hadoop和hbase分布式配置及整合eclipse开发
Hadoop搭建与Eclipse开发环境设置

hadoop搭建与eclipse开发环境设置――邵岩飞1.Ubuntu 安装安装ubuntu11.04 desktop系统。
如果是虚拟机的话,这个无所谓了,一般只需要配置两个分区就可以。
一个是\另一个是\HOME 文件格式就用ext4就行了。
如果是实机的话建议在分配出一个\SWAP分区。
如果嫌麻烦建议用wubi安装方式安装。
这个比较傻瓜一点。
2.Hadoop 安装hadoop下载到阿帕奇的官方网站下载就行,版本随意,不需要安装,只要解压到适当位置就行,我这里建议解压到$HOME\yourname里。
3.1 下载安装jdk1.6如果是Ubuntu10.10或以上版本是不需要装jdk的,因为这个系统内置openjdk63.2 下载解压hadoop不管是kubuntu还是ubuntu或者其他linux版本都可以通过图形化界面进行解压。
建议放到$HOME/youraccountname下并命名为hadoop.如果是刚从windows系统或者其它系统拷贝过来可能会遇到权限问题(不能写入)那么这就需要用以下命令来赋予权限。
sudo chown –R yourname:yourname [hadoop]例如我的就是:sudo chown –R dreamy:dreamy hadoop之后就要给它赋予修改权限,这就需要用到:sudo chmod +X hadoop3.3 修改系统环境配置文件切换为根用户。
●修改环境配置文件/etc/profile,加入:你的JAVA路径的说明:这里需要你找到JAVA的安装路径,如果是Ubuntu10.10或10.10以上版本,则应该在/usr/bin/java这个路径里,这个路径可能需要sudo加权限。
3.4 修改hadoop的配置文件●修改hadoop目录下的conf/hadoop-env.sh文件加入java的安装根路径:●把hadoop目录下的conf/core-site.xml文件修改成如下:<?xml version="1.0"?><?xml-stylesheet type="text/xsl" href="configuration.xsl"?><!-- Put site-specific property overrides in this file. --><configuration><property><name>hadoop.tmp.dir</name><value>/hadoop</value></property><property><name></name><value>hdfs://ubuntu:9000</value></property><property><name>dfs.hosts.exclude</name><value>excludes</value></property><property>●把hadoop目录下的conf/ hdfs-site.xml文件修改成如下:<?xml version="1.0"?><?xml-stylesheet type="text/xsl" href="configuration.xsl"?><!-- Put site-specific property overrides in this file. --><configuration><property><name>dfs.data.dir</name><value>/hadoop/data</value></property><property><name>dfs.replication</name><value>3</value></property></configuration>●把hadoop目录下的conf/ mapred-site.xml文件修改成如下:注意:别忘了hadoop.tmp.dir,.dir,dfs.data.dir参数,hadoop存放数据文件,名字空间等的目录,格式化分布式文件系统时会格式化这个目录。
eclipse hadoop开发环境配置

eclipse hadoop开发环境配置win7下安装hadoop完成后,接下来就是eclipse hadoop开发环境配置了。
具体的操作如下:一、在eclipse下安装开发hadoop程序的插件安装这个插件很简单,haoop-0.20.2自带一个eclipse的插件,在hadoop目录下的contrib\eclipse-plugin\hadoop-0.20.2-eclipse-plugin.jar,把这个文件copy到eclipse的eclipse\plugins目录下,然后启动eclipse就算完成安装了。
这里说明一下,haoop-0.20.2自带的eclipse的插件只能安装在eclipse 3.3上才有反应,而在eclipse 3.7上运行hadoop程序是没有反应的,所以要针对eclipse 3.7重新编译插件。
另外简单的解决办法是下载第三方编译的eclipse插件,下载地址为:/p/hadoop-eclipse-plugin/downloads/list由于我用的是Hadoop-0.20.2,所以下载hadoop-0.20.3-dev-eclipse-plugin.jar.然后将hadoop-0.20.3-dev-eclipse-plugin.jar重命名为hadoop-0.20.2-eclipse-plugin.jar,把它copy到eclipse的eclipse\plugins目录下,然后启动eclipse完成安装。
安装成功之后的标志如图:1、在左边的project explorer 上头会有一个DFS locations的标志2、在windows -> preferences里面会多一个hadoop map/reduce的选项,选中这个选项,然后右边,把下载的hadoop根目录选中如果能看到以上两点说明安装成功了。
二、插件安装后,配置连接参数插件装完了,启动hadoop,然后就可以建一个hadoop连接了,就相当于eclipse里配置一个weblogic的连接。
Hadoop云计算基础架构的搭建和hbase和hive的整合应用

Hadoop云计算基础架构的搭建和hbase和hive的整合应用谭洁清;毛锡军【摘要】本论文介绍一种常见的云计算分布式hadoop架构及其子项目分布式的hbase数据库和hive数据仓库,真实搭建一个hadoop云计算实验平台,并整合hbase和hive,通过创建数据表并验证实现了两数据库之间的访问,为以后的大规模的数据的存储,计算和应用创造基础.【期刊名称】《贵州科学》【年(卷),期】2013(031)005【总页数】4页(P32-35)【关键词】hadoop;云计算;hbase;hive【作者】谭洁清;毛锡军【作者单位】贵州省新技术研究所,贵阳550025;贵州省新技术研究所,贵阳550025【正文语种】中文【中图分类】TP3011 Hadoop,hbase和hive的简介Hadoop是一个分布式系统基础架构,由Apache基金会开发。
用户可以在不了解分布式底层细节的情况下,开发分布式程序。
充分利用集群的威力高速运算和存储。
简单地说来,Hadoop是一个可以更容易开发和运行处理大规模数据的软件平台。
Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。
HDFS有着高容错性的特点。
Hadoop有许多元素构成。
其最底部是Hadoop Distributed File System(HDFS),它存储Hadoop集群中所有存储节点上的文件。
HDFS(对于本文)的上一层是MapReduce引擎,是一个并行计算框架,该引擎由 JobTrackers和 TaskTrackers组成(Tom White,2010)。
在Hadoop的安装之前,先介绍一下Hadoop对各个节点的角色定义。
Hadoop分别从3个角度将主机划分为2种角色。
第一,划分为master和slave;第二,从HDFS的角度,将主机划分为NameNode和DataNode(在分布式文件系统中,目录的管理很重要,管理目录的就相当于主人,而NameNode就是目录管理者);第三,从MapReduce的角度,将主机划分为 JobTracker和TaskTracker(一个job经常被划分为多个task,从这个角度不难理解它们之间的关系)。
HADOOP(4)eclipse开发整合
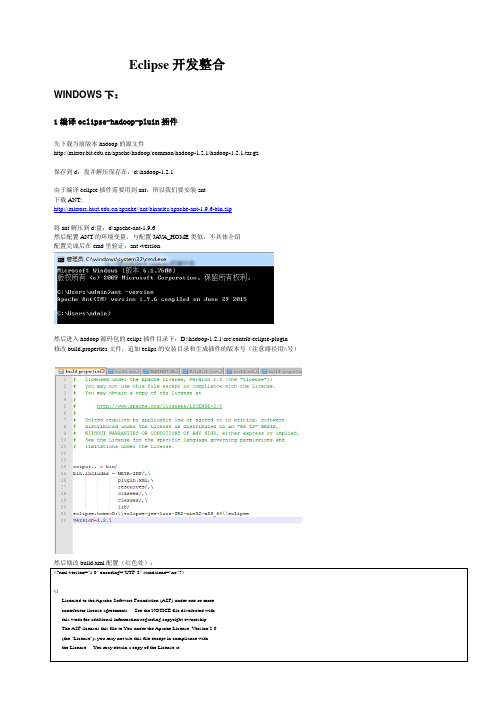
Eclipse开发整合WINDOWS下:1编译eclipse-hadoop-pluin插件先下载当前版本hadoop的源文件/apache/hadoop/common/hadoop-1.2.1/hadoop-1.2.1.tar.gz保存到d:盘并解压保存在:d:\hadoop-1.2.1由于编译eclipse插件需要用到ant,所以我们要安装ant下载ANT:/apache//ant/binaries/apache-ant-1.9.6-bin.zip将ant解压到d:盘:d\apache-ant-1.9.6然后配置ANT的环境变量,与配置JA V A_HOME类似,不具体介绍配置完成后在cmd里验证:ant -version然后进入hadoop源码包的eclips插件目录下:D:\hadoop-1.2.1\src\contrib\eclipse-plugin修改build.properties文件,追加eclips的安装目录和生成插件的版本号(注意路径用\\号)然后修改build.xml配置(红色处):<?xml version="1.0" encoding="UTF-8" standalone="no"?><!--Licensed to the Apache Software Foundation (ASF) under one or morecontributor license agreements. See the NOTICE file distributed withthis work for additional information regarding copyright ownership.The ASF licenses this file to You under the Apache License, Version 2.0(the "License"); you may not use this file except in compliance withthe License. You may obtain a copy of the License at/licenses/LICENSE-2.0Unless required by applicable law or agreed to in writing, softwaredistributed under the License is distributed on an "AS IS" BASIS,WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.See the License for the specific language governing permissions andlimitations under the License.--><project default="jar" name="eclipse-plugin"><import file="../build-contrib.xml"/><path id="eclipse-sdk-jars"><fileset dir="${eclipse.home}/plugins/"><include name="org.eclipse.ui*.jar"/><include name="org.eclipse.jdt*.jar"/><include name="org.eclipse.core*.jar"/><include name="org.eclipse.equinox*.jar"/><include name="org.eclipse.debug*.jar"/><include name="org.eclipse.osgi*.jar"/><include name="org.eclipse.swt*.jar"/><include name="org.eclipse.jface*.jar"/><include name="org.eclipse.team.cvs.ssh2*.jar"/><include name="com.jcraft.jsch*.jar"/></fileset><fileset dir="D:/hadoop-1.2.1"><include name="hadoop*.jar"/></fileset></path><!-- Override classpath to include Eclipse SDK jars --><path id="classpath"><pathelement location="${build.classes}"/><pathelement location="${hadoop.root}/build/classes"/><path refid="eclipse-sdk-jars"/></path><!-- Skip building if eclipse.home is unset. --><target name="check-contrib" unless="eclipse.home"><property name="skip.contrib" value="yes"/><echo message="eclipse.home unset: skipping eclipse plugin"/></target><target name="compile" depends="init, ivy-retrieve-common" unless="skip.contrib"><echo message="contrib: ${name}"/><javacencoding="${build.encoding}"srcdir="${src.dir}"includes="**/*.java"destdir="${build.classes}"debug="${javac.debug}"deprecation="${javac.deprecation}"><classpath refid="classpath"/></javac></target><!-- Override jar target to specify manifest --><target name="jar" depends="compile" unless="skip.contrib"><mkdir dir="${build.dir}/lib"/><copy file="D:/hadoop-1.2.1/hadoop-core-${version}.jar" tofile="${build.dir}/lib/hadoop-core.jar" verbose="true"/> <copy file="D:/hadoop-1.2.1/lib/commons-cli-${commons-cli.version}.jar" todir="${build.dir}/lib" verbose="true"/> <copy file="D:/hadoop-1.2.1/lib/commons-configuration-1.6.jar" todir="${build.dir}/lib" verbose="true"/><copy file="D:/hadoop-1.2.1/lib/commons-httpclient-3.0.1.jar" todir="${build.dir}/lib" verbose="true"/><copy file="D:/hadoop-1.2.1/lib/commons-lang-2.4.jar" todir="${build.dir}/lib" verbose="true"/><copy file="D:/hadoop-1.2.1/lib/jackson-core-asl-1.8.8.jar" todir="${build.dir}/lib" verbose="true"/><copy file="D:/hadoop-1.2.1/lib/jackson-mapper-asl-1.8.8.jar" todir="${build.dir}/lib" verbose="true"/><jarjarfile="${build.dir}/hadoop-${name}-${version}.jar"manifest="${root}/META-INF/MANIFEST.MF"><fileset dir="${build.dir}" includes="classes/ lib/"/><fileset dir="${root}" includes="resources/ plugin.xml"/></jar></target></project>修改D:\hadoop-1.2.1\src\contrib\eclipse-plugin\META-INF文件夹下的MANIFEST.MF文件(红色部分):Manifest-Version: 1.0Bundle-ManifestVersion: 2Bundle-Name: MapReduce Tools for EclipseBundle-SymbolicName: org.apache.hadoop.eclipse;singleton:=trueBundle-Version: 0.18Bundle-Activator: org.apache.hadoop.eclipse.ActivatorBundle-Localization: pluginRequire-Bundle: org.eclipse.ui,org.eclipse.core.runtime,unching,org.eclipse.debug.core,org.eclipse.jdt,org.eclipse.jdt.core,org.eclipse.core.resources,org.eclipse.ui.ide,org.eclipse.jdt.ui,org.eclipse.debug.ui,org.eclipse.jdt.debug.ui,org.eclipse.core.expressions,org.eclipse.ui.cheatsheets,org.eclipse.ui.console,org.eclipse.ui.navigator,org.eclipse.core.filesystem,mons.loggingEclipse-LazyStart: trueBundle-ClassPath: classes/,lib/hadoop-core.jar,lib/commons-cli-1.2.jar,lib/commons-configuration-1.6.jar,lib/commons-httpclient-3.0.1.jar,lib/commons-lang-2.4.jar,lib/jackson-core-asl-1.8.8.jar,lib/jackson-mapper-asl-1.8.8.jarBundle-Vendor: Apache Hadoop然后在cmd下进入到D:\hadoop-1.2.1\src\contrib\eclipse-plugin目录,运行ant:cd D:\hadoop-1.2.1\src\contrib\eclipse-pluginant jar完成后提示:然后在D:\hadoop-1.2.1\build\contrib\eclipse-plugin下会看到生成了文件hadoop-eclipse-plugin-1.2.1.jar,将其拷贝到eclipse安装目录下的plugins 的文件夹下(D:\eclipse-jee-luna-SR2-win32-x86_64\eclipse\plugins)然后启动eclipse可以看到插件已经有了然后配置我们的hadoop:Window-->Preferences-->Hadoop Map/Reduce填入hadoop本机上hadoop源码包解压所放的目录配置Hdfs位置:Windows -->Show View -->Other-->MapReduce Tools-->Map/Reduce Location然后在在Map/Reduce Location视图下New Hadoop Location填入hdfs地址及jobTracker端口和NameNode端口(很可惜的是这里的User name填hadoop或者其他说明值如果是window系统都不起作用,很是坑爹。
hadoop搭建与eclipse开发环境设置--已验证通过
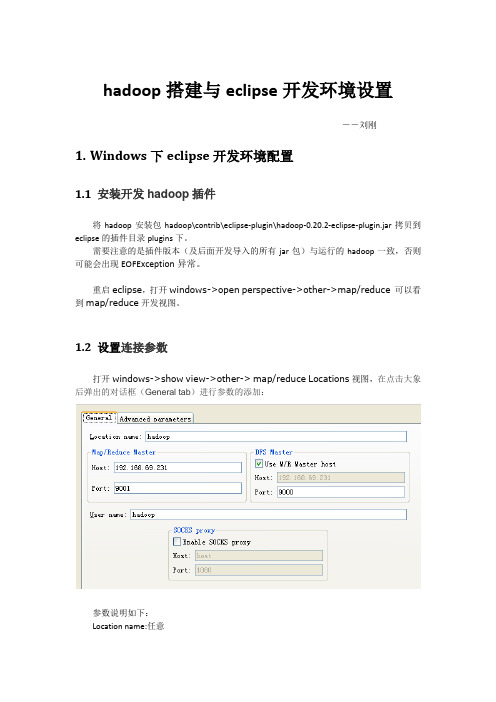
hadoop搭建与eclipse开发环境设置――刘刚1.Windows下eclipse开发环境配置1.1 安装开发hadoop插件将hadoop安装包hadoop\contrib\eclipse-plugin\hadoop-0.20.2-eclipse-plugin.jar拷贝到eclipse的插件目录plugins下。
需要注意的是插件版本(及后面开发导入的所有jar包)与运行的hadoop一致,否则可能会出现EOFException异常。
重启eclipse,打开windows->open perspective->other->map/reduce 可以看到map/reduce开发视图。
1.2 设置连接参数打开windows->show view->other-> map/reduce Locations视图,在点击大象后弹出的对话框(General tab)进行参数的添加:参数说明如下:Location name:任意map/reduce master:与mapred-site.xml里面mapred.job.tracker设置一致。
DFS master:与core-site.xml里设置一致。
User name: 服务器上运行hadoop服务的用户名。
然后是打开“Advanced parameters”设置面板,修改相应参数。
上面的参数填写以后,也会反映到这里相应的参数:主要关注下面几个参数::与core-site.xml里设置一致。
mapred.job.tracker:与mapred-site.xml里面mapred.job.tracker设置一致。
dfs.replication:与hdfs-site.xml里面的dfs.replication一致。
hadoop.tmp.dir:与core-site.xml里hadoop.tmp.dir设置一致。
hadoop.job.ugi:并不是设置用户名与密码。
一个hivehbasehdoop+eclipse的实例

hbase,hive,hadoop一个演示的例子。
1. 在终端上创建表;(hive)CREATE EXTERNAL TABLE MYRELATION(key INT, name STRING,telphone1 STRING,telphone2 STRING,telphone3 STRING,groups STRING,valid BOOLEAN)STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'WITH SERDEPROPERTIES("hbase.columns.mapping"=":key,fullname:name,tel:office,tel:home,tel:mobile,belo ngto:groups,isserved:valid")TBLPROPERTIES(""="relationship");CREATE TABLE RELATIONSHIP(key INT, name STRING,telphone1 STRING,telphone2 STRING,telphone3 STRING,groups STRING,valid BOOLEAN)STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'WITH SERDEPROPERTIES("hbase.columns.mapping"=":key,fullname:name,tel:office,tel:home,tel:mobile,belo ngto:groups,isserved:valid")TBLPROPERTIES(""="relationship");hive> CREATE TABLE RELATIONSHIP(> key INT, name STRING,telphone1 STRING,telphone2 STRING,telphone3 STRING,groups STRING,valid BOOLEAN)> STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'> WITH SERDEPROPERTIES("hbase.columns.mapping"=":key,fullname:name,tel:office,tel:home,tel:mobile,belongto:groups,isserved:valid")> TBLPROPERTIES(""="relationship");OKTime taken: 1.579 seconds///////////////////////////////////2. 在hbase 显示创建表hbase(main):012:0> describe 'relationship'DESCRIPTION ENABLEDTRUE{NAME => 'relationship', FAMILIES => [{NAME => 'belongto', BLOOMFILTER => 'NONE', REPLICATION_SCOPE => '0',COMPRESSION => 'NONE', VERSIONS => '3', TTL => '2147483647', BLOCKSIZE => '65536', IN_MEMORY => 'false', BLOCKCACHE =>'true'},{NAME => 'fullname', BLOOMFILTER => 'NONE', REPLICATION_SCOPE => '0',COMPRESSION => 'NONE', VERSIONS => '3', TTL => '2147483647', BLOCKSIZE =>'65536', IN_MEMORY => 'false', BLOCKCACHE => 'true'},{NAME => 'isserved', BLOOMFILTER => 'NONE', REPLICATION_SCOPE => '0',COMPRESSION => 'NONE', VERSIONS => '3',TTL => '2147483647', BLOCKSIZE => '65536', IN_MEMORY => 'false', BLOCKCACHE =>'true'},{NAME => 'tel', BLOOMFILTER =>'NONE', REPLICATION_SCOPE => '0', COMPRESSION =>'NONE', VERSIONS => '3', TTL => '2147483647', BLOCKSIZE => '65536', IN_MEMORY => 'false', BLOCKCACHE =>'true'}]}1 row(s) in 0.0330 seconds3. 写入数据(hbase)put 'relationship','002','fullname:name','fung'put 'relationship','002','tel:home','1234'put 'relationship','002','tel:office','22222'put 'relationship','002','tel:mobile','22222'put 'relationship','002','belongto:groups','students'put 'relationship','002','isserved:valid','true'4. (hbase)显示写入的结果hbase(main):022:0> get 'relationship','002'COLUMN CELLbelongto:groups timestamp=1351644542319, value=studentsfullname:name timestamp=1351644194862, value=fungisserved:valid timestamp=1351644710533, value=truetel:home timestamp=1351644515829, value=1234tel:mobile timestamp=1351644640471, value=22222tel:office timestamp=1351644523975, value=222226 row(s) in 0.0280 seconds5. (hive)显示写入的数据hive> select * from relationship;OK2 fung 22222 1234 22222 students trueTime taken: 0.229 seconds6. 程序(eclipse)/*** 显示所有数据*/public static void getAllData (String tablename) throws Exception{ Configuration hcfg = HBaseConfiguration.create();HTable table = new HTable(hcfg, tablename);Scan s = new Scan();ResultScanner ss = table.getScanner(s);for(Result r:ss){for(KeyValue kv:r.raw()){System.out.print(new String(kv.getFamily()));// System.out.print(new String(r.));System.out.println(new String(kv.getValue()));}}}问题:ng.NoClassDefFoundError: org/apache/zookeeper/KeeperException 原因:没有zookerper包,引入即可。
Linux环境下Hadoop+HBase在Eclipse中的编译打包步骤
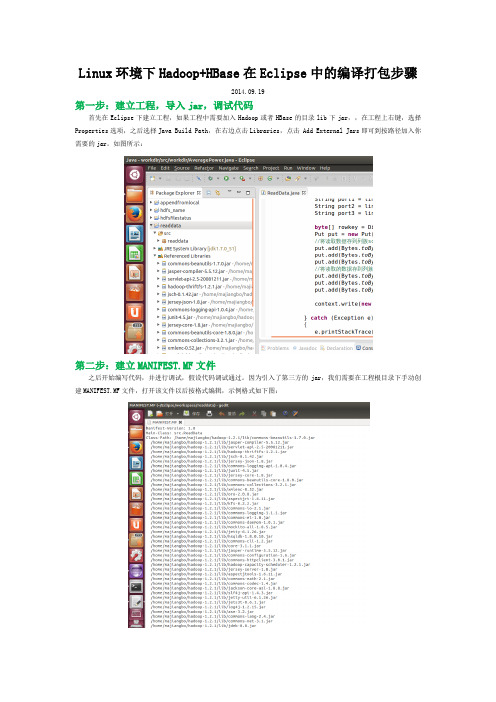
Linux环境下Hadoop+HBase在Eclipse中的编译打包步骤2014.09.19第一步:建立工程,导入jar,调试代码首先在Eclipse下建立工程,如果工程中需要加入Hadoop或者HBase的目录lib下jar,,在工程上右键,选择Properties选项,之后选择Java Build Path,在右边点击Libraries,点击 Add External Jars即可到按路径加入你需要的jar。
如图所示:第二步:建立MANIFEST.MF文件之后开始编写代码,并进行调试,假设代码调试通过。
因为引入了第三方的jar,我们需要在工程根目录下手动创建MANIFEST.MF文件,打开该文件以后按格式编辑,示例格式如下图:格式说明如下:●在MANIFEST.MF中,一般设置Manifest-Version: 1.0。
●其中Main-Class根据你的工程源码主类位置而定,比如在工程中,src下的package为readdata,代码中主类为ReadData,那么在Main-Class下就应该为Main-Class: readdata.ReadData。
●对于Class-Path,因为引用的jar很多,不可能一一手动输入,此时可以再全选这些jar,然后右键点击,弹出如下菜单,选择Copy Qualified Name之后复制到MANIFEST.MF文件的Class-Path下。
注意:在每个冒号后都要加一个空格,格式不对的话会报错invalid header field。
并且,如果Class-Path引入了过多的jar打包时会报错line too long,此时,在Class-Path的第二行开始,行首改为两个空格,第一行冒号后面仍为一个空格。
MANIFEST.MF编辑完毕后,在工程上右键,选择Refresh刷新一下,就能看到已经编辑完成的MANIFEST.MF 文件。
第三步:开始Export之后在左侧工程上右键,选择Export选项,弹出如下窗口:选择Java下的JAR file选项:点击Next下一步继续:勾选Export generated class files and resources以及Export Java source files and resources。
基于Eclipse的Hadoop应用开发环境配置

基于Eclipse的Hadoop应用开发环境配置我的开发环境:操作系统fedora 14 一个namenode 两个datanodeHadoop版本:hadoop-0.20.205.0Eclipse版本:eclipse-SDK-3.7.1-linux-gtk.tar.gz第一步:先启动hadoop守护进程第二步:在eclipse上安装hadoop插件1.复制 hadoop安装目录/contrib/eclipse-plugin/hadoop-eclipse-plugin-0.20.205.0.jar 到eclipse安装目录/plugins/ 下。
2.重启eclipse,配置hadoop installation directory。
如果安装插件成功,打开Window-->Preferens,你会发现Hadoop Map/Reduce 选项,在这个选项里你需要配置Hadoop installation directory。
配置完成后退出。
3.配置Map/Reduce Locations。
在Window-->Show View中打开Map/Reduce Locations。
在Map/Reduce Locations中新建一个Hadoop Location。
在这个View中,右键-->New Hadoop Location。
在弹出的对话框中你需要配置Location name,如Hadoop,还有Map/Reduce Master和DFS Master。
这里面的Host、Port分别为你在mapred-site.xml、core-site.xml中配置的地址及端口。
如:Map/Reduce Master192.168.1.1019001DFS Master192.168.1.1019000配置完后退出。
点击DFS Locations-->Hadoop如果能显示文件夹(2)说明配置正确,如果显示"拒绝连接",请检查你的配置。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Hadoop和HBase分布式配置及整合My Eclipse开发Q:620734263说明:本文档主要侧重hadoop和hbase在windows下的开发.在linux上开发自行修改即可.一、下载安装包下载hadoop-0.20.2、hbase-0.90.3及cygwin软件二、安装cygwin和配置sshcygwin的安装google一下就行.三、在主机配置ssh无密码连接在这里找两台主机(仅供测试用),master(192.168.169.121)和slaver1(192.168.169.34)分别在两台主机C:\WINDOWS\system32\drivers\etc\hosts配置如下:至此在master上ssh slaver1就行,第一次要输入密码,系统将slaver1加入到know_hosts 中.以后就不用输入四、配置hadoop现在master上配置如下:在/hadoop-0.20.2/conf/masters、slavers文件中加入主机:配置完成后将此copy到slaver1上去.为了输入简单: 配置环境变量:HADOOP_HOME = e:/hadoop-0.20.2五、启动测试机器如有节点启动不起来的情况:可以先stop-all.sh再删除临时文件/tmp和日志文件logs.再从新格式化节点,重新启动(start-all.sh)主机.六、配置HBaseHBase是什么?官网WIKI,英文看不懂,google翻译…先配置环境变量吧.HBASE_HOME = e:/habse-0.90.3接着取消/cygwin/etc/pofile的注释修改<property><name>hbase.rootdir</name> //如果是在单机下只保留这一项即可<value>hdfs://master:9001/hbase</value> //与hadoop中的core-site.xml配置一直</property><property><name>hbase.cluster.distributed</name><value>true</value></property><property><name>hbase.master</name><value>hdfs://master:60000</value></property><property><name>hbase.zookeeper.quorum</name><value>slaver1</value> //这里配置的主机说是单数,参考wiki </property><property><name>hbase.zookeeper.property.dataDir</name><value>/data/work/zookeeper</value></property>七、启动Hbase八、整合eclipse做开发将hadoop-0.20.2的/hadoop-0.20.2/contrib/eclipse-plugin/hadoop-0.20.2-eclipse-plugin.jar插件以link的方式集成到my eclipise中,具体的操作自己查看.如果有问题,请将my eclipse升级到8.0以后的重启my eclipse将会在右上放工程模式中看到蓝色__ __/ \~~~/ \,----( .. )/ \__ __//| (\ |(^ \ /___\ /\ |新建工程新建map和reduce类,以及M/R驱动类:一个Map/Reduce例子import java.io.IOException;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.*;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop.mapreduce.Mapper;import org.apache.hadoop.mapreduce.Reducer;import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;public class NewMaxTemperature {static class NewMaxTemperatureMapper extends Mapper<LongWritable, Text, Text, IntWritable> {// private static final int MISSING = 99;public void map(LongWritable key, Text value, Context context)throws IOException, InterruptedException {String line = value.toString();String year = line.substring(2, 6);int airTemperature;int startIndex = line.indexOf("+");int endIndex = line.indexOf(".");airTemperature = Integer.parseInt(line.substring(startIndex+1, endIndex));// String quality = line.substring(0, 2);// if (airTemperature !=MISSING && quality.matches("[00]")){context.write(new Text(year), new IntWritable(airTemperature));//}}}static class NewMaxTemperatureReducer extends Reducer<Text, IntWritable, Text, IntWritable> {public void reduce(Text key, Iterable<IntWritable> values, Context context)throws IOException, InterruptedException {int maxValue = Integer.MIN_V ALUE;for (IntWritable value : values) {maxValue = Math.max(maxValue, value.get());}context.write(key, new IntWritable(maxValue));}}public static void main(String[] args) throws Exception {if (args.length != 2) {System.err.println("Usage: NewMaxTemperature <input path><output path>");System.exit(-1);}Job job = new Job();job.setJarByClass(NewMaxTemperature.class);FileInputFormat.addInputPath(job, new Path("/user/Administrator/input"));FileOutputFormat.setOutputPath(job, new Path("/user/Administrator/output"));job.setMapperClass(NewMaxTemperatureMapper.class);job.setReducerClass(NewMaxTemperatureReducer.class);job.setOutputKeyClass(Text.class);job.setOutputValueClass(IntWritable.class);System.exit(job.waitForCompletion(true) ? 0 : 1);}}一个HBASE的例子:import java.io.IOException;import java.util.ArrayList;import java.util.List;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.hbase.HBaseConfiguration;import org.apache.hadoop.hbase.HColumnDescriptor;import org.apache.hadoop.hbase.HTableDescriptor;import org.apache.hadoop.hbase.KeyValue;import org.apache.hadoop.hbase.MasterNotRunningException;import org.apache.hadoop.hbase.ZooKeeperConnectionException;import org.apache.hadoop.hbase.client.Delete;import org.apache.hadoop.hbase.client.Get;import org.apache.hadoop.hbase.client.HBaseAdmin;import org.apache.hadoop.hbase.client.HTable;import org.apache.hadoop.hbase.client.Put;import org.apache.hadoop.hbase.client.Result;import org.apache.hadoop.hbase.client.ResultScanner;import org.apache.hadoop.hbase.client.Scan;import org.apache.hadoop.hbase.util.Bytes;public class TestHbase {private static Configuration conf = HBaseConfiguration.create();public void putData(){try {HTable table = new HTable(conf,"test");Put put = new Put(Bytes.toBytes("rows1"));put.add(Bytes.toBytes("id"), Bytes.toBytes("0"), Bytes.toBytes("feng"));table.put(put);} catch (IOException e) {e.printStackTrace();}}public void putData1(){try {HTable table = new HTable(conf,"test");String[] columns = new String[]{"id","age","name"};for(int i=0;i<columns.length;i++){Put put = new Put(Bytes.toBytes("rows"+(i+1)));for(int j=0;j<3;j++){put.add(Bytes.toBytes(columns[j]), Bytes.toBytes(String.valueOf(i)), Bytes.toBytes("n_"+i));table.put(put);}}} catch (IOException e) {e.printStackTrace();}}public void createTable() throws IOException{String tablename = "test";String[] columns = new String[]{"id","age","name"};HBaseAdmin admin = new HBaseAdmin(conf);if (admin.tableExists(tablename)) {System.out.println("表已存在");}else{HTableDescriptor tableDesc = new HTableDescriptor(tablename);for(int i=0;i<columns.length;i++){tableDesc.addFamily(new HColumnDescriptor(columns[i]));}admin.createTable(tableDesc);System.out.println("创建表成功!.");}}public void delete() throws IOException{try {HBaseAdmin admin = new HBaseAdmin(conf);admin.disableTable("scores");admin.deleteTable("scores");System.out.println("表删除成功!");} catch (MasterNotRunningException e) {e.printStackTrace();} catch (ZooKeeperConnectionException e) {e.printStackTrace();}}public void scaner(){try {HTable table = new HTable(conf, "test");Scan s = new Scan();ResultScanner rs = table.getScanner(s);for(Result r:rs){// System.out.println(new String(r.getRow()));// byte[] b = r.getValue(Bytes.toBytes("cf"), Bytes.toBytes("c")); // if(b!=null){// System.out.println(new String(b));// }KeyValue[] kv = r.raw();for(int i=0;i<kv.length;i++){System.out.print(new String(kv[i].getRow())+" ");System.out.print(new String(kv[i].getFamily())+":");System.out.print(new String(kv[i].getQualifier())+" ");System.out.print(kv[i].getTimestamp()+" ");System.out.println(new String(kv[i].getValue()));}}} catch (IOException e) {e.printStackTrace();}}//scan 'test', {COLUMNS => ['id'], CACHE_BLOCKS => false}public void getFamily(){try {HTable table = new HTable(conf, "test");Get get = new Get(Bytes.toBytes("rows1"));Result r = table.get(get);byte[] b = r.getValue(Bytes.toBytes("id"), Bytes.toBytes(1));if(b==null){System.out.println("值不存在!检查簇是不是存在");return;}else{System.out.println(new String(b));}} catch (IOException e) {e.printStackTrace();}}/** 删除某一行数据* */public void deleteRow() throws IOException{HTable table = new HTable(conf, "test");List<Delete> list = new ArrayList<Delete>();Delete d1 = new Delete("rows2".getBytes());list.add(d1);table.delete(list);控制台输出:11/06/26 15:30:16 DEBUG catalog.CatalogTracker: Stopping catalog trackerorg.apache.hadoop.hbase.catalog.CatalogTracker@178460d11/06/26 15:30:16 DEBUG client.HConnectionManager$HConnectionImplementation: Lookedup root region location,connection=org.apache.hadoop.hbase.client.HConnectionManager$HConnectionImpl ementation@2bd3a; hsa=slaver1:6002011/06/26 15:30:16 DEBUG client.HConnectionManager$HConnectionImplementation: Cached location for .META.,,1.1028785192 is slaver1:6002011/06/26 15:30:16 DEBUG client.MetaScanner: Scanning .META. starting atrow=test,,00000000000000 for max=10 rows11/06/26 15:30:16 DEBUG client.HConnectionManager$HConnectionImplementation: Cached location for test,,1309073416281.9e47124da6d9845efd91385ba73c18ee. is slaver1:60020创建表成功!11/06/26 15:30:16 INFO zookeeper.ZooKeeper: Initiating client connection, connectString=192.168.169.34:2181 sessionTimeout=180000 watcher=hconnection11/06/26 15:30:16 INFO zookeeper.ClientCnxn: Opening socket connection to server /192.168.169.34:218111/06/26 15:30:16 INFO zookeeper.ClientCnxn: Socket connection established to slaver1/192.168.169.34:2181, initiating session11/06/26 15:30:16 INFO zookeeper.ClientCnxn: Session establishment complete on server slaver1/192.168.169.34:2181, sessionid = 0x1314670b4d70005, negotiated timeout = 18000011/06/26 15:30:16 DEBUG client.HConnectionManager$HConnectionImplementation: Lookedup root region location,connection=org.apache.hadoop.hbase.client.HConnectionManager$HConnectionImpl ementation@b1aebf; hsa=slaver1:6002011/06/26 15:30:16 DEBUG client.HConnectionManager$HConnectionImplementation: Cached location for .META.,,1.1028785192 is slaver1:6002011/06/26 15:30:16 DEBUG client.MetaScanner: Scanning .META. starting at。