决策树分类-8页文档资料
第4讲分类—决策树

Attrib2 Large Medium Small Medium Large Medium Large Small Medium Small
Attrib3 125K 100K 70K 120K 95K 60K 220K 85K 75K 90K
Class No No No No Yes No No Yes No Yes
Refund Yes NO No MarSt Single, Divorced TaxInc < 80K NO > 80K YES
10
Married
NO
2012-8-12
数据挖掘与知识管理
17
Apply Model to Test Data TFra bibliotekst Data
R efund M arital Status M arried Taxable Incom e 80K C heat ? No
Attrib2 Small Medium Large Small Large
Attrib3 55K 80K 110K 95K 67K
Class ? ? ? ? ?
Decision Tree
Deduction
Test Set
2012-8-12
数据挖掘与知识管理
19
2、决策树概念
2.1 分类树 2.2 医疗数据例子 2.3 决策树
Refund Yes NO No MarSt Single, Divorced TaxInc < 80K NO > 80K YES
10
Married
NO
2012-8-12
数据挖掘与知识管理
16
Apply Model to Test Data Test Data
决策树讲解

GainRatio ( A)
Gain( A) SplitInf( K )
SplitInf (K) 称为分裂信息,它反映了属性分裂数据的延展度与平衡性,计算公式如下: 在上式中,
SplitInf ( K )
i 1
1
2
3
4
SUGGESTION
16
Part 1
Part 2
Part 3
Part 4
C&RT
三、classification and regression tree(C&RT)(对二元分类比较有效) 1)可自动忽略对目标变量没有贡献的属性变量,也为判断属性变量的重要性,减少 变量数据提供参考; 2)在面对诸如存在缺失值、变量数多等问题时C&RT 显得非常稳健(robust); 3)估计模型通常不用花费很长的训练时间; 4)推理过程完全依据属性变量的取值特点(与 C5.0不同,C&RT的输出字段既可以 是数值型,也可以是分类型) 5)比其他模型更易于理解——从模型中得到的规则能得到非常直观的解释,决策推 理过程可以表示成IF…THEN的形式; 6)目标是定类变量为分类树,若目标变量是定距变量,则为回归树; 7)通过检测输入字段,通过度量各个划分产生的异质性的减小程度,找到最佳的一 个划分; 8)非常灵活,可以允许有部分错分成本,还可指定先验概率分布,可使用自动的成 本复杂性剪枝来得到归纳性更强的树。
4
决策树的发展
Part
2
Part 1
Part 2
Part 3
Part 4
决策树的发展
决策树方法是一种比较通用的分类函数逼近法,它是一种常用于预测
决策树分类

L 1 L 1
对比度反映了影像纹理的清晰度,纹理的沟纹越深, 其对比度越大,影像的视觉效果越清晰。 (5)非相似度 Dissimilarity: f 5 i j P(i, j )
i 0 j 0 L 1 L 1
非相似度与对比度相同,用来量测相似性,当局部区域 高
耕地
水体
未利用地
用户精度%
建1
43
5
11
1
0
5
3
63.24
建2
2
47
9
1
0
2
2
74.6
建3
9
4
41
7
3
3
17
48.81
绿地
0
0
1
51
4
1
6
80.95
耕地
0
0
1
9
43
0
0
81.13
水体
0
0
0
1
0
39
0
97.5
未利用地
4
4
10
0
3
0
25
54.35
生产精度%
74.14
78.33
56.16
决策树(部分)
4.基于决策树的分类试验(一)
洪泽湖试验区分类结果
基于决策树的研究区分类结果精度分析
分类总精度=83.81%, Kappa系数=0.8164。
基于决策树的分类试验(二)
水 体 居民地 道 路 荒草地 水 田 林 地 阴 影
江宁试验区基于决策树的分类结果
三种方法对江宁试验区各类地物分类的精度比较
2.4.2 纹理特征提取
决策树分类--ppt课件

数服从多数的原则在树叶上标出所属类别(不纯的类别) 5 否则,根据平均信息期望值E或GAIN值选出一个最佳属性作
为节点N的测试属性 6 节点属性选定后,对于该属性中的每个值:
从N生成一个分支,并将数据表中与该分支有关的数据收集形 成分支节点的数据表,在表中删除节点属性那一栏 7如果分支数据表属性非空,则转1,运用以上算法从该节点建立子树
按属性A对D划分后,数据集的信息熵:
InfoA (D)
v
j1
Dj D
*
Info(
D
j
)
其中, D j充当第 j 个划分的权重。 D
InfoA(D)越小, 表示划分的纯度越高
信息增益
Gain( A) Info(D) InfoA (D)
选择具有最高信息增益Gain(A) 的属性A作为分裂属性
(2)D中包含有20%的正例和80%的负例。 H(D) = -0.2 * log20.2 - 0.8 * log20.8 = 0.722
(3)D中包含有100%的正例和0%的负例。 H(D) = -1 * log21 - 0 * log20 =0
可以看到一个趋势,当数据变得越来越“纯”时,熵的值变得越来越小。 当D中正反例所占比例相同时,熵取最大值。 当D 中所有数据都只属于一个类时,熵得到最小值。 因此熵可以作为数据纯净度或混乱度的衡量指标。这正是决策树学习中 需要的。
学生 否 否 否 否 是 是 是 否 是 是 是 否 是 否
信用 一般 好 一般 一般 一般 好 好 一般 一般 一般 好 好 一般 好
买了电脑 否 否 是 是 是 否 是 否 是 是 是 是 是 否
决策树分类
∑ − pi log2 ( pi ) .其中,P 是任意样本属于c 的概率,一般可以用来si/s估计。 1
设一个属性 A 具有 V 个不同的值{ a1, a2,..., av }。利用属性 A 将集合 S 划分
为 V 个子集{ s1, s2 ,..., sv },其中 s 包含了集合 s 中属性 取 aj 值的数据样本。若 属性 A 被选为测试属性(用于对当前样本集进行划分),设 s 为子集 si 中属于 c 类 别的样本数。那么利用属性 A 划分当前样本集合所需要的信息(熵)可以计算如下:
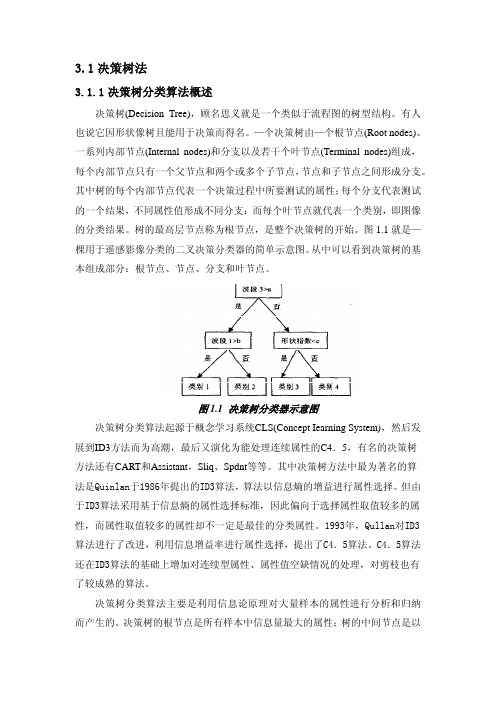
图 1.1 决策树分类器示意图 决策树分类算法起源于概念学习系统CLS(Concept Iearning System),然后发 展到ID3方法而为高潮,最后又演化为能处理连续属性的C4.5,有名的决策树 方法还有CART和Assistant,Sliq、Spdnt等等。其中决策树方法中最为著名的算 法是Quinlan于1986年提出的ID3算法,算法以信息熵的增益进行属性选择。但由 于ID3算法采用基于信息熵的属性选择标准,因此偏向于选择属性取值较多的属 性,而属性取值较多的属性却不一定是最佳的分类属性。1993年,Qullan对ID3 算法进行了改进,利用信息增益率进行属性选择,提出了C4.5算法。C4.5算法 还在ID3算法的基础上增加对连续型属性、属性值空缺情况的处理,对剪枝也有 了较成熟的算法。 决策树分类算法主要是利用信息论原理对大量样本的属性进行分析和归纳 而产生的。决策树的根节点是所有样本中信息量最大的属性;树的中间节点是以
RID
Age
Income
Student Credit_rating Class
1
Youth
High
No
Fair
决策树

决策树所用图解符号及结构:
• 决策树形图是人们对某个决策问题未来可能发生的 状态与方案的可能结果所作出的预测在图纸上的分 析。因此画决策树形图的过程就是拟定各种可行方 案的过程,也是进行状态分析和估算方案结果值的 过程。画决策树形图时,应按照图的结构规范由左 向右逐步绘制、逐步分析。其步骤如下: • (1)根据实际决策问题,以初始决策点为树根出发, 从左至右分别选择决策点、方案枝、状态节点、概 率枝等画出决策树。 • (2)从右至左逐步计算各个状态节点的期望收益值 或期望损失值,并将其数值标在各点上方。 • (3)在决策点将各状态节点上的期望值加以比较, 选取期望收益值最大的方案。对落选的方案要进行 “剪枝”,即在效益差的方案枝上画上“∥”符号。 最后留下一条效益最好的方案。
4
步骤
• 例2:某企业为了生产某种新产品,决定对一条生产线的 技术改造问题拟出两种方案,一是全部改造,二是部分改 造。若采用全部改造方案,需投资280万元。若采用部分 改造方案只需投资150万元;两个方案的使用期都是10年. 估计在此期间,新产品销路好的概率是0.7,销路不好的 概率是0.3,两个改造方案的年度损益值如表 所示。请问 该企业的管理者应如何决策改造方案。
8
谢谢欣赏
91Βιβλιοθήκη • 决策树基本模型 • 决策树又称决策图,是以方框和圆圈及节点,并由直线连 接而形成的一种像树枝形状的结构图。单阶段决策树如图 所示:
2
• (1)决策点:它是以方框表示的节点。一般决策点位于决 策树的最左端,即决策树的起点位置,但如果所作的决策属 于多阶决策,则决策树图形的中间可以有多个决策点方框, 以决策树“根”部的决策点为最终决策方案。 • (2)方案枝:它是由决策点起自左而右画出的若干条直线, 每条直线表示一个备选方案。方案枝表示解决问题的途径, 通常是两枝或两枝以上。 • (3)状态节点:在每个方案枝的末端画上一个“ ○”并注 上代号叫做状态节点。状态节点是决策分枝的终点,也是表 示一个备选方案可能遇到的自然状态的起点。其上方的数字 表示该方案的期望损益值。 • (4)概率枝:从状态节点引出的若干条直线叫概率枝,每 条直线代表一种自然状态及其可能出现的概率(每条分枝上 面注明自然状态及其概率)。 • (5)结果点:它是画在概率枝的末端的一个三角节点(△)。 在结果点处列出不同的方案在不同的自然状态及其概率条件 下的收益值或损失值。
《决策树分类》word版
基于专家知识的决策树分类概述基于知识的决策树分类是基于遥感影像数据及其他空间数据,通过专家经验总结、简单的数学统计和归纳方法等,获得分类规则并进行遥感分类。
分类规则易于理解,分类过程也符合人的认知过程,最大的特点是利用的多源数据。
如图1所示,影像+DEM就能区分缓坡和陡坡的植被信息,如果添加其他数据,如区域图、道路图土地利用图等,就能进一步划分出那些是自然生长的植被,那些是公园植被。
图1.JPG图1 专家知识决策树分类器说明图专家知识决策树分类的步骤大体上可分为四步:知识(规则)定义、规则输入、决策树运行和分类后处理。
1.知识(规则)定义规则的定义是讲知识用数学语言表达的过程,可以通过一些算法获取,也可以通过经验总结获得。
2.规则输入将分类规则录入分类器中,不同的平台有着不同规则录入界面。
3.决策树运行运行分类器或者是算法程序。
4.分类后处理这步骤与监督/非监督分类的分类后处理类似。
知识(规则)定义分类规则获取的途径比较灵活,如从经验中获得,坡度小于20度,就认为是缓坡,等等。
也可以从样本中利用算法来获取,这里要讲述的就是C4.5算法。
利用C4.5算法获取规则可分为以下几个步骤:(1)多元文件的的构建:遥感数据经过几何校正、辐射校正处理后,进行波段运算,得到一些植被指数,连同影像一起输入空间数据库;其他空间数据经过矢量化、格式转换、地理配准,组成一个或多个多波段文件。
(2)提取样本,构建样本库:在遥感图像处理软件或者GIS软件支持下,选取合适的图层,采用计算机自动选点、人工解译影像选点等方法采集样本。
(3)分类规则挖掘与评价:在样本库的基础上采用适当的数据挖掘方法挖掘分类规则,后基于评价样本集对分类规则进行评价,并对分类规则做出适当的调整和筛选。
这里就是C4.5算法。
4.5算法的基本思路基于信息熵来“修枝剪叶”,基本思路如下:从树的根节点处的所有训练样本D0开始,离散化连续条件属性。
计算增益比率,取GainRatio(C0)的最大值作为划分点V0,将样本分为两个部分D11和D12。
数据分类-决策树(PPT 71页)
no fair no excellent no fair no fair yes fair yes excellent yes excellent no fair yes fair yes fair yes excellent no excellent yes fair no excellent
属性
G a in (A ) I n fo (D ) I n fo A (D )
信息增益例子
类 P: buys_computer = “yes” 类 N: buys_computer = “no”
5
4
Infoage(D)
14
I(2,3)
14
I(4,0)
In fo (D ) 1 9 4 lo g 2 (1 9 4 ) 1 5 4 lo g 2 (1 5 4 ) 0 .9 4 0
16
分类的评价准则-约定和假设
给定测试集 X test {( xi , yi ) | i 1,2, , N }, 其中 N 表示测试集中的样本个 数; xi表示测试集中的数据样 本; yi表示数据样本 xi的类标号; 假设分类问题含有 m 个类别,则 yi {c1, c2 , , cm } 对于测试集的第 j个类别,设定: 被正确分类的样本数量 是 TP j 被错误分类的样本数量 是 FN j 其他类别被错误分类为 该类的样本数量是 FP j
适合的描述属性作为分支属性 ▪ 并根据该属性的不同取值向下建立分支
26
决策树示例-购买保险
A1-公司职员
否 否 否 否 是 是 是 否 是 是 是 否 是 否
A2-年龄
<=40 <=40 41~50 >50 >50 >50 41~50 <=40 <=40 >50 <=40 41~50 41~50 >50
决策树(完整)
二分类学习任务 属性 属性值
• 根结点:包含全部样本 • 叶结点:对应决策结果 “好瓜” “坏瓜” • 内部结点:对应属性测试
决策树学习的目的:为了产生一颗泛化能力强的决策树, 即处理未见示例能力强。
Hunt算法:
无需划分
无法划分 无法划分
不能划分 不能划分
1,2,3,4,5,6,8,10,15
验证集:4,5,8,9,11,12
训练集:好瓜 坏瓜 1,2,3,6,7,10,14,15,16,17 6,7,15,17
6,7,15 4,13 (T,F) 5 (F) 6 7,15
17
11,12 (T,T)
减去结点⑥ 4 验证集变为: 7 考察结点顺序: ⑥⑤②③①
8,9 (T,F)
7
9 (F)
15
1 1 0 0 Ent ( D ) Ent ( D ) ( log 2 log 2 ) 0 1 1 1 1
1 17
则“编号”的信息增益为:
1 Gain( D, 编号) Ent ( D) Ent ( Dv ) 0.998 v 1 17
远大于其他候选属性 信息增益准则对可取值数目较多的属性有所偏好
0998entd?220044loglog04444tentd?????228855loglog096113131313tentd????41317170263ttgaindentdentdentd????????密度0381根结点包含17个训练样本密度有17个不同取值候选划分点集合包含16个候选值每一个划分点能得到一个对应的信息增益密度好瓜0243否0245否0343否0360否0403是10437是20481是30556是40593否0680是50634是60639否0657否0666否0697是70719否0774是80381t?td?td?文档仅供参考如有不当之处请联系本人改正
决策树分类资料
预后评估:根据患者的病情和体质,评估预后情况
推荐系统领域
推荐系统:根据用户历史行为和偏好,为用户推荐商品或服务
应用场景:电商、视频、音乐、新闻等领域
决策树分类:用于预测用户偏好,提高推荐准确性
优势:易于理解和实现,适用于大规模数据
自然语言处理领域
情感分析:分析文本中的情感倾向,如正面、负面、中立等
应用:在实际应用中,可以减少信用卡欺诈损失,提高银行风控能力
结果:准确率较高,可以有效识别欺诈行为
方法:利用决策树分类算法,根据客户的交易行为、信用记录等信息进行分类
利用决策树分类进行情感分析
添加标题
添加标题
添加标题
添加标题
决策树分类:一种常用的机器学习算法,用于分类和预测
情感分析:通过分析文本中的情感倾向,判断文本的情感色彩
汇报人:XX
XX,
目录
决策树的定义
决策树是一种常用的分类算法,用于预测和分类数据
决策树通过创建一系列规则来预测目标变量
决策树由节点和边组成,每个节点代表一个特征,每个边代表一个决策
决策树的最终结果是一个分类结果,用于预测目标变量的值
决策树分类的原理
决策树是一种常用的分类算法,通过构建一棵决策树来预测目标变量的值。
实践案例:利用决策树分类算法进行情感分析,如电影评论、产品评价等
效果评估:准确率、召回率等指标评估决策树分类算法的效果
利用决策树分类进行客户细分
实践案例:某电商公司利用决策树分类技术对客户进行细分,提高营销效果
决策树分类的应用:在客户细分中,决策树分类可以帮助企业更好地理解客户需求,提高营销效果,降低营销成本。
随机森林算法
随机森林是一种集成学习方法,由多个决策树组成
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
基于专家知识的决策树分类概述基于知识的决策树分类是基于遥感影像数据及其他空间数据,通过专家经验总结、简单的数学统计和归纳方法等,获得分类规则并进行遥感分类。
分类规则易于理解,分类过程也符合人的认知过程,最大的特点是利用的多源数据。
如图1所示,影像+DEM就能区分缓坡和陡坡的植被信息,如果添加其他数据,如区域图、道路图土地利用图等,就能进一步划分出那些是自然生长的植被,那些是公园植被。
图1.JPG图1 专家知识决策树分类器说明图专家知识决策树分类的步骤大体上可分为四步:知识(规则)定义、规则输入、决策树运行和分类后处理。
1.知识(规则)定义规则的定义是讲知识用数学语言表达的过程,可以通过一些算法获取,也可以通过经验总结获得。
2.规则输入将分类规则录入分类器中,不同的平台有着不同规则录入界面。
3.决策树运行运行分类器或者是算法程序。
4.分类后处理这步骤与监督/非监督分类的分类后处理类似。
知识(规则)定义分类规则获取的途径比较灵活,如从经验中获得,坡度小于20度,就认为是缓坡,等等。
也可以从样本中利用算法来获取,这里要讲述的就是C4.5算法。
利用C4.5算法获取规则可分为以下几个步骤:(1)多元文件的的构建:遥感数据经过几何校正、辐射校正处理后,进行波段运算,得到一些植被指数,连同影像一起输入空间数据库;其他空间数据经过矢量化、格式转换、地理配准,组成一个或多个多波段文件。
(2)提取样本,构建样本库:在遥感图像处理软件或者GIS软件支持下,选取合适的图层,采用计算机自动选点、人工解译影像选点等方法采集样本。
(3)分类规则挖掘与评价:在样本库的基础上采用适当的数据挖掘方法挖掘分类规则,后基于评价样本集对分类规则进行评价,并对分类规则做出适当的调整和筛选。
这里就是C4.5算法。
4.5算法的基本思路基于信息熵来“修枝剪叶”,基本思路如下:从树的根节点处的所有训练样本D0开始,离散化连续条件属性。
计算增益比率,取GainRatio(C0)的最大值作为划分点V0,将样本分为两个部分D11和D12。
对属性C0的每一个值产生一个分支,分支属性值的相应样本子集被移到新生成的子节点上,如果得到的样本都属于同一个类,那么直接得到叶子结点。
相应地将此方法应用于每个子节点上,直到节点的所有样本都分区到某个类中。
到达决策树的叶节点的每条路径表示一条分类规则,利用叶列表及指向父结点的指针就可以生成规则表。
图2.JPG图2 规则挖掘基本思路算法描述如下:算法:从空间数据集(多波段文件)中挖掘分类规则输入:训练样本输出:分类规则表方法:一、读取数据集名字二、读取所有的训练样本A、读取属性信息C、原始类E、样本值A,并将样本划分为训练样本(2/3)和评价样本(1/3)。
B、属性信息C可以是连续(DISCRETE)或离散(CONTINUOUS)的,分别将属性注上这两种标记;若属性是DISCERTE,读取其可能取得值,并都存储在一个列表中;每一个属性都有一个标记,一个给定的属性编号及初始化的取值列表均存储于一个属性的数据结构中,并将数据结构存储在一个哈希表中。
C、原始类E当作一个附加属性信息储存在属性列表中。
D、以增量方式读取每一个样本A,将所有的样本储存在一个表中,每一行代表一个样本。
三、利用数据集构建树A、离散化连续条件属性C DISCRETE,获得的分割点集T(t1,t2……)作为条件属性C的新的取值。
B、分别计算所有条件属性的增益比率GainRatio(C),取增益比率值最大的条件属性作为树的划分节点,其值或范围作为划分值V(v1,v2……)来生成树的分枝。
C、判断该层与每一个等价子集的原始类类别是否一致。
若一致,生成叶子结点。
否则,继续计算增益比率GainRatio(C)和选择条件属性C,得到树的节点和划分值V,直至所有的样本已分类完毕。
四、测试生成树将测试样本C′带入树中,当某一测试样本的分类预测错误时,记录分类错误的计数,并将测试样本添加到训练样本中,转向步骤三,重新构建树。
否则,输出分类树五、抽取分类规则到达树的叶节点的每条路径表示一条分类规则从树中抽取分类规则,打印规则和分类的详细信息C4.5网上有源代码下载,vc和c++版本都能获得。
Decision Tree的使用一、规则获取选取Landsat TM5影像和这个地区对应的DEM数据,影像和DEM经过了精确配准。
规则如下描述:Class1(朝北缓坡植被):NDVI>0.3, slope<20, aspect<90 and aspect>270Class2(非朝北缓坡植被):NDVI>0.3, slope<20, 90<=aspect<=270Class3(陡坡植被):NDVI>0.3, slope>=20,Class4(水体):NDVI<=0.3, 0<b4<20Class5(裸地):NDVI<=0.3, b4>=20Class6(无数据区,背景): NDVI<=0.3, b4=0也可以按照二叉树描述方式:第一层,将影像分为两类,NDVI大于0.3,NDVI小于或等于0.3;第二层,NDVI高的,分为坡度大于或等于20度和坡度小于20度。
以此往下划分。
二、输入决策树规则打开主菜单->classification->Decision Tree->Build New Decision Tree,如图3所示,默认显示了一个节点。
图3.JPG图3 Decision Tree界面首先我们按照NDVI的大小划分第一个节点,单击Node1,跳出图4对话框,Name为NDVI>0.3,在Expression中填写:{ndvi} gt 0.3。
图4.JPG图4 添加规则表达式点击OK 后,会提示你给{ndvi}指定一个数据源,如图5所示,点击第一列中的变量,在对话框中选择相应的数据源,这样就完成第一层节点规则输入。
图5.JPG图5 指定数据源Expression 中的表达式是有变量和运算符(包括数学函数)组成,支持的运算符如表1所示表达式部分可用函数 基本运算符 +、-、*、/三角函数 正弦Sin(x)、余弦cos(x)、正切tan(x)反正弦Asin(x)、反余弦acos(x)、反正切atan(x)双曲线正弦Sinh(x)、双曲线余弦cosh(x)、双曲线正切tanh(x)关系/逻辑 小于LT 、小于等于LE 、等于EQ 、不等于NE 、大于等于GE 、大于GTand 、or 、not 、XOR最大值(>)、最小值 (<)其他符号 指数(^)、自然指数exp自然对数对数alog(x)以10为底的对数alog10(x)整形取整——round(x)、ceil(x)平方根(sqrt )、绝对值(adb )表1 运算符ENVI 决策树分类器中的变量是指一个波段的数据或作用于数据的一个特定函数。
变量名必须包含在大括号中,即{变量名};或者命名为bx ,x代表数据,比如哪一个波段。
如果变量被赋值为多波段文件,变量名必须包含一个写在方括号中的下标,表示波段数,比如{pc[2]}表示主成分分析的第一主成分。
支持特定变量名如表2,也可以通过IDL自行编写函数。
变量作用slope 计算坡度aspect 计算坡向ndvi 计算归一化植被指数Tascap [n]穗帽变换,n表示获取的是哪一分量。
pc [n]主成分分析,n表示获取的是哪一分量。
lpc局部主成分分析,n表示获取的是哪一分量。
[n]mnf [n] 最小噪声变换,n表示获取的是哪一分量。
Lmnf[n]局部最小噪声变换,n表示获取的是哪一分量。
Stdev波段n的标准差[n]lStdev波段n的局部标准差0[n]Mean波段n的平均值[n]lMean波段n的局部平均值[n]Min [n]、max波段n的最大、最小值[n]lMin [n]、lmax波段n的局部最大、最小值[n]表2变量表达式第一层节点根据NDVI的值划分为植被和非植被,如果不需要进一步分类的话,这个影像就会被分成两类:class0和class1。
对NDVI大于0.3,也就是class1,根据坡度划分成缓坡植被和陡坡植被。
在class1图标上右键,选择Add Children。
单击节点标识符,打开节点属性窗口,Name 为Slope<20,在Expression中填写:{Slope} lt 20。
同样的方法,将所有规则输入,末节点图标右键Edit Properties,可以设置分类结果的名称和颜色,最后结果如图6所示。
图6.JPG图6 规则输入结果图三、执行决策树选择Options->Execute,执行决策树,跳出图7所示对话框,选择输出结果的投影参数、重采样方法、空间裁剪范围(如需要)、输出路径,点击OK之后,得到如图8所示结果。
在决策树运行过程中,会以不同颜色标示运行的过程。
图7.JPG图7 输出结果图8.JPG图8 决策树运行结果回到决策树窗口,在工作空白处点击右键,选择Zoom In,可以看到每一个节点或者类别有相应的统计结果(以像素和百分比表示)。
如果修改了某一节点或者类别的属性,可以左键单击节点或者末端类别图标,选择Execute,重新运行你修改部分的决策树。
图9.JPG图9 运行决策树后的效果分类后处理和其他计算机分类类似的过程。