《多元统计分析》第三版例题习题数据文件
多元统计分析第二章部分课后习题

第二章课后习题1.现选取内蒙古、广西、贵州、云南、西藏、宁夏、新疆、甘肃和青海等9个内陆边远省区。
选取人均GDP、第三产业比重、人均消费支出、人口自然增长率及文盲半文盲人口占15岁以上人口等五项能够较好的说明各地区社会经济发展水平的指标,验证一下边远及少数民族聚居区的社会经济发展水平与全国平均水平有无显著差异。
边远及少数民族聚居区社会经济发展水平的指标数据地区人均GDP(元)三产比重(%)人均消费(元)人口增长(%)文盲半文盲(%)内蒙古506831.121418.2315.83广西407634.220409.0113.32贵州234229.8155114.2628.98云南435531.3205912.125.48西藏371643.5155115.957.97宁夏427037.3194713.0825.56新疆622935.4 274512.8111.44甘肃345632.8161210.0428.65青海436740.9204714.4842.92资料来源:《中国统计年鉴(1998)》,北京,中国统计出版社,1998。
五项指标的全国平均水平为:)15.789.5297232.8701.6212(0'=μ解:(1)先利用SPSS软件检验各变量是否遵从多元正态分布(见输出结果1-1)输出结果1-1正态性检验Kolmogorov-Smirnov a Shapiro-Wilk统计量Df Sig. 统计量df Sig.人均GDP .219 9 .200*.958 9 .781 三产比重.145 9 .200*.925 9 .437 人均消费.209 9 .200*.873 9 .131 人口增长.150 9 .200*.949 9 .682 文盲半文盲.246 9 .124 .898 9 .242 *. 这是真实显著水平的下限。
a. Lilliefors 显著水平修正上表给出了对每一个变量进行正态性检验的结果,因为该例中样本数n=9,所以此处选用Shapiro-Wilk 统计量。
多元统计上机练习及答案(附数据)

均值协方差估计1.通过SPSS将产业数据命名:V1:第一产业;V2:第二产业;V3:第三产业。
2. 求X=(V1,V2,V3)’的均值向量估计(给出SPSS的相关输出表格及结果)。
通过SPSS从表1中得知所求向量的样本均值为(554.0797, 2142.4481, 1675.703)‘。
3. 求D(X)的估计量(给出SPSS的相关输出表格及结果)。
通过SPSS的相关中的双变量模块,得到如下输出表格。
通过表2得知随机向量的样本协差阵为:4.根据Pearson相关系数,试判断三个产业中,哪两个产业的相关性最高?通过表2得知,V2与V3的Pearson相关系数为0.968,即第二产业与第三产业相关程度最高。
均值向量比较及方差分析数据描述:数据中给出了不同民族(1,2,3)、城乡(1,2)居民的收入及文化程度信息,试根据数据回答以下问题。
1.就城乡居民来讲,收入及文化收入服从二元正态分布吗(为什么,请列明理由)?服从二维正态分布。
2.城乡的居民收入及文化程度存在着差异吗?(请通过均值向量检验作出回答,要求写明假设检验,检验统计的选择及依据,检验结果及依据。
)表2:Box's 共變異數矩陣等式檢定aBox's M 共變異等式檢定.112F .034df1 3df2 87120.000顯著性.992檢定因變數的觀察到的共變異數矩陣在群組內相等的空假設。
a. 設計:截距 + 城乡城乡的居民收入及文化程度不存在着差异。
3. 该数据适合通过方差分析来比较不同民族的收入及文化程度差异吗(请列明理由及依据【正态性及方差齐性检验】)。
表5:Box's 共變異數矩陣等式檢定aBox's M 共變異等式檢定2.354F .338df1 6df2 10991.077顯著性.917檢定因變數的觀察到的共變異數矩陣在群組內相等的空假設。
a. 設計:截距 + 民族数据通过了正态性及方差齐性检验,所以该数据适合通过方差分析来比较不同民族的收入及文化程度差异.4. 如果该数据适合做方差分析,初步的检验结果是什么?需要进一步做两两比较吗?表6:多變數檢定a效果數值 F 假設 df 錯誤 df 顯著性截距Pillai's 追蹤.995 2046.322b 2.000 20.000 .000Wilks' Lambda.005 2046.322b 2.000 20.000 .000 (λ)Hotelling's 追蹤 204.632 2046.322b 2.000 20.000 .000Roy's 最大根204.632 2046.322b 2.000 20.000 .000 民族Pillai's 追蹤.898 8.561 4.000 42.000 .000Wilks' Lambda.103 21.166b 4.000 40.000 .000 (λ)Hotelling's 追蹤 8.702 41.332 4.000 38.000 .000Roy's 最大根8.700 91.352c 2.000 21.000 .000a. 設計:截距 + 民族b. 確切的統計資料c. 統計資料是 F 的上限,其會產生顯著層次上的下限。
多元统计分析基础练习题参考答案

注意:基本格式和前面罗老师的要求一致,这是统计分析的基本格式。
表格最好用三线表,不用也行,但基本格式要规范,不能把软件里的表格直接copy 过来!下面参考答案,大家主要看一下,要如何分析数据,格式上,我没太多时间规范排版,很多直接从软件中copy 过来的,这不规范!不要学!求:(1)人均GDP 作自变量,人均消费水平作因变量,绘制散点图,并说明二者之间的关系形态。
(2)计算两个变量之间的线性相关系数,说明两个变量之间的关系强度。
(3)求出估计的回归方程,并解释回归系数的实际意义。
(4)计算判定系数,并解释其意义。
(5)检验回归方程线性关系的显著性(0.05α=)。
(6)如果某地区的人均GDP 为5000元,预测其人均消费水平。
(7)求人均GDP 为5000元时,人均消费水平95%的置信区间和预测区间。
解:(1)可能存在线性关系。
(2)相关系数:有很强的线性关系。
(3)回归方程:734.6930.309y x=+回归系数的含义:人均GDP没增加1元,人均消费增加0.309元。
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% 注意:图标不要原封不动的完全复制软件中的图标,要按规范排版。
表1 回归系数模型非标准化系数标准化系数t 显著性B 标准误Beta1 (常量)734.693 139.540 5.265 0.003人均GDP(元)0.309 0.008 0.998 36.492 0.000 a. 因变量: 人均消费水平(元)%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%(4)模型汇总模型R R 方调整 R 方标准估计的误差1 .998a.996 .996 247.303a. 预测变量: (常量), 人均GDP。
人均GDP对人均消费的影响达到99.6%。
(5)F 检验:734.6930.30950002278.693y =+⨯=(元)。
《多元统计分析》习题

《多元统计分析》习题分为三部分:思考题、验证题和论文题思考题第一章绪论1﹑什么是多元统计分析?2﹑多元统计分析能解决哪些类型的实际问题?第二章聚类分析1﹑简述系统聚类法的基本思路。
2﹑写出样品间相关系数公式。
3﹑常用的距离及相似系数有哪些?它们各有什么特点?4﹑利用谱系图分类应注意哪些问题?5﹑在SAS和SPSS中如何实现系统聚类分析?第三章判别分析1﹑简述距离判别法的基本思路,图示其几何意义。
2﹑判别分析与聚类分析有何异同?3﹑简述贝叶斯判别的基本思路。
4﹑简述费歇判别的基本思路。
5﹑简述逐步判别法的基本思想。
6﹑在SAS和SPSS软件中如何实现判别分析?第四章主成分分析1﹑主成分分析的几何意义是什么?2﹑主成分分析的主要作用有那些?3﹑什么是贡献率和累计贡献率,其意义何在?4﹑为什么说贡献率和累计贡献率能反映主成分中所包含的原始变量的信息?5﹑为什么要用标准化数据去估计V的特征向量与特征值?6﹑证明:对于标准化数据有S=R。
7﹑主成分分析在SAS和SPSS中如何实现?第五章因子分析1﹑因子得分模型与主成分分析模型有何不同?2﹑因子载荷阵的统计意义是什么?3﹑方差旋转的目的是什么?4﹑因子分析有何作用?5﹑因子模型与回归模型有何不同?6﹑在SAS和SPSS中如何实现因子分析?第六章对应分析1﹑简述对应分析的基本思想。
2﹑简述对应分析的基本原理。
3﹑简述因子分析中Q型与R 型的对应关系。
4﹑对应分析如何在SAS和SPSS中实现?第七章典型相关分析1﹑典型相关分析适合分析何种类型的数据?2﹑简述典型相关分析的基本思想。
3﹑典型变量有哪些性质?4﹑典型相关系数和典型变量有何意义?5﹑典型相关分析有何作用?6 ﹑在SAS和SPSS中如何实现典型相关分析?验证题第二章聚类分析1、为了更深入了解我国人口的文化程度,现利用1990年全国人口普查数据对全国30个省、直辖市、自治区进行聚类分析。
分析选用了三个指标:(1)大学以上文化程度的人口占全部人口的比例(DXBZ);(2)初中文化程度的人都占全部人口的比例(CZBZ);(3)文盲半文盲人口占全部人口的比例(WMBZ),分别用来反映较高、中等、较低文化程度人口的状况。
多元统计分析 第三章 习题

因子分析作业
一家公司正试图对其销售员工的质量做评估,并且正寻找一种考察或一系列测试,以期可以解释是否有创造良好销售额的潜能。
该公司已挑选了50个销售人员的随机样本,还已对每一个人就3项表现作了评估,销售增长、销售利润和新客户销售额。
这些测度量已被变为同一尺度,其中100表示“平均业绩”。
50个人中的每一个接受4项测试,分别测量创造力、机械推理、抽象推理和数学能力。
(数据见练习9.19)
a、假设对标准化变量有正交因子模型,求m=2和m=3个公因子的主成分解或极大似然解。
b、由a的解,求m=2和m=3的旋转载荷,解释m=2和m=3的因子解。
c、列出m=2和m=3的共同度和特殊方差,比较这些结果,此时你更愿意选择m 等于什么值,为什么?
d、设随机选取一个新的销售人员,得到测验分数)
,
,
110
98
'
x,用
105
(
,
20
35
,
18
15
,
,
加权最小二乘法和回归方法,计算这个销售人员的因子得分。
多元统计分析笔记附实例

多元统计分析笔记附实例1.主成分分析,因⼦分析,对应分析可以⽤来简化数据结构⼜不会损失太多信息2.聚类分析和判别分析是对所考察的变量按相似程度进⾏分类。
3.回归分析⽤来判断⼀些变量的变化是不是依赖于另外⼀些变量的变化,如果是,建⽴变量之间的定量关系式,并⽤于预测4.典型相关分析⽤来分析两组变量之间的相互关系5.多元数据的统计推断参数估计假设检验6.参数估计:⽤样本值估计总体X中的某些参数。
点估计:区间估计:7.数学期望的置信区间分为⽅差已知和⽅差未知置信区间:估计参数的取值范围8.假设检验:对总体的分布律或分布参数作某种假设,根据抽样得到的值,俩判断假设是否成⽴。
9.假设检验分为参数检验和⾮参数检验。
参数检验是在总体分布类型已经知道情况下进⾏的,其⽬的是对总体的参数及其有关性质做出明确判断。
⾮参数检验这是总体分布类型未知的情况下进⾏的检验10.相关系数是⽤来描述两个变量间的线性相关程度的。
简单线性相关系数:Pearson11.标准化:(1)min-max标准化对原始数据进⾏线性变换适⽤于最⼤值和最⼩值已知⽬的是把所有制映射到[0,1] 区间。
(2)Z-zcore 标准化适⽤于最⼤值和最⼩值未知,或者超出取值范围的离群数据的值。
12. 聚类分析:分析-----分类—系统聚类---检验聚类分析显著性:/doc/f89672b26294dd88d0d26b9a.html/article/e8cdb32b7a2daf37052bade5.html⽤SPSS做相关分析的应⽤⽰例【例】表1是某市从1978年⾄1992年社会商品零售总额、居民收⼊和全市总⼈⼝统计数字表,试分析它们之间是否存在线性关系。
表1某市统计表第⼀步:建⽴数据⽂件。
定义变量:序号为Number,假设年份⽤y表⽰,零售总额⽤r表⽰,居民收⼊⽤i表⽰,全市总⼈⼝⽤p表⽰,输⼊数据,如下截图⽰:第⼆步:进⾏数据分析。
在数据⽂件管理窗⼝中,点击Analyze,展开下拉菜单,再点击Correlate中的Bivariate项,进⼊Bivariate Correlations对话框,请童鞋们看下图:(1)在左边的这个东东为源变量列框,右边的Variables框为待分析的变量列框,就是这个东东:(2)再看下边的Correlation Coefficients选项,也就是分析⽅法选择项,就是这个东东。
多元统计分析课后练习答案

多元统计分析课后练习答案第1章多元正态分布1、在数据处理时,为什么通常要进行标准化处理?数据的标准化是将数据按比例缩放,使之落入一个小的特定区间。
在某些比较和评价的指标处理中经常会用到,去除数据的单位限制,将其转化为无量纲的纯数值,便于不同单位或量级的指标能够进行比较和加权。
其中最典型的就是0-1标准化和Z 标准化。
2、欧氏距离与马氏距离的优缺点是什么?欧氏距离也称欧几里得度量、欧几里得度量,是一个通常采用的距离定义,它是在m 维空间中两个点之间的真实距离。
在二维和三维空间中的欧氏距离的就是两点之间的距离。
缺点:就大部分统计问题而言,欧氏距离是不能令人满意的。
每个坐标对欧氏距离的贡献是同等的。
当坐标表示测量值时,它们往往带有大小不等的随机波动,在这种情况下,合理的方法是对坐标加权,使变化较大的坐标比变化较小的坐标有较小的权系数,这就产生了各种距离。
当各个分量为不同性质的量时,“距离”的大小与指标的单位有关。
它将样品的不同属性之间的差别等同看待,这一点有时不能满足实际要求。
没有考虑到总体变异对距离远近的影响。
马氏距离表示数据的协方差距离。
为两个服从同一分布并且其协方差矩阵为Σ的随机变量与的差异程度:如果协方差矩阵为单位矩阵,那么马氏距离就简化为欧氏距离,如果协方差矩阵为对角阵,则其也可称为正规化的欧氏距离。
优点:它不受量纲的影响,两点之间的马氏距离与原始数据的测量单位无关。
由标准化数据和中心化数据计算出的二点之间的马氏距离相同。
马氏距离还可以排除变量之间的相关性的干扰。
缺点:夸大了变化微小的变量的作用。
受协方差矩阵不稳定的影响,马氏距离并不总是能顺利计算出。
3、当变量X1和X2方向上的变差相等,且与互相独立时,采用欧氏距离与统计距离是否一致?统计距离区别于欧式距离,此距离要依赖样本的方差和协方差,能够体现各变量在变差大小上的不同,以及优势存在的相关性,还要求距离与各变量所用的单位无关。
如果各变量之间相互独立,即观测变量的协方差矩阵是对角矩阵, 则马氏距离就退化为用各个观测指标的标准差的倒数作为权数的加权欧氏距离。
多元统计练习题.doc
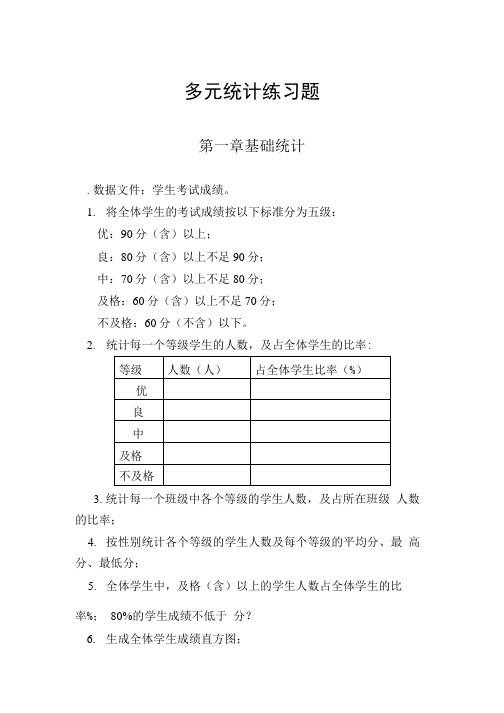
多元统计练习题第一章基础统计.数据文件:学生考试成绩。
1.将全体学生的考试成绩按以下标准分为五级:优:90分(含)以上;良:80分(含)以上不足90分;中:70分(含)以上不足80分;及格:60分(含)以上不足70分;不及格:60分(不含)以下。
2.统计每一个等级学生的人数,及占全体学生的比率:3.统计每一个班级中各个等级的学生人数,及占所在班级人数的比率;4.按性别统计各个等级的学生人数及每个等级的平均分、最高分、最低分;5.全体学生中,及格(含)以上的学生人数占全体学生的比率%;80%的学生成绩不低于分?6.生成全体学生成绩直方图;7.用P-P图或Q-Q图观察学生成绩是否来自正态分布。
并结合下一道题(8)的结果来看用P-P图或Q-Q图观察分布的局限性。
8.用K-S检验法,以0.05显著性水平,检验全体学生成绩是否来自正态总体(n或y),检验统计量值z=, 它对应的水平(近似)值Asymp. Sig =。
如果是0.1的显著性水平呢?二.数据文件:公司职工。
1.填表:2.填表:3.对全体职工按年龄(age)分组,标准如下:第1组,青年:age<35;第2 组,中年:35<age<60;第3组,老年:ageN60.填表:4.的%;中年女职工的人数为人,占全体女职工人数的%。
5.中年男办事员的平均当前薪金(salary)为元,他们中的最低受教育年限(educ)是年。
7.该公司80%的员工当前薪金(salary)不低于元。
8.如果把本文件数据看成某个正态总体的样本,试在0.05的显著性水平下检验:1)不同性别职工的平均受教育年限(educ)有无显著差异?(填y或n);检验统计量值t=,显著性值Sig.=。
2)青年职工与中年职工的平均当前薪金(salary)有无显著差异?(填y或n);检验统计量值t=,显著性值Sig.=。
3 )老、中、青三部分人平均受教育年限(educ)分别是:老年人年,中年人年,青年人年。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
何晓群《多元统计分析》第三版(2012)数据下载第2章[例2-1] 1999年财政部、国家经贸委、人事部和国家计委联合发布了《国有资本金效绩评价规则》。
其中,对竞争性工商企业的评价指标体系包括下面八大基本指标:净资产收益率、总资产报酬率、总资产周转率、流动资产周转率、资产负债率、已获利息倍数、销售增长率和资本积累率。
下面我们借助于这一指标体系对我国上市公司的运营情况进行分析,以下数据为35家上市公司2008年年报数据,这35家上市公司分别来自于电力、煤气及水的生产和供应业,房地行业,信息技术业,在后面各章中也经常以该数据为例进行分析。
习题3.今选取内蒙古、广西、贵州、云南、西藏、宁夏、新疆、甘肃和青海等9个内陆边远省份。
选取人均GDP、第三产业比重、人均消费支出、人口自然增长率及文盲半文盲人口占15岁以上人口的比例等五项能够较好的说明各地区社会经济发展水平的指标。
验证一下边远及少数民族聚居区的社会经济水平与全国平均水平有无显著差异。
数据来源:《中国统计年鉴》(1998)。
5项指标的全国平均水平μ0=(6212.01 32.87 2972 9.5 15.78)/第3章例3-1 若我们需要将下列11户城镇居民按户主个人的收入进行分类,对每户作了如下的统计,结果列于表3-1。
在表中,“标准工资收入”、“职工奖金”、“职工津贴”、“性别”、“就业身份”等称为指标,每户称为样品。
若对户主进行分类,还可以采用其他指标,如“子女个数”、“政治面貌”等,指标如何选择取决于聚类的目的。
表3-1 某市2001年城镇居民户主个人收入数据X1 职工标准工资收入 X5 单位得到的其他收入X2 职工奖金收入 X6 其他收入X3 职工津贴收入 X7 性别X4 其他工资性收入 X8 就业身份X1 X2 X3 X4 X5 X6 X7 X8 540.00 0.0 0.0 0.0 0.0 6.00 男国有1137.00 125.00 96.00 0.0 109.00 812.00 女集体1236.00 300.00 270.00 0.0 102.00 318.00 女国有1008.00 0.0 96.00 0.0 86.0 246.00 男集体1723.00 419.00 400.00 0.0 122.00 312.00 男国有1080.00 569.00 147.00 156.00 210.00 318.00 男集体1326.00 0.0 300.00 0.0 148.00 312.00 女国有1110.00 110.00 96.00 0.0 80.00 193.00 女集体1012.00 88.00 298.00 0.0 79.00 278.00 女国有1209.00 102.00 179.00 67.00 198.00 514.00 男集体1101.00 215.00 201.00 39.00 146.00 477.00 男集体例3-3English Norwegian Danish Dutch German FrenchOne En en een ein unTwo To to twee zwei deuxThree Tre tre drie drei troisFour Fire fire vier vier quatreFive Fem fem vijf funf einqSix Seks seks zes sechs sixseven Sju syv zeven siebcn septEight Ate otte acht acht huitNine Ni ni negen neun neufTen Ti ti tien zehn dixSpanish Italian Polish Hungarian FinnishUno uno jeden egy yksiDos due dwa ketto kaksiTres tre trzy harom kolmecuatro quattro cztery negy neuaCinco cinque piec ot viisiSeix sei szesc hat kuusiSiete sette siedem het seitsemanOcho otto osiem nyolc kahdeksaunueve nove dziewiec kilenc yhdeksanDiez dieci dziesiec tiz kymmenen例3-4X1 食品支出(元/人)X5 交通和通讯支出(元/人)X2 衣着支出(元/人)X6 娱乐、教育和文化服务支出(元/人)X3 家庭设备、用品及服务支出(元/人)X7 居住支出(元/人)X4 医疗保健支出(元/人)X8 杂项商品和服务支出(元/人)X1 X2 X3 X4 X5 X6 X7 X8 辽宁1772.14 568.25 298.66 352.20 307.21 490.83 364.28 202.50 浙江2752.25 569.95 662.31 541.06 623.05 917.23 599.98 354.39 河南1386.76 460.99 312.97 280.78 246.24 407.26 547.19 188.52 甘肃1552.77 517.16 402.03 272.44 265.29 563.10 302.27 251.41 青海1711.03 458.57 334.91 307.24 297.72 495.34 274.48 306.45例3-5x1 人均粮食支出(元/人) x5 人均衣着支出(元/人)x2 人均副食支出(元/人)x6 人均日用杂品支出(元/人)x3 人均烟、酒、饮料支出(元/人)x7 人均水电燃料支出(元/人)x4 人均其他副食支出(元/人)x8 人均其他非商品支出(元/人)第4章[例4-1] 判别分析的一个重要应用是用于动植物的分类当中,最著名的一个例子是1936年Fisher的鸢尾花数据(Iris Data)。
鸢尾花为法国的国花,Setosa、Versicolour、Virginica是三种有名的鸢尾花,其萼片是绚丽多彩的,和向上的花瓣不同,花萼是下垂的。
这三种鸢尾花很像,人们试图建立模型,根据萼片和花瓣的四个度量来把鸢尾花分类。
该数据给出150个鸢尾花的萼片长(sepal length)、萼片宽(sepal width)、花瓣长(petal length)、花瓣宽(petal width)以及这些花分别属于的种类(Species)等共五个变量。
萼片和花瓣的长宽为四个定量变量,而种类为分类变量(取三个值Setosa、Versicolour、Virginica)。
这里三种鸢尾花各有50个观测值。
数据格式如下图所示:定义新的变量y为被解释变量,用“1”代表Setosa鸢尾花,用“2”代表V ersicolour鸢尾花,用“3”代表Virginica鸢尾花,将萼片长(sepal length)、萼片宽(sepal width)、花瓣长(petal length)和花瓣宽(petal width)四个变量作为解释变量。
使用SPSS软件中的Analyze→Classify→Discriminant,就进入了判别分析的对话框。
分组变量(Grouping Variable)选择y,然后定义y的区域,最小值是1,最大值是3。
解释变量(Independents)选择sepal.length、sepal.width、petal.length和petal.width。
统计量(Statistics)选项中选择描述统计量Means,Univariate ANOV As和Box’M ,函数选择Fisher和非标准化函数,矩阵选择Within-groups correlation。
分类(Classify)选项中选择先验概率(所有组相等或根据组的大小计算概率),因为三个品种的都是50种,因此两种选择的效果一样,子选项显示(display)中选择每个个体的结果(Casewise results),综合表(Summery Table)和“留一个在外”(Leave-one-out classifation)的验证原则,协方差矩阵选择Within-groups,作图选择Combined-groups。
保存(Save)选项中可以选择预测的分类、判别得分以及所属类别的概率。
如果采用逐步判别法,我们还可以选择判别的方法(Method)。
得到分析结果如下:输出结果4-1Discriminant(1)输出结果4-1分析的是各组的描述统计量和对各组均值是否相等的检验。
第1张表反映的是有效样本量及变量缺失的情况。
第2张表是各组变量的描述统计分析。
第3张表是对各组均值是否相等的检验。
由第3张表可以看出,在0.01的显著性水平上我们拒绝变量萼片长(sepal length)、萼片宽(sepal width)、花瓣长(petal length)和花瓣宽(petal width)在三组的均值相等的假设,即认为变量萼片长(sepal length)、萼片宽(sepal width)、花瓣长(petal length)和花瓣宽(petal width)在三组的均值是有显著性差异的。
输出结果4-2Box's Test of Equality of Covariance Matrices输出结果4-2是对各组协方差矩阵是否相等的Box’M 检验。
第1张表反映协方差矩阵的秩和行列式的对数值。
由行列式值可以看出协方差矩阵不是病态矩阵。
第2张表是对各总体协方差阵是否相等的统计检验。
由F 值及其显著水平,我们在0.05的显著性水平下拒绝原假设(原假设假定各总体协方差阵相等)。
因此,在分类(Classify)选项中的协方差矩阵选择可以考虑采用Separate-groups ,以检验采用Within-groups 和Separate-groups 两种协方差所得出的结果是否存在显著差异。
如果存在显著差异就应该采用Separate-groups 协方差矩阵,反之,就用Within-groups 协方差矩阵。
输出结果4-3Summary of Canonical Discriminant Functions(1)输出结果4-3分析的是典型判别函数。
第1张表反映判别函数的特征值、解释方差的比例和典型相关系数。
第一判别函数解释了99.1%的方差,第二判别函数解释了0.9%的方差,两个判别函数解释了全部方差。
第2张表是对两个判别函数的显著性检验。
由Wilks’ Lambda 检验,认为两个判别函数在0.05的显著性水平上是显著的。