音频基本知识
数字音频基础知识

第一章数字音频基础知识重要内容⏹声音基础知识⏹结识数字音频⏹数字音频专业知识第1节声音基础知识1.1 声音旳产生⏹声音是由振动产生旳。
物体振动停止,发声也停止。
当振动波传到人耳时,人便听到了声音。
⏹人能听到旳声音,涉及语音、音乐和其他声音(环境声、音效声、自然声等),可以分为乐音和噪音。
✦乐音是由规则旳振动产生旳,只包具有限旳某些特定频率,具有拟定旳波形。
✦噪音是由不规则旳振动产生旳,它包具有一定范畴内旳多种音频旳声振动,没有拟定旳波形。
1.2 声音旳传播⏹声音靠介质传播,真空不能传声。
✦介质:可以传播声音旳物质。
✦声音在所有介质中都以声波形式传播。
⏹音速✦声音在每秒内传播旳距离叫音速。
✦声音在固体、液体中比在气体中传播得快。
✦15ºC 时空气中旳声速为340m/s 。
1.3 声音旳感知⏹外界传来旳声音引起鼓膜振动经听小骨及其他组织传给听觉神经,听觉神经再把信号传给大脑,这样人就听到了声音。
⏹双耳效应旳应用:立体声⏹人耳能感受到(听觉)旳频率范畴约为20Hz~20kHz,称此频率范畴内旳声音为可听声(audible sound)或音频(audio),频率<20Hz声音为次声,频率>20kHz声音为超声。
⏹人旳发音器官发出旳声音(人声)旳频率大概是80Hz~3400Hz。
人说话旳声音(话音voice / 语音speech)旳频率一般为300Hz~3000 Hz(带宽约3kHz)。
⏹老式乐器旳发声范畴为16Hz (C2)~7kHz(a5),如钢琴旳为27.5Hz (A2)~4186Hz(c5)。
1.4 声音旳三要素⏹声音具有三个要素:音调、响度(音量/音强)和音色⏹人们就是根据声音旳三要素来辨别声音。
音调(pitch )⏹音调:声音旳高下(高音、低音),由“频率”(frequency)决定,频率越高音调越高。
✦声音旳频率是指每秒中声音信号变化旳次数,用Hz 表达。
例如,20Hz 表达声音信号在1 秒钟内周期性地变化20 次。
音频基础知识及编码原理

音频基础知识及编码原理音频是我们日常生活中不可或缺的一部分,它通过我们的耳朵传达声音信息。
音频的基础知识和编码原理对于我们理解音频的特性和进行音频处理都是非常重要的。
一、音频基础知识1.音频信号:音频信号是一种连续时间变化的模拟信号,它可以通过声音的压力波来传递声音信息。
在计算机中,音频信号会被采样和量化为离散的数字信号。
2.音频频率:音频频率是指声音中的振荡周期数量。
它以赫兹(Hz)为单位表示,描述了声波的频率。
人类可以听到的频率范围约为20Hz到20kHz,不同的生物和设备有着不同的频率感知范围。
3.音频幅度:音频幅度是指声音的强度或振幅。
它可以通过声音的声压级来表示,单位为分贝(dB)。
声压级越高,声音就越大;声压级越低,声音就越小。
4. 音频声道:音频声道是指音频信号的通道数量。
单声道(mono)只有一个通道,立体声(stereo)有两个通道,多声道(multi-channel)有三个或更多个通道。
5.音频采样率:音频采样率是指音频信号在单位时间内进行采样的次数。
它以赫兹(Hz)为单位表示,描述了数字音频的采样精度。
常见的采样率有44.1kHz和48kHz,高采样率可以提高音频的质量。
二、音频编码原理音频编码是将模拟音频信号转换为数字音频信号的过程。
在音频编码中,采样和量化是两个主要步骤。
1.采样:采样是将连续时间的模拟音频信号转换为离散时间的数字音频信号的过程。
采样率决定了采样的频率,即每秒钟采样的次数。
采样过程会将每个采样点的幅度值记录下来,形成一个采样序列。
2.量化:量化是将连续的模拟音频信号转换为离散的数字音频信号的过程。
它将每个采样点的幅度值映射到一个有限的数值范围内,通常使用固定的比特数来表示每个采样点的幅度。
3.压缩编码:为了减小数字音频的文件大小,音频信号通常会经过压缩编码的处理。
压缩编码可以通过去除信号中的冗余信息或者使用有损压缩算法来实现。
常见的音频压缩编码格式有MP3、AAC和FLAC等。
音频基础知识

音频,英文是AUDIO,也许你会在录像机或VCD的背板上看到过AUDIO输出或输入口。
这样我们可以很通俗地解释音频,只要是我们听得见的声音,就可以作为音频信号进行传输。
有关音频的物理属性由于过于专业,请大家参考其他资料。
自然界中的声音非常复杂,波形极其复杂,通常我们采用的是脉冲代码调制编码,即PCM编码。
PCM通过采样、量化、编码三个步骤将连续变化的模拟信号转换为数字编码。
一、音频基本概念1、什么是采样率和采样大小(位/bit)。
声音其实是一种能量波,因此也有频率和振幅的特征,频率对应于时间轴线,振幅对应于电平轴线。
波是无限光滑的,弦线可以看成由无数点组成,由于存储空间是相对有限的,数字编码过程中,必须对弦线的点进行采样。
采样的过程就是抽取某点的频率值,很显然,在一秒中内抽取的点越多,获取得频率信息更丰富,为了复原波形,一次振动中,必须有2个点的采样,人耳能够感觉到的最高频率为20kHz,因此要满足人耳的听觉要求,则需要至少每秒进行40k次采样,用40kHz表达,这个40kHz就是采样率。
我们常见的CD,采样率为。
光有频率信息是不够的,我们还必须获得该频率的能量值并量化,用于表示信号强度。
量化电平数为2的整数次幂,我们常见的CD位16bit的采样大小,即2的16次方。
采样大小相对采样率更难理解,因为要显得抽象点,举个简单例子:假设对一个波进行8次采样,采样点分别对应的能量值分别为A1-A8,但我们只使用2bit的采样大小,结果我们只能保留A1-A8中4个点的值而舍弃另外4个。
如果我们进行3bit的采样大小,则刚好记录下8个点的所有信息。
采样率和采样大小的值越大,记录的波形更接近原始信号。
2、有损和无损根据采样率和采样大小可以得知,相对自然界的信号,音频编码最多只能做到无限接近,至少目前的技术只能这样了,相对自然界的信号,任何数字音频编码方案都是有损的,因为无法完全还原。
在计算机应用中,能够达到最高保真水平的就是PCM编码,被广泛用于素材保存及音乐欣赏,CD、DVD以及我们常见的WAV文件中均有应用。
音频入门知识
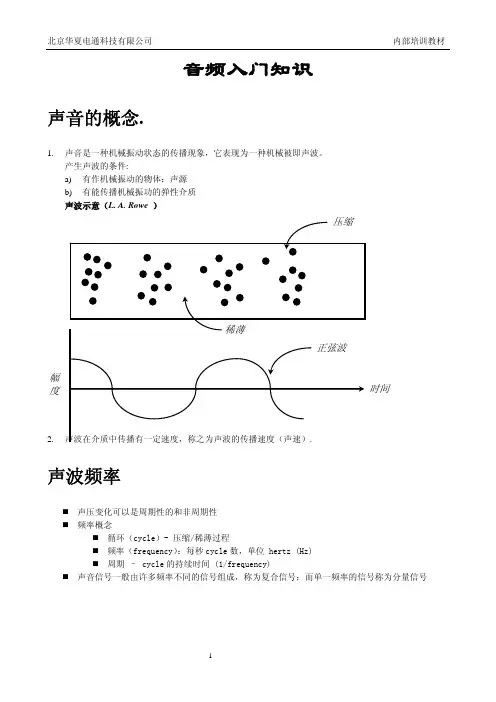
音频入门知识声音的概念.1. 声音是一种机械振动状态的传播现象,它表现为一种机械被即声波。
产生声波的条件:a) 有作机械振动的物体:声源 b) 有能传播机械振功的弹性介质 声波示意(L. A. Rowe )2.声波频率声压变化可以是周期性的和非周期性 频率概念循环(cycle)- 压缩/稀薄过程 频率(frequency):每秒cycle 数,单位 hertz (Hz) 周期 – cycle 的持续时间 (1/frequency)声音信号一般由许多频率不同的信号组成,称为复合信号;而单一频率的信号称为分量信号时间幅度频率范围频率小于20Hz 一般称为次声波(subsonic)人的听觉器官能感知的声音频率范围约为20Hz~20kHz的信号称为音频(Audio)信号人发音器官发声频率约是80~3400Hz,但人说话的信号频率约为300~3000Hz,即话音(speech)信号高于20kHz的信号称为超声波 (ultrasonic)超声波及次声波一般不能引起人听觉器官的感觉,但可借助一些仪器设备进行观察和测量乐音与噪音1.一般乐音指具有确定的基频以及与该基频有较小整数倍关系的各阶谐频(harmonic tone)2.频率比基音高的所有分音统称泛音(over tone),泛音的频率不必与基音成整数倍关系3.在主观上把令人不愉快或不需要的声音定义为噪音4.噪音的频谱较为复杂,具有无规则的振幅和波形的连续频谱声音三要素1.响度(音响)loudness到达人耳的声扰动振幅所产生的听觉的大小声振动能量是物理特性,可用声强(sound pressure)定义,单位:帕斯卡 (Pa)实用上通常都以对数方式的声压级 (sound pressure level)表示,单位:分贝(db)响度是主观量,不能用任何仪器正确地测量声音响度使用了以两个声强之比的对数为基础的相对标度,单位:宋(sone)2.音调(音高)pitch或tone人对声音刺激频率的主观判断与估量,称之为音调 (Pitch),单位:美(Mel)Frequency是物理量,而音调是人的感觉听觉经验一般女生的声音比男生高较大物体振动的音调较低3.音色(音质)timber由其频谱决定: 不同乐器发出同一音高的乐音,仍然可以分辨可以把音色描述为音的瞬时横截面,即用谐音(泛音)的数目、强度、分布和相位来描述。
音频的基础知识

音频的基础知识一、计算机和网络是怎样存储、处理和传递声音的?计算机和网络存储、处理和传递的是二进制数据。
用二进制数字序列表示声音,是利用现代信息技术处理和传递声音信号的前提。
数字声音的获取有以下两种方式:1、将声音数字化2、利用MIDI设备输入或用计算机软件编写MIDI音乐二、声音的数字化模拟音频信号:声波通过话筒转变为时间上连续的电压波,电压波与引起电压波的声波的变化规律是一致的,因此可以利用电压波来模拟声音信号,这种电压波被称为模拟音频信号。
模拟/数字转换:计算机内部只能处理数字信息,因此必须借助于一种设备,将时间上连续的模拟音频信号转变为用来表示声音的数据序列,计算机才能进行识别和处理,也就是通过话筒以及相关电压放大电路把声波转换成电压的波形。
通过“采样”和“量化”可以实现模拟量的数字化,这个过程称为“模数转换”(A/D转换),承担转换任务的电路和芯片称为“数模转换器”(ADC)采样:按一定的频率,即每个一小段时间,测得模拟信号的模拟量值。
量化:采样时测的的模拟电压值,要进行分级量化。
方法是按整个电压变化的最大幅度划分成几个区段,把落在某区段的采样到的样品值归成一类,并给出相应的量化值。
通过采样和量化,一个连续的波形变成了一系列二进制数字表示的数据。
数字化的声音的质量取决于采样频率和量化分级的细密程度。
量化的分辨率越高,所得数字化的声音的保真程度也越好,数据量也越大。
在播放时,计算机还要将数字信号转化成模拟信号。
例题:在某声音的数字化过程中,使用44.1KHZ的取样频率,16位量化位数,则采集四声道的此声音1分钟所需的储存空间约为__A165.75MB B21.168MBC20.672MB D10.584MB波形声音的码率(kb/s)=44.1 * 16 * 4=2822.4kb/s2822.4kb/s=2822.4/8=352.8KB/s352.8KB/s* 60s=21168KB=20.672MB选C三、MIDI音乐MIDI是音乐设备数字接口。
音频基本知识
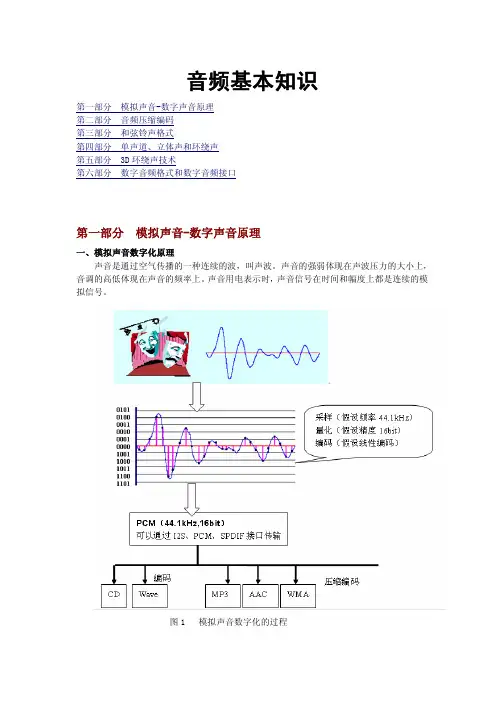
音频基本知识第一部分 模拟声音-数字声音原理第二部分 音频压缩编码第三部分 和弦铃声格式第四部分 单声道、立体声和环绕声第五部分 3D环绕声技术第六部分数字音频格式和数字音频接口第一部分 模拟声音-数字声音原理一、模拟声音数字化原理声音是通过空气传播的一种连续的波,叫声波。
声音的强弱体现在声波压力的大小上,音调的高低体现在声音的频率上。
声音用电表示时,声音信号在时间和幅度上都是连续的模拟信号。
图1 模拟声音数字化的过程声音进入计算机的第一步就是数字化,数字化实际上就是采样和量化。
连续时间的离散化通过采样来实现。
声音数字化需要回答两个问题:①每秒钟需要采集多少个声音样本,也就是采样频率(f s)是多少,②每个声音样本的位数(bit)应该是多少,也就是量化位数。
¾采样频率奈奎斯特理论(采样定理)指出,采样频率不应低于声音信号最高频率的两倍,这样才能把以数字表达的声音还原成原来的声音。
采样的过程就是抽取某点的频率值,很显然,在一秒中内抽取的点越多,获取得频率信息更丰富,为了复原波形,一次振动中,必须有2个点的采样,人耳能够感觉到的最高频率为20kHz,因此要满足人耳的听觉要求,则需要至少每秒进行40k次采样,用40kHz表达,这个40kHz就是采样率。
我们常见的CD,采样率为44.1kHz。
电话话音的信号频率约为3.4 kHz,采样频率就选为8 kHz。
常见的音频录制时的采样率和量化位数:镭射碟 声音录制格式 从数字音频接口输入输出DVD杜比数字 杜比数字位信号线性PCM 线性PCM(48kHz采样/16bit或48KHz采样/24bit等)CD 线性PCM 线性PCM(44.1kHz采样/16bit)VCD MPEG 线性PCM(44.1kHz采样/16bit)表1 常见音频录制及传输格式¾量化精度光有频率信息是不够的,我们还必须纪录声音的幅度。
量化位数越高,能表示的幅度的等级数越多。
音频基础知识
⾳频基础知识⼀.⾳频基础知识1.⾳频编解码原理数字⾳频的出现,是为了满⾜复制、存储、传输的需求,⾳频信号的数据量对于进⾏传输或存储形成巨⼤的压⼒,⾳频信号的压缩是在保证⼀定声⾳质量的条件下,尽可能以最⼩的数据率来表达和传送声⾳信息。
信号压缩过程是对采样、量化后的原始数字⾳频信号流运⽤适,当的数字信号处理技术进⾏信号数据的处理,将⾳频信号中去除对⼈们感受信息影响可以忽略的成分,仅仅对有⽤的那部分⾳频信号,进⾏编排,从⽽降低了参与编码的数据量。
数字⾳频信号中包含的对⼈们感受信息影响可以忽略的成分称为冗余,包括时域冗余、频域冗余和听觉冗余。
1.1时域冗余.幅度分布的⾮均匀性:信号的量化⽐特分布是针对信号的整个动态范围⽽设定的,对于⼩幅度信号⽽⾔,⼤量的⽐特数A.幅度分布的⾮均匀性据位被闲置。
B.样值间的相关性:声⾳信号是⼀个连续表达过程,通过采样之后,相邻的信号具有极强的相似性,信号差值与信号本⾝相⽐,数据量要⼩的多。
C.信号周期的相关性:声⾳信息在整个可闻域的范围内,每个瞬间只有部分频率成分在起作⽤,即特征频率,这些特征频率会以⼀定的周期反复出现,周期之间具有相关关系。
D.长时⾃我相关性:声⾳信息序列的样值、周期相关性,在⼀个相对较长的时间间隔也会是相对稳定的,这种稳定关系具有很⾼的相关系数。
E.静⾳:声⾳信息中的停顿间歇,⽆论是采样还是量化都会形成冗余,找出停顿间歇并将其样值数据去除,可以减少数据量。
1.2频域冗余.长时功率谱密度的⾮均匀性:任何⼀种声⾳信息,在相当长的时间间隔内,功率分布在低频部分⼤于⾼频部分,功率谱A.长时功率谱密度的⾮均匀性具有明显的⾮平坦性,对于给定的频段⽽⾔,存在相应的冗余。
B.语⾔特有的短时功率谱密度:语⾳信号在某些频率上会出现峰值,⽽在另⼀些频率上出现⾕值,这些共振峰频率具有较⼤的能量,由它们决定了不同的语⾳特征,整个语⾔的功率谱以基⾳频率为基础,形成了向⾼次谐波递减的结构。
音频基本知识
1、人耳能听到的频率范围是20—20KHZ。
2、把声能转换成电能的设备是传声器。
3、把电能转换成声能的设备是扬声器。
4、声频系统出现声反馈啸叫,通常调节均衡器。
5、房间混响时间过长,会出现声音混浊。
6、房间混响时间过短,会出现声音发干。
7、唱歌感觉声音太干,当调节混响器。
8、讲话时出现声音混浊,可能原因是加了混响效果。
9、声音三要素是指音强、音高、音色。
10、音强对应的客观评价尺度是振幅。
11、音高对应的客观评价尺度是频率。
12、音色对应的客观评价尺度是频谱。
13、人耳感受到声剌激的响度与声振动的频率有关。
14、人耳对高声压级声音感觉的响度与频率的关系不大。
15、人耳对中频段的声音最为灵敏。
16、人耳对高频和低频段的声音感觉较迟钝。
17、人耳对低声压级声音感觉的响度与频率的关系很大。
18、等响曲线中每条曲线显示不同频率的声压级不相同,但人耳感觉的响度相同。
19、等响曲线中,每条曲线上标注的数字是表示响度级。
20、用分贝表示放大器的电压增益公式是20lg(输出电压/输入电压)。
21、响度级的单位为phon。
22、声级计测出的dB值,表示计权声压级。
23、音色是由所发声音的波形所确定的。
24、声音信号由稳态下降60dB所需的时间,称为混响时间。
25、乐音的基本要素是指旋律、节奏、和声。
26、声波的最大瞬时值称为振幅。
27、一秒内振动的次数称为频率。
28、如某一声音与已选定的1KHz纯音听起来同样响,这个1KHz纯音的声压级值就定义为待测声音的响度。
29、人耳对1~3KHZ的声音最为灵敏。
30、人耳对100Hz以下,8K以上的声音感觉较迟钝。
31、舞台两侧的早期反射声对原发声起加重和加厚作用,属有益反射声作用。
32、观众席后侧的反射声对原发声起回声作用,属有害反射作用。
33、声音在空气中传播速度约为340m/s。
34、要使体育场距离主音箱约34m的观众听不出两个声音,应当对观众附近的补声音箱加0.1s延时。
音频基础知识
⾳频基础知识Audio知识简介⼲⼀⾏专⼀⾏VS学⼀⾏丢⼀⾏第⼀部分:HTS基本概念:HTS(Home Theater System)通俗的讲就是将电影院搬到家⾥,然后就成了家庭影院,就公司的产品⽽⾔可以简单的理解为:DVD/BD player + 功放+ Speaker 组成:节⽬源(碟⽚+碟机等)+ 放声系统(AV功放+⾳箱组等)+显⽰部分(电视机/投影仪)配置家庭影院的好处:⾼清晰的如⽔晶般的画⾯,环绕的⽴体声,清晰的⼈声,震撼的低⾳效果,可以提供⼏乎⾝临其境的感觉。
在强烈的视听冲击下,能感受到现实和虚拟的完美交汇,触发更深的⼈⽣感悟。
第⼆部分:Audio百度定义:1.Audio指⼈说话的声⾳频率,通常指300Hz---3400Hz的频带2.指存储声⾳内容的⽂件3.在某些⽅⾯能指作为波滤的振动。
⾳频这个专业术语,⼈类能够听到的所有声⾳都称之为⾳频,它可能包括噪⾳,声⾳被录制下来以后,⽆论是说话声,歌声乐器都可以通过数字⾳乐软件处理。
把它制作成CD,这时候所有的声⾳没有改变,因为CD本来就是⾳频⽂件的⼀种类型。
⽽⾳频只是储存在计算机⾥的声⾳,演讲和⾳乐,如果有计算机加上相应的⾳频卡,可以把所有的声⾳录制下来,声⾳的声学特性,⾳的⾼低都可以⽤计算机硬盘⽂件的⽅式储存下来,反过来,也可以把眄来的⾳频⽂件通过⼀定的⾳频程序播放,还原以前录下的声⾳。
Audio的分类:按编码格式分类:mp3,wav, aac, ogg, flac, aiff, ac3(亦称之Dolby digital), dts, pcm, Dolby true hd(HD), Dolby digital plus(HD), dts hd master audio(HD), dts hd high resolution audio(HD), dts hd low bit rate(HD)多声道⾳频的分类:C:center L: left front R: Right frontLS: Left surround RS: right surround S: surround(单个环绕声道)LB:left back surround RB: right back surroundCs: Center surround1.带LFE声道的分法:根据码流中实际的通道数分X的值为0/1,0表⽰不带LFE通道,1表⽰含LFE通道1.x C 如1.0 为C,1.1为C+LFE2.x->L+R3.x->C+L+R4.x->L+R+LS+RS5.x->L+R+C+LS+RS6.x->L+R+C+LS+RS+Cs7.x->L+R+C+LS+RS+LB+RB2.不带LFE声⾳的分法:根据喇叭摆放的位置分其中C/L/R均摆放在前⾯,LS/RS/S/LB/RB均摆在两边/后⾯,如下图1/0->C2/0->L+R3/0->C+L+R2/1->L+R+S2/2->L+R+LS+RS3/1->L+R+C+S3/2->L+R+C+LS+RS3/3->L+R+C+LS+RS+Cs3/4->L+R+C+LS+RS+LB+RB3.声⾳信号的传输:(1)定义及I2S总线构成:I2S(Inter-IC Sound)总线是飞利浦公司为数字⾳频设备之间的⾳频数据传输⽽制定的⼀种总线标准,该总线专责于⾳频设备之间的数据⼈,⼴泛应⽤于各种多媒体系统。
音视频基础知识及概念
音频技术基础—常见音频编码标准
• ITU-T Recommendation G.711 • ITU-T Recommendation G.722 / G.722.1 • ITU-T Recommendation G.723.1 & Annex A • ITU-T Recommendation G.728 & Annex G • ITU-T Recommendation G.729 & Annex A B • MP3(MPEG-1 audio layer 3) • AAC(Advanced Audio Coding,先进音频编码)
音频技术基础—波形编码方式
• ADPCM
– DPCM这种编译码器对幅度急剧变化的输入信 号会产生比较大的噪声,改进的方法之一就是 使用自适应的预测器和量化器,所谓自适应就 是指,量化位数随着幅度的变化而变化,这样 就产生了自适应差分脉冲编码调制(Adaptive Differential PCM,ADPCM)。
到了。
• 音调
• 音调是反映声音高低的,由声波的频率决定。频率高的声音 音调高,听起来尖细;频率低的声音音调低,听起来低沉。
• 对于不同的频段,人耳对音调的辨别能力不同,中频段最灵 敏,高、低频段较差。对于1KHz左右的声音,一般人可以
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
音频基本知识第一部分 模拟声音-数字声音原理第二部分 音频压缩编码第三部分 和弦铃声格式第四部分 单声道、立体声和环绕声第五部分 3D环绕声技术第六部分数字音频格式和数字音频接口第一部分 模拟声音-数字声音原理一、模拟声音数字化原理声音是通过空气传播的一种连续的波,叫声波。
声音的强弱体现在声波压力的大小上,音调的高低体现在声音的频率上。
声音用电表示时,声音信号在时间和幅度上都是连续的模拟信号。
图1 模拟声音数字化的过程声音进入计算机的第一步就是数字化,数字化实际上就是采样和量化。
连续时间的离散化通过采样来实现。
声音数字化需要回答两个问题:①每秒钟需要采集多少个声音样本,也就是采样频率(f s)是多少,②每个声音样本的位数(bit per sample,bps)应该是多少,也就是量化精度。
¾采样频率采样频率的高低是根据奈奎斯特理论(Nyquist theory)和声音信号本身的最高频率决定的。
奈奎斯特理论指出,采样频率不应低于声音信号最高频率的两倍,这样才能把以数字表达的声音还原成原来的声音。
采样的过程就是抽取某点的频率值,很显然,在一秒中内抽取的点越多,获取得频率信息更丰富,为了复原波形,一次振动中,必须有2个点的采样,人耳能够感觉到的最高频率为20kHz,因此要满足人耳的听觉要求,则需要至少每秒进行40k 次采样,用40kHz表达,这个40kHz就是采样率。
我们常见的CD,采样率为44.1kHz。
电话话音的信号频率约为3.4 kHz,采样频率就选为8 kHz。
¾量化精度光有频率信息是不够的,我们还必须纪录声音的幅度。
量化位数越高,能表示的幅度的等级数越多。
例如,每个声音样本用3bit表示,测得的声音样本值是在0~8的范围里。
我们常见的CD位16bit的采样精度,即音量等级有2的16次方个。
样本位数的大小影响到声音的质量,位数越多,声音的质量越高,而需要的存储空间也越多。
¾压缩编码经过采样、量化得到的PCM数据就是数字音频信号了,可直接在计算机中传输和存储。
但是这些数据的体积太庞大了!为了便于存储和传输,就需要进一步压缩,就出现了各种压缩算法,将PCM转换为MP3,AAC,WMA等格式。
常见的用于语音(Voice)的编码有:EVRC (Enhanced Variable Rate Coder) 增强型可变速率编码,AMR、ADPCM、G.723.1、G.729等。
常见的用于音频(Audio)的编码有:MP3、AAC、AAC+、WMA等二、问题1、为什么要使用音频压缩技术?我们可以拿一个未压缩的CD文件(PCM音频流)和一个MP3文件作一下对比:PCM音频:一个采样率为44.1KHz,采样大小为16bit,双声道的PCM编码CD文件,它的数据速率则为 44.1K×16×2 =1411.2 Kbps,这个参数也被称为数据带宽。
将码率除以8 bit,就可以得到这个CD的数据速率,即176.4KB/s。
这表示存储一秒钟PCM编码的音频信号,需要176.4KB的空间。
MP3音频:将这个WAV文件压缩成普通的MP3,44.1KHz,128Kbps的码率,它的数据速率为128Kbps/8=16KB/s。
如下表所示:比特率 存1秒音频数据所占空间CD(线性PCM) 1411.2 Kbps 176.4KBMP3 128Kbps 16KBAAC 96Kbps 12KBmp3PRO 64Kbps 8KB表1 相同音质下各种音乐大小对比2、频率与采样率的关系采样率表示了每秒对原始信号采样的次数,我们常见到的音频文件采样率多为44.1KHz,这意味着什么呢?假设我们有2段正弦波信号,分别为20Hz和20KHz,长度均为一秒钟,以对应我们能听到的最低频和最高频,分别对这两段信号进行40KHz的采样,我们可以得到一个什么样的结果呢?结果是:20Hz的信号每次振动被采样了40K/20=2000次,而20K的信号每次振动只有2次采样。
显然,在相同的采样率下,记录低频的信息远比高频的详细。
这也是为什么有些音响发烧友指责CD有数码声不够真实的原因,CD的44.1KHz采样也无法保证高频信号被较好记录。
要较好的记录高频信号,看来需要更高的采样率,于是有些朋友在捕捉CD音轨的时候使用48KHz的采样率,这是不可取的!这其实对音质没有任何好处,对抓轨软件来说,保持和CD提供的44.1KHz一样的采样率才是最佳音质的保证之一,而不是去提高它。
较高的采样率只有相对模拟信号的时候才有用,如果被采样的信号是数字的,请不要去尝试提高采样率。
3、流特征随着网络的发展,人们对在线收听音乐提出了要求,因此也要求音频文件能够一边读一边播放,而不需要把这个文件全部读出后然后回放,这样就可以做到不用下载就可以实现收听了。
也可以做到一边编码一边播放,正是这种特征,可以实现在线的直播,架设自己的数字广播电台成为了现实。
第二部分 音频压缩编码一.有损(lossy)/无损(lossless)/未压缩(uncompressed)音频格式未压缩音频是一种没经过任何压缩的简单音频。
未压缩音频通常用于影音文件的的PCM 或WAV音轨。
无损压缩音频是对未压缩音频进行没有任何信息/质量损失的压缩机制。
无损压缩音频一般不使用于影音世界,但是存在的格式有无损WMA或Matroska里的FLAC。
有损压缩音频尝试尽可能多得从原文件删除没有多大影响的数据,有目的地制成比原文件小多的但音质却基本一样。
有损压缩音频普遍流行于影音文件,包括AC3, DTS, AAC, MPEG-1/2/3, Vorbis, 和Real Audio.我们也来讨论下无损/有损压缩过程。
只要你转换成一种有损压缩音频格式(例如wav 转MP3),质量上有损失,那么它就是有损压缩。
从有损压缩音频格式转换成另一有损压缩音频格式(例如Mp3转AAC)更槽糕,因为它不仅会引入原文件存在的损失,而且第2次编码也会有损失。
二、语音(Voice)编码和音频(Audio)编码语音编码主要是针对语音通信系统中的编码方案,应用在有线或无线通信中;音频编码是针对音乐的编码方案,主要用来更方便地实现对音乐文件进行网络传输和存储。
两者的差别一方面是频带不同,另一方面是压缩要求不一样,音乐要求具有高保真度和立体感等要求。
音频编码最常见的是MPEG的音频编码。
语音的编码技术通常分为三类:波形编码、参量编码和混合编码。
其中,波形编码和参量编码是两种基本类型。
波形编码是将时间域信号直接变换为数字代码,力图使重建语音波形保持原语音信号的波形形状。
波形编码的基本原理是在时间轴上对模拟语音按一定的速率抽样,然后将幅度样本分层量化,并用代码表示。
解码是其反过程,将收到的数字序列经过解码和滤波恢复成模拟信号。
它具有适应能力强、语音质量好等优点,但所用的编码速率高,在对信号带宽要求不太严格的通信中得到应用,而对频率资源相对紧张的移动通信来说,这种编码方式显然不合适。
脉冲编码调制(PCM)和增量调制(△M),以及它们的各种改进型自适应增量调制(ADM),自适应差分编码(ADPCM)等,都属于波形编码技术。
它们分别在64以及16Kbit/s的速率上,能给出高的编码质量,当速率进一步下降时,其性能会下降较快。
参量编码又称为声源编码,是将信源信号在频率域或其它正交变换域提取特征参量,并将其变换成数字代码进行传输。
具体说,参量编码是通过对语音信号特征参数的提取和编码,力图使重建语音信号具有尽可能高的可靠性,即保持原语音的语意,但重建信号的波形同原语音信号的波形可能会有相当大的差别。
这种编码技术可实现低速率语音编码,比特率可压缩到2Kbit/s-4.8Kbit/s ,甚至更低,但语音质量只能达到中等,特别是自然度较低,连熟人都不一定能听出讲话人是谁。
线性预测编码(LPC )及其它各种改进型都属于参量编码。
混合编码将波形编码和参量编码组合起来,克服了原有波形编码和参量编码的弱点,结合各自的长处,力图保持波形编码的高质量和参量编码的低速率,在4-16Kbit/s速率上能够得到高质量的合成语音。
多脉冲激励线性预测编码(MPLPC ),规划脉冲激励线性预测编码(KPELPC),码本激励线性预测编码(CELP)等都是属于混合编码技术。
很显然,混合编码是适合于数字移动通信的语音编码技术。
三、无线通信中常见语音编码PHS为32kbit/s的ADPCM编码,GSM为13kbit/s的规则脉冲激励长期预测(RPE-LTP)编码,WCDMA使用的是自适应多速率编码(AMR),cdma2000使用的是可变速率编码(IS-773,IS-127)。
1、AMR编码(介绍它的原因是因为手机中有使用AMR铃声)。
在3G多媒体通信的发展过程中,音视频编码有了很大的发展。
1999年初,3GPP采纳了由爱立信、诺基亚、西门子提出的自适应多速率(AMR)标准作为第三代移动通信中语音编解码器的标准。
AMR声码器采用代数码本激励线性预测(ACELP:Algebraic Code Excited Linear Prediction)编码方式。
AMR标准针对不同的应用,分别提出了AMR-NB,AMR-WB和AMR-WB+三种不同的协议。
AMR-NB应用于窄带,而AMR-WB和AMR-WB+则应用于宽带通信中。
对于手机铃声,AMR-NB对应的铃声文件扩展名是.amr,AMR-WB对应铃声文件扩展名是.awb。
它们不是音乐,而是录音得到的原声。
2、ADPCM编码自适应差分脉码调制(ADPCM)是在差分脉码调制(DPCM)的基础上发展起来的。
DPCM根据信号的过去样值预测下一个样值,并将预测误差加以量化、编码,而后进行传输,由于预测误差的幅度变化范围小于原信号的幅度变化范围,因此在相同量化噪声条件下,DPCM的量化比特数小于PCM,从而达到语音压缩编码的目的。
ADPCM与DPCM比较,两者主要区别在于ADPCM中的量化器和预测器采用了自适应控制。
同时,在译码器中多了一个同步编码调整,其作用是为了在同步级连时不产生误差积累。
20世纪80年代以来,32kb/s的ADPCM技术已日趋成熟,并接近PCM的质量,但却节省一半的信道容量,因而受到重视。
1984年CCITT提出G721建议,采用动态锁定量化器,这是一种具有自适应速度控制32kb/s的自适应量化器,并将它作为国际标准化的语音编码方法。
1986年又对G721建议进行了修正,称G726建议。
ADPCM不适合作音乐的编码,常用于录音。
雅马哈的MMF铃声用到MIDI+PCM/ADPCM技术,其中PCM和ADPCM就是模拟音效,包括人声。
四、各种主流音频编码(或格式)的介绍1、PCM编码PCM(Pulse Code Modulation),即脉冲编码调制,指模拟音频信号只经过采样、模数转换直接形成的二进制序列,未经过任何编码和压缩处理。