线性判别分析LDA
LDA线性判别分析

LDA线性判别分析LDA(Linear Discriminant Analysis),也被称为Fisher线性判别分析,是一种经典的统计模型和机器学习算法,常用于降维和模式识别任务。
LDA的目标是寻找一个线性变换,将高维数据投影到一个低维子空间上,使得在该子空间上的投影具有最优的数据分离性能。
换句话说,LDA希望找到投影方式,使得不同类别的数据在低维子空间上的投影显著分离,并且同一类别内部的数据尽可能地紧密聚集。
LDA的基本思想是通过计算类间离散度矩阵和类内离散度矩阵来得到最佳的投影方向。
类间离散度矩阵度量的是不同类别数据分布之间的差异,而类内离散度矩阵度量的是同一类别内部数据之间的差异。
LDA目标函数可以表示为J(w)=w^T*Sw*w/(w^T*Sb*w),其中w是投影方向,Sw为类内离散度矩阵,Sb为类间离散度矩阵。
在实际应用中,我们需要先计算类内离散度矩阵Sw和类间离散度矩阵Sb,然后通过求解J(w)的最大值来得到最佳的投影方向w。
通常情况下,可以通过特征值分解或者广义特征值分解来求解最优的投影方向。
LDA的应用非常广泛,特别是在模式识别和计算机视觉领域。
它可以用于人脸识别、手写数字识别、垃圾邮件过滤等任务。
LDA的优点是在高维数据集中可以找到最优的投影方向,具有很好的数据分离性能。
而且LDA不需要事先假设数据分布的形式,适用于各种分布情况。
然而,LDA也存在一些限制。
首先,LDA假设数据满足多元正态分布,如果数据违反了该假设,那么LDA的判别性能可能会下降。
其次,LDA投影到的低维子空间的维度最多等于类别数减一,这可能导致信息丢失。
此外,当类别样本数量不平衡时,LDA的效果可能会受到影响。
为了克服LDA的局限性,人们提出了一些改进的方法。
例如,局部判别分析(Local Discriminant Analysis)可以在局部区域内构建LDA模型,适用于非线性可分的数据。
深度学习的发展也为LDA的改进提供了新的思路和方法,如稀疏表示LDA和核LDA等。
linear discriminate analysis

linear discriminate analysis【实用版】目录1.线性判别分析的定义和基本概念2.线性判别分析的应用场景和问题解决能力3.线性判别分析的具体方法和步骤4.线性判别分析的优缺点和局限性5.线性判别分析的实际应用案例正文线性判别分析(Linear Discriminant Analysis,简称 LDA)是一种常用的监督学习方法,主要用于解决分类问题。
它是一种线性分类方法,通过找到一个最佳的线性分类器,将数据分为不同的类别。
LDA 基于数据分布的假设,即不同类别的数据具有不同的分布,通过最大化类内差异和最小化类间差异来实现分类。
LDA 的应用场景非常广泛,可以用于文本分类、图像分类、生物信息学、社会科学等领域。
在这些领域中,LDA 能够有效地解决分类问题,提高分类准确率。
例如,在文本分类中,LDA 可以通过分析词汇分布,将文本分为不同的主题或类别。
线性判别分析的具体方法和步骤如下:1.收集数据并计算数据矩阵。
2.计算数据矩阵的协方差矩阵和矩阵的特征值和特征向量。
3.根据特征值和特征向量构建线性分类器。
4.使用分类器对数据进行分类。
尽管 LDA 在分类问题上表现良好,但它也存在一些优缺点和局限性。
首先,LDA 要求数据矩阵的列向量是线性无关的,这可能会限制其在某些数据集上的表现。
其次,LDA 对数据中的噪声非常敏感,噪声的存在可能会对分类结果产生不良影响。
此外,LDA 是一种基于线性分类的方法,对于非线性分类问题可能无法有效解决。
尽管如此,LDA 在实际应用中仍然具有很高的价值。
例如,在文本分类中,LDA 可以有效地识别不同主题的文本,并为用户提供个性化的推荐。
在生物信息学中,LDA 可以用于基因表达数据的分类,以识别不同类型的细胞或疾病。
在社会科学中,LDA 可以用于对调查数据进行分类,以便更好地理解受访者的需求和偏好。
总之,线性判别分析是一种强大的分类方法,可以应用于各种领域。
线性判别分析

线性判别分析
线性判别分析(linear discriminant analysis,LDA)是对费舍尔的线性鉴别方法的归纳,这种方法使用统计学,模式识别和机器学习方法,试图找到两类物体或事件的特征的一个线性组合,以能够特征化或区分它们。
所得的组合可用来作为一个线性分类器,或者,更常见的是,为后续的分类做降维处理。
之前我们讨论的PCA、ICA也好,对样本数据来言,可以是没有类别标签y的。
回想我们做回归时,如果特征太多,那么会产生不相关特征引入、过度拟合等问题。
我们可以使用PCA来降维,但PCA没有将类别标签考虑进去,属于无监督的。
比如回到上次提出的文档中含有“learn”和“study”的问题,使用PCA后,也许可以将这两个特征合并为一个,降了维度。
但假设我们的类别标签y是判断这篇文章的topic是不是有关学习方面的。
那么这两个特征对y几乎没什么影响,完全可以去除。
Fisher提出LDA距今已近七十年,仍然是降维和模式分类领域应用中最为广泛采用而且极为有效的方法之一,其典型应用包括人脸检测、人脸识别、基于视觉飞行的地平线检测、目标跟踪和检测、信用卡欺诈检测和图像检索、语音识别等。
线性判别分析(LinearDiscriminantAnalysis,LDA)

线性判别分析(LinearDiscriminantAnalysis,LDA)⼀、LDA的基本思想线性判别式分析(Linear Discriminant Analysis, LDA),也叫做Fisher线性判别(Fisher Linear Discriminant ,FLD),是模式识别的经典算法,它是在1996年由Belhumeur引⼊模式识别和⼈⼯智能领域的。
线性鉴别分析的基本思想是将⾼维的模式样本投影到最佳鉴别⽮量空间,以达到抽取分类信息和压缩特征空间维数的效果,投影后保证模式样本在新的⼦空间有最⼤的类间距离和最⼩的类内距离,即模式在该空间中有最佳的可分离性。
如下图所⽰,根据肤⾊和⿐⼦⾼低将⼈分为⽩⼈和⿊⼈,样本中⽩⼈的⿐⼦⾼低和⽪肤颜⾊主要集中A组区域,⿊⼈的⿐⼦⾼低和⽪肤颜⾊主要集中在B组区域,很显然A组合B组在空间上明显分离的,将A组和B组上的点都投影到直线L上,分别落在直线L的不同区域,这样就线性的将⿊⼈和⽩⼈分开了。
⼀旦有未知样本需要区分,只需将⽪肤颜⾊和⿐⼦⾼低代⼊直线L的⽅程,即可判断出未知样本的所属的分类。
因此,LDA的关键步骤是选择合适的投影⽅向,即建⽴合适的线性判别函数(⾮线性不是本⽂的重点)。
⼆、LDA的计算过程1、代数表⽰的计算过程设已知两个总体A和B,在A、B两总体分别提出m个特征,然后从A、B两总体中分别抽取出、个样本,得到A、B两总体的样本数据如下:和假设存在这样的线性函数(投影平⾯),可以将A、B两类样本投影到该平⾯上,使得A、B两样本在该直线上的投影满⾜以下两点:(1)两类样本的中⼼距离最远;(2)同⼀样本内的所有投影距离最近。
我们将该线性函数表达如下:将A总体的第个样本点投影到平⾯上得到投影点,即A总体的样本在平⾯投影的重⼼为其中同理可以得到B在平⾯上的投影点以及B总体样本在平⾯投影的重⼼为其中按照Fisher的思想,不同总体A、B的投影点应尽量分开,⽤数学表达式表⽰为,⽽同⼀总体的投影点的距离应尽可能的⼩,⽤数学表达式表⽰为,,合并得到求从⽽使得得到最⼤值,分别对进⾏求导即可,详细步骤不表。
LDA线性判别分析报告

LDA线性判别分析报告LDA线性判别分析(Linear Discriminant Analysis)是一种经典的线性分类方法。
它的目的是通过线性投影将数据从高维空间降维到低维空间,并在降维后的空间中寻找最佳的分类边界。
LDA在模式识别和机器学习领域有广泛的应用,特别在人脸识别、语音识别等领域取得了较好的效果。
LDA是一种有监督的降维方法,它在降维的同时将数据的类别信息考虑进去。
具体来说,LDA的目标是使得同一类别的数据点尽量聚集在一起,不同类别之间的距离尽量拉大。
这样一来,在降维后的空间中,可以更容易找到线性分类边界,从而提高分类的准确度。
LDA的思想基于以下两个假设:1.数据符合高斯分布。
LDA假设每个类别的数据点都符合高斯分布,且各个类别的协方差矩阵相同。
2.数据点是独立的。
LDA假设不同类别的数据点之间是独立的。
LDA的步骤如下:1.计算各个类别的均值向量。
对于有N个类别的数据,每个类别的均值向量可以通过计算平均值得到。
2.计算类内散度矩阵(Sw)和类间散度矩阵(Sb)。
类内散度矩阵衡量了同一类别数据点之间的差异,可以通过计算每个类别内部数据点和对应的均值向量之间的协方差矩阵的和来求得。
类间散度矩阵衡量了不同类别数据点之间的差异,可以通过计算不同类别均值向量之间的协方差矩阵的加权和来求得。
3.解LDA的优化问题。
LDA的目标是最大化类间散度矩阵与类内散度矩阵的比值,可以通过对Sw的逆矩阵与Sb的乘积进行特征值分解得到最佳投影方向。
4.选取投影方向。
根据上一步骤求得的特征值,选择最大的k个特征值对应的特征向量,这些特征向量构成了投影矩阵W。
其中k为降维后的维度,通常比原本的维度小。
LDA的优点在于它能充分利用类别信息,提高分类的准确度。
同时,LDA计算简单且直观,对数据的分布并没有太多的假设要求。
然而,LDA 也有一些限制。
首先,LDA假设数据符合高斯分布,这对于一些非线性数据是不适用的。
其次,LDA是一种线性分类方法,对于非线性问题可能效果不佳。
线性判别分析(LDA)
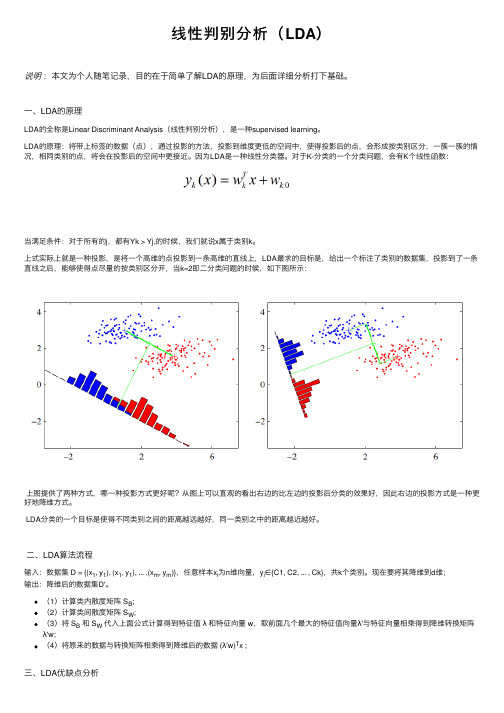
线性判别分析(LDA)说明:本⽂为个⼈随笔记录,⽬的在于简单了解LDA的原理,为后⾯详细分析打下基础。
⼀、LDA的原理LDA的全称是Linear Discriminant Analysis(线性判别分析),是⼀种supervised learning。
LDA的原理:将带上标签的数据(点),通过投影的⽅法,投影到维度更低的空间中,使得投影后的点,会形成按类别区分,⼀簇⼀簇的情况,相同类别的点,将会在投影后的空间中更接近。
因为LDA是⼀种线性分类器。
对于K-分类的⼀个分类问题,会有K个线性函数:当满⾜条件:对于所有的j,都有Yk > Yj,的时候,我们就说x属于类别k。
上式实际上就是⼀种投影,是将⼀个⾼维的点投影到⼀条⾼维的直线上,LDA最求的⽬标是,给出⼀个标注了类别的数据集,投影到了⼀条直线之后,能够使得点尽量的按类别区分开,当k=2即⼆分类问题的时候,如下图所⽰:上图提供了两种⽅式,哪⼀种投影⽅式更好呢?从图上可以直观的看出右边的⽐左边的投影后分类的效果好,因此右边的投影⽅式是⼀种更好地降维⽅式。
LDA分类的⼀个⽬标是使得不同类别之间的距离越远越好,同⼀类别之中的距离越近越好。
⼆、LDA算法流程输⼊:数据集 D = {(x1, y1), (x1, y1), ... ,(x m, y m)},任意样本x i为n维向量,y i∈{C1, C2, ... , Ck},共k个类别。
现在要将其降维到d维;输出:降维后的数据集D'。
(1)计算类内散度矩阵 S B;(2)计算类间散度矩阵 S W;(3)将 S B和 S W代⼊上⾯公式计算得到特征值λ和特征向量 w,取前⾯⼏个最⼤的特征值向量λ'与特征向量相乘得到降维转换矩阵λ'w;(4)将原来的数据与转换矩阵相乘得到降维后的数据 (λ'w)T x ;三、LDA优缺点分析LDA算法既可以⽤来降维,⼜可以⽤来分类,但是⽬前来说,主要还是⽤于降维。
数据挖掘中的线性判别分析方法原理解析

数据挖掘中的线性判别分析方法原理解析数据挖掘是一门利用计算机技术从大量数据中挖掘出有用信息的学科。
在这个信息爆炸的时代,人们面临着海量的数据,如何从中提取出有价值的信息成为了一项重要的任务。
线性判别分析(Linear Discriminant Analysis,简称LDA)是数据挖掘中一种常用的分类方法,它能够在高维数据中找到最佳的投影方向,从而实现数据的降维和分类。
LDA方法的基本思想是在保持不同类别之间的区分能力最大化的同时,最大化同一类别内部的相似性。
具体而言,LDA通过计算类别之间的散度和类别内部的散度来确定最佳的投影方向。
散度可以理解为数据的离散程度,散度越大表示数据之间的差异越大,散度越小表示数据之间的差异越小。
在进行LDA之前,首先需要对数据进行预处理。
通常情况下,我们会对数据进行标准化处理,使得数据的均值为0,方差为1。
这样可以避免某些特征对于分类结果的影响过大。
接下来,我们需要计算类别之间的散度和类别内部的散度。
类别之间的散度可以通过计算不同类别之间的均值差异来得到。
而类别内部的散度可以通过计算每个类别内部的协方差矩阵来得到。
协方差矩阵描述了数据之间的相关性,可以用来衡量数据的离散程度。
在计算完散度之后,我们需要求解一个优化问题,即最大化类别之间的散度和最小化类别内部的散度。
这个优化问题可以通过求解广义瑞利商的最大特征值和对应的特征向量来实现。
最大特征值对应的特征向量就是最佳的投影方向,它能够将数据从高维空间映射到一维空间。
通过LDA方法,我们可以将高维数据映射到低维空间,并且保持了数据的分类信息。
这样不仅可以减少数据的维度,降低计算复杂度,还可以提高分类的准确性。
除了在数据挖掘中的应用,LDA方法还被广泛应用于模式识别、人脸识别、图像处理等领域。
在人脸识别中,LDA可以提取出最具有判别性的特征,从而提高识别的准确性。
在图像处理中,LDA可以将图像从高维空间映射到低维空间,从而实现图像的降噪和压缩。
模式识别上lda的原理

模式识别上lda的原理
LDA(Linear Discriminant Analysis,线性判别分析)是一种经典的模式识别技术,用于降维、分类和数据可视化等任务。
其基本原理基于最大化类间差异和最小化类内差异,以找到能够有效区分不同类别的特征。
LDA 的主要目标是找到一个投影方向,使得投影后的数据在该方向上具有最大的可分性。
具体来说,LDA 假设数据来自两个或多个类别,并且每个类别可以通过一个高斯分布来描述。
通过找到一个投影方向,使得不同类别之间的投影距离尽可能大,同时同一类别内的投影距离尽可能小。
LDA 的原理可以通过以下步骤来解释:
1. 数据预处理:将数据进行标准化或中心化处理,使得每个特征具有零均值和单位方差。
2. 计算类内散度矩阵:通过计算每个类别的样本在原始特征空间中的协方差矩阵,得到类内散度矩阵。
3. 计算类间散度矩阵:通过计算所有类别样本的总体协方差矩阵,得到类间散度矩阵。
4. 计算投影方向:通过求解类间散度矩阵的特征值和特征向量,找到能够最大化类间差异的投影方向。
5. 投影数据:将原始数据在找到的投影方向上进行投影,得到降维后的特征。
6. 分类或可视化:可以使用投影后的特征进行分类任务或数据可视化。
LDA 的原理基于统计学习和降维的思想,通过最大化类间差异和最小化类内差异来找到最具判别力的投影方向。
它在模式识别和数据分析中具有广泛的应用,如人脸识别、语音识别和文本分类等领域。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
LDA 算法入门一.LDA 算法概述:线性判别式分析(Linear Discriminant Analysis , LDA),也叫做Fisher 线性判别(Fisher Linear Discriminant ,FLD),是模式识别的经典算法,它是在1996年由Belhumeur 引入模式识别和人工智能领域的。
线性鉴别分析的基本思想是将高维的模式样本投影到最佳鉴别矢量空间,以达到抽取分类信息和压缩特征空间维数的效果,投影后保证模式样本在新的子空间有最大的类间距离和最小的类内距离,即模式在该空间中有最佳的可分离性。
因此,它是一种有效的特征抽取方法。
使用这种方法能够使投影后模式样本的类间散布矩阵最大,并且同时类内散布矩阵最小。
就是说,它能够保证投影后模式样本在新的空间中有最小的类内距离和最大的类间距离,即模式在该空间中有最佳的可分离性。
二. LDA 假设以及符号说明:假设对于一个nR 空间有m 个样本分别为12,,m x x x ,即每个x 是一个n 行的矩阵,其中in 表示属第i类的样本个数,假设一共有c 个类,则12i c n n n n m ++++=。
b S : 类间离散度矩阵 w S :类内离散度矩阵i n :属于i 类的样本个数 i x :第i 个样本 u :所有样本的均值i u :类i 的样本均值三. 公式推导,算法形式化描述根据符号说明可得类i 的样本均值为:1i x classiiu x n ∈=∑ (1.1)同理我们也可以得到总体样本均值:11mi i u x m ==∑(1.2)根据类间离散度矩阵和类内离散度矩阵定义,可以得到如下式子:()()1cTb i i i i S n u u u u ==--∑(1.3)()()1k cTw i k i k i x classiS u x u x =∈=--∑∑ (1.4)当然还有另一种类间类内的离散度矩阵表达方式:()()()1cTb i i i S P i u u u u ==--∑ (1.5)()()()(){}11(i)(i)E |k cTw i k i k i x classii cTi i i P S u x u x n P u x u x x classi=∈==--=--∈∑∑∑ (1.6)其中()P i 是指i 类样本的先验概率,即样本中属于i 类的概率()in P i m=,把()P i 代入第二组式子中,我们可以发现第一组式子只是比第二组式子都少乘了1m ,我们将在稍后进行讨论,其实对于乘不乘该1m,对于算法本身并没有影响,现在我们分析一下算法的思想, 我们可以知道矩阵()()Ti i u u u u --的实际意义是一个协方差矩阵,这个矩阵所刻画的是该类与样本总体之间的关系,其中该矩阵对角线上的函数所代表的是该类相对样本总体的方差(即分散度),而非对角线上的元素所代表是该类样本总体均值的协方差(即该类和总体样本的相关联度或称冗余度),所以根据公式(1.3)可知(1.3)式即把所有样本中各个样本根据自己所属的类计算出样本与总体的协方差矩阵的总和,这从宏观上描述了所有类和总体之间的离散冗余程度。
同理可以的得出(1.4)式中为分类内各个样本和所属类之间的协方差矩阵之和,它所刻画的是从总体来看类内各个样本与类之间(这里所刻画的类特性是由是类内各个样本的平均值矩阵构成)离散度,其实从中可以看出不管是类内的样本期望矩阵还是总体样本期望矩阵,它们都只是充当一个媒介作用,不管是类内还是类间离散度矩阵都是从宏观上刻画出类与类之间的样本的离散度和类内样本和样本之间的离散度。
LDA 做为一个分类的算法,我们当然希望它所分的类之间耦合度低,类内的聚合度高,即类内离散度矩阵的中的数值要小,而类间离散度矩阵中的数值要大,这样的分类的效果才好。
这里我们引入Fisher 鉴别准则表达式:()T b fisher Tw S J S ϕϕϕϕϕ= (1.7)其中ϕ为任一n 维列矢量。
F isher 线性鉴别分析就是选取使得()fisherJ ϕ达到最大值的矢量ϕ作为投影方向,其物理意义就是投影后的样本具有最大的类间离散度和最小的类内离散度。
我们把公式(1.4)和公式(1.3)代入公式(1.7)得到:()()()()()11k cTTi i i i fisher cTT i k i k i x classin u u u u J u x u x ϕϕϕϕϕ==∈--=--∑∑∑(1.8)我们可以设矩阵()T i R u u ϕ=-其中ϕ可以看成是一个空间,也就是说()T i u u ϕ-是()i u u -构成的低维空间(超平面)的投影。
()()TT i i u u u u ϕϕ--也可表示为T R R ,而当样本为列向量时,T RR 即表示()i u u -在ϕ空间的几何距离的平方。
所以可以推出Fisher 线性鉴别分析表达式的分子即为样本在投影ϕ空间下的类间几何距离的平方和,同理也可推出分母为样本在投影ϕ空间下的类内几何距离的平方差,所以分类问题就转化到找一个低维空间使得样本投影到该空间下时,投影下来的类间距离平方和与类内距离平方和之比最大,即最佳分类效果。
所以根据上述思想,即通过最优化下面的准则函数找到有一组最优鉴别矢量构成的投影矩阵opt W (这里我们也可以看出1m可以通过分子分母约掉,所以前面所提到的第一组公式和第二组公式所表达的效果是一样的)。
[]12arg max,,T b opt n Tw W S W W w w w W S W==(1.9)可以证明,当w S 为非奇异(一般在实现LDA 算法时,都会对样本做一次PCA 算法的降维,消除样本的冗余度,从而保证w S 是非奇异阵,当然即使w S 为奇异阵也是可以解的,可以把w S 或b S 对角化,这里不做讨论,假设都是非奇异的情况)时,最佳投影矩阵opt W 的列向量恰为下来广义特征方程b w S S ϕλϕ=(1.10)的d 个最大的特征值所对应的特征向量(矩阵1w b S S -的特征向量),且最优投影轴的个数1dc ≤- 。
根据(1.10)式可以推出 b i w i S S ϕλϕ=(1.11)又由于[]12,,,d Wϕϕϕ=下面给出验证:把(1.10)式代入(1.9)式可得:11111111max T T b w b w T T b dd w d d b dd d w d T T T i b i i i w i i i w i iTTTi w ii w ii w iS S S S S S S S S S S S S S ϕλϕϕϕϕλϕϕλϕϕϕϕλϕϕϕϕλϕλϕϕλϕϕϕϕϕϕ===⇒===⇒==== (1.12)根据公式的意义来看,要使得max 最大则只要取i λ 即可。
所以根据公式(1.9)可得出结论:投影矩阵opt W 的列向量为d (自取)个最大特征值所对应的特征向量,其中1d c ≤- 。
四.算法的物理意义和思考4.1 用一个例子阐述LDA算法在空间上的意义下面我们利用LDA进行一个分类的问题:假设一个产品有两个参数来衡量它是否合格,我们假设两个参数分别为:2.95 6.632.537.793.57 5.653.16 5.472.58 4.462.16 6.223.27 3.52实验数据来源:/kardi/tutorial/LDA/Numerical%20Example.html所以我们可以根据上图表格把样本分为两类,一类是合格的,一类是不合格的,所以我们可以创建两个数据集类:cls1_data =2.9500 6.63002.5300 7.79003.5700 5.65003.1600 5.4700cls2_data =2.5800 4.46002.1600 6.22003.2700 3.5200其中cls1_data为合格样本,cls2_data为不合格的样本,我们根据公式(1.1),(1.2)可以算出合格的样本的期望值,不合格类样本的合格的值,以及总样本期望:E_cls1 =3.0525 6.3850E_cls2 =2.6700 4.7333E_all =2.8886 5.6771我们可以做出现在各个样本点的位置:图一其中蓝色‘*’的点代表不合格的样本,而红色实点代表合格的样本,天蓝色的倒三角是代表总期望,蓝色三角形代表不合格样本的期望,红色三角形代表合格样本的期望。
从x,y轴的坐标方向上可以看出,合格和不合格样本区分度不佳。
我们在可以根据表达式(1.3),(1.4)可以计算出类间离散度矩阵和类内离散度矩阵:Sb =0.0358 0.15470.1547 0.6681 Sw =0.5909 -1.3338 -1.3338 3.5596我们可以根据公式(1.10),(1.11)算出1w b S S 特征值以及对应的特征向量:L =0.0000 0 0 2.8837对角线上为特征值,第一个特征值太小被计算机约为0了 与他对应的特征向量为 V =-0.9742 -0.9230 0.2256 -0.3848根据取最大特征值对应的特征向量:(-0.9230,-0.3848),该向量即为我们要求的子空间,我们可以把原来样本投影到该向量后 所得到新的空间(2维投影到1维,应该为一个数字) new_cls1_data = -5.2741 -5.3328 -5.4693 -5.0216为合格样本投影后的样本值 new_cls2_data = -4.0976 -4.3872 -4.3727为不合格样本投影后的样本值,我们发现投影后,分类效果比较明显,类和类之间聚合度很高,我们再次作图以便更直观看分类效果图二蓝色的线为特征值较小所对应的特征向量,天蓝色的为特征值较大的特征向量,其中蓝色的圈点为不合格样本在该特征向量投影下来的位置,二红色的‘*’符号的合格样本投影后的数据集,从中个可以看出分类效果比较好(当然由于x,y轴单位的问题投影不那么直观)。
我们再利用所得到的特征向量,来对其他样本进行判断看看它所属的类型,我们取样本点(2.81,5.46),我们把它投影到特征向量后得到:result = -4.6947 所以它应该属于不合格样本。
4.2 LDA算法与PCA算法在传统特征脸方法的基础上,研究者注意到特征值打的特征向量(即特征脸)并一定是分类性能最好的方向,而且对K-L变换而言,外在因素带来的图像的差异和人脸本身带来的差异是无法区分的,特征脸在很大程度上反映了光照等的差异。
研究表明,特征脸,特征脸方法随着光线,角度和人脸尺寸等因素的引入,识别率急剧下降,因此特征脸方法用于人脸识别还存在理论的缺陷。
线性判别式分析提取的特征向量集,强调的是不同人脸的差异而不是人脸表情、照明条件等条件的变化,从而有助于提高识别效果。