Fortran进行批处理的方法剖析
Fortran 程式语言的编,译与执行简述

〔call sub_name ( ) 〕
九、註解與識別指令
C ;
首欄 C 後之任何文字為註解功能,不被編譯
* ; 首欄 * 後之任何文字,不被編譯 73 ~ 80 欄位,通常為識別說明用
Fortran Programming
由老師之範例中暸解語言的定義! 由範例之執行中領悟邏輯的關聯!
加法運算:+ 減法運算:乘法運算:* 除法運算:/ 冪次方運算:**;^
Ans = -(a+(b*c-d**3.)*25.+e*e*e)/2. 運算式中之運算次序依一般數學運算次序
八、控制指令
〔if ( ) goto no.〕 〔if ( ) then // else // endif〕 〔do no. // no. continue〕
一、檔案(文書)編輯
編輯完成 執行儲存
二、Fortran 程式語言編譯
在工作目錄cjs
下呼叫 c 磁碟的 mingw 目錄的 bin 子目錄的 g77.exe 來將 福傳檔案 *.for 編譯為 可執行檔 *.exe
二、Fortran 程式語言編譯
Fortran程式語言編譯指令(1) C:\cjs>c:\mingw\bin\g77t1.for-ot1.exe
磁碟機 工作的子目錄 編譯軟體名稱 編譯檔案名稱 儲存檔案名稱 檔案名稱類型
C碟 c 碟的 cjs 目錄 g77.exe t1.for t1.exe Primary-name . sub-name
三、程式的執行
*.for 經編譯得
*.exe 可執行檔
執行 〔t1 〕
結果 〔7〕
Fortran 程式語言 的 編、譯與執行簡述
Fortran 程序基础

2021/7/1
26
数组操作
PROGRAM TEST IMPLICIT NONE ! 变量定义 REAL :: A1, A2,A3,A4,A5,B(5,5) READ(*, *)A1,A2,A3,A4,A5 ! 数组片断的引用 B(1,1:5) = A1 B(2,1:5) = A2 B(3,1:5) = A3 B(4,1:5) = A4 B(5,1:5) = A5
数组可用DIMENSION语句定义 DIMENSION runoff(365) Real runoff ※使用数组必须先定义
2021/7/1
25
数组操作
数组引用
(1)引用数组元素 数组名(下标),如 runoff(15),rain(3,5)
(2)引用全部数组 数组名,如: real B(10),A(10) B=A
2021/7/1
8
数据类型及I/0格式
变量的定义及类型说明:
(1)类型说明语句
integer year, month, day
real runoff
character*10 station
(2)隐含约定
I~N 规则
2021/7/1
9
数据类型及I/0格式
输入、输出语句
READ(设备号, 格式说明或格式说明语句标号) [变量列表] WRITE (设备号, 格式说明或格式说明语句标号) [变量列表]
其他程序控制语句 End Pause stop
2021/7/1
22
Fortran程序流程控制
实例分析
(1)1~100求和 (2)输入5个数,按大小排序
2021/7/1
23
数组操作
Fortran进行批处理地方法

Fortran中批量处理文件的方法总结—循环读取目录下的所有符合条件的文件=====================一、简单的介绍在一年之前,我写过一个程序,主要是对Micaps资料进行批量处理,将逐日资料处理为旬、月的数据,在那个程序中,始终有一个问题困扰我,就是如何自动生成该读取的下一个文件名,这使我真正开始关注fortran中的批处理,时隔一年,决定写下这些文字,将我用到的一些fortran批处理的方法和大家共享,交流。
对于那些只要会用程序,不求其中原理的朋友,请马上跳过这些文字,直接去下载附件吧!程序里有使用说明,但是,如果你不懂原理,估计现成的程序你使用起来也会碰壁哦!这里所说的批处理是指对某一个目录下的指定后缀的文件的批量读取和处理。
我总结的批处理方法大概可以用下面这个示意图来说明:|||将文件目录写入一个文本文件,供fortran循环读取|————手动输入文件名|————运行程序之前命令行工具导出文件名|————程序运行后,未开始计算之前,生成文件名| ————调用CMD命令生成| ————GETFILEINFOQQ方法生成| ————调用WIN32API生成||在程序运行时动态生成文件名||对于第一种方法,我将主要介绍如何将目录写入文件,然后举出一个小的示例来验证。
第二种方法主要是说明其思路。
二、方法的介绍1、将文件目录写入一个文本文件,供fortran循环读取1.1、手动输入文件名这是最基本的方法啦,如果文件个数不多,而且文件名中包含了空格等特殊字符的话,建议使用这种方法,在这里就不多说啦,至于在fortran中的处理,等几个小方法介绍完之后会有一个例子来说明。
1.2、运行程序之前命令行工具导出文件名这是一个既高效又保险的方法,主要思路就是通过强大的CMD命令列出目录下的文件到一个指定的文件中,然后由fortran去循环读取该文件中的文件名信息,从而批量处理。
a、从运行工具打开你的CMD窗口;b、转到要处理的当前目录(可省略):CD /d 路径,如:CD /d e:\test这样可以快速到达e:\test目录c、使用DIR命令列出文件目录信息到指定的文件,通常使用的Dir *.*>新文件名这个命令在这里已经不能满足要求,因为会列出一堆对于我们处理而言无用的信息,现在要使用的命令是:DIR /b filter>newfile注意,其中的filter为文件筛选,必须自己修改为所需的,比如你可以把它改成*.txt,这样,就会列出当前目录下的所有txt结尾的文件了。
fortranlu分解法

Fortran LU分解法是一种用于解线性方程组的算法,它可以将一个方阵分解为一个下三角矩阵和一个上三角矩阵的乘积。
这种分解方法可以用于高斯消元法、最小二乘法和特征值计算等多种应用中。
在Fortran中,LU分解可以通过调用预先定义好的子程序实现。
下面是一个示例程序,演示如何使用Fortran LU分解法解一个线性方程组:program LUdecompositionimplicit noneinteger, parameter :: n = 3real, dimension(n,n) :: A, L, Ureal, dimension(n) :: b, xinteger :: i, j, k! Input matrix A and vector bA = reshape([2.0, 1.0, 1.0, 6.0, 2.0, 1.0, -2.0, -1.0, 3.0], shape(A))b = [1.0, 2.0, 3.0]! LU decomposition of Acall lu(n, A, L, U)! Solve Ax=b using forward and backward substitutiondo i = 1, nx(i) = b(i) / L(i,i)end dodo i = n, 1, -1do j = i+1, nx(i) = x(i) - U(i,j) * x(j)end dox(i) = x(i) / U(i,i)end do! Output solution xprint *, "Solution: ", xend program LUdecomposition在上面的程序中,我们首先定义了一个3x3的矩阵A和一个3x1的向量b。
然后,我们调用预先定义的子程序lu对矩阵A进行LU分解,得到下三角矩阵L和上三角矩阵U。
接下来,我们使用前向和后向代入法解方程组Ax=b,得到解向量x。
第10章 Fortran程序单元

• 一个Fortran程序中通常不是只由一个主程序组成, 而是由几个按某种方式划分的不同程序单元来共 同组成。尽管Fortran程序中允许只有主程序而没 有子程序,但绝不允许只有子程序而没有主程序。 在Fortran中,程序的执行总是从主程序开始的。 • Fortran中的程序单元可以大体划分为主程序、子 程序两种,其中子程序又可以进一步划分为函数 子程序、子例行子程序和数据块子程序。数据块 子程序通常用于实现变量的初始化赋值,函数子 程序和子例行子程序在用途上基本是一致的,但 是也有许多不同之处。本章将详细介绍Fortran中 的程序单元和它们的基本用法。
10.4 子例行子程序
• 同函数子程序相比,子例行子程序通常用于完成 更为复杂的任务。子例行子程序接受外界传入的 参数并对其进行处理,子例行程序名不会用来返 回处理结果。形象一点来说,函数子程序像检验 机,它不改变参数的值但会告诉外界一个检测结 果;而子例行子程序更像一个加工机器,外界来 的参数经过它的加工会以新的形象出现。本节主 要介绍子例行子程序的相关知识。
10.5 子程序的多入口点和多折返点
• 尽管子程序中不允许直接定义其他的子程序,但 是在Fortran 77时代,可以通过特殊的方式在同 一个子程序中定义多个不同的过程入口。通过调 用不同的过程定义来实现调用同一个子程序中的 不同执行段。除了提供多入口点外,Fortran 77 时代也提供特殊的多折返点来实现特定条件的子 程序调用返回方式。
10.6 Fortran 90/95中的特殊子程序类型
• 在Fortran 90/95标准中,除了继续对前述的一般 子程序类型提供支持外,还新增了三种特殊的子 程序类型。这三种子程序类型就是前述章节中曾 经提到过的RECURSIVE、PURE和ELEMENTAL三种属 性。RECURSIVE属性允许过程进行自身调用,也就 是常说的递归调用;PURE和ELEMENTAL属性都用于 数组的并行处理。
fortran 90 文件(文件的操作语句)解析

土木学院
这是已被打开 的数据文件的 内容
土木学院
土木学院
$
10
100 202
U1=2 Open(Unit=2,File='F2.DAT',Status='New', Access='Sequential',Form='Formatted') do 10 I=1,30 write(*,*) "请输入学号、两门成绩" Read(*,*) N,A,B C=A+B Write(2,202) '学号:', N,'总成绩',C continue 输入30个学生的学号 Close(2) 和两门成绩,最后将总 Format(I2,F5.1,F5.1) 成绩与学号输出来. Format(A,I2,A,F7.1) End
我们现在主要以磁盘设备为例来介绍FORTRAN 对文件操作的语句(打开、关闭、定位、输入和输出)
土木学院
FORTRAN的数据文件由记录组成,也就是对文 件的存取是以记录为单位进行的;
文件
记录:长度不超过规定范围的数字或文本 的集合;
记录
Fortran的数据文件按存取方式可划分为: 1. 顺序存取文件(顺序文件) 其存取操作必须从头到尾顺序进行; 2. 直接存取文件(直接文件或随机文件) 在程序的执行过程中对任意一个指定的 记录进行操作(读和写)。
Access=SD 代表文件的存取方式: Direct:以直接方式存取;Sequential: 以顺序方式存取;
Form=fe 代表文件存放格式:Formatted-字符形式
在Open中省略Access和Form,则表示打开文件为 有格式顺序存取文件.
(最新整理)fortran90文件(文件的操作语句)解析

$ Access=‘Direct’,Form=‘Formatted’,Recl=16的)长度是相等的,但真正写
Do 10 I=1,N
到文件中的实际字节的个数
Write(12,100,Rec=I) I,Sqrt(Real(I))
可以比说明的长度短。
10 Continue
记录号:是不可少的参
100 Format(I3, E13.6) 数,文件的第一个记录
•
Read(*,*) N,A,B
•
C=A+B
•
Write(2,202) '学号:', N,'总成绩',C
• 10 continue
•
Close(2)
• 100 Format(I2,F5.1,F5.1)
• 202 Format(A,I2,A,F7.1)
输入30个学生的学号 和两门成绩,最后将总 成绩与学号输出来.
• 也可以使用表控输入输出语句对文件进行 格式输入输出,如:WRITE(3,*) N,M。
Next
2021/7/26
土木学院
13.2 有格式直接存取文件
• 直接存取可以任意确定需要读写记录的位 置;
• 直接存取只适用于磁盘文件;
• 其基本的操作与顺序存取大致相同,主要不 同的是:Open的说明、Read和Write的控制 项不同。
2021/7/26
土木学院
2021/7/26
土木学院
13.1有格式顺序存取文件
• 下面我们就介绍如何从文件中获得数据: (例如:从文件F1.DAT中读取数据,经过处理 后,将结果保存在F2.DAT中) 1. 准备数据文件(可以在各种编辑器中完成, 输入格式及宽度与程序要求的一致),数据文 件名的后缀为 *.DAT(也可以是*.txt); 2. 编写数据输入和数据处理文件,最后将结 果输出到F2.DAT中.
fortran编译器操作
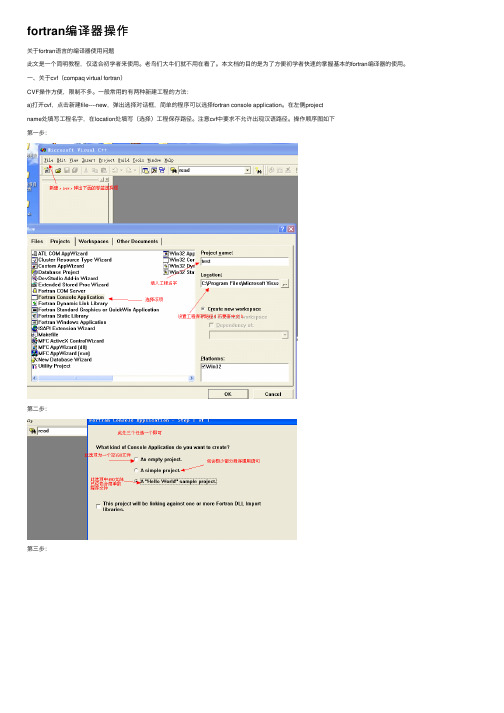
fortran编译器操作关于fortran语⾔的编译器使⽤问题此⽂是⼀个简明教程,仅适合初学者来使⽤。
⽼鸟们⼤⽜们就不⽤在看了。
本⽂档的⽬的是为了⽅便初学者快速的掌握基本的fortran编译器的使⽤。
⼀、关于cvf(compaq virtual fortran)CVF操作⽅便,限制不多。
⼀般常⽤的有两种新建⼯程的⽅法:a)打开cvf,点击新建file----new,弹出选择对话框,简单的程序可以选择fortran console application。
在左侧projectname处填写⼯程名字,在location处填写(选择)⼯程保存路径。
注意cvf中要求不允许出现汉语路径。
操作顺序图如下第⼀步:第⼆步:第三步:第四步:运⾏⾄此,所有步骤完成。
b)直接打开cvf,点击新建⽂档(new)然后单击保存,弹出保存对话框,选择保存路径及⽂件夹,⽂件名改为“⼯程名.f90”格式此处注意如果是fortran⾃由格式,请保存为*.f90或*.f95格式,如果是固定格式请保存为*.for或*.f格式。
因为编译器是根据后缀的不同调⽤不同的语⾔编译器,否则将出错。
保存⽂件的路径和⽂件夹即为该⼯程所在的路径和⽂件夹。
同样不能有汉语。
⽰意图如下:第⼀步第⼆步、第三步、⾄此,所有的⼯程完成。
⼆、关于CVF的调试(debug)在相应代码编辑框左侧发灰⾊的竖线部分,⿏标变为反三⾓⽅向的形状时即可右键⿏标,选择insert/remove BreakPoint选项,在代码左侧可以看到⼀个红⾊的标⽰(代码⾏尽量不要设在代码最后。
可以设置到⾃认为可能发⽣错误的地⽅。
或者尽量靠前设置),此时就可以按F5进⼊调试状态。
可以在watch窗⼝查看各个变量,数组的值与内容。
按F11进⾏单步运⾏。
查看错误出处。
具体的更细致的调试,请参看相关⽂献或书籍。
这类书籍不少。
具体操作如下:6三、关于IVF (intel virtual fortran )编译器的使⽤由于ivf 要求⽐较严格,且⾃⾝不带IDE 窗⼝。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Fortran中批量处理文件的方法总结—循环读取目录下的所有符合条件的文件=====================一、简单的介绍在一年之前,我写过一个程序,主要是对Micaps资料进行批量处理,将逐日资料处理为旬、月的数据,在那个程序中,始终有一个问题困扰我,就是如何自动生成该读取的下一个文件名,这使我真正开始关注fortran中的批处理,时隔一年,决定写下这些文字,将我用到的一些fortran批处理的方法和大家共享,交流。
对于那些只要会用程序,不求其中原理的朋友,请马上跳过这些文字,直接去下载附件吧!程序里有使用说明,但是,如果你不懂原理,估计现成的程序你使用起来也会碰壁哦!这里所说的批处理是指对某一个目录下的指定后缀的文件的批量读取和处理。
我总结的批处理方法大概可以用下面这个示意图来说明:|||将文件目录写入一个文本文件,供fortran循环读取|————手动输入文件名|————运行程序之前命令行工具导出文件名|————程序运行后,未开始计算之前,生成文件名| ————调用CMD命令生成| ————GETFILEINFOQQ方法生成| ————调用WIN32API生成||在程序运行时动态生成文件名||对于第一种方法,我将主要介绍如何将目录写入文件,然后举出一个小的示例来验证。
第二种方法主要是说明其思路。
二、方法的介绍1、将文件目录写入一个文本文件,供fortran循环读取1.1、手动输入文件名这是最基本的方法啦,如果文件个数不多,而且文件名中包含了空格等特殊字符的话,建议使用这种方法,在这里就不多说啦,至于在fortran中的处理,等几个小方法介绍完之后会有一个例子来说明。
1.2、运行程序之前命令行工具导出文件名这是一个既高效又保险的方法,主要思路就是通过强大的CMD命令列出目录下的文件到一个指定的文件中,然后由fortran去循环读取该文件中的文件名信息,从而批量处理。
a、从运行工具打开你的CMD窗口;b、转到要处理的当前目录(可省略):CD /d 路径,如:CD /d e:\test这样可以快速到达e:\test目录c、使用DIR命令列出文件目录信息到指定的文件,通常使用的Dir *.*>新文件名这个命令在这里已经不能满足要求,因为会列出一堆对于我们处理而言无用的信息,现在要使用的命令是:DIR /b filter>newfile注意,其中的filter为文件筛选,必须自己修改为所需的,比如你可以把它改成*.txt,这样,就会列出当前目录下的所有txt结尾的文件了。
Newfile就是你需要存放文件名的那个文件,比如可以是dir.txt,这样就成了 dir/b*.txt>dir.txt,就会把当前目录下的所有文件都列出到dir.txt文件中,当然,由于dir.txt 也在当前目录,所以也会被算进去,这在处理的时候是需要注意的,下面几种方法中同样考虑了这个问题。
你可以选择手动删掉,或者把dir.txt这个文件存到其他地方去,或者,不要和你需要的文件具有相同的后缀也行,比如:dir /b *.txt>e:\dir.txt (假设当前目录是e:\test)如果省略了第二步中的转到当前目录的话,就需要在dir命令后输入完整的路径了,而且新生成的文件也要选择有权限建立新文件的地方存放,比如你在c:\users目录下输入:dir /b e:\test\*.txt>e:\dir.txt,这个命令和上面先转到e:\test目录下的效果是一样的。
现在你是不是比较好奇,/b 是干嘛的,其实就是只列出文件名,不要其他的附件信息,比如创建时间,文件大小等等这些对于我们批处理无关的信息。
如果你想包含某个目录下的子目录,那么,就可以这样写:Dir /b/s filter>newfile/s就表示包含子目录,但是,这样会有一个问题,那就是,批处理的时候必须获得正确的路径才能操作,这样得到的子目录里面的文件不会有任何标志说他是来自子目录的,因此fortran处理的时候就无法判断了,所以,如果包含了子目录,那么请用下面的命令:Dir /a-d/b/s filter>newfile现在去看看新生成的文件吧,怎么样,很惊喜吧!懂了这个方法,下面一部分的第一个方法对你来说就是小菜一碟啦。
如果你使用的win7(或vista)系统,而且无法正常使用CVF编译器的话,那么第一部分到这里就算结束啦,除非,你会在其他fortran编译器中调用WIN32API。
1.3、程序运行后,未开始计算之前生成文件名1.3.1、在程序中调用CMD命令这个方法其实就是上一个方法的进化版,只不过变成了在程序运行的时候调用命令自动生成,这样整个过程显得少一点,只需要在程序里设置好相关的参数即可。
这个方法的关键在于SYSTEMQQ函数的使用,这是CVF编译器封装的调用CMD命令的一个函数,存在于DFLIB库中,其语法命令为:result = SYSTEMQQ(commandline)commandline:表示需要进行的CMD操作,字符串形式,函数中的实际长度由传入的参数决定,input类型(表示输入为参数);Results:一个逻辑型变量(logical(4)),如果成功为true,失败为false(不解的是程序中要实现的东西都是正常的,比如仅仅传入dir命令,返回的结果仍然为F,请高手赐教)给出一个简单的例子:USE DFLIBLOGICAL(4)resultresult = SYSTEMQQ('copy e:\dir.txt e:\test\dir.txt')这个命令将第一个路径中的文件复制到为第二个路径中的文件。
通过这个例子再结合上面一个方法,就可以很方法便的构造出我们需要用来批处理的子函数,关键语句如下所示:subroutine ListToFile(fPath,outPut)character*(*),InTent(In):: fPath,outPutcharacter*100CMDLOGICAL(4) resCMD="dir/a-d/b/s "//trim(fPath)//" >"//trim(outPut)res=SYSTEMQQ(CMD)endsubroutine其中传入的是文件筛选值和输出的路径,这个方法也是我在第一部分中最为推荐的一个方法了,代码简洁高效,能够输出完整的路径,可以包含子文件夹,唯一的缺点就是输出的文件个数不能直接在程序中调用(方便循环),需要在批处理的时候使用其他方法来判断文件是否读取结束。
1.3.2、使用GETFILEINFOQQ方法生成文件目录该方法是下面一个方法的进化版,是由CVF对WIN32的API进行了封装,这样,我们就可以通过简单的调用函数来实现一些面向对象的功能。
简单的翻译了一下官方给出的GETFILEINFOQQ函数信息:Module: USE DFLIB (存在于DFLIB库中)语法简介:Syntaxresult = GETFILEINFOQQ (files, buffer, handle)files :输入类型的字符型变量,表示你需要查找的路径(也就是我们上面方法中的筛选值),同样可以使用*或者?这样的通配符。
buffer :在函数运行中会获得一个值,可供输出使用,这个值就是所找到的文件的相关信息,属于FILE$INFO类型的变量(该类型定义于:fortran安装路径DF98\INCLUDE路径下),其结构如下:TYPE FILE$INFOINTEGER(4)CREATIONINTEGER(4)LASTWRITEINTEGER(4)LASTACCESSINTEGER(4)LENGTHINTEGER(4)PERMITCHARACTER(255)NAMEEND TYPE FILE$INFOhandle :接受输入和输出整型变量,表示文件控制信息(同样在DFLIB中定义),包含以下内容:FILE$FIRST - First matching file found.FILE$LAST - Previous file was the last valid file.FILE$ERROR - No matching file found.Results: 返回值是一个整型变量(integer(4)),表示的不含空格的文件名长度,如果文件未找到,则返回0。
了解了以上信息,我们就可以通过编程进行循环调用这个函数,每找到一个符合条件的文件,就把他输入到指定路径的文件中去,注意,凡是input类型的变量都必须传入数值,否则会出错。
如果你比较有探索精神,就试着用这个介绍和思路来编程一下吧,子程序如下所示(完整的请下载附件)Subroutine GetFileList(cFileName,outPut,iFile)UseDFLib,only:GetFileInfoQQ,GetLastErrorQQ,FILE$INFO,FILE$LAST,FILE$ERROR,FILE$ FIRST,ERR$NOMEM,ERR$NOENT,FILE$DIR !引入库函数Implicit None!根据上面的语法介绍来定义变量Character*(*),Intent(In)::cFileName !筛选值character*(*),intent(In)::output !输出路径Integer,Intent(InOut)::iFile !记录已经找到几个文件TYPE (FILE$INFO) info !找到的文件的信息INTEGER(4)::Wildhandle,length !文件控制信息,文件大小,Wildhandle = FILE$FIRSTiFile = 0DOWHILE (.TRUE.) !循环找文件length = GetFileInfoQQ(cFileName,info,Wildhandle) !调用函数找文件!如果遇到错误或者不能再找到不同的文件,则进入选择,准备退出IF ((Wildhandle .EQ. FILE$LAST) .OR.(Wildhandle .EQ. FILE$ERROR)) THEN SELECT CASE (GetLastErrorQQ())CASE (ERR$NOMEM) !//内存不足iFile = - 1ReturnCASE (ERR$NOENT) !//碰到通配符序列尾,正常退出ReturnCASE DEFAULTiFile = 0ReturnEND SELECTEND IFiFile= iFile + 1Call WriteFileName( Trim() ,outPut, iFile) !调用子函数输出文件名ENDDOEnd Subroutine GetFileList注意,在调用子函数输出文件名时,要做一些处理,主要是判断文件是否存在(不存在则新建,如果是第一次找到,而且文件存在,则覆盖,否则追加),以及找到的是否为我们自己建立的这个dir.txt文件(如果是,则忽略,找到的文件数量-1)这个方法也不错,如果不需要子目录的信息,其优越性不亚于上一种方法,因为该子函数能够直接返回找到的文件数量。