Oracle的全文检索技术
达梦与oracle的对比

2、其次是确保不停机,使Oracle数据库一直维持在正常的运行状态,避免停机给客户带来的损失
高安全性
1、DM7是具有自主知识产权的高安全数据库管理系统,已通过公安部安全四级评测。是目前安全等级最高的商业数据库之一。同时DM7还通过了中国信息安全测评中心的EAL4级评测。
兼容
1、体系结构方面,DM7兼容oracle的单库单实例式结构、表空间-数据文件机制、回滚机制、多版本并发控制、闪回。
2、应用开发接口兼容,兼容PL/SQL常用语法90%、OCI、OOCI、OO4O接口兼容、系统包机制。
3、维护管理方式兼容,兼容大量V$动态视图、AWR性能分析报告、10053等事件。
6、DM7中实现了数据字典缓存技术,执行期间不必封锁整个数据字典,可以有效降低DDL操作对整体系统并发执行的影响。
7、DM7为具有多个处理器(CPU)的计算机提供了并行查询,以优化查询执行和索引操作。并行查询其优势就是可以通过多个线程来处理查询作业,从而提高查询的效率。
8、DM7数据压缩采用智能压缩策略,自动选择最合适的压缩算法进行数据压缩,可以显著提升数据的压缩比,进一步减少系统的空间资源开销。
通用性
1、DM7兼容多种硬件体系,可运行于X86、SPARC、POWER等硬件体系之上。DM7各种平台上的数据存储结构和消息通信结构完全一致,使得DM7各种组件在不同的硬件平台上具有一致的使用特性。
2、DM7实现了平台无关性,支持Windows系列、各版本Linux(2.4及2.4以上内核)、Unix、NeoKylin、AIX、Solaris等各种主流操作系统。DM7的服务器、接口程序和管理工具均可在32位/64位版本操作系统上使用。
使用Oracle全文索引搜索文本

使用Oracle全文索引搜索文本不使用Oracle text功能,也有很多方法可以在Oracle数据库中搜索文本.可以使用标准的INSTR 函数和LIKE操作符实现。
SELECT *FROM mytext WHERE INSTR (thetext, 'Oracle') > 0;SELECT * FROM mytext WHERE thetext LIKE '%Oracle%';有很多时候,使用instr和like是很理想的, 特别是搜索仅跨越很小的表的时候.然而通过这些文本定位的方法将导致全表扫描,对资源来说消耗比较昂贵,而且实现的搜索功能也非常有限,因此对海量的文本数据进行搜索时,建议使用oralce提供的全文检索功能建立全文检索的步骤步骤一检查和设置数据库角色首先检查数据库中是否有CTXSYS用户和CTXAPP脚色。
如果没有这个用户和角色,意味着你的数据库创建时未安装intermedia功能。
你必须修改数据库以安装这项功能。
默认安装情况下,ctxsys用户是被锁定的,因此要先启用ctxsys 的用户。
步骤二赋权在ctxsys用户下把ctx_ddl的执行权限赋于要使用全文索引的用户,例:grant execute on ctx_ddl to pomoho;步骤三设置词法分析器(lexer)Oracle实现全文检索,其机制其实很简单。
即通过Oracle专利的词法分析器(lexer),将文章中所有的表意单元(Oracle 称为term)找出来,记录在一组以dr$开头的表中,同时记下该term 出现的位置、次数、hash 值等信息。
检索时,Oracle 从这组表中查找相应的term,并计算其出现频率,根据某个算法来计算每个文档的得分(score),即所谓的‘匹配率’。
而lexer则是该机制的核心,它决定了全文检索的效率。
Oracle 针对不同的语言提供了不同的lexer, 而我们通常能用到其中的三个:n basic_lexer: 针对英语。
oracle对表选择索引的扫描方法

Oracle在执行查询时,会根据查询条件选择合适的索引来进行扫描。
它使用以下几种
方法来选择索引扫描方式:
1. 全表扫描(Full Table Scan):当没有适用的索引或者优化器认为全表扫描更高效时,Oracle会选择对整个表进行扫描。
这通常在小表或者需要扫描大部分数据的情况下发生。
2. 索引扫描(Index Scan):如果有适用的索引,Oracle可以使用索引扫描来避免全表
扫描。
索引扫描可以是范围扫描(Range Scan)、唯一索引扫描(Unique Scan)、位
图索引扫描(Bitmap Index Scan)等。
3. 聚簇索引扫描(Clustered Index Scan):当表使用聚簇索引时,Oracle可以通过聚簇
索引扫描来获取数据。
聚簇索引将相邻行的数据存储在一起,因此可以减少磁盘I/O
操作。
4. 索引唯一扫描(Index Unique Scan):当查询条件中包含唯一索引的完整键值时,Oracle可以使用索引唯一扫描来获取数据。
这种扫描方式只返回满足条件的一行数据。
5. 索引范围扫描(Index Range Scan):当查询条件中包含索引的部分键值时,Oracle
可以使用索引范围扫描来获取数据。
这种扫描方式返回满足条件的多行数据。
以上是Oracle选择索引扫描方法的一些常见方式,实际选择会受到许多因素的影响,
如索引的选择性、表的大小、查询条件的复杂度等。
优化器会根据统计信息和成本评
估来选择最佳的索引扫描方式。
基于Oracle Text的信息系统资料库全文检索技术

( )过滤 器 提取 文 档 数 据 并 将其 转换 为文 本 表 示 方 式 。存 储 二进 制 文 档 ( wod 2 如 r
或 ar b t co a 文件 )时需 要 这样 做 。过滤器的输 出不 必是 纯 文本 格 式 , 可 以是 x 或 h — 它 ml t
ml 之类 的文 本 格式 。
O al Te t rce x 的原 理及 其 在信 息 系统 中的使 用 。
关 键词 : a l Te t 资料库 ; 文检 索 0rce x ; 全
1 引 言
OrceT x 是 Orce al e t a l 提供 的一 个服务 集 , 功能 十分 强大 , 可 以 为文 档 提 供索 引 方 它 法 、 行检 索 , 可 以对 文 档进 行格式 转换 、 进 还 存储 和 管理等 。它 不仅 支 持 TXT、 HTML等 纯文 本格 式 , 支持 很 多种 二进 制格 式的 文档 , D C、 P P F等等 。OrceTe t 还 如 O P T、 D al x 还 可用来 对 不 同语 种 的 文档进 行 检索 。Orc x 是完 全集 成在 数据 库 核心 内的 , 对 数 a l Te t e 它 据 库 中的 文档 进 行检 索 的效 率很 高 。
( )分段 器 提取 过 滤器 的输 出信息 , 3 并将 其转 换为 纯文 本 。包 括 x 和 h ml 内的 ml t 在
不 同 文本 格式 有 不 同的分 段器 。转换 为纯 文本 涉 及检 测 重要 文档 段标 记 、 移去 不 可 见 的 信 息 和文本 重新 格式化 。
( )词 法 分析 器提 取 分段器 中的纯 文本 , 将 其拆 分 为不 连 续 的标 记 。既 存在 空 白 4 并 字 符 分 隔语 言使 用 的词 法分 析器 , 也存在分 段复 杂的亚 洲语 言使用 的专 门词法 分析器 。 ( )索 引引 擎提 取词 法分 析器 中的所 有标 记 、 档 段在 分段 器 中的偏 移 量 以及 被 称 5 文 为 非索 引字 的 低 信息含 量字 列表 , 并构 建反 向索 引 。倒排 索 引 存 储标 记和 含有 这 些 标 记
全文检索方案
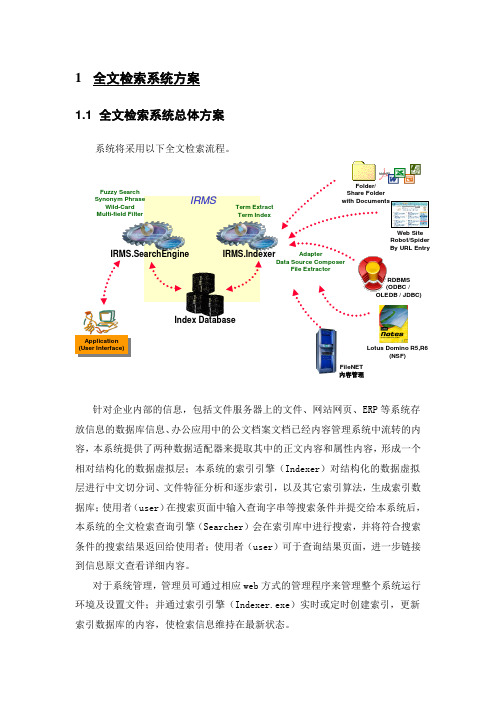
1 全文检索系统方案1.1 全文检索系统总体方案系统将采用以下全文检索流程。
针对企业内部的信息,包括文件服务器上的文件、网站网页、ERP 等系统存放信息的数据库信息、办公应用中的公文档案文档已经内容管理系统中流转的内容,本系统提供了两种数据适配器来提取其中的正文内容和属性内容,形成一个相对结构化的数据虚拟层;本系统的索引引擎(Indexer )对结构化的数据虚拟层进行中文切分词、文件特征分析和逐步索引,以及其它索引算法,生成索引数据库;使用者(user )在搜索页面中输入查询字串等搜索条件并提交给本系统后,本系统的全文检索查询引擎(Searcher )会在索引库中进行搜索,并将符合搜索条件的搜索结果返回给使用者;使用者(user )可于查询结果页面,进一步链接到信息原文查看详细内容。
对于系统管理,管理员可通过相应web 方式的管理程序来管理整个系统运行环境及设置文件;并通过索引引擎(Indexer.exe )实时或定时创建索引,更新索引数据库的内容,使检索信息维持在最新状态。
IRMS.Indexer Index DatabaseIRMS.SearchEngine(User Interface)Application (User Interface)ApplicationTerm Extract Term Index Folder/Share Folder with DocumentsWeb Site Robot/Spider By URL EntryRDBMS(ODBC /OLEDB / JDBC)Lotus Domino R5,R6(NSF)FileNET內容管理Fuzzy SearchSynonym PhraseWild-CardMulti-field Filter IRMS AdapterData Source ComposerFile Extractor1.2 全文检索系统平台架构本系统基于组件化和松散耦合架构和设计,系统平台架构示意图如下:整个系统主要分为信息整合、信息萃取和服务、应用整合三个部分。
oracle检索第5行

oracle检索第5行摘要:1.Oracle 简介2.Oracle 检索第5 行的方法3.实例操作正文:【Oracle 简介】Oracle 是一款广泛应用于企业级数据管理的关系型数据库管理系统,以其高性能、安全稳定、可扩展性强而著称。
Oracle 数据库支持多种数据类型,可以满足不同业务场景的需求,因此在全球范围内拥有大量用户。
【Oracle 检索第5 行的方法】在Oracle 中,要检索第5 行数据,可以使用ROWNUM 伪列或者使用ROW_NUMBER() 分析函数。
下面分别介绍这两种方法:方法一:使用ROWNUM 伪列```sqlSELECT * FROM (SELECT t.*, ROWNUM rn FROM your_table t) WHERE rn = 5;```方法二:使用ROW_NUMBER() 分析函数```sqlSELECT * FROM (SELECT t.*, ROW_NUMBER() OVER (ORDER BYsome_column) rn FROM your_table t) WHERE rn = 5;```【实例操作】假设有一个名为“employees”的表,包含以下列:id, name, age, department。
现在要检索第5 行的数据,可以使用以下SQL 语句:方法一:```sqlSELECT * FROM (SELECT t.*, ROWNUM rn FROM employees t) WHERE rn = 5;```方法二:```sqlSELECT * FROM (SELECT t.*, ROW_NUMBER() OVER (ORDER BY id) rn FROM employees t) WHERE rn = 5;```以上两种方法都可以实现检索第5 行数据的需求。
[转载]oracleText全文检索功能对中文分词的支持情况
![[转载]oracleText全文检索功能对中文分词的支持情况](https://img.taocdn.com/s3/m/8df837d72dc58bd63186bceb19e8b8f67c1ceff2.png)
[转载]oracleText全⽂检索功能对中⽂分词的⽀持情况下⾯例⼦在XE中测试通过。
准备⼯作:CREATE TABLE issues (ID NUMBER,summary VARCHAR(120),description CLOB,author VARCHAR(80),ot_version VARCHAR(10));INSERT INTO issuesVALUES (1, 'Jane', 'Text does not make tea','Oracle Text is unable to make morning tea', 1);INSERT INTO issuesVALUES (2, 'John', 'It comes in the wrong color','I want to have Text in pink', 1);INSERT INTO issuesVALUES (3, 'Mike', 'I come from china', '所以我讲中⽂', 1);--下⾯两句话很难解析的INSERT INTO issuesVALUES (4, 'Mike', 'I come from china', '吉林省长春市的⼈民', 1);INSERT INTO issuesVALUES (5, 'Mike', 'I come from china','我们要积极地主动作好计划⽣育⼯作', 1);-- define datastore preference for issuesBEGIN--ctx_ddl.drop_preference ('issue_lexer');ctx_ddl.set_attribute ('issue_store', 'output_type', 'CLOB');ctx_ddl.create_preference ('issue_lexer', 'CHINESE_LEXER');END;/-- index issues 没有指定任何lexerCREATE INDEX issue_index ON issues(author) INDEXTYPE IS ctxsys.CONTEXT;--进⾏查询SELECT *FROM issuesWHERE contains (author, '中⽂', 1) > 0;会返回no rows selected。
oracle查询数据库名称的语句

oracle查询数据库名称的语句在Oracle数据库中,可以使用多种方法查询数据库名称。
以下是一些常用的查询方法:1. 使用全局数据字典视图:在Oracle数据库中,可以使用全局数据字典视图来查询数据库名称。
全局数据字典视图存储了关于数据库实例和对象的元数据信息。
具体的查询语句如下:```SELECT nameFROM v$database;```这将返回数据库的名称。
2. 使用系统表:Oracle数据库还提供了一些系统表,可以通过这些系统表查询数据库名称。
其中,`v$database`表和`v$instance`表是常用的。
```SELECT nameFROM v$database;```或```SELECT nameFROM v$instance;```这两个查询都可以返回数据库的名称。
3. 使用SQL*Plus命令:如果在Oracle数据库中使用SQL*Plus命令行工具,可以通过以下命令来查询数据库名称:```SELECT ora_database_nameFROM dual;```这将从`dual`表中返回数据库的名称。
4. 使用特殊的行属性:在Oracle数据库中,可以使用`SELECT`语句的`FROM`子句中的特殊行属性来查询数据库名称。
```SELECT*FROMtable(sys_context('userenv','con_name'));```这将返回数据库的名称。
总结起来,查询Oracle数据库名称的方法有很多种,包括使用全局数据字典视图、系统表、SQL*Plus命令和特殊的行属性等。
根据实际情况选择合适的方法来查询数据库名称。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Oracle的全文检索技术Oracle一直致力于全文检索技术的研究,当Oracle9i Rlease2发布之时,Oracle数据库的全文检索技术已经非常完美,Oracle Text使Oracle9i具备了强大的文本检索能力和智能化的文本管理能力。
Oracle Text是Oracle9i采用的新名称,在Oracle8/8i中它被称作Oracle interMedia Text。
使用Oracle Text,可以方便而有效地利用标准的SQL工具来构建基于文本的新的开发工具或对现有应用程序进行扩展。
应用程序开发人员可以在任何使用文本的Oracle数据库应用程序中充分利用Oracle Text搜索,应用范围可以是现有应用程序中可搜索的注释字段,也可是实现涉及多种文档格式和复杂搜索标准的大型文档管理系统。
Oracle Text支持Oracle数据库所支持的大多数语言的基本全文搜索功能。
虽然大多数大型数据库都支持全文检索,但Oracle在这方面无疑是最出色的。
Oracle 能搜索多种格式的文档,如Word,Execl,PowerPoint,Html,PDF等等。
但在使用中也发现有遗憾的地方,Oracle Text无论使用何种过滤器(INSO_FILTER或NULL_FILTER)及何种词法分析器(BASIC_LEXER,CHINESE_VGRAM_LEXER还是CHINESE_LEXER)都不能检索出中文内容的文本文档(TXT,RTF)。
1 Oracle Text的体系架构下图是Oracle Text的体系架构:图1 Oracle Text的体系架构Oracle Text 索引文档时所使用的主要逻辑步骤如下:(1)数据存储逻辑搜索表的所有行,并读取列中的数据。
通常,这只是列数据,但有些数据存储使用列数据作为文档数据的指针。
例如,URL_DATASTORE 将列数据作为URL 使用。
如果对本地文件进行检索,只要指定DATASTORE中FILE_DA TASTORE参数为文件的路径即可。
(2)过滤器提取文档数据并将其转换为文本表示方式。
存储二进制文档(如Word 或Acrobat 文件) 时需要这样做。
过滤器的输出不必是纯文本格式-- 它可以是XML 或HTML 之类的文本格式。
(3)分段器提取过滤器的输出信息,并将其转换为纯文本。
包括XML 和HTML 在内的不同文本格式有不同的分段器。
转换为纯文本涉及检测重要文档段标记、移去不可见的信息和文本重新格式化。
(4)词法分析器提取分段器中的纯文本,并将其拆分为不连续的标记。
既存在空白字符分隔语言使用的词法分析器,也存在分段复杂的亚洲语言使用的专门词法分析器。
(5)索引引擎提取词法分析器中的所有标记、文档段在分段器中的偏移量以及被称为非索引字的低信息含量字列表,并构建反向索引。
倒排索引存储标记和含有这些标记的文档。
归纳起来如下:(1)建表并装载文本(包含带有需要检索的文本字段)(2)配置索引(3)建立索引(4)发出查询(5)索引维护:同步与优化(将在后面介绍)文本装载要实现文本的全文检索首先必须把正确的文本加载到数据库表中,默认的建立索引行为要求将文档装载在文本列中,尽管可以用其它方式(包括文件系统和URL 形式)存储文档(在"数据存储"选项进行设置)。
默认情况下,系统应该将文档装载在文本列中。
文本列可以是VARCHAR2、CLOB、BLOB、CHAR或BFILE。
注意,只有在将Oracle7系统移植到Oracle8的情况下才支持用LONG和LONG RAW 这两个相反的列类型存储文本。
不能为列类型NCLOB、DA TE和NUMBER建立索引。
关于文档格式,因为系统能为包括HTML、PDF、Microsoft Word和纯文本在内的大多数文档格式建立索引,可以将其中的任何文档类型装载到文本列中(在"过滤器"选项中设置)。
有关所支持的文档格式的详细信息,可以参阅Oracle Text User's Guideand Reference 中的附录"Supported Filter Formats"。
装载方法主要有以下几种:(1)SQL INSERT 语句(2)ctxload 可执行文件(3)SQL*Loader(4)从BFILE 中装载LOB 的DBMS_LOB.LOADFROMFILE() PL/SQL 过程(5)Oracle Call Interface建立索引文本装入文本列后,就可以创建Oracle Text索引。
文档以许多不同方案、格式和语言存储。
因此,每个Oracle Text 索引有许多需要设置的选项,以针对特定情况配置索引。
创建索引时,Oracle Text可使用若干个默认值,但在大多数情况下要求用户通过指定首选项来配置索引。
每个索引的许多选项组成功能组,称为"类",每个类集中体现配置的某一方面,可以认为这些类就是与文档数据库有关的一些问题。
例如:数据存储、过滤器、词法分析器、相关词表、存储等。
每个类具有许多预定义的行为,称之为对象。
每个对象是类问题可能具有的答案,并且大多数对象都包含有属性。
通过属性来定制对象,从而使对索引的配置更加多变以适应于不同的应用。
(1)存储(Storage)类存储类指定构成Oracle Text索引的数据库表和索引的表空间参数和创建参数。
它仅有一个基本对象:BASIC_STORAGE,其属性包括:I_Index_Clause、I_Table_Clause、K_Table_Clause、N_Table_Clause、P_Table_Clause、R_Table_Clause。
(2)数据存储(Datastore)类数据存储:关于列中存储文本的位置和其他信息。
默认情况下,文本直接存储到列中,表中的每行都表示一个单独的完整文档。
其他数据存储位置包括存储在单独文件中或以其URL 标识的Web 页上。
七个基本对象包括:Default_Datastore、Detail_Datastore、Direct_Datastore、File_Datastore、Multi_Column_Datastore 、URL_Datastore、User_Datastore,。
(3)文档段组(Section Group)类文档段组是用于指定一组文档段的对象。
必须先定义文档段,然后才能使用索引通过WITHIN 运算符在文档段内进行查询。
文档段定义为文档段组的一部分。
包含七个基本对象:AUTO_SECTION_GROUP、BASIC_SECTION_GROUP、HTML_SECTION_GROUP、NEWS_SECTION_GROUP、NULL_SECTION_GROUP、XML_SECTION_GROUP、PATH_SECTION_GROUP。
(4)相关词表(Wordlist)类相关词表标识用于索引的词干和模糊匹配查询选项的语言,只有一个基本对象BASIC_WORDLIST,其属性有:Fuzzy_Match、Fuzzy_Numresults、Fuzzy_Score、Stemmer、Substring_Index、Wildcard_Maxterms、Prefix_Index、Prefix_Max_Length、Prefix_Min_Length。
(5)索引集(Index Set)索引集是一个或多个Oracle 索引(不是Oracle Text索引) 的集合,用于创建CTXCAT类型的Oracle Text索引,只有一个基本对象BASIC_INDEX_SET。
(6)词法分析器(Lexer)类词法分析器类标识文本使用的语言,还确定在文本中如何标识标记。
默认的词法分析器是英语或其他西欧语言,用空格、标准标点和非字母数字字符标识标记,同时禁用大小写。
包含8个基本对象:BASIC_LEXER、CHINESE_LEXER、CHINESE_VGRAM_LEXER、JAPANESE_LEXER、JAPANESE_VGRAM_LEXER、KOREAN_LEXER、KOREAN__MORPH_ LEXER、MULTI_LEXER。
(7)过滤器(Filter)类过滤器确定如何过滤文本以建立索引。
可以使用过滤器对文字处理器处理的文档、格式化的文档、纯文本和HTML 文档建立索引,包括5个基本对象:CHARSET_FILTER、INSO_FILTER INSO、NULL_FILTER、PROCEDURE_FILTER、USER_FILTER。
(8)非索引字表(Stoplist)类非索引字表类是用以指定一组不编入索引的单词(称为非索引字)。
有两个基本对象:BASIC_STOPLIST (一种语言中的所有非索引字) 、MULTI_STOPLIST (包含多种语言中的非索引字的多语言非索引字表)。
查询建立了索引,就可以使用SELECT 语句中的CONTAINS 运算符发出文本查询。
使用CONTAINS 可以进行两种查询:单词查询和ABOUT查询。
5.1 词查询示例词查询是对输入到CONTAINS 运算符中单引号间的精确单词或短语的查询。
在以下示例中,我们将查找文本列中包含oracle 一词的所有文档。
每行的分值由使用标签 1 的SCORE 运算符选定:SELECT SCORE(1) title from news WHERE CONTAINS(text, 'oracle', 1) > 0;在查询表达式中,可以使用AND 和OR 等文本运算符来获取不同结果。
还可以将结构性谓词添加到WHERE 子句中。
可以使用count(*)、CTX_QUERY.COUNT_HITS 或CTX_QUERY.EXPLAIN 来计算查询的命中(匹配) 数目。
5.2 ABOUT查询示例在所有语言中,ABOUT查询增加了某查询所返回的相关文档的数目。
在英语中,ABOUT 查询可以使用索引的主题词组件,该组件在默认情况下创建。
这样,运算符将根据查询的概念返回文档,而不是仅依据所指定的精确单词或短语。
例如,以下查询将查找文本列中关于主题politics 的所有文档,而不是仅包含politics 一词的文档:SELECT SCORE(1) title from news WHERE CONTAINS(text, 'about(politics)', 1) > 0;索引维护索引建好后,如果表中的数据发生变化,比如增加或修改了记录,怎么办?由于对表所发生的任何DML语句,都不会自动修改索引,因此,必须定时同步(sync)和优化(optimize)索引,以正确反映数据的变化。