minitab实例分析(1)合集
minitab应用实例

从一个分类总体中抽样
加 工 的 直 径
加工的轴 2组的样本
总体
样本
minitab应用实例
过程抽样
过程在运动
总体抽样
样本
有助于理解过程的特性和状况
样本
决定总体的特征
minitab应用实例
抽样的方法
随机抽样
分组随机抽样
minitab应用实例
应采取什么方法从总体或过程抽样?
大多数的统计工具需要使用随机的和有代表性的数据。不论你是从一个过程 还是从一个总体收集数据,你必须选定正确的抽样方法,以确保你的样本从 统计角度看是有效的。
总体
过程
minitab应用实例
过程抽样
过程在运动
总体抽样
样本
有助于理解过程的特性和状况
一直关注数据! 哪些 KPIV 在驱动 KPOV? 从统计 角度讲, 你需要检查什么?
minitab应用实例
直方图
过程居中,分散及形状
为什么使用直方图?
•汇总一定时间内收集的数据. •用图形显示出数据的频率分布.
如何使用?
运用直方图显示数据的频率分布
直方图有什么作用?
•体现数据分布频率 •揭示数据的居中,偏差及形状 •显示数据的分布。 •作为预测未来过程表现的工具 •帮助确定过程变化 •帮助回答如下问题: “该过程的能力是否能满足我的客户的需求?” •用来显示大量数据的简单有用的工具
minitab应用实例
2020/11/2
minitab应用实例
什么是总体?
“总体” 代表着. . .所有的信息 (人员, 物品,事件,活动,等.)
Minitab实际应用

Minitab还提供了强大的数据管理和过程控制功能,可以帮助用户管理和跟踪数据, 以及进行过程改进和控制。
Minitab与其他统计软件的比较
与其他统计软件相比,Minitab具有 易用性和直观性强的特点,使得用户 可以快速学习和掌握各种统计方法。
描述性统计量
计算数据的均值、中位数、众数、标准差等统计 量,以全面了解数据的基本特征。
数据筛选和整理
对数据进行筛选和整理,去除异常值和缺失值, 确保数据质量。
推论性统计分析
参数估计
使用参数估计方法,对总体参数进行估计,如总体均 值和总体比例。
假设检验
通过假设检验方法,对总体参数进行假设检验,判断 假设是否成立。
方差分析
使用方差分析方法,比较不同组数据的均值是否存在 显著差异。
图表制作与展示
01
02
03
直方图
使用直方图展示数据的分 布情况,直观地了解数据 的形状和变化趋势。
箱线图
使用箱线图展示数据的中 心趋势、异常值和离群点。
散点图
使用散点图展示两个变量 之间的关系,判断是否存 在相关性。
03
Minitab在质量控制中的应用
制定改进计划
利用Minitab的流程图和矩阵工具,制 定详细的改进计划和时间表。
测量阶段的应用
数据收集
使用Minitab的数据输入和整理功能,确保数据准确无误地录 入。
测量系统分析
通过Minitab的统计分析工具,评估测量系统的稳定性和准确 性。
分析阶段的应用
描述性统计分析
利用Minitab的图表和统计功能,对数据进行初步的描述性分析,了解数据的 分布和异常值情况。
minitab之MSA分析实例
M--工序能力分析(连续型):案例:Camshaft.MTW ① 工程能力统计:
短期 工序能力
长期 工序能力
X平均=目标值 -> Cp=Cpm
X平均≠目标值 -> Cp > Cpm
② 求解Zst(输入历史均值):
历史均值:表示强行将它拉到中心位置 ->不考虑偏移-> Zst (Bench)
③ 求解Zlt(无历史均值):
A—假设测定:
(4): 2 proportion t(离散-单样本)
< 统计-基本统计量- 2 proportion t: >
背景:为确认两台设备不良率是否相等,
A: 检查1000样本,检出14不良, B: 检查1200样本,检出13不良, 能否说P1=P2? (α = 0.05 )
P-Value > 0.05 → Ho →P1 = P2
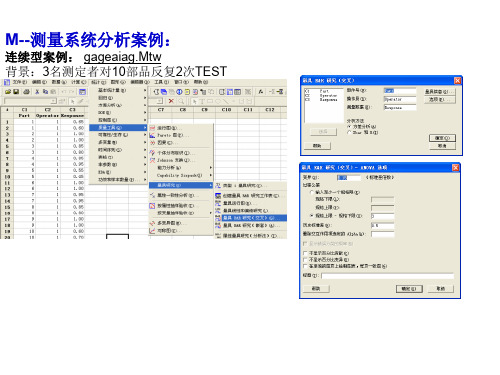
M--测量系统分析案例:
连续型案例: gageaiag.Mtw 背景:3名测定者对10部品反复2次TEST
所有点落在管理界限内 ->良好
大部分点落在管理界限外 ->主变动原因:部品变动
->良好
->测量值随部品的变动 ->测量值随OP的变动
->对于部品10,OP有较大分歧;
M--测量系统分析: 离散型案例(名目型):gage名目.Mtw
通过分散分析,判断1次效果、2次效果的有意性; - 主效果有有意, - 交互效果无有意。
显示因子的水准不能线性变换 (Coded) 时的回归系数. - Coded是指实际因子水准 (-1, +1)变换为线性变换。
I — DOE: (2):多因子不同水准 ① 因子配置设计:
MINITAB事例

2~4面(专用检具), 2~4(CMM) 的箱线图 双样本 T 检验和置信区间: 2~4面(专用检具), 样本 T
0.045
专用检具) 2 ~ 4 面 ( 专用检具 ) , 2 ~ 4 ( CMM ) 的箱线图
0.040 平均值 N 平均值 标准差 标准误 0.035 2~4面(专用检具) 10 0.02020 0.00962 0.0030 2~4(CMM) 10 0.02240 0.00972 0.0031 0.030 0.025 差值 = mu (2~4面(专用检具)) - mu (2~4(CMM)) 差值估计: -0.00220 差值的 95% 置信区间: (-0.01133, 0.00693) 0.020 差值 = 0 (与 ≠) 的 T 检验: T 值 = -0.51 P 值 = 0.618 自由度 = 17 0.015 0.010 2~4面(专用检具) 2~4(CMM) 数据
0.03 0.02 0.01
0.03 差值估计: 0.00190 差值的 95% 置信区间: (-0.01353, 0.01733) 0.02 差值 = 0 (与 ≠) 的 T 检验: T 值 = 0.26 P 值 = 0.798 自由度 = 17
P大于0.05无明显统计区别
0.01 0.00 1~3面(专用检具) 1~3面(CMM)
P大于0.05无明显统计区别
0.015 0.010 2~4面(专用检具) 2~4(CMM)
双样本 T 检验和置信区间: MAX(专用检具), max(CMM)
MAX ( 专用检具 ) , ma x ( CMM ) 的箱线图 专用检具)
MAX(专用检具) 与 max(CMM) 的双样本 T
0.14
平均值 0.12 N 平均值 标准差 标准误 MAX(专用检具) 10 0.0351 0.0165 0.0052 0.10 max(CMM) 10 0.0633 0.0252 0.0080
MSA测量系统分析之Minitab中文应用案例(步骤清晰实用)精选全文

应多数值在控 制限外
在控制限外表示过程实际 的变差大,同时表明测量 能力高。
均值
部件对比图:可显示在研究过程中所测量的并按部件排列的所有测量结果。测量结果用 点表示,平均值用带十字标的圆形符号表示。 判断:1.每个部件的多个测量值应紧靠在一起,表示测量的重复再现性的变差 小。
2.各平均值之间的差别应明显,这样可以清楚地看出各部件之间的差别。 例:图中的7#、10#重复测量的精确度较其他点要差,如果测量系统的R&R偏大时,可 以对7#、10#进行分析。
所有点落在管理界限内 ->良好
大部分点落在管理界限外 ->主变动原因:部品变动
->良好
->测量值随部品的变动 ->测量值随OP的变动
->对于部品10,OP有较大分歧;
M--测量系统分析: 离散型案例(名目型):gage名目.Mtw
背景:3名测定者对30部品反复2次TEST
检查者1需要再教育; 检查者3需要追加训练; (反复性)
(2).在量具信息与选项栏分别填入相关资料与信息。
填入相关 资料
注:其他选项若无要求,选择 默认项,不做改动。
一般为6 倍标准差
零件公差 规格
4.5、结果生成:数据表与图表
图表分析表
数据会话表
5.结果分析: (1)图表分析
变异分量条形图:展示了会话窗口中的计算结果,此图显示整个散布中R&R 占的比重是否充分小。 判断:量具R&R,重复(Repeat), 再现性(Reprod)越小越好。
A—假设测定:案例:2sample-t.MTW (2): 2-sample t(单样本)
① 正态性验证:
<统计-基本统计- 正态性检验 : >
minitab 分类模型案例

minitab 分类模型案例Minitab是一种常用的统计分析软件,它可以用于各种分类模型的建立和分析。
下面列举了10个基于Minitab的分类模型案例,来说明其在实际应用中的作用和效果。
1. 疾病诊断模型:医院收集了大量患者的临床数据和诊断结果,利用Minitab建立了一个疾病诊断模型。
该模型可以根据患者的临床指标,如血压、血糖、血脂等,预测患者是否患有某种疾病,并给出相应的诊断建议。
2. 信用评分模型:银行通过Minitab分析了大量客户的信用记录和还款情况,建立了一个信用评分模型。
该模型可以根据客户的个人信息、财务状况和信用历史等因素,预测客户的还款能力和风险等级,并据此决定是否给予贷款。
3. 市场细分模型:一家电商公司利用Minitab分析了大量用户的购物行为和偏好数据,建立了一个市场细分模型。
该模型可以根据用户的购买记录、浏览行为和兴趣标签等,将用户分为不同的市场细分群体,并据此进行个性化推荐和营销策略。
4. 员工离职预测模型:一家公司利用Minitab分析了员工的离职记录和个人信息,建立了一个员工离职预测模型。
该模型可以根据员工的职位、工龄、绩效等因素,预测员工是否有离职倾向,并据此采取相应的人力资源管理措施。
5. 欺诈检测模型:一家保险公司利用Minitab分析了保单的理赔记录和客户信息,建立了一个欺诈检测模型。
该模型可以根据保单的理赔金额、申请时间、客户的历史记录等因素,预测保单是否存在欺诈嫌疑,并据此采取相应的调查和处理措施。
6. 产品质量分类模型:一家制造公司利用Minitab分析了产品的质量数据和生产参数,建立了一个产品质量分类模型。
该模型可以根据产品的生产批次、工艺参数、质量指标等因素,预测产品的合格率和质量等级,并据此进行质量控制和改进。
7. 股票市场预测模型:一家投资公司利用Minitab分析了股票市场的历史数据和宏观经济指标,建立了一个股票市场预测模型。
该模型可以根据股票的历史价格、交易量、市场情绪等因素,预测股票的涨跌趋势,并据此进行投资决策和风险管理。
minitab应用实例

Minitab应用实例引言Minitab是一款流行的统计分析软件,可用于数据分析、质量管理和过程改进。
它提供了广泛的功能和工具,使用户能够轻松地进行数据探索、统计分析和报告生成。
本文将通过介绍几个实际应用实例,展示Minitab的一些主要功能和应用场景。
这些实例将涵盖数据探索、假设检验、回归分析和质量控制等方面。
数据探索数据探索是数据分析的第一步,它可以帮助我们了解数据的特征和结构。
Minitab提供了多种方式来进行数据探索,包括数据摘要、描述性统计、数据可视化等。
例如,我们有一组销售数据,想要了解销售额的分布和趋势。
我们可以使用Minitab的柱状图和直方图功能,绘制销售额的分布图。
这样可以直观地看到销售额在哪个区间的数据更多,是否存在异常值等。
另外,Minitab还提供了箱线图、散点图等图表类型,可以帮助我们分析数据间的相关性和趋势。
假设检验假设检验是统计学中常用的技术,用于验证关于总体参数的假设。
Minitab提供了多种假设检验的功能,可以帮助我们进行参数估计和假设检验。
举个例子,我们有一份某公司员工的薪资数据,我们想要检验该公司的平均薪资是否高于行业平均水平。
我们可以使用Minitab的t检验功能来进行假设检验,得出结论是否拒绝原假设。
除了t检验,Minitab还支持多种其他假设检验方法,如方差分析、卡方检验等。
回归分析回归分析是用于建立因果关系模型的一种统计技术。
Minitab提供了强大的回归分析功能,可以帮助我们建立和评估回归模型。
例如,我们有一份汽车销售数据,想要预测汽车销售量与价格、广告费用和促销活动等变量之间的关系。
我们可以使用Minitab的多元线性回归功能来建立回归模型,并通过分析回归系数和显著性水平来评估模型的拟合优度。
此外,Minitab还提供了其他回归分析方法,如逐步回归、逻辑回归等。
质量控制质量控制是制造业中重要的环节,用于监控和改善产品的质量。
Minitab提供了一系列用于质量控制的统计工具和方法。
用Minitab进行公差分析实例

产生的8组随机数据表如图源自根据尺寸链设置表达式和存储单元
输入step的规格
结果如图
Example one 尺寸链如下:
尺寸链尺寸及公差
TOLERANCE ANALYSIS DATA SHEET
Name of Stack-Up: ODD bezel to D part - Step(x) Dimension Identification 1 ODD Bezel: Cav. Side to rib on code side 2 ODD: Tray盤至Device鐵殼 3 Length of ODD Device 4 ODD conn: Mapping position to align pin 5 ODD conn: Align pin size 6 Assy Gap 7 Lower Case: Align hole size 8 Lower Case: Align hole to edge 9 Nominal Positive Negative Tolerance Note (mm) (mm) + 17.290 0.900 17.290 0.900 0.100 0.200 0.200 0.100 2.500 0.050 2.600 149.250 0.050 0.100 0.050 0.100
126.100 126.100 4.750 2.500 0.050 2.600 149.250 4.750
用Minitab进行公差 1. 定义表头
①输入随机数据个数 2. 产生正态随机数据
②左击,删除以前存储列 再选择左面的存储列 ③输入尺寸值 ④输入公差/3
尺寸1 产生的随机数据如图, 依次类推产生8个随机数据
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
查出力 1-β = 0.8
差值:u0-ua =25-30=-5
功效值(查出力): 1-β =0.8 标准差:sigma=10
A—假设测定-决定标本大小:
(2):1-sample T(未知u)
<统计-功效和样本数量- 1-sample t: >
背景:Ha~N(30,100/25) H0~ N(25,100/n )-为测定分布差异的标本大小
M--测量系统分析: 连续型案例: gageaiag.Mtw 背景:3名测定者对10部品反复2次TEST
所有点落在管理界限内 ->良好
大部分点落在管理界限外 ->主变动原因:部品变动
->良好
->测量值随部品的变 ->测量值随OP的变动
->对于部品10,OP有较大分歧;
M--测量系统分析: 离散型案例(名目型):gage名目.Mtw
通过形态确认: -正规分布有无; -异常点有无;
(2) Plot(散点图)-X、Y双变量
通过形态确认: -相关关系; -确认严重脱离倾向的点;
(3)Matrix Plot(行列散点图-矩阵图)-多变量 (4)Box Plot(行列散点图-矩阵图)-多变量
(5)Multi-vari Chart(多变因图)Sinter.MTW
A—假设测定:案例:2sample-t.MTW (2): 2-sample t(单样本)
① 正态性验证:
<统计-基本统计- 正态性检验 : >
背景:判断两个母集团Data的平均, 统计上是否相等(有差异)
步骤①:分别测定2组data是否正规分布; ②:测定分散的同质性; ③:t-test;
P-Value > 0.05 → 正态分布
M--工序能力分析(连续型):案例:Camshaft.MTW ① 工程能力统计:
短期 工序能力
长期 工序能力
X平均=目标值 -> Cp=Cpm
X平均≠目标值 -> Cp > Cpm
② 求解Zst(输入历史均值):
历史均值:表示强行将它拉到中心位置 ->不考虑偏移-> Zst (Bench)
③ 求解Zlt(无历史均值):
无历史均值: -> 考虑偏移-> Zlt (Bench)
* Zshift = Zlt (Bench) - Zlt (Bench) =12.13-1.82=0.31
工序能力分析:案例:Camshaft.MTW 另:capability sixpack工具
M--工序能力分析(离散型):案例:bpcapa.MTW (1):二项分布的Zst
<统计-功效和样本数量- 1 Proportion : >
背景:H0:P= 0.9
Ha:P < 0.9 测定数据P1=0.8 、 P2=0.9
有意水平 α = 0.05
查出力 1-β = 0.9
P1=0.8 功效值(查出力): 1-β =0.9 P2=0.9
母比率0.8 实际上是否0.9以下,需要样本102个
两数据不能相差较大, 否则说明检查者一致的判定 与标准有一定差异
M--正态性测定: (测定工序能力的前提) 案例: 背景:3名测定者对10部品反复2次TEST
P-value > 0.05 -> 正态分布(P越大越好) 本例:P= 0.022 ,数据不服从正态分布。 原因:1、Data分层混杂;
2、群间变动大;
缺陷率: 不良率是否 受样本大小 影响?
-平均(预想)PPM=226427 -Zlt=0.75 =>Zst=Zlt+1.5=2.25
M--工序能力分析(离散型):案例:bpcapa.MTW (2):Poisson分布的Zst
A—Graph(坐标图):案例:Pulse.MTW
(1) Histograpm(直方图)-单变量
有意水平 α = 0.05
查出力 1-β = 0.8
差值:u0-ua =25-30=-5
功效值(查出力): 1-β =0.8 标准差(推定值):sigma=10
样本数量27 >已知u的1-sample Z的样本数量 ->t 分布假定母标准偏差未制定分析;
A—假设测定-决定标本大小:
(3):1 Proportion(单样本)
目的:掌握多X因子变化对Y的影响(交互作用细节); <统计-方差分析-双因子:>
材料、交互的P < 0.05 ->有意;
A—假设测定-决定标本大小: (1):1-sample Z(已知u)
<统计-功效和样本数量- 1-sample Z: >
背景:Ha~N(30,100/25) H0~ N(25,100/n )-为测定分布差异的标本大小
背景:3名测定者对30部品反复2次TEST
检查者1需要再教育; 检查者3需要追加训练; (反复性)
个人与标准的一致性 (再现性?)
两数据不能相差较大, 否则说明检查者一致的 判定与标准有一定差异
M--测量系统分析: 离散型案例(顺序型):散文.Mtw 背景:3名测定者对30部品反复2次TEST
张四 需要再教育; 张一、张五需要追加训练; (反复性)
目的:掌握多X因子变化对Y的影响(大概);
-> 材料和时间 存在交互作用;
(5)Multi-vari Chart(多变因图)Sinter.MTW
目的:掌握多X因子变化对Y的影响(); <统计-方差分析-主效果图、交互效果图:>
倾斜越大,主效果越大
无交互效果 -> 平行; 有交互效果 -> 交叉;
(5)Multi-vari Chart(多变因图)Sinter.MTW
假设P:H0的P值(0.9)
母比率0.8 实际上是否小于0.9,需要样本217个
A—假设测定:案例:Camshaft.MTW (1): 1-sample t(单样本)
背景:对零件尺寸测定100次,数据能否说明与目标值(600)一致 (α = 0.05 )
P-Value > 0.05 → Ho(信赖区间内目标值存在) →可以说平均值为600
A—假设测定-决定标本大小:
(3):2 Proportion(单样本)
<统计-功效和样本数量- 1 Proportion : >
背景:H0:P1=P2
Ha:P1 < P2 有意水平 α = 0.05 查出力 1-β = 0.9
P的备择值:实际要测定的比例? --母比率;
功效值(查出力): 1-β =0.9