分布式存储系统技术说明
分布式存储技术原理

分布式存储技术原理
分布式存储技术是一种将数据在多台独立的存储设备上分散存储的技术。
它主要通过将数据分割成较小的块,并将它们存储在不同的物理设备或节点上,以提高存储系统的性能、可靠性和可扩展性。
分布式存储技术的原理基于以下几个关键概念:
1. 数据分区:将数据切分成较小的块,并为每个块分配一个唯一的标识符。
这样做的目的是将数据分散到不同的存储节点上,以便提高并行处理的能力和系统的容错性。
2. 数据复制:为了增加数据的可靠性和可用性,分布式存储系统通常会对数据块进行多次复制,并将它们存储在不同的节点上。
这样,即使某个节点发生故障或网络中断,系统仍然可以从其他可用的副本中获取数据。
3. 数据一致性:在分布式存储系统中,由于数据块可能存在多个副本,节点之间必须保持数据的一致性。
这通常通过使用一致性协议(如Paxos或Raft)来实现,以确保所有节点上的数
据副本都是最新的。
4. 数据访问:分布式存储系统通常提供不同的访问接口,如块存储、文件系统或对象存储。
这些接口允许应用程序以各种方式访问和管理存储的数据。
5. 节点管理:分布式存储系统需要一种机制来管理存储节点的
加入和离开。
这包括节点的自动发现、负载均衡、数据迁移和故障恢复等功能。
总的来说,分布式存储技术通过将数据切分、复制和分散存储在多个节点上,以提高系统的性能、可用性和可扩展性。
通过使用一致性协议和节点管理机制,它还可以确保数据的一致性和容错性。
这些原理为现代大规模数据存储和处理系统提供了基础。
大数据存储的三种路径

大数据存储的三种路径1.引言1.1 概述大数据存储是指存储和管理大规模数据的技术和方法。
随着大数据应用的广泛普及,数据量的快速增长给传统的存储方式带来了巨大的挑战。
为了高效地存储和处理大规模数据,人们提出了不同的存储路径。
本文将介绍三种主要的大数据存储路径,并分析它们的特点和适用场景。
第一种路径是分布式文件系统存储。
分布式文件系统是一种将数据分散存储在多个独立节点上的系统,可以提供高可靠性和高性能的数据存储服务。
这种路径适用于需要处理大容量数据的场景,可以通过横向扩展的方式增加存储容量和计算能力。
第二种路径是分布式数据库存储。
分布式数据库是一种将数据分片存储在多个节点上,并通过分布式计算和数据复制等技术实现数据一致性和高可用性的存储系统。
这种路径适用于需要频繁进行数据查询和分析的场景,可以提供高性能的数据访问能力。
第三种路径是对象存储。
对象存储通过将数据划分为独立的对象,并使用唯一的标识符进行管理和访问。
对象存储提供了高度伸缩性和可靠性的存储服务,适用于需要长期保存和管理大规模数据的场景。
通过对这三种不同的存储路径的介绍,我们可以看到它们各自具有一定的优势和适用场景。
在实际应用中,我们需要根据数据的具体特点和需求来选择最合适的存储路径,以便实现高效的数据存储和管理。
在未来的研究中,我们还可以进一步探索不同存储路径之间的融合和优化,提升大数据存储的性能和可扩展性。
1.2文章结构1.2 文章结构本文将就大数据存储的三种路径进行探讨和分析。
文章分为引言、正文和结论三个部分进行组织。
引言部分将对大数据存储的概述进行介绍,包括对大数据存储的重要性和应用范围进行说明。
同时,我们将介绍文章的结构和目的,以便读者能够清晰地了解文章的内容和意义。
正文部分将分为三个小节,分别阐述了大数据存储的三种路径。
每个小节包含路径的详细描述和关键要点的介绍。
第一种路径中,我们将详细描述这种存储路径并突出要点1的重要性。
具体而言,我们将探讨这种路径的适用性、使用方法以及可能的应用场景。
ONEStor分布式存储系统介绍
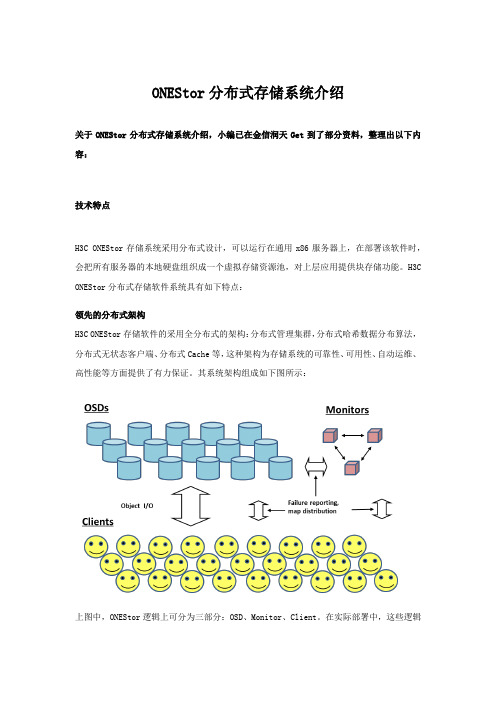
ONEStor分布式存储系统介绍关于ONEStor分布式存储系统介绍,小编已在金信润天Get到了部分资料,整理出以下内容:技术特点H3C ONEStor存储系统采用分布式设计,可以运行在通用x86服务器上,在部署该软件时,会把所有服务器的本地硬盘组织成一个虚拟存储资源池,对上层应用提供块存储功能。
H3C ONEStor分布式存储软件系统具有如下特点:领先的分布式架构H3C ONEStor存储软件的采用全分布式的架构:分布式管理集群,分布式哈希数据分布算法,分布式无状态客户端、分布式Cache等,这种架构为存储系统的可靠性、可用性、自动运维、高性能等方面提供了有力保证。
其系统架构组成如下图所示:上图中,ONEStor逻辑上可分为三部分:OSD、Monitor、Client。
在实际部署中,这些逻辑组件可灵活部署,也就是说既可以部署在相同的物理服务器上,也可以根据性能和可靠性等方面的考虑,部署在不同的硬件设备上。
下面对每一部分作一简要说明。
OSD:Object-based Storage DeviceOSD由系统部分和守护进程(OSD deamon)两部分组成。
OSD系统部分可看作安装了操作系统和文件系统的计算机,其硬件部分包括处理器、内存、硬盘以及网卡等。
守护进程即运行在内存中的程序。
在实际应用中,通常将每块硬盘(SSD或HDD)对应一个OSD,并将其视为OSD的硬盘部分,其余处理器、内存、网卡等在多个OSD之间进行复用。
ONEStor存储集群中的用户都保存在这些OSD中。
OSD deamon负责完成OSD的所有逻辑功能,包括与monitor 和其他OSD(事实上是其他OSD的deamon)通信以维护更新系统状态,与其他OSD共同完成数据的存储和维护,与client通信完成各种数据对象操作等等。
Monitor:Monitor是集群监控节点。
Monitor持有cluster map信息。
所谓Cluster Map,粗略的说就是关于集群本身的逻辑状态和存储策略的数据表示。
分布式存储解决方案

分布式存储解决方案目录一、内容概览 (2)1. 背景介绍 (3)2. 目标与意义 (3)二、分布式存储技术概述 (5)1. 分布式存储定义 (6)2. 分布式存储技术分类 (7)3. 分布式存储原理及特点 (8)三、分布式存储解决方案架构 (9)1. 整体架构设计 (10)1.1 硬件层 (12)1.2 软件层 (13)1.3 网络层 (14)2. 关键组件介绍 (15)2.1 数据节点 (16)2.2 控制节点 (18)2.3 存储节点 (19)2.4 其他辅助组件 (20)四、分布式存储解决方案核心技术 (22)1. 数据分片技术 (23)1.1 数据分片原理 (25)1.2 数据分片策略 (26)1.3 数据分片实例分析 (28)2. 数据复制与容错技术 (29)2.1 数据复制原理及策略 (31)2.2 容错机制与实现方法 (32)2.3 错误恢复过程 (34)3. 数据一致性技术 (35)3.1 数据一致性概念及重要性 (36)3.2 数据一致性协议与算法 (37)3.3 数据一致性维护与保障措施 (38)4. 负载均衡与性能优化技术 (39)4.1 负载均衡原理及策略 (41)4.2 性能优化方法与手段 (43)4.3 实例分析与展示 (43)五、分布式存储解决方案应用场景及案例分析 (44)1. 场景应用分类 (46)2. 具体案例分析报告展示 (47)一、内容概览分布式存储解决方案是一种旨在解决大规模数据存储和管理挑战的技术架构,它通过将数据分散存储在多个独立的节点上,提高数据的可用性、扩展性和容错能力。
本文档将全面介绍分布式存储系统的核心原理、架构设计、应用场景以及优势与挑战。
我们将从分布式存储的基本概念出发,阐述其相较于集中式存储的优势,如数据分布的均匀性、高可用性和可扩展性。
深入探讨分布式存储系统的关键组件,包括元数据管理、数据分布策略、负载均衡和容错机制等,并分析这些组件如何协同工作以保障数据的可靠存储和高效访问。
云计算——分布式存储

THANKS
感谢观看
云计算——分布式存储
汇报人: 2023-12-14
目录
• 分布式存储概述 • 分布式存储技术原理 • 分布式存储系统架构 • 分布式存储应用场景 • 分布式存储性能优化策略 • 分布式存储安全问题及解决方案
01
分布式存储概述
定义与特点
定义
分布式存储是一种数据存储技术,它通过将数据分散到多个独立的节点上,以 实现数据的分布式存储和访问。
云计算平台建设
01
02
03
云存储服务
分布式存储作为云计算平 台的核心组件,提供高效 、可扩展的存储服务。
云服务集成
与其他云服务(如计算、 网络、安全等)紧密集成 ,形成完整的云计算解决 方案。
自动化运维与管理
通过自动化工具实现分布 式存储系统的运维和管理 ,提高效率。
物联网数据存储与处理
实时数据采集
现状
目前,分布式存储技术已经成为了云计算领域的重要组成部 分,各大云服务提供商都提供了基于分布式存储的云存储服 务。同时,随着技术的不断发展,分布式存储的性能和稳定 性也在不断提高。
优势与挑战
优势
分布式存储具有高性能、高可用性、安全性、容错性和可维护性等优势,它可以 提供更加高效、灵活和可靠的数据存储服务,同时还可以提供更加灵活的扩展能 力,以满足不断增长的数据存储需求。
支持物联网设备实时采集 数据,并存储在分布式存 储系统中。
数据处理与分析
对物联网数据进行处理和 分析,提取有价值的信息 。
智能决策与控制
基于物联网数据分析结果 ,实现智能决策和控制, 提高生产效率。
05
分布式存储性能优化策略
数据压缩与解压缩技术
数据库分布式系统的说明书

数据库分布式系统的说明书一、引言数据库分布式系统是一种基于分布式计算和存储的数据库系统,可以将数据和计算任务分散到多个节点上进行并行处理,从而提高系统的性能与可扩展性。
本文将详细介绍数据库分布式系统的原理、架构以及应用场景。
二、原理与架构1. 分布式数据存储数据库分布式系统中的数据通常被分散存储在多个节点上,每个节点负责管理一部分数据。
这样的分布方式可以提高数据的可用性和容错性,同时也增加了系统的并行处理能力。
2. 分布式数据访问为了实现对分布式存储的数据的高效访问,数据库分布式系统采用了一些常用的技术手段,如数据划分、数据复制、数据分片等。
这些技术可以提高数据的可靠性、查询效率和负载均衡能力。
3. 分布式事务处理在分布式环境下,事务处理变得更加复杂。
数据库分布式系统通过引入分布式事务协调器来协调多个节点上的事务执行,保证数据的一致性和可靠性。
4. 分布式查询与计算数据库分布式系统支持将查询和计算任务分发到多个节点上进行并行处理,从而提高系统的查询性能和计算能力。
常用的分布式查询与计算技术包括MapReduce、Spark等。
三、应用场景数据库分布式系统在许多领域都有广泛的应用,以下是几个典型的应用场景。
1. 大规模数据分析对于大规模的数据分析任务,传统的单机数据库往往无法满足性能要求。
通过将数据分散存储在多个节点上,并使用分布式查询和计算技术,可以大幅提高数据分析的效率和速度。
2. 云计算平台云计算平台需要支持大规模用户的数据存储和查询需求,因此数据库分布式系统是其基础设施之一。
通过将数据库分布在多个物理节点上,可以提供高可用性和扩展性的数据服务。
3. 实时数据处理对于实时数据处理场景,数据库分布式系统可以通过数据的并行处理和分布式计算来实现对实时数据的快速处理和分析。
这在金融、物联网等领域有着重要的应用价值。
四、总结数据库分布式系统是一个基于分布式计算和存储的数据库架构,可以提高系统的性能、可靠性和可扩展性。
分布式存储系统详解
传统SAN架构
FC/IP
孤立的存储资源:存储通过 专用网络连接到有限数量的 服务器。
存储设备通过添加硬盘框 增加容量,控制器性能成 为瓶颈。
第3页
分布式Server SAN架构
虚拟化/操作系统 InfiniBand /10GE Network
InfiniBand /10GE Network
Server 3
Disk3 P9 P10 P11 P12
P2’ P6’ P14’ P18’
Disk4 P13 P14’ P15 P16’ P7’ P11’ P19’ P23’
Disk5 P17 P18’ P19 P20’ P3’ P12’ P15’ P24’
Disk6 P21 P22 P23 P24 P4’ P8’ P16’ P20’
第10页
FusionStorage部署方式
融合部署
指的是将VBS和OSD部署在同一台服务器中。 虚拟化应用推荐采用融合部署的方式部署。
分离部署
指的是将VBS和OSD分别部署在不同的服务器中。 高性能数据库应用则推荐采用分离部署的方式。
第11页
基础概念 (1/2)
资源池:FusionStorage中一组硬盘构成的存储池。
第二层为SSD cache,SSD cache采用热点读机制,系统会统计每个读取的数据,并统计热点访问因 子,当达到阈值时,系统会自动缓存数据到SSD中,同时会将长时间未被访问的数据移出SSD。
FusionStorage预读机制,统计读数据的相关性,读取某块数据时自动将相关性高的块读出并缓存
到SSD中。
数据可靠是第一位的, FusionStorage建议3副本配 置部署。
如果两副本故障,仍可保障 数据不丢失。
分布式存储系统简介
分布式存储系统简介从以下三个⽅⾯对分布式存储系统进⾏简单介绍:1.⾸先,什么是分布式存储系统呢?简单的说,就是将⽂件存储到多个服务器中。
2.其次,为什么需要分布式存储系统?因为单机存储资源和计算资源已经不能满⾜⽤户的需求。
3.最后,如何实现⼀个分布式存储系统或者说实现⼀个分布式存储系统需要做哪些⼯作?(1)既然是将⽂件存储到多个服务器中那就需要确定将⽂件具体存储到哪些服务器⾥,两种⽅式,⼀种是通过控制服务器,由这个控制服务器负责统⼀调度,客户端请求存储⼀个⽂件时,⾸先与控制服务器交互,控制服务器返回需要保存到服务器的地址,读取⽂件时也需要与控制服务器交互,获取存储位置信息,其中HDFS、GFS等分布式存储使⽤此种技术,namenode就类似于控制服务器⾓⾊。
另外⼀个⽅式是,不需要控制服务器,客户端⾃⼰计算需要存储到哪⾥,最简单的⽅式是直接取hash,⽐如有8台存储服务器,只需要把⽂件内容或者⽂件名取hash模8即可计算出应该存储到哪台存储服务器。
但有个问题是,当服务器数量增减时,hash就失效了,⼏乎需要重排迁移所有数据,根本没有办法实现⽔平扩展,这在分布式系统中是⽆法忍受的。
为了避免出现这种情况,引⼊了⼀致性hash算法,⼜称为环哈希,其中OpenStack Swift、华为FusionStorage就是使⽤的该⽅法。
除了环hash,当然还有其他的类hash算法,⽐如CRUSH算法,其中开源分布式存储系统Ceph就是使⽤的该⽅法。
需要注意的是虽然基于hash的⽂件分布映射⽅法不需要控制节点计算需要存储的位置,但仍然需要控制服务器保存⼀些集群元数据,⽐如集群的成员信息、映射规则、监控等等,如Ceph的mon服务。
(2)但是,如果只有⼀个控制服务,则存在单点故障,挂掉了就会导致服务不可⽤。
为了避免单点故障,具备⾼可⽤特点,必然需要同时启动多个控制服务,有多个控制服务就必须区分谁是leader,谁是slave,因此需要分布式⼀致性来协调选主,可以基于现有的分布式协调系统实现,如Zookeeper、Etcd服务等,也可以直接基于Paxos、Raft算法实现。
技术细则 百度
技术细则百度1. 简介本文档旨在介绍百度公司的技术细则,包括其技术架构、开发规范以及数据安全等方面的内容。
百度是中国领先的互联网公司,提供涵盖搜索引擎、在线地图、在线音乐和视频、电子商务等多个领域的产品和服务。
2. 技术架构百度公司的技术架构采用分布式系统和云计算技术为基础,具有高可用性、可扩展性和灵活性。
以下是其主要组成部分:2.1 分布式存储百度采用分布式存储系统来处理海量数据的存储和访问。
其存储系统具有良好的扩展性和冗余性,能够处理高并发的读写请求,并保证数据的一致性和可靠性。
2.2 分布式计算百度的计算系统基于分布式计算框架,能够进行大规模的数据处理和计算任务。
通过将计算任务划分成多个子任务,并分发到不同的计算节点上执行,可以提高计算效率和处理能力。
2.3 服务治理百度采用微服务架构来实现服务的拆分和管理。
每个服务由一个或多个微服务组成,通过服务治理系统进行统一管理和监控。
服务治理系统包括服务注册中心、配置中心、负载均衡和故障恢复等组件。
2.4 数据安全百度对数据安全非常重视,采用多层次的安全策略和技术来保护用户数据。
包括数据加密、访问控制、安全审计等措施,以确保数据的机密性、完整性和可用性。
3. 开发规范为了保证代码的质量和可维护性,百度制定了一系列的开发规范和最佳实践。
以下是一些主要的开发规范:3.1 代码规范百度采用统一的代码风格和命名规范,以提高代码的可读性和一致性。
包括缩进、命名规则、注释规范等方面的规范。
3.2 测试规范百度鼓励开发人员编写单元测试和集成测试来保证代码的质量。
测试代码要覆盖尽可能多的场景和边界条件,并进行持续集成和自动化测试。
3.3 文档规范百度强调文档的重要性,要求开发人员编写清晰、详细的文档来记录代码和系统的设计。
文档要包括设计思路、接口说明、使用方法等内容。
3.4 版本控制百度使用分布式版本控制系统来管理代码,每个项目都有自己的代码仓库。
开发人员提交代码前需要进行代码审查,并遵循代码合并和发布的流程。
概述四种主流的大数据技术(一)
概述四种主流的大数据技术(一)概述四种主流的大数据技术引言:大数据技术在不断进步和创新的过程中,已经成为当今世界中最重要和炙手可热的技术之一。
它可以帮助企业和组织从海量的数据中提取有价值的信息和洞见,从而支持决策和业务发展。
本文将概述四种主流的大数据技术,包括分布式存储系统、分布式处理框架、机器学习算法和数据可视化工具。
一、分布式存储系统:1. Hadoop分布式文件系统(HDFS):介绍HDFS的基本原理和特点。
2. Cassandra分布式数据库:探讨Cassandra的数据模型和可伸缩性。
3. Amazon S3:说明Amazon S3如何实现高性能、高可靠性的文件存储。
4. Google Cloud Storage:介绍Google Cloud Storage的特点和用途。
5. Apache HBase:探讨HBase的数据模型和应用场景。
二、分布式处理框架:1. Apache Spark:介绍Spark的特点和优势。
2. Apache Hadoop MapReduce:探讨MapReduce的原理和应用。
3. Apache Flink:说明Flink如何支持实时流处理和批处理。
4. Apache Storm:介绍Storm的实时分布式计算能力。
5. Apache Beam:探讨Beam的跨多种分布式处理框架的兼容性。
三、机器学习算法:1. 回归算法:介绍线性回归、逻辑回归等常用的回归算法。
2. 分类算法:探讨决策树、支持向量机等常用的分类算法。
3. 聚类算法:说明K-means、DBSCAN等常用的聚类算法。
4. 关联规则挖掘算法:介绍Apriori、FP-growth等挖掘频繁项集的算法。
5. 深度学习算法:探讨神经网络、卷积神经网络等深度学习算法的基本原理。
四、数据可视化工具:1. Tableau:介绍Tableau的交互性和灵活性。
2. Power BI:探讨Power BI的数据分析和可视化能力。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
技术层次图各技术简介1.1mybatis简介MyBatis 是支持普通SQL查询,存储过程和高级映射的优秀持久层框架。
MyBatis 消除了几乎所有的JDBC代码和参数的手工设置以及结果集的检索。
MyBatis 使用简单的XML或注解用于配置和原始映射,将接口和Java 的POJOs(Plain Old Java Objects,普通的Java对象)映射成数据库中的记录。
每个MyBatis应用程序主要都是使用SqlSessionFactory实例的,一个SqlSessionFactory实例可以通过SqlSessionFactoryBuilder获得。
SqlSessionFactoryBuilder可以从一个xml配置文件或者一个预定义的配置类的实例获得。
用xml文件构建SqlSessionFactory实例是非常简单的事情。
推荐在这个配置中使用类路径资源(classpath resource),但你可以使用任何Reader实例,包括用文件路径或file://开头的url创建的实例。
MyBatis有一个实用类----Resources,它有很多方法,可以方便地从类路径及其它位置加载资源。
1.2webservice简介Web service是一个平台独立的,低耦合的,自包含的、基于可编程的web的应用程序,可使用开放的XML(标准通用标记语言下的一个子集)标准来描述、发布、发现、协调和配置这些应用程序,用于开发分布式的互操作的应用程序。
1.3jquery简介jQuery UI 是以jQuery 为基础的开源JavaScript 网页用户界面代码库。
包含底层用户交互、动画、特效和可更换主题的可视控件。
我们可以直接用它来构建具有很好交互性的web应用程序。
所有插件测试能兼容jQuery UI包含了许多维持状态的小部件(Widget),因此,它与典型的jQuery 插件使用模式略有不同。
所有的jQuery UI 小部件(Widget)使用相同的模式,所以,只要您学会使用其中一个,您就知道如何使用其他的小部件(Widget)。
1.4springmvc简介Spring MVC属于SpringFrameWork的后续产品,已经融合在Spring Web Flow里面。
Spring 框架提供了构建Web 应用程序的全功能MVC 模块。
使用Spring 可插入的MVC 架构,可以选择是使用内置的Spring Web 框架还可以是Struts 这样的Web 框架。
通过策略接口,Spring 框架是高度可配置的,而且包含多种视图技术,例如JavaServer Pages(JSP)技术、Velocity、Tiles、iText 和POI。
Spring MVC 框架并不知道使用的视图,所以不会强迫您只使用JSP 技术。
Spring MVC 分离了控制器、模型对象、分派器以及处理程序对象的角色,这种分离让它们更容易进行定制。
1.5spring简介Spring是一个开源框架,Spring是于2003 年兴起的一个轻量级的Java 开发框架,由Rod Johnson 在其著作Expert One-On-One J2EE Development and Design中阐述的部分理念和原型衍生而来。
它是为了解决企业应用开发的复杂性而创建的。
Spring使用基本的JavaBean来完成以前只可能由EJB完成的事情。
然而,Spring的用途不仅限于服务器端的开发。
从简单性、可测试性和松耦合的角度而言,任何Java应用都可以从Spring中受益。
◆目的:解决企业应用开发的复杂性◆功能:使用基本的JavaBean代替EJB,并提供了更多的企业应用功能◆范围:任何Java应用简单来说,Spring是一个轻量级的控制反转(IoC)和面向切面(AOP)的容器框架。
◆轻量——从大小与开销两方面而言Spring都是轻量的。
完整的Spring框架可以在一个大小只有1MB多的JAR文件里发布。
并且Spring所需的处理开销也是微不足道的。
此外,Spring是非侵入式的:典型地,Spring应用中的对象不依赖于Spring的特定类。
◆控制反转——Spring通过一种称作控制反转(IoC)的技术促进了松耦合。
当应用了IoC,一个对象依赖的其它对象会通过被动的方式传递进来,而不是这个对象自己创建或者查找依赖对象。
你可以认为IoC与JNDI相反——不是对象从容器中查找依赖,而是容器在对象初始化时不等对象请求就主动将依赖传递给它。
◆面向切面——Spring提供了面向切面编程的丰富支持,允许通过分离应用的业务逻辑与系统级服务(例如审计(auditing)和事务(transaction)管理)进行内聚性的开发。
应用对象只实现它们应该做的——完成业务逻辑——仅此而已。
它们并不负责(甚至是意识)其它的系统级关注点,例如日志或事务支持。
◆容器——Spring包含并管理应用对象的配置和生命周期,在这个意义上它是一种容器,你可以配置你的每个bean如何被创建——基于一个可配置原型(prototype),你的bean可以创建一个单独的实例或者每次需要时都生成一个新的实例——以及它们是如何相互关联的。
然而,Spring不应该被混同于传统的重量级的EJB容器,它们经常是庞大与笨重的,难以使用。
◆框架——Spring可以将简单的组件配置、组合成为复杂的应用。
在Spring中,应用对象被声明式地组合,典型地是在一个XML文件里。
Spring也提供了很多基础功能(事务管理、持久化框架集成等等),将应用逻辑的开发留给了你。
◆MVC——Spring的作用是整合,但不仅仅限于整合,Spring 框架可以被看做是一个企业解决方案级别的框架。
客户端发送请求,服务器控制器(由DispatcherServlet实现的)完成请求的转发,控制器调用一个用于映射的类HandlerMapping,该类用于将请求映射到对应的处理器来处理请求。
HandlerMapping 将请求映射到对应的处理器Controller(相当于Action)在Spring 当中如果写一些处理器组件,一般实现Controller 接口,在Controller 中就可以调用一些Service 或DAO来进行数据操作ModelAndView 用于存放从DAO 中取出的数据,还可以存放响应视图的一些数据。
如果想将处理结果返回给用户,那么在Spring 框架中还提供一个视图组件ViewResolver,该组件根据Controller 返回的标示,找到对应的视图,将响应response 返回给用户。
所有Spring的这些特征使你能够编写更干净、更可管理、并且更易于测试的代码。
它们也为Spring中的各种模块提供了基础支持。
1.6quartz简介Quartz是OpenSymphony开源组织在Job scheduling领域又一个开源项目,它可以与J2EE与J2SE应用程序相结合也可以单独使用。
Quartz可以用来创建简单或为运行十个,百个,甚至是好几万个Jobs这样复杂的程序。
Jobs可以做成标准的Java组件或EJBs。
1.7log4j简介们也可以控制每一条日志的输出格式;通过定义每一条日志信息的级别,我们能够更加细致地控制日志的生成过程。
最令人感兴趣的就是,代码。
1.8hdfs简介Hadoop分布式文件系统(HDFS)被设计成适合运行在通用硬件(commodity hardware)上的分布式文件系统。
它和现有的分布式文件系统有很多共同点。
但同时,它和其他的分布式文件系统的区别也是很明显的。
HDFS是一个高度容错性的系统,适合部署在廉价的机器上。
HDFS能提供高吞吐量的数据访问,非常适合大规模数据集上的应用。
HDFS放宽了一部分POSIX约束,来实现流式读取文件系统数据的目的。
HDFS在最开始是作为Apache Nutch搜索引擎项目的基础架构而开发的。
HDFS是Apache Hadoop Core项目的一部分。
1.9hive简介据文件映射为一张数据库表,并提供简单的sql查询功能,可以将sql 语句转换为MapReduce任务进行运行。
其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专1.10sqoop简介Sqoop(发音:skup)是一款开源的工具,主要用于在HADOOP(Hive)与传统的数据库(mysql、postgresql...)间进行数据的传递。
1.11oracle简介ORACLE数据库系统是美国ORACLE公司(甲骨文)提供的以分布式数据库为核心的一组软件产品,是目前最流行的客户/服务器(CLIENT/SERVER)或B/S体系结构的数据库之一。
比如SilverStream 就是基于数据库的一种中间件。
ORACLE数据库是目前世界上使用最为广泛的数据库管理系统,作为一个通用的数据库系统,它具有完整的数据管理功能;作为一个关系数据库,它是一个完备关系的产品;作为分布式数据库它实现了分布式处理功能。
但它的所有知识,只要在一种机型上学习了ORACLE知识,便能在各种类型的机器上使用它。
Oracle数据库最新版本为Oracle Database 12c。
Oracle数据库12c引入了一个新的多承租方架构,使用该架构可轻松部署和管理数据库云。
此外,一些创新特性可最大限度地提高资源使用率和灵活性,如Oracle Multitenant可快速整合多个数据库,而Automatic Data Optimization和Heat Map能以更高的密度压缩数据和对数据分层。
这些独一无二的技术进步再加上在可用性、安全性和大数据支持方面的主要增强,使得Oracle数据库12c成为私有云和公有云部署的理想平台。
1.12jstl简介JSTL(JSP Standard Tag Library,JSP标准标签库)是一个不断完善的开放源代码的JSP标签库,是由apache的jakarta小组来维护的。
JSTL只能运行在支持JSP1.2和Servlet2.3规范的容器上,如tomcat 4.x。
在JSP 2.0中也是作为标准支持的。