linux路由协议网络协议栈
Linux基础:网络协议篇
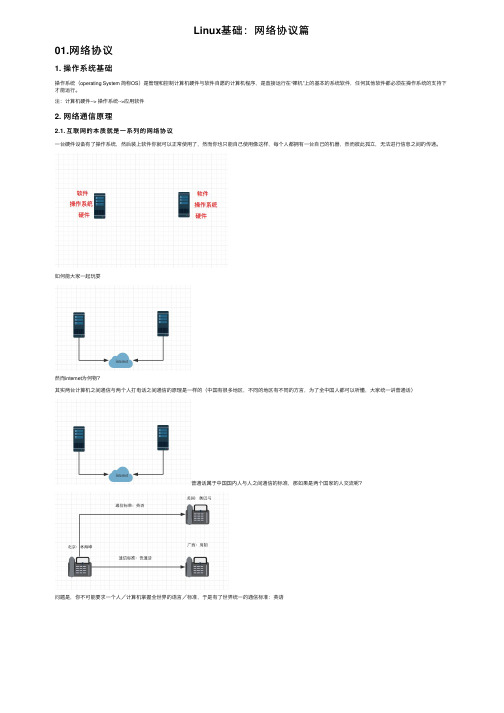
Linux基础:⽹络协议篇01.⽹络协议1. 操作系统基础操作系统(operating System 简称OS)是管理和控制计算机硬件与软件⾃愿的计算机程序,是直接运⾏在“裸机”上的基本的系统软件,任何其他软件都必须在操作系统的⽀持下才能运⾏。
注:计算机硬件--> 操作系统-->应⽤软件2. ⽹络通信原理2.1. 互联⽹的本质就是⼀系列的⽹络协议⼀台硬件设备有了操作系统,然后装上软件你就可以正常使⽤了,然⽽你也只能⾃⼰使⽤像这样,每个⼈都拥有⼀台⾃⼰的机器,然⽽彼此孤⽴,⽆法进⾏信息之间的传递。
如何能⼤家⼀起玩耍然⽽internet为何物?其实两台计算机之间通信与两个⼈打电话之间通信的原理是⼀样的(中国有很多地区,不同的地区有不同的⽅⾔,为了全中国⼈都可以听懂,⼤家统⼀讲普通话)普通话属于中国国内⼈与⼈之间通信的标准,那如果是两个国家的⼈交流呢?问题是,你不可能要求⼀个⼈/计算机掌握全世界的语⾔/标准,于是有了世界统⼀的通信标准:英语结论:英语成为世界上所有⼈通信的统⼀标准,如果把计算机看成分布于世界各地的⼈,那么连接两台计算机之间的internet实际上就是,⼀系列同的标准,这些标准称之为互联⽹协议,互联⽹的本质就是⼀系列的协议,总称为‘互联⽹协议’互联⽹协议的功能:定义计算机如何接⼊internet,以及接⼊internet的计算机通信的标准。
2.2. osi七层协议互联⽹协议按照不同分为osi七层(应表会传⽹数物)或tcp/ip五层或tcp/ip四层每层运⾏常见物理设备传输层------->四层交换机、四层的路由器⽹络层------->路由器、三层交换机数据链路层------->⽹桥、以太⽹交换机、⽹卡物理层------->中继器、集线器、双绞线osi七层协议数据传输的封包与解包过程2.3. tcp/ip五层模型讲解我们将应⽤层,表⽰层,会话层并作应⽤层,从tcp/ip五层协议的⾓度来阐述每层的由来与功能,搞清楚了每层的主要协议就理解了整个互联⽹通信的原理⾸先,⽤户感知到的只是最上⼀层应⽤层,⾃上⽽下每层都依赖下⼀层,所以我们最下层开始切⼊⽐较好理解每层都运⾏特定的协议,越往上越靠近⽤户,越往下越靠近硬件2.3.1. 物理层物理层由来:上⾯提到,孤⽴的计算机之间要想⼀起玩,就必须接⼊internet,⾔外之意就是计算机之间必须完成组⽹物理层主要功能:主要是基于电⽓特性发送⾼低电压(电信号),⾼电压对应数字1,低电压对应数字02.3.2. 数据链路层数据链路层的由来:单纯的电信号0和1没有任何意义,必须规定电信号多少位⼀组,,每组什么意思数据链路层的功能:定义了电信号的分组⽅式以太⽹协议:早期的时候各个公司都有⾃⼰的分组⽅式,后来形成了统⼀的标准,即以太⽹协议ethernetethernet规定使⽤者必须有⼀块⽹卡⼀组电信号构成⼀个数据包,叫做帧每⼀组数据帧分成:报头head和数据data两部分head包含:(固定18个字节)发送者/原地址,6个字节接受者/⽬标地址,6个字节数据类型,6个字节data包含:(最短46字节,最长1500字节)数据包的具体内容head长度+data长度=最短64字节,最长1518字节,超过最⼤限制就分⽚发送mac地址:head中包含的源和⽬标地址由来:ethernet规定接⼊internet的设备都必须具备⽹卡,发送端和接收端的地址便是指⽹卡的地址,即mac地址mac地址:每块⽹卡出⼚时都被烧制上⼀个世界唯⼀的mac地址,长度为48位2进制,通常12位16进制数表⽰(前六位是⼚商编号,后六位是流⽔线号)⼴播:有了mac地址,统⼀⽹络内的两台主机就可以通信了(⼀台主机通过arp协议获取另外⼀台主机的mac地址)ethernet采⽤最原始的⽅式,⼴播的⽅式进⾏通信,即计算机通信基本靠吼2.3.3. ⽹络层⽹络层的由来:有了ethernet、MAC地址、⼴播的发送⽅式,世界上的计算机就可以彼此通信了,问题是世界范围的互联⽹是由⼀个个彼此隔离的⼩的局域⽹组成的,那么如果所有的通信都采⽤以太⽹的⼴播⽅式,那么⼀台机器发送的包全世界都会收到,这就不仅仅是效率低的问题了,这是⼀种灾难上图结论:必须找出⼀种⽅法区分哪些计算机属于同⼀⼴播域,哪些不是,如果是就采⽤⼴播的⽅式发送,如果不是,就采⽤路由的⽅式(向不同⼴播域/⼦⽹分发数据包),mac地址是⽆法区分的,他只跟⼚商有关⽹络层功能:引⼊⼀套新的地址⽤来区分不同的⼴播域/⼦⽹,这套地址即⽹络地址IP协议:规定⽹络地址的协议叫ip协议,他定义的地址称之为ip地址,⼴泛采⽤的v4版本即ipv4它规定⽹络地址由32位2进制表⽰范围0.0.0.0-255.255.255.255⼀个ip地址通常写成四段⼗进制数,例:172.16.10.1注:ip地址+mac地址=>全世界范围内唯⼀的⼀台计算机ip地址分成两部分⽹络部分:标识⼦⽹主机部分:标识主机注意:单纯的ip地址段只是标识了ip地址的种类,从⽹络部分或主机部分都⽆法辨识⼀个ip所处的⼦⽹例:172.16.10.1与172.16.10.2并不能确定⼆者处于同⼀⼦⽹⼦⽹掩码所有“⼦⽹掩码”,就是表⽰⼦⽹络特征的⼀个参数,它在形式上等同于IP地址,也是⼀个32位进制数字,它的⽹络部分全部为1,主机部分全为0。
openwrt的技术结构

openwrt的技术结构
OpenWrt 是一个基于 Linux 操作系统的开源路由器固件。
它的技术结构主要包括以下几个方面:
1. Linux 内核:OpenWrt 基于 Linux 内核,提供了网络、存储、文件系统等基本功能。
2. 用户空间:OpenWrt 的用户空间包括各种应用程序和工具,用于实现路由器的各种功能,如网络配置、防火墙、无线网络、VPN 等。
3. 包管理系统:OpenWrt 使用包管理系统来管理应用程序和工具的安装和升级。
它支持通过 opkg 命令行工具或 Web 界面来安装和管理包。
4. 配置系统:OpenWrt 使用 UCI( Unified Configuration Interface )来管理路由器的配置。
UCI 提供了一种标准化的方式来存储和管理路由器的配置信息。
5. 网络协议栈:OpenWrt 支持各种网络协议,如 TCP/IP、UDP、ICMP 等。
它还支持 IPv6 和 VPN 等高级网络功能。
6. 无线网络:OpenWrt 支持各种无线网络标准,如 Wi-Fi、蓝牙等。
它提供了丰富的无线网络管理功能,如无线安全、SSID 设置、信道选择等。
7. 开发工具:OpenWrt 提供了一系列开发工具,如交叉编译环境、调试工具等,方便开发者进行二次开发和定制。
8. 硬件支持:OpenWrt 支持各种硬件平台,包括 x86、ARM、MIPS 等。
它可以根据不同的硬件平台进行定制和优化。
总之,OpenWrt 的技术结构是一个高度模块化、可定制化的系统,它为用户提供了丰富的功能和灵活的配置选项,同时也为开发者提供了一个强大的开发平台。
linux路由转发原理

linux路由转发原理
在Linux系统中,路由转发指的是将接收到的网络数据包从一
个网络接口转发到另一个网络接口的过程。
Linux系统通过以
下几个步骤实现路由转发:
1. 数据包接收:当一个网络接口接收到一个数据包时,操作系统会捕获数据包,并将其传递给网络协议栈进行处理。
2. 路由决策:在接收到数据包后,操作系统会根据其目的IP
地址进行路由决策,确定将数据包发送到哪个网络接口。
它会检查系统的路由表,找到与目的IP地址最匹配的路由项。
路
由表中的每个路由项包含目的网络地址、下一跳地址和出接口。
3. 数据包转发:根据路由决策,操作系统将数据包从接收网络接口转发到指定的出接口。
这个过程涉及到重新封装数据包,包括设置新的源和目的MAC地址。
通过重新封装,操作系统
可以将数据包发送到下一跳路由器或目的主机。
4. 数据包转发控制:操作系统还可以根据配置和策略控制路由转发过程。
例如,可以通过配置IP转发表来允许或拒绝特定
的数据包转发。
此外,还可以使用网络地址转换(NAT)来
修改数据包中的IP地址和端口。
总结起来,Linux系统的路由转发原理是根据目的IP地址查找路由表,然后将数据包从接收网络接口转发到指定的出接口,同时进行必要的数据包封装和重写。
Internet网络协议族

Internet⽹络协议族1、linux⽬前⽀持多种协议族,每个协议族⽤⼀个net_porto_family结构实例来表⽰,在初始化时,会调⽤sock_register()函数初始化注册到net_families[NPROTO]中去;同时出现了⼀个地址族的概念,⽬前协议族和地址族是⼀⼀对应关系。
历史上曾经有⼀个协议族⽀持多个地址族,实际上从未实现过。
在socket.h⽂件中PF_XX和AF_XX 值⼀样2、由于不同协议族的结构差别很⼤,为了封装统⼀,以便在初始化时,可以统⼀接⼝,于是就有了net_proto_family。
其⽤sock_register统⼀注册,初始化钩⼦,具体初始化,其实现见钩⼦实现,类似于VFS 的实现⽅式。
⼀种很好的设计思想。
/*ops->create在应⽤程序创建套接字的时候,引起系统调⽤,从⽽在函数__sock_create中执⾏ops->create netlink为netlink_family_ops应⽤层创建套接字的时候,内核系统调⽤sock_create,然后执⾏该函数pf_inet的net_families[]为inet_family_ops,对应的套接⼝层ops参考inetsw_array中的inet_stream_ops inet_dgram_ops inet_sockraw_ops,传输层操作集分别为tcp_prot udp_prot raw_protnetlink的net_families[]netlink_family_ops,对应的套接⼝层ops为netlink_opsfamily协议族通过sock_register注册传输层接⼝tcp_prot udp_prot netlink_prot等通过proto_register注册IP层接⼝通过inet_add_protocol(&icmp_protocol等注册,这些组成过程参考inet_init函数*/struct net_proto_family {//操作集参考inetsw_arrayint family;int (*create)(struct net *net, struct socket *sock,int protocol, int kern);协议族的套接字创建函数指针,每个协议族实现都不同struct module *owner;};Internet 协议族的net_proto_family结构实例为inet_family_ops,创建套接字socket时,其调⽤接⼝为inet_create().2、inet_protosw 结构/* This is used to register socket interfaces for IP protocols. */struct inet_protosw {struct list_head list;/* 初始化时将相同的type的inet_protosw散列在同⼀个链表*//* These two fields form the lookup key. */unsigned short type; /* This is the 2nd argument to socket(2). 表⽰套接⼝字的类型,对于Internet 协议族有三种类型 SOCK_STREAM SOCK_DGRAM SOCK_RAW 对于与应⽤层socket函数的第⼆个参数type*/ unsigned short protocol; /* This is the L4 protocol number. */struct proto *prot; /*套接⼝⽹络层⼝,tcp为tcp_port udp为udp_port 原始套接字为raw_port*/const struct proto_ops *ops;/* 套接⼝传输层接⼝,tcp为inet_stream_ops,udp 为inet_dgram_ops,原始套接字为inet_sockraw_ops*/unsigned char flags; /* See INET_PROTOSW_* below. */};#define INET_PROTOSW_REUSE 0x01 /* Are ports automatically reusable? 端⼝重⽤*/#define INET_PROTOSW_PERMANENT 0x02 /* Permanent protocols are unremovable. 协议不能被替换卸载*/#define INET_PROTOSW_ICSK 0x04 /* Is this an inet_connection_sock? 是不是为连接类型的接⼝*/View Codetcp 不能被替换卸载切为连接型套接字,udp 不能被替换和卸载,rawsocket端⼝可以重⽤。
linux ipv6报文接收流程 -回复

linux ipv6报文接收流程-回复Linux IPv6报文接收流程IPv6是下一代互联网协议,与IPv4相比,它具有更大的地址空间和更高的网络安全性。
在Linux系统中,处理IPv6报文的流程相对复杂,涉及到不同的网络协议栈和内核模块。
本文将详细介绍Linux系统中IPv6报文的接收流程,并逐步回答相关问题。
1. 前提条件在开始详细讨论IPv6报文接收流程之前,我们需要明确一些前提条件。
首先,Linux系统中需要启用IPv6功能。
这意味着在内核配置中,需要开启IPv6协议支持以及相关的网络协议栈,如IPv6路由、邻居发现、套接字等。
这通常是通过在内核编译配置文件(如.config)中设置相应的选项来实现的。
其次,还需要一个可用的网络接口。
在IPv6中,网络接口通常使用全局唯一的IPv6地址作为标识符。
因此,系统需要至少一个支持IPv6的网络接口,以便能够接收和发送IPv6报文。
2. IPv6报文接收流程在Linux系统中,IPv6报文的接收流程通常涉及以下几个关键步骤。
2.1. 网络接口首先,网络接口需要监听和接收来自网络的报文。
这意味着系统中至少有一个网络接口需要配置为IPv6模式,并已连接到IPv6网络。
例如,网络接口eth0可以配置为IPv6模式,并分配一个IPv6地址。
2.2. 网络驱动程序接下来,网络驱动程序负责接收来自网络接口的报文。
网络驱动程序通常与特定的硬件设备相关联,如以太网卡。
当硬件设备接收到报文时,它会通过网络驱动程序传递给内核。
2.3. 协议栈处理内核中的网络协议栈负责进一步处理接收到的IPv6报文。
这涉及到几个关键模块,包括IPv6路由、分片、套接字等。
2.3.1. IPv6路由IPv6路由模块根据目标IPv6地址确定接收报文的下一跳。
它会检查系统的IPv6路由表,找到与目标地址最匹配的路由条目,并确定下一跳的IPv6地址。
2.3.2. 分片如果接收到的报文太大而无法在链路层传输,内核会将其进行分片。
操作系统中的网络协议栈及其实现

操作系统中的网络协议栈及其实现在当今的数字化时代,网络已经成为了人们生活和工作中不可或缺的一部分。
作为连接互联网的重要中介,操作系统扮演着一个重要的角色。
操作系统中的网络协议栈是实现网络通信的核心组件,本文将对操作系统中的网络协议栈及其实现进行探讨。
一、网络协议栈的作用和基本原理操作系统中的网络协议栈是一系列网络协议的集合,用于实现数据在网络中的传输和通信。
它通过网络接口设备与物理网络相连,负责数据封装、分组、路由和传输等一系列工作。
网络协议栈按照分层结构组织,通常包括物理层、数据链路层、网络层、传输层和应用层等不同的层次。
1. 物理层物理层是网络协议栈的最底层,负责将数字数据转换为物理信号,并通过物理介质进行传输。
它关注的是物理连接、电气特性和传输速率等问题。
2. 数据链路层数据链路层建立在物理层之上,负责将数据分组组装为数据帧,并通过物理介质传输。
它包括逻辑链路控制、介质访问控制和数据帧的错误检测和纠正等功能。
3. 网络层网络层负责数据在网络中的路由选择和传输控制。
它提供了网络互联和数据包交换的功能,具有IP地址分配、路由表维护等重要功能。
4. 传输层传输层为应用程序提供了端到端的可靠通信服务。
它通过端口号标识应用程序,负责数据的分段、重组和流控制等工作。
5. 应用层应用层是网络协议栈的最高层,提供了各种网络应用程序的接口和服务。
它包括HTTP、FTP、DNS等协议,用于实现电子邮件、文件传输、域名解析等功能。
二、网络协议栈的实现方式操作系统中的网络协议栈可以通过不同的实现方式来实现,下面介绍两种常用的实现方式。
1. 单内核实现方式单内核实现方式是指将网络协议栈的各个层次直接嵌入到操作系统的内核中。
这种实现方式的优点是效率高,因为各个层次之间可以直接进行函数调用。
然而,缺点是网络协议栈与操作系统内核紧密耦合,不够灵活,对于协议的更新和扩展需要修改内核代码。
2. 用户态协议栈实现方式用户态协议栈实现方式是指将网络协议栈的各个层次实现为用户态的进程或线程。
linux socket 内核原理
Linux中的Socket是一种用于网络通信的编程接口,它允许进程通过网络进行数据传输。
Socket在Linux内核中的实现涉及到多个组件和原理。
1. 网络协议栈:Linux内核中的网络协议栈负责处理网络通信的各个层次,包括物理层、数据链路层、网络层和传输层。
Socket通过网络协议栈与网络进行交互。
2. 套接字数据结构:在Linux内核中,套接字(Socket)被实现为一种数据结构,用于表示网络连接。
套接字数据结构包含了连接的相关信息,如IP地址、端口号等。
3. 文件描述符:在Linux中,套接字被视为一种文件,因此每个套接字都有一个对应的文件描述符。
通过文件描述符,进程可以对套接字进行读写操作。
4. 网络设备驱动程序:Linux内核中的网络设备驱动程序负责处理网络设备的底层操作,如发送和接收数据包。
套接字通过网络设备驱动程序与网络设备进行通信。
5. 网络协议处理:当进程通过套接字发送或接收数据时,Linux内核会根据套接字的协议类型(如TCP或UDP)进行相应的协议处理。
这包括建立连接、数据分片、错误检测等操作。
6. 系统调用:在用户空间中,进程通过系统调用(如socket、bind、connect等)来创建和操作套接字。
系统调用会触发内核中相应的函数,完成套接字的创建和操作。
总的来说,Linux内核中的Socket实现涉及到网络协议栈、套接字数据结构、文件描述符、网络设备驱动程序、网络协议处理和系统调用等多个组件和原理。
这些组件和原理共同工作,使得进程能够通过套接字进行网络通信。
{"code":0,"msg":"请求出现异常","data":{}}。
mss的默认值
mss的默认值MSS的默认值是什么?MSS(Maximum Segment Size)是TCP协议中的一个参数,用于指定TCP数据包中数据部分的最大长度。
在TCP连接建立时,双方会协商MSS值,以确定每个TCP数据包可以携带的最大数据量。
MSS的默认值是由操作系统和网络设备决定的。
不同操作系统和设备可能有不同的默认值。
下面将分别介绍Windows、Linux和路由器等设备中MSS的默认值。
Windows中MSS的默认值在Windows操作系统中,默认情况下,TCP/IP协议栈会使用1460字节作为MSS的默认值。
这个值是根据以太网MTU(Maximum Transmission Unit)大小(1500字节)减去IP头(20字节)和TCP头(20字节)计算得出的。
如果需要修改Windows中TCP/IP协议栈中MSS的默认值,可以通过修改注册表项来实现。
具体方法如下:1. 打开注册表编辑器(regedit.exe)2. 定位到HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\Tc pip\Parameters路径3. 创建一个名为TcpWindowSize的DWORD类型键值4. 将键值数据设置为所需MSS大小减去40字节后得到的数值例如,如果需要将MSS设置为1400字节,则TcpWindowSize键值应设置为1360。
Linux中MSS的默认值在Linux操作系统中,默认情况下,TCP/IP协议栈会使用1460字节作为MSS的默认值,与Windows相同。
不过,在Linux中可以通过修改内核参数来修改MSS的默认值。
需要修改的内核参数是tcp_mss_default,它定义了TCP连接建立时协商的MSS默认值。
可以通过以下命令来查看当前内核参数值:sysctl net.ipv4.tcp_mss_default要修改该参数的值,可以使用以下命令:sysctl -w net.ipv4.tcp_mss_default=1400其中,1400是所需的MSS大小。
Linux命令高级技巧使用route进行网络路由配置
Linux命令高级技巧使用route进行网络路由配置Linux命令高级技巧:使用route进行网络路由配置在Linux操作系统中,网络路由是连接不同网络之间的关键工具。
通过正确配置路由表,可以实现数据在不同网络之间的传递。
route命令是Linux中用于管理和配置网络路由的命令。
本文将介绍使用route 命令进行网络路由配置的高级技巧。
一、route命令基本用法route命令用于查看、添加和删除路由表的条目。
其基本语法如下:`route [options] [command] [destination]`常用的route命令选项和参数包括:- -n:以数字形式显示IP地址和网络掩码。
- -v:显示详细信息。
- add:添加路由表条目。
- del:删除路由表条目。
- default:指定默认网关。
- netmask:指定网络掩码。
- gw:指定网关地址。
例如,要添加一个路由表条目,将目标网络192.168.1.0/24的数据包通过网关192.168.0.1发送,可以使用以下命令:`route add -net 192.168.1.0 netmask 255.255.255.0 gw 192.168.0.1`二、动态路由配置动态路由是指通过路由协议动态更新路由表,实现自动路由配置的功能。
Linux系统支持多种动态路由协议,如RIP、OSPF和BGP。
使用动态路由可以提高网络的可靠性和可扩展性。
1. RIP协议配置RIP(Routing Information Protocol)是一种基于距离向量算法的路由协议,用于在小型和中型网络中实现动态路由。
在Linux系统中,可以使用Quagga软件包来实现RIP协议。
首先,安装Quagga软件包:`sudo apt-get install quagga`然后,编辑主配置文件`/etc/quagga/ripd.conf`,添加以下内容:```router ripnetwork eth0network eth1redistribute connected```其中,eth0和eth1分别表示需要参与RIP协议的接口。
计算机网络的基本组成
计算机网络的基本组成引言计算机网络是由一组相互连接的计算机系统组成,它们通过通信链路进行数据传输和资源共享。
在现代社会中,计算机网络起到了至关重要的作用。
在本文中,我们将探讨计算机网络的基本组成,包括硬件、软件和协议。
一、硬件组成1. 主机:主机是计算机网络的核心组成部分。
它能够运行网络应用程序,并通过网络与其他计算机进行通信。
主机可以是个人电脑、服务器、路由器等。
2. 网络设备:网络设备是用于连接计算机的硬件设备,包括网卡、交换机、路由器、集线器等。
这些设备可以使计算机之间能够进行数据交换和通信。
3. 传输介质:传输介质是指在计算机网络中传输数据的媒介,包括有线介质和无线介质。
有线介质主要包括双绞线、同轴电缆和光纤,而无线介质则指的是蓝牙、Wi-Fi等无线通信技术。
二、软件组成1. 操作系统:计算机网络中的主机通常运行着操作系统,如Windows、Linux等。
操作系统提供了网络功能的支持,包括对网络接口的控制、数据传输的调度等。
2. 应用程序:应用程序是运行在计算机网络上的软件程序。
例如,Web浏览器、电子邮件客户端和聊天工具等应用程序可以使用户在网络上进行信息检索、通信和协作。
三、协议组成1. 网络协议:网络协议是计算机网络中实现通信的规则和约定。
常见的网络协议包括TCP/IP协议、HTTP协议、SMTP协议等。
它们定义了数据传输的格式、通信的方式以及错误处理等。
2. 网络协议栈:计算机网络中的协议通常按照协议栈的形式组织。
一个典型的协议栈包括物理层、数据链路层、网络层、传输层和应用层。
这些层次化的协议可以使不同的计算机和设备能够进行有效的通信。
结论计算机网络的基本组成包括硬件、软件和协议。
硬件组成包括主机、网络设备和传输介质,它们提供了计算机网络的物理基础。
软件组成包括操作系统和应用程序,它们支持和实现了网络功能。
协议组成包括网络协议和协议栈,它们定义了通信的规则和方式。
这些组成部分相互配合,共同构成了一个完整的计算机网络系统。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
迈普学习总结经过在公司里学习了几个月,把大体的工作总结于下:在参与1800-20 3G路由的开发中,我参与了l2tp, gre,静态路由, ipsec,日志关键信息提取的编写。
并同时参与了ipsec-tools源码,linux kernel 网络协议栈源码,l2tpd源码分析。
并且同时了解了vrrp,rip等协议。
L2TP模块:L2tp代码流程:其中认证过程分为pap和chap认证:Pap认证:Chap认证:大体过程应该是这样的,中间也许有错,主要是记不大清楚了。
Pppd 向内核注册过程如下图:做lac 的路由器通过拨号到lns ,通过上面的连接认证后,lns 会给lac 分配一个私有ip 地址,该Ip 地址可以和2通信。
通过这个过程后,久可以让内网1的pc 访问内网2的pc 。
Gre 模块:模型:开始的时候,内网1和内网2是不能相互到达的,因为中间有许多中间网络。
当建立好GRE 隧道后,内网1就可以和内网2通信了。
实现:GRE 脚本主要通过iproute2这个工具实现。
使用的主要脚本命令: Ip route add $name mode gre remote $remoteip local $localip ttl 255 Ip route set $name up Ip route add net $net/$mask dev $name脚本流程:脚本从lua 保存的配置文件中获取到上面的变量值,然后通过以上指令,将变量值设置到相应的隧道中。
责任:主要担任gre 模块的测试(与linux )。
DDNS 模块:原理:DDNS 又叫动态域名解析。
实用环境是在用户动态获取IP 地址的情况下。
因为传统的DNS 只能与固定IP 地址绑定,一旦IP 地址发生是指在用户的IP地址发生改变时,相应的DDNS客户端会把自己现在的变化后的IP地址传给DDNS服务器,告诉它自己的IP地址已经发生变化,需要服务器将以前绑定域名的IP换成现在变化后的IP地址。
如果内部在加上端口映射,那么久可以实现路由器内部的主机间接与DNS绑定,即其他人通过域名就能访问的内网的某台计算上的服务器。
责任:DDNS的测试。
静态路由模块:原理:举个例子,当一个路由器刚接入到一个网络中时,在这个陌生的环境中,它根本不知道去某个地址该怎么走,静态路由就相当于一个指路人,它告诉路由器某个IP地址该怎么走。
配置的时候,只需要告诉路由器到达某个网络需要从哪张网卡和相应网卡出去的网关地址就可以了。
这样凡是到那个网络的IP数据包,路由器都会将它从相应网卡转发出去(ttl-1)。
它并不关心数据包能否真正的到达。
实现:具体命令:route add –net $net mask $netmask gw $gateway dev $device责任:静态路由的脚本的基本框架。
Ipsec模块:原理:在内核2.6版本中已经存在ipsec模块,该模块的主要作用是让数据包经过加密/认证从安全的隧道中到达指定的目标地址。
它的有几种数据包格式,一种是esp,一种是ah,另一种是esp+ah。
他们的报文格式如下:Ah是一种用于认证报文,它主要是给数据包提供认证,防重放;ESP是一种用于加密报文,当然它也有认证的功能,并且也具有抗重放的机制。
它是一种更优越于AH的报文结构。
另外,esp+ah则是一种集esp和ah于一身的格式,当然它的安全性就更不可否认了。
整个模块分为两大类:第一类,kernel ipsec的实现,第二类上层应用程序ike即为ipsec模块协商认证算法和加密算法的协议。
下面谈谈ike协议。
Ike协议分为两个阶段,第一阶段协商对对方的身份进行认证,并且为第二阶段的协商提供一条安全可靠的通道。
第一个阶段又分为3种模式,我们常用的有两种模式,一个是主模式,一个是积极模式。
第二阶段主要对IPSEC的安全性能进行协商,产生真正可以用来加密数据流的密钥。
主模式(IKE SA 阶段):以上过程中包含验证信息,我就没特别指出了。
具体参见如下:发送cockie包,用来标识唯一的一个IPSEC会话。
IKE阶段一(主模式):发送消息1 initiator====>responsorisakmp headersa payloadproposal payloadtransform payload定义一组策略:加密方法:DES认证身份方法:预共享密钥存活时间:86400秒Diffie-Hellman group:1IKE阶段二(主模式):发送消息2 initiator<====responsor同上IKE阶段三(主模式):发送消息3 initiator====>responsor通过DH算法产生共享密钥KE(Key Exchang) Payloadnonce(暂时) PayloadDH算法:A: P(较大的质数) B: P(较大的质数)G GPriA(随机产生) PriB(随机产生)PubA=G^PriA mod P PubB=G^PriB mod P交换PubA和PubBZ=PubB^PriA mod P Z=PubA^PriB mod PZ就是共享密钥,两个自我产生的Z应相同,它是用来产生3个SKEYID的素材。
IKE阶段四(主模式):发送消息4 initiator<====responsor同上主模式第3、4条消息其实就是DH算法中需要交换的几个参数,然后路由器再通过DH算法计算出的公共密钥计算出以下3个参数(这是在发送第5、6个消息前完成的):SKEYID_d:留在在第二阶段用,用来计算后续的IKE密钥资源;SKEYID_a:散列预共享密钥,提供IKE数据完整性和认证;SKEYID_e:用来加密下一阶段的message,data, preshared key,包括第二阶段。
IKE阶段五(主模式):发送消息5 initiator====>responsorIdentity Payload:用于身份标识Hash Payload:用来认证以上2个负载都用SKEYID_e加密IKE阶段六(主模式):发送消息6 initiator<====responsor同上消息5、6是用来验证对等体身份的。
至此IKE协商第一阶段完成。
主要会发送6个报文,由于最后一组报文发送的是身份,此时身份已经加密,因此,只能采用地址进行认证,但其安全性高于积极模式。
缺点是耗时比积极模式长。
积极模式:主要发送3个报文,安全性没有主模式好,由于其ID不加密,因此可用于移动客户端模式。
即不用地址作为ID。
优点:速度快,缺点安全性不高。
第二阶段快速模式(IPSec SA 阶段):首先判断是否启用了PFS(完美转发安全),若启用了则重新进行DH算法产生密钥,若没有启用则是用第一阶段的密钥。
IPSec阶段一(快速模式):发送消息1 initiator====>responsor同样定义一组策略,继续用SKEYID_e加密:Encapsulation— ESPIntegrity checking— SHA-HMACDH group— 2Mode— TunnelIPSec阶段二(快速模式):发送消息2 initiator<====responsor同上,主要是对消息1策略的一个确认。
在发送消息3前,用SKEYID_d,DH共享密钥,SPI等产生真正用来加密数据的密钥。
IPSec阶段三(快速模式):发送消息3 initiator====>responsor用来核实responsor的liveness。
至此,整个IPSec协商的两个过程已经完成,两端可以进行安全的数据传输。
实现:ike协议我们主要是通过利用开源软件ipsec-tools来实现的。
责任:负责ipsec的代码BUG解决(BUG数量多,就不列出了),ipsec的证书申请脚本编写(研究了openssl)。
Ipsec-tools流程:eay_init();//opensll初始化initlcconf();//本地配置文件初始化initrmconf();//远端配置文件初始化oakley_dhinit();//dh算法初始化compute_vendorids();//dpdparse(ac, av);//传进来的参数分析ploginit();//本地日志初始化pfkey_init()//内核接口af_key初始化,主要是向内核注册isakmp_cfg_init(ISAKMP_CFG_INIT_COLD))//isakmp配置初始化cfparse();//配置文件分析,别且赋值给相应结构体session();//主要会话下面是session函数里面的实现:sched_init();//调度初始化init_signal();//信号初始化admin_init()//和setkey, racoonctl的连接口初始化initmyaddr();//初始化本地地址isakmp_init()//isakmp初始化initfds();//初始化select的套接字natt_keepalive_init ();//初始化nat协商的相关内容for (i = 0; i <= NSIG; i++)//信号的相应保存变量初始化sigreq[i] = 0;check_sigreq();//检测是否收到有信号error = select(nfds, &rfds, (fd_set *)0, (fd_set *)0, timeout);//多路监听admin_handler();//监听到setkey和racoonctl的fd触发,调用该函数处理isakmp_handler(p->sock);//监听到ike连接信息和ike协商信息处理函数pfkey_handler();//监听的内核af_key发上来的信息处理函数(包含发起ike协商等)isakmp_handler(p->sock);函数里最重要的函数是isakmp_main()isakmp_handler(p->sock);()这个函数里面除了数据包有效性检查外,ph1_main()第一阶段函数,quick_main()第二阶段处理函数,这两个函数最重要。
这两个函数内分别用了一个重要的结构体:如下ph1exchange[][] 整个racoon就靠这个结构体来进行协商。
(可以说是贯穿整个racoon)__P((struct ph1handle *, vchar_t *)) = {/* error */{ {}, {}, },/* Identity Protection exchange */{{ nostate1, ident_i1send, nostate1, ident_i2recv, ident_i2send,ident_i3recv, ident_i3send, ident_i4recv, ident_i4send, nostate1, },{ nostate1, ident_r1recv, ident_r1send, ident_r2recv, ident_r2send,ident_r3recv, ident_r3send, nostate1, nostate1, nostate1, },},/* Aggressive exchange */{{ nostate1, agg_i1send, nostate1, agg_i2recv, agg_i2send,nostate1, nostate1, nostate1, nostate1, nostate1, },{ nostate1, agg_r1recv, agg_r1send, agg_r2recv, agg_r2send,nostate1, nostate1, nostate1, nostate1, nostate1, },},/* Base exchange */{{ nostate1, base_i1send, nostate1, base_i2recv, base_i2send,base_i3recv, base_i3send, nostate1, nostate1, nostate1, },{ nostate1, base_r1recv, base_r1send, base_r2recv, base_r2send,nostate1, nostate1, nostate1, nostate1, nostate1, },},};可以看的到上面有第一阶段有三个模式的发送和接受函数(main , Aggressive, base);其中有每一个模式下的交互消息一个函数。