s.It demonstrates that audio and spatial visual features are more useful to address the audio-visual event localization task than C3D features on the AVE dataset.From Table1,we canfind that V c3d related models can obtain good results,only when videos have rich action and motion information(e.g.plane,motocycle,and train etc).3.2Different Attention MechanismsIn our paper,we propose an audio-guided visual attention mechanism to adap-tively learn which visual regions in each segment of a video to look for the cor-responding sounding object or activity.Here,we further explore visual-guidedSupplementary File3 Table1.Supervised audio-visual event localization prediction accuracy(%)of each event category on AVE test dataset.A,V s,V c3d,V s+c3d,AV s,AV c3d,and AV s+c3d refer to supervised audio,spatial,C3D,spatial+C3D,audio+spatial,audio+C3D, audio+spatial+C3D features-based models,respectively.Notice that the V s model denotes the V model in our main paper.With additional C3D features,the AV s+c3d model does not show noticeable improvements than the AV s model over all event categories.So,we only utilize spatial visual features in our main paper.The top-2 results are highlighted in boldModels bell man dog plane car woman copt.violinflute ukul.frying truck shofar moto. A83.954.149.451.140.036.544.166.181.878.177.820.061.034.4 V s76.740.644.168.360.624.750.644.444.717.570.669.240.066.7 V c3d61.733.538.277.257.236.455.340.023.514.453.342.348.070.0 V s+c3d76.741.238.877.260.051.257.158.340.042.575.680.060.072.2 AV s84.457.655.377.256.772.453.580.687.680.080.075.460.068.9 AV c3d83.362.953.572.849.481.861.272.288.273.880.040.062.074.4 AV s+c3d85.050.657.176.166.771.267.171.290.675.685.678.562.073.3 Models guitar train clock banjo goat baby bus chain.cat horse toilet rodent acco.mand.A70.665.381.384.453.061.38.368.130.08.370.649.060.764.7 V s57.873.579.445.662.051.360.073.123.335.060.642.066.041.3 V c3d57.877.178.140.657.017.543.343.111.713.372.89.034.022.7 V s+c3d48.968.866.361.772.020.056.773.821.720.071.148.064.039.3 AV s63.988.881.376.175.057.541.783.161.733.383.957.074.763.3 AV c3d69.482.488.879.444.068.840.076.938.320.076.153.064.772.7 AV s+c3d70.085.388.167.860.067.5 5.082.533.318.388.370.081.366.7 Table2.Overall accuracy(%)of supervised audio-visual event localization with dif-ferent features on AVE test datasetModels A V s V c3d V s+c3d AV s AV c3d AV s+c3dAccuracy59.555.346.457.971.468.771.6Table3.Audio-visual event localization overall accuracy(%)on AVE dataset.A , A -att,V,V-att,A +V,A +V-co-att denote that these models use audio,attended audio,visual,attended visual,audio-visual,and attended audio and attended visual features,respectively.Note that V represents that the model only use spatial visual features extracted from VGGNet,and the models without attention use global average to produce feature vectors;A models use audio features extracted from the last pooling layer of pre-trained VGG-like model in[6](for details,please see Sec.3.2)Models A A -att V V-att A +V A +V-co-attAccuracy54.354.155.358.570.269.94Y.Tian,J.Shi,B.Li,Z.Duan,and C.XuFig.1.Visual results of visual-guided audio attention and audio-guided visual attention mechanisms.Each row represents one example.From left to right,images are log-mel spectrum patch,visual-guided audio attention map,a reference video frame,and audio-guided visual attention map,respectively.audio attention mechanism and audio-visual co-attention mechanism,where the latter integrates audio-guided visual attention and visual-guided audio attention. These attention mechanisms serve as a weighted global pooling method to gener-ate audio or visual feature vectors.The visual-guided audio attention function is similar to that in the audio-guided visual attention model,and the co-attention model uses both attended audio and attended visual feature vectors.To implement visual-guided audio attention mechanism,we extract audio features from the last pooling layer of pre-trained VGG-like model in[6].Note that the network uses a log-mel spectrogram patch with96×64bins to represent a1s waveform signal,so its pool5layer will produce feature maps with spatial resolution;this is different than audio features of A models in our main paper and in Tabs.1and2of this supplementaryfile.The reason is that the audio features in A models are128-D vectors extracted from the last fully-connected layer.We denote a model using audio features in this section as A to differentiate it from the model A used in our main paper and in Tabs.1and2.Table3illustrates supervised audio-visual event localization results of differ-ent attention models.We can see that the the A model in Tab.3is worse than the A model in Tab.2,which demonstrates that the audio features extracted from the last FC layer of[6]is more powerful.Similar to results in our main paper, V-att outperforms V.However,A -att is not better than A ,and A +V-co-attSupplementary File5 is slightly worse than A +V,which validate that visual-guided audio attention and audio-visual co-attention can not effectively improve audio-visual event lo-calization performance.Figure3illustrates visual results of audio attention and visual attention mechanisms.Clearly,we canfind that audio-guided visual at-tention can locate semantic regions with sounding objects.We also observe that the visual-guided audio attention tends to capture certain frequency patterns, but it is pretty hard to interpret the results of visual-guided audio attention, which we leave to explore in the future work.3.3Action RecognitionTable 4.Action recognition accuracy(%)on a Moments subset.We show Top-1 accuracy of different models on the test set with874videos over30categories.A and V models only use audio and visual content respectively.Ensemble denotes average ensemble over A and V as in[9].A+V utilizes the proposed fusion method in the paper to integrate audio and visual information.Models Chance A V Ensemble A+VAccuracy 3.333.551.354.959.5Action and Event Recognition on the Moments We further evaluated the proposed audio-visual modeling framework on a vision-oriented dataset:Mo-ments[9].Moments dataset includes a collection of one million short videos with a label each,corresponding to actions and events unfolding within3sec-onds.Due to time limitation,we sampled around6000videos from the Moments by automatically ignoring salient videos(around30%)from30categories.Note that the30categories arefirst30classes of100categories after deleting some categories which contain fewer sounding videos(<80/200).Moreover,training and testing videos are not manually selected,therefore audio content and visual content may be not related in these videos.We modified the audio-visual event localization framework by averaging pooling features from LSTMs to address the audio-visual action classification problem.The action recognition results on the Moments subset are shown in Table4.Surprisingly,we see that visual in-formation is much more useful for this vision-oriented dataset,and integrating audio and visual signals using the proposed framework can significantly improve the recognition performance.References1.Gemmeke,J.F.,Ellis,D.P.,Freedman,D.,Jansen,A.,Lawrence,W.,Moore,R.C.,Plakal,M.,Ritter,M.:Audio set:An ontology and human-labeled dataset for audio events.In:ICASSP.(2017)2.3.Chollet,F.,et al.:Keras.https:///fchollet/keras(2015)4.Abadi,M.,Agarwal,A.,Barham,P.,Brevdo,E.,Chen,Z.,Citro,C.,Corrado,G.S.,Davis,A.,Dean,J.,Devin,M.,Ghemawat,S.,Goodfellow,I.,Harp,A.,Irving,G.,6Y.Tian,J.Shi,B.Li,Z.Duan,and C.XuIsard,M.,Jia,Y.,Jozefowicz,R.,Kaiser,L.,Kudlur,M.,Levenberg,J.,Man´e,D.,Monga,R.,Moore,S.,Murray,D.,Olah,C.,Schuster,M.,Shlens,J.,Steiner,B.,Sutskever,I.,Talwar,K.,Tucker,P.,Vanhoucke,V.,Vasudevan,V.,Vi´e gas,F.,Vinyals,O.,Warden,P.,Wattenberg,M.,Wicke,M.,Yu,Y.,Zheng,X.:TensorFlow: Large-scale machine learning on heterogeneous systems(2015)Software available from tensorfl.5.Kingma,D.,Ba,J.:Adam:A method for stochastic optimization.In:Proc.ICLR.(2015)6.Hershey,S.,Chaudhuri,S.,Ellis,D.P.,Gemmeke,J.F.,Jansen,A.,Moore,R.C.,Plakal,M.,Platt,D.,Saurous,R.A.,Seybold,B.,et al.:Cnn architectures for large-scale audio classification.In:ICASSP.(2017)131–1357.Tran,D.,Bourdev,L.,Fergus,R.,Torresani,L.,Paluri,M.:Learning spatiotemporalfeatures with3d convolutional networks.In:Proceedings of the IEEE international conference on computer vision.(2015)4489–44978.Karpathy,A.,Toderici,G.,Shetty,S.,Leung,T.,Sukthankar,R.,Fei-Fei,L.:Large-scale video classification with convolutional neural networks.In:Proceedings of the IEEE conference on Computer Vision and Pattern Recognition.(2014)1725–1732 9.Monfort,M.,Zhou,B.,Bargal,S.A.,Yan,T.,Andonian,A.,Ramakrishnan,K.,Brown,L.,Fan,Q.,Gutfruend,D.,Vondrick,C.,et al.:Moments in time dataset: one million videos for event understanding。
视频的英文是什么
视频的英文是什么她看视频的时候总是很安静,陷入了无的状态。
下面店铺为大家带来视频的英语意思和相关用法,欢迎大家一起学习!视频的英语意思video视频的相关英语例句1. Other causes of migraine are VDU screens and strip-lighting.偏头痛的其他诱因还有电脑的视频显示器和灯管照明。
2. Visitors are shown an audio-visual presen-tation before touring the cellars.参观酒窖前,游客们先观看了有声的视频介绍。
3. You can also tour the site on modern coaches equipped with videos.您也可以乘坐配有视频设备的现代化长途汽车游览那处遗址。
4. James Watson, Philip Mayo and I gave a slide and video presentation.詹姆斯·沃森、菲利普·梅奥和我利用幻灯片和视频进行了介绍。
5. Transferring cine film or slides to video should be a doddle.把电影胶片或幻灯片转换成视频应该不费吹灰之力。
6. Video movie-making can quickly become addictive.制作视频电影能很快让人入迷。
7. I'm having difficulty using my video editing equipment and can't fathom out the various connections.我不会使用视频编辑设备,而且搞不清各种各样的连接。
8. There's a big difference between an amateur video and a slick Hollywood production.业余人士拍摄的视频片段和制作精良的好莱坞影片之间存在着巨大的差距。
新世纪英语本科《综合教程》教案Unit1,Book1(SecondEdition)
新世纪英语本科《综合教程》教案Unit1,Book1(SecondEdition)教师备课、学生自学的参考资料教师备课、学生自学的参考资料Reading aloudCultural informationAudiovisual supplementReading aloud Listen and read the following sentences, paying attention to the pauses between sense groups.1. When I was ten / I was suddenly confronted with the anguish of moving from the only home / I had ever known.2. DIt isn’t easy, / is it, Billy?‖ / he said softly, / sitting down on the steps beside me.3. I was standing by his rosebush / when an uncle came to tell me / that my grandfather had died.教师备课、学生自学的参考资料Reading aloudCultural informationAudiovisual supplement4. It’s that special place in your heart / that makes them so.5. D ... We seem to have so many ways of saying goodbye / and they all have one thing in common: / sadness.‖教师备课、学生自学的参考资料Reading aloudCultural informationAudiovisual supplementCultural information Quote Bertrand Russell: Young men who have reason to fear that they will be killed in battle may justifiably feel bitter in the thought that they have been cheated of the best things that life has to offer. But in an old man who has known human joys and sorrows, and has achieved whatever work it was in him to do, the fear of death is somewhat abject and ignoble. The best way to overcome it ― so at least it seems to me ― is to make your interests gradually wider and more impersonal.教师备课、学生自学的参考资料Reading aloudCultural informationAudiovisual supplementHenry David Thoreau: The failures and reverses which await men ― and one after another sadden the brow of youth ― adda dignity to the prospect of human life, which no Arcadian success would do.教师备课、学生自学的参考资料Reading aloudCultural informationAudiovisual supplementAudiovisual supplement Watch a video clip and answer the following questions.1. What are the people doing in the video? The mother and her three children were moving to a new place.2. How did the boys feel?Simon felt excited about moving to a large house because he wanted to keep some bigger pets. But Jared was not happy about the moving. / He was angry about it.教师备课、学生自学的参考资料Reading aloudCultural informationAudiovisual supplement3. Have your family ever moved from one place to another?Students are encouraged to answer this question freely.教师备课、学生自学的参考资料Reading aloudCultural informationAudiovisual supplement教师备课、学生自学的参考资料Reading aloudCultural informationAudiovisual supplementMom:There it is. Pretty much 。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
DOI10.1007/s11042-012-1097-xAn audio-visual approach to web video categorizationBogdan Emanuel Ionescu·Klaus Seyerlehner·Ionu¸t Mironic˘a·Constantin Vertan·Patrick Lambert©Springer Science+Business Media,LLC2012Abstract In this paper,we discuss and audio-visual approach to automatic web video categorization.To this end,we propose content descriptors which exploit audio, temporal,and color content.The power of our descriptors was validated both in the context of a classification system and as part of an information retrieval approach. For this purpose,we used a real-world scenario,comprising26video categories from the media platform(up to421h of video footage).Additionally,to bridge the descriptor semantic gap,we propose a new relevance feedback technique which is based on hierarchical clustering.Experiments demonstrated that with this technique retrieval performance can be increased significantly and becomes comparable to that of high level semantic textual descriptors.Keywords Audio block-based descriptors·Color perception·Action assessment·Video relevance feedback·Video genre classificationB.E.Ionescu(B)·I.Mironic˘a·C.VertanLAPI,University Politehnica of Bucharest,061071,Bucharest,Romaniae-mail:bionescu@alpha.imag.pub.roI.Mironic˘ae-mail:imironica@alpha.imag.pub.roC.Vertane-mail:constantin.vertan@upb.roB.E.Ionescu·mbertLISTIC,Polytech Annecy-Chambery,University of Savoie,74944,Savoie,Francemberte-mail:mbert@univ-savoie.frK.SeyerlehnerDCP,Johannes Kepler University,4040Linz,Austriae-mail:klaus.seyerlehner@jku.at1IntroductionAutomatic labeling of video footage according to genre is a common requirement in indexing large and heterogeneous collections of video material.This task can be tackled,either globally or locally.Global classification approaches aim to categorize videos into one of several main genres,such as cartoons,music,news,sports, documentaries,or with finer granularity into sub-genres,for instance,according to specific types of sports(e.g.,football,hockey)or movie(e.g.,drama,thriller).Local classification approaches,in contrast,label video segments instead of whole videos according to specific human-centered concepts,for instance,outdoor vs.indoor scenes,action segments,scenes showing violence(see TRECVid campaign[36]).In this paper,we address the global classification task and consider the problem within a machine learning paradigm.In the literature,many sources of information have been exploited for this task[2].A common approach is to use text-based information.Most existing web media search engines(e.g.,YouTube,)rely on text-based retrieval,as it provides a higher semantic level of description than other information sources.Text is obtained either from scene text(e.g.,graphic text,sub-titles),from the transcripts of dialogues obtained with speech recognition techniques, or from other external sources,for instance,synopses,user tags,mon genre classification approaches include classic Bag-of-Words model[6]and Term Frequency-Inverse Document Frequency(TF-IDF)approaches[16].Using audio-visual information is less accurate than using text.Audio-based infor-mation can be derived either from the time or from the frequency domain.Typical time-domain approaches include the use of Root Mean Square(RMS)of signal energy[27],sub-band information[17],Zero-Crossing Rate(ZCR)[20]or silence ratio.Frequency-domain features include energy distribution,frequency centroid [20],bandwidth,pitch[4]and Mel-Frequency Cepstral Coefficients(MFCC)[38].The most popular type of audio-visual content descriptors are,however visual descriptors.They exploit both static and dynamic aspects of visual information either in the spatial domain,for instance,using color,temporal structure,objects,feature points,motion,or in the compressed domain,for example,using MPEG coefficients [2].Color descriptors are generally derived at the image level and quantified via color histograms or other low-level parameters such as predominant color,color entropy, and variance(various color spaces are employed,e.g.RGB—Red Green Blue, HSV—Hue Saturation Value,and YCbCr—Luminance,Chrominance)[7,10].Tem-poral structure-based descriptors exploit temporal segmentation of video sequences.A video sequence is composed of several video shots connected by video transitions, which can be sharp(cuts)or gradual(fades,dissolves)[19].Existing approaches basically exploit the frequency of their occurrence in the movie.Although some approaches use this information directly[44](e.g.,rhythm,average shot length), others derive features related to visual activity and exploit the concept of action (e.g.,a high frequency of shot changes is often correlated with action)[48].Object-based features in genre classification are generally limited to characterizing the occurrence of face and text regions in frames[44,48].Other related approaches exploit the presence of feature points,for example,using the well known SIFT descriptors[43].Motion-based descriptors are derived either by motion detection techniques(foreground detection)or by motion estimation(i.e.,prediction of pixel displacement vectors between frames).Typical features describe motion density, camera movement(global movement),or object trajectory[8].Finally,less commonare features computed in the compressed video domain,for example,using DCT (Discrete Cosine Transform)coefficients and embedded motion vectors from the MPEG flow[42].Their main advantage is their availability with the initial video file.All sources of information provide advantages and disadvantages.However, depending on the classification scenario,some prove to be more convenient than others.Text-based information,due to its high informational redundancy and re-duced availability with visual information,can be less relevant when addressing a reduced number of genres(e.g.,TV media genres).Also,it can produce high error rates if retrieved with speech transcription techniques[2];however,it is the “golden standard”in web genre categorization;object-based information,although computationally expensive to process,tends to be semi-automatic(requires human confirmation);motion information tends to be available in high quantities during the entire sequence(object/camera),but is insufficient by itself to distinguish between specific genres,for instance,movies,sports,music[2].Audio-based information provides good discriminative power for most common TV genres and requires fewer computational resources to be obtained and processed.Color information is not only simple to extract and inexpensive to process,but also very powerful in distinguishing cinematic principles and techniques;temporal-based information is a popular choice and proves to be powerful as long as efficient video transition detection algorithms are employed(e.g.,adapting to web-specific low-quality video contents[13]).The remainder of this paper is organized as follows:Section2discusses,and situates our work in relation to,several relevant genre classification approaches. Section3presents the proposed video descriptors(audio,temporal,and color-based).Section4discusses the improvement in retrieval performance achieved with relevance feedback,and proposes an approach inspired by hierarchical clustering. Experimental results are presented in Section5,while Section6presents the conclu-sions and discusses future work.2Related workAlthough,some sources of information provide better results than others in video genre categorization[2],the most reliable approaches—which also target a wider range of genres—are multi-modal,that is multi-source.In this section,we discuss the performance of several approaches we consider relevant for the present work—from single-modal(which are limited to coping with a reduced number of genres)to multi-modal(which target more complex categorizations).We focus exclusively on approaches relying on audio-visual information—the subject of this study.A simple,single-modal approach is that proposed in[29].It addresses genre classification using only video dynamics,namely background camera motion and object motion.A single feature vector in the DCT-transformed space ensures low-pass filtering,orthogonality,and reduced feature dimension.A classifier based on a Gaussian Mixture Model(GMM)is then used to identify three common genres: sports,cartoons,and news.Despite the limited content information used,applying this approach to a reduced number of genres achieves detection errors below 6%.The authors of[48]used spatio-temporal information such as average shot length,cut percentage,average color difference,camera motion(temporal)and face frames ratio,average brightness,and color entropy(spatial).Genre classification isaddressed at different levels according to a hierarchical ontology of video genres. Several classification schemes(Decision Trees and several SVM approaches)are used to classify video footage into the main genres movie,commercial,news,music, and sports,and further into sub-genres:movies into action,comedy,horror,and cartoons,and sports into baseball,football,volleyball,tennis,basketball,and soccer. The highest precision in video genre categorization is around88.6%and in sub-genre categorization97%for sports and up to81.3%for movies.However,truly multi-modal approaches also include audio information.For instance,the approach in[47]combines synchronized audio(14Mel-Frequency Cepstral Coefficients—MFCC)and visual features(mean and standard deviation of motion vectors,MPEG-7visual descriptors).Dimensionality of the feature vectors is reduced by means of Principal Component Analysis(PCA),and videos are clas-sified with a GMM-based classifier.Tested with five common video genres,namely sports,cartoons,news,commercials,and music,this approach yields an average correct classification up to86.5%.Another example is the approach proposed in [23].Features are extracted from four sources:visual-perceptual information(color, texture,and motion),structural information(shot length,shot distribution,shot rhythm,shot clusters duration,and saturation),cognitive information(e.g.,number, positions,and dimensions of faces)and aural information(transcribed text,sound characteristics).These features are used to train a parallel Neural Network,which achieves an accuracy of up to95%in distinguishing between seven video genres and sub-genres,namely football,cartoons,music,weather forecast,newscast,talk shows,and commercials.A generic approach to video categorization was discussed in[1].Each video document is modeled by a Temporal Relation Matrix(TRM) which describes the relationship between video segments,that is,temporal intervals related to the occurrence of a specific type of event.Events are defined based on the specificity of video features,such as speech,music,applause,speaker(audio) and color,texture,activity rate,face detection,costume(visual).TRMs provide a similarity measure between documents.Experimental tests with several classification approaches(mostly tree-based)and the six video genres news,soccer,TV series, documentary,TV games,and movies resulted in individual genre F score ratios ranging from40%to100%(e.g.,for a Random Forest with cross-validation).In this paper,we propose three categories of content descriptors which exploit both audio and visual modalities.Although these sources of information have already been exploited,one of the novelties of our approach is the way we compute the descriptors.The proposed audio features are block-level-based and have the advantage of capturing local temporal information by analyzing sequences of con-secutive frames in a time-frequency representation.Visual information is described with temporal information and color properties.Temporal descriptors are derived using a classic confirmed approach,that is,analysis of shot change frequency[23,48]. Further,we introduce a novel way of assessing action content by considering human perception.We seek to capture aspects of color perception with our color descriptors. Instead of the typical low-level color descriptors(e.g.,predominant color,color variance,color entropy and frame-based histograms[48]),we project histogram features onto a standard human color naming system and determine descriptors such as the percentage of light colors,cold colors,saturated colors,color contrasts,and elementary hue distribution.This achieves a higher semantic level of description.A preliminary validation of the proposed descriptors classifying seven common TV genres(i.e.,animated movies,commercials,documentaries,movies,music videos,news broadcast,and sports)yielded average precision and recall ratios of87–100% and77–100%,respectively[12].We extended and adapted this approach to the categorization of web video genres.Several experimental tests conducted on a real-world scenario—using up to26genres provided by the media platform and approximately421h of video footage—demonstrated the power of our audio-visual descriptors in this classification task.Tests were conducted both in the context of a classification system and as part of an information retrieval approach.To bridge the semantic gap,we also investigated the potential use of user expertise and propose a new relevance feedback technique which is based on hierarchical clustering.This allows us to boost retrieval performance of the audio-visual descriptors close to that obtained with high-level semantic textual information.3Content descriptionAs previously mentioned,we use both,audio and visual information to classify video genres.From the existing modalities we exploit the audio soundtrack,temporal structure,and color content.Our selection is motivated by the specificity of these information sources with respect to video genre.For instance,most common video genres have very specific audio signatures:music clips contain music,there is a higher prevalence of mono-logues/dialogues in news broadcasts,documentaries have a mixture of natural sounds,speech,and ambient music,in sports there is crowd noise,and so on. Considered visually,temporal structure and colors highlight specific genre contents; for instance,commercials and music clips tend to have a high visual tempo,music clips and movies tend to have darker colors(mainly due to the use of special effects),commercials use many gradual transitions,documentaries have reduced action content,animated movies have specific color palettes and color contrasts, sports usually have a predominant hue(e.g.,green for soccer,white for ice hockey), in news broadcasting an anchor is present(high frequency of faces).The proposed content descriptors are to be determined globally,thus covering the complete sequence.Each modality results in a feature vector.This approach has the advantage of facilitating data fusion by simple concatenation of the resulting data. Below we describe each category of descriptors and emphasize their advantages. 3.1Audio descriptorsTo address the range of video genres,we propose audio descriptors which are related to rhythm,timbre,onset strength,noisiness and vocal aspects[35].The proposed set of audio descriptors,called block-level audio features,have the key advantage of capturing temporal information from the audio track at a local level.Standard spectral audio features,such as Mel Frequency Spectral Coefficient,Spectral Cen-troid,and Spectral Roll Off,are commonly extracted from each spectral frame of the time-frequency representation of an audio signal(capturing a time span of20ms). The features we propose are computed from sequences of consecutive spectral frames called blocks.Depending on the feature,a block consists of10to up to512 consecutive spectral frames.Thus,local features can themselves capture temporalproperties(e.g.,rhythmic aspects)of an audio track over a time span ranging from half a second up to12s of audio.Blocks are analyzed at a constant rate and their frames overlap by default by 50%.We determine one local feature vector per block.These local vectors are then summarized by computing simple statistics separately for each dimension of the local feature vectors(e.g.,depending on the feature,we use mean,variance,or median).A schematic diagram of this procedure is depicted in Fig.1.First,the audio track is converted into a22kHz mono signal.To obtain a perceptual time-frequency representation of the video soundtrack,we then compute the short-time Fourier transform and map the frequency axis according to the loga-rithmic cent-scale.Because human frequency perception is logarithmic.The resulting time-frequency representation consists of97logarithmically spaced frequency bands. Further,we derive the following complex block-level audio features:–spectral pattern(1block=10frames,0.9percentile statistics):characterize the timbre of the soundtrack by modeling those frequency components that are simultaneously active.The dynamic aspect of the signal is retained by sorting each frequency band of a block along the time axis.The block width varies depending on the extracted patterns,which allows capturing temporal information over different time spans.–delta spectral pattern(1block=14frames,0.9percentile statistics):captures the strength of onsets.To emphasize onsets,we first compute the difference between the original spectrum and a copy of the original spectrum delayed by3frames.As with the spectral pattern,each frequency band is then sorted along the time axis.–variance delta spectral pattern(1block=14frames,variance statistics):is basically an extension of the delta spectral pattern and captures the variation of the onset strength over time.Fig.1Processing a time(OX axis)—frequency(OY axis)representation in terms of spectral blocks (N is the number of blocks)–logarithmic fluctuation pattern(1block=512frames,0.6percentile statistics): captures the rhythmic aspects of the audio signal.In order to extract the am-plitude modulations from the temporal envelope in each band,periodicities are detected by computing the Fast Fourier Transform(FFT)along each frequency band of a block.The periodicity dimension is then reduced from256to37 logarithmically spaced periodicity bins.–spectral contrast pattern(1block=40frames,0.1percentile statistics):roughly estimates the“tone-ness”of an audio track.For each frame,within a block, the difference between spectral peaks and valleys in20sub-bands is computed, and the resulting spectral contrast values are sorted along the time axis in each frequency band.–correlation pattern(1block=256frames,0.5percentile statistics).To capture the temporal relation of loudness changes over different frequency bands,we use the correlation coefficients between all possible pairs of frequency bands within a block.The resulting correlation matrix forms the correlation pattern.The correlation coefficients are computed for a reduced frequency resolution of 52bands.These audio features in combination with a Support Vector Machine(SVM) classifier constitute a highly efficient automatic music classification system.At the 2010Music Information Retrieval Evaluation eXchange,this approach ranked first in automatic music genre classification[35].However,the proposed approach has not yet been applied to video genre classification.3.2Temporal structure descriptorsTemporal descriptors are derived using a classic confirmed approach,that is,analysis of the shot change frequency[48].Unlike existing approaches,we refine the assess-ment of the action level on the basis of human perception.One of the main factors contributing to the success of temporal descriptors is an accurate preceding temporal segmentation[19].First,we detect both cuts and gradual transitions.Cuts are detected by means of an adaptation of the histogram-based approach proposed in[13];fades and dissolves are detected using a pixel-level statistical approach[5]and the analysis of fading-in and fading-out pixels[39], respectively.Further,we compute the following descriptors:–rhythm:capture the movie’s tempo of visual change,we compute the relative number of shot changes occurring within a time interval of T=5s,denotedζT.Then,the rhythm is defined as the movie average shot change ratio,¯v T=E{ζT}.–action:We aim to define two opposite situations:video segments with high action content(called“hot action”,e.g.,fast changes,fast motion,visual effects)with ζT>3.1,and video segments with low action content(i.e.,containing mainly static scenes)withζT<0.6.These thresholds were determined experimentally using user ground truth.A group of ten people was asked to manually browse the content of several TV movies and identify,if possible,frame segments(i.e., intervals[frame A;frame B])which fall into the two action categories mentioned.To avoid inter-annotator consistency,each person annotated different video parts.For each manually labeled action segment,we computed the mean shot change ratio,¯v T,to capture the corresponding changing rhythm.Then wecomputed the average and standard deviation of¯v T over all segments withineach action ing this information as ground truth,we determineζTintervals for each type of action content as[E{¯v T}−σ¯v T;E{¯v T}+σ¯v T]and thus the two threshold limits(lower limit for high action and upper limit for lowaction).Further,we quantify the action content using two parameters—hot-action ratio(H A)and low-action ratio(LA),determined by:H A=T H AT total,LA=T LAT total(1)where T H A and T LA represent the total length of hot and low action segments, respectively,and T total is the movie total length.–gradual transitions ratio:Since high numbers of gradual transitions are generally related to a specific video content we compute:GT=T dissolves+T fade−in+T fade−outT total(2)where T X represents the total duration of all gradual transitions of type X.This provides information about editing techniques which are specific to a genre,such as movies or commercial clips.3.3Color descriptorsColor information is an important source for describing visual content.Most of the existing color-based genre classification approaches are limited to using intensity-based parameters or generic low-level color features such as average color differences,average brightness,average color entropy[48],variance of pixel inten-sity,standard deviation of gray level histograms,percentage of pixels with saturation above a certain threshold[41],lighting key[28],object color,and texture.We propose a more sophisticated strategy which addresses the perception of color content[11].A simple and efficient way to accomplish this is using color names; associating names with colors allows everyone to create a mental image of a given color or color mixture.We project colors onto a color naming system,and color properties are described using statistics of color distribution,elementary hue distrib-ution,color visual properties(e.g.,percentage of light colors,warm colors,saturated colors),and relationships between colors(adjacency and complementarity).Prior to parameter extraction,we use an error diffusion scheme to project colors onto a more manageable color palette—the non-dithering216color Webmaster palette(an efficient color naming system).Colors are represented by the following descriptors:–global weighted color histogram is computed as the weighted sum of each shot color histogram:h GW(c)=Mi=0⎡⎣1N iN ij=0h jshot i(c)⎤⎦·T shot iT total(3)where M is the total number of video shots,N i is the total number of the retainedframes for shot i(we use temporal sub-sampling),h jshot i is the color histogramof frame j from shot i,c is a color index from the Webmaster palette(we usecolor reduction),and T shoti is the length of shot i.The longer the shot,the moreimportant its contribution to the global histogram of the movie.–elementary color histogram:describes the distribution of elementary hues in the sequence:h E(c e)=215c=0h GW(c)|Name(c e)⊂Name(c)(4)where c e is an elementary color from the Webmaster color dictionary(colors are named according to color hue,saturation,and intensity),and Name()returns a color’s name from the palette dictionary.–color properties:We define several color ratios to describe color properties.For instance,the light color ratio,P light,reflects the percentage of bright colors in the movie:P light=215c=0h GW(c)|W light⊂Name(c)(5)where c is a color whose name contains one of the words defining brightness, and W light∈{“light”,“pale”,“white”}.Using the same reasoning and keywords specific to each property,we define dark color ratio(P dark),hard saturated color ratio(P hard),weak saturated color ratio(P weak),warm color ratio(P warm)and cold color ratio(P cold).Additionally,we capture movie color richness with two parameters:color vari-ation,P var,which is the number of significantly different colors,and color diversity,P div,defined as the number of significantly different color hues[11].–color relationship:we compute P adj,the number of perceptually similar colors in the movie and P compl,the number of perceptually opposite color pairs.This level of description provides several advantages:the globally weighted color histogram,h GW,extends the definition of static image histograms by taking into account the video temporal structure.Values describe percentages of colors appearing during the entire sequence,which provides a global color signature of the sequence.Further,with the elementary color histogram,h E,we provide a projection of color to pure spectrum colors(hues),thus disregarding the saturation and intensity information.This mechanism ensures invariance to color fluctuations (e.g.,illumination changes)and provides information about predominant hues.Color property and color relationship ratios provide a more perceptual analysis of the color distribution by quantifying dark-light,warm-cold,saturated and percep-tually similar(adjacent)—opposite(complementary)colors.Finally,color variability and diversity provide information on how much variability is in the color palette of a movie and its basic hues.For instance,the presence of many diverse colors may signify more vivid sequences.4Relevance feedbackFollowing this content description methodology,we investigated the potential use of Relevance Feedback(RF)techniques in bridging the inherent semantic gap that results from the automatic nature of the annotation process.Globally,a typicalRF scenario can be formulated thus:for a certain retrieval query,a user provides feedback by marking the results as relevant or non-relevant.Then,the system computes a better representation of the information needed based on this ground truth,and retrieval is further refined.This process can go through one or more such iterations[22].In the literature,many approaches have been investigated.One of the earliest and most successful relevance feedback algorithms is the Rocchio algorithm[24]. It updates the query features by adjusting the position of the original query in the feature space according to the positive and negative examples and their associated importance factors.Another example is the Feature Relevance Estimation(FRE) approach[32],which assumes for a given query that a user may consider some specific features more important than others.Every feature is given an importance weight such that features with greater variance have lower importance than ele-ments with smaller variations.More recently,machine learning techniques have been introduced to relevance feedback approaches.Some of the most successful techniques use Support Vector Machines[18],classification trees,such as Decision Trees[21],Random Forest[46]or boosting techniques,such as AdaBoost[9].The relevance feedback problem can be formulated either as a two-class classification of the negative and positive samples or as a one-class classification problem(i.e., separating positive samples from negative samples).We propose an RF approach that is based on Hierarchical Clustering(HC)[15].A typical agglomerative HC strategy starts by assigning one cluster to each object in the feature space.Then,similar clusters are progressively merged based on the evaluation of a specified distance metric.By repeating this process,HC produces a dendrogram of the objects,which may be useful for displaying data and discovering data relationships.This clustering mechanism can be very valuable in solving the RF problem by providing a mechanism to refine the relevant and non-relevant clusters in the query results.A hierarchical representation of the similarity between objects in the two relevance classes allows us to select an optimal level from the dendrogram which provides a better separation of the two than the initial retrieval.The proposed hierarchical clustering relevance feedback(HCRF)is based on the general assumption that the video content descriptors provide sufficient representa-tive power that,within the first window of retrieved video sequences,there are at least some videos relevant to the query that can be used as positive feedback.This can be ensured by adjusting the size of the initial feedback window.Also,in most cases,there is at least one non-relevant video that can be used as negative feedback. The algorithm comprises three steps:retrieval,training,and updating.Retrieval We provide an initial retrieval using a nearest-neighbor strategy.We return a ranked list of the N RV videos most similar to the query video using the Euclidean distance between features.This constitutes the initial RF window.Then, the user provides feedback by marking relevant results,which triggers the actual HCRF mechanism.Training The first step of the RF algorithm consists of initializing the clusters.At this point,each cluster contains a single video from the initial RF window.Basically, we attempt to create two dendrograms,one for relevant and one for non-relevant videos.For optimization reasons,we use a single global cluster similarity matrix for。