彩色图像分割算法:Color Image Segmentation Based on Mean Shift and Normalized Cuts
外文翻译---特征空间稳健性分析:彩色图像分割

附录2:外文翻译Robust Analysis of Feature Spaces: Color ImageSegmentationAbstractA general technique for the recovery of significant image features is presented. The technique is based on the mean shift algorithm, a simple nonparametric procedure for estimating density gradients. Drawbacks of the current methods (including robust clustering) are avoided. Feature space of any nature can be processed, and as an example, color image segmentation is discussed. The segmentation is completely autonomous, only its class is chosen by the user. Thus, the same program can produce a high quality edge image, or provide, by extracting all the significant colors, a preprocessor for content-based query systems. A 512 512 color image is analyzed in less than 10 seconds on a standard workstation. Gray level images are handled as color images having only the lightness coordinate.Keywords: robust pattern analysis, low-level vision, content-based indexing1 IntroductionFeature space analysis is a widely used tool for solving low-level image understanding tasks. Given an image, feature vectors are extracted from local neighborhoods and mapped into the space spanned by their components. Significant features in the image then correspond to high density regions in this space. Feature space analysis is the procedure of recovering the centers of the high density regions, i.e., the representations of the significant image features. Histogram based techniques, Hough transform are examples of the approach.When the number of distinct feature vectors is large, the size of the feature space is reduced by grouping nearby vectors into a single cell. A discretized feature space is called an accumulator. Whenever the size of the accumulator cell is not adequate for the data, serious artifacts can appear. The problem was extensively studied in the context of the Hough transform, e.g.. Thus, for satisfactory results a feature space should have continuous coordinate system. The content of a continuous feature space can be modeled as a sample from a multivariate, multimodal probability distribution. Note that for real images the number of modes can be very large, of the order of tens.The highest density regions correspond to clusters centered on the modes of the underlying probability distribution. Traditional clustering techniques, can be used for feature space analysis but they are reliable only if the number of clusters is small and known a priori. Estimating the number of clusters from the data is computationally expensive and not guaranteed to produce satisfactory result.A much too often used assumption is that the individual clusters obey multivariate normal distributions, i.e., the feature space can be modeled as a mixture of Gaussians. The parameters of the mixture are then estimated by minimizing an error criterion. For example, a large class of thresholding algorithms are based on the Gaussian mixture model of the histogram, e.g.. However, there is no theoretical evidence that an extracted normal cluster necessarily corresponds to a significant image feature. On the contrary, a strong artifact cluster may appear when several features are mapped into partially overlapping regions.Nonparametric density estimation avoids the use of the normality assumption. The two families of methods, Parzen window, and k-nearest neighbors, both require additional input information (type of the kernel, number of neighbors). Thisinformation must be provided by the user, and for multimodal distributions it is difficult to guess the optimal setting.Nevertheless, a reliable general technique for feature space analysis can be developed using a simple nonparametric density estimation algorithm. In this paper we propose such a technique whose robust behavior is superior to methods employing robust estimators from statistics.2 Requirements for RobustnessEstimation of a cluster center is called in statistics the multivariate location problem. To be robust, an estimator must tolerate a percentage of outliers, i.e., data points not obeying the underlying distribution of the cluster. Numerous robust techniques were proposed, and in computer vision the most widely used is the minimum volume ellipsoid (MVE) estimator proposed by Rousseeuw.The MVE estimator is affine equivariant (an affine transformation of the input is passed on to the estimate) and has high breakdown point (tolerates up to half the data being outliers). The estimator finds the center of the highest density region by searching for the minimal volume ellipsoid containing at least h data points. The multivariate location estimate is the center of this ellipsoid. To avoid combinatorial explosion a probabilistic search is employed. Let the dimension of the data be p. A small number of (p+1) tuple of points are randomly chosen. For each (p+1) tuple the mean vector and covariance matrix are computed, defining an ellipsoid. The ellipsoid is inated to include h points, and the one having the minimum volume provides the MVE estimate.Based on MVE, a robust clustering technique with applications in computer vision was proposed in. The data is analyzed under several \resolutions" by applying the MVE estimator repeatedly with h values representing fixed percentages of the data points. The best cluster then corresponds to the h value yielding the highest density inside the minimum volume ellipsoid. The cluster is removed from the feature space, and the whole procedure is repeated till the space is not empty. The robustness of MVE should ensure that each cluster is associated with only one mode of the underlying distribution. The number of significant clusters is not needed a priori.The robust clustering method was successfully employed for the analysis of a large variety of feature spaces, but was found to become less reliable once the number of modes exceeded ten. This is mainly due to the normality assumption embeddedinto the method. The ellipsoid defining a cluster can be also viewed as the high confidence region of a multivariate normal distribution. Arbitrary feature spaces are not mixtures of Gaussians and constraining the shape of the removed clusters to be elliptical can introduce serious artifacts. The effect of these artifacts propagates as more and more clusters are removed. Furthermore, the estimated covariance matrices are not reliable since are based on only p + 1 points. Subsequent post processing based on all the points declared inliers cannot fully compensate for an initial error.To be able to correctly recover a large number of significant features, the problem of feature space analysis must be solved in context. In image understanding tasks the data to be analyzed originates in the image domain. That is, the feature vectors satisfy additional, spatial constraints. While these constraints are indeed used in the current techniques, their role is mostly limited to compensating for feature allocation errors made during the independent analysis of the feature space. To be robust the feature space analysis must fully exploit the image domain information.As a consequence of the increased role of image domain information the burden on the feature space analysis can be reduced. First all the significant features are extracted, and only after then are the clusters containing the instances of these features recovered. The latter procedure uses image domain information and avoids the normality assumption.Significant features correspond to high density regions and to locate these regions a search window must be employed. The number of parameters defining the shape and size of the window should be minimal, and therefore whenever it is possible the feature space should be isotropic. A space is isotropic if the distance between two points is independent on the location of the point pair. The most widely used isotropic space is the Euclidean space, where a sphere, having only one parameter (its radius) can be employed as search window. The isotropy requirement determines the mapping from the image domain to the feature space. If the isotropy condition cannot be satisfied, a Mahalanobis metric should be defined from the statement of the task.We conclude that robust feature space analysis requires a reliable procedure for the detection of high density regions. Such a procedure is presented in the next section.3 Mean Shift AlgorithmA simple, nonparametric technique for estimation of the density gradient was proposed in 1975 by Fukunaga and Hostetler. The idea was recently generalized by Cheng.Assume, for the moment, that the probability density function p(x) of the p-dimensional feature vectors x is unimodal. This condition is for sake of clarity only, later will be removed. A sphere X S of radius r, centered on x contains the featurevectors y such that r x y ≤-. The expected value of the vector x y z -=, given x and X S is[]()()()()()dy S y p y p x y dy S y p x y S z E X X S X S X X ⎰⎰∈-=-==μ(1) If X S is sufficiently small we can approximate()()X S X V x p S y p =∈,where p S r c V X ⋅=(2)is the volume of the sphere. The first order approximation of p(y) is()()()()x p x y x p y p T∇-+=(3) where ()x p ∇ is the gradient of the probability density function in x. Then()()()()⎰∇--=X X S S Tdy x p x p V x y x y μ(4) since the first term vanishes. The value of the integral is()()x p x p p r ∇+=22μ(5) or[]()()x p x p p r x S x x E X ∇+=-∈22(6) Thus, the mean shift vector, the vector of difference between the local mean and the center of the window, is proportional to the gradient of the probability density at x. The proportionality factor is reciprocal to p(x). This is beneficial when the highest density region of the probability density function is sought. Such region corresponds to large p(x) and small ()x p ∇, i.e., to small mean shifts. On the other hand, low density regions correspond to large mean shifts (amplified also by small p(x) values).The shifts are always in the direction of the probability density maximum, the mode. At the mode the mean shift is close to zero. This property can be exploited in a simple, adaptive steepest ascent algorithm.Mean Shift Algorithm1. Choose the radius r of the search window.2. Choose the initial location of the window.3. Compute the mean shift vector and translate the search window by that amount.4. Repeat till convergence.To illustrate the ability of the mean shift algorithm, 200 data points were generated from two normal distributions, both having unit variance. The first hundred points belonged to a zero-mean distribution, the second hundred to a distribution having mean 3.5. The data is shown as a histogram in Figure 1. It should be emphasized that the feature space is processed as an ordered one-dimensional sequence of points, i.e., it is continuous. The mean shift algorithm starts from the location of the mode detected by the one-dimensional MVE mode detector, i.e., the center of the shortest rectangular window containing half the data points. Since the data is bimodal with nearby modes, the mode estimator fails and returns a location in the trough. The starting point is marked by the cross at the top of Figure 1.Figure 1: An example of the mean shift algorithm.In this synthetic data example no a priori information is available about the analysis window. Its size was taken equal to that returned by the MVE estimator, 3.2828. Other, more adaptive strategies for setting the search window size can also be defined.Table 1: Evolution of Mean Shift AlgorithmIn Table 1 the initial values and the final location,shown with a star at the top of Figure 1, are given.The mean shift algorithm is the tool needed for feature space analysis. The unimodality condition can be relaxed by randomly choosing the initial location of the search window. The algorithm then converges to the closest high density region. The outline of a general procedure is given below.Feature Space Analysis1. Map the image domain into the feature space.2. Define an adequate number of search windows at random locations in the space.3. Find the high density region centers by applying the mean shift algorithm to each window.4. Validate the extracted centers with image domain constraints to provide the feature palette.5. Allocate, using image domain information, all the feature vectors to the feature palette.The procedure is very general and applicable to any feature space. In the next section we describe a color image segmentation technique developed based on this outline.4 Color Image SegmentationImage segmentation, partioning the image into homogeneous regions, is a challenging task. The richness of visual information makes bottom-up, solely image driven approaches always prone to errors. To be reliable, the current systems must be large and incorporate numerous ad-hoc procedures, e.g.. The paradigms of gray level image segmentation (pixel-based, area-based, edge-based) are also used for color images. In addition, the physics-based methods take into account information about the image formation processes as well. See, for example, the reviews. The proposed segmentation technique does not consider the physical processes, it uses only the given image, i.e., a set of RGB vectors. Nevertheless, can be easily extended to incorporate supplementary information about the input. As homogeneity criterioncolor similarity is used.Since perfect segmentation cannot be achieved without a top-down, knowledge driven component, a bottom-up segmentation technique should·only provide the input into the next stage where the task is accomplished using a priori knowledge about its goal; and·eliminate, as much as possible, the dependence on user set parameter values.Segmentation resolution is the most general parameter characterizing a segmentation technique. Whilethis parameter has a continuous scale, three important classes can be distinguished.Undersegmentation corresponds to the lowest resolution. Homogeneity is defined with a large tolerance margin and only the most significant colors are retained for the feature palette. The region boundaries in a correctly undersegmented image are the dominant edges in the image.Oversegmentation corresponds to intermediate resolution. The feature palette is rich enough that the image is broken into many small regions from which any sought information can be assembled under knowledge control. Oversegmentation is the recommended class when the goal of the task is object recognition.Quantization corresponds to the highest resolution.The feature palette contains all the important colors in the image. This segmentation class became important with the spread of image databases, e.g.. The full palette, possibly together with the underlying spatial structure, is essential for content-based queries.The proposed color segmentation technique operates in any of the these three classes. The user only chooses the desired class, the specific operating conditions are derived automatically by the program.Images are usually stored and displayed in the RGB space. However, to ensure the isotropy of the feature space, a uniform color space with the perceived color differences measured by Euclidean distances should be used. We have chosen the *v**L space, whose coordinates are related to the RGB values by nonlinear uD was used as reference illuminant. The transformations. The daylight standard65chromatic information is carried by *u and *v, while the lightness coordinate *L can be regarded as the relative brightness. Psychophysical experiments show that *v**L space may not be perfectly isotropic, however, it was found satisfactory for uimage understanding applications. The image capture/display operations alsointroduce deviations which are most often neglected.The steps of color image segmentation are presented below. The acronyms ID and FS stand for image domain and feature space respectively. All feature space computations are performed in the ***v u L space.1. [FS] Definition of the segmentation parameters.The user only indicates the desired class of segmentation. The class definition is translated into three parameters·the radius of the search window, r;·the smallest number of elements required for a significant color, min N ;·the smallest number of contiguous pixels required for a significant image region, con N .The size of the search window determines the resolution of the segmentation, smaller values corresponding to higher resolutions. The subjective (perceptual) definition of a homogeneous region seem s to depend on the “visual activity” in the image. Within the same segmentation class an image containing large homogeneous regions should be analyzed at higher resolution than an image with many textured areas. The simplest measure of the “visual activity” can be derived from the global covariance matrix. The square root of its trace,σ, is related to the power of the signal(image). The radius r is taken proportional to σ. The rules defining the three segmentation class parameters are given in Table 2. These rules were used in the segmentation of a large variety images, ranging from simple blood cells to complex indoor and outdoor scenes.When the goal of the task is well defined and/or all the images are of the same type, the parameters can be fine tuned.Table 2: Segmentation Class Parameters2. [ID+FS] Definition of the search window.The initial location of the search window in the feature space is randomly chosen. To ensure that the search starts close to a high density region several locationcandidates are examined. The random sampling is performed in the image domain and a few, M = 25, pixels are chosen. For each pixel, the mean of its 3 3 neighborhood is computed and mapped into the feature space. If the neighborhood belongs to a larger homogeneous region, with high probability the location of the search window will be as wanted. To further increase this probability, the window containing the highest density of feature vectors is selected from the M candidates.3. [FS] Mean shift algorithm.To locate the closest mode the mean shift algorithm is applied to the selected search window. Convergence is declared when the magnitude of the shift becomes less than 0.1.4. [ID+FS] Removal of the detected feature.The pixels yielding feature vectors inside the search window at its final location are discarded from both domains. Additionally, their 8-connected neighbors in the image domain are also removed independent of the feature vector value. These nei ghbors can have “strange” colors due to the image formation process and their removal cleans the background of the feature space. Since all pixels are reallocated in Step 7, possible errors will be corrected.5. [ID+FS] Iterations.Repeat Steps 2 to 4, till the number of feature vectors in the selected searchN.window no longer exceedsmin6. [ID] Determining the initial feature palette.N vectors.In the feature space a significant color must be based on minimumminN pixels Similarly, to declare a color significant in the image domain more thanminof that color should belong to a connected component. From the extracted colors only those are retained for the initial feature palette which yield at least one connectedN. The neighbors removed at Step 4 component in the image of size larger thanminare also considered when defining the connected components Note that the threshold N which is used only at the post processing stage.is notcon7. [ID+FS] Determining the final feature palette.The initial feature palette provides the colors allowed when segmenting the image. If the palette is not rich enough the segmentation resolution was not chosen correctly and should be increased to the next class. All the pixel are reallocated basedon this palette. First, the pixels yielding feature vectors inside the search windows at their final location are considered. These pixels are allocated to the color of the window center without taking into account image domain information. The windowsare then inflated to double volume (their radius is multiplied with p32). The newly incorporated pixels are retained only if they have at least one neighbor which was already allocated to that color. The mean of the feature vectors mapped into the same color is the value retained for the final palette. At the end of the allocation procedure a small number of pixels can remain unclassified. These pixels are allocated to the closest color in the final feature palette.8. [ID+FS] Postprocessing.This step depends on the goal of the task. The simplest procedure is the removal from the image of all small connected components of size less thanN.Thesecon pixels are allocated to the majority color in their 3⨯3 neighborhood, or in the case of a tie to the closest color in the feature space.In Figure 2 the house image containing 9603 different colors is shown. The segmentation results for the three classes and the region boundaries are given in Figure 5a-f. Note that undersegmentation yields a good edge map, while in the quantization class the original image is closely reproduced with only 37 colors. A second example using the oversegmentation class is shown in Figure 3. Note the details on the fuselage.5 DiscussionThe simplicity of the basic computational module, the mean shift algorithm, enables the feature space analysis to be accomplished very fast. From a 512⨯512 pixels image a palette of 10-20 features can be extracted in less than 10 seconds on a Ultra SPARC 1 workstation. To achieve such a speed the implementation was optimized and whenever possible, the feature space (containing fewer distinct elements than the image domain) was used for array scanning; lookup tables were employed instead of frequently repeated computations; direct addressing instead of nested pointers; fixed point arithmetic instead of floating point calculations; partial computation of the Euclidean distances, etc.The analysis of the feature space is completely autonomous, due to the extensive use of image domain information. All the examples in this paper, and dozens more notshown here, were processed using the parameter values given in Table 2. Recently Zhu and Yuille described a segmentation technique incorporating complex global optimization methods(snakes, minimum description length) with sensitive parameters and thresholds. To segment a color image over a hundred iterations were needed. When the images used in were processed with the technique described in this paper, the same quality results were obtained unsupervised and in less than a second. The new technique can be used un modified for segmenting gray level images, which are handled as color images with only the *L coordinates. In Figure 6 an example is shown.The result of segmentation can be further refined by local processing in the image domain. For example, robust analysis of the pixels in a large connected component yields the inlier/outlier dichotomy which then can be used to recover discarded fine details.In conclusion, we have presented a general technique for feature space analysis with applications in many low-level vision tasks like thresholding, edge detection, segmentation. The nature of the feature space is not restricted, currently we are working on applying the technique to range image segmentation, Hough transform and optical flow decomposition.255⨯pixels, 9603 colors.Figure 2: The house image, 192(a)(b)Figure 3: Color image segmentation example.512⨯pixels, 77041 colors. (b)Oversegmentation: 21/21(a)Original image, 512colors.(a)(b)Figure 4: Performance comparison.116⨯pixels, 200 colors. (b) Undersegmentation: 5/4 colors.(a) Original image, 261Region boundaries.(a)(b)(c)(d)(e)(f)Figure 5: The three segmentation classes for the house image. The right columnshows the region boundaries.(a)(b) Undersegmentation. Number of colors extracted initially and in the featurepalette: 8/8.(c)(d) Oversegmentation: 24/19 colors. (e)(f) Quantization: 49/37 colors.(a)(b)(c)256 Figure 6: Gray level image segmentation example. (a)Original image, 256pixels.(b) Undersegmenta-tion: 5 gray levels. (c) Region boundaries.特征空间稳健性分析:彩色图像分割摘要本文提出了一种恢复显著图像特征的普遍技术。
工业机器视觉基础教程-halcon篇

工业机器视觉基础教程-halcon篇工业机器视觉是指应用机器视觉技术在工业生产中,实现产品质量检测、工业自动化等一系列目标。
而HALCON则是一款功能齐全、具备丰富图像处理库的应用授权软件。
本文将介绍HALCON图像处理中的基本操作和应用。
一、HALCON图像处理的基本操作1.图像加载:使用read_image操作,该操作可以加载多种图像格式的图片文件。
如:read_image(Image, “test.jpg”)。
2.图像显示:使用disp_image操作可以对加载图像进行可视化处理并显示在界面上。
如:disp_image(Image)。
3.图像缩放:resize_image操作可以对图像进行缩放处理,缩放后的图像尺寸可以根据需求调整。
如:resize_image(Image,Image2,800,600,”bilinear”)。
4.图像灰度化:使用rgb1_to_gray操作可以将彩色图像转化为灰度图像。
如:rgb1_to_gray(Image,Image2)。
5.边缘检测:使用edge_image操作可以对图像进行边缘检测,检测出目标区域的轮廓和边缘。
如:edge_image(Image,Image2,”canny”)。
6.形态学操作:morph_operator操作可以对图像进行形态学操作,如膨胀、腐蚀、开、闭等。
如:morph_operator(Image,Image2,”dilation”,5)。
7.颜色分割:color_segmentation操作可以根据像素的颜色信息进行分割处理,一般是针对彩色图像。
如:color_segmentation (Image,Image2,“HSV”,[1, 0,0],[255, 255, 255])。
二、HALCON图像处理的应用1.工业质检:HALCON图像处理可以应用于工业质检领域,在生产线上进行产品质量检测,包括外观、尺寸、缺陷等。
2.智能制造:HALCON图像处理可以实现机器视觉智能制造,根据生产工艺流程和生产数据进行智能制造调节和优化。
研究内容英文翻译

研究内容英文翻译研究内容research content;study content;Content双语例句全部research contents contents research content study content Content1.总之,GIS应用服务器负载平衡是分布式GIS的重要研究内容。
In conclusion, the load balancing of GIS application server is important research contents of distributed GIS.2.具体研究内容如下:1.基于RGB综合显著性的彩色图像分割方法研究。
The concrete research contents are as follows. 1. Color image segmentation based on RGB comprehensive information saliency.3.所以本课题的主要研究内容就是构建Office安全功能并验证设计与实现的一致性并消除实现与设计原形的歧义。
So the main idea of the subject is how to construct Office security functions and verify the design.4.本文的研究内容是设计开发一个基于USB摄像头的嵌入式图像采集系统。
The process of designing a image-capturing system with a USB webcamera based on embedded system is described.5.本文的研究内容就是设计SO2和H2S气体浓度测量装置。
This study is to design SO2 and H2S gas concentration measurement devices.。
基于RGB颜色空间的彩色图像分割
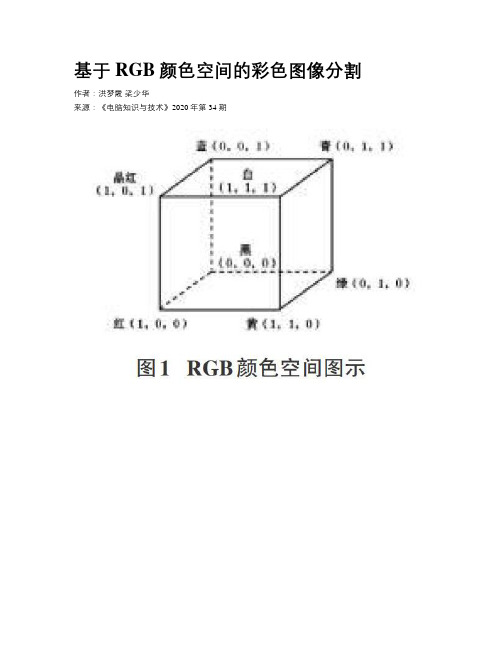
基于RGB颜色空间的彩色图像分割作者:洪梦霞梁少华来源:《电脑知识与技术》2020年第34期摘要:颜色分割可用于检测身体肿瘤、从森林或海洋背景中提取野生动物的图像,或者从单一的背景图像中提取其他彩色物体,大数据时代背景下,颜色空间对于图像分析仍然非常有用,通过在RGB和HSV颜色空间可视化图像,可以看到图像颜色分布的散点图。
通过阈值分割,确定要提取的所有像素的阈值,在所有像素中获取期望的像素,得到分割后的图像。
实验结果分析,使用OpenCV基于Python中的颜色从图像中分割对象,可以达到简单、快速、可靠的目的。
关键词:颜色空间;颜色分割;阈值分割中图分类号:TP3 文献标识码:A文章编号:1009-3044(2020)34-0225-03Abstract: Color segmentation can be used to detect body tumors, extract wildlife images from forest or marine background, or extract other color objects from a single background image. In the background of big data era, color space is still very useful for image analysis. By visualizing images in RGB and HSV color spaces, we can see the scatter map of image color distribution. Through threshold segmentation, the threshold of all the pixels to be extracted is determined, and the desired pixels are obtained from all pixels to obtain the segmented image. Experimental results show that using OpenCV to segment objects from images based on Python color can achieve the purpose of simple, fast and reliable.Key words: color space; color segmentation; threshold segmentation圖像分割是把图像分成若干个特定的、具有独特性质的区域并分割出感兴趣区域的过程。
结合蚁群和自动区域生长的彩色图像分割算法

结合蚁群和自动区域生长的彩色图像分割算法李浩;何建农【摘要】In order to overcome some shortcomings of traditional region growing algorithm , such as bad initial seed pixels and poor robustness of growing order, this paper puts forward a method of color image segmentation based on ant colony optimization region growing. First of all, according to the given threshold, we can select automatically the seed pixels by using ant colony algorithm, then select growth and adjacent termination criterion on the basis of the distance di and similarity value d (Hi,Hj), finally optimize segmentation result by using mathematical morphologymethod. We can find that this algorithm has obvious advantages in the segmentation accuracy compared with JSEG and SRG algorithm.%为克服传统区域生长算法对初始种子像素选择以及生长顺序鲁棒性较差等缺点,提出了一种基于蚁群算法优化区域生长的彩色图像分割方法。
首先,根据给定阈值,利用蚁群算法自动选取种子像素,然后,根据相邻距离 di 和相似度值 d(Hi,Hj)的值选取生长及终止准则,最后利用数学形态学方法对分割结果进行优化。
基于区域生长的彩色图像分割算法

基于区域生长的彩色图像分割算法抽象—图像分割不仅是图像处理领域的一个经典的研究主题,也是图像处理技术的热点和焦点。
随着计算机处理技术的发展和彩色应用范围的增加,彩色图像分割算法引起研究人员越来越多的关注。
彩色图像分割算法可以被看作是在灰度分割算法上的一个扩展。
但是彩色图像具有丰富的信息功能或研究一个特别适用彩色图像分割的新的图像分割方法来改善原始灰度图像。
本文提出了在传统的种子区域生长的基础上形成与流域相结合的算法的一种彩色图像自动分割区域的方法。
关键词:彩色图像分割分水岭算法种子区域生长算法1INTRODUCTION人们只关心在图像的研究和应用中的某些部分,这些部分经常被称为目标或前景,它们通常对应于图像的特定性质或特定领域。
这就需要提取并将它们分辨识别和分析对象。
在此基础上可能进一步对目标作用。
图像分割是一种技术和工艺,它可以将其分为不同的区域形象特征,并提取有利的目标。
这些特色可以是像素,灰度,颜色,质地等。
预先定义的目标可以对应一个区域或多个区域。
为了说明图像处理分割的水平,我们已经介绍了“形象工程”概念,它是涉及图像分割的理论,方法,算法,工具,设备而成德一个整体框架。
图像工程师应用研究图像领域的一个新课题,它内容非常丰富,根据抽象程度和研究方法的不同,它可以被分为三个层次: 图像处理,图像分析和图像理解。
图像处理重点在于图像之间的转化和提高图像的视觉效果。
图像分析主要是监测和衡量制定目标图像,以获取其客观信息来描述图像。
图像理解的关键是进一步研究每个目标的性质及其相互间的联系,以及得到原始图像的客观情况的解释,一次来为图像指导并计划采取措施。
图像处理,图像分析和图像理解有不同的操作。
图像处理时比较低级别的操作,它主要致力于像素水平,图像分析是中极水平,它着重于测量,表达和描述目标物。
图像理解主要是高层次的运作,本质上它注重通过计算和对数据符号的推理来描述事物。
图像分割是从图像处理到图像分析的关键步骤。
融合直方图阈值和K均值的彩色图像分割方法陈坤

2013, 49 (4)
Computer Engineering and Applications 计算机工程与应用
⦾ 图形图像处理 ⦾
融合直方图阈值和 K-均值的彩色图像分割方法
陈n, MA Yan, LI Shunbao
上海师范大学 信息与机电工程学院, 上海 200234 College of Information Mechanical and Electrical Engineering, Shanghai Normal University, Shanghai 200234, China CHEN Kun, MA Yan, LI Shunbao. Color image segmentation method by using histogram threshold and K-means. Computer Engineering and Applications, 2013, 49 (4) : 170-173. Abstract:This paper presents a simple and effective segmentation method for color image. All possible uniform regions in the color image are obtained by using the histogram threshold technique. That is, the main peak values is found in order to initialize and merge the regions and obtain the uniform regions marked by the corresponding clustering centers. The adaptive K-means clustering algorithm is given to improve compactness of the formed uniform regions. The experimental results show that, compared with IAFHA (improved ant colony-Fuzzy C-means hybrid algorithm)method, the proposed method can receive the less segmentation regions, fast segmentation speed and have certain robustness. Key words: color image segmentation; histogram threshold; K-means clustering 摘 要: 提出了一种简单有效的彩色图像分割方法。应用直方图阈值技术获得彩色图像中所有可能的均匀区域, 即通过寻
基于聚类和小波变换的彩色图像分割方法

基于聚类和小波变换的彩色图像分割方法作者:李景兰刘怀强来源:《现代电子技术》2008年第14期摘要:提出一种将聚类和小波变换相结合的彩色图像分割方法。
首先将图像划分成16×16子块,然后在块中按照视觉一致性准则进行颜色聚类,对于聚类后的子块,提取其颜色特征。
利用小波变换得到每个分块的纹理特征,将颜色特征和纹理特征的组合作为对图像进行分割的依据。
该方法将聚类算法和小波算法结合,并符合人类视觉特征的分割策略。
利用提出的算法对多幅自然图像进行分割实验,实验结果证明该算法的有效性。
关键词:彩色图像分割;颜色聚类;小波变换;纹理特征Abstract:his paper presents a color image segmentation method by combination of clustering and wavelet transform algorithmhe original image is first partitioned into 16×16 sub-blocks which are not overlapped,and then the sub-blocks are segmented by color clustering algorithm based on perceptual uniformityColor features are extracted from the segmented sub-blocksexture features of each sub-blocks are extracted by using of wavelet transformhen,the features of color and texture is combined,which is gist to segmenting imagehe proposed method combines the advantages of clustering and wavelet transform algorithm approaches,which is in accord with the human segmentation strategyhe algorithm proposed is applied to segment a number of natural images and its effectiveness and efficiency is confirmed by experimKeywords:1 引言目前,彩色图像的分割应用广泛,人们为探求符合人类视觉特征的快速分割方法[1],从不同的角度出发提出一些方法。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Color Image Segmentation Based onMean Shift and Normalized CutsWenbing Tao,Hai Jin,Senior Member,IEEE,andYimin Zhang,Senior Member,IEEEAbstract—In this correspondence,we develop a novel approach that provides effective and robust segmentation of color images.By incor-porating the advantages of the mean shift(MS)segmentation and the normalized cut(Ncut)partitioning methods,the proposed method requires low computational complexity and is therefore very feasible for real-time image segmentation processing.It preprocesses an image by using the MS algorithm to form segmented regions that preserve the desirable discontinuity characteristics of the image.The segmented regions are then represented by using the graph structures,and the Ncut method is applied to perform globally optimized clustering.Because the number of the segmented regions is much smaller than that of the image pixels, the proposed method allows a low-dimensional image clustering with significant reduction of the complexity compared to conventional graph-partitioning methods that are directly applied to the image pixels.In addition,the image clustering using the segmented regions,instead of the image pixels,also reduces the sensitivity to noise and results in enhanced image segmentation performance.Furthermore,to avoid some inappro-priate partitioning when considering every region as only one graph node, we develop an improved segmentation strategy using multiple child nodes for each region.The superiority of the proposed method is examined and demonstrated through a large number of experiments using color natural scene images.Index Terms—Color image segmentation,graph partitioning,mean shift (MS),normalized cut(Ncut).I.I NTRODUCTIONImage segmentation is a process of dividing an image into different regions such that each region is nearly homogeneous,whereas the union of any two regions is not.It serves as a key in image analysis and pattern recognition and is a fundamental step toward low-level vision, which is significant for object recognition and tracking,image re-trieval,face detection,and other computer-vision-related applications [1].Color images carry much more information than gray-level ones [24].In many pattern recognition and computer vision applications,the color information can be used to enhance the image analysis process and improve segmentation results compared to gray-scale-based ap-proaches.As a result,great efforts have been made in recent years to investigate segmentation of color images due to demanding needs. Existing image segmentation algorithms can be generally classified into three major categories,i.e.,feature-space-based clustering,spa-tial segmentation,and graph-based approaches.Feature-space-based clustering approaches[12],[13]capture the global characteristics of the image through the selection and calculation of the image features, which are usually based on the color or texture.By using a specific distance measure that ignores the spatial information,the feature Manuscript received August3,2006;revised December10,2006.This work was supported by the National Natural Science Foundation of China under Grant60603024.This paper was recommended by Associate Editor I.Bloch. W.Tao and H.Jin are with the Cluster and Grid Computing Laboratory, School of Computer Science and Technology,Huazhong University of Science and Technology,Wuhan430074,China,and also with the Service Computing Technology and System Laboratory,School of Computer Science and Technol-ogy,Huazhong University of Science and Technology,Wuhan430074,China (e-mail:wenbingtao@;hjin@).Y.Zhang is with the Center for Advanced Communications,Villanova University,Villanova,PA19085USA(e-mail:yimin.zhang@). Color versions of one or more of thefigures in this paper are available online at .Digital Object Identifier10.1109/TSMCB.2007.902249samples are handled as vectors,and the objective is to group them into compact,but well-separated clusters[7].Although the data clustering approaches are efficient infinding salient image features,they have some serious drawbacks as well.The spatial structure and the detailed edge information of an image are not preserved,and pixels from disconnected regions of the image may be grouped together if their feature spaces overlap.Given the importance of edge information,as well as the need to preserve the spatial relation-ship between the pixels on the image plane,there is a recent tendency to handle images in the spatial domain[11],[28].The spatial segmen-tation method is also referred to as region-based when it is based on region entities.The watershed algorithm[19]is an extensively used technique for this purpose.However,it may undesirably produce a very large number of small but quasi-homogenous regions.Therefore,some merging algorithm should be applied to these regions[20],[28]. Graph-based approaches can be regarded as image perceptual grouping and organization methods based on the fusion of the feature and spatial information.In such approaches,visual group is based on several key factors such as similarity,proximity,and continuation[3], [5],[21],[25].The common theme underlying these approaches is the formation of a weighted graph,where each vertex corresponds to n image pixel or a region,and the weight of each edge connecting two pixels or two regions represents the likelihood that they belong to the same segment.The weights are usually related to the color and texture features,as well as the spatial characteristic of the corresponding pixels or regions.A graph is partitioned into multiple components that minimize some cost function of the vertices in the components and/or the boundaries between those components.So far,several graph cut-based methods have been developed for image segmentations[8], [14],[22],[23],[27],[30],[31].For example,Shi and Malik[23] proposed a general image segmentation approach based on normalized cut(Ncut)by solving an eigensystem,and Wang and Siskind[8] developed an image-partitioning approach by using a complicated graph reduction.Besides graph-based approaches,there are also some other types of image segmentation approaches that mix the feature and spatial information[4],[29].This correspondence concerns a Ncut method in a large scale. It has been empirically shown that the Ncut method can robustly generate balanced clusters and is superior to other spectral graph-partitioning methods,such as average cut and average association[23]. The Ncut method has been applied in video summarization,scene detection[17],and cluster-based image retrieval[18].However,image segmentation approaches based on Ncut,in general,require high computation complexity and,therefore,are not suitable for real-time processing[23].An efficient solution to this problem is to apply the graph representation strategy on the regions that are derived by some region segmentation method.For example,Makrogiannis et al.[20] developed an image segmentation method that incorporates region-based segmentation and graph-partitioning approaches.This method first produces a set of oversegmented regions from an image by using the watershed algorithm,and a graph structure is then applied to represent the relationship between these regions.Not surprisingly,the overall segmentation performance of the region-based graph-partitioning approaches is sensitive to the region segmentation results and the graph grouping strategy.The inherent oversegmentation effect of the watershed algorithm used in[20]and [28]produces a large number of small but quasi-homogenous regions, which may lead to a loss in the salient features of the overall image and,therefore,yield performance degradation in the consequent region grouping.To overcome these problems,we propose in this correspondence a novel approach that provides effective and robust image segmentation1083-4419/$25.00©2007IEEEwith low computational complexity by incorporating the mean shift (MS)and the Ncut methods.In the proposed method,wefirst perform image region segmentation by using the MS algorithm[4],and we then treat these regions as nodes in the image plane and apply a graph structure to represent them.Thefinal step is to apply the Ncut method to partition these regions.The MS algorithm is a robust feature-space analysis approach[4] which can be applied to discontinuity preserving smoothing and image segmentation problems.It can significantly reduce the number of basic image entities,and due to the good discontinuity preservingfiltering characteristic,the salient features of the overall image are retained.The latter property is particularly important in the partitioning of natural images,in which only several distinct regions are used in representing different scenes such as sky,lake,sand beach,person,and animal, whereas other information within a region is often less important and can be neglected.However,it is difficult to partition a natural image into significative regions to represent distinct scenes,depending only on the MS segmentation algorithm.The main reason is that the MS algorithm is an unsupervised clustering-based segmentation method, where the number and the shape of the data cluster are unknown a priori.Moreover,the termination of the segmentation process is based on some region-merging strategy applied to thefiltered image result,and the number of regions in the segmented image is mainly determined by the minimum number of pixels in a region,which is denoted as M(i.e.,regions containing less than M pixels will be eliminated and merged into its neighboring region).In our proposed approach,therefore,an appropriate value of M is chosen to yield a good region representation in the sense that the number of segmented regions is larger than the number of typical scenes,but is much smaller than the number of pixels in the image,and the boundary information of the typical scenes is retained by the boundaries of the regions. The Ncut method[23],on the other hand,can be considered as a classification method.In most image segmentation applications,the Ncut method is applied directly to the image pixels,which are typically of very large size and thus require huge computational complexity. For example,to use the Ncut method in[26],a gray image has to be decimated into a size of160×160pixels or smaller.In summary,it is difficult to get real-time segmentation using the Ncut method.In the proposed method,the Ncut method is applied to the segmented regions instead of the raw image pixels.As such,it eliminates the major problem of the Ncut method that requires prohibitively high complexity.By applying the Ncut method to the preprocessed regions rather than the raw image pixels,the proposed method achieves a significant reduction of the computational cost and,therefore,renders real-time image segmentation much more practically implemental. On the other hand,due to some approximation in the implementation of the Ncut method,the segmentation processing of a graph exploiting the lower dimensional region-based weight matrix also provides more precise and robust partitioning performance compared to that based on the pixel-based weight matrix.This correspondence is organized as follows.In Section II,we introduce the background of the proposed method.In Section III,the proposed algorithm is described for effective color image partition-ing.In Section IV,we demonstrate the superiority of the proposed method by comparing the performance of the proposed approach to existing methods using a variety of color natural scene images.Finally, Section V concludes this correspondence.II.MS AND G RAPH P ARTITIONINGA.Image Region Segmentation Based on MSThe computational module based on the MS procedure is an ex-tremely versatile tool for feature-space analysis.In[4],two applica-tions of the feature-space analysis technique are discussed based on the MS procedure:discontinuity preservingfiltering and the segmentation of gray-level or color images.In this section,we present a brief review of the image segmentation method based on the MS procedure [4],[9],[10].We consider radially symmetric kernels satisfying K(x)= c k,d k( x 2),where constant c k,d>0is chosen such that ∞K(x)dx=∞c k,d k( x 2)dx=1[note that k(x)is defined only for x≥0].k(x)is a monotonically decreasing function and is referred to as the profile of the kernel.Given the function g(x)=−k (x)for profile,the kernel G(x)is defined as G(x)=c g,d g( x 2).For n data points x i,i=1,...,n,in the d-dimensional space R d,the MS is defined asm h,G(x)=ni=1x i gx−x i 2ni=1gx−x i 2−x(1)where x is the center of the kernel(window),and h is a bandwidth parameter.Therefore,the MS is the difference between the weighted mean,using kernel G as the weights and x as the center of the kernel (window).The MS method is guaranteed to converge to a nearby point where the estimate has zero gradient[4].Regions of low-density values are of no interest for the feature-space analysis,and in such regions,the MS steps are large.On the other hand,near local maxima,the steps are small,and the analysis is more refined.The MS procedure,thus,is an adaptive gradient ascent method[6].The center position of kernel G can be updated iteratively byy j+1=ni=1x i gy j−x ih2ni=1gy j−x ih2,j=1,2, (2)where y1is the center of the initial position of the kernel.Based on the above analysis,the MS imagefiltering algorithm can be obtained.First,an image is represented as a2-D lattice of p-dimensional vectors(pixels),where p=1for gray-level images, p=3for color images,and p>3for multispectral images.The space of the lattice is known as the spatial domain,while the graph level and the color of spectral information are represented in the range domain.For both domains,the Euclidean metric is assumed.Let x i and z i,i=1,...,n,respectively,be the d-dimensional(d=p+2) input and thefiltered image pixels in the joint spatial-range domain. The segmentation is actually a merging process performed on a region that is produced by the MSfiltering.The use of the MS seg-mentation algorithm requires the selection of the bandwidth parameter h=(h r,h s),which,by controlling the size of the kernel,determines the resolution of the mode detection.B.Spectral Graph PartitioningAmong many graph theoretic algorithms,spectral graph-partitioning methods have been successfully applied to many areas in computer vision,including motion analysis[16],image segmentation [8],[23],[27],[31],image retrieval[18],video summarization[17], and object recognition[15].In this correspondence,we use one of these techniques,namely,the Ncut method[23],for region clustering. Next,we briefly review the Ncut method based on the studies in[14], [23],and[27].Roughly speaking,a graph-partitioning method attempts to organize nodes into groups such that the intragroup similarity is high and theFig.1.(a)Original image.(b)Result image after using the MS segmentation algorithm.(c)Labeled regions.(d)RAGs produced by the node space relation,with a region corresponding to a node.(e)Final region-partitioning result using the Ncut method on the RAG in(d).intergroup similarity is low.Given a graph G=(V,E,W),where Vis the set of nodes,and E is the set of edges connecting the nodes.A pair of nodes u andνis connected by an edge and is weightedby w(u,ν)=w(ν,u)≥0to measure the dissimilarity between them.W is an edge affinity matrix with w(u,ν)as its(u,ν)th element.Thegraph can be partitioned into two disjoint sets A and B=V−Aby removing the edges connecting the two parts.The degree ofdissimilarity between the two sets can be computed as a total weight ofthe removed edges.This closely relates to a mathematical formulationof a cut[22]cut(A,B)=u∈A,ν∈Bw(u,ν).(3)This problem offinding the minimum cut has been well studied[22],[23],[27].However,the minimum cut criterion favors groupingsmall sets of isolated nodes in the graph because the cut definedin(3)does not contain any intragroup information[23].In otherwords,the minimum cut usually yields overclustered results when itis recursively applied.This motivates several modified graph partitioncriteria,including the Ncut[23]Ncut(A,B)=cut(A,B)assoc(A,V)+cut(A,B)assoc(B,V)(4)where assoc(A,V)denotes the total connection from nodes in A to all nodes in the graph,and asso(B,V)is similarly defined.Unlike the cut criterion that has a bias in favor of cutting small sets of nodes,the Ncut criterion is unbiased.III.P ROPOSED A PPROACHA.Description of the Algorithm SchemeWe now describe our proposed algorithm.From a data-flow point of view,the outline of the proposed algorithm can be characterized as the following.First,an image is segmented into multiple separated regions using the MS algorithm.Second,the graph representation of these regions is constructed,and the dissimilarity measure between the regions is defined.Finally,a graph-partitioning algorithm based on the Ncut is employed to form thefinal segmentation map.The regions produced by the MS segmentation can be represented by a planar weighted region adjacency graph(RAG)G=(V,E,W) that incorporates the topological information of the image structure and region connectivity.The majority of region-merging algorithms define the region dissimilarity metric as the distance between two adjacent regions in an appropriate feature space.This dissimilarity metric plays a decisive role in determining the overall performance of the image segmentation process.To define the measure of dissimilarity between neighboring regions,wefirst define an appropriate feature space.Features like color,texture,statistical characteristics,and2-D shape are useful for segmentation purposes and can be extracted from an image region.We adopt the color feature in this paper because it is usually the most dominant and distinguishing visual feature and adequate for a number of segmentation tasks.The average color components are computed over a region’s pixels and are described by a three-element color vector.When an image is segmented based on the MS method into n regions R i,i=1,...,n,the mean vector ¯XR i={¯x1i,¯x2i,¯x3i}is computed for each region,where¯x1i,¯x2i, and¯x3i are the mean pixel intensities of the i th region in the three different color spaces,respectively.Proper selection of the color spaces is important to the development of a good region-merging algorithm.To obtain meaningful segmentation results,the perceived color difference should be associated with the Euclidean distance in the color space.The spaces L∗u∗v∗and L∗a∗b∗have been particularly designed to closely approximate the perceptually uniform color spaces.In both cases,L∗, which is the lightness(relative brightness)coordinate,is defined in the same way.The two spaces differ only in the chromaticity coordinates, and in practice,there is no clear advantage of using one over the other. In this paper,we employed L∗u∗v∗motivated by its linear mapping property[2].By defining the color space,we can compute the weight matrix W of all regions.The weight w(u,ν)between regions u andνis defined asw(u,ν)=e−F(u)−F(ν) 22d I,if u andνare adjacent0,otherwise(5)where F(u)={L(u),u(u),v(u)}is the color vector of region u,and · 2denotes the vector norm operator.In addition,d I is a positive scaling factor that determines the sensitivity of w(u,ν)to the color difference between nodes u andν.Under a graph representation,region grouping can be naturally formulated as a graph-partitioning problem.In the proposed method, the Ncut algorithm is used to solve such a problem.The major difference between the proposed method and the conventional Ncut algorithm is that the construction of the weight matrix is based not on the pixels of the original image but rather on the segmentation result of the MS algorithm.The advantages of using regions instead of pixels in constructing the weight matrix are twofold:1)It offers a considerable reduction of computational complexity,since the number of basic image entities is by far smaller than that of the pixels.Thus,the size of the weight matrix and,subsequently,the complexity of the graphTABLE IW EIGHT M ATRIX W OF A LL R EGION N ODESFig. 2.(a)RAGs produced by the node space relations,with a regioncorresponding to three nodes.(b)Final region-partitioning result using theNcut method on the RAG in(a).(c)Partitioning result using the Ncut methodimplemented by Cour et al.[26].form thefirst cluster,regions3–5the second cluster,regions6–12thethird cluster,and regions13and14the fourth cluster.C.Segmentation Improvement Using Multiple Child NodesAlthough the graph-partitioning process merges the regions gener-ated by the MS algorithm into four clusters,thefinal region segmen-tation result in Fig.1(e)is not perfect because the sky and the topregion of the mountain near the sky are merged into the same cluster.The grouping of the other regions is not satisfactory either.It is wellFig.3.Test results of color images with partitioning class k=3in(a)and k=6in(b).(First column)The original test images.(Second column)The region segmentation results by the MS algorithm.The white lines show the contour boundaries of these regions,and the number of regions of the result image in each row of(a)and(b)(from top to bottom)is90,28,104,106,90,38,159,97,and66,respectively.(Third column)The contour images of thefinal region-merging results using the proposed method.(Fourth column)The original images overlapped with the contour of thefinal region-partitioning results.(Fifth column)The partitioning results by directly applying the Ncut method to the image pixels[26].The image size is240×160.known that the Ncut algorithms try tofind a“balanced partition”[23] of a weighted graph,and the cut does not have a bias in favor of cutting small sets of isolated nodes in the graph.Therefore,it is not surprising that the sky cannot be segmented out because it is only considered as a node of the weighted graph.An effective solution to this problem is to consider every region generated by the MS algorithm as multiple nodes rather than a single one.The child nodes of a region have the same feature value and are all adjacent with all the child nodes of the neighboring region.That is to say,there are edges between all the child nodes of two adjacentregions.The weights between the child nodes within a region areall one,whereas the weights between the child nodes between twoadjacent regions are all the same and equal to the weight betweenthe two regions.This yields a new weight matrix W C=W⊗1C, where⊗denotes the Kronecker product operator,and1C is the C×Cmatrix with all unit entries.In this experiment,we set the number ofchild nodes in each region to C=3,and the top-left12×12entriesof W C,which correspond to regions1–4as shown in bold fonts inFig.4.Test results of color images with the variable partitioning class.The partitioning class k of each row(from top to bottom)is4,6,8,10,and12,respectively. The number of regions of the result image in the second column is(from top to bottom)49,117,92,128,and98,respectively.The size of the image is160×240 for thefirst row and240×160for other rows.TABLE IIIC OMPARED C OMPUTATIONAL C OST B ETWEEN THE P ROPOSED M ETHOD AND THE Ncut M ETHODshows the segmentation results of the Ncut method implemented byCour et al.[26]where the sky is separated into two parts.IV.E XPERIMENTAL R ESULTSWe have applied the proposed algorithm for the segmentation of aset of color images with natural scenes.In this section,we present theexperimental results,indicating the different stages of the method.Thecontrastive experiment results using the Ncut method implemented byCour et al.[26]are also presented for comparison.The sizes of allthe test images are either240×160or160×240.The parametersof the MS segmentation algorithm are set to h=(h r,h s)=(6,8) and M=50.With this parameter setting,the number of the regionsproduced by the MS algorithm is less than200regions(i.e.,the RAGhas less than200nodes)for all the test images we used.Therefore,the dimension of the weight matrix is dramatically reduced from thenumber of image pixels to the number of regions,and subsequently,thecomplexity of the graph structure employed for image representationis also reduced.To retain the advantage of the balanced partition of theNcut method,we use C=3to construct the weight matrix W C.The test examples include three image sets.The results of thefirstset of examples are shown in Fig.3(a),where the partitioning classk is three.The results of the second set of examples are shown inFig.3(b),where k=6.The results of the third set of examples areshown in Fig.4with varying values of k.In eachfigure,thefivecolumns respectively show,from left to right,the original test image,the resultant image after applying the MS segmentation algorithm,the contour image of thefinal region partitioning,the original imagesoverlapped with thefinal partitioning contour,and the partitioningresult using the Ncut method implemented by Cour et al.[26].As discussed in Section III-C,considering a region produced by theMS algorithm as several identical child nodes can prevent the pixels inthis region from being divided into several parts when the Ncut methodis applied.For example,in the second row of Fig.3(a),the imageincludes thefisher in the foreground and the lake in the background.Therefore,an effective segmentation method should distinguish thefisher from the lake background.However,when the Ncut method isdirectly applied to the image pixels,the image is partitioned into threeregions where each region includes one part of the lake.If wefirstprocess the image using the MS segmentation algorithm,then the mostpixels of the lake background are formed into a region.The proposedmethod treats this region as several nodes with the identical charac-teristic and,as such,avoids partitioning the lake into several differentparts.The experimental results of the second andfifth rows in Fig.3(b)and the third andfifth rows in Fig.4also support the same claim.For all the experimental results shown in Figs.3and4,the proposedmethod effectively partitions the natural scenes into several mean-ingful regions and provides an improved performance compared tothe Ncut method,which does not always yield meaningful regions.Fig.3(a)shows images with relatively simple scene,and thus,a smallpartitioning class of k=3is chosen.The test sets in Figs.3(b)and4include more complicated color natural scenes,and thus,a larger valueof k is used.Finally,we consider the computational cost of the proposed methodand compare it with that of the Ncut method.A PC,which is equippedwith a2.0-GHz Pentium CPU and512-MB memory,is used.The maincomputational cost of the Ncut method is to compute the eigenvectorsof the source image.In the experiments used in this paper,the Ncutmethod[26]requires30–50s to compute the eigenvectors of the grayimage of240×160pixels.The computation of the proposed methodconsists of two sections.Thefirst section is to segment the original im-age using the MS segmentation algorithm,which takes approximately2s to process an image.The second section is to partition the region nodes produced by the MS segmentation algorithm using the Ncut method,which depends on the number of the initial region nodes and the requestedfinal regions.In the experiments performed in this paper, the number of the regions is less than200,and for C=3,the number of the child nodes is less than600.The computation of partitioning the regions using the Ncut method takes less than300ms.Table III compares the computational cost between the proposed method and the Ncut method for the images depicted in Figs.3and4.The significant reduction of the computational cost by using the proposed method is evident.Moreover,we notice that the MS algorithm is more feasible for parallel operations than the Ncut method because the complicated eigendecomposition problem in the Ncut method is difficult to be par-allelized.In the proposed method,the main computational cost is the region segmentation,whereas the computational cost of partitioning the region nodes using the Ncut method is negligibly small.Thus,the proposed method is more feasible to real-time image processing,such as content-based image retrieval,particularly when parallel processing is used.V.C ONCLUSIONIn this correspondence,we have developed a new algorithm for the segmentation of color images.The proposed algorithm takes the advantages of the MS segmentation method and the Ncut grouping method,whereas their drawbacks are avoided.The use of the MS method permits the formation of segments that preserve discontinuity characteristic of an image.On the other hand,the application of the region adjacent graph and Ncut methods to the resulting segments, rather than directly to the image pixels,yields superior image segmen-tation performance.The proposed method requires significantly lower computational complexity and,therefore,is feasible to real-time image processing.A CKNOWLEDGMENTThe authors would like to thank the anonymous reviewers for their valuable comments.R EFERENCES[1]N.Pal and S.Pal,“A review on image segmentation techniques,”PatternRecognit.,vol.26,no.9,pp.1277–1294,Sep.1993.[2]G.Wyszecki and W.S.Stiles,Color Science:Concepts and Methods,Quantitative Data and Formulae,2nd ed.New York:Wiley,1982.[3]G.Kanizsa,Grammatica del Vedere.Bologna,Italy,1980.[4]aniciu and P.Meer,“Mean shift:A robust approach toward featurespace analysis,”IEEE Trans.Pattern Anal.Mach.Intell.,vol.24,no.5, pp.603–619,May2002.[5]B.Caselles,B.Coll,and J.-M.Miorel,“A Kanisza programme,”Progr.Nonlinear Differential Equations Appl.,vol.25,pp.35–55,1996.[6]R.van den Boomgaard and J.van de Weijer,“On the equivalenceof local-modefinding,robust estimation and mean-shift analysis as used in early vision tasks,”in Proc.Int Conf.Pattern Recog.,2002, pp.30927–30930.[7]R.O.Duda,P.E.Hart,and D.G.Sork,Pattern Classification.New York:Wiley-Interscience,2000.[8]S.Wang and J.M.Siskind,“Image segmentation with ratio cut,”IEEETrans.Pattern Anal.Mach.Intell.,vol.25,no.6,pp.675–690,Jun.2003.[9]Y.Cheng,“Mean shift,mode seeking,and clustering,”IEEE Trans.Pat-tern Anal.Mach.Intell.,vol.17,no.8,pp.790–799,Aug.1995.[10]aniciu,“An algorithm for data-driven bandwidth selection,”IEEETrans.Pattern Anal.Mach.Intell.,vol.25,no.2,pp.281–288,Feb.2003.[11]V.Grau,A.U.J.Mewes,M.Alcaniz,R.Kikinis,and S.K.Warfield,“Improved watershed transform for medical image segmentation using prior information,”IEEE Trans.Image Process.,vol.23,no.4,pp.447–458,Apr.2004.[12]D.W.Jacobs,D.Weinshall,and Y.Gdalyahu,“Classification with non-metric distances:Image retrieval and class representation,”IEEE Trans.Pattern Anal.Mach.Intell.,vol.22,no.6,pp.583–600,Jun.2000.。