聚类分析SPSS操作
SPSS聚类分析加具体案例
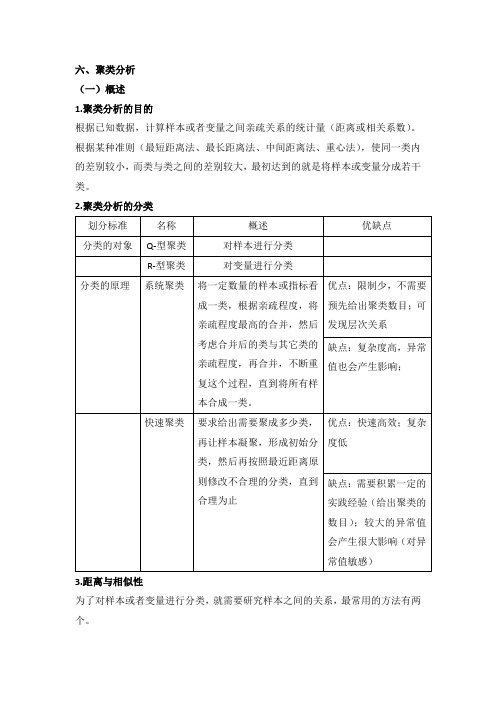
六、聚类分析(一)概述1.聚类分析的目的根据已知数据,计算样本或者变量之间亲疏关系的统计量(距离或相关系数)。
根据某种准则(最短距离法、最长距离法、中间距离法、重心法),使同一类内的差别较小,而类与类之间的差别较大,最初达到的就是将样本或变量分成若干类。
2.聚类分析的分类3.距离与相似性为了对样本或者变量进行分类,就需要研究样本之间的关系,最常用的方法有两个。
(二)系统聚类1.系统聚类的步骤距离的具体定义及计算方式计算n各样本两两之间的距离将距离接近的数据依次合并为一类,再计算,再合并 画聚类图,解释类与类之间的关系2.亲疏程度度量方法3.系统聚类的分类4.SPSS操作及实例SPSS采用的是凝聚法。
案例:根据30个省的23个主要行业的平均工资情况,通过聚类分析来判断哪些地区平均工资水平高。
SPSS操作及结果:打开SPSS上方菜单栏中的分析->分类->系统聚类选择变量->勾选统计量->在绘制里选择树状图和冰柱图勾选方法(通常使用组间联接)->度量区间->选择标准化方式(全距从0到1)下图为近似矩阵表,标注了相关系数,数值越大,距离越接近下图为聚类分析结果表,第一类表示这是聚类分析的第几步,第二三列表示该步中那几个样本或者小类聚成一类,第四列表示距离,第五六列表示本步骤中参与的是个体还是小类(0表示样本,非0表示第n步生成的小类),第七列表示本步骤的聚类结果将在以下第几步中用到。
下面是冰柱图和树状图的结果,根据树状图可以看出,如果分为三类的话,第一类包括北京上海,第二类包括天津、广东、浙江、江苏、西藏,剩下的归为一类。
(三)快速聚类(适合大样本聚类)1.快速聚类的步骤指定聚类数目K确定K个初始类的中心(自定义或者根据数据中心初步确定)根据距离最近的原则进行分类根据新的中心位置,重新计算每一记录距离新的类别中心的的距离,并重新分类重复步骤4,直到达到标准2.SPSS操作及实例打开SPSS上方菜单栏中的分析->分类->K-均值聚类选择变量->勾选统计量->定义变量值选择迭代次数->选项(勾选初始聚类中心、每个个案的聚类信息)->定义变量值->保存(勾选聚类成员、聚类中心距离)下图为输出的初始聚类中心下图为最终距离中心,第一类平均工资最高,第二类次之,第三类最低下图为每个聚类中的案例数和聚类成员。
SPSS聚类分析具体操作步骤spss如何聚类

算法步骤:初始 化聚类中心、分 配数据点到最近 的聚类中心、重 新计算聚类中心、 迭代直到聚类中 心不再变化
适用场景:探索 性数据分析、市 场细分、异常值 检测等
注意事项:选择 合适的聚类数目、 处理空值和异常 值、考虑数据的 尺度问题
定义:根据数据点间的距离或相似性,将数据点分为多个类别的过程 常用方法:层次聚类、K-均值聚类、DBSCAN聚类等 适用场景:适用于探索性数据分析,发现数据中的模式和结构 注意事项:选择合适的距离度量方法、确定合适的类别数目等
常见的聚类分析方法包括层次聚类、Kmeans聚类、DBSCAN聚类等。
聚类分析基于数据的相似性或距离度量, 将相似的数据点归为一类,使得同一类 中的数据点尽可能相似,不同类之间的 数据点尽可能不同。
聚类分析广泛应用于数据挖掘、市场细分、 模式识别等领域。
K-means聚类:将数据划分为K个簇,使得每个数据点到所在簇中心的距离之和最小
聚类结果的可视化:通过图表展示聚类结果 聚类质量的评估:使用适当的指标评估聚类效果的好坏 聚类结果的解释:根据实际需求和背景知识,对聚类结果进行合理的解释和解读 聚类结果的应用:探讨聚类结果在各个领域的应用场景和价值
SPSS聚类分析常 用方法
定义:将数据集 划分为K个聚类, 使得每个数据点 属于最近的聚类 中心
聚类结果展示:通过图表或表格展示聚类结果,包括各类别的样本数和占比
聚类质量评估:采用适当的指标评估聚类效果,如轮廓系数、Davies-Bouldin指数等
聚类结果解读:根据业务背景和数据特征,解释各类别的含义和特征 聚类结果应用:说明聚类分析在具体场景中的应用,如市场细分、客户分类等
SPSS聚类分析注 意事项
确定聚类变量:选 择与聚类目标相关 的变量,确保变量 间无高度相关性。
spss聚类分析案例

spss聚类分析案例在进行SPSS聚类分析时,我们通常会遵循一系列步骤来确保分析的准确性和有效性。
以下是一个典型的聚类分析案例,展示了如何使用SPSS软件进行数据分析。
首先,我们需要收集数据。
数据可以是定量的,也可以是定性的,但必须与研究问题相关。
例如,如果我们正在研究消费者购买行为,我们可能会收集关于消费者年龄、收入、购买频率和偏好的数据。
接下来,我们将数据导入SPSS。
这可以通过直接输入数据、从Excel文件导入或使用SPSS的数据导入向导来完成。
一旦数据在SPSS中,我们需要检查数据的准确性和完整性,确保没有缺失值或异常值。
在进行聚类分析之前,我们通常需要对数据进行预处理。
这可能包括标准化变量、处理缺失值和异常值,以及可能的变量转换。
标准化是重要的,因为它确保了所有变量在聚类分析中具有相同的权重。
然后,我们选择聚类方法。
SPSS提供了几种聚类方法,包括K-means聚类、层次聚类和双向聚类。
选择哪种方法取决于数据的特性和研究目的。
例如,如果我们有明确的类别数量,K-means聚类可能是合适的;如果我们希望看到数据的层次结构,层次聚类可能更合适。
在选择了聚类方法后,我们需要确定聚类的数量。
这可以通过多种方法来确定,包括肘部方法、轮廓系数或基于信息准则的方法。
确定聚类数量后,我们可以运行聚类算法,并将数据点分配到不同的聚类中。
聚类完成后,我们需要评估聚类的质量。
这可以通过查看聚类的内部一致性和聚类之间的差异来完成。
我们还可以进行统计测试,如ANOVA或卡方检验,来检验聚类是否在统计上显著。
最后,我们解释聚类结果。
这包括识别每个聚类的特征,以及这些特征如何与研究问题相关。
例如,如果我们发现一个聚类主要由高收入、频繁购买的消费者组成,这可能表明这是一个高价值的市场细分。
在整个聚类分析过程中,我们可能会进行多次迭代,调整聚类方法、聚类数量或数据预处理步骤,以获得最佳的聚类结果。
聚类分析是一个动态的过程,需要根据数据和研究目的进行调整。
SPSS聚类分析实验报告

SPSS聚类分析实验报告一、实验目的本实验旨在通过SPSS软件对样本数据进行聚类分析,找出样本数据中的相似性,并将样本划分为不同的群体。
二、实验步骤1.数据准备:在SPSS软件中导入样本数据,并对数据进行处理,包括数据清洗、异常值处理等。
2.聚类分析设置:在SPSS软件中选择聚类分析方法,并设置分析参数,如距离度量方法、聚类方法、群体数量等。
3.聚类分析结果:根据分析结果,对样本数据进行聚类,并生成聚类结果。
4.结果解释:分析聚类结果,确定每个群体的特征,观察不同群体之间的差异性。
三、实验数据本实验使用了一个包含1000个样本的数据集,每个样本包含了5个变量,分别为年龄、性别、收入、教育水平和消费偏好。
下表展示了部分样本数据:样本编号,年龄,性别,收入,教育水平,消费偏好---------,------,------,------,---------,---------1,30,男,5000,大专,电子产品2,25,女,3000,本科,服装鞋包3,35,男,7000,硕士,食品饮料...,...,...,...,...,...四、实验结果1. 聚类分析设置:在SPSS软件中,我们选择了K-means聚类方法,并设置群体数量为3,距离度量方法为欧氏距离。
2.聚类结果:经过聚类分析后,我们将样本分为了3个群体,分别为群体1、群体2和群体3、每个群体的特征如下:-群体1:年龄偏年轻,女性居多,收入较低,教育水平集中在本科,消费偏好为服装鞋包。
-群体2:年龄跨度较大,男女比例均衡,收入中等,教育水平较高,消费偏好为电子产品。
-群体3:年龄偏高,男性居多,收入较高,教育水平较高,消费偏好为食品饮料。
3.结果解释:根据聚类结果,我们可以看到不同群体之间的差异性较大,每个群体都有明显的特征。
这些结果可以帮助企业更好地了解不同群体的消费习惯,为市场营销活动提供参考。
五、实验结论通过本次实验,我们成功地对样本数据进行了聚类分析,并得出了3个不同的群体。
spss聚类分析步骤

spss聚类分析步骤什么是聚类分析聚类分析是一种通过将相似的样本数据进行分组的方法,以便于研究者可以更好地理解数据中的模式和结构。
在聚类分析中,研究者希望将数据样本划分为若干个互不重叠的群体,每个群体内的样本相似度较高,而不同群体之间的样本相似度较低。
spss的聚类分析功能spss是一种功能强大的统计分析软件,它提供了丰富的数据分析功能。
在spss中,可以使用聚类分析功能来进行数据样本的分组和分类。
聚类分析功能可以帮助研究者发现数据中的模式、规律和群体。
使用spss的聚类分析功能,可以根据变量之间的相似性将样本分成若干个组,从而更好地理解数据。
spss聚类分析步骤以下是使用spss进行聚类分析的基本步骤:1.打开数据文件:首先,需要打开包含要进行聚类分析的数据的spss数据文件。
可以通过点击菜单栏的“文件”选项打开数据文件,或者通过键盘快捷键“Ctrl + O”。
2.转换变量类型:在进行聚类分析之前,需要将数据中的所有变量转换为合适的类型。
例如,如果有一些分类变量,需要将其转换为因子变量。
可以通过点击菜单栏的“数据”选项,然后选择“转换变量类型”来进行变量类型的转换。
3.选择变量:在进行聚类分析之前,需要确定要使用的变量。
可以选择所有的变量,也可以只选择特定的变量。
选择变量可以通过点击菜单栏的“数据”选项,然后选择“选择变量”来进行。
4.进行聚类分析:选择好变量之后,可以进行聚类分析。
可以通过点击菜单栏的“分析”选项,然后选择“聚类”来进行聚类分析。
5.配置聚类分析参数:在进行聚类分析之前,需要配置一些参数。
例如,确定要使用的聚类方法和相似性测度。
可以根据具体的研究目的和数据特点来选择合适的参数。
6.运行聚类分析:配置好参数之后,可以点击“确定”按钮来运行聚类分析。
spss会根据选择的变量和参数,对样本数据进行聚类,并生成相应的结果。
7.分析聚类结果:在进行聚类分析之后,可以对聚类结果进行进一步的分析。
SPSS软件聚类分析过程的图文解释及结果的全面分析

SPSS聚类分析过程聚类的主要过程一般可分为如下四个步骤:1.数据预处理(标准化)2.构造关系矩阵(亲疏关系的描述)3.聚类(根据不同方法进行分类)4.确定最佳分类(类别数)SPSS软件聚类步骤1. 数据预处理(标准化)→Analyze →Classify →Hierachical Cluster Analysis →Method 然后从对话框中进行如下选择从Transform Values框中点击向下箭头,此为标准化方法,将出现如下可选项,从中选一即可:标准化方法解释:None:不进行标准化,这是系统默认值;Z Scores:标准化变换;Range –1 to 1:极差标准化变换(作用:变换后的数据均值为0,极差为1,且|x ij*|<1,消去了量纲的影响;在以后的分析计算中可以减少误差的产生。
);Range 0 to 1(极差正规化变换/ 规格化变换);2. 构造关系矩阵在SPSS中如何选择测度(相似性统计量):→Analyze →Classify →Hierachical Cluster Analysis →Method 然后从对话框中进行如下选择常用测度(选项说明):Euclidean distance:欧氏距离(二阶Minkowski距离),用途:聚类分析中用得最广泛的距离;Squared Eucidean distance:平方欧氏距离;Cosine:夹角余弦(相似性测度;Pearson correlation:皮尔逊相关系数;3. 选择聚类方法SPSS中如何选择系统聚类法常用系统聚类方法a)Between-groups linkage 组间平均距离连接法方法简述:合并两类的结果使所有的两两项对之间的平均距离最小。
(项对的两成员分属不同类)特点:非最大距离,也非最小距离b)Within-groups linkage 组内平均连接法方法简述:两类合并为一类后,合并后的类中所有项之间的平均距离最小C)Nearest neighbor 最近邻法(最短距离法)方法简述:用两类之间最远点的距离代表两类之间的距离,也称之为完全连接法d)Furthest neighbor 最远邻法(最长距离法)方法简述:用两类之间最远点的距离代表两类之间的距离,也称之为完全连接法e)Centroid clustering 重心聚类法方法简述:两类间的距离定义为两类重心之间的距离,对样品分类而言,每一类中心就是属于该类样品的均值特点:该距离随聚类地进行不断缩小。
spss聚类分析PPT课件

G7
G3
G4
G8
G7
0
G3
3
0
G4
5
2
0
G8
7
4
2
0
30
10/16/2024
(3)在D(1)中最小值是D34=D48=2,由于G4与G3合并, 又与G8合并,因此G3、G4、G8合并成一个新类G9,其与其 它类的距离D(2)
G7
G9
G7
0
G9
3
0
31
10/16/2024
(4)最后将G7和G9合并成G10,这时所有的六个样品聚为一 类,其过程终止。 上述聚类的可视化过程如下:
1
2
3
4
5
1
0
8.062 17.804 26.907 30.414
2
8.062 0
25.456 34.655 38.21
3
17.804 25.456 0
9.22 12.806
4
26.907 34.655 9.22 0
3.606
5
30.414 38.21 12.806 3.606 0
26
10/16/2024
系统聚类过程是:假设总共有n个样品(或变量)
第一步:将每个样品(或变量)独自聚成一类,共有 n类;
第二步:根据所确定的样品(或变量)“距离”公式, 把距离较近的两个样品(或变量)聚合为一类,其 它的样品(或变量)仍各自聚为一类,共聚成n 1 类;
第三步:将“距离”最近的两个类进一步聚成一类, 共聚成n 2类;……,以上步骤一直进行下去,最后17 将所有的样品(或变量)全聚成一类。
(1)选择样品距离公式,绝对距离最简单,形成D(0)
SPSS19.0之聚类分析

1.1 系统聚类本次实验的系统聚类都是凝聚系统聚类,为了控制变量,都采用平方Euclidean距离。
1.1.1 最短距离聚类法最短距离法聚类步骤如下:1.规定样本间的距离,计算样本两两之间的距离,得到对称矩阵。
开始每个样品自成一类。
2.选择对称矩阵中的最小非零元素。
将两个样品之间最小距离记为D1,将这两个样品归并成为一类,记为G1。
3.计算G1与其他样品距离。
重复以上过程直到所有样品合并为一类。
我们在SPSS中实现最短距离分析非常简单。
单击“”-->“”-->“”。
将弹出如图1-1所示的对话框,设置相应的参数即可。
图1-1 最短距离法我们的数据已经做过标准化,在“转化值”-->“标准化”选项上选无。
在统计量的聚类成员中选择“无”,因为这是非监督分类,不需要指定最终分出的类个数。
在绘制中选择绘制“树状图”。
单击确定,得到以下结果。
聚类表阶群集组合系数首次出现阶群集下一阶群集1 群集 2 群集 1 群集 21 21 28 .211 0 0 102 12 24 .465 0 0 63 2 27 .491 0 0 54 13 20 .585 0 0 95 2 14 .645 3 0 66 2 12 .678 5 2 77 2 7 .702 6 0 88 2 25 .773 7 0 99 2 13 .916 8 4 1110 21 29 1.085 1 0 1211 2 18 1.106 9 0 12表1-2 聚类过程我们可以通过更加形象直观的树状图来观察整个聚类过程和聚类效果。
如图1-2所示,最短距离法组内距离小,但组间距离也较小。
分类特征不够明显,无法凸显各个省份的能源消耗的特点。
但是我们可以看到广东省能源消耗组成和其他省份特别不同,在其他方法中也显现出来。
12 2 21 1.115 11 10 13 13 2 17 1.360 12 0 14 14 2 26 1.564 13 0 15 15 2 22 1.627 14 0 16 16 2 5 1.649 15 0 17 17 2 8 1.877 16 0 18 18 2 16 3.027 17 0 19 19 2 30 3.543 18 0 20 20 2 11 4.930 19 0 21 21 2 4 5.024 20 0 22 22 2 10 6.445 21 0 24 23 1 9 8.262 0 0 26 24 2 15 10.093 22 0 25 25 2 23 10.096 24 0 26 26 1 2 10.189 23 25 27 27 1 6 11.387 26 0 28 28 1 3 13.153 27 0 29 2911932.36728图1-2 最短距离法聚类图1.1.2 组间联接聚类组间联接聚类法定义为两类之间的平均平方距离,即。