256 257 258字符编码
国家代码和邮编
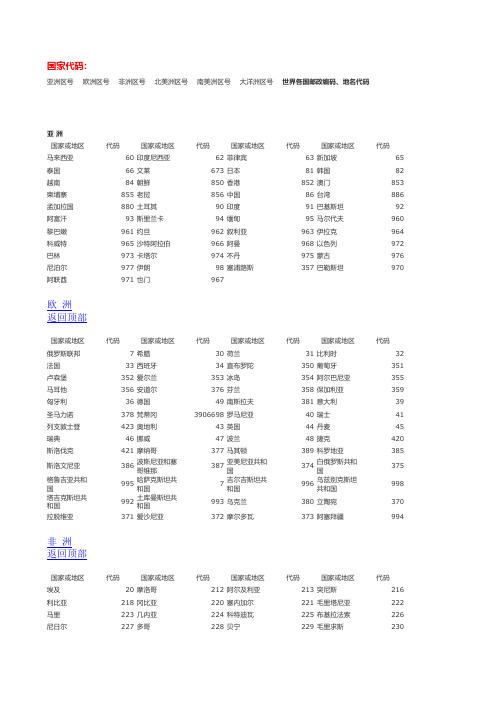
塞内加尔999066SNJE伊朗999067YL莫桑比克999068MSB扎伊尔999069ZYE肯尼亚999070KNY阿根廷999071AGT巴拿马999072BNM圭亚那999073GYN巴西999074BX古巴999075GB哥伦比亚999076GLB以色列999080YSL俄罗斯999081ELS拉脱维亚999082LTW克罗地亚999083KLD秘鲁999084ML墨西哥999085MXG马耳他999086MET阿富汗999087AFH沙特阿拉伯999088ST巴林999089BL不丹999090BD缅甸999091MD文莱达鲁萨兰999092WLDLSL 朝鲜999093CX柬埔寨999094JPZ黎巴嫩999095LBN马尔代夫999096MEDF蒙古999097MG尼泊尔999098NBE叙利亚999099XLY越南999100YN也门999101YM 亚速尔群岛和马德拉群岛999102YSEMDL阿尔及利亚999103AEJLY安哥拉999104AGL贝宁999105BN博茨瓦纳999106BCWN 布隆迪999107BLD喀麦隆999108KML 加那利群岛999109JNL佛得角999110FDJ中非999111ZF科摩罗999112KML 冈比亚999113GBY几内亚比绍999114JNYBS 赤道几内亚999115CDJNY利比亚999116LBY莱索托999117LST利比里亚999118LBLY 马拉维999119MLW毛里求斯999120MLQS 毛里塔尼亚999121MLTNY纳米比亚999122NMBY 乌干达999123WGD留尼汪岛999124LNW圣多美和普林西比999125SDMPLX塞舌耳999126SSE 塞拉利昂999127SLLA索马里999128SML 苏丹999129SD圣赫勒拿岛999130SHLN 斯威士兰999131SWSL坦桑尼亚999132TSNY 多哥999133DG赞比亚999134ZBY津巴布韦999135JBBW南非999136NF阿尔巴尼亚999137AEBNY安道尔999138ADE 保加利亚999139BJLY科西嘉999140KXJ直布罗陀999141ZBLT冰岛999142BD列支敦士登999143LZDSD摩纳哥999144MNG 圣马力诺999145SMLN乌克兰999146WKL 白俄罗斯999147BELS爱沙尼亚999148ASNY 立陶宛999149LTW南斯拉夫999150NSLF斯洛文尼亚999151SLWNY 安提瓜和巴布达999152ATGBBD荷属安的列斯群岛999153ADLS巴哈马999154BHM 巴巴多斯999155BBDS伯利兹999156BLZ百慕大群岛999157BMD玻利维亚999158BLWY开曼群岛999159KM智利999160ZL哥斯达黎加999161GSDLJ多米尼加联邦999162DMNJLB多米尼加共和国999163DMNJGH萨尔瓦多999164SEWD 厄瓜多尔999165EGDE格林纳达999166GLND瓜德罗普岛999167GDLP危地马拉999168WDML 法属圭亚那999169GYN海地999170HD洪都拉斯999171HDLS牙买加999172YMJ马尔维纳斯群岛999173MEWNS马提尼克岛999174MTNK 蒙特塞拉特岛999175MTSLT尼加拉瓜999176NJLG巴拉圭999177BLG波多黎个999178BDLG圣克里斯托夫和尼维斯岛999179SKLSTF圣卢西亚岛999180SLXY圣文森特和格林纳丁斯岛999181SWSTGL苏里南999182SLN特立尼达和多巴哥999183TLNDDB特克斯和凯科斯群岛999184TKSKKS乌拉圭999185WLG 美属维尔京群岛999186WEJ英属维尔京群岛999187WEJ委内瑞拉999188WNRL 基里巴斯999189JLBS马绍尔999190MSE 加罗林999191JLL马里亚纳群岛999192MLYN瑙鲁999193NL 新喀里多尼亚岛999194XKLDNY法属波利尼西亚999196BLNXY所罗门群岛999197SLM西萨摩亚999198XSMY东萨摩亚999199DSMY 汤加999200TJ图瓦卢999201TWL瓦努阿图999202WNAT夏威夷群岛999203XWY关岛999204GD中途岛999205ZTD威克岛999206WKD阿塞拜疆999207ASBJ 摩尔多瓦999208MEDW亚美尼亚999209YMNY 斐济999210FJ斯特歇斯岛999211STXS 格陵兰岛999212GLLD库腊索999213KLS阿鲁巴999214ALB博内尔999215BNE圣马丁999216SMD萨巴999217SB圣尤斯特歇999218SYSTXS圣诞岛999219SDD诺福克群岛999220NFKQD科科斯群岛999221KKSQD 洛德豪岛999222LDHD社会999223SH土布艾999224TBA土阿莫土999225TAMT 马克萨斯999226MKSS甘比尔999227GBE巴斯群岛999228BSQD腊帕岛999229LPD乌兹别克斯坦999033。
汉字编码表

附表二:常用汉字输入3位数码表001 002 003 004A:安暗按案005 006 007 008009 010 011 012013 014 015 B:吧八白百败班般板半包办016 017 018 019020 021 022 023024 025 026 棒帮薄保报北备被本泵比027 028 029 030031 032 033 034035 036 037 闭边编变标表滨宾丙病并038 039 040 041042 043 044玻播波补不布部C:045046 047 048049 050 051 052053 054055 裁材财彩菜餐参仓藏操草056057 058 059 060 061 062 063064 065 066 厕策侧册测层茶查察差柴067068 069 070 071072 073 074 075076 077 产场常长厂超朝巢车陈称078079 080 081082 083 084 085086 087 088 城成程吃持池此充冲初出089090 091 092093 094 095 096097 098 099 厨除储处川传船串窗春磁100101 102 103 104105 106次从粗翠存错萃D:107 108 109 110 111 112 113 114 115 116 117 达打答大带代待丹单当党118 119 120 121 122 123 124 125 126 127 128档岛导到道盗德得的等登129 130 131 132 133 134 135 136 137 138 139灯低笛迪底地第点电店吊140 141 142 143 144 145 146 147 148 149 150调碟顶定订东动栋都督毒151 152 153 154 155 156 157 158杜度段断堆队对多E:159 160 161 162儿耳尔二F:163 164 165 166 167 168 169 170 171 172 173 发阀法返范芳方房防访放174 175 176 177 178 179 180 181 182 183 184 非啡肥费分粉封风凤否185 186 187 188 189 190 191 192 193 194 195 符扶服福副复付负附芙赋196 197翡翻G:198 199 200 201 202 203 204 205 206 207 208 该改干感港高告歌格隔个209 210 211 212 213 214 215 216 217 218 219各更工功公共购故关观管220 221 222 223 224 225 226 227 228 229 230馆灌光广瑰规桂柜贵果锅231 232国过H:233 234 235 236 237 238 239 240 241 242 243 哈海韩汉航豪好号浩荷和244 245 246 247 248 249 250 251 252 253 254 合河黑恒烘宏红候后呼忽255 256 257 258 259 260 261 262 263 264 265 护户花华画划化话环缓换266 267 268 269 270 271 272 273 274 275 276 黄皇恢回惠会混活火或货J:277 278 279 280 281 282 283 284 285 286 287 基机激辑吉集急即级技季288 289 290 291 292 293 294 295 296 297 298 剂寄计记际继纪夹佳家加299 300 301 302 303 304 305 306 307 308 309 甲架监间检键件健建江讲310 311 312 313 314 315 316 317 318 319 320 胶交角教界接街节捷洁金321 322 323 324 325 326 327 328 329 330 331 津紧锦仅进禁荆靖京精经332 333 334 335 336 337 338 339 340 341 342 警镜九酒救旧居据菊局巨343 344 345 346俱鹃卷菌K:347 348 349 350 351 352 353 354 355 356 357 咖卡开康颗科可克客肯空358 359 360 361 362 363 364控口库块快框困L:365 366 367 368 369 370 371 372 373 374 375 拉腊来蓝兰览缆廊劳老乐376 377 378 379 380 381 382 383 384 385 386 类冷离理礼莉丽历力璃联387 388 389 390 391 392 393 394 395 396 397 连帘两凉量亮疗料淋零龄398 399 400 401 402 403 404 405 406 407 408 铃领令流六龙隆楼漏炉鲁409 410 411 412 413 414 415 416 417 418 419 露路录率滤绿略逻榈浏锂M:420 421 422 423 424 425 426 427 428 429 430 码麦卖满漫帽每玫没梅煤431 432 433 434 435 436 437 438 439 440 441 美门秘密面秒灭明名命模442 443 444 445 446 447 448 449 450 451膜磨摩默沫牡母幕木茉N:452 453 454 455 456 457 458 459 460 461 462 拿耐南男囊脑内能尼拟年463 464 465 466 467 468凝宁牛钮女挪P:469 470 471 472 473 474 475 476 477 478 479 排牌盘判乓旁泡配喷烹膨480 481 482 483 484 485 486 487 488 489 490 啤皮片卜票品聘乒平瓶屏491 492 493坡铺普Q:494 495 496 497 498 499 500 501 502 503 504 七其棋齐企启起器期气汽505 506 507 508 509 510 511 512 513 514 515 千前潜腔蔷强抢桥切秦青516 517 518 519 520 521 522 523 524 525 526 清请求球区取去泉全却确527 528雀裙R:529 530 531 532 533 534 535 536 537 538 539 燃然热人任认日蓉荣容肉540 541 542 543乳入软弱S:544 545 456 457 548 549 550 551 552 553 554 洒腮三散桑色沙杉山删扇555 556 557 558 559 560 561 562 563 564 565 膳商上稍舍摄射涉社设身566 567 568 569 570 571 572 573 574 575 576 深神沈审声生是失师狮湿577 578 579 580 581 582 583 584 585 586 587 十石时食实始史式示世事588 589 590 591 592 593 594 595 596 597 598 释饰市室视试收受手首售599 600 601 602 603 604 605 606 607 608 609 输疏书熟术竖数属刷栓双610 611 612 613 614 615 616 617 618 619 620 水税斯司四送素速塑宿算621 622锁所T:623 624 625 626 627 628 629 630 631 632 633 谈它台泰态檀探堂棠唐桃634 635 636 637 638 639 640 641 642 643 644 套特腾梯提体天填条跳厅645 646 647 648 649 650 651 652 653 654 655 停庭通桐统投头脱突图途656 657团退W:658 659 660 661 662 663 664 665 666 667 668 外湾委尾未位卫为威围薇669 670 671 672 673 674 675 676 677 678 679 维委尾未位卫温文稳卧680 681 682 683 684 685 686 687 688 689乌污无梧五舞雾物务误X:690 691 692 693 694 695 696 697 698 699 700 析西吸息洗系细下仙鲜显701 702 703 704 705 706 707 708 709 710 711 现限线厢香相箱祥响削销712 713 714 715 716 717 718 719 720 721 722 消小效鞋协写卸新心信星723 724 725 726 727 728 729 730 731 732 733 兴行型行杏性休修许蓄序734 735 736 737 738 739 740 741 742 743续选学血熏循询寻讯馨Y:744 745 746 747 748 749 750 751 752 753 754 压雅亚烟研岩延演验央洋755 756 757 758 759 760 761 762 763 764 765 阳药要业页液一医衣移仪766 767 768 769 770 771 772 773 774 775 776 已以乙艺役意忆议异因音777 778 779 780 781 782 783 784 785 786 787 银饮印樱应营迎影映用邮788 789 790 791 792 793 794 795 796 797 798 油游有右虞娱与语玉育玉799 800 801 802 803 804 805 806 807 808 809 浴寓预域元原园员源远苑810 811 812 813 814 815院月阅允运阈Z:816 817 818 819 820 821 822 823 824 825 826 杂灾载在暂燥造则择增轧827 828 829 830 831 832 833 834 835 836 837 展站障招照这珍阵蒸征整838 839 840 841 842 843 844 845 846 847 848 正政郑枝支知脂织直值址849 850 851 852 853 854 855 856 857 858 859 指止只纸置制智治中终钟860 861 862 863 864 865 866 867 868 869 870 种重周洲珠竹主柱贮筑注871 872 873 874 875 876 877 878 879 880 881 专转庄装壮准桌咨紫子自882 883 884 885 886 887 888 889 890 891 892 字棕综总走足组左作座圳893最其它:894 895 896 897 898 899 900 901 902 903 904 ABCDEFGHIJK905 906 907 908 909 910 911 912 913 914 915 LMNOPQRSTUV916 917 918 919 920 921 922 923 924 925 926 WXYZ0123456927 928 929 930 931 932 933789()别欠。
各国电话代码

亚洲马来西亚 60亚洲印度尼西亚 62亚洲菲律宾 63亚洲新加坡 65亚洲泰国 66亚洲关岛 671亚洲文莱 673亚洲日本 81亚洲韩国 82亚洲越南 84亚洲朝鲜 850亚洲柬埔寨 855亚洲老挝 856亚洲中国 86亚洲孟加拉国 880亚洲土耳其 90亚洲印度• 91亚洲巴基期坦•92亚洲斯里兰卡• 94亚洲马尔代夫 961亚洲黎巴嫩 962亚洲约旦 963亚洲叙利亚 964亚洲伊拉克 965亚洲科威特 966亚洲沙特阿拉伯 967亚洲阿拉伯也门共和国 968亚洲阿曼 969亚洲阿拉伯联合酋长国 972亚洲以色列 973亚洲巴林 974亚洲卡塔尔 975亚洲不丹 976亚洲蒙古 977亚洲尼泊尔 978亚洲伊朗 98亚洲阿富汗 93洲名称地区名称邮政编码电话区号欧洲俄罗斯 7欧洲希腊 30欧洲荷兰 31欧洲比利时 32欧洲法国 33欧洲摩纳哥 3393欧洲安道尔 33628欧洲西班牙 34欧洲加那利群岛 3422欧洲直布罗陀 350欧洲葡萄牙 351欧洲卢森保 352欧洲爱尔兰 353欧洲冰岛 354欧洲阿尔巴尼亚 355欧洲马耳他 356欧洲塞浦路斯 357欧洲芬兰 358欧洲保加利亚 359欧洲匈牙利 336欧洲德国 349欧洲南斯拉夫 338欧洲意大利 39欧洲圣马力诺 39549欧洲梵蒂冈 396欧洲罗马尼亚 40欧洲瑞士 41欧洲列士敦士登 4175欧洲奥地利 43欧洲英国 44欧洲丹麦 45欧洲瑞典 46欧洲挪威 47欧洲法兰 48洲名称地区名称邮政编码电话区号美洲美国 1美洲加拿大 1美洲中途岛 1808美洲威克岛 1808美洲夏威夷 1808美洲安圭拉岛 1809美洲维尔京群岛 1809美洲特立尼达和多巴哥 1809美洲圣卢西亚 1809美洲圣克里斯托费和尼维斯 1809 美洲波多黎各 1809美洲蒙特塞拉特岛 1809美洲牙买加 1809美洲格林纳达 1809美洲多米尼加共和国 1809美洲开曼群岛 1809美洲百慕大群岛 1809美洲安提瓜和巴布达 1809美洲巴哈马 1809美洲巴巴多斯 1809美洲特克斯和凯科斯群岛 1809美洲阿拉斯加 1907美洲法罗群岛 298美洲格陵兰岛 299美洲伯利兹 501美洲危地马拉 502美洲萨尔瓦多 503美洲洪都拉斯 504美洲尼加拉瓜 505美洲哥斯达黎加 506美洲巴拿马 507美洲海地 509美洲墨西哥 52美洲古巴 53美洲福克兰群岛 500美洲秘鲁 51美洲阿根延 54美洲巴西 55美洲智利 56美洲哥伦比亚 57美洲委内瑞拉 58美洲玻利维亚 591美洲圭亚那 592美洲厄瓜多尔 593美洲法属圭亚那 594美洲巴拉圭 595美洲马提尼克 596美洲苏里南 597美洲乌拉圭 598美洲荷属安的列斯群岛 599美洲圣文桑特岛和格雷纳丁斯 1809 洲名称地区名称邮政编码电话区号大洋洲澳大利亚 61大洋洲新西兰 64大洋洲马里亚纳群岛 670大洋洲科科斯岛 6722大洋洲诺福克岛 6723大洋洲圣庭岛 6724大洋洲瑙鲁 674大洋洲巴布亚新几内亚 675大洋洲汤加 676大洋洲所罗门群岛 677大洋洲瓦努阿图 678大洋洲斐济 679大洋洲科克群岛 682大洋洲纽埃岛 683大洋洲东萨摩亚 684大洋洲西萨摩亚 685大洋洲基里巴斯 686大洋洲新喀里多尼亚群岛 687大洋洲图瓦卢 688大洋洲法属波里尼西亚 689洲名称地区名称邮政编码电话区号非洲埃及 20非洲摩洛哥 210非洲阿尔及利亚 213非洲突尼斯 216非洲利比亚 218非洲冈比亚 220非洲塞内加尔 221非洲毛里塔尼亚 222非洲马里 223非洲几内亚 224非洲科特迪瓦 225非洲布基纳法索 226非洲尼日尔 227非洲多哥 228非洲贝宁 229非洲毛里求斯 230非洲利比里亚 231非洲塞拉利昴 232非洲加纳 233非洲尼日利亚 234非洲乍得 235非洲中非 236非洲喀麦隆 237非洲佛得角 238非洲圣多美和普林西比 239非洲赤道几内亚 240非洲加蓬 241非洲刚果 242非洲扎伊尔 243非洲安哥拉 244非洲几内亚比绍 245非洲阿森松 247非洲塞舌尔 248非洲苏丹 249非洲卢旺达 250非洲埃塞俄比亚 251 非洲索马里 252非洲吉布提 253非洲肯尼亚 254非洲坦桑尼亚 255 非洲乌干达 256非洲布隆迪 257非洲莫桑比克 258 非洲赞比亚 260非洲马达加斯加 261 非洲留尼旺岛 262 非洲津巴布韦 263 非洲纳米比亚 264 非洲马拉维 265非洲莱索托 266非洲博茨瓦纳 267 非洲斯威士兰 268 非洲科摩罗 269非洲南非 27非洲圣赫勒拿 290 非洲阿鲁巴岛 297。
ch01计算机中的数和码

2、OV:溢出标志。专为判断带符号数运 算是否发生溢出而设置。OV=1,有溢出; OV=0,未溢出。
PSW PSW.7 PSW.6 PSW.5 PSW.4 PSW.3 PSW.2 PSW.1 PSW.0
(D0H) CY AC F0 RS1 RS0 OV
-
P
运算对标志的影响举例
0000 0011 3 +0000 1100 +12
转十进制 并冠以“+”
结束
例1-7
求11100101
+46
补码的运算:
通过引进补码,可将减法运算转换为加 法运算。规则如下:
[X+Y]补=[X]补+[Y]补
[X-Y]补=[X]补- [Y]补= [X]补+[-Y]补
其中X,Y为正负数均可,符号与数值统一编码参与运 算。
内容提要
1.有限字长的二进制数 2.十进制与二进制的转换 3.带符号二进制数的表示及其运算 4.溢出及运算的有效性 5.BCD码 6.ASCII码
1、有限字长的二进制数
二进制记数法 二进制数:用0和1两个数码来表示的数。 如果数的后面有后缀“B”,表示二进制数
n1
NB Bi 2i im
例1-1:101B = 5
0 ≤ X ≤ 2n-1 ;
带符号整数的二进制表示
具有三种表示方法 原码
反码
补码
原码以最高位为符号位,“0”表示正,“1”表 示负;其余的位是绝对值;
1字节时,绝对值为7位,数值范围是 ±0~±127;2字节时,绝对值为15位,数值 范围是±0~±32767;
原码表示中“0”有“+0”和“-0”;
补码的表示范围: -2n-1< x <+2n-1-1
世界电话编码

1 -- 北美洲号码计划区2 -- 大部分是非洲地区3 -- 欧洲4 -- 欧洲5 -- 墨西哥和中南美洲6 -- 东南亚及大洋洲7 - 俄罗斯及附近地区(前苏联)8 -- 东亚以及特殊服务9 - 西亚及南亚、中东* 1:美国* 1:加拿大* 20 -- 埃及* 210 -- 未分配。
此号码原先留给摩洛哥* 211 -- 未分配。
此号码原先留给摩洛哥* 212 -- 摩洛哥* 213 -- 阿尔及利亚* 214 -- 未分配。
此号码原先留给阿尔及利亚* 215 -- 未分配。
此号码原先留给阿尔及利亚* 216 -- 突尼斯* 217 -- 未分配。
此号码原先留给突尼斯* 218 -- 利比亚* 219 -- 未分配。
此号码原先留给利比亚* 220 -- 冈比亚* 221 -- 塞内加尔* 222 -- 毛里塔尼亚* 223 -- 马里* 224 -- 几内亚* 225 -- 科特迪瓦* 226 -- 布基纳法索* 227 -- 尼日尔* 228 -- 多哥* 229 -- 贝宁* 230 -- 毛里求斯* 231 -- 利比里亚* 232 -- 塞拉利昂* 233 -- 加纳* 234 -- 尼日利亚* 235 -- 乍得* 236 -- 中非共和国* 237 -- 喀麦隆* 239 -- 圣多美和普林西比* 240 -- 赤道几内亚* 241 -- 加蓬* 242 -- 刚果共和国(布)* 243 -- 刚果民主共和国(金)(即前扎伊尔)* 244 -- 安哥拉* 245 -- 几内亚比绍* 246 -- 迪戈加西亚* 247 -- 阿森松岛* 248 -- 塞舌尔* 249 -- 苏丹* 250 -- 卢旺达* 251 -- 埃塞俄比亚* 252 -- 索马里* 253 -- 吉布提* 254 -- 肯尼亚* 255 -- 坦桑尼亚* 256 -- 乌干达* 257 -- 布隆迪* 258 -- 莫桑比克* 259 -- 桑西巴 - 从未使用――参见255坦桑尼亚* 260 -- 赞比亚* 261 -- 马达加斯加* 262 -- 留尼汪* 263 -- 津巴布韦* 264 -- 纳米比亚* 265 -- 马拉维* 266 -- 莱索托* 267 -- 博茨瓦纳* 268 -- 斯威士兰* 269 -- 科摩罗和马约特* 27 -- 南非* 28x -- 未分配* 290 -- 圣赫勒拿* 291 -- 厄立特里亚* 292 -- 未分配* 293 -- 未分配* 294 -- 未分配* 295 -- 中止(原先分配给圣马力诺,参见+378)* 296 -- 未分配* 297 -- 阿鲁巴* 298 -- 法罗群岛* 299 -- 格陵兰* 31 -- 荷兰* 32 -- 比利时* 33 -- 法国* 34 -- 西班牙* 350 -- 直布罗陀* 351 -- 葡萄牙* 352 -- 卢森堡* 353 -- 爱尔兰* 354 -- 冰岛* 355 -- 阿尔巴尼亚* 356 -- 马耳他* 357 -- 塞浦路斯* 358 -- 芬兰* 359 -- 保加利亚* 36 -- 匈牙利* 37 -- 曾经是东德的区号,合并后的德国区号为49 * 370 -- 立陶宛* 371 -- 拉脱维亚* 372 -- 爱沙尼亚* 373 -- 摩尔多瓦* 374 -- 亚美尼亚* 375 -- 白俄罗斯* 376 -- 安道尔* 377 -- 摩纳哥* 378 -- 圣马力诺* 379 -- 保留给梵蒂冈* 38 -- 前南斯拉夫分裂前的区号* 380 -- 乌克兰* 381 -- 塞尔维亚* 382 -- 黑山 (黑山)* 383 -- 未分配* 384 -- 未分配* 385 -- 克罗地亚* 386 -- 斯洛文尼亚* 387 -- 波黑* 388 -- 欧洲电话号码空间――环欧洲服务* 389 -- 马其顿(前南斯拉夫马其顿共和国, FYROM)* 39 -- 意大利* 40 -- 罗马尼亚* 41 -- 瑞士* 42 -- 曾经是捷克斯洛伐克的区号* 420 -- 捷克共和国* 422 -- 未分配* 423 -- 列支敦士登* 424 -- 未分配* 425 -- 未分配* 426 -- 未分配* 427 -- 未分配* 428 -- 未分配* 429 -- 未分配* 43 -- 奥地利* 44 -- 英国* 45 -- 丹麦* 46 -- 瑞典* 47 -- 挪威* 48 -- 波兰* 49 -- 德国* 500 -- 福克兰群岛* 501 -- 伯利兹* 502 -- 危地马拉* 503 -- 萨尔瓦多* 504 -- 洪都拉斯* 505 -- 尼加拉瓜* 506 -- 哥斯达黎加* 507 -- 巴拿马* 508 -- 圣皮埃尔岛及密克隆岛* 509 -- 海地* 51 -- 秘鲁* 52 -- 墨西哥* 53 -- 古巴(本应属于北美区,由于历史原因分在5区)* 54 -- 阿根廷* 55 -- 巴西* 56 -- 智利* 57 -- 哥伦比亚* 58 -- 委内瑞拉* 590 -- 瓜德罗普* 591 -- 玻利维亚* 592 -- 圭亚那* 593 -- 厄瓜多尔* 594 -- 法属圭亚那* 595 -- 巴拉圭* 596 -- 马提尼克* 597 -- 苏里南* 598 -- 乌拉圭* 599 -- 荷属安的列斯* 60 -- 马来西亚* 61 -- 澳大利亚* 62 -- 印度尼西亚* 63 -- 菲律宾* 64 -- 新西兰* 65 -- 新加坡* 66 -- 泰国* 670 -- 东帝汶- 曾经是北马里亚纳群岛(现在是1)* 671 -- 曾经是关岛(现在是1)* 672 -- 澳大利亚海外领地:南极洲、圣诞岛、可可斯群岛、和诺福克岛* 673 -- 文莱* 674 -- 瑙鲁* 675 -- 巴布亚新几内亚* 676 -- 汤加* 677 -- 所罗门群岛* 678 -- 瓦努阿图* 679 -- 斐济* 680 -- 帕劳* 681 -- 沃利斯和富图纳群岛* 682 -- 库克群岛* 683 -- 纽埃* 684 -- 美属萨摩亚* 685 -- 萨摩亚* 686 -- 基里巴斯,吉尔伯特群岛* 687 -- 新喀里多尼亚群岛* 688 -- 图瓦卢,埃利斯群岛* 689 -- 法属波利尼西亚* 690 -- 托克劳群岛* 691 -- 密克罗尼西亚联邦* 692 -- 马绍尔群岛7 -- 俄罗斯、哈萨克斯坦81 -- 日本* 82 -- 韩国* 83x -- 未分配* 84 -- 越南* 850 -- 朝鲜* 851 -- 未分配* 852 -- 香港* 853 -- 澳门* 854 -- 未分配* 855 -- 柬埔寨* 856 -- 老挝* 857 -- 未分配* 858 -- 未分配* 859 -- 未分配* 86 -- 中国* 870 -- Inmarsat "SNAC" service* 871 -- Inmarsat (大西洋东)* 872 -- Inmarsat (太平洋)* 873 -- Inmarsat (印度洋)* 874 -- Inmarsat (大西洋西)* 875 -- 预留给海洋移动通讯服务* 876 -- 预留给海洋移动通讯服务* 877 -- 预留给海洋移动通讯服务* 878 -- 环球个人通讯服务* 879 -- 预留给国家移动/海洋使用* 880 -- 孟加拉国* 881 -- 移动卫星系统* 882 -- 国际网络* 883 -- 未分配* 884 -- 未分配* 885 -- 未分配* 886 -- 台湾(非正式分配,国际电讯联盟本身的记录是“预留”)* 90 -- 土耳其* 91 -- 印度* 92 -- 巴基斯坦* 93 -- 阿富汗* 94 -- 斯里兰卡* 95 -- 缅甸* 960 -- 马尔代夫* 961 -- 黎巴嫩* 962 -- 约旦* 963 -- 叙利亚* 964 -- 伊拉克* 965 -- 科威特* 966 -- 沙特阿拉伯* 967 -- 也门* 968 -- 阿曼* 969 -- 曾经是也门民主共和国的区号,现在和967也门的区号合并* 970 -- 预留给巴勒斯坦* 971 -- 阿拉伯联合酋长国* 972 -- 以色列* 973 -- 巴林* 974 -- 卡塔尔* 975 -- 不丹* 976 -- 蒙古* 977 -- 尼泊尔* 978 -- 未分配* 979 -- International Premium Rate Service* 98 -- 伊朗* 990 -- 未分配* 991 -- International Telecommunications Public Correspondence Service trial (ITPCS) * 992 -- 塔吉克斯坦* 993 -- 土库曼斯坦* 994 -- 阿塞拜疆* 995 -- 格鲁吉亚* 996 -- 吉尔吉斯斯坦* 997 -- 未分配* 998 -- 乌兹别克斯坦* 999 -- 保留,可能移作紧急救援。
200-299数字谐音编码

200张明敏201爱淋雨202克拉克203爱莲说204入殓师205安乐窝206熔炼炉207卖力气208日历表209干辣椒210人易老211任盈盈212按一按213日月山214荣誉室215呆鹦鹉216喝饮料217任意球218扔硬币219太阳镜220 紫竹林221爱戴你222鹅鹅鹅223热热身224喝热水225猛如虎226入海流227扔暗器228周润发229猪肉卷230中山陵231按手印(安徽凤阳小岗村18位农民按下18个红手印232中山装233 (猫扑表情233表示好笑)234做善事235妊娠纹236扔手雷237注射器238肉松饼239乳酸菌240总司令241饿死你(二十三,饿一天。
二十四,忌口日。
二十五,要空腹。
二十六,看看肉。
二十七,想想鸡。
二十八,闻闻鸭。
二十九,送你走)242人吃人243住宿生244肇事车245热水壶246猪饲料247热水器248和氏璧249紫水晶250核物理251爱乌鸦252核污染253润肤霜254詹姆斯255周武王256赠汪伦257任我行258支付宝259软猬甲260人流量261海洛因262如来掌263安禄山264俄罗斯265正露丸266干露露267蒸馏器268自律部269侏罗纪270竹蜻蜓271爱奇艺272爱琴海273日心说274日全食275足球袜276站起来277热气球278癌细胞279喝喜酒280若比邻(在刚果进行正式访问的国务院总理温家宝参观布拉柴中学时,温总走上讲台,在黑板上写下了“海内存知己,天涯若比邻”这句中国名言)281哥白尼282日本人283赵本山284占卜师285纸牌服286日不落287坐便器(马桶)288做爸爸290=250+38+2289染发剂290(二百五,三八,二,他全有)291歌剧院292终结者293氨基酸294针灸师295海军服296周杰伦297治脚气298日记本299爱久久。
《三国群英传7》完整秘籍编码(含武将编号)
《三国群英传7》完整秘籍编码(文字版)在有显示征战天下的界面输入cheatmodeopen,然后按回车键,屏幕中间会出现黑条,再一次输入cheatmodeopen,再按一次回车,秘籍开锁完成。
之后就可进入游戏了,在游戏的任何时候都可以输入想用的秘籍,先按右边的ctrl键,屏幕出现黑条,将输入的秘籍输进去后,按回车可完成。
例如添加物品:按右边的ctrl键后,黑条出现,输入addthing,空格键,物品编号,空格键,物品数量。
这样就可以了。
在进入游戏后的主界面,输入cheatmodeopen按下enter键启动秘籍(以后均是右Ctrl打开秘技输入)。
主界面:输入useeventnation按enter就可以扮演刘邦和项羽了(霸王在临隐藏关)!大地图:游戏直接胜利:mode overwin大地图时间加快:sftime 1~100 (数字越小速度越快)增加建物金钱:addvalue cmoney 建物编号金钱数物品加入国库:addthing 物品编号数量增加武将经验值:addvalue exp 武将编号经验值开启事件地点:openeventplace 事件地点编号选择出战部队界面:我方直接获胜:bfresult 0敌方直接获胜:bfresult 1改变我方兵种:st 兵种编号千人战界面:施放武将技:bm 武将技编号施放组合技:cbm 组合技编号施放情义技:bm 武将技编号时间暂停:time千人战以平局结束:bfover城市、关卡、港口编号1 西凉2 陇右3 安定4 弘农5 咸阳6 陈仓7 扶风8 街亭9 天水 10 雁门11 绛 12 平阳 13 晋阳 14 邺 15 虎牢 16 壶关 17 界桥 18 汜水 19 代郡 20 平原21 乌巢 22 濮阳 23 乐陵 24 南皮 25 高唐 26 北平 27 襄平 28 昌黎 29 乐浪 30 带方31 下卞 32 祈山 33 阳平 34 梓潼 35 成都 36 江州 37 五丈原 38 白水 39 上庸40 汉中 41 筑阳 42 蕸萌 43 巴郡 44 襄阳 45 白帝 46 临江 47 长阪波 48 乌林 49 郿50 长安 51 洛阳 52 宛 53 延津 54 官渡 55 新野 56 许昌 57 汝南 58 陈留 59 庐江60 谯 61 小沛 62 定陶 63 乐安 64 北海 65 都阳 66 下邳 67 徐州 68 淮安 69 盱眙70 寿春 71 合淝 72 江夏 73 夏口 74 赤壁 75 湘潭 76 桂阳 77 长沙 78 庐陵 79 南海80 豫章 81 区阿 82 建业 83 南昌 84 鄱阳 85 吴 86 会稽 87 松江 88 江陵 89 零陵90 桂林 91 涪陵 92 武陵 93 交趾 94 建宁 95 云南 96 夷州 97 鹿耳门 98 邪马台99阿苏 100出云 101 佐贺 102 阿久根 103下关特殊地点201 毒龙潭 202 猛虎穴 203 大雪山 204 火焰山 205 兽神洞 206 青龙塔 207 白虎塔208 玄武塔 209 朱雀塔 210 麒麟塔 211 桃源仙乡 212 尸洞 213 九泉之渊 224 黄沙寨225 天王寨 226 虎头寨 227 黑风寨 228 翻江寨 229 天柱山 230 洞庭坞 231 百花坞232 偃月坞 233 九里山 234 大兴山 235 飞凤寨 236 血蛟坞 237 百兽寨 238 巨熊寨239 纠云寨 240 龙王坞 241 白狼寨 252 金牛山 253 龙魂井 254 龙岳 255 万蛇坑256 先秦地监 257 紫金废矿 258 子午谷 259 地心眼 260 荒漠废营 261 百草林262 无名地穴 263 瘴气林 264 哑泉 265 柔泉 266 黑泉 267 灭泉 268 豹子269 云梦泽270 碧水地穴 271 景山洞窟 272 虎啸坡 273 疫鬼洞 274 瘟神谷 275 大夏泽 276 海隅泽277 玄冰窟 278 先秦荒冢 279 先秦古墓 280 大渚泽 281 罗刹谷 300 瀛洲岛 301 蓬莱岛所有兵种编号47 神剑禁卫 48 神枪禁卫 49 狻猊铁骑 50 星官 51 天狗 52 巫女 74 精锐翼弓兵75 天骑兵 90 高丽战鼓兵 91 高丽大刀兵 92 高丽女戟兵 98 恶夔骑兵所有道具编号及详解消耗品1 木铜铃2 尸兵符印3 秘忍卷轴4 将军印盒5 刀车兵符6 链球兵符7 剑兵兵符8 木槌兵符9 水兵兵符 10 匈奴号角 11 黄巾兵符 12 投石兵符13 弩车兵符 14 兽兵兵符 15 女兵兵符 16 蛮兵兵符 17 斧骑兵兵符616 弓骑兵兵符 617 舞娘兵符 618 龙炮兵令 619 天狗卷轴 620 巫女卷轴18 强弩兵兵符 19 长枪兵兵符 20 长弓兵兵符 21 重步兵兵符 22 箭矢阵法书23 天地阵法书 24 翔鹰阵法书 25 雁形阵法书 26 锥形阵法书 621 水镜阵法书30 珠宝 31 黄金 32 美女 33 玉器 34 绸缎 35 布匹 568 无暇玉璧569 龙纹白玉 570 四灵宝镜 567 金珠36 灵山妙药 37 九牛二虎丸 38 雪山灵芝 39 灵芝 40 长白人参 41 人参563 北斗天浆 564 玉屑金丹 565 薤叶芸香 566 琼浆玉液剑类武器42 干将莫邪 43 草剃 44 冰凤炎凰 45 仁义无双 46 寒铁双股剑47 巨阙剑 48 魑魅魍魉 49 逆天剑 50 倚天剑 51 虎牙剑52 皇天怒 53 飞星 54 流采 55 华铤 56 不知火57 七星刀 58 方土 59 东极 60 破山剑 61 青釭剑62 白虹 63 紫电 64 辟邪 65 流星 66 青冥67 百里 68 村正 70 流光 71 双股剑 72 太一73 凄然 75 风云斩 76 龙渊剑 77 龟纹 78 火精82 思召 762 不攻 767 明昭 768 血刃 769 邪月770 湛卢 771 莫邪 815 孔雀刺 817 鸳鸯圈 818 乾坤圈820 两仪剑 821 鱼肠 822 苍天帝剑 823 黄帝剑 824 追潮825 天羽斩 826 伪帝剑 791 雷斩刀 831 铃鼓扇类武器91 真火朱雀扇 92 朱雀扇 93 玄冥法扇 94 金羽扇 95 驭风剑翎扇96 火焰扇 97 天罡劈水扇 98 彩霓扇 99 孔雀扇 776 五光扇777 噬血扇 778 天罡扇 779 幽冥扇 780 玄冰扇 781 真火扇827 黯噬 828 蚀魂 829 五光宝扇大刀类武器111 翔龙偃月刀 112 青龙偃月刀 113 雷公鞭 114 虎贲大刀 115 日月双锤116 鳌头两刃斧 117 战国大刀 118 春秋大刀 119 混沌双斧 120 天罡斧121 混沌开天刀 123 波母 124 南极 125 编驹 128 车轮斧129 玄铁碎棍 130 鬼头大刀 131 阳枣锤 135 金瓜锤 224 UJ大鸡腿784 精铁偃月刀 786 八极刀 787 焰斩刀 788 干将 789 毒龙790 魂咬 792 太阿 793 赤霄 819 凤凰锤 830 炼狱魔刀832 泰山府君杖 833 奥汀多赖把 850 UJ玩具槌枪类武器157 神鬼方天戟 158 方天画戟 159 万胜丈八矛 160 丈八蛇矛 161 九天龙魂贯162 龙胆枪 163 霸王凤凰枪 164 凤凰枪 165 虎贲方天戟 166 神龙戈167 破军蒺藜枪 168 青天钩镰枪 169 西极 170 不周 171 龙髓枪172 应龙戟 173 紫龙戟 174 斩马钩镰枪 175 焰火尖枪 176 拐刃蒺藜枪177 双刃月牙戟 794 点睛 795 灼针 796 冰芒 800 锦牙枪801 蛇尖枪 802 虎胆枪 803 天羽凤凰枪 804 震雷青龙戟弓类武器205 万里起云烟 206 机铁连环弓 207 北极 208 追魂弓 209 爆炎弓210 神鸢弓 807 绝音弓 808 追星 810 落月 811 射魄812 黄忠弓 813 惊雷 814 机铁火神弓坐骑225 幼麒麟 226 黑麒麟 227 火麒麟 228 白玉麒麟 229 天马230 龙马 231 四不像 232 穷奇 233 飞镰 234 追风白凰235 紫金赤兔马 236 赤兔马 237 卷毛赤兔马 239 爪黄飞电 241 钢甲战马244 重甲黑豹 245 重甲战虎 246 燎原火 248 的卢 252 藤甲战牛257 黑豹 258 战虎 639 金甲雄狮 638 炼狱战马 637 通天战马641 鳞甲战狼 646 狻猊 645 白骨战马 644 兵马俑马 284 骷髅马道具285 西蜀地形图 286 幻世录Ⅱ 287 幻世录 288 兵书24篇 289 孟德新书290 史记 291 春秋左传 578 UJ好人卡 723 铁 724 钢 725 百炼钢726 精钢 727 神铁 728 青铜 729 流星铁 754 百斩钢所有武将技编号: 60伏兵连阵63后伏连阵230 超水龙狂涛 234 超地龙极震238 超风龙天旋 242 超火龙怒焰所有组合技编号: 507 兽皇破邪阵武将编号:1 丁奉2 丁原3 丁斐4 丁枫5 丁瑶6 丁仪7 刁玄8 李典9 於诠 10 士瑞孙11 士异 12 士壹 13 士碧 14 士徽 15 士变 16 大乔 17 小乔 18 山淘 19 公孙度20 公孙恭21 公孙康 22 公孙渊 23 公孙婷 24 公孙越 25 公孙范 26 公孙续 27 公孙瓒28 卞喜 29 天香 30 太史亨31 太史昭容 32 太史慈 33 孔月 34 孔秀 35 孔岫 36 孔羡37 孔融 38 文媛 39 文钦 40 文聘41 文芯 42 文鸯 43 文丑 44 方悦 45 毋丘俭46 毛玠 47 牛金 48 牛辅 49 王子服 50 王元姬51 王允 52 王方 53 王平 54 王伉55 王匡 56 王戎 57 王甫 58 王忠 59 王服 60 王威61 王若华 62 王昶 63 王修64 王朗 65 王烈 66 王真 67 王晟 68 王基 69 王祥 70 王累71 王植 72 王浑 73 王筠74 王经 75 王粲 76 王颀 77 王浚 78 王双 79 王览 80 令狐劭81 令狐愚 82 司马孚83 司马炎 84 司马昭 85 司马师 86 司马朗 87 司马衷 88 司马望 89 司马玲 90 司马玮91 司马徽 92 司马懿 93 左慈 94 甘若男 95 甘倩 96 甘宁 97 田欣 98 田楷 99 田豫100 田丰101 田畴 102 田续 103 申耽 104 申仪 105 石苞 106 石崇 107 伊大目108 伊默 109 伊藉 110 伏完111 伏寿 112 仲长统 113 全琮 114 全端 115 吉太116 吉穆 117 吉邈 118 向秀 119 向朗 120 向宠121 成宜 122 朱治 123 朱虹 124 朱桓125 朱异 126 朱然 127 朱损 128 朱隽 129 朱熊 130 朱褒131 朱据 132 朱灵 133 朱赞134 羊枯 135 羊道 136 羊徽瑜 137 何姬 138 何宴 139 何进 140 何蜜141 何仪142 冷苞 143 吾彦 144 吴子兰 145 吴臣 146 吴班 147 吴纲 148 吴质 149 吴兰150 吴懿151 吕布 152 吕岱 153 吕威璜 154 吕虔 155 吕凯 156 吕翔 157 吕箐158 吕纹 159 吕义 160 吕蒙161 吕范 162 吕据 163 吕旷 164 宋忠 165 宋扬 166 宋宪167 岑昏 168 李文姬 169 李典 170 李恢171 李异 172 李堪 173 李肃 174 李傕175 李福 176 李蒙 177 李儒 178 李丰 179 李鹏 180 李严181 杜远 182 杜袭 183 步鹭184 车胄 185 辛毗 186 辛敞 187 辛评 188 辛宪英 189 邢道荣 190 阮咸191 阮籍192 典韦 193 卓膺 194 卑衍 195 周玉 196 周昕 197 周胤 198 周仓 199 周泰 200 周瑜201 周鲂 202 孟坦 203 孟达 204 尚广 205 武安国 206 法正 207 沮授 208 沮鹄209 芙蓉 210 金采频211 金旋 212 邴原 213 邯郸商 214 侯成 215 侯音 216 俞涉217 姜叙 218 姜维 219 姜霞 220 施但221 皇甫嵩 222 纪灵 223 胡车儿 224 胡芬225 胡班 226 胡轸 227 胡奋 228 胡道 229 范慎 230 范疆231 韦昭 232 韦康 233 种劭234 235 种辑 236 伦直 237 凌统 238 凌操 239 唐咨 240 夏侯令女241 夏侯玄242 夏侯和 243 夏侯尚 244 夏侯威 245 夏侯恩 246 夏侯涓 247 夏侯敦 248 夏侯渊249 夏侯茂 250 夏侯娇251 夏侯德 252 夏侯儒 253 夏侯霸 254 孙大虎 255 孙小虎256 孙仁 257 孙休 258 孙匡 259 孙秀 260 孙和261 孙亮 262 孙娟 263 孙峻 264 孙朗265 孙桓 266 孙狼 267 孙乾 268 孙坚 269 孙异 270 孙翊271 孙登 272 孙皓 273 孙策274 孙瑜 275 孙韶 276 孙霓裳 277 孙静 278 孙礼 279 孙权 280 宴明281 徐他282 徐晃 283 徐庶 284 徐盛 285 徐荣 286 徐质 287 徐邈 288 桓范 289 留略 290 留赞291 祖茂 292 祖郎 293 祝公道 294 秦旦 295 秦宓 296 秦琪 297 耿纪 298 荀攸299 荀或 300 袁杏301 袁尚 302 袁芳 303 袁胤 304 袁绍 305 袁术 306 袁隗 307 袁熙308 袁遗 309 袁谭 310 郝昭311 马元义 312 马日禅 313 马休 314 马宇 315 马均316 马良 317 马岱 318 马延 319 马忠 320 马玩321 马琳 322 马超 323 马云萝324 马翠 325 马遵 326 马谡 327 马邈 328 马腾 329 马铁 330 高沛331 高定 332 高升333 高柔 334 高堂隆 335 高翔 336 高顺 337 高干 338 高览 339 愿星 340 崔勇341 崔琰 342 常雕 343 张子谦 344 张允 345 张布 346 张白骑 347 张休 348 张任349 张角 350 张佩351 张承 352 张松 353 张虎 354 张南 355 张既 356 张昭 357 张英358 张苞 359 张郃 360 张飞361 张悌 362 张纯 363 张纮 364 张梁 365 张梅 366 张猛367 张球 368 张绍 369 张陵 370 张华371 张杨 372 张温 373 张达 374 张宁 375 张卫376 张鲁 377 张勋 378 张横 379 张燕 380 张燕燕381 张辽 382 张济 383 张翼384 张举 385 张嶷 386 张绣 387 张邈 388 张闿 389 张顗 390 张宝391 张馨392 张莺莺 393 曹仁 394 曹文叔 395 曹丕 396 曹休 397 曹宇 398 曹性 399 曹昂400 曹芳401 曹洪 402 曹殷 403 曹真 404 曹纯 405 曹豹 406 曹淑 407 曹爽 408 曹植409 曹华 410 曹节411 曹羡 412 曹彰 413 曹肇 414 曹据 415 曹操 416 曹羲 417 曹遵418 曹睿 419 梁习 420 梁兴421 梅成 422 凉茂 423 淳于嘉 424 淳于导 425 淳于琼426 毕轨 427 笮融 428 许子将 429 许攸 430 许贡431 许靖 432 许禇 433 许仪434 逢纪 435 郭女王 436 郭石 437 郭汜 438 郭攸之 439 郭奕 440 郭淮441 郭嘉442 郭图 443 郭槐 444 陈式 445 陈到 446 陈武 447 陈宫 448 陈泰 449 陈珪 450 陈雪451 陈琳 452 陈登 453 陈群 454 陈瑀 455 陈震 456 陈横 457 陈矫 458 陈骞 459 陈兰460 陆抗461 陆英 462 陆凯 463 陆逊 464 陆绩 465 陶芷 466 陶浚 467 陶谦468 傅士仁 469 傅彤 470 傅巽471 傅干 472 傅婴 473 乔玄 474 乔乔 475 乔瑁476 焦触 477 程武 478 程秉 469 傅彤 480 程普481 程远志 482 程银 483 华佗484 华雄 485 华歆 486 貂蝉 487 费诗 488 费袆 489 费耀 490 贺齐491 鄂焕 492 冯习493 黄忠 494 黄祖 495 黄强 496 黄皓 497 黄舞蝶 498 黄盖 499 黄权 500 杨弘501 杨任 502 杨奉 503 杨昂 504 杨松 505 杨阜 506 杨柏 507 杨秋 508 杨修 509 杨祚510 杨彪511 杨琦 512 杨仪 513 杨密 514 杨丑 515 杨怀 516 杨艳 517 董允 518 董卓519 董和 520 董宜521 董承 522 董旻 523 董昭 524 董厥 525 董衡 526 董袭 527 虞翻528 贾午 529 贾充 530 贾南风531 贾荃 532 贾逵 533 贾华 534 贾诩 535 贾范536 贾黎民 536 贾黎民 538 邹陀 539 邹圆 540 邹靖541 雍闓 542 雷储 543 雷铜544 雷薄 545 廖化 546 廖立 547 廖琴 548 满宠 549 甄宓 550 管亥551 管承 552 管辂553 管宁 554 臧洪 555 臧霸 556 裴元绍 557 赵弘 558 赵昂 559 赵统 560 赵累561 赵云 562 赵葳 563 赵广 564 赵范 565 蒯良 566 蒯越 567 刘巴 568 刘伶 569 刘陶570 刘岱571 刘延 572 刘表 573 刘封 574 刘度 575 刘珠 576 刘焉 577 刘理 578 刘绍579 刘备 580 刘循581 刘琦 582 刘琮 583 刘虞 584 刘辟 585 刘慧娘 586 刘莹587 刘璋 588 刘范 589 刘贤 590 刘勋591 刘晔 592 刘禅 593 刘繇 594 刘嚣 595 审配596 樊建 597 樊稠 598 乐进 599 潘凤 600 潘璋601 潘浚 602 潘隐 603 滕胤 604 滕丽605 嵇康 606 蒋石 607 蒋钦 608 蒋舒 609 蒋琬 610 蒋干611 蒋义渠 612 蒋济613 蔡中 614 蔡和 615 蔡邕 616 蔡阳 617 蔡琰 618 蔡瑁 619 蔡勋 620 蔡薇621 诸葛均 622 诸葛直 623 诸葛芸 624 诸葛亮 625 诸葛恪 626 诸葛琪 627 诸葛瑾628 诸葛诞 629 诸葛靓 630 邓冰631 邓艾 632 邓忠 633 邓芝 634 邓茂 635 邓贤636 邓扬 637 巩志 638 巩都 639 鲁珍 640 鲁肃641 卢植 642 穆顺 643 钱铜 644 阎宇645 阎柔 646 阎圃 647 阎芝 648 阎象 649 阎温 650 霍戈651 霍峻 652 骆峻 653 骆统654 鲍信 655 鲍隆 656 戴员 657 戴陵 658 濮阳兴 659 糜竺 660 糜芳661 糜贞662 薛综 663 薛莹 664 谢景 665 钟绅 666 钟会 667 钟缙 668 钟繇 669 隐蕃 670 韩玄671 韩忠 672 韩浩 673 韩嵩 674 韩当 675 韩遂 676 韩福 677 韩暹 678 韩融 679 韩黛680 韩馥681 扰龙宗 682 简雍 683 聂友 684 颜良 685 魏攸 686 魏延 687 魏讽688 魏腾 689 魏续 690 庞统691 庞义 692 庞德 693 谭雄 694 谯周 695 边张 696 关平697 关羽 698 关索 699 关统 700 关凤701 关兴 702 趜义 703 趜演 704 祢衡705 严白虎 706 严如意 707 严政 708 严畯 709 严纲 710 严舆711 严颜 712 苏飞713 阚泽 714 顾雍 715 龚英莲 716 龚都 717 龚景 718 丘力居 719 北宫伯玉 720 去卑721 白虎文 722 步度根 723 拓拔力微 724 於扶罗 725 越吉 726 雅丹 727 彻里吉728 苻健 729 素利 730 能臣抵之731 厥机 732 普卢 733 无臣氏 734 弥加 735 左贤王736 那楼 737 呼厨泉 738 速仆丸 739 楼班 740 蹋顿741 泄归泥 742 治元多743 治无戴 744 千万 745 俄何烧戈 746 月牙儿 747 依尔伦 748 喀丽儿 749 呼兰750 叶丝婉751 华黎 752 穆塔儿761 兀突骨 762 孟香 763 孟优 764 孟获 765 祝融夫人766 木鹿大王 767 朵思大王 768 沙摩柯 769 金环三结 770 迷当大王771 带来洞主772 忙牙长 773 阿会喃 774 董荼那 775 轲比能 776 孟鹰 777 孟狼 778 黑龙洞主779 孟节 780 哈尼781 杨锋 782 孔雀 783 阿诗玛 784 莎雅 785 麻荷萝 786 银花夫人787 翠娃 801 须佐之男 802 大国主 803 建御名方 804 少彦名 805 大物主 806 建御雷807 迩迩艺 808 山幸彦 809 海幸彦 810 天手力男811 小碓皇子 812 迦具土813 大山津见 814 久久能智 815 志那都彦 816 棉津见 817 阿昙 818 隼人 819 神武820 五濑821 月读 822 玉依姬 823 市寸岛姬 824 多纪理姬 825 多岐都姬 826 佐久夜姬827 弟橘姬 828 须势理姬 829 丰玉姬 830 栉名田姬831 卑弥呼 880 黄月英所有情义技编号: 599 火凤展翼600 神凰灭世601 青岚绝剑602 花岚绝剑603 鬼神烈戟604 八卦火神炮605 八卦灭元炮606 炎魔破地607 火神灭世608 天剑惊雷609 魔刀灭魂610 忠义傲世611 仁义齐天612 黑蛟怒翻613 共工霸海614 百剑绝踪615 奔雷袭电616 天雷殛电617 青龙天狼牙620 艳绝众生621 祈攘秘仪622 虎啸灭军623 五虎破极624 八阵回天625 八极归元626 紫盖腾龙628 龙凤天舞。
LZW编码算法详解
LZW编码算法详解LZW(Lempel-Ziv & Welch)编码又称字串表编码,是Welch将Lemple和Ziv所提出来的无损压缩技术改进后的压缩方法。
GIF图像文件采用的是一种改良的LZW 压缩算法,通常称为GIF-LZW压缩算法。
下面简要介绍GIF-LZW的编码与解码方程解:例现有来源于二色系统的图像数据源(假设数据以字符串表示):aabbbaabb,试对其进行LZW编码及解码。
1)根据图像中使用的颜色数初始化一个字串表(如表1),字串表中的每个颜色对应一个索引。
在初始字串表的LZW_CLEAR和LZW_EOI分别为字串表初始化标志和编码结束标志。
设置字符串变量S1、S2并初始化为空。
2)输出LZW_CLEAR在字串表中的索引3H(见表2第一行)。
3)从图像数据流中第一个字符开始,读取一个字符a,将其赋给字符串变量S2。
判断S1+S2=“a”在字符表中,则S1=S1+S2=“a”(见表2第二行)。
4)读取图像数据流中下一个字符a,将其赋给字符串变量S2。
判断S1+S2=“aa”不在字符串表中,输出S1=“a”在字串表中的索引0H,并在字串表末尾为S1+S2="aa"添加索引4H,且S1=S2=“a”(见表2第三行)。
5)读下一个字符b赋给S2。
判断S1+S2=“ab”不在字符串表中,输出S1=“a”在字串表中的索引0H,并在字串表末尾为S1+S2=“ab”添加索引5H,且S1=S2=“b”(见表2第四行)。
6)读下一个字符b赋给S2。
S1+S2=“bb”不在字串表中,输出S1=“b”在字串表中的索引1H,并在字串表末尾为S1+S2=“bb”添加索引6H,且S1=S2=“b”(见表2第五行)。
7)读字符b赋给S2。
S1+S2=“bb”在字串表中,则S1=S1+S2=“bb”(见表2第六行)。
8)读字符a赋给S2。
S1+S2=“bba”不在字串表中,输出S1=“bb”在字串表中的索引6H,并在字串表末尾为S1+S2=“bba”添加索引7H,且S1=S2=“a”(见表2第七行)。
日本七田真右脑记忆1000数字编码联想口诀
薛兆春新编;七田真右脑记忆1000数字编码联想口诀;1青蛙2头巾3土星4煤5硫酸6水库7章鱼8牡蛎9吊床10热气球11旗子12骸骨13鬼屋14通心粉15独眼怪物16照相机17海草18围巾19灯塔20影子21萨克斯22百合23夏威夷24排球25哨子26水泥搅拌车27牡丹28年糕29被炉30长脖子怪物31梅干32勺子33萤火虫34东京塔35黑板36粉笔37暗号38钱形平次39公园40杜鹃花41铁锹42三角形43信44野猪45花瓶46复印机47丑女人48额头49梅50黄莺51鳄鱼52摇篮53肥皂54霉55法院56和服57老鼠58琴59紧急出口60蜻蜓61胸针62朋友63高尔夫球64鱼糕65电饭锅66蝙蝠67佐渡岛68力士69大鼓70牛蒡71保龄球72推铅球73英国74桌子75毛衣76盂兰盆会舞77人造卫星78气球79歌手80合成器81游泳池82丰臣秀吉83铜像84脚跟85黑痣86钥匙87田间小道88住宿车89门帘90洗衣机91石油92炸薯条93番茄酱94围腰95圆木96枕头97毕加索98打呼噜99银杏100胡椒数字编码联想口诀;(1——100)1青蛙拿头巾洗脸闻到了土星味,是煤里的硫酸流到了水库,章鱼和牡蛎把吊床绑在热气球上,从旗子里看到骸骨进了鬼屋吃通心粉,独眼怪物拿照相机摄下了海草、围巾和灯塔的影子萨克斯里吹出了百合花,在夏威夷的排球场上表演。
哨子响了水泥搅拌车流出牡丹和年糕,被炉里长脖子怪物拿梅干和勺子捉萤火虫,东京塔挂的黑板用粉笔做下暗号,钱形平次在公园观赏杜鹃花。
铁锹做的三角形、信封里跳出一头野猪,踩碎了花瓶和复印机,扑向丑女人的额头。
梅、黄莺鳄鱼坐在摇篮里闻到肥皂发霉了,向法院起诉。
和服被老鼠穿上,拿了琴从紧急出口偷跑了,蜻蜓戴着胸针和朋友打高尔夫球,把鱼糕放到电饭锅让蝙蝠看着,佐渡岛的力士擂着大鼓吃着牛蒡菜,到保龄球馆推铅球,累了坐在英国馆桌子上穿上毛衣看盂兰盆会舞。
人造卫星的气球上坐着歌手,打开合成器瞭望游泳池。
字符集编码详解
字符集编码详解字符集编码是计算机科学中的一个重要概念,主要用于将字符集中的字符转换为计算机可以理解和处理的数字形式。
以下是一些常见的字符集编码及其详解:ASCII码:ASCII(American Standard Code for Information Interchange,美国信息交换标准代码)是最基础的字符集编码,它使用7位或8位二进制数来表示字符。
ASCII码包括了128个或256个字符,包括英文字母、数字、标点符号等。
其中,0x00-0x20和0x7F是控制字符,如换行、回车等。
GB2312:GB2312是中国国家标准的简体中文字符集编码,收录了简化汉字及符号、字母、日文假名等共7445个图形字符,其中汉字占6763个。
在GB2312编码中,一个汉字通常由两个字节表示,每个字节均采用七位编码表示。
这种表示方式也称为区位码,其中前字节表示区号,后字节表示位号。
UTF-8:UTF-8是一种针对Unicode的可变长度字符编码,也是一种广泛使用的编码方式。
在UTF-8编码中,一个字符可以占用1到4个字节,其中英文字符通常占用1个字节,而中文字符则占用3个字节。
UTF-8编码具有良好的兼容性和扩展性,可以表示全世界绝大多数语言的字符。
UTF-7:UTF-7是一种使用7位ASCII码对Unicode码进行转换的编码方式。
它的设计目的是为了在只能传递7位编码的邮件网关中传递信息。
UTF-7对英语字母、数字和常见符号直接显示,而对其他符号用修正的Base64编码。
UTF-7编码通常用于电子邮件等需要传输多种语言字符的场景。
除了以上几种常见的字符集编码外,还有许多其他的编码方式,如UTF-16、UTF-32、ISO-8859-1等。
不同的编码方式具有不同的特点和适用范围,需要根据具体的应用场景选择合适的编码方式。
需要注意的是,不同的字符集编码之间可能存在不兼容的情况,因此在进行字符编码转换时需要谨慎处理,以避免出现乱码等问题。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
256 257 258字符编码
一、什么是字符编码
字符编码是计算机技术中的一个重要概念,它指的是将字符转换为计
算机能够识别和处理的数据形式的过程。
计算机内部只能识别和处理
数字,而字符编码就是将字符映射为对应的数字或者二进制形式,以
便计算机能够正确地处理和显示文本信息。
二、常见的字符编码方案
在计算机领域,常见的字符编码方案有ASCII、Unicode和UTF-8等。
这些字符编码方案分别具有不同的特点和适用范围。
1. ASCII编码
ASCII编码是最早的字符编码方案,它规定了128个字符的编码,包
括英文字母、数字和一些特殊字符。
由于ASCII编码只能表示128个
字符,无法满足其他语种的需要,因此逐渐被Unicode和UTF-8所取代。
2. Unicode编码
Unicode编码是一种全球通用的字符编码方案,它包含了世界上几乎
所有的文字字符,可以表示多种语言的文字。
Unicode编码使用16
位或32位来表示字符,能够满足不同语种的需求,是目前最为广泛应用的字符编码方案之一。
3. UTF-8编码
UTF-8是一种可变长度的Unicode编码方案,它可以使用1~4个字节来表示一个字符,适合在互联网上传输和存储文本信息。
由于UTF-8编码具有良好的兼容性和节省空间的特点,因此在互联网应用中得到了广泛的应用。
三、字符编码的重要性
字符编码在计算机领域具有非常重要的作用,它直接影响着计算机能否正确地显示和处理文本信息。
正确的字符编码方案可以保证不同语言的文字能够被准确地表达和显示,从而实现跨语言的信息交流和共享。
1. 多语言支持
随着全球化的发展,不同国家和地区之间的交流日益频繁,多语言支持成为了计算机系统的基本需求。
而正确的字符编码方案可以实现在同一个系统中支持多种语言的显示和输入,为用户提供更加便捷的操作体验。
2. 数据传输
在网络通信和数据传输过程中,字符编码的选择直接影响着数据的准确传输和解析。
采用合适的字符编码方案可以有效地避免因编码问题造成的数据丢失和信息不清晰的情况,保证数据的完整性和可靠性。
3. 数据存储
在数据存储和数据库设计中,选择合适的字符编码方案可以有效地节约存储空间并提高数据的存储效率。
合理的字符编码方案还可以保证数据在不同系统之间的互操作性,降低数据转换和处理的成本。
四、字符编码的选择和应用
在实际的软件开发和系统设计中,选择合适的字符编码方案对于保证系统的稳定性和可靠性具有重要的意义。
需要根据不同的应用场景和需求来确定合适的字符编码方案,以确保系统能够正确地处理和显示各种文本信息。
1. 互联网应用
对于互联网应用来说,UTF-8编码是首选的字符编码方案。
UTF-8编码能够有效地支持多种语言的文字显示和传输,可以避免因字符编码问题而导致的乱码和显示异常,保证用户能够正常地浏览和交流各种信息。
2. 跨评台开发
在跨评台开发的场景中,需要考虑不同操作系统和设备的字符编码兼容性。
为了确保软件能够在不同评台上正确地显示和处理文本信息,开发者需要选择适合跨评台开发的字符编码方案,并严格遵循相关的字符编码规范。
3. 多语言支持
在支持多语言的软件和系统中,合理选择和应用字符编码方案至关重要。
开发者需要根据不同语种的特点和需求,选择适合的字符编码方
案并进行合理的字符编码转换和处理,以确保用户能够正常地使用多
种语言进行文字输入和输出。
五、总结
字符编码是计算机领域中的重要概念,它关系着文字的显示、传输和
存储等方方面面。
合理选择和应用字符编码方案可以保证系统的稳定
性和可靠性,为用户提供良好的操作体验。
在软件开发和系统设计中,开发者需要充分理解不同的字符编码方案,并根据实际需求选择合适
的字符编码方案,以确保系统能够正确地处理和显示各种语言的文字
信息。
字符编码在计算机领域中是一个至关重要的概念,它对于确保
文字的显示、传输和存储具有重要的作用。
在现代的信息化社会中,
人们需要使用计算机进行跨语言的信息交流和共享,因此正确的字符
编码方案对于实现多语言支持和数据传输具有至关重要的意义。
字符编码方案的选择对于实现多语言支持至关重要。
随着全球化的发展,人们需要使用计算机进行各种语言文字的输入和输出。
而不同语
种的字符在计算机中需要以数字或者二进制形式来表示和处理,因此
选择适合多语言支持的字符编码方案可以确保系统能够正确地显示和
处理各种语言的文字信息,为用户提供更加便捷的操作体验。
字符编码方案对于数据传输具有重要的影响。
在网络通信和数据传输
过程中,字符编码的选择直接影响着数据的准确传输和解析。
采用合
适的字符编码方案可以有效地避免因编码问题造成的数据丢失和信息
不清晰的情况,保证数据的完整性和可靠性。
特别是在互联网应用中,采用UTF-8编码可以避免因字符编码问题而导致的乱码和显示异常,
保证用户能够正常地浏览和交流各种信息。
字符编码方案的选择对于数据存储和数据库设计也具有重要的意义。
选择合适的字符编码方案可以有效地节约存储空间并提高数据的存储
效率。
合理的字符编码方案还可以保证数据在不同系统之间的互操作性,降低数据转换和处理的成本。
在数据存储和数据库设计中,开发
者需要根据实际需求选择合适的字符编码方案,并严格遵循相关的字
符编码规范,以确保数据能够正常地存储和检索。
在实际的软件开发和系统设计中,选择合适的字符编码方案对于保证
系统的稳定性和可靠性具有重要的意义。
不同的应用场景和需求需要
采用不同的字符编码方案,以确保系统能够正确地处理和显示各种文
本信息。
在互联网应用中,UTF-8编码是首选的字符编码方案,能够
有效地支持多种语言的文字显示和传输。
在跨评台开发的场景中,需要考虑不同操作系统和设备的字符编码兼
容性。
为了确保软件能够在不同评台上正确地显示和处理文本信息,
开发者需要选择适合跨评台开发的字符编码方案,并严格遵循相关的
字符编码规范。
在支持多语言的软件和系统中,合理选择和应用字符
编码方案至关重要。
开发者需要根据不同语种的特点和需求,选择适
合的字符编码方案并进行合理的字符编码转换和处理,以确保用户能
够正常地使用多种语言进行文字输入和输出。
字符编码对于计算机领域具有重要的意义。
合理选择和应用字符编码
方案可以保证系统的稳定性和可靠性,为用户提供良好的操作体验。
在软件开发和系统设计中,开发者需要充分理解不同的字符编码方案,并根据实际需求选择合适的字符编码方案,以确保系统能够正确地处
理和显示各种语言的文字信息。
不断的研究和应用新的字符编码技术
也是非常重要的,以适应日益多样化和复杂化的信息交流和共享需求。