小说采集器的详细使用方法
采集器说明书

ZD1000图书数据采集器说明书目录第一部分采集器的基本使用 (2)1.如何开关机? (2)2.关于充电 (2)3.外接U盘、鼠标、键盘 (2)4.如何在PDA和电脑之间拷贝文件 (3)5.如果使PDA一开机,就自动运行《PDA采集查重盘点系统》? (3)第二部分图解《PDA采集查重盘点系统》 (3)1.功能介面 (3)2.查重采集功能 (4)3.盘点功能 (6)4.休眠 (6)5.退出 (6)6.关于 (6)7.系统设置 (7)8.输入法 (7)第三部分外部软件的使用 (7)DB=》EXCEL、ACCESS (7)EXCEL、ACCESS==》DB (7)MARC文件(.ISO)==》DB (7)第一部分采集器的基本使用1.如何开关机?2.关于充电每次电池电力用完时,请及时充电。
充满需用时大约8小时(或充至PDA右下方的绿色电源指示灯不再闪烁)。
3.外接U盘、鼠标、键盘ZD1000型数据采集器的综合数据线提供了3个USB接口和1个串口,可以同时外接U盘、鼠标和键盘。
接上这些外设后,ZD1000型数据采集器就是一个微型的电脑了,可以使用外接的鼠标来执行移动指针、选择、点击等操作,也可以使用外接的键盘进行打字输入,接入U盘后,在PDA“我的设备”里多了一个“硬盘”。
说明:PDA 内部的盘和外接的盘(U盘)同属闪存盘,保存在这些盘内的数据,不会因为没电而消失。
外接U盘后,在“我的设备”里多了一个“硬盘”图标。
电源指示灯。
4.如何在PDA和电脑之间拷贝文件“复制、粘贴”的操作与普通电脑上的操作是一样的(即在PDA 中选择需复制的文件或文件夹,执行“复制”,然后进入需复制到的目录,执行“粘贴”。
)。
使用外接U盘,可以方便地实现PDA和电脑之间拷贝文件。
5.如果使PDA一开机,就自动运行《PDA采集查重盘点系统》?初次运行《PDA采集查重盘点系统》程序,会自动设置为一开机就自动运行《PDA采集查重盘点系统》。
微信文章采集器使用方法详解
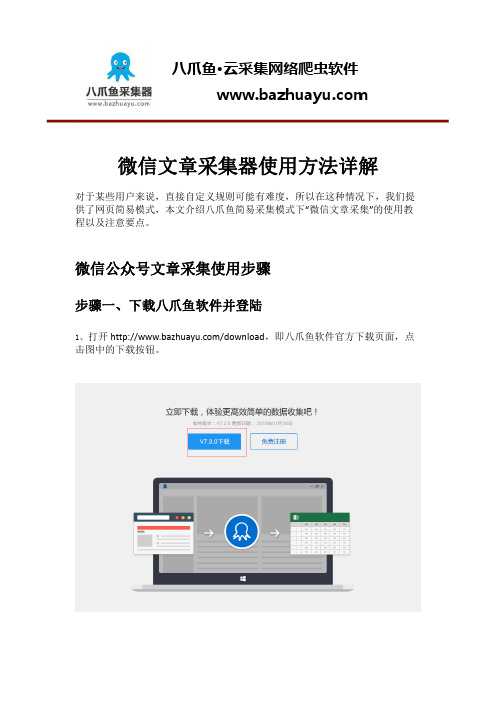
微信文章采集器使用方法详解对于某些用户来说,直接自定义规则可能有难度,所以在这种情况下,我们提供了网页简易模式,本文介绍八爪鱼简易采集模式下“微信文章采集”的使用教程以及注意要点。
微信公众号文章采集使用步骤步骤一、下载八爪鱼软件并登陆1、打开/download,即八爪鱼软件官方下载页面,点击图中的下载按钮。
2、软件下载好了之后,双击安装,安装完毕之后打开软件,输入八爪鱼用户名密码,然后点击登陆步骤二、设置微信文章爬虫规则任务1、进入登陆界面之后就可以看到主页上的网站简易采集了,选择立即使用即可。
2、进去之后便可以看到目前网页简易模式里面内置的所有主流网站了,需要采集微信公众号内容的,这里选择搜狗即可。
3、找到搜狗公众号这条爬虫规则,点击即可使用。
4、搜狗公众号简易采集模式任务界面介绍查看详情:点开可以看到示例网址任务名:自定义任务名,默认为搜狗公众号任务组:给任务划分一个保存任务的组,如果不设置会有一个默认组公众号URL列表填写注意事项:提供要采集的网页网址,即搜狗微信中相关公众号的链接。
多个公众号输入多个网址即可。
采集数目:输入希望采集的数据条数示例数据:这个规则采集的所有字段信息。
5、微信文章爬虫规则设置示例例如要采集相关旅游、美食的公众号文章在设置里如下图所示:任务名:自定义任务名,也可以不设置按照默认的就行任务组:自定义任务组,也可以不设置按照默认的就行商品评论URL列表:/weixin?type=1&s_from=input&query=电影&ie=utf8&_sug_=n&_sug_type_=/weixin?type=1&s_from=input&query=美食&ie=utf8&_sug_=n&_sug_type_=一行一个,使用回车(Enter)进行换行。
采集数目:可根据自身需求选填(当前默认)注意事项:URL列表中建议不超过2万条步骤三、保存并运行微信文章爬虫规则1、设置好爬虫规则之后点击保存。
小猪采集器教程

1、打开小猪采集器,点击任务切换到“我的任务”,鼠标移动
到分组,右键击出菜单栏,选择新建任务。如图:
2、选择转载任务 在新建任务界面选择转载任务,点击下一步,如图:
二、任务配置Leabharlann 任务配置界面如图:1、填写任务名
可以随意填写,最好和任务相关。如图:
2、增加采集源 点击采集源下边增加,如下图。弹出增加采集源界面,在 输入框输入要采集的网址,一行一个;也可以导入已经编辑在 txt文档里面的网址,txt文档里的网址也必须是一行一个的格 式。如图(第二张图见下页):
4、增加发布源
点击转发到下边的“增加”,如图,会弹出增加发布网址 界面,这里有两个选项可供选择:
如果你已经在发布标签下添加了网址或者采集到本地文件 或者直接发布到数据库就点击选择本地,下面根据自己的类型 选择,如图:
如果你添加的是网址,就点击添加网址,会切换到添加 网址界面, 如图:
5、给发布网站配置网站信息 操作方法是鼠标移动到已经添加了的网址列表,点击右键, 这里需要用户注意的是,在不同的标签下右键会有不同的效果。 在编号和规则下面右键会击出一个菜单,在版块/标题下面右键 会预览当前网址,在地址下右键会打开这个网址,在账号/设置 和登录下右键会打开网站个性设置界面,配置账户就是在网站 个性设置里面配置的,如图:
3、给采集地址配置网站信息
如果采集的网址不是论坛类或者不需要登录、回复的用户请忽略此步骤。 操作方法是鼠标移动到已经添加了的网址列表,点击右键,这里需要用户注意 的是,在不同的标签下右键会有不同的效果。在编号和规则下面点击右键弹出一个 菜单,在版块/标题下面右键会预览当前网址,在地址下右键会打开这个网址,在 账号/设置和登录下右键会打开网站个性设置界面,配置账户就是在网站个性设置 里面配置的,如图:
文章采集软件使用方法
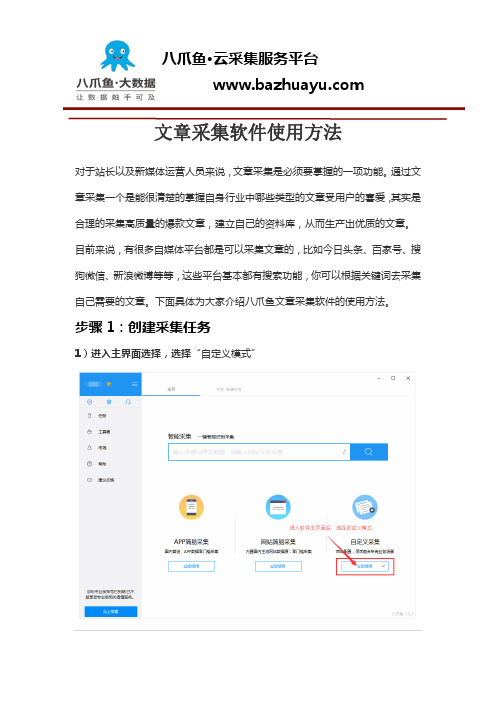
对于站长以及新媒体运营人员来说,文章采集是必须要掌握的一项功能。
通过文章采集一个是能很清楚的掌握自身行业中哪些类型的文章受用户的喜爱,其实是合理的采集高质量的爆款文章,建立自己的资料库,从而生产出优质的文章。
目前来说,有很多自媒体平台都是可以采集文章的,比如今日头条、百家号、搜狗微信、新浪微博等等,这些平台基本都有搜索功能,你可以根据关键词去采集自己需要的文章。
下面具体为大家介绍八爪鱼文章采集软件的使用方法。
步骤1:创建采集任务1)进入主界面选择,选择“自定义模式”文章采集软件使用步骤12)将上面网址的网址复制粘贴到网站输入框中,点击“保存网址”文章采集软件使用步骤23)保存网址后,页面将在八爪鱼采集器中打开,红色方框中的信息是这次演示要采集的内容,即为今日头条最新发布的热点新闻。
文章采集软件使用步骤3步骤2:设置ajax页面加载时间●设置打开网页步骤的ajax滚动加载时间●找到翻页按钮,设置翻页循环●设置翻页步骤ajax下拉加载时间1)网页打开后,需要进行以下设置:打开流程图,点击“打开网页”步骤,在右侧的高级选项框中,勾选“页面加载完成向下滚动”,设置滚动次数,每次滚动间隔时间,一般设置2秒,这个页面的滚动方式,选择直接滚动到底部;最后点击确定文章采集软件使用步骤4注意:今日头条的网站属于瀑布流网站,没有翻页按钮,这里的滚动次数设置将影响采集的数据量。
文章采集软件使用步骤5步骤3:采集新闻内容创建数据提取列表1)如图,移动鼠标选中评论列表的方框,右键点击,方框底色会变成绿色 然后点击“选中子元素”文章采集软件使用步骤6注意:点击右上角的“流程”按钮,即可展现出可视化流程图。
2)然后点击“选中全部”,将页面中需要需要采集的信息添加到列表中文章采集软件使用步骤7注意:在提示框中的字段上会出现一个“X”标识,点击即可删除该字段。
文章采集软件使用步骤83)点击“采集以下数据”文章采集软件使用步骤9 4)修改采集字段名称,点击下方红色方框中的“保存并开始采集”文章采集软件使用步骤10步骤4:数据采集及导出1)根据采集的情况选择合适的采集方式,这里选择“启动本地采集”文章采集软件使用步骤11说明:本地采集占用当前电脑资源进行采集,如果存在采集时间要求或当前电脑无法长时间进行采集可以使用云采集功能,云采集在网络中进行采集,无需当前电脑支持,电脑可以关机,可以设置多个云节点分摊任务,10个节点相当于10台电脑分配任务帮你采集,速度降低为原来的十分之一;采集到的数据可以在云上保存三个月,可以随时进行导出操作。
网络文字抓取工具使用方法

网络文字抓取工具使用方法网页文字是网页中常见的一种内容,有些朋友在浏览网页的时候,可能会有批量采集网页内容的需求,比如你在浏览今日头条文章的时候,看到了某个栏目有很多高质量的文章,想批量采集下来,下面本文以采集今日头条为例,介绍网络文字抓取工具的使用方法。
采集网站:使用功能点:●Ajax滚动加载设置●列表内容提取步骤1:创建采集任务 1)进入主界面选择,选择“自定义模式”今日头条网络文字抓取工具使用步骤12)将上面网址的网址复制粘贴到网站输入框中,点击“保存网址”今日头条网络文字抓取工具使用步骤23)保存网址后,页面将在八爪鱼采集器中打开,红色方框中的信息是这次演示要采集的内容,即为今日头条最新发布的热点新闻。
今日头条网络文字抓取工具使用步骤3步骤2:设置ajax页面加载时间●设置打开网页步骤的ajax滚动加载时间●找到翻页按钮,设置翻页循环●设置翻页步骤ajax下拉加载时间1)网页打开后,需要进行以下设置:打开流程图,点击“打开网页”步骤,在右侧的高级选项框中,勾选“页面加载完成向下滚动”,设置滚动次数,每次滚动间隔时间,一般设置2秒,这个页面的滚动方式,选择直接滚动到底部;最后点击确定今日头条网络文字抓取工具使用步骤4注意:今日头条的网站属于瀑布流网站,没有翻页按钮,这里的滚动次数设置将影响采集的数据量。
今日头条网络文字抓取工具使用步骤5步骤3:采集新闻内容创建数据提取列表1)如图,移动鼠标选中评论列表的方框,右键点击,方框底色会变成绿色然后点击“选中子元素”今日头条网络文字抓取工具使用步骤6注意:点击右上角的“流程”按钮,即可展现出可视化流程图。
2)然后点击“选中全部”,将页面中需要需要采集的信息添加到列表中今日头条网络文字抓取工具使用步骤7注意:在提示框中的字段上会出现一个“X”标识,点击即可删除该字段。
今日头条网络文字抓取工具使用步骤8 3)点击“采集以下数据”今日头条网络文字抓取工具使用步骤94)修改采集字段名称,点击下方红色方框中的“保存并开始采集”今日头条网络文字抓取工具使用步骤10步骤4:数据采集及导出1)根据采集的情况选择合适的采集方式,这里选择“启动本地采集”今日头条网络文字抓取工具使用步骤11说明:本地采集占用当前电脑资源进行采集,如果存在采集时间要求或当前电脑无法长时间进行采集可以使用云采集功能,云采集在网络中进行采集,无需当前电脑支持,电脑可以关机,可以设置多个云节点分摊任务,10个节点相当于10台电脑分配任务帮你采集,速度降低为原来的十分之一;采集到的数据可以在云上保存三个月,可以随时进行导出操作。
采集器软件使用
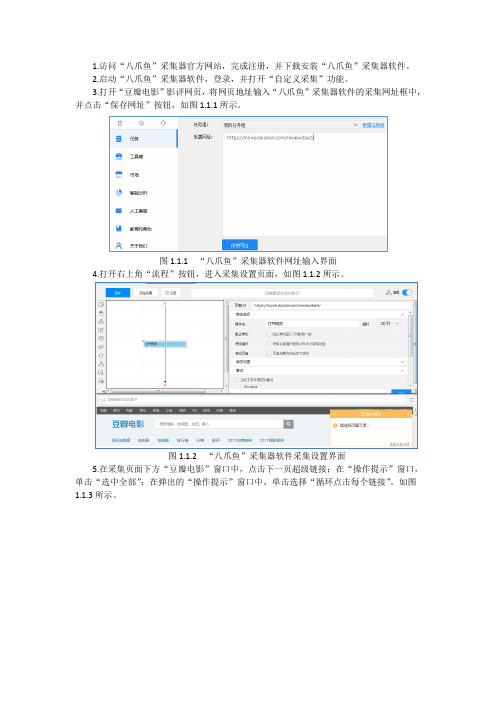
1.访问“八爪鱼”采集器官方网站,完成注册,并下载安装“八爪鱼”采集器软件。
2.启动“八爪鱼”采集器软件,登录,并打开“自定义采集”功能。
3.打开“豆瓣电影”影评网页,将网页地址输入“八爪鱼”采集器软件的采集网址框中,并点击“保存网址”按钮,如图1.1.1所示。
图1.1.1 “八爪鱼”采集器软件网址输入界面4.打开右上角“流程”按钮,进入采集设置页面,如图1.1.2所示。
图1.1.2 “八爪鱼”采集器软件采集设置界面5.在采集页面下方“豆瓣电影”窗口中,点击下一页超级链接;在“操作提示”窗口,单击“选中全部”;在弹出的“操作提示”窗口中,单击选择“循环点击每个链接”。
如图1.1.3所示。
图1.1.3 “八爪鱼”采集器软件操作提示选择界面6.选择页面元素。
点击影评用户名,在“操作提示”窗口,单击“选中全部”;在一次弹出的“操作提示”窗口中,单击选择“采集以下链接文本”。
此时,配置抓取模板中添加了提取的数据样式,如图1.1.4所示。
图1.1.4 “八爪鱼”采集器软件数据样式呈现界面7.重复上一步骤操作,把电影名、影评内容添加到“配置抓取模板”中。
并在“配置抓取模板”中单击字段名称,更改字段名称。
然后,单击“操作提示”窗口中“保存并开始采集”,如图1.1.5所示。
图1.1.5 “八爪鱼”采集器软件配置抓取模板8.在“运行任务”窗口选择“启动本地采集”,开始数据采集,如图1.1.6所示。
图1.1.6 “八爪鱼”采集器软件运行任务界面9.在“提取到的数据”窗口,选择“导出数据”按钮;然后选择需要的导出方式,完成数据的收集与保存,如图1.1.7所示。
图1.1.7 “八爪鱼”采集器软件导出方式选择界面。
关关采集器规则编写教程(最详细的教程)

<dt>
<strong>遮天正文
</strong>
</dt>
单一代码为 <dt>
<strong> 修改正则 为<dt>\s*<strong>
其中的\s* 表示 匹配 与任何白字符匹配,包括空格、制表符、分页符等 也就是说 在 </ul> 与<dt><strong> 之间 不管有多少个空格 都可以用 \s* 来表示
/bookreader/{NovelKey}-{ChapterKey}.html
注:这种写法 PubChapter_GetChapterKey里必需是获得章节编号的如“<li><strong><a href="/book/\d*-(\d*).html">.+?</a></strong></li>”
《<a href="/book/1258.html" id="htmltimu" title="遮天">遮天</a>》 改成 《<a href="/book/\d*.html" id="htmltimu" title=".+?">(.+?)</a>》
NovelAuthor(获得小说作者)、LagerSort(获得小说大类)、SmallSort(获得小说大类)、NovelIntro(获得小说简介)、NovelKeyword(获得小说主角(关键字))、NovelDegree(获得写作进程)、NovelCover(获得小说封面) 这些同 10.一样获取即可
小说网站利用关关采集器编写采集规则教程

小说网站编写教程,详细交大家如何编写关关规则首先介绍一下关关采规则当中需要用到的一些标签d*表示数字 s*表示空格+换行 .+?表示字符(不能为空) .* 表示字符(可以为空)() 表示我们需要的部分 ((.| )*)章节的内容部分,包括了换行。
=====与杰奇后台标签的对应关系===== 相当于 ([^><]*)~~~~ 相当于 ([^><'"]*)^^^^ 相当于 ([^>第一步:我们先复制一份原来的规则做模板(规则文件存放在Rules目录下)。
比如说我今天演示的采集站点是笔仙屋() 这个小说站点那么我就把我复制的那份做模板的规则命名为:笔仙屋.xml这个主要是便于规则的管理。
第二步:运行采集器里的规则管理工具,打开后载入刚刚我们命名为笔仙屋.xml的文件。
第三步:现在可以正式的编写规则了,我们写规则时要找的标志性代码必需是整个页面里唯一的代码,其次我们取用的部份代码越精简越好。
1. GetSiteName(站点名称)这里我们写笔仙屋(在执行任务时会在上方显示)2. GetSiteCharset(站点编码)这里我们打开源代码查找charset=得到charset=gbk这个gbk就是我们需要的站点编码3. GetSiteUrl(站点地址)写入4. NovelListUrl(站点最新列表地址)因为这些每个站点的不同,这个就需要自己去找了. NovelList_GetNovelKey(从最新列表中获得小说编号)此规则中需要同时获得书名,获得书名是在手动模式的时候用到,如果你要用手动模式那么必须获得书名,否则手动模式将会无法使用。
我们打开地址查看源文件,我们编写这个规则的时候找到想要获得的内容所在的地方,比如我们打开地址看到想要获得的内容的第一本小说的名字是“赘婿”我们在源文件里面找到“赘婿”复制代码我们编写规则用到的代码其实也不是很多,编写规则的原则是能省则省,也就是说代码越短越好除非万不得已一般精短一些比较好。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
小说采集器的详细使用方法本文介绍使用八爪鱼采集器采集小说(以起点小说为例)方法。
采集网站:https:///info/53269
使用功能点:
分页列表及详细信息提取
/tutorial/fylbxq7.aspx?t=1
步骤1:创建采集任务
1)进入主界面,选择“自定义模式”
小说采集器的详细使用步骤1
2)将要采集的网址复制粘贴到网站输入框中,点击“保存网址”
小说采集器的详细使用步骤2
步骤2:创建列表循环
1)在页面右上角,打开“流程”,以展现出“流程设计器”和“定制当前操作”两个板块。
选中页面里的第一条链接,系统会自动识别页面内的同类链接,选择“选中全部”
小说采集器的详细使用步骤3 2)选择“循环点击每个链接”
小说采集器的详细使用步骤4
步骤3:采集小说内容
1)选中页面内要采集的小说内容(被选中的内容会变成绿色),选择“采集该元素的文本”
小说采集器的详细使用步骤5 2)修改字段名称
小说采集器的详细使用步骤6 3)选择“启动本地采集”
小说采集器的详细使用步骤7
步骤4:数据采集及导出
1)采集完成后,会跳出提示,选择“导出数据。
选择“合适的导出方式”,将采集好的评论信息数据导出
小说采集器的详细使用步骤8
2)这里我们选择excel作为导出为格式,数据导出后如下图,这个时候小说就完全的采集下来了。
小说采集器的详细使用步骤9 相关采集教程:
新浪微博数据采集
豆瓣电影短评采集
搜狗微信文章采集。