Pgsql学习笔记
PLsql学习笔记

PL/SQL学习笔记PLSQL特有的%TYPE属性来声明与XX类型一致的变量类型:举例:...v_st_name%TYPE;v_min_balancev_balance%TYPE:= 10;...可绑定变量(Bind Variable 也称为Host Variable , 非PLSQL 变量):可绑定变量是一种在缩主环境中定义的变量,所谓缩主环境一般指示SQLPLUS执行环境或者是PLSQL Developer 的Command Window执行环境;可绑定变量可用于在运行时把值传递给PLSQL, 创建语法:V ARIABLE return_codeNUMBERV ARIABLE return_msgV ARCHAR2(30)大家注意,在标准的PLSQL中定义变量是不能用V ARIABLE关键字的,此关键字只在SQLPLUS执行环境中有效,可使用PRINT语句输出变量内容。
在PLSQL中使用这种变量时,前面加”:”, 以示区分。
SELECT INTO 语句:用于把从数据库查询出内容存入变量BEGININSERT INTO employees(employee_id, first_name, last_name, email,hire_date, job_id, salary)V ALUES(employees_seq.NEXTV AL, 'Ruth', 'Cores', 'RCORES',sysdate, 'AD_ASST', 4000);END;循环语句的语法与其他语言类似:有基本循环、For循环、Wihle循环三种LOOPstatement1;. . .EXIT [WHEN condition];END LOOP;WHILE condition LOOPstatement1;statement2;. . .END LOOP;FOR counter IN [REVERSE]lower_bound..upper_bound LOOPstatement1;statement2;. . .END LOOP;概述:PLSQL中常用的自定义类型就两种:记录类型、PLSQL内存表类型(根据表中的数据字段的简单和复杂程度又可分别实现类似于简单数组和记录数组的功能)记录类型的定义语法:TYPE type_name IS RECORD(field_declaration[, field_declaration]…);identifiertype_name;这里的field_declaration 的具体格式可以是:field_name {field_type | variable%TYPE| table.column%TYPE | table%ROWTYPE}[[NOT NULL] {:= | DEFAULT} expr]%ROWTYPE属性:在PLSQL中%ROWTYPE 表示某张表的记录类型或者是用户指定以的记录类型,使用此属性可以很方便的定义一个变量,其类型与某张表的记录或者自定义的记录类型保持一致。
old郭带你学postgresql 笔记

old郭带你学postgresql 笔记Old郭带你学PostgreSQL 笔记在当今互联网时代,数据大爆炸已经成为家常便饭。
而PostgreSQL 作为一种高可靠、可扩展的开源数据库,逐渐成为了开发者的首选。
本文将由老师Old郭带领大家来学习PostgreSQL,并记录下本人的学习笔记。
一、PostgreSQL 的安装步骤:1.官网下载PostgreSQL2.安装后检查是否配置成功3.安装好后找到"SQL shell"打开4.输入密码二、PostgreSQL 的基本使用方法1.查看数据库\l2.连接到数据库连接到数据库后可以进行一系列操作,如创建表、插入数据等操作。
3.创建数据库在连接数据库后,输入以下命令创建一个名为"test"的数据库:CREATE DATABASE test;4.创建表在数据库中首先要创建表,这是对数据进行操作的基础。
下面的列举了一些常用的数据类型:INT:整型VARCHAR:可变长度字符串CHAR:定长字符串FLOAT:浮点数DOUBLE:双精度浮点数DATE:日期TIME:时间DATETIME:日期时间CREATE TABLE table_name(column_name data_type);例如创建一张名为"Student"的表,包含"name"和"age"两个字段:CREATE TABLE Student(name VARCHAR(20),age INT);5.插入数据INSERT INTO table_name(column1,column2,...)VALUES(value1,value2,...);例如向上一步创建的名为"Student"的表中插入一条数据:INSERT INTO Student(name,age) VALUES('Tom',18);6.查询SELECT column_name1,column_name2,... FROM table_name WHERE filter_conditions;其中,filter_conditions可以是某个具体的值,也可以是某种范围。
PostgreSQL学习手册(目录)

PostgreSQL学习⼿册(⽬录)事实上之前有很长⼀段时间都在纠结是否有必要好好学习它,但是始终都没有⼀个很好的理由说服⾃⼰。
甚⾄是直到这个项⽬最终决定选⽤PostgreSQL时,我都没有真正意识到学习它的价值,当时只是想反正和其它数据库差不多,能⽤就⾏了。
然⽽有⼀天晚上,⾃⼰也不知道为什么,躺在床上开始回想整个项⽬的实施过程,想着想着就想到了数据库选型这⼀问题上了。
事情是这样的,最初客户将他们的产品⽬标定位为主打中型规模,同时也要在⼀定程度上⽀持⼩型规模。
鉴于此,我们为他们提供的⽅案是中型规模的数据库选⽤Oracle,⼩型规模的选定MySQL,在经过多轮商谈之后这个⽅案通过了。
然⽽随着项⽬的深⼊,客户突然有⼀天提出,由于成本和市场推⼴等问题,该产品的数据库部分需要进⾏⼀定的调整,调整的结果是中型规模可以同时⽀持Oracle和MySQL,⽽⼩型规模则要同时⽀持MySQL和PostgreSQL,原因⾮常简单,PostgreSQL是纯免费的数据库产品。
听到这个消息之后,我当时就⾮常恼⽕,因为当初为了保证运⾏时效率(国标),我们的数据库访问层是完全基于数据库供应商提供的原始C接⼝开发的,甚⾄都没有考虑ODBC提供的原始C接⼝,以防在转换中失去效率,或是ODBC本⾝为了强调通⽤性⽽不得不牺牲某些数据库的优化特征,如批量插⼊、批量读取等。
最后的结果显⽽易见,客户就是上帝,上帝的意见就是真理,这样我们就不得不基于现有的访问层接⼝⼜重新开发了⼀套⽀持PostgreSQL原⽣C接⼝的驱动。
然⽽随着对PostgreSQL的不断学习,对它的了解也在逐步加深,后来发现它的功能还是⾮常强⼤的,特别是对GIS空间数据的⽀持就更加的吸引我了。
于是就在脑⼦⾥为MySQL和PostgreSQL做了⼀个简单的对⽐和分析,最后得出⼀个结论,相⽐MySQL,PostgreSQL并没有什么刚性的缺点,但是它的纯免费特征确实是MySQL⽆法⽐拟的。
Oracle深度学习笔记内存架构之PGASQLWork区

5.Oracle深度学习笔记——内存架构之PGA SQL Work 区
SQL工作区域是用于内存密集型操作的从PGA内存分配的。
例如排序操作,会使用排序区域来排序一组行。
同样,哈希连接操作使用哈希区域来从左边输入来建立哈希表。
此外,bitmap merge使用位图合并区域来从合并多个位图索引中获取的数据。
如果,操作的数据综合不能放到工作区域,那么ORACLE会把输入的数据劈成更小的片。
当然,多余的会先放到临时磁盘空间,后续处理。
当自动PGA内存管理使能的时候,数据库自动调整工作区域大小。
通常,大的工作区域可能明显提升操作性能,当然代价是消耗很多的内存。
最好的是,工作区域大小足浴容纳输入的数据和相关SQL操作需要的辅助内存结构。
如果不够大,输入的数据将会被放到磁盘上,那么响应时间就会增大。
在极端CASE下,如果工作区域和输入的数据相比实在太小,数据库必须多次将数据分片,大大增加响应时间。
PGA在专有服务器和共享服务器模式下的分配区别如下图1:。
Pgsql学习笔记

Pgsql学习笔记1、PGSQL自动递增序列的做法首先,在声明该列时用SERIAL类型,然后用setval(‘序列发生器’,递增的初始值)函数设置列的初始值,其中‘序列发生器’可以在表建好后,在系统生成的有关该表的SQL脚本中找到。
其次,在使用时只要调用nextval(‘序列发生器名称’)就可以了。
2、数组构造器,用关键字ARRAY。
行构造器,用关键字row()主要用途可以用在判断某字段是否为空。
3、类型转换的两种方式:CAST ( expression AS type )或expression::type,其expression为需要转换的表达式、type为要转为的类型。
4、可以用以下语句来重命名一个表或者字段重命名一字段:ALTER TABLE 表名 RENAME 字段名 TO 新的字段名重命名表名:ALTER TABLE 表名 RENAME TO 新的表名5、类型 decimal 和 numeric 是等效的。
常用的整型为integer,6、PGSQL实现取第一调记录的方法是在SQL语句后面加上limit 1 。
7、HAVING字句的作用是:当分组后需要加上条件是用HAVING不能用WHERE,而且HAVING子句中可以包含聚合函数。
WHERE 和 HAVING 的基本区别如下: WHERE 在分组和聚集计算之前选取输入行(因此,它控制哪些行进入聚集计算),而 HAVING 在分组和聚集之后选取分组的行。
因此,WHERE 子句不能包含聚集函数;因为试图用聚集函数判断那些行输入给聚集运算是没有意义的。
相反,HAVING 子句总是包含聚集函数。
(严格说来,你可以写不使用聚集的 HAVING 子句,但这样做很少有用。
同样的条件可以更有效地用于 WHERE 阶段。
)8、随机查询一个表中的一条记录的的语句SELECT column FROM table ORDER BY RANDOM() LIMIT 19、PGSQL中几种字符串类型的比较:类型内部名称说明VARCHAR(n) varchar 指定了最大长度,变长字符串,不足定义长度的部分不补齐CHAR(n) bpchar 定长字符串,实际数据不足定义长度时,以空格补齐TEXT text 没有特别的上限限制(仅受行的最大长度限制)BYTEA bytea 变长字节序列(使用NULL也是允许的)"char" char 一个字符由上表可以看出,一般情况下为了避免空格带来的麻烦可以选用VARCHAR(n)这种方式来申明一个字符串10.创建序列号CREATE TABLE person (id SERIAL, --实际上PGSQL是通过SERIAL这种数据类型来实现序列号功能的name TEXT);11、在触发器中有两种对象:NEW和OLD(对于INSERT 和UPDATE 触发器而言,是NEW 行,对于DELETE 触发器而言,是OLD 行)12、触发器实例首先建立一个posts表CREATE TABLE posts(id serial NOT NULL,title character varying(50),body text,created timestamp with time zone DEFAULT now(),modified timestamp with time zone DEFAULT now())WITHOUT OIDS;ALTER TABLE posts OWNER TO postgres;建立触发器函数-- Function: posts_insert()-- DROP FUNCTION posts_insert();CREATE OR REPLACE FUNCTION posts_insert()RETURNS "trigger" AS$BODY$beginif(NEW.title <> 'aaaa')thenNEW.body='ce shi chu fa';end if;return NEW;end$BODY$LANGUAGE 'plpgsql' VOLATILE;ALTER FUNCTION posts_insert() OWNER TO postgres;建立触发器CREATE TRIGGER p_b_insertBEFORE INSERTON postsFOR EACH ROWEXECUTE PROCEDURE posts_insert();13、PGSQL中存在事务的保存点SAVEPOINT,当在事务中设置了保存点,一旦发生错误我们不用回滚到事务的开始,用ROLLBACK TO可以直接回滚到指定的保存点。
PGSQL存储过程学习
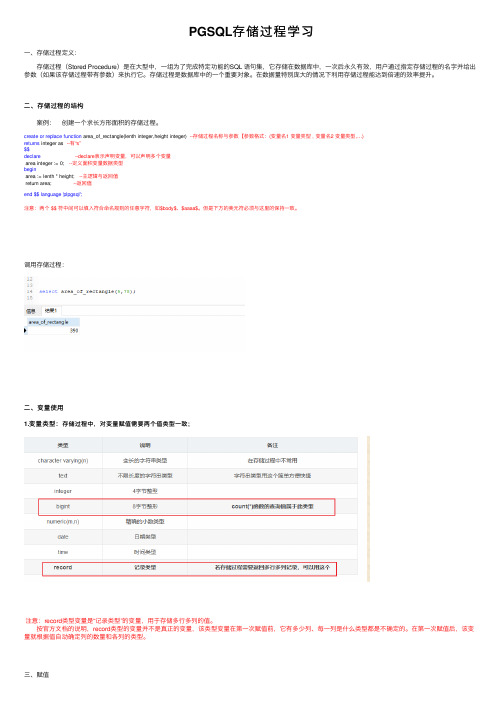
PGSQL存储过程学习⼀、存储过程定义:存储过程(Stored Procedure)是在⼤型中,⼀组为了完成特定功能的SQL 语句集,它存储在数据库中,⼀次后永久有效,⽤户通过指定存储过程的名字并给出参数(如果该存储过程带有参数)来执⾏它。
存储过程是数据库中的⼀个重要对象。
在数据量特别庞⼤的情况下利⽤存储过程能达到倍速的效率提升。
⼆、存储过程的结构 案例: 创建⼀个求长⽅形⾯积的存储过程。
create or replace function area_of_rectangle(lenth integer,height integer) --存储过程名称与参数【参数格式:(变量名1 变量类型 , 变量名2 变量类型,…)returns integer as --有“s”$$declare --declare表⽰声明变量,可以声明多个变量area integer := 0; --定义⾯积变量数据类型beginarea := lenth * height; --主逻辑与返回值return area; --返回值end $$ language 'plpgsql';注意:两个 $$ 符中间可以填⼊符合命名规则的任意字符,如$body$、$aaaa$。
但是下⽅的美元符必须与这⾥的保持⼀致。
调⽤存储过程:⼆、变量使⽤1.变量类型:存储过程中,对变量赋值需要两个值类型⼀致;注意:record类型变量是“记录类型”的变量,⽤于存储多⾏多列的值。
按官⽅⽂档的说明,record类型的变量并不是真正的变量,该类型变量在第⼀次赋值前,它有多少列、每⼀列是什么类型都是不确定的。
在第⼀次赋值后,该变量就根据值⾃动确定列的数量和各列的类型。
三、赋值 3.1、静态赋值: student_name := '张静'; 3.2、动态赋值: select name into student_name from class where stu_No = 1; --或者 execute 'select name from class where stu_No = 1' into student_name;四、基本流程语句:存储过程中,使⽤RAISE NOTICE可以在运⾏时将变量输出显⽰4.1、if语句IF ... THEN ... END IF;IF ... THEN ... ELSE ... END IF;IF ... THEN ... ELSE ... THEN ... ELSE ... END IF;--例:if student_name = '张静' thenRAISE NOTICE '我是张静';else if student_name like '%李%' thenRAISE NOTICE '我姓李';elseRAISE NOTICE '我不是张静,也不姓李';4.2、case语句CASE ... WHEN ... THEN ... ELSE ... END CASE;CASE WHEN ... THEN ... ELSE ... END CASE;--例:case student_name when '张静','晓静' thenRAISE NOTICE '张静和晓静都是我的名称';elseRAISE NOTICE '你叫错名字了';end case;--例:case when student_name = '张静'or student_name = '晓静' thenRAISE NOTICE '张静和晓静都是我的名称';elseRAISE NOTICE '你叫错名字了';end case;4.3、循环[ <<label>> ]LOOP循环体语句;EXIT [ label ] [ WHEN 判断条件表达式 ];END LOOP [ label ];--例-计算1到100的和:sum := 0;i := 0;loopi := i + 1;sum := sum + i;exit when i = 100 ;end loop;RAISE NOTOCE '1到100的和为:%',sum;[ <<label>> ]WHILE 判断条件表达式 LOOP循环体语句;END LOOP [ label ];--例 - 计算1到100的和:sum := 0;i := 1;while i<=100 loopsum := sum + i;i := i + 1;end loopRAISE NOTOCE '1到100的和为:%',sum;[ <<label>> ]FOR 循环控制变量 IN [ REVERSE ] 循环范围 [ BY expression ] LOOP循环体语句;END LOOP [ label ];--计算1到100的和:--例1 - 循环执⾏过程类似于:for(i=1;i<=100;i++){}sum := 0;for i in 1..100 loopsum := sum + i;end loop;RAISE NOTOCE '1到100的和为:%',sum;--例2 - 循环执⾏过程类似于:for(i=100;i>=1;i--){}sum := 0;for i in REVERSE 100..1 loopsum := sum + i;end loop;RAISE NOTOCE '1到100的和为:%',sum;--计算1到100之间所有奇数的和--例3 - 循环执⾏过程类似于:for(i=1;i<=100;i=i+2){}sum := 0;for i in 1..100 by 2 loopsum := sum + i;end loop;RAISE NOTOCE '1到100的和为:%',sum;[ <<label>> ]FOR 变量 IN 查询语句 LOOP循环体语句;END LOOP [ label ];--例 - 遍历班级中每个⼈的名字:for student_name in select name from class loopRAISE NOTICE '姓名:%',student_name;end loop;四、查询并返回多条记录案例1:create or replace function f_get_member_info(id integer)returns setof record as --setof是关键字,暂时不清楚其作⽤;record是返回的数据类型,即记录类型数据;$$ --两个美元符必须存在,中间可以填⼊符合命名规则的字符(如$body$,$abc$),但必须与下⽅的两个美元符相统⼀declarerec record; --定义记录类型的变量,⽤于存储查询的结果begin--开始for循环,执⾏SELECT语句。
pgsql基础语法

pgsql基础语法在数据库领域中,pgsql是一种常用的关系型数据库管理系统。
掌握pgsql的基础语法是学习和使用该系统的前提条件。
本文将介绍pgsql的基础语法,包括创建数据库、创建表、插入数据、查询数据、更新数据和删除数据等操作。
一、创建数据库要创建数据库,可以使用CREATE DATABASE语句,语法如下:CREATE DATABASE database_name;其中,database_name是要创建的数据库的名称。
例如,要创建一个名为mydb的数据库,可以执行以下语句:CREATE DATABASE mydb;二、创建表在创建数据库之后,可以创建表来存储数据。
要创建表,可以使用CREATE TABLE语句,语法如下:CREATE TABLE table_name (column1 datatype,column2 datatype,column3 datatype,...);其中,table_name是要创建的表的名称,column1、column2等是表的列名,datatype是列的数据类型。
例如,要创建一个名为mytable的表,该表包含id、name和age三个列,可以执行以下语句:CREATE TABLE mytable (id serial PRIMARY KEY,name varchar(50),age integer);在上面的示例中,id列使用了serial数据类型,它是一种自增长的整数类型,并且被指定为主键。
三、插入数据在创建表之后,可以向表中插入数据。
要插入数据,可以使用INSERT INTO语句,语法如下:INSERT INTO table_name (column1, column2, column3, ...) VALUES (value1, value2, value3, ...);其中,table_name是要插入数据的表的名称,column1、column2等是表的列名,value1、value2等是要插入的值。
postgresql 常用sql 语句

一、概述PostgreSQL是一种功能强大的开源关系型数据库管理系统,广泛应用于各种规模和类型的应用程序中。
在使用PostgreSQL时,熟练掌握常用的SQL语句是非常重要的,可以帮助用户更高效地管理和操作数据库。
本文将介绍PostgreSQL中常用的SQL语句,帮助读者更好地使用这一数据库管理系统。
二、连接数据库1. 连接到数据库使用以下命令可以连接到PostgreSQL数据库:```psql -U username -d database_name```其中,-U参数用于指定用户名,-d参数用于指定要连接的数据库名称。
2. 退出数据库在连接到数据库后,可以使用以下命令退出数据库:```\q```三、数据库管理1. 创建数据库使用以下命令可以在PostgreSQL中创建数据库: ```CREATE DATABASE database_name;```2. 删除数据库若要删除数据库,可以使用以下命令:```DROP DATABASE database_name;```四、表操作1. 创建表使用以下命令可以在数据库中创建表:```CREATE TABLE table_name (column1 datatype,column2 datatype,column3 datatype,...);```2. 删除表若要删除表,可以使用以下命令:```DROP TABLE table_name;```五、数据操作1. 插入数据使用以下命令可以向表中插入数据:```INSERT INTO table_name (column1, column2, column3, ...) VALUES (value1, value2, value3, ...);```2. 查询数据查询表中的数据可以使用以下命令:```SELECT column1, column2, ...FROM table_nameWHERE condition;```3. 更新数据若要更新表中的数据,可以使用以下命令:```UPDATE table_nameSET column1 = value1, column2 = value2, ...WHERE condition;```4. 删除数据若要删除表中的数据,可以使用以下命令:```DELETE FROM table_nameWHERE condition;```六、数据过滤1. 按条件过滤使用WHERE子句可以对查询结果进行条件筛选,例如: ```SELECT *FROM table_nameWHERE column1 = value;```2. 模糊查询若要进行模糊查询,可以使用LIKE运算符,例如:```SELECT *FROM table_nameWHERE column1 LIKE 'value';```七、数据排序1. 升序排序若要按升序对查询结果进行排序,可以使用以下命令: ```SELECT *FROM table_nameORDER BY column1 ASC;```2. 降序排序若要按降序对查询结果进行排序,可以使用以下命令: ```SELECT *FROM table_nameORDER BY column1 DESC;```八、聚合函数1. 求和使用SUM函数可以对数据列进行求和操作,例如:```SELECT SUM(column1)FROM table_name;```2. 平均值若要计算数据列的平均值,可以使用AVG函数:```SELECT AVG(column1)FROM table_name;```3. 计数使用COUNT函数可以统计行数或满足条件的行数,例如: ```SELECT COUNT(*)FROM table_name;九、数据分组1. 分组统计若要对数据进行分组统计,可以使用GROUP BY子句,例如:```SELECT column1, COUNT(*)FROM table_nameGROUP BY column1;```2. 分组筛选若要对分组后的数据进行筛选,可以使用HAVING子句:```SELECT column1, COUNT(*)FROM table_nameGROUP BY column1HAVING COUNT(*) > 1;```十、连接表1. 内连接使用INNER JOIN可以连接两个表,并返回满足连接条件的行,例```SELECT *FROM table1INNER JOIN table2ON table1.column1 = table2.column2;```2. 左连接若要返回左表中所有行以及与其关联的右表中的行,可以使用LEFT JOIN:```SELECT *FROM table1LEFT JOIN table2ON table1.column1 = table2.column2;```十一、子查询1. 标量子查询若要返回单一值的子查询结果,可以使用标量子查询,例如:```SELECT column1,(SELECT MAX(column2) FROM table2) AS max_value FROM table1;```2. 列表子查询使用列表子查询可以返回一列多行结果,例如:```SELECT column1FROM table1WHERE column1 IN (SELECT column2 FROM table2); ```十二、索引1. 创建索引若要在表的一个或多个列上创建索引,可以使用以下命令: ```CREATE INDEX index_nameON table_name (column1, column2, ...);```2. 删除索引若要删除索引,可以使用以下命令:```DROP INDEX index_name;```十三、事务管理1. 开始事务使用以下命令可以开始一个事务:```BEGIN;```2. 提交事务若要将未提交的事务更改保存到数据库中,可以使用以下命令: ```COMMIT;```3. 回滚事务若要撤销未提交的事务更改,可以使用以下命令:```ROLLBACK;```十四、权限管理1. 授权若要授予用户对数据库或表的特定操作许可,可以使用GRANT命令:```GRANT permissionON object_nameTO user_name;```2. 撤销权限若要撤销用户对数据库或表的特定操作许可,可以使用REVOKE命令:```REVOKE permissionON object_nameFROM user_name;```3. 角色管理使用CREATE ROLE命令可以创建新角色,使用ALTER ROLE命令可以修改角色,使用DROP ROLE命令可以删除角色。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Pgsql学习笔记RAISE NOTICE '%', a;--输出1、PGSQL自动递增序列的做法首先,在声明该列时用SERIAL类型,然后用setval(‘序列发生器’,递增的初始值)函数设置列的初始值,其中‘序列发生器’可以在表建好后,在系统生成的有关该表的SQL脚本中找到。
其次,在使用时只要调用nextval(‘序列发生器名称’)就可以了。
2、数组构造器,用关键字ARRAY。
行构造器,用关键字row()主要用途可以用在判断某字段是否为空。
3、类型转换的两种方式:CAST ( expression AS type )或expression::type,其expression为需要转换的表达式、type为要转为的类型。
4、可以用以下语句来重命名一个表或者字段重命名一字段:ALTER TABLE 表名 RENAME 字段名 TO 新的字段名重命名表名:ALTER TABLE 表名 RENAME TO 新的表名5、类型 decimal 和 numeric 是等效的。
常用的整型为integer,6、PGSQL实现取第一调记录的方法是在SQL语句后面加上limit 1 。
7、HAVING字句的作用是:当分组后需要加上条件是用HAVING不能用WHERE,而且HAVING子句中可以包含聚合函数。
WHERE 和 HAVING 的基本区别如下: WHERE 在分组和聚集计算之前选取输入行(因此,它控制哪些行进入聚集计算),而 HAVING 在分组和聚集之后选取分组的行。
因此,WHERE 子句不能包含聚集函数;因为试图用聚集函数判断那些行输入给聚集运算是没有意义的。
相反,HAVING 子句总是包含聚集函数。
(严格说来,你可以写不使用聚集的 HAVING 子句,但这样做很少有用。
同样的条件可以更有效地用于 WHERE 阶段。
)8、随机查询一个表中的一条记录的的语句SELECT column FROM table ORDER BY RANDOM() LIMIT 19、PGSQL中几种字符串类型的比较:类型内部名称说明VARCHAR(n) varchar 指定了最大长度,变长字符串,不足定义长度的部分不补齐CHAR(n) bpchar 定长字符串,实际数据不足定义长度时,以空格补齐TEXT text 没有特别的上限限制(仅受行的最大长度限制)BYTEA bytea 变长字节序列(使用NULL也是允许的)"char" char 一个字符由上表可以看出,一般情况下为了避免空格带来的麻烦可以选用VARCHAR(n)这种方式来申明一个字符串10.创建序列号CREATE TABLE person (id SERIAL, --实际上PGSQL是通过SERIAL这种数据类型来实现序列号功能的name TEXT);11、在触发器中有两种对象:NEW和OLD(对于INSERT 和UPDATE 触发器而言,是NEW 行,对于DELETE 触发器而言,是OLD 行)12、触发器实例首先建立一个posts表CREATE TABLE posts(id serial NOT NULL,title character varying(50),body text,created timestamp with time zone DEFAULT now(),modified timestamp with time zone DEFAULT now())WITHOUT OIDS;ALTER TABLE posts OWNER TO postgres;建立触发器函数-- Function: posts_insert()-- DROP FUNCTION posts_insert();CREATE OR REPLACE FUNCTION posts_insert()RETURNS "trigger" AS$BODY$beginif(NEW.title <> 'aaaa')thenNEW.body='ce shi chu fa';end if;return NEW;end$BODY$LANGUAGE 'plpgsql' VOLATILE;ALTER FUNCTION posts_insert() OWNER TO postgres;建立触发器CREATE TRIGGER p_b_insertBEFORE INSERTON postsFOR EACH ROWEXECUTE PROCEDURE posts_insert();13、PGSQL中存在事务的保存点SAVEPOINT,当在事务中设置了保存点,一旦发生错误我们不用回滚到事务的开始,用ROLLBACK TO可以直接回滚到指定的保存点。
BEGIN;UPDATE accounts SET balance = balance - 100.00WHERE name = 'Alice';SAVEPOINT my_savepoint;UPDATE accounts SET balance = balance + 100.00WHERE name = 'Bob';-- 呀!加错钱了,应该用 Wally 的账号ROLLBACK TO my_savepoint;UPDATE accounts SET balance = balance + 100.00WHERE name = 'Wally';COMMIT;14、PGSQL表与表之间还支持继承,一旦子表继承了父表,那么子就拥有了父表的多有字段信息。
如:下面的例子capitals继承了cities。
CREATE TABLE cities (name text,population real,altitude int -- (单位是英尺));CREATE TABLE capitals (state char(2)) INHERITS (cities);输入这句SQL:” select * from capitals”会出现下面的情况15、限制和级联删除是两种最常见的选项,外键参照时有一下几个选项控制级联删除:(1)、RESTRICT禁止删除被引用的行。
(2)、NO ACTION的意思是如果在检查约束的时候,如果还存在任何引用行,则抛出错误;如果你不声明任何东西,那么它就是缺省的行为。
(这两个选择的实际区别是,NO ACTION 允许约束检查推迟到事务的晚些时候,而RESTRICT不行。
)(3)、CASCADE声明在删除一个被引用的行的时候,引用它的行也会被自动删除掉。
(4)、在外键字段上的动作还有两个选项:SET NULL和SET DEFAULT。
这样会导致在被引用行删除的时候,引用它们的字段分别设置为空或者缺省值。
请注意这些选项并不能让你逃脱被观察和约束的境地。
比如,如果一个动作声明SET DEFAULT,但是缺省值并不能满足外键,那么动作就会失败。
(5)、类似ON DELETE,还有ON UPDATE选项,它是在被引用字段修改(更新)的时候调用的。
可用的动作是一样的。
16、给表重命名“ALTER TABLE products RENAME TO items;”17、日期函数18、数组数据类型的下标从1开始。
19、UPDATE TAB1 SET(COL1,COL2,COL3)=(TAB2.COL1,TAB2.COL2,TAB2.COL3) FROM TAB2 <WHERE>语法20、单引号,pgsql的sql语句中单引号转义用两个单引号。
21、字符串处理函数PostgreSQL修改数据库表的列属性(ALTER语句)2010-08-03 15:03:11| 分类:数据库技术 |举报|字号订阅我们可以用客户端的语句改写,psql比如把数据库表journal里的keyword,ekeyword属性改为character(350),原来为character(200),那么我们可以这样操作:psql postgres -c "ALTER TABLE journal ALTER keyword TYPE character(350)"psql postgres -c "ALTER TABLE journal ALTER ekeyword TYPE character(350)"好了,修改结束。
描述ALTER TABLE 变更一个现存表的定义。
它有好几种子形式:ADD COLUMN这种形式用和 CREATE TABLE 里一样的语法向表中增加一个新的字段。
DROP COLUMN这种形式从表中删除一个字段。
请注意,和这个字段相关的索引和表约束也会被自动删除。
如果任何表之外的对象依赖于这个字段,你必须说 CASCADE,比如,外键参考,视图等等。
ALTER COLUMN TYPE这种类型改变表中一个字段的类型。
该字段涉及的索引和简单的表约束将被自动地转换为使用新的字段类型,方法是重新分析最初提供的表达式。
可选的 USING 子句声明如何从旧的字段值里计算新的字段值;如果省略,那么缺省的转换就是从旧类型像新类型的赋值转换。
如果从旧数据类型到新类型没有隐含或者赋值的转换,那么必须提供一个 USING。
SET/DROP DEFAULT这种形式为一个字段设置或者删除缺省值。
请注意缺省值只应用于随后的 INSERT 命令;它们不会导致已经在表中的行的数值的修改。
我们也可以为视图创建缺省,这个时候它们是在视图的 ON INSERT 规则应用之前插入 INSERT 语句中去的。
SET/DROP NOT NULL这些形式修改一个字段是否标记为允许 NULL 值或者是拒绝 NULL 值。
如果表在字段中包含非空值,那么你只可以 SET NOT NULL。
SET STATISTICS这个形式为随后的 ANALYZE 操作设置每字段的统计收集目标(default_statistics_target)。
目标的范围可以在 0 到 1000 之内设置;另外,把他设置为 -1 则表示重新恢复到使用系统缺省的统计目标。
有关 PostgreSQL 查询规划器使用的统计信息的更多信息,请参考Section 13.2。
SET STORAGE这种形式为一个字段设置存储模式。
这个设置控制这个字段是内联保存还是保存在一个附属的表里,以及数据是否要压缩。
PLAIN 必需用于定长的数值,比如 integer,并且是内联的,不压缩的。
MAIN 用于内联,可压缩的数据。
EXTERNAL 用于外部保存,不压缩的数据,而 EXTENDED 用于外部的压缩数据。