BP神经网络算法的改进及在Matlab中的实现
基于遗传算法的BP神经网络MATLAB代码

基于遗传算法的BP神经网络MATLAB代码以下是基于遗传算法的BP神经网络的MATLAB代码,包括网络初始化、适应度计算、交叉运算、突变操作和迭代训练等。
1.网络初始化:```matlabfunction net = initialize_network(input_size, hidden_size, output_size)net.input_size = input_size;net.hidden_size = hidden_size;net.output_size = output_size;net.hidden_weights = rand(hidden_size, input_size);net.output_weights = rand(output_size, hidden_size);net.hidden_biases = rand(hidden_size, 1);net.output_biases = rand(output_size, 1);end```2.适应度计算:```matlabfunction fitness = calculate_fitness(net, data, labels)output = forward_propagation(net, data);fitness = sum(sum(abs(output - labels)));end```3.前向传播:```matlabfunction output = forward_propagation(net, data)hidden_input = net.hidden_weights * data + net.hidden_biases;hidden_output = sigmoid(hidden_input);output_input = net.output_weights * hidden_output +net.output_biases;output = sigmoid(output_input);endfunction result = sigmoid(x)result = 1 ./ (1 + exp(-x));end```4.交叉运算:```matlabfunction offspring = crossover(parent1, parent2)point = randi([1 numel(parent1)]);offspring = [parent1(1:point) parent2((point + 1):end)]; end```5.突变操作:```matlabfunction mutated = mutation(individual, mutation_rate) for i = 1:numel(individual)if rand < mutation_ratemutated(i) = rand;elsemutated(i) = individual(i);endendend```6.迭代训练:```matlabfunction [best_individual, best_fitness] =train_network(data, labels, population_size, generations, mutation_rate)input_size = size(data, 1);hidden_size = round((input_size + size(labels, 1)) / 2);output_size = size(labels, 1);population = cell(population_size, 1);for i = 1:population_sizepopulation{i} = initialize_network(input_size, hidden_size, output_size);endbest_individual = population{1};best_fitness = calculate_fitness(best_individual, data, labels);for i = 1:generationsfor j = 1:population_sizefitness = calculate_fitness(population{j}, data, labels);if fitness < best_fitnessbest_individual = population{j};best_fitness = fitness;endendselected = selection(population, data, labels);for j = 1:population_sizeparent1 = selected{randi([1 numel(selected)])};parent2 = selected{randi([1 numel(selected)])};offspring = crossover(parent1, parent2);mutated_offspring = mutation(offspring, mutation_rate);population{j} = mutated_offspring;endendendfunction selected = selection(population, data, labels) fitnesses = zeros(length(population), 1);for i = 1:length(population)fitnesses(i) = calculate_fitness(population{i}, data, labels);end[~, indices] = sort(fitnesses);selected = population(indices(1:floor(length(population) / 2)));end```这是一个基于遗传算法的简化版BP神经网络的MATLAB代码,使用该代码可以初始化神经网络并进行迭代训练,以获得最佳适应度的网络参数。
标准BP算法及改进的BP算法标准BP算法及改进的BP算法应用(1)

➢ 隐含层神经元数
➢ 初始权值的选取 ➢ 学习速率 ➢ 期望误差的选取
22
2020/3/6
网络的层数
理论上已经证明:具有偏差和至少一个S型隐含层 加上一个线性输出层的网络,能够逼近任何有理函 数
定理:
增加层数主要可以进一步的降低误差,提高精度, 但同时也使网络复杂化,从而增加了网络权值的训 练时间。
%输入向量P和目标向量T
P = -1:0.1:1
T = [-0.96 -0.577 -0.0729 0.377 0.641 0.66 0.461 0.1336 -0.201 -0.434 -0.5 -0.393 0.1647 0.0988 0.3072 0.396 0.3449 0.1816 -0.0312 -0.2183 -0.3201 ];
4.3 BP学习算法
假设输入为P,输入神经元有r个,隐含层内有s1个神经 元,激活函数为F1,输出层内有s2个神经元,对应的激 活函数为F2,输出为A,目标矢量为T
12
2020/3/6
4.3 BP学习算法
信息的正向传递
隐含层中第i个神经元的输出
输出层第k个神经元的输出
定义误差函数
13
4.4.2应用举例
1、用BP神经网络实现两类模式分类 p=[1 -1 -2 -4;2 1 1 0]; t=[0 1 1 0]; %创建BP网络和定义训练函数及参数 NodeNum=8;%隐含层节点数 TypeNum=1;%输出维数 Epochs=1000;%训练次数 TF1='logsig'; TF2='logsig';
D1=deltatan(A1,D2,W2);
[dWl,dBl]=learnbp(P,D1,lr);
Bp神经网络的Matlab实现

式, 同一层之 间不存 在相 互连接 , 隐层 可 以有 一层或 多层 . 层与层 之 间有 两种 信号在 流通 : 一种是 工 作信 号 ( 实线 表 示 )它是 施 加输 入信 号 后 用 , 向前传 播直 到在输 出端 产生 实 际输 出的信 号 , 是输 入 和权 值 的 函数 . 另
我们 可 以直观 、 便地进 行分 析 、 算 及仿 真 工作 _ . 经 网络 工 具箱 是 M tb以神 经 网 络 为基 础 , 方 计 2神 j aa l 包含 着 大
量B p网络 的作 用 函数和算 法 函数 , B 为 p网络 的仿 真研 究 提供 了便 利 的工 具 . 运用 神 经 网络 工具 箱 一般 按 照
21年 1 00 0月
湘 南 学 院 学报
J u n lo a g a o ra f Xin n n Umv  ̄i e t y
Oc . 2 0 t . 01 V0 . l No. J3 5
第 3 卷第 5期 1
B p神 经 网络 的 Ma a 现 t b实 l
石 云
一
输 入层
隐 层
输 出层
种是 误差信 号 ( 虚线 表示 )网络实 际输 出与期望 输 出间的差 值 即为 用 ,
图 1 典型 B p网络 模 型
误差 , 由输 出端开 始逐层 向后传 播 . p网络 的学 习过程 程 由前 向计 算 它 B
BP神经网络matlab实现的基本步骤

1、数据归一化2、数据分类,主要包括打乱数据顺序,抽取正常训练用数据、变量数据、测试数据3、建立神经网络,包括设置多少层网络(一般3层以内既可以,每层的节点数(具体节点数,尚无科学的模型和公式方法确定,可采用试凑法,但输出层的节点数应和需要输出的量个数相等),设置隐含层的传输函数等。
关于网络具体建立使用方法,在后几节的例子中将会说到。
4、指定训练参数进行训练,这步非常重要,在例子中,将详细进行说明5、完成训练后,就可以调用训练结果,输入测试数据,进行测试6、数据进行反归一化7、误差分析、结果预测或分类,作图等数据归一化问题归一化的意义:首先说一下,在工程应用领域中,应用BP网络的好坏最关键的仍然是输入特征选择和训练样本集的准备,若样本集代表性差、矛盾样本多、数据归一化存在问题,那么,使用多复杂的综合算法、多精致的网络结构,建立起来的模型预测效果不会多好。
若想取得实际有价值的应用效果,从最基础的数据整理工作做起吧,会少走弯路的。
归一化是为了加快训练网络的收敛性,具体做法是:1 把数变为(0,1)之间的小数主要是为了数据处理方便提出来的,把数据映射到0~1范围之内处理,更加便捷快速,应该归到数字信号处理范畴之内。
2 把有量纲表达式变为无量纲表达式归一化是一种简化计算的方式,即将有量纲的表达式,经过变换,化为无量纲的表达式,成为纯量比如,复数阻抗可以归一化书写:Z = R + jωL = R(1 + jωL/R) ,复数部分变成了纯数量了,没有量纲。
另外,微波之中也就是电路分析、信号系统、电磁波传输等,有很多运算都可以如此处理,既保证了运算的便捷,又能凸现出物理量的本质含义。
神经网络归一化方法:由于采集的各数据单位不一致,因而须对数据进行[-1,1]归一化处理,归一化方法主要有如下几种,供大家参考:1、线性函数转换,表达式如下:复制内容到剪贴板代码:y=(x-MinValue)/(MaxValue-MinValue)说明:x、y分别为转换前、后的值,MaxValue、MinValue分别为样本的最大值和最小值。
智能控制BP神经网络实验报告
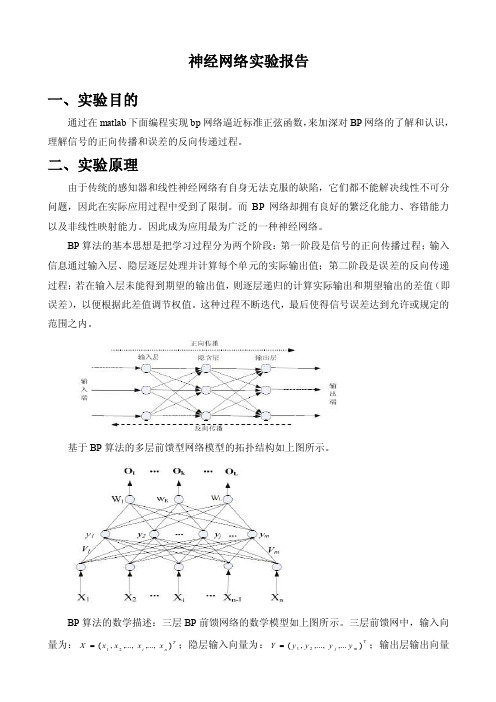
神经网络实验报告一、实验目的通过在matlab 下面编程实现bp 网络逼近标准正弦函数,来加深对BP 网络的了解和认识,理解信号的正向传播和误差的反向传递过程。
二、实验原理由于传统的感知器和线性神经网络有自身无法克服的缺陷,它们都不能解决线性不可分问题,因此在实际应用过程中受到了限制。
而BP 网络却拥有良好的繁泛化能力、容错能力以及非线性映射能力。
因此成为应用最为广泛的一种神经网络。
BP 算法的基本思想是把学习过程分为两个阶段:第一阶段是信号的正向传播过程;输入信息通过输入层、隐层逐层处理并计算每个单元的实际输出值;第二阶段是误差的反向传递过程;若在输入层未能得到期望的输出值,则逐层递归的计算实际输出和期望输出的差值(即误差),以便根据此差值调节权值。
这种过程不断迭代,最后使得信号误差达到允许或规定的范围之内。
基于BP 算法的多层前馈型网络模型的拓扑结构如上图所示。
BP 算法的数学描述:三层BP 前馈网络的数学模型如上图所示。
三层前馈网中,输入向量为:Tn i x x x x X),...,,...,,(21=;隐层输入向量为:Tm j y y y y Y),...,...,,(21=;输出层输出向量为:Tl k o o o o O),...,...,,(21=;期望输出向量为:Tl k d d d d d),...,...,(21=。
输入层到隐层之间的权值矩阵用V 表示,Ym j v v v v V),...,...,(21=,其中列向量j v 为隐层第j 个神经元对应的权向量;隐层到输出层之间的权值矩阵用W 表示,),...,...,(21l k w w w w W =,其中列向量k w 为输出层第k 个神经元对应的权向量。
下面分析各层信号之间的数学关系。
对于输出层,有∑====mj x v net mj netf yi ij jjj,...,2,1,,...,2,1),(对于隐层,有∑=====mj i jkkkk lk y wnetl k netf O 0,...,2,1,,...,2,1),(以上两式中,转移函数f(x)均为单极性Sigmoid 函数:xex f -+=11)(f(x)具有连续、可导的特点,且有)](1)[()('x f x f x f -=以上共同构成了三层前馈网了的数学模型。
PSO优化的BP神经网络(Matlab版)

PSO优化的BP神经⽹络(Matlab版)前⾔:最近接触到⼀些神经⽹络的东西,看到很多⼈使⽤PSO(粒⼦群优化算法)优化BP神经⽹络中的权值和偏置,经过⼀段时间的研究,写了⼀些代码,能够跑通,嫌弃速度慢的可以改⼀下训练次数或者适应度函数。
在我的理解⾥,PSO优化BP的初始权值w和偏置b,有点像数据迁徙,等于⽤粒⼦去尝试作为⽹络的参数,然后训练⽹络的阈值,所以总是会看到PSO优化了权值和阈值的说法,(⼀开始我是没有想通为什么能够优化阈值的),下⾯是我的代码实现过程,关于BP和PSO的原理就不⼀⼀赘述了,⽹上有很多⼤佬解释的很详细了……⾸先是利⽤BP作为适应度函数function [error] = BP_fit(gbest,input_num,hidden_num,output_num,net,inputn,outputn)%BP_fit 此函数为PSO的适应度函数% gbest:最优粒⼦% input_num:输⼊节点数⽬;% output_num:输出层节点数⽬;% hidden_num:隐含层节点数⽬;% net:⽹络;% inputn:⽹络训练输⼊数据;% outputn:⽹络训练输出数据;% error : ⽹络输出误差,即PSO适应度函数值w1 = gbest(1:input_num * hidden_num);B1 = gbest(input_num * hidden_num + 1:input_num * hidden_num + hidden_num);w2 = gbest(input_num * hidden_num + hidden_num + 1:input_num * hidden_num...+ hidden_num + hidden_num * output_num);B2 = gbest(input_num * hidden_num+ hidden_num + hidden_num * output_num + 1:...input_num * hidden_num + hidden_num + hidden_num * output_num + output_num);net.iw{1,1} = reshape(w1,hidden_num,input_num);net.lw{2,1} = reshape(w2,output_num,hidden_num);net.b{1} = reshape(B1,hidden_num,1);net.b{2} = B2';%建⽴BP⽹络net.trainParam.epochs = 200;net.trainParam.lr = 0.05;net.trainParam.goal = 0.000001;net.trainParam.show = 100;net.trainParam.showWindow = 0;net = train(net,inputn,outputn);ty = sim(net,inputn);error = sum(sum(abs((ty - outputn))));end 然后是PSO部分:%%基于多域PSO_RBF的6R机械臂逆运动学求解的研究clear;close;clc;%定义BP参数:% input_num:输⼊层节点数;% output_num:输出层节点数;% hidden_num:隐含层节点数;% inputn:⽹络输⼊;% outputn:⽹络输出;%定义PSO参数:% max_iters:算法最⼤迭代次数% w:粒⼦更新权值% c1,c2:为粒⼦群更新学习率% m:粒⼦长度,为BP中初始W、b的长度总和% n:粒⼦群规模% gbest:到达最优位置的粒⼦format longinput_num = 3;output_num = 3;hidden_num = 25;max_iters =10;m = 500; %种群规模n = input_num * hidden_num + hidden_num + hidden_num * output_num + output_num; %个体长度w = 0.1;c1 = 2;c2 = 2;%加载⽹络输⼊(空间任意点)和输出(对应关节⾓的值)load('pfile_i2.mat')load('pfile_o2.mat')% inputs_1 = angle_2';inputs_1 = inputs_2';outputs_1 = outputs_2';train_x = inputs_1(:,1:490);% train_y = outputs_1(4:5,1:490);train_y = outputs_1(1:3,1:490);test_x = inputs_1(:,491:500);test_y = outputs_1(1:3,491:500);% test_y = outputs_1(4:5,491:500);[inputn,inputps] = mapminmax(train_x);[outputn,outputps] = mapminmax(train_y);net = newff(inputn,outputn,25);%设置粒⼦的最⼩位置与最⼤位置% w1阈值设定for i = 1:input_num * hidden_numMinX(i) = -0.01*ones(1);MaxX(i) = 3.8*ones(1);end% B1阈值设定for i = input_num * hidden_num + 1:input_num * hidden_num + hidden_numMinX(i) = 1*ones(1);MaxX(i) = 8*ones(1);end% w2阈值设定for i = input_num * hidden_num + hidden_num + 1:input_num * hidden_num + hidden_num + hidden_num * output_numMinX(i) = -0.01*ones(1);MaxX(i) = 3.8*ones(1);end% B2阈值设定for i = input_num * hidden_num+ hidden_num + hidden_num * output_num + 1:input_num * hidden_num + hidden_num + hidden_num * output_num + output_num MinX(i) = 1*ones(1);MaxX(i) = 8*ones(1);end%%初始化位置参数%产⽣初始粒⼦位置pop = rands(m,n);%初始化速度和适应度函数值V = 0.15 * rands(m,n);BsJ = 0;%对初始粒⼦进⾏限制处理,将粒⼦筛选到⾃定义范围内for i = 1:mfor j = 1:input_num * hidden_numif pop(i,j) < MinX(j)pop(i,j) = MinX(j);endif pop(i,j) > MaxX(j)pop(i,j) = MaxX(j);endendfor j = input_num * hidden_num + 1:input_num * hidden_num + hidden_numif pop(i,j) < MinX(j)pop(i,j) = MinX(j);endif pop(i,j) > MaxX(j)pop(i,j) = MaxX(j);endendfor j = input_num * hidden_num + hidden_num + 1:input_num * hidden_num + hidden_num + hidden_num * output_numif pop(i,j) < MinX(j)pop(i,j) = MinX(j);endif pop(i,j) > MaxX(j)pop(i,j) = MaxX(j);endendfor j = input_num * hidden_num+ hidden_num + hidden_num * output_num + 1:input_num * hidden_num + hidden_num + hidden_num * output_num + output_num if pop(i,j) < MinX(j)pop(i,j) = MinX(j);endif pop(i,j) > MaxX(j)pop(i,j) = MaxX(j);endendend%评估初始粒⼦for s = 1:mindivi = pop(s,:);fitness = BP_fit(indivi,input_num,hidden_num,output_num,net,inputn,outputn);BsJ = fitness; %调⽤适应度函数,更新每个粒⼦当前位置Error(s,:) = BsJ; %储存每个粒⼦的位置,即BP的最终误差end[OderEr,IndexEr] = sort(Error);%将Error数组按升序排列Errorleast = OderEr(1); %记录全局最⼩值for i = 1:m %记录到达当前全局最优位置的粒⼦if Error(i) == Errorleastgbest = pop(i,:);break;endendibest = pop; %当前粒⼦群中最优的个体,因为是初始粒⼦,所以最优个体还是个体本⾝for kg = 1:max_iters %迭代次数for s = 1:m%个体有52%的可能性变异for j = 1:n %粒⼦长度for i = 1:m %种群规模,变异是针对某个粒⼦的某⼀个值的变异if rand(1)<0.04pop(i,j) = rands(1);endendend%r1,r2为粒⼦群算法参数r1 = rand(1);r2 = rand(1);%个体位置和速度更新V(s,:) = w * V(s,:) + c1 * r1 * (ibest(s,:)-pop(s,:)) + c2 * r2 * (gbest(1,:)-pop(s,:));pop(s,:) = pop(s,:) + 0.3 * V(s,:);%对更新的位置进⾏判断,超过设定的范围就处理下。
BP神经网络实验详解(MATLAB实现)

BP神经网络实验详解(MATLAB实现)BP(Back Propagation)神经网络是一种常用的人工神经网络结构,用于解决分类和回归问题。
在本文中,将详细介绍如何使用MATLAB实现BP神经网络的实验。
首先,需要准备一个数据集来训练和测试BP神经网络。
数据集可以是一个CSV文件,每一行代表一个样本,每一列代表一个特征。
一般来说,数据集应该被分成训练集和测试集,用于训练和测试模型的性能。
在MATLAB中,可以使用`csvread`函数来读取CSV文件,并将数据集划分为输入和输出。
假设数据集的前几列是输入特征,最后一列是输出。
可以使用以下代码来实现:```matlabdata = csvread('dataset.csv');input = data(:, 1:end-1);output = data(:, end);```然后,需要创建一个BP神经网络模型。
可以使用MATLAB的`patternnet`函数来创建一个全连接的神经网络模型。
该函数的输入参数为每个隐藏层的神经元数量。
下面的代码创建了一个具有10个隐藏神经元的单隐藏层BP神经网络:```matlabhidden_neurons = 10;net = patternnet(hidden_neurons);```接下来,需要对BP神经网络进行训练。
可以使用`train`函数来训练模型。
该函数的输入参数包括训练集的输入和输出,以及其他可选参数,如最大训练次数和停止条件。
下面的代码展示了如何使用`train`函数来训练模型:```matlabnet = train(net, input_train, output_train);```训练完成后,可以使用训练好的BP神经网络进行预测。
可以使用`net`模型的`sim`函数来进行预测。
下面的代码展示了如何使用`sim`函数预测测试集的输出:```matlaboutput_pred = sim(net, input_test);```最后,可以使用各种性能指标来评估预测的准确性。
(PSO-BP)结合粒子群的神经网络算法以及matlab实现

(PSO-BP)结合粒⼦群的神经⽹络算法以及matlab实现原理:PSO(粒⼦群群算法):可以在全局范围内进⾏⼤致搜索,得到⼀个初始解,以便BP接⼒BP(神经⽹络):梯度搜素,细化能⼒强,可以进⾏更仔细的搜索。
数据:对该函数((2.1*(1-x+2*x.^2).*exp(-x.^2/2))+sin(x)+x','x')[-5,5]进⾏采样,得到30组训练数据,拟合该⽹络。
神经⽹络结构设置:该⽹络结构为,1-7-1结构,即输⼊1个神经元,中间神经元7个,输出1个神经元程序步骤:第⼀步:先采⽤抽取30组数据,包括输⼊和输出第⼀步:运⾏粒⼦群算法,进⾏随机搜索,选择⼀个最优的解,该解的维数为22维。
第⼆步:在;粒⼦群的解基础上进⾏细化搜索程序代码:clcclearticSamNum=30;HiddenNum=7;InDim=1;OutDim=1;load train_xload train_fa=train_x';d=train_f';p=[a];t=[d];[SamIn,minp,maxp,tn,mint,maxt]=premnmx(p,t);NoiseVar=0.01;Noise=NoiseVar*randn(1,SamNum);SamOut=tn + Noise;SamIn=SamIn';SamOut=SamOut';MaxEpochs=60000;lr=0.025;E0=0.65*10^(-6);%%%the begin of PSOE0=0.001;Max_num=500;particlesize=200;c1=1;c2=1;w=2;vc=2;vmax=5;dims=InDim*HiddenNum+HiddenNum+HiddenNum*OutDim+OutDim;x=-4+7*rand(particlesize,dims);v=-4+5*rand(particlesize,dims);f=zeros(particlesize,1);%%for jjj=1:particlesizetrans_x=x(jjj,:);W1=zeros(InDim,HiddenNum);B1=zeros(HiddenNum,1);W2=zeros(HiddenNum,OutDim);B2=zeros(OutDim,1);W1=trans_x(1,1:HiddenNum);B1=trans_x(1,HiddenNum+1:2*HiddenNum)';W2=trans_x(1,2*HiddenNum+1:3*HiddenNum)';B2=trans_x(1,3*HiddenNum+1);Hiddenout=logsig(SamIn*W1+repmat(B1',SamNum,1));Networkout=Hiddenout*W2+repmat(B2',SamNum,1);Error=Networkout-SamOut;SSE=sumsqr(Error)f(jjj)=SSE;endpersonalbest_x=x;personalbest_f=f;[groupbest_f i]=min(personalbest_f);groupbest_x=x(i,:);for j_Num=1:Max_numvc=(5/3*Max_num-j_Num)/Max_num;%%v=w*v+c1*rand*(personalbest_x-x)+c2*rand*(repmat(groupbest_x,particlesize,1)-x);for kk=1:particlesizefor kk0=1:dimsif v(kk,kk0)>vmaxv(kk,kk0)=vmax;else if v(kk,kk0)<-vmaxv(kk,kk0)=-vmax;endendendendx=x+vc*v;%%for jjj=1:particlesizetrans_x=x(jjj,:);W1=zeros(InDim,HiddenNum);B1=zeros(HiddenNum,1);W2=zeros(HiddenNum,OutDim);B2=zeros(OutDim,1);W1=trans_x(1,1:HiddenNum);B1=trans_x(1,HiddenNum+1:2*HiddenNum)';W2=trans_x(1,2*HiddenNum+1:3*HiddenNum)';B2=trans_x(1,3*HiddenNum+1);Hiddenout=logsig(SamIn*W1+repmat(B1',SamNum,1));Networkout=Hiddenout*W2+repmat(B2',SamNum,1);Error=Networkout-SamOut;SSE=sumsqr(Error);f(jjj)=SSE;end%%for kk=1:particlesizeif f(kk)<personalbest_f(kk)personalbest_f(kk)=f(kk);personalbest_x(kk)=x(kk);endend[groupbest_f0 i]=min(personalbest_f);if groupbest_f0<groupbest_fgroupbest_x=x(i,:);groupbest_f=groupbest_f0;endddd(j_Num)=groupbest_fendstr=num2str(groupbest_f);trans_x=groupbest_x;W1=trans_x(1,1:HiddenNum);B1=trans_x(1,HiddenNum+1:2*HiddenNum)';W2=trans_x(1,2*HiddenNum+1:3*HiddenNum)';B2=trans_x(1,3*HiddenNum+1);%the end of PSO%%for i=1:MaxEpochs%%Hiddenout=logsig(SamIn*W1+repmat(B1',SamNum,1));Networkout=Hiddenout*W2+repmat(B2',SamNum,1);Error=Networkout-SamOut;SSE=sumsqr(Error)ErrHistory=[ SSE];if SSE<E0,break, enddB2=zeros(OutDim,1);dW2=zeros(HiddenNum,OutDim);for jj=1:HiddenNumfor k=1:SamNumdW2(jj,OutDim)=dW2(jj,OutDim)+Error(k)*Hiddenout(k,jj);endendfor k=1:SamNumdB2(OutDim,1)=dB2(OutDim,1)+Error(k);enddW1=zeros(InDim,HiddenNum);dB1=zeros(HiddenNum,1);for ii=1:InDimfor jj=1:HiddenNumfor k=1:SamNumdW1(ii,jj)=dW1(ii,jj)+Error(k)*W2(jj,OutDim)*Hiddenout(k,jj)*(1-Hiddenout(k,jj))*(SamIn(k,ii));dB1(jj,1)=dB1(jj,1)+Error(k)*W2(jj,OutDim)*Hiddenout(k,jj)*(1-Hiddenout(k,jj));endendendW2=W2-lr*dW2;B2=B2-lr*dB2;W1=W1-lr*dW1;B1=B1-lr*dB1;endHiddenout=logsig(SamIn*W1+repmat(B1',SamNum,1));Networkout=Hiddenout*W2+repmat(B2',SamNum,1);aa=postmnmx(Networkout,mint,maxt);x=a;newk=aa;figureplot(x,d,'r-o',x,newk,'b--+')legend('原始数据','训练后的数据');xlabel('x');ylabel('y');toc注:在(i5,8G,win7,64位)PC上的运⾏时间为30s左右。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
$# ) ## ,# ! * & " ># & " +! & &" #$%
&统的算法增加了动量项 # 加权调节公式为 ’ ( !! ! ! " ! " " " ’ > $ ’ ’(> ’ ( " % (! (# "$% "$% % & & &! &! ! ""! $ ""! " $% ’(> ’ ’ (# " "$% $ # "$% * % %( &! &! &! $% $ & > # & !" # !# " # # ! * % # .* % #" # # # % 则 !! 若& 为输出节点 # >.* $ * .* * & " ! &" &! &" 若 为隐节点 # 则 !! & >.* $ & "* &! &" $ & # #$%
第#期 陈桦等 ! ,( B C 神经网络算法的改进及在 D E F + E G 中的实现 H, %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% 执行代码后 " 在命令行中将实时显示网络的训练状态 " 如下所示 ! # # # / $ 6 0< SD" 7 * I O’ A ’ ’"D 3 7A" R Q > A > U K ’ =" < & E ^ M U N F (" = ( H # Q !8 % U K > ’ !> # # / $ 6 0< SD" 7 * I O= ’ A ’ ’"D 3 7’" ’ ’ = A # > @ @ > U K ’ =" < & E ^ M U N F !8 % # # > A # # # > U K > ’ !’" # # / $ 6 0< SD" 7 * I O> ’ ’ A ’ ’"D 3 7R" A ( @ R @ U K ’ = > U K ’ =" < & E ^ M U N F !8 % # ’ ( ’ Q H ( Q > U K > ’ !’" # # / $ 6 0< SD" 7 * I O> > ( A ’ ’"D 3 7Q" ’ R # A = U K ’ R > U K ’ =" < & E ^ M U N F !8 % # ’ ’ Q ’ @ H = R > U K > ’ !’" / $ 6 0< SD" C U & W * & P E N I UL * E +P U F " !8 对网络进行仿真测试 " % # !E Y[ M P$ N U F Y !E !!!# % ’ ’ # R ?>" ’ ’ ( (’" Q Q R Q’" Q Q Q # ! ?>"
#
"若达到误差精度或循环次数要求 # 则输出结果 # 否则回到 ! " ( = # !! ! #! 用 D E F + E G 神经网络工具箱进行设计与分析 #" >! 网络构建和初始化 在D 仿真 # 第一步是建立网络对象 ( 函数 N E F + E G 中对改进的 B C 算法进行测试 ) U V W W建立一个可训练 的前馈网络 # 这需要 ( 个输入参数 ’ 第 > 个参数是一个 / X #的矩阵以定义 / 个输入向量的最小值和最大 值* 第 # 个参数是一个表示每层神经元个数的数组 * 第 A 个参数是包含每层用到的转移函数名称的细胞数 组* 最后 > 个参数是用到的训练函数的名称 ( 创建一个二层网络 # 其网络模型如图 > 所示 (
* +飞思科技产品研法中心编 " 北京 ! 电子工业出版社 " > D E F + E G R" = 辅助神经网络分析与设计 * D+ " # ’ ’ A" >" * +焦李成 "神经网络计算 * 西安电子科技大学出版社 " # D+ "西安 ! > Q Q A" Q" * +于敏学 "李敏生 "神经网络模型的结构和算法的分离 * + $ % ! A , "北京理工大学学报 " # ’ ’ >" # > = = @ H!= Q ’" * +李广琼 "蒋加伏 "关于对 B + 自然科学版 % " $ % ! ( C 神经网络算法改进的研究 * , "常德师范学院学报 $ # ’ ’ A" > = # A >!A A"
图 >! 二层网络模型示意图 命令为 ’ ! + , # + , # # . # " * N U F YN U V W W ?>#* ’= A# > Z F E N [ M Z Z \ & U + M N Z ] F & E M N ^ Z L % L 这个命令建立了网络对象并且初始化了网络权重和偏置 # 它的输入是两个元素的向量 # 第 > 层有 A 个 神经元 # 第 # 层有 > 个神经元 ( 第 > 层的转移函数是 F # 输出层的转移函数是+ ( 输入向 量 E N K [ M P * M ^ M N U E & L 的第 > 个元素的范围是 ?> 到 ## 输入向量的第 # 个 元 素的 范围是 ’ 到 =# 训练 函 数 是 F ( & E M N ^ 接下来就 L 可以进行训练了 ( #" #! 网络训练 带动量的批处理梯度下降法用训练函数 F # 则性能函数低于 & E M N ^ P 触发 ( 如果训练次数超过 U * I O [ L % # 梯度值低于 # 或者训练时间超过 训练就会结束 ( 程序代码如下 ’ * E + P M N & E ^ F M P U L L
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% " " # > ’ ’ ’?= @ > > # ’ ’ ( ’ #?’ ’ ( =?’ A ! 文章编号 !
B C 神经网络算法的改进及在 D E F + E G 中的实现
陈桦 ! 程云艳
" 陕西科技大学计算机与信息工程学院 # 陕西 咸阳 !H $ > # ’ @ >
# ’ ’ A?> >?’ A! " 收稿日期 &
万方数据 作者简介 & 陈桦 " # 男# 上海市人 # 教授 # 研究方向 & , > Q R #? $ : $ S : $D# : 3 :T
陕西科技大学学报 第# 0( #卷 R0 %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
! + , # + , # # . # " * /生成一个前馈 B U F YN U V W W ?>#* ’= A# > Z F E N [ M Z Z \ & U + M N Z Z F & E M N ^ P Z C 网络 !N !!/ L % L /每隔 [ U F " F & E M N C E & E P" [ O * VY= ’* O * V 次显示一次 !N !!!!!/ / /设置学习速度 U F " F & E M N C E & E P" + & Y’" ’ =* !N / /设置动量系数 U F " F & E M N C E & E P" P I Y’" Q* !N / /训练单位时间 U F " F & E M N C E & E P" U * I O [ YA ’ ’* !N % / /目标误差 U F " F & E M N C E & E P" * E + Y> U K =* !N L , * / /指定输入值 Y+ ?> ?>##* ’=’= !% , * / /目标值 F Y+ ?> ?>>> ! 万方数据 ! # # " * / /训练网络 U F Y F & E M N N U F F !N %
!" #!!!!!!!!!!!!!!! !!!! 陕西科技大学学报 !!!!!!!!!!!!!!!!!!$ & " # ’ ’ ( % -./ 0$ 123 4$$0 5 6.0 6 ) 7 / 3 6 8 923 : 6 7 0 : 7;8 7 :401 < 9!!!!! ! ) * + " # # !!!!!!, ( =!
!! 引言 是目前比较流行的神经网络学习算法 # 是能实 现映射 变换的 前 B C 算法 " B E I J K & * E E F M * NE + * & M F O P$ % % L L 馈型网络中最常用的一类网络 # 是一种典型的误差修正方法 % 但标准 B 易 形成局 部 C 算法存 在一 些缺陷 & 极小而得不到整体最优 # 迭代次数多 # 收 敛 速 度 慢% 前 人 已 提 出 了 不 少 改 进 方 法# 本文基于 ) * +提 出 的 L ’ 批处理 ( 思想 # 以及加入动量项提高训练速度的方法 # 给出了带动量 的批 处理梯 度下降 算法 # 并用 D E F + E G 神经网络工具箱进行了设计分析及仿真 % "!B C 算法的改进 >" >!B C 算法收敛速度慢的原因 " $ > B C 算法中网络参数每次调节的幅度 均 以 一 个 与 网 络 误 差 函 数 或 其 对 权 值 导 数 大 小 成 正 比 的 固 在误差曲面较平坦处 # 由于这一偏导数值较小 # 因而权值参数的调节幅度也较 小 # 以 定因子! 进行 % 这样 # 致于需要经过多次调整才能将误差函数曲面降低 ) 而 在 误差曲 面较 高曲率 处 # 偏 导 数 较 大# 权值参数调节 的幅度也较大 # 以致在误差函数最小点附近发生过冲 现象 # 使权 值调节 路径 变 为 锯 齿 形 # 难以收敛到最小 点# 导致 B 算法收敛速度慢 % C " $ 但由于网络 误差 函数矩 阵的严 重 # B C 算法中权值参数的调节是沿误差函数梯度下降方向进行的 # 使这一梯度最速下降方向偏离面向误差曲面的最小点方向 # 从而急剧加长了权值参数到最小点的 病态性 # *+ 搜索路径 # 自然大大增加了 B 这也造成了 B C 算法的学习时间 # C 算法收敛速度慢 # % >" #! 带动量的批处理梯度下降算法 针对 B 作者提出了带动量的批处理梯 度下 降的思 想 # 即每 一个输 入样 本对 C 算法收敛速度慢的缺点 # 网络并不立即产生作用 # 而是等到全部输入样本到齐 # 将全部误差求和累加 # 再集中修改权值一次 # 即根据