OpenMP并行实验报告
OpenMP并行实验报告

并行实验报告一、积分计算圆周率1.1 积分计算圆周率的向量优化1.1.1 串行版本的设计任务:理解积分求圆周率的方法,将其用C代码实现。
注意:理论上,dx越小,求得的圆周率越准确;在计算机中由于表示的数据是有精度围的,如果dx太小,积分次数过多,误差积累导致结果不准确。
以下为串行代码:#include<stdio.h>#include<time.h>#define N 10000000double get_pi(int dt){double pi=0.0;double delta =1.0/dt;int i;for(i=0; i<dt; i++){double x=(double)i/dt;pi+=delta/(1.0+x*x);}return pi*4;}int main(){int dx;double pai;double start,finish;dx=N;start=clock();pai=get_pi(dx);finish=clock();printf("%.8lf\n",pai);printf("%.8lfS\n",(double)(finish-start)/CLOCKS_PER_SEC); return 0;}时间运行如下:第一次:time=0.02674000S第二次:time=0.02446500S第三次:time=0.02402800S三次平均为:0.02508S1.1.2 SSE向量优化版本设计任务:此部分需要给出单精度和双精度两个优化版本。
注意:(1)测试均在划分度为10的7次方下完成。
以下是SSE双精度的代码:#include<stdio.h>#include<x86intrin.h>#include<time.h>#define N 10000000double get_pi(int dt){double pi=0.0;double delta =1.0/dt;int i;for(i=0; i<dt; i++){double x=(double)i/dt;pi+=delta/(1.0+x*x);}return pi*4;}double get_pi_sse(size_t dt){double pi=0.0;double delta =1.0/dt;__m128d xmm0,xmm1,xmm2,xmm3,xmm4;xmm0=_mm_set1_pd(1.0);xmm1=_mm_set1_pd(delta);xmm2=_mm_set_pd(delta,0.0);xmm4=_mm_setzero_pd();for(long int i=0; i<=dt-2; i+=2){xmm3= _mm_set1_pd((double)i*delta);xmm3= _mm_add_pd(xmm3,xmm2);xmm3= _mm_mul_pd(xmm3,xmm3);xmm3= _mm_add_pd(xmm0,xmm3);xmm3= _mm_div_pd(xmm1,xmm3);xmm4= _mm_add_pd(xmm4,xmm3);}double tmp[2] __attribute__((aligned(16))); _mm_store_pd(tmp,xmm4);pi+=tmp[0]+tmp[1]/*+tmp[2]+tmp[3]*/;return pi*4.0;}int main(){int dx;double pai;double start,finish;dx=N;start=clock();pai=get_pi_sse(dx);finish=clock();printf("%.8lf\n",pai);printf("%.8lfS\n",(double)((finish-start)/CLOCKS_PER_SEC)); return 0;}时间运行如下:第一次:time=0.00837500S第二次:time=0.00741100S第三次:time=0.00772000S三次平均为:0.00783S以下是SSE单精度的代码:#include<stdio.h>#include<x86intrin.h>#include<time.h>#define N 10000000float get_pi_sse(size_t dt){float pi=0.0;float delta =1.0/dt;__m128 xmm0,xmm1,xmm2,xmm3,xmm4;xmm0=_mm_set1_ps(1.0);xmm1=_mm_set1_ps(delta);xmm2=_mm_set_ps(delta*3,delta*2,delta,0.0);xmm4=_mm_setzero_ps();for(long int i=0; i<=dt-4; i+=4){xmm3= _mm_set1_ps((float)i*delta);xmm3= _mm_add_ps(xmm3,xmm2);xmm3= _mm_mul_ps(xmm3,xmm3);xmm3= _mm_add_ps(xmm0,xmm3);xmm3= _mm_div_ps(xmm1,xmm3);xmm4= _mm_add_ps(xmm4,xmm3);}float tmp[4] __attribute__((aligned(16)));_mm_store_ps(tmp,xmm4);pi+=tmp[0]+tmp[1]+tmp[2]+tmp[3];return pi*4.0;}int main(){int dx;float pai;double start,finish;dx=N;start=clock();pai=get_pi_sse(dx);finish=clock();printf("%.8f\n",pai);printf("%.8lfS\n",(double)((finish-start)/CLOCKS_PER_SEC)); return 0;}时间运行如下:第一次:time=0.00406100S第二次:time=0.00426400S第三次:time=0.00437600S三次平均为:0.00423S1.1.3 AVX向量优化版本设计任务:此部分需要给出单精度和双精度两个优化版本注意:(1)测试均在划分度为10的7次方下完成。
多核多线程技术OpenMP_实验报告2
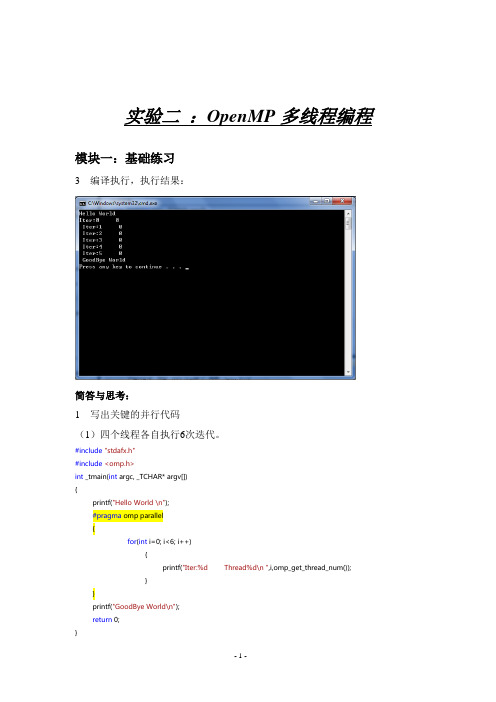
实验二:OpenMP多线程编程模块一:基础练习3 编译执行,执行结果:简答与思考:1 写出关键的并行代码(1)四个线程各自执行6次迭代。
#include"stdafx.h"#include<omp.h>int _tmain(int argc, _TCHAR* argv[]){printf("Hello World \n");#pragma omp parallel{for(int i=0; i<6; i++){printf("Iter:%d Thread%d\n ",i,omp_get_thread_num());}}printf("GoodBye World\n");return 0;}(2)四个线程协同完成6次迭代。
#include"stdafx.h"#include<omp.h>int _tmain(int argc, _TCHAR* argv[]){printf("Hello World \n");#pragma omp parallel{#pragma omp forfor(int i=0; i<6; i++){printf("Iter:%d Thread%d\n ",i,omp_get_thread_num());}}printf("GoodBye World\n");return 0;}2 附加练习:(1)编译执行下面的代码,写出两种可能的执行结果。
int i=0,j = 0;#pragma omp parallel forfor ( i= 2; i < 7; i++ )for ( j= 3; j< 5; j++ )printf(“i = %d, j = %d\n”, i, j);可能的结果:1种2种i=2,j=3 i=2,j=3i=2,j=4 i=2,j=4i=3,j=3 i=3,j=3i=3,j=4 i=3,j=4i=6,j=3 i=5,j=3i=6,j=4 i=5,j=4i=4,j=3 i=5,j=3i=4,j=4 i=5,j=4i=5,j=3 i=6,j=3i=5,j=4 i=6,j=4(2)编译执行下面的代码,写出两种可能的执行结果。
并行程序实验报告

并行程序设计实验报告姓名:学号:一、实验目的通过本次试验,了解使用OpenMP编程的基本方法和MPI的编程方法,通过实践实现的基本程序,掌握基本的线程及进程级并行应用开发技术,能够分析并行性能瓶颈及相应优化方法。
二、实验环境Linux操作系统,mpi库,多核处理器三、实验设计与实现(一)MPI并行程序设计用MPI编写一个greeting程序,编号为0的进程接受其它各进程的“问候”,并在计算机屏幕上显示问候情况。
用MPI编写一个多进程求积分的程序,并通过积分的方法求π的值,结果与π的25位精确值比较。
(二)多线程程序设计用Pthreads或OpenMP编写通过积分的方法求π的程序。
把该程序与相应的MPI程序比较。
用Pthreads或OpenMP编写编写矩阵相乘的程序,观察矩阵增大以及线程个数增减时的情形。
四、实验环境安装(一)MPI环境安装1.安装kylin操作系统的虚拟机(用VirtualBox)2.安装增强功能,使之与windows主机能够文件共享。
3.拷贝mpich-3.0.4.tar.gz到/root/myworkspace/目录下,并解压(tar xzf mpich-3.0.4.tar.gz)4.下面开始安装mkdir /root/myworkspace/mpi./configure --prefix=/root/myworkspace/mpi --disable-f77 --disable-fcmakemake install5.配置环境变量打开/root/.bashrc文件,在文件的末尾加上两行:PATH=$PATH:/root/myworkspace/mpi/binexport PATH保存退出,然后执行命令source /root/.bashrc(二)openMP实验环境安装Visual Studio中修改:项目->属性->c/c++->语言,将“OpenMP支持”改成“是”:五、实验结果及分析(一)MPI并行程序设计实验一:问候发送与接收非零号进程将问候的信息发送给0号进程,0号进程依次接收其它进程发送过来的消息并将其输出。
华科并行实验报告

一、实验模块计算机科学与技术二、实验标题并行计算实验三、实验目的1. 了解并行计算的基本概念和原理;2. 掌握并行编程的基本方法;3. 通过实验加深对并行计算的理解。
四、实验环境1. 操作系统:Windows 102. 编程语言:C++3. 并行计算平台:OpenMP五、实验步骤1. 准备实验环境首先,在计算机上安装OpenMP库,并配置环境变量。
2. 编写并行计算程序编写一个简单的并行计算程序,实现以下功能:(1)计算斐波那契数列的第n项;(2)计算素数的个数;(3)计算矩阵乘法。
以下为斐波那契数列的并行计算程序示例:```cpp#include <omp.h>#include <iostream>using namespace std;int main() {int n = 30;int fib[31] = {0};fib[0] = 0;fib[1] = 1;#pragma omp parallel forfor (int i = 2; i <= n; i++) {fib[i] = fib[i - 1] + fib[i - 2];}cout << "斐波那契数列的第" << n << "项为:" << fib[n] << endl; return 0;}```3. 编译程序使用g++编译器编译程序,并添加OpenMP库支持。
```bashg++ -fopenmp -o fib fib.cpp```4. 运行程序在命令行中运行编译后的程序,观察结果。
5. 分析结果通过对比串行计算和并行计算的结果,分析并行计算的优势。
六、实验过程1. 准备实验环境,安装OpenMP库并配置环境变量;2. 编写并行计算程序,实现斐波那契数列的并行计算;3. 编译程序,并添加OpenMP库支持;4. 运行程序,观察结果;5. 分析结果,对比串行计算和并行计算的性能。
并行程序设计实验报告-OpenMP 进阶实验

实验2:OpenMP 进阶实验1、实验目的掌握生产者-消费者模型,具备运用OpenMP相关知识进行综合分析,可实现实际工程背景下生产者-消费者模型的线程级负责均衡规划和调优。
2、实验要求1)single与master语句制导语句single 和master 都是指定相关的并行区域只由一个线程执行,区别在于使用master 则由主线程(0 号线程)执行,使用single 则由运行时的具体情况决定。
两者还有一个区别是single 在结束处隐含栅栏同步,而master 没有。
在没有特殊需求时,建议使用single 语句。
程序代码见程序2-12)barrier语句在多线程编程中必须考虑到不同的线程对同一个变量进行读写访问引起的数据竞争问题。
如果线程间没有互斥机制,则不同线程对同一变量的访问顺序是不确定的,有可能导致错误的执行结果。
OpenMP中有两种不同类型的线程同步机制,一种是互斥机制,一种是事件同步机制。
其中事件同步机制的设计思路是控制线程的执行顺序,可以通过设置barrier同步路障实现。
3)atomic、critical与锁通过critical 临界区实现的线程同步机制也可以通过原子(atomic)和锁实现。
后两者功能更具特点,并且使用更为灵活。
程序代码见程序2-2、2-3、2-44)schedule语句在使用parallel 语句进行累加计算时是通过编写代码来划分任务,再将划分后的任务分配给不同的线程去执行。
后来使用paralle for 语句实现是基于OpenMP 的自动划分,如果有n 次循环迭代k 个线程,大致会为每一个线程分配[n/k]各迭代。
由于n/k 不一定是整数,所以存在轻微的负载均衡问题。
我们可以通过子句schedule 来对影响负载的调度划分方式进行设置。
5)循环依赖性检查以对π 的数值估计的方法为例子来探讨OpenMP 中的循环依赖问题。
圆周率π(Pi)是数学中最重要和最奇妙的数字之一,对它的计算方法也是多种多样,其中适合采用计算机编程来计算并且精确度较高的方法是通过使用无穷级数来计算π 值。
OpenMP+MPI混合并行编程

H a r b i n I n s t i t u t e o f T e c h n o l o g y并行处理与体系结构实验报告实验题目: OpenMP+MPI混合并行编程院系:计算机科学与技术姓名:学号:实验日期: 2011-12-25哈尔滨工业大学实验四:OpenMP+MPI混合并行编程一、实验目的1、复习前几次实验的并行机制,即OpenMP与MPI编程模式。
2、掌握OpenMP与MPI混合并行编程模式。
二、实验内容1、使用OpenMP+MPI混合编程并与OpenMP、MPI单独编程的比较。
在OpenMp并行编程中,主要针对细粒度的循环级并行,主要是在循环中将每次循环分配给各个线程执行,主要应用在一台独立的计算机上;在MPI并行编程中,采用粗粒度级别的并行,主要针对分布式计算机进行的,他将任务分配给集群中的所有电脑,来达到并行计算;OpenMp+MPI混合编程,多台机器间采用MPI分布式内存并行且每台机器上只分配一个MPI进程,而各台机器又利用OpenMP进行多线程共享内存并行。
2、分析影响程序性能的主要因素。
在采用OpenMP实现的并行程序中,由于程序受到计算机性能的影响,不能大幅度的提高程序运行速度,采用了集群的MPI并行技术,程序被放到多台电脑上运行,多台计算机协同运行并行程序,但是,在集群中的每台计算机执行程序的过程又是一个执行串行程序的过程,因此提出的OpenMP+MPI技术,在集群内采用MPI技术,减少消息传递的次数以提高速度,在集群的每个成员上又采用OpenMP技术,节省内存的开销,这样综合了两种并行的优势,来提升并行程序的执行效率。
三、实验原理OpenMP编程:使用Fork-Join的并行执行模式。
开始时由一个主线程执行程序,该线程一直串行的执行,直到遇到第一个并行化制导语句后才开始并行执行。
含义如下:①Fork:主线程创建一队线程并行执行并行域中的代码;②Join:当各线程执行完毕后被同步或中断,最后又只有主线程在执行。
哈工大软件学院并行程序设计课程实验报告之二

《并行程序设计》课程实验报告实验2:基于Windows Thread和OpenMP的多线程编程姓名*** 院系软件学院学号**********任课教师张伟哲指导教师苏统华实验地点软件学院五楼机房实验时间2015年4月8日实验课表现出勤、表现得分实验报告得分实验总分操作结果得分一、实验目的要求:需分析本次实验的基本目的,并综述你是如何实现这些目的的?一、1.熟练掌握C++语言;。
2、掌握Visual Studio* .NET*集成开发环境的使用;3、掌握Windows32 Thread API开发多线程程序;4、掌握Windows32 Thread API中互斥机制的使用方式二、1.掌握OpenMP的基本功能、构成方式、句法;2、掌握OpenMP体系结构、特点与组成;3、掌握采用OpenMP进行多核架构下多线程编程的基本使用方法和调试方法。
二、实验内容该部分填写在实验过程中,你都完成了哪些工作。
一、1. 定位到文件夹Win32 Threads\ HelloThreads\,用Microsoft Visual studio打开文件HelloThread.sln,编译并运行程序;2. 对main.cpp中函数进行修改,要求输出线程创建顺序(例如:Hello Thread 0, Hello Thread 1, Hello Thread 2 等等);注意:利用CreateThread()循环变量作为每个线程的执行顺序唯一标识3. 编译并多次运行程序,记录线程执行顺序,分析线程程序执行顺序是否不可预见及其产生原因4. 定位到文件夹Win32 Threads\ Pi\,用Microsoft Visual studio打开文件Pi.sln,编译并运行程序;5. 对此串行代码使用Windows32 Thread API进行线程化,要求4线程实现,且每次迭代计算仅由一个线程完成6. 使用CRITICAL_SECTION机制和Semaphors机制对多线程共享变量进行互斥操作,避免数据竞争。
并行计算实验报告

分析 :这样的加速比 , 是符合预测 , 很好的 . 附 :(实验 源码 ) 1 pi.cpp #include <cstdio> #include <cstdlib> #include <cstring> #include <cctype> #include <cmath> #include <ctime> #include <cassert>
#include <climits> #include <iostream> #include <iomanip> #include <string> #include <vector> #include <set> #include <map> #include <queue> #include <deque> #include <bitset> #include <algorithm> #include <omp.h> #define MST(a, b) memset(a, b, sizeof(a)) #define REP(i, a) for (int i = 0; i < int(a); i++) #define REPP(i, a, b) for (int i = int(a); i <= int(b); i++) #define NUM_THREADS 4 using namespace std; const int N = 1e6; double sum[N]; int main() { ios :: sync_with_stdio(0); clock_t st, ed; double pi = 0, x; //串行 st = clock(); double step = 1.0 / N; REP(i, N) { x = (i + 0.5) * step; pi += 4.0 / (1.0 + x * x); } pi /= N; ed = clock(); cout << fixed << setprecision(10) << "Pi: " << pi << endl; cout << fixed << setprecision(10) << "串行用时: " << 1.0 * (ed - st) / CLOCKS_PER_SEC << endl; //并行域并行化 pi = 0; omp_set_num_threads(NUM_THREADS); st = clock(); int i; #pragma omp parallel private(i) { double x; int id; id = omp_get_thread_num();
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
并行实验报告一、积分计算圆周率1.1 积分计算圆周率的向量优化1.1.1 串行版本的设计任务:理解积分求圆周率的方法,将其用C代码实现。
注意:理论上,dx越小,求得的圆周率越准确;在计算机中由于表示的数据是有精度范围的,如果dx太小,积分次数过多,误差积累导致结果不准确。
以下为串行代码:#include<stdio.h>#include<time.h>#define N 10000000double get_pi(int dt){double pi=0.0;double delta =1.0/dt;int i;for(i=0; i<dt; i++){double x=(double)i/dt;pi+=delta/(1.0+x*x);}return pi*4;}int main(){int dx;double pai;double start,finish;dx=N;start=clock();pai=get_pi(dx);finish=clock();printf("%.8lf\n",pai);printf("%.8lfS\n",(double)(finish-start)/CLOCKS_PER_SEC); return 0;}时间运行如下:第一次:time=0.02674000S第二次:time=0.02446500S第三次:time=0.02402800S三次平均为:0.02508S1.1.2 SSE向量优化版本设计任务:此部分需要给出单精度和双精度两个优化版本。
注意:(1)测试均在划分度为10的7次方下完成。
以下是SSE双精度的代码:#include<stdio.h>#include<x86intrin.h>#include<time.h>#define N 10000000double get_pi(int dt){double pi=0.0;double delta =1.0/dt;int i;for(i=0; i<dt; i++){double x=(double)i/dt;pi+=delta/(1.0+x*x);}return pi*4;}double get_pi_sse(size_t dt){double pi=0.0;double delta =1.0/dt;__m128d xmm0,xmm1,xmm2,xmm3,xmm4;xmm0=_mm_set1_pd(1.0);xmm1=_mm_set1_pd(delta);xmm2=_mm_set_pd(delta,0.0);xmm4=_mm_setzero_pd();for(long int i=0; i<=dt-2; i+=2){xmm3= _mm_set1_pd((double)i*delta);xmm3= _mm_add_pd(xmm3,xmm2);xmm3= _mm_mul_pd(xmm3,xmm3);xmm3= _mm_add_pd(xmm0,xmm3);xmm3= _mm_div_pd(xmm1,xmm3);xmm4= _mm_add_pd(xmm4,xmm3);}double tmp[2] __attribute__((aligned(16))); _mm_store_pd(tmp,xmm4);pi+=tmp[0]+tmp[1]/*+tmp[2]+tmp[3]*/;return pi*4.0;}int main(){int dx;double pai;double start,finish;dx=N;start=clock();pai=get_pi_sse(dx);finish=clock();printf("%.8lf\n",pai);printf("%.8lfS\n",(double)((finish-start)/CLOCKS_PER_SEC)); return 0;}时间运行如下:第一次:time=0.00837500S第二次:time=0.00741100S第三次:time=0.00772000S三次平均为:0.00783S以下是SSE单精度的代码:#include<stdio.h>#include<x86intrin.h>#include<time.h>#define N 10000000float get_pi_sse(size_t dt){float pi=0.0;float delta =1.0/dt;__m128 xmm0,xmm1,xmm2,xmm3,xmm4;xmm0=_mm_set1_ps(1.0);xmm1=_mm_set1_ps(delta);xmm2=_mm_set_ps(delta*3,delta*2,delta,0.0);xmm4=_mm_setzero_ps();for(long int i=0; i<=dt-4; i+=4){xmm3= _mm_set1_ps((float)i*delta);xmm3= _mm_add_ps(xmm3,xmm2);xmm3= _mm_mul_ps(xmm3,xmm3);xmm3= _mm_add_ps(xmm0,xmm3);xmm3= _mm_div_ps(xmm1,xmm3);xmm4= _mm_add_ps(xmm4,xmm3);}float tmp[4] __attribute__((aligned(16)));_mm_store_ps(tmp,xmm4);pi+=tmp[0]+tmp[1]+tmp[2]+tmp[3];return pi*4.0;}int main(){int dx;float pai;double start,finish;dx=N;start=clock();pai=get_pi_sse(dx);finish=clock();printf("%.8f\n",pai);printf("%.8lfS\n",(double)((finish-start)/CLOCKS_PER_SEC)); return 0;}时间运行如下:第一次:time=0.00406100S第二次:time=0.00426400S第三次:time=0.00437600S三次平均为:0.00423S1.1.3 A VX向量优化版本设计任务:此部分需要给出单精度和双精度两个优化版本注意:(1)测试均在划分度为10的7次方下完成。
(2)在编译时需要加-mavx 编译选项,才能启用AVX指令集,否则默认SSE指令集(3)理论上,向量版本对比SSE版本和串行版本有明显加速,单精度版本速度明显优于双精度,速度接近双精度的两倍。
以下是AVX双精度的代码:#include<stdio.h>#include<x86intrin.h>#include<time.h>#define N 10000000/*double get_pi(int dt){double pi=0.0;double delta =1.0/dt;int i;for(i=0; i<dt; i++){double x=(double)i/dt;pi+=delta/(1.0+x*x);}return pi*4;}*/double get_pi_avx(size_t dt){double pi=0.0;double delta =1.0/dt;__m256d ymm0,ymm1,ymm2,ymm3,ymm4;ymm0=_mm256_set1_pd(1.0);ymm1=_mm256_set1_pd(delta);ymm2=_mm256_set_pd(delta*3,delta*2,delta,0.0);ymm4=_mm256_setzero_pd();for(long int i=0; i<=dt-4; i+=4){ymm3= _mm256_set1_pd((double)i*delta);ymm3= _mm256_add_pd(ymm3,ymm2);ymm3= _mm256_mul_pd(ymm3,ymm3);ymm3= _mm256_add_pd(ymm0,ymm3);ymm3= _mm256_div_pd(ymm1,ymm3);ymm4= _mm256_add_pd(ymm4,ymm3);}double tmp[4] __attribute__((aligned(32)));_mm256_store_pd(tmp,ymm4);pi+=tmp[0]+tmp[1]+tmp[2]+tmp[3];return pi*4.0;}int main(){int dx;double pai;double start,finish;dx=N;start=clock();pai=get_pi_avx(dx);finish=clock();printf("%.8lf\n",pai);printf("%.8lfS\n",(double)((finish-start)/CLOCKS_PER_SEC)); return 0;}时间运行如下:第一次:time=0.00720200S第二次:time=0.00659800S第三次:time=0.00670600S三次平均为:0.00683S以下是AVX单精度的代码:时间运行如下:第一次:time=0.00234200S第二次:time=0.00234200S第三次:time=0.00230000S三次平均为:0.002328S由以上实验统计得出结论:AVX-float=0.002328 SAVX-double=0.00683 SSSE-float=0.00423 SSSE-double= 0.00783 S基本符合规律:(以下为速度比较)AVX-float > AVX-double ≈SSE-float > SSE-double > serial1.2 积分计算圆周率的OpenMP优化1.2.1 OpenMP并行化任务:在串行代码的基础上进行OpenMP并行优化注意:测试在划分度为10的9次方下完成。
参考代码:#include<stdio.h>#include<omp.h>#define N 1000000000double get_pi(int dt){double pi=0.0;double delta =1.0/dt;int i;#pragma omp parallel for reduction(+:pi) for(i=0; i<dt; i++){double x=(double)i/dt;pi+=delta/(1.0+x*x);}return pi*4;}int main(){int dx;double pai;//double start,finish;dx=N;double start=omp_get_wtime();pai=get_pi(dx);double finish=omp_get_wtime();printf("%.8lf\n",pai);printf("%lf\n",finish-start);return 0;}运行结果如下图:串行结果如下:提速十分明显。