音频数据的压缩
声音压缩典型方法及原理

声音压缩典型方法及原理1. 声音压缩是一种音频信号处理技术,用于减少音频信号的动态范围并增加整体响度。
2. 动态范围是指音频信号中最大和最小幅度之间的差异。
声音压缩通过减小这种差异来提高音频信号的可听性。
3. 声音压缩的主要原理是对音频信号进行自动增益控制(AGC),根据信号的幅度变化调整增益。
4. 自动增益控制通过设置阈值来确定何时启动增益调整。
当信号的幅度超过阈值时,增益被降低以减小动态范围。
5. 增益的调整是通过压缩比来实现的,压缩比是指输入信号的变化与输出信号变化之间的比例关系。
6. 压缩比越高,输出信号的动态范围就越小,音频信号的差异也就越小。
7. 压缩比通常以分贝(dB)为单位进行表达,比如 4:1 的压缩比表示输出信号每增加 4 分贝,输入信号只增加 1 分贝。
8. 压缩比大于 1:1 的情况下,被压缩的音频信号通常会失去部分动态范围,从而产生所谓的“压缩效果”。
9. 压缩效果可以使音频信号更具聚焦性,使细节更加清晰,但过度压缩可能导致音频信号变得平淡无力或产生副作用,如失真或噪音增加。
10. 声音压缩常用的算法之一是均衡压缩算法,它根据输入信号的频谱特征自适应地调整增益。
11. 均衡压缩算法将输入信号分成多个频带,并在每个频带上应用独立的压缩参数。
12. 这种算法可确保在音频信号的各个频段上获得更平衡的增益调整,从而提供更好的音频质量。
13. 另一种常见的压缩方法是峰值限制器,它主要用于防止音频信号过载。
14. 峰值限制器通过将超过某个设定阈值的信号限制在该阈值以内,从而防止信号超载,并保持输出信号处于可接受的范围内。
15. 除了阈值和压缩比,声音压缩中常用的参数还包括攻击时间、释放时间和输出增益等。
16. 攻击时间指的是从输入信号超过阈值到压缩开始生效的时间,攻击时间越短,压缩器的反应越快。
17. 释放时间指的是当输入信号低于阈值时,压缩器停止工作并返回到原始增益水平所需的时间。
sbc编码原理

sbc编码原理SBC编码原理什么是SBC编码?SBC编码(Subband Coding)是一种用于音频数据压缩的技术。
它将音频信号划分成多个子频带,然后对每个子频带进行独立处理。
子频带划分1.SBC编码将音频信号分成若干段,每段称为一个子频带。
2.划分子频带的目的是为了减少对信号的处理复杂度。
SBC编码的原理SBC编码主要包含以下几个步骤:1. 信号分割将音频信号分为不同的频段,每个频段对应一个子频带。
2. 子频带信号处理对每个子频带进行处理,常见的处理方法包括: - 滤波:用滤波器对子频带信号进行滤波,去除不需要的频率分量。
- 量化:将滤波后的信号进行量化,减少数据的表示位数,从而实现数据的压缩。
- 编码:将量化后的信号用合适的编码算法进行编码,以降低数据的冗余性。
3. 重建信号对每个子频带进行逆操作,将处理后的子频带信号合并起来,得到重建的音频信号。
SBC编码的优势•SBC编码可以减小数据的体积,实现音频数据的高效传输和储存。
•SBC编码可以实现对音频信号的压缩,减少存储和传输所需的带宽。
•SBC编码可以在一定程度上保持音频质量,使得压缩后的音频信号在听觉上接近原始音频信号。
SBC编码的应用•SBC编码被广泛应用于音频传输领域,例如蓝牙音频传输协议(A2DP)。
•SBC编码也常用于音频压缩格式,例如MPEG-1音频层3(MP3)。
以上介绍了SBC编码的原理及其优势和应用。
通过合理的信号处理和压缩方法,SBC编码能够有效地减小音频数据的体积,提高数据传输和存储的效率,同时保持较高的音质。
SBC编码的局限性尽管SBC编码具有很多优势,但也存在一些局限性:1. 信息丢失由于SBC编码需要对音频信号进行压缩,因此会存在信息丢失的问题。
压缩过程中去除了一些不重要或冗余的信息,从而导致压缩后的音频信号与原始信号存在差异。
2. 压缩比限制SBC编码的压缩比是有限的。
在保持一定音质的前提下,压缩比将受限于所使用的压缩算法和编码参数。
数据压缩 算法

数据压缩算法数据压缩是一种将数据进行压缩以减小其占用空间的过程。
通过减少数据的冗余信息,数据压缩可以降低数据存储和传输的成本,并提高数据处理效率。
在计算机科学和信息技术领域,数据压缩算法被广泛应用于图像、音频、视频、文本等不同类型的数据。
数据压缩算法主要分为两大类:无损压缩算法和有损压缩算法。
1.无损压缩算法:无损压缩算法是指在压缩的过程中不丢失任何原始数据的信息。
这类算法常用于需要完全还原原始数据的应用场景,如文本文件的压缩和存储。
下面介绍几种常见的无损压缩算法:-霍夫曼编码(Huffman Coding):霍夫曼编码是一种基于概率的字典编码方法,通过将出现频率较高的字符赋予较短的编码,而将出现频率较低的字符赋予较长的编码,从而减小编码的长度,实现数据的压缩。
-雷霍夫曼编码(LZW):雷霍夫曼编码是一种字典编码方法,通过构建字典来逐步压缩数据。
该算法将频繁出现的字符或字符组合映射到较短的码字,从而实现数据的压缩。
-阻塞排序上下文无关算法(BWT):BWT算法通过对数据进行排序和转置,形成新的序列,然后采用算法对该序列进行压缩。
该算法主要用于无损压缩领域中的文本压缩。
-无压缩流传输(Run Length Encoding):RLE算法通过将连续出现的相同数据替换为该数据的计数和值的形式,从而实现数据的压缩。
这种算法主要适用于连续出现频繁的数据,如图像和音频。
2.有损压缩算法:有损压缩算法是指在压缩的过程中丢失一部分原始数据的信息,从而实现较高的压缩比率。
这类算法常用于对数据质量要求较低的应用场景,如音频和视频的压缩和存储。
下面介绍几种常见的有损压缩算法:-基于离散余弦变换的压缩算法(DCT):DCT算法将输入的数据分解为一系列频率成分,然后通过对低频成分和高频成分进行舍弃和量化,从而实现对数据的压缩。
DCT算法广泛应用于音频和图像的压缩领域。
-基于小波变换的压缩算法(DWT):DWT算法通过对数据进行多尺度分解,然后通过选择重要的频率成分和舍弃不重要的频率成分来实现对数据的压缩。
主流压缩技术标准

主流压缩技术标准压缩技术是一种将数据通过特定算法进行处理,减少存储或传输所需空间的技术。
在当今信息时代,数据量不断增长,对数据的存储和传输提出了更高的要求。
为了有效地管理和利用大量数据,压缩技术成为不可或缺的一部分。
在压缩技术中,主流的压缩技术标准主要包括无损压缩和有损压缩两种类型。
无损压缩是指在压缩数据的同时,并不丢失任何信息,压缩后的数据可以完全还原为原始数据。
而有损压缩则是在压缩过程中,为了达到更高的压缩比率,牺牲了一定的数据质量,导致压缩后的数据无法完全还原为原始数据。
在无损压缩技术中,主要有以下几种主流标准:1.ZIP:ZIP是一种常见的无损压缩格式,它采用DEFLATE算法进行数据压缩。
ZIP格式的压缩率相对较高,被广泛应用于文件压缩和归档。
2.GZIP:GZIP也是一种无损压缩算法,通常用于压缩网络传输中的数据。
与ZIP相比,GZIP对于文本数据的压缩效果更好。
3.7z:7z是一种压缩格式,它使用7z压缩算法。
7z格式通常能够达到更高的压缩比率,但解压速度较慢。
在有损压缩技术中,主要有以下几种主流标准:1.JPEG:JPEG是最常用的有损压缩格式之一,广泛应用于图像压缩领域。
JPEG通过去除图像中的冗余信息和感知优化来实现高压缩比率。
2.MP3:MP3是一种有损压缩格式,用于压缩音频文件。
MP3格式通过去除人耳无法察觉的音频信号细节,以达到较高的压缩比。
3.H.264:H.264是一种广泛应用于数字视频压缩的有损压缩标准。
H.264通过去除视频帧中的冗余信息和空间/时间相关性来实现高效的视频压缩。
除了以上介绍的压缩技术标准外,还存在其他一些针对特定领域的压缩技术标准,如FLAC(用于音频)、PNG(用于图像)等。
这些标准在各自领域内具有重要的应用价值。
总结起来,主流的压缩技术标准主要包括无损压缩和有损压缩两种类型。
无损压缩技术主要包括ZIP、GZIP和7z等,而有损压缩技术主要包括JPEG、MP3和H.264等。
无损音乐的抓取、压缩、还原与播放
论坛的无损音乐信息讨论区已经开版了,为了配合新版特别组织一篇关于的帖子,希望对大家有所帮助。
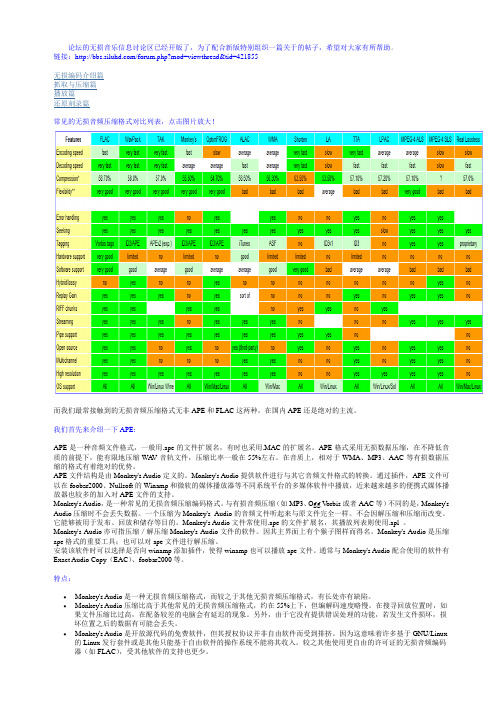
链接:/forum.php?mod=viewthread&tid=421855无损编码介绍篇抓取与压缩篇播放篇还原刻录篇常见的无损音频压缩格式对比列表,点击图片放大!而我们最常接触到的无损音频压缩格式无非APE和FLAC这两种,在国内APE还是绝对的主流。
我们首先来介绍一下APE:APE是一种音频文件格式,一般用.ape的文件扩展名,有时也采用.MAC的扩展名。
APE格式采用无损数据压缩,在不降低音质的前提下,能有限地压缩WA V音轨文件,压缩比率一般在55%左右。
在音质上,相对于WMA、MP3、AAC等有损数据压缩的格式有着绝对的优势。
APE文件结构是由Monkey's Audio定义的。
Monkey's Audio提供软件进行与其它音频文件格式的转换。
通过插件,APE文件可以在foobar2000、Nullsoft的Winamp和微软的媒体播放器等不同系统平台的多媒体软件中播放,近来越来越多的便携式媒体播放器也较多的加入对APE文件的支持。
Monkey's Audio,是一种常见的无损音频压缩编码格式。
与有损音频压缩(如MP3、Ogg V orbis或者AAC等)不同的是,Monkey's Audio压缩时不会丢失数据。
一个压缩为Monkey's Audio的音频文件听起来与原文件完全一样。
不会因解压缩和压缩而改变。
它能够被用于发布、回放和储存等目的。
Monkey's Audio文件常使用.ape的文件扩展名,其播放列表则使用.apl 。
Monkey's Audio亦可指压缩/解压缩Monkey's Audio文件的软件。
因其主界面上有个猴子图样而得名。
Monkey's Audio是压缩ape格式的重要工具;也可以对ape文件进行解压缩。
音频压缩编码原理及标准.

离散余弦变换(DCT)
将原信号沿负方向延拓定义域,并合理选择对称坐标轴, 使其正、负轴对称,这样信号变为实轴对称的偶函数,DFT 变换后仅有余弦项而不存在正弦项,运算量大为减小。 原本的N个样本,经过对称后变为2N个 2N为抽取的样本值总数,为DCT变换的块长度。 例:采样为48KHz的PCM样值进行DCT变换,窗长分别为 21.33ms(相当于1024个样值),5.33ms(相当于256个样 值),则频率分辨率和时间分辨率分别为?
时域编码
结合声音幅度的出现概率来选取量化比特数进行 编码,在满足一定的量化噪声下压缩数码率,从 而降低比特率。
频域编码
利用人耳听觉的声掩蔽特性,在满足一定量化噪 声下来压缩码率 采用滤波和变化,在频域内将其能量较小的分量 忽略,从而实现降低比特率
子带编码:通过带通滤波器分成许多频带子带,分析每 个子带取样的能量,依据心理声学模型来编码 变换编码:变换到频域,根据心理声学模型对变换系数 进行量化和编码
对某频率的声音信号的拾取会采用中心频率接近此频率 的带通滤波器,因此,只有通过该带通滤波器的那部分 噪声才会对该信号产生影响
临界带宽——描述人耳的滤波特性
如果在一频带内噪声的功率等于该纯音的功率,且这时, 纯音刚好能被听到(临界状态),此纯音附近的窄带噪 声带宽的宽度便称为临界带宽 通常认为20Hz~20KHz内有24个临界频带
首先用一组带通滤波器把输入的音频信号分成若干个连 续的子带,然后对每个子带中的音频信号单独编码,在 接收端将各子带单独译码,然后组合、还原成音频信号。 对每个子带的采样值分配不同的比特数。低频分配较多 量化比特,高频分配较少量化比特。利用声音信号的频 谱特点及人耳的感知模型。
四种压缩算法原理介绍
四种压缩算法原理介绍压缩算法是将数据经过特定的编码或转换方式,以减少数据占用空间的方式进行压缩。
常见的压缩算法可以分为四种:无损压缩算法、有损压缩算法、字典压缩算法和算术编码压缩算法。
一、无损压缩算法是指在数据压缩的过程中不丢失任何信息,压缩前后的数据完全相同,通过对数据进行编码或转换,以减少数据的存储空间。
常见的无损压缩算法有:1. 霍夫曼编码(Huffman Coding):霍夫曼编码是一种可变长度编码方式,通过根据数据出现频率给予高频率数据较低的编码长度,低频率数据较高的编码长度,从而达到减少数据存储空间的目的。
2.雷霍尔曼编码(LZ77/LZ78):雷霍尔曼编码是一种字典压缩算法,它通过在数据中并替换相同的字节序列,从而实现数据的压缩。
LZ77算法是将数据划分为窗口和查找缓冲区,通过在查找缓冲区中查找与窗口中相匹配的字节序列来进行压缩。
LZ78算法主要通过建立一个字典,将数据中的字节序列与字典中的序列进行匹配并进行替换,实现数据的压缩。
3.哈夫曼-雷霍尔曼编码(LZW):哈夫曼-雷霍尔曼编码是一种常见的字典压缩算法,它综合了霍夫曼编码和雷霍尔曼编码的特点。
它通过维护一个字典,将数据中的字节序列与字典中的序列进行匹配并进行替换,实现数据的压缩。
二、有损压缩算法是指在数据压缩的过程中会丢失一部分信息,压缩后的数据无法完全还原为原始数据。
常见的有损压缩算法有:1. JPEG(Joint Photographic Experts Group):JPEG 是一种常用的图像压缩算法,它主要通过对图像的颜色和亮度的变化进行压缩。
JPEG算法将图像分成8x8的块,对每个块进行离散余弦变换(DCT),并通过量化系数来削减数据,进而实现压缩。
2. MP3(MPEG Audio Layer-3):MP3 是一种常用的音频压缩算法,它通过分析音频中的声音频率以及人耳对声音的敏感程度,对音频数据进行丢弃或砍切,以减少数据的占用空间。
opus编码压缩方式
大小,并保持高质量的音频输出。
Opus编码采用了一系列先进的算法和技术,具有出色的性能和广泛的应用范围。
本文将详细介绍Opus编码的原理、特点以及它在音频领域中的应用。
一、Opus编码的原理1.1 声音信号模型Opus编码基于声音信号模型进行压缩。
声音信号可以看作是时间上连续的音频样本序列,每个样本表示声音的幅度。
Opus编码通过分析声音信号的频谱、时间相关性和人耳感知特性,选取合适的信号表示方式,从而实现高效的压缩。
1.2 语音编码器和音乐编码器Opus编码器根据输入声音信号的类型,分为语音编码器和音乐编码器两种模式。
语音编码器适用于人类语音的压缩,而音乐编码器则适用于音乐和其他非语音信号的压缩。
这两种编码器为不同类型的声音信号提供了优化的压缩算法。
1.3 预处理和分析在进行编码之前,Opus编码器对输入信号进行预处理和分析。
预处理包括声音信号的预加重处理、音量归一化等,以提高编码的质量和稳定性。
分析阶段则通过对声音信号的频谱、频带能量和时间相关性进行分析,为后续的编码过程提供依据。
1.4 频域分解和控制信号Opus编码器将声音信号转换为频域表示,采用离散傅里叶变换(DFT)将时域信号转换为频域信号。
同时,控制信号也被引入到编码过程中,用于调整编码器的参数和模型,以优化压缩效果。
1.5 量化和编码在频域表示的基础上,Opus编码器进行信号的量化。
量化是指将连续的频域样本映射为离散的量化符号,从而减小数据的表示空间。
量化过程中,编码器根据预设的量化精度和量化表,将频域样本映射为最接近的离散数值。
1.6 熵编码和解码经过量化后的信号被传输到熵编码器,将离散的量化符号映射为二进制码流。
熵编码器利用各种统计方法和算法,根据信号的概率分布进行编码,以实现高效的数据压缩。
解码过程中,熵解码器将二进制码流还原为量化符号,进而还原为频域样本。
1.7 重构和后处理解码器通过逆向的过程将量化符号还原为频域样本,再经过逆离散傅里叶变换(IDFT)将频域信号转换为时域信号。
音频压缩算法
音频压缩算法压缩第7章凌阳音频压缩算法261第7章凌阳音频压缩算法7.1背景介绍7.1.1音频的概述(特点,分类)我们所说的音频是指频率在20Hz~20kHz的声音信号,分为:波形声音,语音和音乐三种,其中波形声音就是自然界中所有的声音,是声音数字化的基础.语音也可以表示为波形声音,但波形声音表示不出语言,语音学的内涵.语音是对讲话声音的一次抽象.是语言的载体,是人类社会特有的一种信息系统,是社会交际工具的符号.音乐与语音相比更规范一些,是符号化了的声音.但音乐不能对所有的声音进行符号化.乐谱是符号化声音的符号组,表示比单个符号更复杂的声音信息内容.7.1.2数字音频的采样和量化将模拟的(连续的)声音波形数字元化(离散化),以便利数字计算机进行处理的过程,主要包括采样和量化两个方面.数字音频的质量取决于:采样频率和量化位数这两个重要参数.此外,声道的数目,相应的音频设备也是影响音频质量的原因.7.1.3音频格式的介绍音频文件通常分为两类:声音文件和MIDI文件(1)声音文件:指的是通过声音录入设备录制的原始声音,直接记录了真实声音的二进制采样数据,通常文件较大;(2)MIDI文件:它是一种音乐演奏指令序列,相当于乐谱,可以利用声音输出设备或与计算机相连的电子乐器进行演奏,由于不包含声音数据,其文件尺寸较小.1)声音文件的格式WAVE文件――*.WAVWAVE文件使用三个参数来表示声音,它们是:采样位数,采样频率和声道数. 在计算机中采样位数一般有8位和16位两种,而采样频率一般有__Hz(11KHz),__Hz(22KHz),__Hz(44KHz)三种.我们以单声道为例,则一般WAVE文件的比特率可达到88K~704Kbps.具体介绍如下:(1)WAVE格式是Microsoft公司开发的一种声音文件格式,它符合RIFF(Resource InterchangeFileFormat)文件规范;第7章凌阳音频压缩算法262(2)用于保存Windows平台的音频信息资源,被Windows平台及其应用程序所广泛支持.(3)WAVE格式支持__,__aw,CCITTLaw和其它压缩算法,支持多种音频位数,采样频率和声道,是PC机上最为流行的声音文件格式.(4)但其文件尺寸较大,多用于存储简短的声音片段.AIFF文件――AIF/AIFF(1)AIFF是音频交换文件格式(AudioInterchangeFileFormat)的英文缩写,是苹果计算机公司开发的一种声音文件格式;压缩(2)被Macintosh平台及其应用程序所支持,NetscapeNavigator浏览器中的LiveAudio也支持AIFF格式,SGI及其它专业音频软件包同样支持这种格式.(3)AIFF支持ACE2,ACE8,MAC3和MAC6压缩,支持16位44.1Kz立体声. Audio文件――*.Audio(1)Audio文件是SunMicrosystems公司推出的一种经过压缩的数字声音格式,是Internet中常用的声音文件格式;(2)NetscapeNavigator浏览器中的LiveAudio也支持Audio格式的声音文件. MPEG文件――*.MP1/*.MP2/*.MP3(1)MPEG是运动图像专家组(MovingPictureExpertsGroup)的英文缩写,代表MPEG标准中的音频部分,即MPEG音频层(MPEGAudioLayer);(2)MPEG音频文件的压缩是一种有损压缩,根据压缩质量和编码复杂程度的不同可分为三层(MPEGAudioLayer1/2/3),分别对应MP1,MP2和MP3这三种声音文件;(3)MPEG音频编码具有很高的压缩率,MP1和MP2的压缩率分别为4:1和6: 1~8:1,而MP3的压缩率则高达10:1~12:1,也就是说一分钟CD音质的音乐,未经压缩需要10MB存储空间,而经过MP3压缩编码后只有1MB左右, 同时其音质基本保持不失真,因此,目前使用最多的是MP3文件格式.RealAudio文件――*.RA/*.RM/*.RAM(1)RealAudio文件是RealNerworks公司开发的一种新型流式音频(Streaming Audio)文件格式;(2)它包含在RealMedia中,主要用于在低速的广域网上实时传输音频信息;(3)网络连接速率不同,客户端所获得的声音质量也不尽相同:对于28.8Kbps的连接,可以达到广播级的声音质量;如果拥有ISDN或更快的线路连接,则可获得CD音质的声音.2)MIDI文件――*.MID/*.RMI(1)MIDI是乐器数字接口(MusicalInstrumentDigitalInterface)的英文缩写,是数字音乐/电子合成乐器的统一国际标准;(2)它定义了计算机音乐程序,合成器及其它电子设备交换音乐信号的方式,还规第7章凌阳音频压缩算法263定了不同厂家的电子乐器与计算机连接的电缆和硬件及设备间数据传输的协议,可用于为不同乐器创建数字声音,可以模拟大提琴,小提琴,钢琴等常见乐器;(3)在MIDI文件中,只包含产生某种声音的指令,这些指令包括使用什么MIDI 设备的音色,声音的强弱,声音持续多长时间等,计算机将这些指令发送给声卡,声卡按照指令将声音合成出来,MIDI在重放时可以有不同的效果,这取决于音乐合成器的质量;(4)相对于保存真实采样资料的声音文件,MIDI文件显得更加紧凑,其文件尺寸通常比声音文件小得多.7.1.4语音压缩编码基础语音压缩编码中的数据量是指:数据量=(采样频率×量化位数)/8(字节数)×声道数目.压缩压缩编码的目的:通过对资料的压缩,达到高效率存储和转换资料的结果,即在保证一定声音质量的条件下,以最小的资料率来表达和传送声音信息.压缩编码的必要性:实际应用中,未经压缩编码的音频资料量很大,进行传输或存储是不现实的.所以要通过对信号趋势的预测和冗余信息处理,进行资料的压缩,这样就可以使我们用较少的资源建立更多的信息.举个例子,没有压缩过的CD品质的资料,一分钟的内容需要11MB的内存容量来存储.如果将原始资料进行压缩处理,在确保声音品质不失真的前提下,将数据压缩一半,5.5MB就可以完全还原效果.而在实际操作中,可以依需要来选择合适的算法.常见的几种音频压缩编码:1)波形编码:将时间域信号直接变换为数字代码,力图使重建语音波形保持原语音信号的波形形状.波形编码的基本原理是在时间轴上对模拟语音按一定的速率抽样,然后将幅度样本分层量化,并用代码表示.译码是其反过程,将收到的数字序列经过译码和滤波恢复成模拟信号.如:脉冲编码调制(PulseCodeModulation,PCM),差分脉冲编码调制(DPCM), 增量调制(DM)以及它们的各种改进型,如自适应差分脉冲编码调制(ADPCM),自适应增量调制(ADM),自适应传输编码(AdaptiveTransferCoding,ATC)和子带编码(SBC)等都属于波形编码技术.波形编码特点:高话音质量,高码率,适于高保真音乐及语音.2)参数编码:参数编码又称为声源编码,是将信源信号在频率域或其它正交变换域提取特征参数,并将其变换成数字代码进行传输.译码为其反过程,将收到的数字序列经变换恢复特征参量,再根据特征参量重建语音信号.具体说,参数编码是通过对语音信号特征参数的提取和编码,力图使重建语音信号具有尽可能高的准确性,但重建信号的波形同原语音信号的波形可能会有相当大的差别.第7章凌阳音频压缩算法264如:线性预测编码(LPC)及其它各种改进型都属于参数编码.该编码比特率可压缩到2Kbit/s-4.8Kbit/s,甚至更低,但语音质量只能达到中等,特别是自然度较低.参数编码特点:压缩比大,计算量大,音质不高,廉价!3)混合编码:混合编码使用参数编码技术和波形编码技术,计算机的发展为语音编码技术的研究提供了强有力的工具,大规模,超大规模集成电路的出现,则为语音编码的实现提供了基础.80年代以来,语音编码技术有了实质性的进展,产生了新一代的编码算法,这就是混合编码.它将波形编码和参数编码组合起来,克服了原有波形编码和参数编码的弱点,结合各自的长处,力图保持波形编码的高质量和参数编码的低速率.如:多脉冲激励线性预测编码(MPLPC),规划脉冲激励线性预测编码(KPELPC), 码本激励线性预测编码(CELP)等都是属于混合编码技术.其数据率和音质介于参数和波形编码之间.总之,音频压缩技术之趋势有两个:压缩1)降低资料率,提高压缩比,用于廉价,低保真场合(如:电话).2)追求高保真度,复杂的压缩技术(如:CD).语音合成,辨识技术的介绍: 按照实现的功能来分,语音合成可分两个档次:(1)有限词汇的计算机语音输出(2)基于语音合成技术的文字语音转换(TTS:Text-to-Speech)按照人类语言功能的不同层次,语音合成可分为三个层次:(1)从文字到语音的合成(Text-to-Speech)(2)从概念到语音的合成(Concept-to-Speech)(3)从意向到语音的合成(Intention-to-Speech)图7.1是文本到语音的转换过程:文本处理语音合成韵律处理语音数据库词典及语言规范合成语音输出文本输入图7.1从文本到语音转换过程示意语音辨识:语音辨识技术有三大研究范围:口音独立,连续语音及可辨认字词数量. 口音独立:1)早期只能辨认特定的使用者即特定语者(SpeakerDependent,SD)模式,使用者可针对特定语者辨认词汇(可由使用者自行定义,如人名声控拨号),作简单快速的训第7章凌阳音频压缩算法265练纪录使用者的声音特性来加以辨认.随着技术的成熟,进入语音适应阶段SA(speakeradaptation),使用者只要对于语音辨识核心,经过一段时间的口音训练后,即可拥有不错的辨识率.2)非特定语者模式(SpeakerIndependent,SI),使用者无需训练即可使用,并进行辨认.任何人皆可随时使用此技术,不限定语者即男性,女性,小孩,老人皆可. 连续语音:1)单字音辨认:为了确保每个字音可以正确地切割出来,必须一个字一个字分开来念,非常不自然,与我们平常说话的连续方式,还是有点不同.2)整个句子辨识:只要按照你正常说话的速度,直接将要表达的说出来,中间并不需要停顿,这种方式是最直接最自然的,难度也最高,现阶段连续语音的辨识率及正确率,虽然效果还不错但仍需再提高.然而,中文字有太多的同音字,因此目前所有的中文语音辨识系统,几乎都是以词为依据,来判断正确的同音字.可辨认词汇数量:内建的词汇数据库的多寡,也直接影响其辨识能力.因此就语音辨识的词汇数量来说亦可分为三种:1)小词汇量(10-100)2)中词汇量(100-1000)3)无限词汇量(即听写机)图7.2是简化的语音识别原理图,其中实线部分成为训练模块,虚线部分为识别压缩模块.复杂声学,言语条件下的语音输入语音模型声学模式训练语音匹配语音模式训练语音处理识别结果,理解结果语言模型图7.2语音识别原理简图第7章凌阳音频压缩算法2667.2凌阳音频简介7.2.1凌阳音频压缩算法的编码标准表7.1是不同音频质量等级的编码技术标准(频响): 表7.1信号类型频率范围(Hz)采样率(kHz)量化精度(位) 电话话音200~__宽带音频(AM质量)50~__-__调频广播(FM质量)20~15k37.816高质量音频(CD质量)20~20k44.116凌阳音频压缩算法处理的语音信号的范围是200Hz-3.4KHz的电话话音.7.2.2压缩分类压缩分无损压缩和有损压缩.无损压缩一般指:磁盘文件,压缩比低:2:1~4:1. 而有损压缩则是指:音/视频文件,压缩比可高达100:1.凌阳音频压缩算法根据不同的压缩比分为以下几种(具体可参见语音压缩工具一节内容):SACM-A2022年:压缩比为8:1,8:1.25,8:1.5SACM-S480:压缩比为80:3,80:4.5SACM-S240:压缩比为80:1.5按音质排序:A2022年S480S2407.2.3凌阳常用的音频形式和压缩算法1)波形编码:sub-band即SACM-A2022年特点:高质量,高码率,适于高保真语音/音乐.压缩2)参数编码:声码器(vocoder)模型表达,抽取参数与激励信号进行编码.如: SACM-S240.特点:压缩比大,计算量大,音质不高,廉价!3)混合编码:CELP即SACM-S480特点:综合参数和波形编码之优点.除此之外,还具有FM音乐合成方式即SACM-MS01.第7章凌阳音频压缩算法2677.2.4分别介绍凌阳语音的播放,录制,合成和辨识凌阳的__A是16位单片机,具有DSP功能,有很强的信息处理能力,最高时钟频率可达到49MHz,具备运算速度高的优势等等,这些都无疑为语音的播放,录放,合成及辨识提供了条件.凌阳压缩算法中SACM_A2022年,SACM_S480,SACM_S240主要是用来放音,可用于语音提示,而DVR则用来录放音.对于音乐合成MS01,该算法较繁琐,而且需要具备音乐理论,配器法及和声学知识,所以对于特别爱好者可以到我们的网站去了。
什么是数据压缩算法请介绍几种常见的数据压缩算法
什么是数据压缩算法请介绍几种常见的数据压缩算法数据压缩算法是一种通过减少数据表示的位数或者利用数据的统计特性来减少数据占用空间的技术。
数据压缩算法广泛应用于计算机科学和信息技术领域,在数据传输、存储和处理中起到了关键作用。
本文将介绍几种常见的数据压缩算法,包括无损压缩算法和有损压缩算法。
一、无损压缩算法无损压缩算法是指能够还原原始数据的压缩算法,压缩后的数据与原始数据完全相同。
以下是几种常见的无损压缩算法。
1. 哈夫曼编码(Huffman Coding)哈夫曼编码是一种基于数据出现频率的最优前缀编码算法。
该算法通过构建哈夫曼树来生成唯一的编码表,将频率较高的数据用较短的编码表示,从而实现数据压缩。
哈夫曼编码广泛应用于文件压缩、图像压缩等领域。
2. 霍夫曼编码(Huffman Coding)霍夫曼编码是一种用于压缩无损图像数据的编码算法,它是以哈夫曼编码为基础进行优化而得到的。
霍夫曼编码通过统计图像中像素的出现频率来生成编码表,并利用较短的编码来表示频率较高的像素值。
这使得图像数据能够以更少的位数来表示,从而实现了数据的压缩。
3. Lempel-Ziv-Welch压缩算法(LZW)Lempel-Ziv-Welch压缩算法是一种无损压缩算法,常用于文本文件的压缩。
该算法通过不断增加编码长度的方式来处理输入的数据流,将出现的字符序列以短编码代替,并将新出现的字符序列添加到编码表中。
这种算法有效地利用了数据中的重复模式,实现了数据的高效压缩。
二、有损压缩算法有损压缩算法是指为了实现更高的压缩率,可以牺牲一定的数据精度或质量的压缩算法。
以下是几种常见的有损压缩算法。
1. JPEG压缩算法(Joint Photographic Experts Group)JPEG压缩算法是一种广泛应用于图像压缩的有损压缩算法。
该算法通过将图像分割为多个8x8的小块,对每个小块进行离散余弦变换(DCT)和量化,并对量化后的系数进行编码和熵编码。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
网络与多媒体技术
10.1 数据压缩概述
衡量一种数据压缩技术的好坏有三个重要的指标
压缩比 图像质量或音质 压缩和解压的速度
数据压缩原理
原始的多媒体信源数据存在着客观上的大量冗余。信 息理论认为:若信源编码的熵大于信源的实际熵,该 信源中一定存在冗余度。去掉冗余不会减少信息量, 仍可原样恢复数据;但若减少了熵,数据则不能完全 恢复。不过在允许的范围内损失一定的熵,数据仍然 可以近似恢复。
网络与多媒体技术
10.1 数据压缩概述
数据压缩技术标准
H.263:在H.261的基础上发展而来的加强版,它借鉴 了MPEG-1的优点,支持PSTN,能在低带宽上传输高 质量的视频流。 H.264:由ISO/IEC(IEC,国际电工委员会)与ITU-T 组成的联合视频组(Joint Video Team,JVT)制定 的新一代视频压缩编码标准。在相同的重建图像质量 下,H.264比H.263+和MPEG-4减小50%码率,对信道 时延的适应性较强,既可工作于低时延模式以满足实 时业务,如会议电视等,又可工作于无时延限制的场 合,如视频存储等;提高网络适应性,加强对误码和 丢包的处理,提高解码器的差错恢复能力。
网络与多媒体技术
10.2 音频数据的压缩 音频信号压缩编码的主要依据是人耳的听 觉特性,主要有两点: • 1.人的听觉系统中存在一个听觉阈值电平, 低于这个电平的声音信号人耳听不到 . • 2.人的听觉存在屏蔽效应。当几个强弱不同 的声音同时存在时,强声使弱声难以听到,并 且两者之间的关系与其相对频率的大小有关 . 声音编码算法就是通过这些特性来去掉更 多的冗余数据,来达到压缩数据的目的。
网络与多媒体技术
10.1 数据压缩概述
数据压缩原理
变换编码。有失真编码。对原始数据从初始空间或时 间域进行数学变换,使得信号中最重要的部分在变换 域中易于识别,并且集中出现,可以重点处理;相反 使能量较少的部分较分散,可以进行粗处理。 三个步骤:变换、变换域采样和量化。 分析—合成编码。有失真编码。通过对原始数据的分 析,将其分解成一系列更适合表示的“基元”或“参数”, 编码仅对这些基本单元或参数进行。而译码时则借助 于一定的规则或模型,按照一定的算法将这些基元或 参数再“综合”成原数据的一个逼近。
网络与多媒体技术
10.1 数据压缩概述
数据压缩原理
因为人的感觉的某些不敏感性,多媒体数据中还存在 着从主观感受角度看去的大量冗余,即:在人眼允许 的误差范围之内,压缩前后的图像如果不做非常细致 的对比是很难觉察出两者的差别的。 统计编码:无失真编码。根据信息出现概率的分布特 性进行的压缩编码。 预测编码:有失真编码。根据原始的离散信号之间存 在关联性的特点,利用前面的一个或多个信号对下一 个信号进行预测,然后对实际值和预测值的差进行编 码。网络与多ຫໍສະໝຸດ 体技术10.1 数据压缩概述
数据压缩技术标准
H.26X。由CCITT(Consultative Committee of International Telegraph and Telephone 国际电报电 话咨询委员会,从1993年3月1日起,改组为ITU)制 定的标准。包括H.261、H.263、H.264,简称为H.26X 主要应用于实时视频通信领域 H.261:是ITU-T为在综合业务数字网(ISDN)上开展 双向声像业务(可视电话、视频会议)而制定的,速 率为64kb/s的整数倍。H.261只对CIF(352×288)和 QCIF(176×144)两种图像格式进行处理。H.261是 最早的运动图像压缩标准。
• 常用工具:WinRar、WinZip、ARC等
网络与多媒体技术
10.1 数据压缩概述
数据压缩方法 有损压缩:
• 利用了人类视觉和听觉器官对图像或声音中的某些 频率成分不敏感的特性,允许在压缩过程中损失一 定的信息;虽然不能完全恢复原始数据,但是所损 失的部分对理解原始图像或声音的影响较小,却换 来了大得多的压缩比。有损压缩广泛应用于语音、 图像和视频数据的压缩。 • 常用的有损压缩方法有:PCM(脉冲编码调制)、预测 编码、变换编码(主要是离散余弦变换方法)、插值和 外推法(空域亚采样、时域亚采样、自适应)等等。 • 常用工具:JPEG、MPEG等
网络与多媒体技术
10.1 数据压缩概述
数据压缩方法
无损压缩:
• 利用数据的统计冗余进行压缩,可完全恢复原始数 据而不引入任何失真,但压缩率受到统计冗余度理 论限制,一般为2:1到5:1。 • 多媒体应用中经常使用的无损压缩方法主要是基于 统计的编码方案,如游程编码(run length)、 Huffman编码、算术编码和LZW编码等等。
第十章 多媒体数据压缩技术
计算机网络与多媒体技术
网络与多媒体技术
多媒体关键技术
10.1
10.2 10.3
数据压缩概述
音频数据的压缩
静态图像的数据压缩
10.4
运动图像的数据压缩
网络与多媒体技术
10.1 数据压缩概述
由于多媒体数据量非常大,造成计算机的存储和网络传输负担 若帧速率为25帧/秒,则1s的数据量大约为25MB,一个640MB 的光盘只能存放大约25s的动态图像 一幅640×480分辨率的24位真彩色图像的数据量约为900KB; 一个100MB的硬盘只能存储约100幅静止图像画面 解决办法之一就是进行数据压缩,压缩后再进行存储和传输, 到需要时再解压、还原。 以目前常用的位图格式的图像存储方式为例,像素与像素之间 无论是在行方向还是在列方向都具有很大的相关性,因而整体 上数据的冗余度很大,在允许一定限度失真的前提下,能够对 图像数据进行很大程度的压缩。
网络与多媒体技术
10.2 音频数据的压缩
声音信号的基本参数: 频率:信号每秒钟变化的次数。次声、可听声和超声 振幅:声波波形的最大位移。 音频压缩标准: 电话质量的语音压缩标准:300Hz~3.4KHz。当采样频 率为8KHz,量化位数为8bit时所对应的速率为6kbit/s。 调幅广播质量的音频压缩标准:50Hz~7KHz。当使用 16KHz的抽样频率和14bit的量化位数时,信号速率为 224kbit/s。符合1988年ITU制定的G.722标准。 高保真立体声音频压缩标准:50Hz~20KHz。在44.1KHz 抽样频率下用16bit量化,信号速率为每声道705kbit/s。 目前比较成熟的标准为“MPEG音频”。