利用Scala语言开发Spark应用程序
Spark大数据实时计算:基于Scala开发实战

6.3 RDD的方法(算 子)分类
6.4基础练习
01
6.5实战案 例
02
6.6 RDD持 久化缓存
03
6.7持久化 缓存API详 解
04
6.8 RDD容 错机制 Checkpoi nt
06
6.10本章 习题
05
6.9本章总 结
6.1 RDD概念与详解
6.1.1 RDD简介 6.1.2 RDD的主要属性 6.1.3小结
1
3.1样例类
2
3.2模式匹配
3
3.3 Option 类型
4
3.4偏函数
5
3.5正则表达 式
3.7提取器
3.6异常处理
3.8泛型
3.9 Actor
3.10 Actor编程案 例
3.11本章总结 3.12本章习题
3.1样例类
3.1.1定义样例类 3.1.2样例类方法 3.1.3样例对象
3.2模式匹配
1.9 Map映射
1.9.1不可变Map 1.9.2可变Map 1.9.3 Map基本操作
1.10函数式编程
1.10.1遍历(foreach) 1.10.2使用类型推断简化函数定义 1.10.3使用下画线简化函数定义 1.10.4映射(map) 1.10.5扁平化映射(flatMap) 1.10.6过滤(filter) 1.10.7排序 1.10.8分组(groupBy) 1.10.9聚合(reduce)
8.3数据分类和Spark SQL适用场景
8.3.1结构化数据 8.3.2半结构化数据 8.3.3非结构化数据
8.9 Spark SQL初体验
8.9.1 SparkSession入口 8.9.2创建DataFrame 8.9.3创建Dataset 8.9.4两种查询风格
基于spark运行scala程序
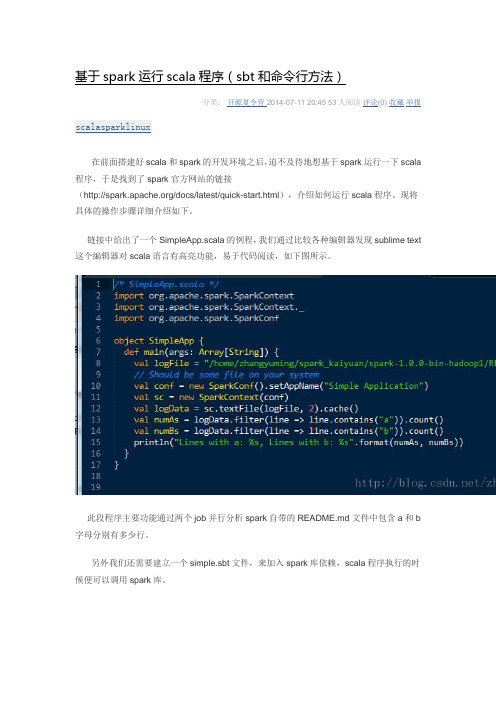
基于spark运行scala程序(sbt和命令行方法)分类:开源夏令营2014-07-11 20:45 53人阅读评论(0) 收藏举报scalasparklinux在前面搭建好scala和spark的开发环境之后,迫不及待地想基于spark运行一下scala 程序,于是找到了spark官方网站的链接(/docs/latest/quick-start.html),介绍如何运行scala程序。
现将具体的操作步骤详细介绍如下。
链接中给出了一个SimpleApp.scala的例程,我们通过比较各种编辑器发现sublime text 这个编辑器对scala语言有高亮功能,易于代码阅读,如下图所示。
此段程序主要功能通过两个job并行分析spark自带的README.md文件中包含a和b 字母分别有多少行。
另外我们还需要建立一个simple.sbt文件,来加入spark库依赖,scala程序执行的时候便可以调用spark库。
建立好simple.sbt文件后,由于需要对整个工程进行打包成jar文件才能执行,官网建议使用sbt(simple buildtool)这个工具对整个工程进行打包,而sbt对工程的目录有一定的要求,如下图所示建立好工程目录。
由于sbt工具并不是linux自带的软件,因此还需要安装,我这里由于安装sbt的时候是在linux电脑上直接安装的,不方便截图,因此不做过多说明,安装好了sbt工具后,运行sbt package命令(电脑需要联网),电脑会分析工程自行下载一些其他需要的文件,然后将文件打包,在我的电脑上在下图所示的目录中会生成simple-project_2.10-1.0.jar的包。
UnixPut the jar in your ~/bin directory, put the linejava -Xmx512M -jar `dirname $0`/sbt-launch.jar "$@"in a file called sbt in your ~/bin directory and do$ chmod u+x ~/bin/sbtThis allows you to launch sbt in any directory by typing sbt at the command prompt.sbt will pick up any HTTP proxy settings from the http.proxy environment variable. If you are behind a proxy requiring authentication, you must in addition pass flags to setthe http.proxyUserand http.proxyPassword properties:java -Dhttp.proxyUser=username -Dhttp.proxyPassword=mypassword -Xmx512M -jar `di rname $0`/sbt-launch.jar "$@"这个时候运行spark-submit命令并附带一些参数便可得到结果。
Spark官方文档——本地编写并运行scala程序

Spark官⽅⽂档——本地编写并运⾏scala程序快速开始本⽂将介绍如何⽤scala、java、python编写⼀个spark单击模式的程序。
⾸先你只需要在⼀台机器上成功建造Spark;做法:进⼊Spark的根⽬录,输⼊命令:$ sbt/sbt package(由于天朝伟⼤的防⽕墙,⼤陆地区是⽆法成功的,除⾮你可以顺利FQ),不想爬墙的可以下载预编译好的Spark ,Spark shell的交互式分析⼀、基础概念:Spark的交互式脚本是⼀种学习API的简单途径,也是分析数据集交互的有⼒⼯具。
在Spark根⽬录运⾏:./spark-shellSpark抽象的分布式集群空间叫做Resilient Distributed Dataset (RDD)弹性数据集。
RDD有两种创建⽅式:1、从Hadoop的⽂件系统输⼊(例如HDFS);2、有其他已存在的RDD转换得到新的RDD。
实践:1、现在我们利⽤Spark⽬录下的README⽂件来创建⼀个新的RDD:scala> val textFile = sc.textFile("README.md")textFile: spark.RDD[String] = spark.MappedRDD@2ee9b6e32、RDD有两种操作,分别是action(返回values)和transformations(返回⼀个新的RDD);下⾯开始些少量的actions:scala> textFile.count() // Number of items in this RDDres0: Long = 74scala> textFile.first() // First item in this RDDres1: String = # Spark3、下⾯使⽤transformations中的filter返回⼀个⽂件⼦集的新RDDscala> textFile.filter(line => line.contains("Spark")).count() // How many lines contain "Spark"?res3: Long = 15⼆、基于RDD的更多操作1、RDD的actions和transformations可以被⽤于更多复杂的计算。
精通Spark的开发语言:Scala最佳实践

Scala是一门以JVM为目标运行环境并将面向对象和函数式编程语言的最佳特性结合在一起的编程语言,此课程是大数据框架Spark的前置课程:1,Spark框架是采用Scala语言编写的,精致而优雅。
要想成为Spark高手,你就必须阅读Spark的源代码,就必须掌握Scala;2,虽然说现在的Spark可以采用多语言Java、Python等进行应用程序开发,但是最快速的和支持最好的开发API依然并将永远是Scala方式的API,所以你必须掌握Scala来编写复杂的和高性能的Spark分布式程序;培训对象1,系统架构师、系统分析师、高级程序员、资深开发人员;2,牵涉到大数据处理的数据中心运行、规划、设计负责人;3,云计算大数据从业者和Hadoop使用者;4,政府机关,金融保险、移动和互联网等大数据来源单位的负责人;5,高校、科研院所涉及到大数据与分布式数据处理的项目负责人;6,数据仓库管理人员、建模人员,分析和开发人员、系统管理人员、数据库管理人员以及对数据仓库感兴趣的其他人员;学员基础了解面向对象编程;有Java或者C/C++基础会更棒;王家林老师Spark亚太研究院院长和首席专家,Spark源码级专家,对Spark潜心研究(2012年1月起)2年多后,在完成了对Spark的13不同版本的源码的彻底研究的同时不断在实际环境中使用Spark的各种特性的基础之上,编写了世界上第一本系统性的Spark书籍并开设了世界上第一个系统性的Spark 课程并开设了世界上第一个Spark高端课程(涵盖Spark内核剖析、源码解读、性能优化和商业案例剖析)。
Spark源码研究狂热爱好者,醉心于Spark的新型大数据处理模式改造和应用。
Hadoop源码级专家,曾负责某知名公司的类Hadoop框架开发工作,专注于Hadoop一站式解决方案的提供,同时也是云计算分布式大数据处理的最早实践者之一,Hadoop的狂热爱好者,不断的在实践中用Hadoop解决不同领域的大数据的高效处理和存储,现在正负责Hadoop在搜索引擎中的研发等,著有《云计算分布式大数据Hadoop实战高手之路---从零开始》《云计算分布式大数据Hadoop 实战高手之路---高手崛起》《云计算分布式大数据Hadoop。
第83课:用Scala和Java二种方式实战Spark Streaming开发

3、reduceByKey 操作:
4、print 等操作:
/* * 第四步:接下来就像对于 RDD 编程一样基于 DStream 进行编程!!!原因是 DStream 是 RDD 产生的模 * 板(或者说类),在 Spark Streaming 具体发生计算前,其实质是把每个 Batch 的 DStream 的操作翻译成 * 为对 RDD 的操作!!! * 对初始的 DStream 进行 Transformation 级别的处理,例如 map、filter 等高阶函数等的编程,来进行具体 * 的数据计算 * 第 4.1 步:讲每一行的字符串拆分成单个的单词 */ JavaDStream<String> words = lines.flatMap(new FlatMapFunction<String, String>() { // 如果是 Scala,由于 SAM 转换,所以可以写成 val words = lines.flatMap { line => line.split(" ")}
第二步,创建 SparkStreamingContext:
我们采用基于配置文件的方式创建 SparkStreamingContext 对象。
/* * 第二步:创建 SparkStreamingContext: * 1,这个是 SparkStreaming 应用程序所有功能的起始点和程序调度的核心 * SparkStreamingContext 的构建可以基于 SparkConf 参数,也可基于持久化的 SparkStreamingContext 的 * 内容来恢复过来(典型的场景是 Driver 崩溃后重新启动,由于 Spark Streaming 具有连续 7*24 小时不, * 间断运行的特征所有需要在 Driver 重新启动后继续上衣系的状态,此时的状态恢复需要基于曾经的 * Checkpoint); * 2,在一个 Spark Streaming 应用程序中可以创建若干个 SparkStreamingContext 对象,使用下一个 * SparkStreamingContext 之前需要把前面正在运行的 SparkStreamingContext 对象关闭掉,由此, * 我们获得一个重大的启发,SparkStreaming 框架也只是 Spark Core 上的一个应用程序而已, * 只不过 Spark Streaming 框架箱运行的话需要 Spark 工程师写业务逻辑处理代码; */ JavaStreamingContext jsc = new JavaStreamingContext(conf, Durations.seconds(5));
Spark之使用SparkSql操作Hive的Scala程序实现

Spark之使⽤SparkSql操作Hive的Scala程序实现依赖<dependency><groupId>org.apache.spark</groupId><artifactId>spark-hive_2.11</artifactId><version>2.1.3</version></dependency>scala代码package com.zy.sparksqlimport org.apache.spark.SparkContextimport org.apache.spark.sql.SparkSession/*** 通过spark操作hive 把hive.site.xml放到resources中即可把元数据信息写⼊配置的mysql中*/object HiveSupport {def main(args: Array[String]): Unit = {//创建sparkSessionval sparkSession: SparkSession = SparkSession.builder().appName("HiveSupport").master("local[2]").enableHiveSupport().getOrCreate() //获取scval sc: SparkContext = sparkSession.sparkContextsc.setLogLevel("WARN")//操作hive// sparkSession.sql("create table if not exists person(id int,name string,age int) row format delimited fields terminated by ','")// sparkSession.sql("load data local inpath './data/person.txt' into table person")sparkSession.sql("select * from person").show()sparkSession.stop()}}hive-site.xml<configuration><property><name>javax.jdo.option.ConnectionURL</name><value>jdbc:mysql://192.168.44.31:3306/hive?createDatabaseIfNotExist=true</value><description>JDBC connect string for a JDBC metastore</description></property><property><name>javax.jdo.option.ConnectionDriverName</name><value>com.mysql.jdbc.Driver</value><description>Driver class name for a JDBC metastore</description></property><property><name>javax.jdo.option.ConnectionUserName</name><value>root</value><description>username to use against metastore database</description></property><property><name>javax.jdo.option.ConnectionPassword</name><value>root</value><description>password to use against metastore database</description></property></configuration>还需要把hdfs上的user/hive/warehouse⽬录 chmod 777,不然程序访问不了会报错。
intellij-idea打包Scala代码在spark中运行

intellij-idea打包Scala代码在spark中运⾏、创建好Maven项⽬之后(记得添加Scala框架到该项⽬),修改pom.xml⽂件,添加如下内容:<properties><spark.version>2.1.1</spark.version><scala.version>2.11</scala.version></properties><dependencies><dependency><groupId>org.apache.spark</groupId><artifactId>spark-core_${scala.version}</artifactId><version>${spark.version}</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-streaming_${scala.version}</artifactId><version>${spark.version}</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-sql_${scala.version}</artifactId><version>${spark.version}</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-hive_${scala.version}</artifactId><version>${spark.version}</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-mllib_${scala.version}</artifactId><version>${spark.version}</version></dependency></dependencies><build><plugins><plugin><groupId>org.scala-tools</groupId><artifactId>maven-scala-plugin</artifactId><executions><execution><goals><goal>compile</goal><goal>testCompile</goal></goals></execution></executions><configuration><scalaVersion>${scala.version}</scalaVersion><args><arg>-target:jvm-1.5</arg></args></configuration></plugin><plugin><artifactId>maven-compiler-plugin</artifactId><version>3.6.0</version><configuration><source>1.8</source><target>1.8</target></configuration></plugin><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-surefire-plugin</artifactId><version>2.19</version><configuration><skip>true</skip></configuration></plugin></plugins></build>其中保存之后,需要点击下⾯的import change,这样相当于是下载jar包⼆、编写⼀个Scala程序,统计单词的个数import org.apache.spark.SparkConfimport org.apache.spark.SparkContextobject WordCount {def main(args: Array[String]) {if (args.length == 0) {System.err.println("Usage: spark.example.WordCount <input> <output>")System.exit(1)}val input_path = args(0).toStringval output_path = args(1).toStringval conf = new SparkConf().setAppName("WordCount")conf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")val sc = new SparkContext(conf)val inputFile = sc.textFile(input_path)val countResult = inputFile.flatMap(line => line.split("")).map(word => (word, 1)).reduceByKey(_ + _).map(x => x._1 + "\t" + x._2).saveAsTextFile(output_path)}}三、打包file->Porject Structure->Artifacts->绿⾊的加号->JAR->from modules...然后填写定义的类名,选择copy to..选项(打包这⼀个类)点击ok之后,然后build->build Artifacts->build,等待build完成。
Spark 实战第 1 部分使用Scala 语言开发Spark 应用程序

Spark 实战,第1 部分: 使用Scala 语言开发Spark 应用程序本文旨在通过具有实际意义的案例向读者介绍如何使用Scala 语言开发Spark 应用程序并在Spark 集群上运行。
本文涉及的所有源数据都将从HDFS(Hadoop Distributed File System)读取,部分案例的输出结果也会写入到HDFS, 所以通过阅读本文,读者也会学习到Spark 和HDFS 交互的一些知识。
查看本系列更多内容|3评论:王龙, 软件开发工程师, IBM2015 年7 月21 日•内容关于SparkSpark 由加州大学伯克利分校AMP 实验室(Algorithms, Machines, and People Lab) 开发,可用来构建大型的、低延迟的大数据处理的应用程序。
并且提供了用于机器学习(MLlib), 流计算(Streaming), 图计算(GraphX) 等子模块,最新的 1.4.0 版本更是提供了与R 语言的集成,这使得Spark 几乎成为了多领域通吃的全能技术。
Spark 对数据的存储,转换,以及计算都是基于一个叫RDD(Resilient Distributed Dataset) 分布式内存的抽象,应用程序对需要计算的数据的操作都是通过对RDD 的一系列转化(Transformation) 和动作(Action) 算子完成的,其中转化算子可以把一个RDD 转成另一个RDD,如filter 算子可以通过添加过滤条件生成一个只包含符合条件的数据的新的RDD。
动作算子负责完成最终的计算,如count 算子可以计算出整个RDD 表示的数据集中元素的个数。
关于Spark 所支持的算子以及使用方法请参考Spark 官方网站。
本文所使用的Spark 的发行版是 1.3.1,读者可根据需要下载相应的版本。
回页首关于ScalaScala 语言是一门类Java 的多范式语言,其设计初衷就是为了继承函数式编程的面向对象编程的各种特性,正如Scala 语言官网描述的那样:Object-Oriented Meets Functional, 就是给出了一个关于Scala 语言特性的最简单明了的概括。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
利用Scala语言开发Spark应用程序
park内核是由Scala语言开发的,因此使用Scala语言开发Spark应用程序是自然而然的事情。
如果你对Scala语言还不太熟悉,可以阅读网络教程A Scala Tutorial for Java Programmers或者相关Scala书籍进行学习。
AD:
Spark内核是由Scala语言开发的,因此使用Scala语言开发Spark应用程序是自然而然的事情。
如果你对Scala语言还不太熟悉,可以阅读网络教程A Scala Tutorial for Java Programmers或者相关Scala书籍进行学习。
本文将介绍3个Scala Spark编程实例,分别是WordCount、TopK和SparkJoin,分别代表了Spark 的三种典型应用。
1. WordCount编程实例
WordCount是一个最简单的分布式应用实例,主要功能是统计输入目录中所有单词出现的总次数,编写步骤如下:
步骤1:创建一个SparkContext对象,该对象有四个参数:Spark master位置、应用程序名称,Spark安装目录和jar存放位置,对于Spark On Y ARN而言,最重要的是前两个参数,第一个参数指定为yarn-standalone ,第二个参数是自定义的字符串,举例如下:
valsc=newSparkContext(args(0),
WordCount ,System.getenv( SPARK_HOME ),Seq(System.getenv( SPARK_TEST_JAR )))
步骤2:读取输入数据。
我们要从HDFS上读取文本数据,可以使用SparkCon
valtextFile=sc.textFile(args(1))
当然,Spark允许你采用任何Hadoop InputFormat,比如二进制输入格式SequenceFileInputFormat,此时你可以使用SparkContext中的hadoopRDD函数,举例如下:
valinputFormatClass=classOf[SequenceFileInputFormat[Text,Text]]varhadoopRdd=sc.hadoopRDD(c onf,inputFormatClass,classOf[Text],classOf[Text])
或者直接创建一个HadoopRDD对象:
varhadoopRdd=newHadoopRDD(sc,conf,classOf[SequenceFileInputFormat[Text,Text,classOf[Text],c lassOf[Text])
步骤3:通过RDD转换算子操作和转换RDD,对于WordCount而言,首先需要从输入数据中每行字符串中解析出单词,水草玛瑙 然后将相同单词放到一个桶中,最后统计每个桶中每个单词出现的频率,举例如下:
valresult=hadoopRdd.flatMap{case(key,value)= value.toString().split( \\s+ }.map(word= (word,1)).reduceByKey(_+_)
其中,flatMap函数可以将一条记录转换成多条记录(一对多关系),map函数将一条记录转换为另一条记录(一对一关系),高山茶 reduceByKey函数将key相同的数据划分到一个桶中,并以key为单位分组进行计算,这些函数的具体含义可参考:Spark Transformation。
步骤4:将产生的RDD数据集保存到HDFS上。
可以使用SparkContext中的saveAsTextFile哈数将数据集保存到HDFS目录下,默认采用Hadoop提供的TextOutputFormat,每条记录以(key,value)的形式打印输出,你也可以采用saveAsSequenceFile函数将数据保存为SequenceFile格式等,举例如下:
result.saveAsSequenceFile(args(2))
当然,一般我们写Spark程序时,需要包含以下两个头文件:
importorg.apache.spark._importSparkContext._
WordCount完整程序已在Apache Spark学习:利用Eclipse构建Spark集成开发环境一文中进行了介绍,在次不赘述。
需要注意的是,指定输入输出文件时,需要指定hdfs的URI,比如输入目录是hdfs:hadoop-testtmpinput,输出目录是hdfs:hadoop-testtmpoutput,其中,hdfs:hadoop-test 是由Hadoop配置文件core- site.xml中参数指定的,具体替换成你的配置即可。
2. TopK编程实例
TopK程序的任务是对一堆文本进行词频统计,并返回出现频率最高的K个词。
如果采用MapReduce实现,则需要编写两个作业:WordCount和TopK,而使用Spark则只需一个作业,其中WordCount部分已由前面实现了,接下来顺着前面的实现,找到Top K个词。
注意,本文的实现并不是最优的,有很大改进空间。
步骤1:首先需要对所有词按照词频排序,如下:
valsorted=result.map{case(key,value)= (value,key);exchangekeyandvalue}.sortByKey(true,1)
步骤2:返回前K个:
valtopK=sorted.top(args(3).toInt)
步骤3:将K各词打印出来:
topK.foreach(println)
注意,对于应用程序标准输出的内容,Y ARN将保存到Container的stdout日志中。
在YARN中,每个Container存在三个日志文件,分别是stdout、stderr和syslog,前两个保存的是标准输出产生的内容,第三个保存的是log4j打印的日志,通常只有第三个日志中有内容。
本程序完整代码、编译好的jar包和运行脚本可以从这里下载。
下载之后,按照Apache Spark 学习:利用Eclipse构建Spark集成开发环境一文操作流程运行即可。
3. SparkJoin编程实例
在推荐领域有一个著名的开放测试集是movielens给的,下载链接是:datasetsmovielens,该测试集包含三个文件,分别是ratings.dat、sers.dat、movies.dat,具体介绍可阅读:README.txt,本节给出的SparkJoin实例则通过连接ratings.dat和movies.dat两个文件得到平均得分超过4.0的电影列表,采用的数据集是:ml-1m。
程序代码如下:
importorg.apache.spark._importSparkContext._objectSparkJoin{defmain(args:Array[String]){if(args.l ength!=4){println( usageisorg.test.WordCount master rating movie output )return}valsc=newSparkContext(args(0), WordCount ,System.getenv( SPARK_HOME ),Seq(System.getenv( SPARK_TEST_JAR )))Readratin gfromHDFSfilevaltextFile=sc.textFile(args(1))extract(movieid,rating)valrating=textFile.map(line= {valfileds=line.split( :: )(fileds(1).toInt,fileds(2).toDouble)})valmovieScores=rating.groupByKey().ma p(data=
{valavg=data._2.sumdata._2.size(data._1,avg)})ReadmoviefromHDFSfilevalmovies=sc.textFile(args( 2))valmovieskey=movies.map(line= {valfileds=line.split( :: )(fileds(0).toInt,fileds(1))}).keyBy(tup= tup._1)byjoin,weget movie,averageRating,movieName valresult=movieScores.keyBy(tup= tup._1).join(movieskey).filter(f= f._2._1._2 4.0).map(f= (f._1,f._2._1._2,f._2._2._2))result.saveAsTextFile(args(3))}}
你可以从这里下载代码、编译好的jar包和运行脚本。
这个程序直接使用Spark编写有些麻烦,可以直接在Shark上编写HQL实现,Shark是基于Spark 的类似Hive的交互式查询引擎,具体可参考:Shark。
4. 总结
Spark 程序设计对Scala语言的要求不高,正如Hadoop程序设计对Java语言要求不高一样,只要掌握了最基本的语法就能编写程序,且常见的语法和表达方式是很少的。
通常,刚开始仿照官方实例编写程序,包括Scala、Java和Python三种语言实例。
原文链接:framework-on-yarnspark-scala-writing-application
【编辑推荐】
Linux环境下C编程指南
本书系统地介绍了在Linux平台下用C语言进行程序开发的过程,通过列举大量的程序实例,使读者很快掌握在Linux平台下进行C程序开发。