清华大学数据可视化教程高维数据可视化v
使高维分布高斯化方法

使高维分布高斯化方法
高维分布高斯化是一种可以将高维数据转换为可视化的方法,利用高斯分布的思想和原理,可以将高度复杂的高维数据变得更加简单、直观、易懂,进而分析出有价值的信息。
本文结合具体案例,详细介绍高维分布高斯化的基本原理以及如何运用该方法进行数据分析工作。
高维分布高斯化原理
高维分布高斯化的原理是利用高斯分布的思想和原理,将复杂的高维数据转换为可视化的直观图形,从而更好地理解数据的本质。
高斯分布把概率分布用参数μ(均值)和σ(标准差)来表示,并且一般假设数据均服从高斯分布,然后可以根据实际数据估计出μ和σ的值,以拟合概率分布。
同时,为了减少高维数据的维度,可以通过特征选择的方法,将高维数据转换为低维数据,从而减少特征数量以及数据的复杂度。
应用实例
假设有一个数据集,经过特征选择,去掉不必要的特征后,变成了一个4维的数据。
用高维分布高斯化来可视化该4维数据,思路是:
1.确定4个维度的均值和标准差,分别记作μ1,μ2,σ1,σ2
2. 根据高斯分布的思想,可以把4维数据的每一个值用
mu1,mu2,sigma1,来表示,其中,mu1表示均值,sigma1表示标准差,mu2表示第二个维度的均值。
新媒体数据分析:数据可视化的基本流程

数据可视化的基本流程大多数人对数据可视化的第一印象,可能就是各种图形,比如Excel图表模块中的柱状图、条形图、折线图、饼图、散点图等等,就不一一列举了。
以上所述,只是数据可视化的具体体现,但是数据可视化却不止于此。
数据可视化不是简单的视觉映射,而是一个以数据流向为主线的一个完整流程,主要包括数据采集、数据处理和变换、可视化映射、用户交互和用户感知。
一个完整的可视化过程,可以看成数据流经过一系列处理模块并得到转化的过程,用户通过可视化交互从可视化映射后的结果中获取知识和灵感。
图1 可视化的基本流程图可视化主流程的各模块之间,并不仅仅是单纯的线性连接,而是任意两个模块之间都存在联系。
例如,数据采集、数据处理和变换、可视化编码和人机交互方式的不同,都会产生新的可视化结果,用户通过对新的可视化结果的感知,从而又会有新的知识和灵感的产生。
下面,对数据可视化主流程中的几个关键步骤进行说明。
01数据采集数据采集是数据分析和可视化的第一步,俗话说“巧妇难为无米之炊”,数据采集的方法和质量,很大程度上就决定了数据可视化的最终效果。
数据采集的分类方法有很多,从数据的来源来看,可以分为内部数据采集和外部数据采集。
1.内部数据采集:指的是采集企业内部经营活动的数据,通常数据来源于业务数据库,如订单的交易情况。
如果要分析用户的行为数据、APP的使用情况,还需要一部分行为日志数据,这个时候就需要用「埋点」这种方法来进行APP或Web的数据采集。
2.外部数据采集指的数通过一些方法获取企业外部的一些数据,具体目的包括,获取竞品的数据、获取官方机构官网公布的一些行业数据等。
获取外部数据,通常采用的数据采集方法为「网络爬虫」。
以上的两类数据采集方法得来的数据,都是二手数据。
通过调查和实验采集数据,属于一手数据,在市场调研和科学研究实验中比较常用,不在此次探讨范围之内。
02数据处理和变换数据处理和数据变换,是进行数据可视化的前提条件,包括数据预处理和数据挖掘两个过程。
t-SNE高维数据可视化(python)

t-SNE⾼维数据可视化(python)t-SNE实践——sklearn教程t-SNE是⼀种集降维与可视化于⼀体的技术,它是基于SNE可视化的改进,解决了SNE在可视化后样本分布拥挤、边界不明显的特点,是⽬前最好的降维可视化⼿段。
关于t-SNE的历史和原理详见。
代码见下⾯例⼀TSNE的参数函数参数表:parameters描述n_components嵌⼊空间的维度perpexity混乱度,表⽰t-SNE优化过程中考虑邻近点的多少,默认为30,建议取值在5到50之间early_exaggeration表⽰嵌⼊空间簇间距的⼤⼩,默认为12,该值越⼤,可视化后的簇间距越⼤learning_rate学习率,表⽰梯度下降的快慢,默认为200,建议取值在10到1000之间n_iter迭代次数,默认为1000,⾃定义设置时应保证⼤于250min_grad_norm如果梯度⼩于该值,则停⽌优化。
默认为1e-7metric表⽰向量间距离度量的⽅式,默认是欧⽒距离。
如果是precomputed,则输⼊X是计算好的距离矩阵。
也可以是⾃定义的距离度量函数。
init初始化,默认为random。
取值为random为随机初始化,取值为pca为利⽤PCA进⾏初始化(常⽤),取值为numpy数组时必须shape=(n_samples, n_components)verbose是否打印优化信息,取值0或1,默认为0=>不打印信息。
打印的信息为:近邻点数量、耗时、σσ、KL散度、误差等random_state随机数种⼦,整数或RandomState对象method两种优化⽅法:barnets_hut和exact。
第⼀种耗时O(NlogN),第⼆种耗时O(N^2)但是误差⼩,同时第⼆种⽅法不能⽤于百万级样本angle当method=barnets_hut时,该参数有⽤,⽤于均衡效率与误差,默认值为0.5,该值越⼤,效率越⾼&误差越⼤,否则反之。
两维数据聚类可视化方法

两维数据聚类可视化方法如何使用两维数据聚类可视化方法。
引言:数据聚类是在数据集中将相似数据点归为一类的过程。
聚类分析是数据挖掘和机器学习中一个重要的任务,有助于发现数据集中的潜在模式和结构。
在进行聚类分析时,可视化是一种强大的工具,可以帮助我们理解数据并做出更好的决策。
本文将详细介绍如何使用两维数据聚类可视化方法,以帮助读者更好地理解聚类结果并进行进一步的分析。
一、数据准备1. 选择合适的数据集:为了演示聚类可视化方法,需要选择具有两个维度的数据集。
可以选择现有的数据集,也可以使用模拟的数据集。
重要的是数据集应该包含足够的样本和不同的类别。
2. 数据预处理:在进行聚类之前,需要对数据进行预处理。
这包括去除缺失值、标准化或归一化数据等。
数据预处理的目的是确保所有样本具有相似的尺度和范围,以便更好地进行聚类分析。
二、选择合适的聚类算法1. K均值聚类算法:K均值聚类是一种常用且简单的聚类算法。
它通过将数据集分为k个互不重叠的簇,每个簇都以其质心代表。
K值的选择对聚类结果非常关键,可以尝试使用不同的K值,根据聚类结果的质量来选择最佳的K值。
2. DBSCAN聚类算法:DBSCAN聚类基于数据点之间的密度连接。
它能够找出任意形状和大小的簇,并且可以自动确定簇的数量。
DBSCAN算法对离群点和噪声具有较好的鲁棒性,适用于复杂的数据集。
三、进行聚类分析1. 使用选定的聚类算法对数据进行聚类:根据选择的聚类算法,将数据集分为不同的簇。
每个簇代表一个聚类结果,具有相似的特征或属性。
2. 可视化聚类结果:使用二维可视化方法将聚类结果表示在平面上。
其中一种常用的方法是散点图,以聚类后的样本为点进行表示。
不同的类别可以使用不同的颜色进行区分。
此外,还可以添加其他可视化元素,如簇的中心点或边界。
四、解读和分析聚类结果1. 观察聚类结果:观察可视化的聚类结果,寻找不同簇之间的分界线、聚类紧密度等信息。
观察聚类结果有助于理解数据集中的模式和结构。
多维空间数据可视化方法比较研究

多维空间数据可视化方法比较研究数据可视化是指通过图表、图形等视觉方式将数据呈现出来,帮助人们更好地理解和分析数据的技术和方法。
在数据科学和信息可视化的领域中,多维空间数据可视化一直是一个重要的研究方向。
多维空间数据是指包含多个维度的数据集合,每个维度代表数据的一个特征或属性。
比较研究不同的多维空间数据可视化方法,可以帮助人们选择最合适的方法来分析和展示自己的数据。
在多维空间数据可视化的研究中,有许多不同的方法和技术被提出和应用。
下面将介绍几种常见的多维空间数据可视化方法,并比较它们的优缺点。
1. 散点图矩阵(Scatterplot Matrix)散点图矩阵是一种常见的多维空间数据可视化方法。
它通过在一个图表中同时显示出数据集中的所有维度之间的两两关系,来展示数据的分布和相关性。
散点图矩阵适用于数据维度较少的情况,但当维度较多时,图表会变得拥挤和模糊。
2. 平行坐标图(Parallel Coordinates)平行坐标图是一种用于可视化多维空间数据的有效方法。
它通过一组平行的垂直坐标轴来表示不同的数据维度,以线段的形式将数据点连接在一起。
平行坐标图可以显示出数据的分布和趋势,同时也可以发现不同维度之间的相互关系。
然而,当数据维度非常高时,平行坐标图可能会变得凌乱且难以理解。
3. 雷达图(Radar Chart)雷达图是一种用于显示多维空间数据的图表,它将数据的每个维度表示为一个射线,并将数据点连接在一起形成一个多边形。
雷达图可以直观地展示出数据的相对大小和分布情况,适用于比较不同数据集之间的差异。
然而,雷达图在处理大量数据或高维数据时可能会变得混杂和难以解读。
4. 树状结构图(Tree Map)树状结构图是一种用矩形块表示数据并形成树状结构的可视化方法。
每个矩形块的大小表示数据的某个维度,而矩形块的颜色可以用来表示其他维度的属性。
树状结构图可以帮助人们直观地了解数据的组织结构和层次关系。
然而,树状结构图对于多维空间数据的可视化可能不够直观和灵活。
大数据可视化1-6章课后习题答案
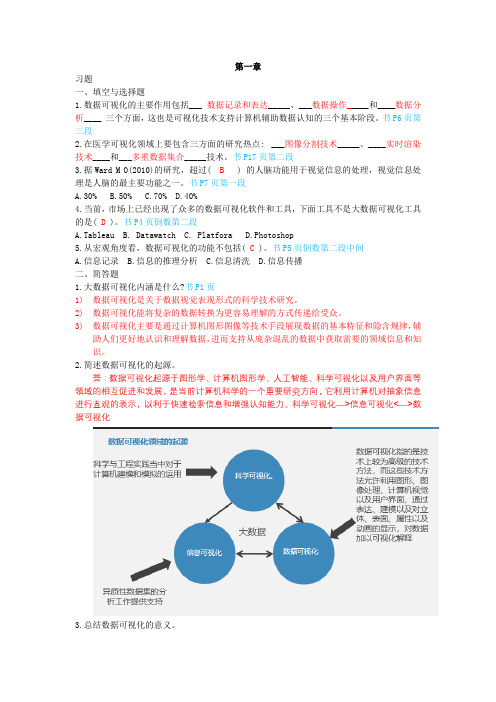
第一章习题一、填空与选择题1.数据可视化的主要作用包括___ 数据记录和表达_____、___数据操作_____和____数据分析____ 三个方面,这也是可视化技术支持计算机辅助数据认知的三个基本阶段。
书P6页第三段2.在医学可视化领域上要包含三方面的研究热点: ___图像分割技术_____、____实时渲染技术____和___多重数据集合_____技术。
书P17页第二段3.据Ward M O(2010)的研究,超过( B ) 的人脑功能用于视觉信息的处理,视觉信息处理是人脑的最主要功能之一。
书P7页第一段A.30%B.50%C.70%D.40%4.当前,市场上已经出现了众多的数据可视化软件和工具,下面工具不是大数据可视化工具的是( D )。
书P4页倒数第二段A.TableauB. DatawatchC. PlatforaD.Photoshop5.从宏观角度看,数据可视化的功能不包括( C )。
书P5页倒数第二段中间A.信息记录B.信息的推理分析C.信息清洗D.信息传播二、简答题1.大数据可视化内涵是什么?书P1页1)数据可视化是关于数据视觉表现形式的科学技术研究。
2)数据可视化能将复杂的数据转换为更容易理解的方式传递给受众。
3)数据可视化主要是通过计算机图形图像等技术手段展现数据的基本特征和隐含规律,辅助人们更好地认识和理解数据,进而支持从庞杂混乱的数据中获取需要的领域信息和知识。
2.简述数据可视化的起源。
答:数据可视化起源于图形学、计算机图形学、人工智能、科学可视化以及用户界面等领域的相互促进和发展,是当前计算机科学的一个重要研究方向,它利用计算机对抽象信息进行直观的表示,以利于快速检索信息和增强认知能力。
科学可视化—>信息可视化<—>数据可视化3.总结数据可视化的意义。
答:1)真(真实性):指是否正确地反映了数据的本质,以及对所反映的事物和规律有无正确的感受和认识。
2)善(倾向性):是可视化所表达的意象对于社会和生活具有什么意义和影响。
使用Matlab进行高维数据降维与可视化的方法

使用Matlab进行高维数据降维与可视化的方法数据降维是数据分析和可视化中常用的技术之一,它可以将高维数据映射到低维空间中,从而降低数据的维度并保留数据的主要特征。
在大数据时代,高维数据的处理和分析变得越来越重要,因此掌握高维数据降维的方法是一项关键技能。
在本文中,我们将介绍使用Matlab进行高维数据降维与可视化的方法。
一、PCA主成分分析主成分分析(Principal Component Analysis,PCA)是一种常用的降维方法,它通过线性变换将原始数据映射到新的坐标系中。
在新的坐标系中,数据的维度会减少,从而方便进行可视化和分析。
在Matlab中,PCA可以使用`pca`函数来实现。
首先,我们需要将数据矩阵X 传递给`pca`函数,并设置降维后的维度。
`pca`函数将返回一个降维后的数据矩阵Y和对应的主成分分析结果。
```matlabX = [1 2 3; 4 5 6; 7 8 9]; % 原始数据矩阵k = 2; % 降维后的维度[Y, ~, latent] = pca(X, 'NumComponents', k); % PCA降维explained_variance_ratio = latent / sum(latent); % 各主成分的方差解释比例```通过这段代码,我们可以得到降维后的数据矩阵Y,它的维度被减少为k。
我们还可以计算出每个主成分的方差解释比例,从而了解每个主成分对数据方差的贡献程度。
二、t-SNE t分布随机邻域嵌入t分布随机邻域嵌入(t-distributed Stochastic Neighbor Embedding,t-SNE)是一种非线性的高维数据降维方法,它能够有效地保留数据样本之间的局部结构关系。
相比于PCA,t-SNE在可视化高维数据时能够更好地展现不同类别之间的差异。
在Matlab中,t-SNE可以使用`tsne`函数来实现。
我们同样需要将数据矩阵X 传递给`tsne`函数,并设置降维后的维度。
2024版大数据导论数据可视化教案

化教案contents •数据可视化基本概念与意义•数据可视化基本原理与方法•大规模数据集处理与可视化挑战•经典案例分析与实践操作指导•数据可视化评估标准与未来发展趋势•课程总结与拓展资源推荐目录数据可视化基本概念与意义数据可视化定义及发展历程数据可视化定义发展历程数据可视化在大数据分析中应用价值快速识别模式和趋势通过可视化展示,可以快速发现数据中的模式和趋势。
提高决策效率直观的数据呈现可以帮助决策者更快地做出决策。
加强数据沟通可视化使得数据更易于被理解和交流,促进团队协作。
常见数据可视化工具与平台介绍功能强大的电子表格软件,内置多种图表类型,适合初学者使用。
专业的数据可视化工具,支持拖拽式操作和丰富的图表类型,适合进阶用户。
商业智能工具,支持数据可视化、报表和仪表盘等功能,适合企业用户。
JavaScript库,支持高度自定义的数据可视化,适合开发者使用。
Excel Tableau Power BI D3.js教学目标与要求01020304数据可视化基本原理与方法数据可视化感知原理数据到视觉元素的映射01感知的层次性02感知的群组性03色彩、形状、位置等视觉元素运用技巧形状运用色彩运用通过不同的形状来表示数据的不同类别和特征,如圆形、方形、三角形等。
位置运用常见图表类型及其适用场景分析01020304柱状图折线图散点图饼图以用户为中心,提供直观、易用的交互方式,使用户能够轻松地探索和理解数据。
交互式设计原则常见交互方式交互式可视化工具交互式可视化案例分析包括鼠标悬停、点击、拖拽、缩放等,以及多视图协同、过滤、排序等高级交互方式。
介绍常用的交互式可视化工具,如Tableau 、D3.js 、Echarts 等,并分析其优缺点和适用场景。
通过实际案例展示交互式可视化的应用效果和价值,如商业智能分析、社交媒体数据分析等。
交互式数据可视化方法探讨大规模数据集处理与可视化挑战大规模数据集特点及其处理挑战数据量大维度高数据质量不一计算资源有限降维技术在高维数据可视化中应用t-SNE 主成分分析(PCA)自定义降维方法UMAP类似,也是一种非线性降维方法,适用于大规模高维数据的可视化。