阵列处理机
自考《计算机系统结构》问答题总结(6)

第六章 1、试分析阵列处理机特点 (1)阵列处理机提⾼速度是利⽤资源重复,利⽤并⾏性中的同时性; (2)处理单元同等地担负起各种运算,其设备利⽤率可能不那么⾼; (3)速度提⾼在硬件价格⼤幅度下降情况下,潜⼒巨⼤; (4)互连络对系统性能影响显著; (5)互连络使阵列处理机⽐固定结构的单功能流⽔线灵活; (6)阵列处理机结构和所采⽤并⾏算法紧密联系; (7)阵列处理机还必须提⾼标量处理速度。
总之,阵列处理机实质上是专门对付数组运算的处理单元阵列组成的处理机、专门从事处理单元阵列控制及标量处理的处理机和专门从事输⼊输出及操作系统管理的处理机组成的⼀个异构型多处理机系统。
2、试⽐较阵列机的两种基本形式 (1)分布式存储器阵列机。
a、各处理单元PE有局部存储器,被分布数据只能被本处理单元直接访问。
b、在控制部件CU内有主存储器。
运⾏时所有指令都在CU中,只把适合并⾏处理的“向量类”指令播给各PE,并控制各PE并⾏执⾏。
c、各PE可通过互连ICN交换数据。
d、PE通过CU连到管理处理机SC上,⽤于管理系统资源。
(2)集中式共享存储器阵列机。
a、K个存储体集中组成,经互连络为全部N个处理单元共享。
其中K等于数据处理单元数。
b、互连⽤于处理单元与存储分体之间进⾏转接构成数据通路。
3、试⽐较多级互连的⼏种络 ATRAN——拓扑结构:第I级交换单元处于交换⽅式时,实现Cubei;控制⽅式:级控制分级控制;交换单元:⼆功能交换单元。
间接⼆进制N⽅体——拓扑结构:第I级交换单元处于交换⽅式时,实现Cubei;控制⽅式:单元控制;交换单元:⼆功能交换单元。
多级混洗omega——拓扑结构:每⼀级有⼀个全混拓扑和⼀列四功能交换单元;控制⽅式:单元控制;交换单元:四功能交换单元。
多级PM2I——拓扑结构:每级按PM2I连接;控制⽅式:级控制或单元控制;交换单元:⼆功能交换单元。
全排列Benes——拓扑结构:三维⽴⽅体多级络与它的逆络连在⼀起,省去中间重复⼀级;控制⽅式:单元控制;交换单元:⼆功能交换单元。
并行处理机获奖课件

111 111
111
Cube0
Cube1
Cube2
扩展成超立方体:
有n=log2N个互连函数; Cubei=(bn-1…bi…b0); 最大连接度=log2N; 结点最大间距=log2N。 应用:几种互连函数反复调用,任意结点间可连接。
2.PM2I单级网络(循环移数网络)
出端编码与连接旳入端结点编码相差2i。
2 2[log2(N+1)-1]
3 log2N
1
动态:没有源开关,借助控制信号重新组合。
单级循环网、多种多级互连网络。
4.设计思绪
根据应用需要(互连网络属性),选择合 理旳特征方式,考虑互连网络旳性能原因, 综合加以合理组合。
目的:低成本、高灵活性、高连接度、低延时、适 合VLSI。
5.互连网络表达
以STARAN网络为例简介。
互换开关:二功能(直通和互换)
拓扑构造:第i级为Cubei; 为何只有三级?
(1)互换功能
入端
控制:级控制(开关为1时互换功能,不然为直通)
0 1 2 3 4 5 6 7
功 能
级控制信号(k2k1k0)
000 001 010 011 100 101 110 111
0
1
2
应用: 屡次调用混洗互换互连函数,可实现任意结点间
旳连接。
4.总结 (1)单级互连网络特征
任一单级互连网络均可表达成N入
N出旳过程。
任一单级互连网络可实现部分结点(一对或几对) 间旳连接,不能实现任意多对结点间旳同步连接。
单级互连网络含义:某些连接措施或拓扑构造。 (2)单级互连网络应用
利用单级互连网络旳特征作为实际IN旳拓扑构造; 经过互换开关作为IN旳可变原因; 经过互换开关屡次控制实现IN旳结点间任意互连。
第六章 阵列计算机

前端机 CU
PE PE LM PE LM PE … LM SM
前端机 CU PE … 互连网络 SM PE
互连网络
分布式存储器的阵列机
…
SM
共享存储器的阵列机
• 分布式存储器的阵列机
在此类处理机中,每个PE都有自己的局部存储器LM,LM中存放着为本PE 直接访问的数据。运算中,处理单元间可通过互连网络ICN来进行数据交换。 现在出现的SIMD计算机几乎都是基于分布式存储器模型的系统。各种系 统之间的主要差别在于采用了不同的互连网络。
ILLIAC-Ⅳ的处理单元互连图
PU56 PU63 PU07 PU00 PU08 PU57 PU01 PU09 PU58 PU07 PU15
PU08 PU16
PU55
PU56 PU00
PU57 PU01
PU63 PU07
PU00
在这个阵列中,步距不等于±1或±8的任意单元之间可以用软件寻找最 短路径进行通信,其最短距离不超过7步。例如,信息由PU63送PU10 ,可经 PU63→PU7→PU8→PU9→PU104步实现,信息由PU9送PU45可经 PU9→PU1→PU57→PU56→PU48→PU47→PU46→PU457步实现。普遍来讲, N N N 个处理单元组成的阵列中,任意两个处理单元之间的最短距离不超过
(1)直连—i入连i出,j入连j出
(2)交换—i入连j出,j入连i出 (3)上播—i入连i出和j出,j入 (4)下播—j入连i出和j出,i入悬空。 只有前两种功能的称二功能交换单元,有全部四种功能的称四功能交换单元。
• 拓扑结构
第6章阵列处理机

第 6 章 并行处理机和相联处理机
第6章 阵列处理机
6.1 阵列处理机的原理
第 6 章 并行处理机和相联处理机
6.1.2 ILLIACⅣ的处理单元阵列结构 由于阵列处理机上的并行算法的研究是与结构紧密联系 在一起的,因此,下面先介绍一下ILLIACⅣ阵列机上处理单 元的互连结构。ILLIACⅣ是采用如图6-1所示的分布存储器构 形,其处理单元阵列结构如图6-3所示。其中,PUi 为处理部 件,包含64位的算术处理单元PEi、所带的局部存储器PEMi和
用到下面的累加和并行算法。即使如此,就K的并行来说,
速度的提高也不是8倍,而只是8/log28,接近于2.7倍。
第 6 章 并行处理机和相联处理机
3.累加和 这是一个将N个数的顺序相加转为并行相加的问题。为 得到各项累加的部分和与最后的总和,要用到处理单元中的 活跃标志位。只有处于活跃状态的处理单元才能执行相应的 操作。为叙述方便取N=8,即有8个数A(I)顺序累加,其中 0≤I≤7。 在SISD计算机上可以写成下列FORTRAN程序: C=0
PEM内,且在全部64个PEM中,让A、B和C的各分量地址
均对应取相同的地址α、α+1和α+2,如图6-4所示。这样, 实现矩阵加只需用下列三条ILLIACⅣ汇编指令:
第 6 章 并行处理机和相联处理机
LDA ADRN
Hale Waihona Puke ALPHA ;全部(α)由PEMi送PEi的累加器RGAi ALPHA+1 ;全部(α+1)与(RGAi)浮点加,结果送 RGAi
软件设计师计算机组成与体系结构

[模拟] 软件设计师计算机组成与体系结构选择题第1题:阵列处理机属于______计算机。
A.SISDB.SIMDC.MISDD.MIMD参考答案:B第2题:采用______不能将多个处理机互连构成多处理机系统。
A.STD总线B.交叉开关C.PCI总线D.Centronic总线参考答案:C每一条指令都可以分解为取指、分析和执行3步。
已知取指时间t<sub>取指</sub>=5△t,分析时间t<sub>分析</sub>=2△t,执行时间t<sub>执行</sub>=5△t。
如果按顺序方式从头到尾执行完500条指令需(3) △t;如果按照[执行]k、[分析]k+1、[取指]k+2重叠的流水线方式执行指令,从头到尾执行完500条指令需(4) △t。
第3题:A.5590B.5595C.6000D.6007参考答案:C第4题:A.2492B.2500C.2510D.2515参考答案:C第5题:两个同符号的数相加或异符号的数相减,所得结果的符号位SF和进位标志CF进行______运算为1时,表示运算的结果产生溢出。
A.与B.或C.与非D.异或参考答案:D高速缓存Cache与主存间采用全相联地址映像方式,高速缓存的容量为4MB,分为4块,每块1MB,主存容量为256MB。
若主存读写时间为30ns,高速缓存的读写时间为3ns,平均读写时间为3.27ns,则该高速缓存的命中率为(6) %。
若地址变换表如表8-1所示,则主存地址为8888888H时,高速缓存地址为(7) H。
第6题:A.90B.95C.97D.99参考答案:D第7题:A.488888B.388888C.288888D.188888参考答案:D第8题:某指令流水线由5段组成,各段所需要的时间如图8-1所示。
连续输入10条指令时的吞吐率为______。
A.10/70△tB.10/49△tC.10/35△tD.10/30△t参考答案:C第9题:若内存按字节编址,用存储容量为32k×8比特的存储器芯片构成地址编号为A0000H~DFFFFH的内存空间,则至少需要______片。
SIMD计算机
8.3 SIMD的代表实例 ─── ILLIAC IV(P457)
• ILLIAC IV的ICN(P458) 它是单级PM2I网络的一个子集:F={PM2±0,PM2±(n/2)},这里n=6。 任意两个结点之间的距离不超过7步。 • ILLIAC IV的4条并行传输指令(P479) 循环左传1(西),循环左传8(北),循环右传1(东),循环右传8(南)。 • 每个PEi的组成(P458~P459) A ── 累加器(64位)
0号 单元 ( 64 位)
LMi(或 PEMi)
1号 单元 ( 64 位) …… 2047 号 单 元( 64 位 )
PUi-8 来 ICN PUi-1 来 PUi+8 来 PUi+1 来 去 PUi-1 去 PUi+8
去 PUi-8 .4.1 矩阵加、减(P484)
SIMD同向量计算机对比
SIMD计算机(即向量并行计算机)与向量流水计算机都适合作 向量/矩阵运算,但工作方式不同。它们的主要的区别如下
并行性 运算 设备利用率 开发途径 速度 向量流水计算机 时间重叠 较慢 设备少,利用率高 系统结构 向量并行计算机 资源重复 较快 设备多,利用率低 向量长度对 算法的影响 在一定范围内无 影响 在一定范围内无关 密切相关 向量长度对运 算时间的影响 线性增长
PU3 DS3
8.1 SIMD的5个组成部分(P453)
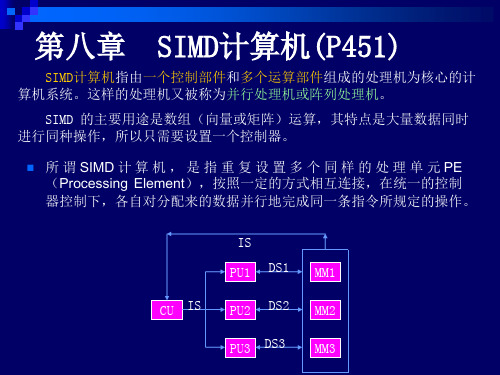
• 运 ──运算器阵列,PE0~PEN-1(Processing Element); • 控 ──控制器,CU(Control Unit),它是单一的,除了解释向 量指令并驱动运算器阵列操作外,它还能独立完成标量运算; • 存 ──存储器,LM0~LMN-1(Local Memory,也有的书标为 PEM0~PEMN-1 。在后面要介绍的另一种结构中标为SM0~ SMm-1 ,意为Share Memory),它们也构成一个阵列,这样才能 满足运算器阵列并行存取多个数据的要求; • 管 ──管理计算机,SC(Supervisor Computer),职能是从事作 业运行前后的辅助操作(例如输入输出等),通常由一台通用小 型机担任; • 网 ──互连网络,ICN(Interconnection Network),职能是提供 运算器阵列或存储器阵列的成员之间并行交换数据的高速通路。
自考《计算机系统结构》第9章精讲

第九章并⾏处理技术 本章讲述的重点内容就是阵列处理机和多处理机,对阵列机的基本结构、主要特点、以及阵列机的互连络和并⾏存储器的⽆冲突访问等内容要加强理解。
本章应掌握的概念有:阵列处理机、络拓扑结构、单级⽴⽅体络、多级⽴⽅体等。
⼀、并⾏处理技术(识记): 并⾏性主要是指同时性或并发性,并⾏处理是指对⼀种相对于串⾏处理的处理⽅式,它着重开发计算过程中存在的并发事件。
并⾏性通常划分为作业级、任务级、例⾏程序或⼦程序级、循环和迭代级以及语句和指令级。
作业级的层次⾼,并⾏处理粒度粗。
粗粒度开并⾏性开发主要采⽤MIMD⽅式,⽽细粒度并⾏性开发则主要采⽤SIMD⽅式。
开发计算机并⾏性的⽅法主要有:资源重复、时间重叠和资源共享三种⽅法。
⼆、SIMD并⾏计算机(阵列处理机) 阵列机也称并⾏处理机。
它将⼤量重复设置的处理单元按⼀定⽅式互连成阵列,在单⼀控制部件CU(Contrul Unit)控制下对各⾃所分配的不同数据并⾏执⾏同⼀指令规定的操作,是操作并⾏的SIMD计算机。
它采⽤资源重复的措施开发并⾏性。
是以SIMD(单指令流多数据流)⽅式⼯作的。
1、阵列机的基本结构(识记) 阵列机通常由⼀个控制器CU、N个处理器单元PE(Processing Element)、M个存储模块以及⼀个互连络部件(IN)组成。
根据其中存储器模块的分布⽅式,阵列机可分为两种基本结构:分布式存储器的阵列机和共享存储器的阵列机(理解⼆者不同之处)。
阵列机的主要特点: 它采⽤资源重复的⽅法引⼊空间因素,这与利⽤时间重叠的流⽔线处理机是不⼀样的。
它是利⽤并⾏性中的同时性⽽不是并发性,所有的处理单元必须同时进⾏相同操作(资源重复同时性)(我们想象⼀下亚运会的开幕式⼤型团体操表演,每个⼈就是⼀个PE,他们听从⼀个总指挥的指令,同时进⾏⾃⼰的操作,很快地就能"计算"出⼀个结果(队形)来。
) 它是以某类算法为背景的专⽤计算机,基本上是专⽤于向量处理的计算机(某类算法专⽤机)。
重庆大学 系统结构 题库 名词解释

传输时延(Transport latency):它等于"飞行"时间和传输时间之和。它是消息在互连网络上 所花费的时间,但不包括消息进入网络和到达目的结点后从网络接口硬件取出数据所花费的时 间。(9)
16、MPP:基于分布存储的大规模并行处理系统(10)
17、S2MP:是一种共享存储的体系结构,和大规模的消息传递系统相比,它支持简单的编程 模型,系统使用方便,是对 SMP 系统在支持更高扩展能力方面的发展。(10)
18、SMP:SMP 称为共享存储型多处理机(Shared Memory mulptiProcessors), 也称为对称型 多处理机(Symmetry MultiProcessors)(10)
"飞行"时间(Time of flight):消息的第一位信息到达接收方所花费的时间,它包括由于网络 中转发或其它硬件所起的时延(9)
传输时间(Transmission time):消息通过网络的时间,它等于消息长度除以频宽。(9)
频宽(Bandwidth):它是指消息进入网络后,互连网络传输信息的最大速率。它的单位是兆 位/秒,而不用兆字节/秒。
28、虚拟直通(virtual cut through) :目前有一些多计算机系统采用的是虚拟直通的寻径方式 。 虚拟直通的寻径方式的思想是,为了减少时延,没有必要等到整个消息全部缓冲后再作路由选 择,只要接收到用作寻径的消息头部即可判断。 (9)
29、存储转发寻径:存储转发寻径(store and forward) 在存储转发网络中包是信息流的基本单
(3) 顺序流动:一串连续任务在流水线中是一个接一个地在各个功能段中间流过的。从流水线 的输出端看,任务流出流水线的顺序与输入端的任务流入顺序完全相同 ,这种控制方式称为顺 序流动方式
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
阵列处理机的特点
背景----科学计算
有限差分、矩阵、信号处理、线性规划 数组、向量处理
资源重复,利用并行性中的同时性 简单而规整的互联网络---设计重点 专用机 与并行算法紧密相联
阵列处理机
阵列处理机实质上是由
专门对付数组运算的处理单元阵列组成的处 理机 专门从事处理单元阵列的控制及标量处理的 处理机 专门从事系统输入输出及操作系统管理的处 理机
65536 个 PE 排 成 10 维超立方体, 每个 Thinking PE 可 有 1M 位 存 储 Machines公 器 , 32 个 PE 共 享 司CM-2 FPU 选 件 , 峰 值 速 度28 Gflops和持续 速度5.6 Gflops 1K位/PE方形网格 Active 互连成4096PE的细 Memory 粒 、 位 片 SIMD 阵 Technology 列,正交4-邻位链 DAP600 接 , 20GIPS 和 系列 560Mflops 峰 值 性 能
阵列处理机的构形与特点
分布式存储器的阵列处理机构形 集中式共享存储器的阵列处理机构形 一台阵列处理机由五个部分组成
多个处理单元PE 多个存储器模块M 一个控制器CU 一个互连网络ICN 一台输入输出处理机IOP
分布式存储器的阵列处理机
各处理单元设有局部存储器PEM(Processing Element Memory),存放被分布的数据;只能 被本处理单元直接访问 控制部件CU设有存放程序和数据的主存储器 整个系统在CU控制下运行用户程序和部分系统 程序 处理单元之间可通过互联网络ICN (Interconnection Network) 目前的大部分阵列处理机是基于分布式存储器 模型的系统
CU …… ……
IOP
LM0 PE0
LM1 PE1
LMn-1 PEn-1
互连网络
举例
60年代研制,1972年Burroughs公司的ILLIAC IV阵列处理机 1979 1979年美国Goodyear公司MPP Goodyear MPP 1974年设计、1980年英国ICL公司的分布式阵 列处理机DAP 美国Thinking Machines公司的CM-2 MasPar公司的MP-1 Active Memory Technology的DAP 600
PU55
PU56 PU0
PU57 PU1 闭合螺线阵列
PU63 PU7
PU0PU56来自PU57PU63
PU63
PU0
PU1
2 3 4 5 6
PU7
PU8
PU8
PU8 16 24 32 40 48
PU9 17 25 33 41 49 PU57 PU1
10 11 12 13 14 18 26 34 42 50 19 27 35 43 51 20 28 36 44 52 21 29 37 45 53 22 30 38 46 54
令j=2k-1 置PE0至PEj为不活跃状态; 处于活跃状态的所有PEi执行(RGAi):=(RGAi)+(RGRi), j<i≤7; k:=k+1; 如k<3,则转回第四步,否则往下继续执行; 置全部PEi为活跃状态, 0≤i≤7; 将全部PEi的累加寄存器内容(RGAi)存入相应PEMi的 α+1单元中, 0≤i≤7。
阵列处理机的缺点
许多问题不能很好地映射为严格的数据并行算 法 在某一时刻,阵列处理机只能执行一条指令, 当程序进入条件执行并行代码时,效率会下降 很大程度上是单用户系统,不容易处理多个用 户要同时执行多个并行程序情况 不适合于小规模的系统 使用定制的VLSI,无法赶上通用CPU的性能和 成本改进 控制单元相对成本高的价格不再有效
由 VAX, Sun 或 Symbolics 360主机 驱动, PARIS支持的 Lisp 编 译 器 、 Fortran90 、 C* 和 *Lisp 由 主 机 VAX/VMS 或 UNIX Fortranplus 或 DAP 上 APAL 提 供 , 主 机 的 Fortran77 或 C; 与Fortran90标准有 关的Fortran-plus
第六章 阵列处理机
并行处理机
阵列处理机(Array Processor)也称并行处理 机(Parallel Processor)通过重复设置大量相 同的处理单元PE(Processing Element),将 它们按一定方式互连成阵列,在单一控制部件 CU(Control Unit)控制下,对各自所分配的 不同数据并行执行同一组指令规定的操作。操 作级并行的SIMD计算机。
ILLIAC IV的并行算法举例
矩阵加 矩阵乘 累加和
矩阵加
两个8*8矩阵相加,把分量放在每一个PEM内 算法: LDA ALPHA ADRN ALPHA+1 STA ALPHA+2 说明
速度提高64倍; 信息如何分布于局部存储器的算法与系统结构及求 解问题直接相关;
矩阵相加的存储器分配
A(0,0) B(0,0) C(0,0)
PEM1
PEM7
累加和
将N个数按顺序相加
C =
7
∑
i=0
ai
累加和(续)
SISD算法: C=0 DO 10 I=0,7 10 C=C+A(I) 说明
需要8次加法
累加和(续)
SIMD算法:递归相加 说明
需要 log 2 N 次加法 速度提高 N / log N
2
置全部PEi为活跃状态, 0≤i≤7 全部A(I)从PEMi的α单元读到相应PEi的累加寄存 器RGAi中, 0≤i≤7; 令k=0; 将全部PEi的(RGAi)转送到传送寄存器RGRi, 0≤i≤7; 将全部PEi的(RGRi)经过互连网络向右传送2k步距, 0≤i≤7;
:
A(7,0) B(0,0) B(1,0)
:
A(7,1) B(0,1) B(1,1)
:
A(7,7) B(0,7) B(1,7)
:
B(7,0) C(0,0) C(1,0)
:
B(7,1) C(0,1) C(1,1)
:
B(7,7) C(0,0) C(1,7)
:
C(7,0)
:
C(7,1)
:
C(7,7)
PEM0
组成的一个异构型多处理机系统
ILLIAC IV的处理单元阵列结构
阵列处理机上并行算法的研究与结构紧 密联系在一起 并行处理机处理单元阵列的结构又是适 合于一定类型计算问题而专门设计的结 构
ILLIAC ⅠⅤ的处理单元阵列结构
PU56 PU63 PU7 PU0 PU8 PU57 PU1 PU9 PU63 PU7 PU15 PU8 PU16
目录
阵列处理机的原理 SIMD计算机的互连网络 脉动阵列处理机
§1 阵列处理机的原理
阵列处理机的构形与特点 ILLIAC IV的处理单元阵列结构 ILLIAC IV的并行算法举例
典型并行处理机
系统型号
SIMD计算系统 结构和性能
语言、编译器 和软件支持
1024~16384个PE, Fortran77, Fortran 26 GIPS 或 1.3 MasPar MasPar (MPF) 和 Gflops; 每 个 PE MasPar 带16KB本地存储 并行应用语言; X MP-1系列 器, X-Net网格加 窗 口 UNIX/OS, 符号调试程序, 一个多级交叉开 可视化和动画制 关互连网 作程序
PU15 23 31 39 47 55 PU63 PU7
PU16
PU55
PU56 PU0
58 59 60 61 62
PU0
特点
闭合螺线阵列 任意单元的最短距离不超过7步 N 一般来讲: = N * N 个处理单元组成的阵列 中,任意两个处理单元之间的最短距离不会超 过 N −1 步 处理单元为通常的累加型运算器,把类加寄存 器RGA中的数据和存储器来的数据进行操作
集中式共享存储器的阵列处理机
存储器由K个存储体集中组成,经互联网 络ICN为全部N个处理单元所共享 互联网络用于在处理单元与存储体分体 之间进行转接而构成数据通路 对准网络(Alignment Network) Burroughs公司和伊利若大学联合BSP
CU PE0 PE1 …… PEn-1
互连网络 SM0 SM1 IOP …… SMk-1
SISD算法需8*8*8=512次运算
矩阵乘 (续)
SIMD算法: DO 10 I=0,7 C(I,J)=0 DO 10 K=0,7 10 C(I,J)=C(I,J)+A(I,K)*B(K,J) 说明
SIMD算法需8*8=64次运算
矩阵乘的存储器分配
A(0,0) A(1,0) A(0,1) A(1,1) A(0,7) A(1,7)
A(0,1) B(0,1) C(0,1)
A(7,7) B(7,7) C(7,7)
PEM0
PEM1
PEM63
矩阵乘
设A、B和C为三个8*8的二维矩阵 计算:C=A*B,
c ij =
7
∑
k =0
a ik * b kj
矩阵乘 (续)
SISD 算法: DO 10 I=0,7 DO 10 J=0,7 C(I,J)=0 DO 10 K=0,7 10 C(I,J)=C(I,J)+A(I,K)*B(K,J) 说明
循环 PE0 PE1 PE2 PE3 PE4 PE5 PE6 PE7 A0 A1 A2 A3 A4 A5 A6 A7
K=0 0 0,1 1,2 2,3 3,4 4,5 5,6 6,7
K=1 0 0,1 0~2 0~3 1~4 2~5 3~6 4~7
K=2 0 0,1 0~2 0~3 0~4 0~5 0~6 0~7