wordnetsimilarity介绍
基于中文WordNet的中英文词语相似度计算

基于中文WordNet的中英文词语相似度计算吴思颖;吴扬扬【摘要】介绍一种基于中文WordNet的中英文词语相似度计算方法.在WordNet同义词集的上下位关系图中,引入了距离、密度、深度3个因素来估计同义词集之间的相似度,采用一个自适应的方案来解决候选同义词集组合的权重和取舍问题.实现了一个可以计算英-英、汉-英、汉-汉词语之间相似度的算法,所得结果比较符合人们对词语的理解.【期刊名称】《郑州大学学报(理学版)》【年(卷),期】2010(042)002【总页数】4页(P66-69)【关键词】中文WordNet;词语相似度;语义相似度【作者】吴思颖;吴扬扬【作者单位】华侨大学计算机科学与技术学院,福建,厦门,361021;华侨大学计算机科学与技术学院,福建,厦门,361021【正文语种】中文【中图分类】TP391Wo rdNet是按语义关系组织的,它使用同义词集合代表概念,词汇关系在词语之间体现,语义关系在概念之间体现,一个词语属于若干个同义词集,而一个同义词集又包含若干个词语.由于语义关系是一种词义之间的关系,而词义是用同义词集合来表示,因此很自然地把语义关系看作为同义词集合之间的关系. WordNet中词汇概念的语义关系主要包括上下位、同义、反义、整体和部分、蕴含、属性、致使等不同的语义关系.中文Wo rdNet建立在普林斯顿大学开发的英文Wo rdNet词典的原理基础上,实现了一个约118 000中文词和115 400同义词集的中文-中文词典的功能,是使用了现有的英-汉词典库对英文WordNet中的词进行手工翻译而得到的.它同样也具有同义词、同等词、泛词等在英-英词典中提供的功能.词语相似度的计算方法主要分为两类[1-2]:一类方法称为基于上下文的方法,它利用大规模的语料或词语定义,收集统计数据,来评估词汇语义相似度;另一类是利用词典中的关系和层次结构,如概念之间的上下位关系和同位关系来计算词语的相似度.文献[3]利用了同义词集在WordNet中的最短距离和这条路径的转向次数来计算词语的相似度;文献[4]引入了本体和语料库,以2个同义词集的公共子结点的范围和公共的信息来计算其相似度;文献[1]从WordNet中提取同义词并采取向量空间方法计算英语词语的相似度.但由于Wo rdNet词典的语言限制,它们都局限于英文词语的语义相似度分析.文献[5]讨论了义原的相似度计算方法、集合和特征结构的相似度计算方法,并在此基础上提出了利用《知网》进行词语相似度计算的算法.本文利用中文Wo rdNet,在Wo rdNet同义词集的上下位关系图中,引入了距离、密度、深度3个因素来估计同义词集之间的相似度,用一个自适应的方案来解决候选同义词集组合的权重和取舍问题,设计并实现了一个能计算英-英、英-汉、汉-汉词语之间相似度的算法,所得结果比较符合人们对词语的理解.要计算2个词语之间的相似度,首先需要分别查出这2个词语所属的所有同义词集,并两两组合计算其相似度,最后根据这些同义词集组合的相似度计算出2个词语之间的相似度.下面分别介绍同义词集和词语的相似度计算.在WordNet中,同义词集(synset)之间的上下位关系形成了一个图结构,每个synset有0个或若干个上位和下位synset.因此,基于以下原则来计算同义词集之间的相似度[6]:1)在上下位关系图中,任意2个synset结点的距离越远,语义相似度越小.2)图中结点所处的位置密度越高,说明该局部的词义划分越细,相似度越低.3)在上下位关系图中相同距离的2个synset结点,所处的层次越深,描述的事物越具体,因此相似度越大.引入距离因子、密度因子、深度因子来衡量同义词集之间的相似度.距离因子σ计算公式为其中,lenth为2个synset之间的距离,θ为阈值参数.距离越大,σ值就越小,当距离大于阈值θ时,距离因子为0.密度越大,语义相似度越低.密度的计算可从局部结点的个数入手,具体方法为:分别从2个当前结点出发向上走3层,每一层的结点个数分别记PN1,PN2,PN3.期间2个结点若相遇,则终止,并将其上层结点数计为0,最终计算局部结点个数PN为其中,PN1是当前结点所在层次的结点个数,PN2,PN3依次为其上层结点个数.则密度因子φ为PN值越大表示密度越大,密度因子越小,且PN≥1,使得0<φ≤1.此外,深度越深,语义相似度越大.深度因子ω的计算公式为其中,dep th为该节点的深度,Ed为整棵语义树中所有结点的平均深度.即当结点的深度大于均值时,其深度因子为正,否则为负.综合考虑距离、密度、深度3个因素,则2个同义词集之间的相似度为若sim>1,则取sim=1.-φ和-ω分别为2个词的密度因子和深度因子的均值;α和β分别为密度因子和深度因子的权重.由于每个词语有一个或多个词义(sense),即它属于若干个同义词集,因此采用如下步骤计算2个词语之间的相似度:1)用联合查询语句在中文Wo rdNet词典数据库的各个翻译版本中,查找出被比较的词(英文单词或中文词语)所有可能出现的同义词集的id.2)将中文单词所属同义词集的标识synset_id转换为对应的英文同义词集的synset_id.3)令词a有m个词义(属于m个同义词集),词b有n个词义,即a,b所属的同义词集有m×n对组合.计算这m×n对同义词集的相似度,并排序.4)从大到小排序后,第1对同义词集所占的比重最大,令其权重为ρ,则第2对同义词集所占的权重为剩余比重×ρ,以此类推.设置一个阈值参数δ(0<δ<1),计算过程中仅考虑所有组合的前百分比阈值,如δ=0.3,则仅计算所有同义词集组合相似度最大的前30%.在实际操作中,当同义词集组合个数较多时,常出现1对或前几对同义词集的相似度非常大,因此首对权重ρ不宜过大,否则将失去综合权衡的意义.为了能够综合考虑被选取的同义词集组合的影响力,考虑根据选取的同义词集组合的数量来调节各组合所占的权重.因此,提出了一个根据同义词集组合个数num自适应调节参数ρ的公式,使得ρ∈[0.5,0.9],即当入选的同义词集组合个数num越小,首对同义词集的权重ρ越高(最大0.9),而ρ值随num的增加而递减(最小0.5),计算公式为其中,num=m×n.根据上述方法,实现了一个基于中文WordNet的词语相似度计算程序模块.在实验中,根据多次尝试中取得的经验,将文中提到的几个参数设置如下:距离因子中的阈值参数θ=7;深度因子中所有结点的平均深度经计算得Ed=8.624 3;密度因子权重α=0.1;深度因子权重β=0.1;同义词集组合前百分比阈值δ=0.2,即取相似度最大的前20%的组合考虑.对于词语相似度计算结果的评价,最好是放到实际的系统中(如本课题后期研究的数据空间的进化将利用此结果数据模式进行匹配),观察不同的计算方法对系统性能的影响,在条件不许可的情况下采用人工判别的方法.对比了文献[5]中介绍的同样能计算中文词语相似度的基于《知网》的词汇语义相似度计算方法,对比结果如表1所示,方法1为文献[5]中介绍的方法,方法2为本文介绍的基于中文WordNet的相似度计算方法.对比表1结果,方法2的实验结果与人们的理解比较一致,方法1得到的相似度与人们的理解相对差别大一些.例如,方法1对“论文”、“文章”、“文献”这样词义接近的词汇的相似度估计相差巨大,因为方法1中计算词语相似度时采用了2个词之间各个概念相似度的最大值.而方法2计算结果中,“论文”与“文章”、“文献”的相似度比较接近,都在0.91以上,因为方法2对词语各个概念(同义词集)的各种组合采取了一种动态加权和的办法,能自适应地调整组合之间的权重.本算法的另一个独特之处是兼容中英文双语的相似度计算,表2给出另外一些测试结果.从实验结果可以看出,“父亲”和“father”同为正式用语,相似度高于“父亲”和“爸爸”,而同为口语的“爸爸”和“dad”也有较高的相似度;“中国”和“亚洲”的相似度高于“中国”和“欧洲”也是较为合理的;“猫”直接类属于“动物”,因此“猫”和“动物”的相似度大于“猫”和“狗”的相似度.总体上看,该方法得到的大部分结果是较为准确的.本文主要分析了中文WordNet的体系结构,根据影响词语相似度的距离、密度和深度3个因素,定义了完整的同义词集之间的相似度算法,并采用了自适应的方法对被查词语的同义词集组合进行了取舍和权重定义.最后,实现了一个计算中英文词语相似度的算法,并进行了实验.测试结果表明:本方法得到的结果与人工判别结果基本一致,比基于《知网》的词汇语义相似度计算方法更符合人们的理解.下一步研究将把词语相似度算法应用于数据空间管理系统的进化和检索中,使数据空间的查询结果更为准确有效.【相关文献】[1] 荀恩东,颜伟.基于语义网计算英语词语相似度[J].情报学报,2006,25(1):43-48.[2] Sebti A,Barfrous A A.A new wo rd sense similarity measure inWordNet[C]//Proceedingsof the International M ulticonference on Computer Science and Information Technology.Washinton D C:IEEE Computer Society,2008:369-373.[3] Hirst G,St-Onge D.Lexical chains as rep resentationsof context fo r the detection and correction of malap ropisms[M]// WordNet:an Electronic Lexical Database.Cambridge M A:M IT Press,1998.[4] Resnik ing information content to evaluate semantic similarity in ataxonomy[C]//Proceedingsof the 14th International Joint Conference on A rtificial Intelligence.San Francisco:Mo rgan Kaufmann Publishers Inc,1995:448-453.[5] 刘群,李素建.基于《知网》的词汇语义相似度计算[J].计算语言学及中文信息处理,2002,7(2):59.[6] 张承立,陈剑波,齐开悦.基于语义网的语义相似度算法改进[J].计算机工程与应用,2006,42(17):165-166.。
基于知网语义相关度计算的词义消歧方法

基于知网语义相关度计算的词义消歧方法
知网语义相关度计算(WordNet Similarity)是一种基于计算语言学原理来测量两个词语之间的相似程度的语义消歧方法。
它利用已有的计算语言学技术、例如WordNet(一种基于英文的信息网络)来实现消歧结果的计算。
知网语义相关度计算在语言处理中有着广泛的应用,不仅在自然语言处理领域中有着广泛使用,而且在机器学习和搜索引擎领域也有着重要的应用。
知网语义相关度计算的基本思想是将两个词语在语义上进行比较,求出它们之间的相似度。
首先,需要通过WordNet数据库中的词语的语义表示来构建出它们的语义概念树;其次,在概念树上求取它们的共同最大子概念;最后,计算它们的最大子概念的深度,或者在语义上的相似性。
为了更好地消歧词语之间的相似性,知网语义相关度计算还采用了一些其他技术,比如词汇相似性(Word Similarity)、语义相似性(Semantic Similarity)和句子相似性(Sentence Similarity)。
简而言之,知网语义相关度计算就是利用WordNet数据库中的词语的语义表示来估计两个词语之间的相似程度的一种消歧方法。
它利用计算语言学技术,比如WordNet数据库中的词语的语义表示、语义相似性、句子相似性等等,来实现相似性的计算。
在实际应用中,它可以帮助计算机更准确地理解人类语言,从而提高机器学习和搜索引擎的性能。
Wordnet中的各种关系

关系英文名词性译名hyponymy名词下位关系hypernymy名词上位关系meronymy名词部分关系component of名词部件部分关系member of名词成员部分关系substance of名词物质部分关系holonymy名词整体关系antonymy名词反义关系attribute名词属性关系Antonymy动词反义关系Troponymy动词下位关系Hypernymy动词上位关系Entailment动词蕴含关系Cause动词致使关系Also See动词相关动词关系Antonymy形容词反义关系Similarity形容词近义关系Relational形容词关系性形容词Also See形容词相关关系Attribute形容词属性关系Antonymy副词反义关系Derived from副词衍生关系含义或示例对应于概念关系的类别表示对某个类的细化,即如果X是一种Y,那么X是Y的下位词(hyponym)is kind of表示对多个具体实例的泛化,即如果X是一种Y,那么Y是X 的上位词(hypernym)is a generalization of如果X是Y的一部分,那么X是Y的部分词(meronym)is part of例如:“鸟嘴/翅膀-鸟”(beak/wing-bird)is component of 例如:“树木”和“森林”(tree-forest)is member of例如:“铝”和“飞机”(aluminum-plane)is substance of 如果X是Y的一部分,那么Y是X的整体词(holonym)contains parts 例如:“胜利-失败”(victory-defeat)opposite of用形容词来表达其值的名词,如“重量”是一个属性,它的值对应的形容词是“轻”和“重”attribute of代表了复杂的若干种语义关系。
如disappear与appear opposite of如果V1在某个特定语义维度表示了V2,那么V1是V2的下位词。
基于知网的词汇语义相似度计算1

我们的工作主要包括: 1. 研究《知网》中知识描述语言的语法,了解其描述一个词义所用的多个义 原之间的关系,区分其在词语相似度计算中所起的作用;我们采用一种更
1 *
+
本项研究受国家重点基础研究计划(973)支持,项目编号是 G1998030507-4 和 G1998030510。 北京大学计算语言学研究所 & 中国科学院计算技术研究所 E-mail: liuqun@ Institute of Computational Linguistics, Peking University & Institute of Computing Technology, Chinese Academy of Science 中国科学院计算技术研究所 E-mail: lisujian@ Institute of Computing Technology, Chinese Academy of Sciences
基于《知网》的词汇语义相似度计算1 Word Similarity Computing Based on How-net
刘群* ﹑李素建+
Qun LIU , Sujian LI
摘要
词义相似度计算在很多领域中都有广泛的应用,例如信息检索、信息抽取、文 本分类、词义排歧、基于实例的机器翻译等等。词义相似度计算的两种基本方 法是基于世界知识(Ontology)或某种分类体系(Taxonomy)的方法和基于统 计的上下文向量空间模型方法。这两种方法各有优缺点。 《知网》是一部比较详尽的语义知识词典,受到了人们普遍的重视。不过,由 于《知网》中对于一个词的语义采用的是一种多维的知识表示形式,这给词语 相似度的计算带来了麻烦。这一点与 WordNet 和《同义词词林》不同。在 WordNet 和《同义词词林》中,所有同类的语义项(WordNet 的 synset 或《同 义词词林》的词群)构成一个树状结构,要计算语义项之间的距离,只要计算 树状结构中相应结点的距离即可。而在《知网》中词汇语义相似度的计算存在 以下问题: 1. 2. 每一个词的语义描述由多个义原组成; 词语的语义描述中各个义原并不是平等的,它们之间有着复杂的关系,通 过一种专门的知识描述的词汇语义相似度计算
—种基于WordNet语义相似度的改进算法

I
( 3 )
L 。 0/ W i d t h ) } ( 1 / 2 ) * W e i g h t ( p a r e n t ( c ) ) c 为中 间结 点
1 Wo r d Ne t 简介
Wo r d Ne t 是由P i r n c e t o n大学的心理学家 , 语言学 家和计 算机 工程师联合设计 的一种基于认 知语言学 的英语词典, 它不只把单词 以字母顺序排列 , 而且按照 单词 的意义组成一个“ 网络 ” 。 由于包含 了语义信息 , 所 以Wo r d Ne t 有别于通常意义上 的字典 。 Wo r d Ne t 描述对象包括复合词 、 短语动词 、 搭配次词 、 成语 、 单 词, 其中单词是最基本的单位。 描述对象被分为名词 、 动词 、 形容词 、 副词 , 它们各 自被组织成一个同义词的网络 , 即有层 次的树形结构 , 每个同义词集合都代表一个基本 的语义概念 , 并且这些集 合之 间也 有各种关系连接 。 在Wo r d Ne t 中以名词为例最基 础的语义 关系是 同 义关系。 S y n s e t 构成 了树形结构 中的每一个概念。 除了上面提到的同 义词关系Wo r d N e t 中还有 很多其他关系来表示不 同概念之 间的关 系, 例如上下位关系为如果 同义 词集合A的所有特征被包含在 同义 词集合B 的特征集合 中, 那么B 是A的下位概念 , A是B的上位概念 。 比如“ 水果” 和“ 苹果” , 苹果包含了水果的所有特征 , 但是水果不具备 苹果的独有特征 , 因此苹果 是水果 的子类是下位关系 , 而水果是苹 果的父类是上位关系 。
本分类等等。 本文在相关研究的基础上除 了考虑路径外考虑 了节点所在树 中的深度和宽度, 提 出一种基于wo r d Ne t 语义相似度的改进算法。
WordNet2.1 功能简介
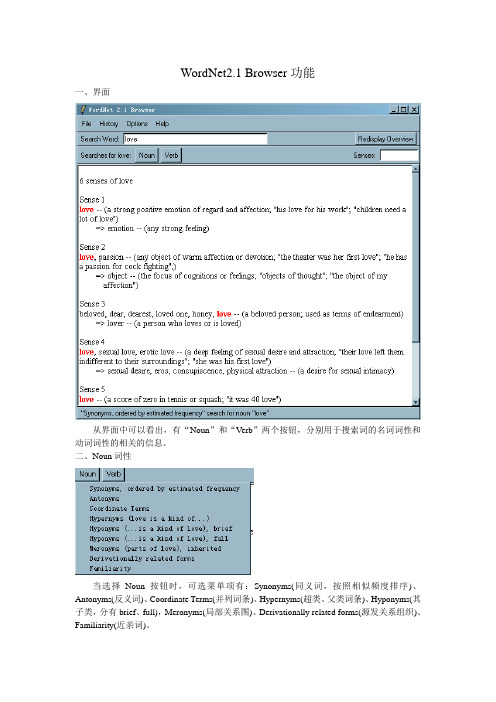
love, passion -- (any object of warm affection or devotion; "the theater was her first love"; "he has a passion for cock fighting";)
=> object -- (the focus of cognitions or feelings; "objects of thought"; "the object of my affection")
*> Somebody ----s something
*> Somebody ----s somebody
Sense 2
love, enjoy -- (get pleasure from; "I love cooking")
EX: They love him to write the letter
Sense 3
HAS PART: trait -- (a distinguishing feature of your personal nature)
HAS PART: character, fiber, fibre -- (the inherent complex of attributes that determine a persons moral and ethical actions and reactions; "education has for its object the formation of character"- Herbert Spencer)
love -- (be enamored or in love with; "She loves her husband deeply")
nltk计算词向量相似度

nltk计算词向量相似度
当使用 NLTK(自然语言处理工具包)计算词向量相似度时,可以使用其中的`word_similarity`函数来实现。
下面是一个示例代码,演示了如何使用 NLTK 计算词向量相似度:
```python
from nltk.corpus import wordnet
from nltk.metrics import word_similarity
# 定义两个词
word1 = "猫"
word2 = "狗"
# 计算词向量相似度
similarity = word_similarity(word1, word2)
# 打印相似度结果
print("相似度:", similarity)
```
在上述示例中,我们首先导入了`wordnet`和`word_similarity`模块。
然后,定义了两个要比较的词`word1`和`word2`。
接下来,使用`word_similarity`函数计算了这两个词的相似度,并将结果存储在`similarity`变量中。
最后,打印出相似度的结果。
需要注意的是,NLTK 的`word_similarity`函数基于 WordNet 词典来计算相似度,它考虑了词的语义关系和词汇层次结构。
然而,该函数仅适用于英文词汇。
如果你要处理其他语言或需要更高级的词向量相似度计算方法,可能需要使用其他的自然语言处理库或工具,如 GloVe、ELMo、BERT 等。
希望这个示例对你有帮助。
如果你有任何进一步的问题,请随时提问。
基于WordNet的英语词语相似度计算

3.1:本文的工作目标 我们相似度计算的最终目标是要服务于一个实用的英语信息检索系统。在信息检索中,
用户的 query 一般都很短,我们能获得的信息很少。虽然,在英语中我们根据用户的 query 一 般可以判断出检索词的词性。但对于多义词,我们往往无法判断出用户到底想检索含有哪个 义项的文档,比如用户输入“bank”,我们很难判断出用户是想查询关于银行方面的文档还是 查询关于河岸方面的文档。在这儿,我们引入相似度计算的方法,目的是为信息检索提供一 个以检索词为中心按照相似度从高到低排列的相似词语的集合,根据这个集合我们可以向用 户返回检索结果或进行问题扩展。我们的方法区分词语的不同词性,对多义词,我们不区分 它的不同义项,只提供一个基于 WordNet 的相似词语的集合。
2|}
1i
,
SW
2
j
)
+
i∈{1,..,|SW
2|}
| SW1 | + | SW 2 |
max
j∈{1,..,|SW
(
1|}
Similarity(SW
2i
,
SW1j )
其中: |SW1|:W1 的 sense 的个数, |SW2|:W2 的 sense 的个数。
4 实验结果及分析
我们对实验结果进行了人工的评价,评价方法主要是对计算得到的语义相似度的序列和
WordNet 现在已经发布了 2.0 版本,本文的实验是基于 1.6 版本进行的。Version 1.6 主要
包括名词、动词、形容词和副词四类实词,虚词不予考察。在上述四类实词中,WordNet 着重 描写的是名词和动词。WordNet 中词汇概念的语义关系主要包括:上下位、同义、反义、整体 和部分、蕴含、属性、致使等。WordNet Version 1.6 种描写了四类实词 99643 个概念节点和超 过 5000000 个语义关系,形成了一张庞大的概念语义网络。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
本文利用WordNet Similarity 工具包进行词义相似度的计算
以下十种相似度计算方法:
①Path方法
该方法主要依据Rada提出的基于最短路径的相似度度量方法[126],将两个词义概念在WordNet层次结构树上最短路径长度的倒数作为两者的相似度。
②Hso方法
该方法即Hirst与St-Onge所提出的基于词汇链的相似度计算方法[128],如2.4节公式
(2.5)所示。
两个词义概念之间的词汇链越长,发生的转向次数越多,则相似度越低。
③Lch方法
该方法由Leacock与Chodorow提出,其对Rada的最短路径方法作了改进,引入了两者在WordNet层次结构树上的深度,如公式(3.2)所示[172]。
其中,表示两个概念在WordNet层次结构树上最短路径的距离,D表示两者在WordNet 概念层次结构树中深度的较大值。
12 (, )dss
④Lesk方法
该方法即2.4节介绍的Lesk所提出的基于释义重叠的相似度计算方法,将两个词义概念的释义的重合词语数量作为两者的相似度[13]。
⑤Lin方法
Lin从信息论的角度来考虑词义概念的相似度,认为相似度取决于不同词义概念所包含信息的共有性(Commonality)和差别性(Difference)[136]。
该方法将相似度定义为公式(3.3):
其中c表示s1与s2在WordNet层次结构树上的最深父结点,P(s)表示任选一个词义概念属于类别s的概率。
⑥Jcn方法
该方法由Jiang和Conrath提出,将词义概念层次结构与语料统计数据结合,将基于最短路径的方法[126]和基于概念结点信息量[133]的方法融合,计算方法如2.4节公式(2.12)所示[135]。
⑦Random方法
该方法将随机生成数作为两个词义概念之间的相似度,仅作为一种基线对照方法。
⑧Resnik方法
该方法为由Resnik提出的基于概念结点信息量的相似度计算方法,根据两个概念所共有的最深父结点的信息量,衡量两者的相似度[133]。
计算方法如2.4节公式(2.9)所示。
⑨Wup方法
该方法是由Wu与Palmer提出的基于路径结构的相似度度量方法[173],综合考虑了
概念结点、共有父结点、根结点之间的路径关联情况,其计算方法如公式(3.4)所示。
将1 s 与2 s 的最深上层父概念记作s3 ,N1 表示由概念结点1 s 到达3 s 的
路径上的结点的数量;N2 表示由2 s 到达3 s 的路径上的结点的数量;N3 表示由3 s 到达
概念层次结构树的根结点的路径上的结点的数量。
⑩Vector_pairs方法
该方法是由Patwardhan与Pedersen提出的基于WordNet层次结构信息和语料库共现信息的相似度计算方法[138]。
对每个词义概念,根据语料库统计信息,得到其释义中词语的共现词语,为其构建释义向量(Gloss Vectors);根据不同词义的释义向量之间的余弦夹角衡量两者的词义相关度。
WordNet中的概念释义往往比较简短,包含的词语比较少;单纯依赖当前释义有时无法判断词义的相关度。
为了解决这一问题,该方法借助WordNet的语义结构关系,寻找与当前概念具有直接语义关系的概念的释义;利用这些关联概念的释义来作为当前概念的补充,以保证释义向量的维数足以判定相关度。
Patwardhan对多种不同词义相似度计算方法的效果进行考查,比较不同方法与人类判断(Human Judgement)的差异,发现Vector_pairs方法得到的相似度与人类判断最为接近;在SensEval-2数据集上的词义消歧实验也表明Vector_pairs方法的效果要优于其它方法[138]。
鉴于此,本章在后续实验中采用Vector_pairs方法来计算词义相似度。
在进行词义选择时,本文需要依次计算歧义词的词义与上下文消歧特征词的相似度,这需要解决词义(Sense)与词语(Word)的相似度计算问题。
参照Rada[126]和Resnik[133]的研究工作,本文利用公式(3.5)将其转换为词义与词义的相似度计算问题;取最相关的词义组合的相似度作为计算结果。
,s 表示某一词义,w表示某一词语,senses(w)表示词语w的词义集合。