检验多重共线性
多重共线性与自相关的检验与解决

5word 格式支持编辑,如有帮助欢迎下载支持。
2 算出来再进行回归即得到以下结果:
Model Summaryb
Model
Std. Error of the
R
R Square
Adjusted R Square
Estimate
Durbin-Watson
1
.993a
.987
.985
.29640
1.862
Model
1
Regression
Residual
综上所述,该模型不存在多重共线性但存在自相关,运用广义差分法解决自相 关后,模型的拟合程度有显著提升,得到优化的模型将更有利于帮助我们分析经济 问题。
实训 总结 分析
这次试验完成得比上次轻松了许多,因为使用软件的频率增加使得用起来更得 心应手。这次的问题是检验和解决模型的多重共线性和自相关,因为多重共线性比 自相关的影响程度更大,且对整个模型的变量个数都有影响,所以先检验和解决多 重共线性再检验和解决自相关。
首先对原始数据进行用普通最小二乘法进行大致的拟合,并选择 Linear Regression-Statistics-Collinearity diagnostics,即用膨胀因子法对原模型进行多重共 线性检验,结果如下:
Model Summary
Model 1
R .982a
R Square .965
Coefficient Correlationsa
Model
第三产业增长率
第一产业增长率
第二产业增长率
1
Correlations
第三产业增长率
1.000
计量经济学实验五 多重共线性的检验与修正 完成版
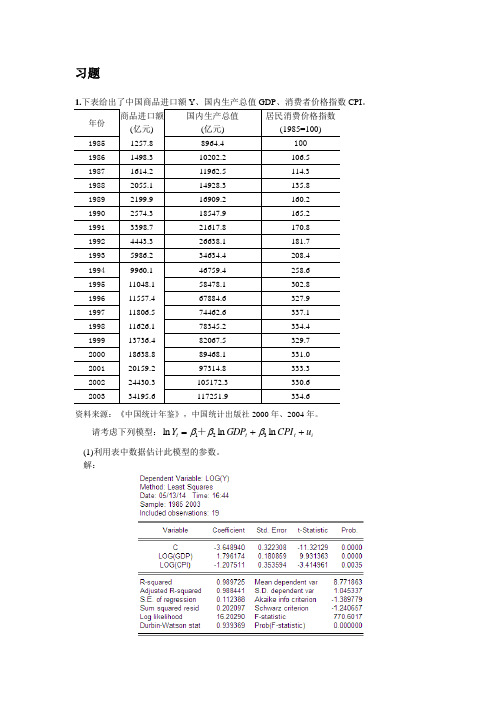
习题1.下表给出了中国商品进口额Y 、国内生产总值GDP 、消费者价格指数CPI 。
年份 商品进口额 (亿元)国内生产总值(亿元)居民消费价格指数(1985=100)1985 1257.8 8964.4 1001986 1498.3 10202.2 106.5 1987 1614.2 11962.5 114.3 1988 2055.1 14928.3 135.8 1989 2199.9 16909.2 160.2 1990 2574.3 18547.9 165.2 1991 3398.7 21617.8 170.8 1992 4443.3 26638.1 181.7 1993 5986.2 34634.4 208.4 1994 9960.1 46759.4 258.6 1995 11048.1 58478.1 302.8 1996 11557.4 67884.6 327.9 1997 11806.5 74462.6 337.1 1998 11626.1 78345.2 334.4 1999 13736.4 82067.5 329.7 2000 18638.8 89468.1 331.0 2001 20159.2 97314.8 333.3 2002 24430.3 105172.3 330.6 200334195.6117251.9334.6资料来源:《中国统计年鉴》,中国统计出版社2000年、2004年。
请考虑下列模型:i t t t u CPI GDP Y ++=ln ln ln 321βββ+ (1)利用表中数据估计此模型的参数。
解:ln 3.6489 1.796ln 1.2075ln t t t Y GDP CPI =--+t= (-11.32) (9.93) (-3.415)20.988770.6.0.1124R F S E ===(2)你认为数据中有多重共线性吗?多重共线性的检验 1)综合统计检验法若 在OLS 法下:R 2与F 值较大,但t 检验值较小,则可能存在多重共线性。
多重共线性检验与修正

多重共线性检验与修正数据来源:《中国统计年鉴2014》12-10、4-3、12-4、12-5、12-8、Eviews操作:1、基本操作:(1)录入数据:命令:data y l m f a ir(y代表粮食产量,l代表第一产业劳动力数量,m代表农业机械总动力,f代表化肥施用量,a代表农作物总播种面积,ir为有效灌溉面积/农作总播种面积得出的灌溉率)(2)做线性回归:命令:LS y c l m f a ir2、检验多重共线性(1)方差膨胀因子判断法在生成的线性回归eq01中,view—coefficient diagnostics—variance inflation factors看生成表格中的Centered VIF,发现L、M、F、A、IR的方差膨胀因子都很大,说明存在严重多重共线性。
(eg:L的Centered VIF指以L为因变量,M、A、F、IR为自变量所做出的辅助回归的判定系数R²,然后1/1-R²得出的值。
)(由课本内容可知,当完全不共线性时,VIF=1;完全共线性时,VIF=正无穷)(2)相关系数矩阵判断法命令:cor l m f a ir这个是通过看各个解释变量之间的相关系数来判断是否存在多重共线性的。
可以看到大多数解释变量之间两两相关系数都大于0.9。
相关系数极大说明解释变量之间存在很高的相关性,因而也就很可能存在共线性。
3、修正多重共线性(1)逐步回归排除引起共线性的变量①菜单栏操作在生成的线性回归eq01中,Estimate—Method—STEPLS接下来会出现两个框框,上面的框框是固定住不做逐步回归的变量,一般设定为y和c下面的框框是需要进行逐步回归选择是否剔除的变量,这里填入l m f a ir 然后出来一个新的表格,这个表格已经自动选择了可以保留的变量l a f,剔除了m ir②命令栏操作命令:STEPLS y c @ l m f a ir这条命令其实和菜单栏操作的意思一样,stepls代表采用逐步回归方法,@前的y、c代表固定不做逐步回归的变量,@后的l、m、f、a、ir代表要做逐步回归的变量出来的结果和菜单栏操作的结果是一样的。
多重共线性检验实训报告

一、实训背景在计量经济学和统计分析中,多重共线性是指模型中的多个自变量之间存在高度的相关性。
这种相关性会导致回归系数估计的不稳定,影响模型的预测能力和解释力。
因此,对多重共线性进行检验和修正对于确保模型的准确性和可靠性至关重要。
本实训旨在通过实际操作,学习如何使用SPSS软件进行多重共线性检验,并探讨相应的修正方法。
二、实训目的1. 理解多重共线性的概念及其对模型的影响。
2. 掌握使用SPSS软件进行多重共线性检验的方法。
3. 学习识别多重共线性的存在,并掌握相应的修正方法。
4. 提高对计量经济学模型诊断和修正的实际操作能力。
三、实训内容1. 数据准备本实训使用的数据集为某城市房价与多个影响因素的相关数据,包括房价(被解释变量)和收入、教育水平、交通便利性、周边设施等(解释变量)。
2. SPSS软件操作(1)数据导入首先,将数据集导入SPSS软件。
在SPSS界面中,点击“文件”菜单,选择“打开”,找到数据文件并导入。
(2)多重共线性检验导入数据后,进行以下操作:a. 点击“分析”菜单,选择“回归”,再选择“线性”。
b. 将被解释变量拖入“因变量”框,将解释变量拖入“自变量”框。
c. 点击“统计”菜单,选择“共线性诊断”。
d. 点击“继续”,然后点击“确定”。
(3)结果分析SPSS会自动计算并显示多重共线性的检验结果,主要包括方差膨胀因子(VIF)和容忍度(Tolerance)。
3. 结果分析(1)方差膨胀因子(VIF)VIF用于衡量变量之间相关性的程度。
一般来说,VIF值大于10表示存在多重共线性问题。
本实训中,我们发现收入、教育水平和交通便利性三个变量的VIF值均大于10,说明这三个变量之间存在严重的多重共线性。
(2)容忍度(Tolerance)容忍度是VIF的倒数,用于衡量变量之间独立性的程度。
一般来说,容忍度值小于0.1表示存在多重共线性问题。
本实训中,我们发现收入、教育水平和交通便利性的容忍度值均小于0.1,进一步证实了这三个变量之间存在多重共线性。
多重共线性的检验与处理

实验名称:多重共线性的检验与处理实验时间:2011.12.10实验要求:主要是学习多重共线性的检验与处理,主要是研究解释变量与其余解释变量之间有严重多重共线性的模型,分析变量之间的相关系数。
通过具体案例建立模型,然后估计参数,求出相关的数据。
再对模型进行检验,看数据之间是否存在多重共线性。
最后利用所求出的模型来进行修正。
实验内容:实例:我国钢材供应量分析通过分析我国改革开放以来(1978-1997)钢材供应量的历史资料,可以建立一个单一方程模型。
根据理论及对现实情况的认识,影响我国钢材供应量 Y(万吨)的主要因素有:原油产量X1(万吨),生铁产量X2(万吨),原煤产量X3(万吨),电力产量X4(亿千瓦小时),固定资产投资X5(亿元),国内生产总值X6(亿元),铁路运输量X7(万吨)。
(一)建立我国钢材供应量的计量经济模型:(二)估计模型参数,结果为:Dependent Variable: YMethod: Least SquaresDate: 11/02/09 Time: 16:09Sample: 1978 1997Included observations: 20Variable Coefficient Std. Error t-Statistic Prob.C 139.2362 718.2493 0.193855 0.8495X1 -0.051954 0.090753 -0.572483 0.5776X2 0.127532 0.132466 0.962751 0.3547X3 -24.29427 97.48792 -0.249203 0.8074X4 0.863283 0.186798 4.621475 0.0006X5 0.330914 0.105592 3.133889 0.0086X6 -0.070015 0.025490 -2.746755 0.0177X7 0.002305 0.019087 0.120780 0.9059R-squared 0.999222 Mean dependent var 5153.350Adjusted R-squared 0.998768 S.D. dependent var 2511.950S.E. of regression 88.17626 Akaike info criterion 12.08573Sum squared resid 93300.63 Schwarz criterion 12.48402Log likelihood -112.8573 F-statistic 2201.081Durbin-Watson stat 1.703427 Prob(F-statistic) 0.000000由此可见,该模型可绝系数很高,F检验值2201.081,明显显著。
计量经济学第八讲

三、多重共线性的检验 (一) 相关系数检验利用相关系数可以分析解释变量之间的两两相关情况。
在EViews 软件中可以直接计算(解释)变量的相关系数矩阵: [命令方式]COR 解释变量名[菜单方式]将所有解释变量设置成一个数组,并在数组窗口中点击View\Correlations. (二) 辅助回归模型检验相关系数只能判断解释变量之间的两两相关情况,当模型的解释变量个数多于两下、并且呈现出较为复杂的相关关系时,可以通过每个解释变量对其他解释变量的辅助回归模型来检验多重共线性,即依次建立k 个辅助回归模型:k i x a x a x a x a a x kki i i i i,,1111111=++++++=++--ε如果,其中某些方程显著,则表明存在多重共线性,所对应的变量可以近似地用其他解释变量线性表示。
辅助回归模型检验不仅能检验多元回归模型的多重共线性,而且可以得到多重共线性的具体形式;如果再结合偏相关关系检验,还能进一步判定是哪些解释变量引起了多重共线性,这有助于分析如何消除多重共线性的影响。
(三) 方差膨胀因子检验对于多元线性回归模型,ib ˆ的方差可以表示成:iijiiijiVIF x x R x x b D ∙∑-=-∑-=22222)(11)()ˆ(σσ其中,i i x R 为2关于其他解释变量辅助回归模型的判定系数,i VIF 为方差膨胀因子。
随着多重共线性程度的增强,VIF 以及系数估计误差都在增大。
因此,可以用VIF 作为衡量多重共线性的一个指标;一般当10>VIF 时,(此时9.02>iR ),认为模型存在较严重的多重共线性。
另一个与VIF 等价的指标是“容许度”(Tolerance ),其定义为:iiiVIF R TOL /1)1(2=-=显然,10≤≤TOL ,当i x 与其他解释变量高度相关时,0→TOL 。
因此,一般当1.0<TOL 时,认为模型存在较严重的多重共线性。
多重共线性的检验和解决的实验报告1

多重共线性的检验和解决的实验报告1
实验三报告
⼀、实验⽬的:
1.掌握多重共线性的识别⽅法
2.能针对具体问题提出解决多重共线性问题的措施
⼆、实验步骤:
1 相关系数法检验多重共线性
( 1 )点击Eviews6.reg注册然后点击Eviews6.exe
(2) 在file —new —workfile 在start date 和end date 输⼊1960、1982点击确定
(3) 在proc中找到import输⼊Excel 表并在弹出的对话框中输⼊Y X2 X3 X4
X5 X6 检查数据输⼊是否正确
(4)在Eviews 编辑框中输⼊ls Y C X1 X2 X3 X4 进⾏回归,结果如下t值
检验不符合。
说明解释变量之间很可能存在多重共线性。
2 画图法检验是否存在多重共线性:
在quick 中点击Graph在弹出的对话框中输⼊X1 Y 、X2 Y、X3 Y X4 Y点击确定,分别选择scatter 选择带回归线,分别可以看出各⾃变量与Y之间的线性关系,也说明解释变量之间可能存在多重共线性。
综合以上两种检验说明解释变量之间存在多重共线性。
3多重共线性的补救措施(逐步回归法):
(1)分别对四个⾃变量进⾏回归,选拟合优度最⼤的X1作为基本⽅程即Y=-12.45554+0.117845X1,采⽤逐步回归法分别对其进⾏回归
通过以上实验得到i i i x x x 321i 1856.38818.11036.05926.127y
+-+-= Y-X1-X2(留,可决系数升⾼,符号正确)-X3(留,可决系数升⾼,符号正确)
-X4(删,可决系数升⾼,X4的系数不显著)。
如何进行回归模型的诊断检验什么是多重共线性

如何进行回归模型的诊断检验什么是多重共线性如何进行回归模型的诊断检验——什么是多重共线性回归模型是统计学中常用的一种分析方法,用于研究自变量与因变量之间的关系。
然而,当回归模型存在问题时,我们需要进行诊断检验,以确保模型的可靠性和准确性。
本文将重点探讨回归模型的诊断检验方法,同时介绍多重共线性的概念和影响。
一、模型假设在进行回归模型的诊断检验之前,我们首先需要了解模型的基本假设。
回归模型的基本假设包括线性关系、误差项的正态分布、同方差性和误差项的独立性。
如果这些假设不满足,将影响模型的结果和推断。
二、常见的回归模型诊断检验方法1. 残差分析残差是实际观测值与回归模型的预测值之间的差异。
通过对残差进行分析,我们可以评估回归模型中是否存在异常值、离群点和非线性关系。
常见的残差分析方法包括残差图、QQ图和残差的自相关检验。
(这里可以具体介绍如何绘制和解读残差图和QQ图,以及如何进行残差的自相关检验)2. 杂项检验在回归模型中,杂项是指未被模型解释的因素。
通过对杂项进行检验,我们可以判断模型是否被未考虑的因素扰动。
常见的杂项检验方法包括D-W检验、Breusch-Pagan检验和White检验。
(这里可以具体介绍杂项检验的原理和步骤)3. 多重共线性检验多重共线性指的是回归模型中多个自变量之间存在高度相关的情况,从而导致模型估计的不稳定性和可靠性下降。
为了检验多重共线性,常见的方法包括方差膨胀因子(VIF)和条件数。
(这里可以具体介绍VIF和条件数的计算方法和阈值判断)三、什么是多重共线性多重共线性是指回归模型中存在高度相关的自变量,从而导致参数估计的不准确性。
多重共线性不仅会影响模型的解释能力和预测准确度,还会使得回归系数的符号和大小发生变化,增加了解释模型的难度。
多重共线性的判断主要是通过计算变量之间的相关系数来完成。
一般认为,当变量间的相关系数大于0.7或0.8时,存在高度的多重共线性。
多重共线性的影响主要体现在模型估计的不稳定性、参数的不准确性以及变量的显著性判断上。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
实验目的:在回归模型牵涉到多个自变量的时候,自变量之间可能会相互关联,即他们之间存在有多重共线性,本节实验的实验目的是如何用Eviews检测各个自变量之间是否存在的多重共线问题以及如何对多重共线性进行修正。
我们实验的原始数据如图所示,判断钢产量y与生铁产量X1,发电量X2,固定资产投资X3,国内生产总值X4,铁路运输量X5之间的关系。
实验步骤:1:打开Eviews7.0. →File→Workfile,选择年度数据,在初始日期和结束日期分别输入“1978”和结束年份“1997”。
点击“OK”确定。
2:在新建工作表中,点击Proc→Import→Read,选定需要导入的Excel工作表,在“Upper-left data cell”中输入数据在Excel中的初始位置“B2”,在“Excel 5+….”中输入“sheet1”,在“Name for serises、”中输入“y x1 x2 x3 x4 x5”点击“OK”即可。
3:在Eviews空白处输入:“ls y c x1 x2 x3 x4 x5”,回车即可,结果如下。
Dependent Variable: YMethod: Least SquaresDate: 04/19/13 Time: 11:24Sample: 1978 1997Included observations: 20Variable Coefficient Std. Error t-Statistic Prob.C 354.5884 435.6968 0.813842 0.4294X1 0.026041 0.120064 0.216892 0.8314X2 0.994536 0.136474 7.287380 0.0000X3 0.392676 0.086468 4.541271 0.0005X4 -0.085436 0.016472 -5.186649 0.0001X5 -0.005998 0.006034 -0.994019 0.3371R-squared 0.999098 Mean dependent var 5153.450 Adjusted R-squared 0.998776 S.D. dependent var 2512.131 S.E. of regression 87.87969 Akaike info criterion 12.03314 Sum squared resid 108119.8 Schwarz criterion 12.33186 Log likelihood -114.3314 Hannan-Quinn criter. 12.09145 F-statistic 3102.411 Durbin-Watson stat 1.919746 Prob(F-statistic) 0.000000经查表可知,t(17)=1.345,结合上表可知,x1和x5没有通过t检验,而且F\检验较大,估计解释变量之间可能存在着多重共线性。
相关性如下图所示:可知X1 X2 X3 X4 X5,之间存在着较强的多重共线我们分别用y和xi做线性回归,结果如下图所示。
R-squared 0.994453 Mean dependent var 5153.450 R-squared 0.995411 Mean dependent var 5153.450 R-squared 0.930148 Mean dependent var 5153.450 R-squared 0.939387 Mean dependent var 5153.450 R-squared 0.879348 Mean dependent var 5153.450可知拟合由强到弱的顺序依次是:X2 X1 X4 X3 X5,我们选定拟合最好的X2作为基准变量,分别导入X1 X4 X3 X5做回归,结果如下:C -287.6867 101.2341 -2.841797 0.0113X2 0.487185 0.112687 4.323352 0.0005 X1 0.415867 0.117497 3.539376 0.0025X1的t统计量为3.539376,而t0.01(17)=1.333,处于拒绝区域,则拒绝零假设,保存X1变量。
然后我们一X2 X1为解释变量,对X3 X4 X5做回归,结果如下:C -260.7822 215.8307 -1.208272 0.2445X2 0.490976 0.119095 4.122544 0.0008X1 0.405060 0.142867 2.835232 0.0119X3 0.004554 0.031986 0.142378 0.8886Variable Coefficient Std. Error t-Statistic Prob.C -393.0125 195.3528 -2.011808 0.0614X2 0.491128 0.114888 4.274839 0.0006X1 0.443259 0.127166 3.485687 0.0031X4 -0.003932 0.006196 -0.634662 0.5346Variable Coefficient Std. Error t-Statistic Prob.C -188.8822 495.0822 -0.381517 0.7078X2 0.502528 0.138221 3.635681 0.0022X1 0.407267 0.128082 3.179734 0.0058X5 -0.000970 0.004752 -0.204146 0.8408可知解释变量X3 X4 X5的t 统计量均小于t0.01(17)=1.3334,接受零假设,即X3 X4 X5前面的系数为零,可以删除,只保留解释变量X2 X1 ,回归结果如下图示。
Variable Coefficient Std. Error t-Statistic Prob. C -287.6867 101.2341 -2.841797 0.0113 X2 0.487185 0.112687 4.323352 0.0005 R-squared0.997358 Mean dependent var 5153.450 Adjusted R-squared 0.997047 S.D. dependent var 2512.131 S.E. of regression 136.5096 Akaike info criterion 12.80815 Sum squared resid 316792.9 Schwarz criterion 12.95751 Log likelihood -125.0815 F-statistic 3208.727回归结果:( 2.841797) (3.539376) (4.323352)y=-287.6867+0.415867X1+0.487185X2 -下面我们再次对修正后的模型进行序列相关检验和异方差检验.序列相关性检验此时t 统计量均能通过检验,但是DW 为0.692473,经查表可知,存在着序列相关性。
又因为DW=2(1-p ),得p=0.6538,以此我们可以用广义差分法再次回归,在这里我们用另一种方法,Cochrane-Orcutt 法估计模型,回归结果如图所示。
C -214.1697 162.8751 -1.314932 0.2083 X1 0.515590 0.118979 4.333443 0.0006 X2 0.375872 0.116493 3.226572 0.0056 AR(1)0.5825210.1863163.1265220.0069 R-squared0.998626 Mean dependent var 5308.474 Adjusted R-squared 0.998351 S.D. dependent var 2480.737 S.E. of regression 100.7230 Akaike info criterion 12.24729 Sum squared resid 152176.9 Schwarz criterion 12.44612 Log likelihood -112.3492 F-statistic 3634.613 Inverted AR Roots.58此时,DW=1.589375,du<DW<4—du ,表明模型中不存在自相关。
回归方程为:( 1.314932) (4.333443) (3.226572)214.16970.51559010.375872X2 y X -=-++异方差性检验我们对方程再次检验异方差性,如下图:White Heteroskedasticity Test: F-statistic 0.900529 Probability 0.489771 Obs*R-squared3.888180 Probability 0.421351Test Equation:Dependent Variable: RESID^2 Method: Least Squares Date: 04/19/13 Time: 23:41 Sample: 1979 1997 Variable Coefficient Std. Error t-Statistic Prob. C -48641.86 42241.01 -1.151532 0.2688 X1 24.88128 45.16291 0.550923 0.5904 X1^2 -0.002558 0.003265 -0.783372 0.4465 X2 -6.771283 37.99257 -0.178227 0.8611 R-squared0.204641 Mean dependent var 8009.308 Adjusted R-squared -0.022604 S.D. dependent var 16252.35 S.E. of regression 16435.01 Akaike info criterion 22.47315 Sum squared resid 3.78E+09 Schwarz criterion 22.72169 Log likelihood -208.4949 F-statistic 0.900529 Durbin-Watson stat2.428196 Prob(F-statistic)0.489771由于22T*R m χ (),检验结果显示2T*R =3.888180,且约束条件的个数m=4,经查表可知2=9.448χ0.05(4),即22T*R m χ<(),落在非拒绝区域,即原方程不存在异方差性。