oracle数据泵
Docker-Oracle数据泵

Docker-Oracle数据泵Oracle总结1.概念,用户,表空间,表,用户拥有表空间,表空间可以有多个用户,表存在与表空间中2.给用户指定表空间--修改用户的表空间alter user username default tablespace userspace;--创建用户时给用户创建表空间create user username identified by userpassword default tablespace userspace;3.查看用户拥有的表空间select default_tablespace from dba_users where username='用户名'4.表空间拥有大小可以用以下命令查看表还有多少空间SELECT a.tablespace_name "表空间名",total "表空间大小",free "表空间剩余大小",(total - free) "表空间使用大小",total / (1024 * 1024 * 1024) "表空间大小(G)",free / (1024 * 1024 * 1024) "表空间剩余大小(G)",(total - free) / (1024 * 1024 * 1024) "表空间使用大小(G)",round((total - free) / total, 4) * 100 "使用率 %"FROM (SELECT tablespace_name, SUM(bytes) freeFROM dba_free_spaceGROUP BY tablespace_name) a,(SELECT tablespace_name, SUM(bytes) totalFROM dba_data_filesGROUP BY tablespace_name) b5.表空间可以扩容(对已有的表进行扩容)sqlplus / as sysdba--执行alter tablespace 表名add datafile '/data/oradbs/表名.dbf' size 4000m;6.Oracle导入导出数据如果数据量大,要使用数据泵,不然导入导出数据很花时间,按照以下命令进行数据的数据泵导出(服务端操作)数据泵文件导出创建数据泵导出数据路径进入数据库sqlplus /nolog以sysdba连接数据库connect /as sysdba创建数据泵文件的导出目录data_dir 可以自己命令,只要和下面的命令中directory保持一直即可create directory data_dir as 'E:\ora\data' ;执行该命令时需要退出数据库directory=【data_dir】要和上面创建目录时directory后面的名称一致expdp 用户名/密码@服务名schemas=用户名dumpfile=expdp.dmp directory=data_dir logfile=expdp.logexpdp [为用户名]/[密码]@[服务名]schemas=[为用户名]dumpfile=[导出数据库文件(可自命名)]directory=[目录名]logfile=[日志文件文件名(可自命名)]命令结束不需要加“;”•数据泵文件导入数据导入准备工作:在本地创建一个存放数据泵文件的路径linux系统为例:/usr/oracle同时将该文件的所属组和用户修改chown oracle:oinstall /usr/oracle如果进入容器后的默认用户没有修改文件的权限,切换到root用户修改su root管理员密码根据自己情况而定,我的容器的密码是helowin进入Docker的Oracle容器docker exec -it 容器名 /bin/bash进入容器后连接oraclesqlplus /nologconnect /as sysdba然后在oracle服务端中创建读取数据泵文件的路径,这些路径都要保持一致data_dirs(这个是创建的列明),【data_dirs】这个可以随意命名,比如【data_dirssss】,只要和接下来的sql语句中的相关字段保持一致即可,即括号前面标注的地方create directory data_dir as '/usr/oracle' ;data_dirs(跟上面名字保持一致),例子【data_dirssss】//给用户读写目录的权限Grant read,write on directory data_dir to 数据库用户名;data_dirs同理上面,例子【data_dirssss】创建数据泵文件所在文件,之后需要将数据泵文件放在该目录下create directory data_dirs as '\usr\oracle' ;数据泵文件导入directory 后面的【data_dirs】跟上面命名的要一致,例子【data_dirssss】impdp OASS1/OASS1@HELOWIN REMAP_SCHEMA = oass1:OASS1 table_exists_action = replace directory=data_dir dumpfile=EXPDP.DMP logfile=expdp.logimpdp [用户名]/[密码]@[服务名]REMAP_SCHEMA=[源用户名1]:[目标用户名2]table_exists_action=replace /存在的表动作(覆盖)/directory=[目录名]dumpfile=[.dmp文件名]logfile=[.log文件名]7.导入过程中可能存在字符集不同的异常,下面的命令可以将字符集统一oracle_11g编码修改SQL>SHUTDOWN IMMEDIATE;SQL>STARTUP MOUNT;SQL>ALTER SYSTEM ENABLE RESTRICTED SESSION;SQL>ALTER SYSTEM SET JOB_QUEUE_PROCESSES=0;SQL>ALTER SYSTEM SET AQ_TM_PROCESSES=0;SQL>ALTER DATABASE OPEN;SQL> ALTER DATABASE CHARACTER SET ZHS16GBK ;SQL>ALTER DATABASE CHARACTER SET INTERNAL_USE ZHS16GBK;SQL>SHUTDOWN IMMEDIATE;SQL>STARTUP;。
数据泵导出忽略表

数据泵导出忽略表数据泵是Oracle数据库中的一种工具,用于将数据库中的数据和对象导出到文件中。
在使用数据泵导出时,有时候我们希望只导出某些表,而忽略其他表。
本文将介绍如何使用数据泵导出并忽略指定的表。
在使用数据泵导出时,可以使用参数来指定要导出的对象。
其中,exclude参数可以用来指定要忽略的对象。
假设我们有一个名为"hr"的用户,该用户下有多个表,我们希望将除了"employees"表之外的所有表导出到文件中,可以按照以下步骤操作:1. 首先,打开命令行窗口,并使用sysdba权限登录到Oracle数据库。
可以使用以下命令登录:```sqlplus / as sysdba```2. 登录后,输入以下命令创建一个目录对象,用于存放导出文件。
假设我们将导出文件存放在"exp_dir"目录下:```CREATE DIRECTORY exp_dir AS '/path/to/export/directory';```请将"/path/to/export/directory"替换为实际的导出目录路径。
3. 创建完目录对象后,可以使用以下命令导出数据:```expdp hr DIRECTORY=exp_dir DUMPFILE=hr_export.dmp EXCLUDE=TABLE:"IN ('EMPLOYEES')"```其中,"hr"为要导出的用户,"hr_export.dmp"为导出文件名。
在EXCLUDE参数中,我们使用了TABLE:"IN ('EMPLOYEES')"来指定要忽略的表。
可以根据实际需求修改这些参数。
4. 执行上述命令后,数据泵将开始导出数据。
导出的进度和详细信息将显示在命令行窗口中。
Oracle数据泵的导入与导出实例详解

Oracle数据泵的导⼊与导出实例详解⽬录前⾔数据泵的导⼊数据泵的导出总结前⾔今天王⼦要分享的内容是关于Oracle的⼀个实战内容,Oracle的数据泵。
⽹上有很多关于此的内容,但很多都是复制粘贴别⼈的,导致很多⼩伙伴想要使⽤的时候不能直接上⼿,所以这篇⽂章⼀定能让你更清晰的理解数据泵。
开始之前王⼦先介绍⼀下⾃⼰的环境,这⾥使⽤的是⽐较常⽤的WIN10系统,Oracle数据库也是安装在本机上的,环境⽐较简单。
数据泵的导⼊导⼊的数据⽂件可能是别⼈导出给你的,也可能是你⾃⼰导出的,王⼦这⾥就是别⼈导出的,⽂件名字是YD.DMP。
在进⾏操作之前,⼀定要问清楚表空间名字,如果表空间命名不统⼀,可能会导致导⼊失败的问题。
所以第⼀步就是建⽴表空间,语句如下:create tablespace VIEWHIGHdatafile 'D:/app/admin/oradata/orcl/VIEWHIGH'size 1M autoextend on next 50M maxsize unlimited;这⾥的datafile路径⼀般选择你本地oracle的数据⽂件路径。
之后,我们可以建⽴⼀个新的⽤户来导⼊数据⽤,这个⽤户名也可以提前问好,最好⽤户名⼀致,否则需要做⼀次⽤户名的映射,这个我们下⽂再说。
建⽴⽤户语句如下:create user DRGS_INITidentified by "vhiadsh"default tablespace VIEWHIGHprofile DEFAULTACCOUNT UNLOCK;建⽴⽤户后需要给⽤户授权,语句如下:--给新建⽤户授DBA权限grant dba to DRGS_INIT;grant unlimited tablespace to DRGS_INIT;接下来我们需要在本地的磁盘中创建⼀个⽂件夹,作为数据泵⽂件夹来使⽤,同时把DMP⽂件放⼊到此⽂件夹下。
oracle利用数据泵备份以及导入数据

oracle利用数据泵备份以及导入数据一、EXPDP备份命令1.创建oracle的备份目录(一)连接数据库Sqlplus conn / as sysdba(二)创建备份目录create directory dpdata1 as 'D:\temp\dmp';(三)查看创建的备份目录select * from dba_directories;2.赋于要导出数据表的所属用户权限grant read,write on directory dpdata1 to rlqb;3.导出数据expdp rlqb/rlqb2014@orcl directory=dpdata1 dumpfile=rlqb.dmplogfile=rlqb.log schemas=rlqb其中Directory 为创建的备份目录Dumpfile 为导出的数据库名称Logfile 为导出的日志Schemas 为导出的数据库名4.导出特定的表导出表中的部分(query):expdp rlqb/rlqb2014 dumpfile=rlqb20130301_info.dmp directory=dpdata1 tables = info query= "' where create_date>to_date(''1981-01-0100:00:00'',''yyyy-mm-dd hh24:mi:ss'')'"注意:有单引号包含双引号导出多个表(tables):expdp rlqb/rlqb2014 dumpfile=rlqb20130301.dmp directory=dpdata1 tables = info, sysuser5.脚本备份数据forfiles /p "D:\workspace\back\databack" /d -7 /c "cmd /c echo deleting @file ... && del /f @path"cd D:\workspace\back\databackrem backup schemasset backupfile=rlqb_%date:~0,4%-%date:~5,2%-%date:~8,2%.dmpset logfile=rlqb_%date:~0,4%-%date:~5,2%-%date:~8,2%.logexpdp rlqb/rlqb2014 directory=dpdata1 dumpfile=%backupfile% logfile=%logfile% schemas=rlqb parallel=4其中forfiles /p "D:\workspace\back\databack" /d -7 /c "cmd /c echo deleting @file ... && del /f @path" 为清除7天的备份的数据负多少就清除几天前的数据如果没有可清除的数据则会报错,但不影响。
Oracle11gR2新特性数据泵实现数据备份与数据还原(e.
Oracle11gR2新特性数据泵实现数据备份与数据还原
一 expdp 数据备份
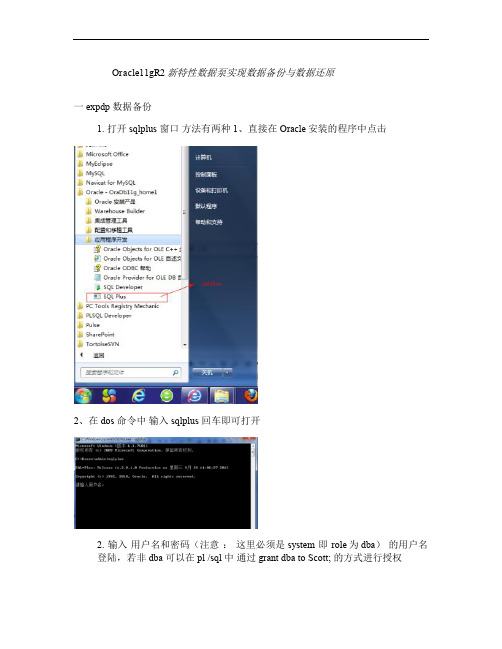
1. 打开sqlplus 窗口方法有两种 1、直接在Oracle安装的程序中点击
2、在dos 命令中输入 sqlplus 回车即可打开
2. 输入用户名和密码(注意:这里必须是system 即 role为dba)的用户名
登陆,若非dba 可以在pl /sql 中通过 grant dba to Scott; 的方式进行授权
3. 查询system 用户下的逻辑目录和真实目录: select * from dba_directories;
4. 为Scott 用户在在逻辑目录DATA_PUMP_DIR上有读写的权限
<5>、打开cmd,
执行expdp 'system/dreams as sysdba' directory= DATA_PUMP_DIR schemas=scott dumpfile=itsmuse20130705.dmp logfile=itsmuse20130705.log
注意:一定要是权限。
二、导入数据详细介绍(impdp)
1.cmd 命令打开 dos窗口
输入impdp ‘system/dreams as sysdba’ directory=DATA_PUMP_DIR SCHEMAS=scott dumpfile=itsmuse20130828.dmp logfile=itsmuse20130828.log 回车即可。
Oracle_数据泵命令导出导入dmp文件

Oracle_数据泵命令导出导⼊dmp⽂件1. oracle命令⾏登录sqlplus pms/pms 或者 connect / as sysdba2. 查询dup存放⽬录⽬录select * from dba_directories;注意:后⾯的E盘下⾯的dpdump\ 必须把你要导⼊的xxx.dmp⽂件放进该⽂件夹3. 执⾏命令直接导⼊impdp导⼊dmp(注意:必须要有导⼊导出的,可以直接给dba权限)该命令需要在cmd的dos命令窗⼝直接执⾏,⽽不是sqlplus.exefull=y 是导⼊⽂件中全部内容ignore=y相当于,如果没有的表,创建并倒⼊数据,如果已经有的表,忽略创建的,但不忽略倒⼊impdp pms/pms@localhost:1521/orcl dumpfile=pms.dmp full=y directory=DATA_PUMP_DIR3. 执⾏命令直接导出(导出位置为DATA_PUMP_DIR这个位置)expdp pms/pms@localhost:1521/orcl dumpfile=pms.dmp full=y directory=DATA_PUMP_DIR导出⽂件:查看建⽴的⽬录Select * from dba_directories删除⽂件DROP DIRECTORY EXPNC_DIR;赋权Grant read,write on directory wly_dump to wly;导出案例1,按表导出expdp wly/wly directory=wly_dump dumpfile=wly.dmp logfile=scott.log tables=dept,emp导出案例2,按⽤户导出expdp wly/wly directory=wly_dump dumpfile=wly.dmp schemas=wly导出案例3,全库导出,且并⾏导出expdp wly/wly directory=wly_dump dumpfile=full.dmp parallel=4 full=y导⼊案例1,按表导⼊,从wly到wly2impdp wly/wly directory=wly_dump dumpfile=tab.dmp tables=scott.dept,scott.emp remap_schema=wly:wly2导⼊案例2,按⽤户导⼊,从wly到wly2impdp wly/wly directory=wly_dump dumpfile=schema.dmp remap_schema=wly:wly2导⼊案例3,全库导⼊impdp wly/wlydirectory=wly_dump dumpfile=full.dmp full=y导⼊案例4,⽆落地⽂件的⽤户拷贝,需要建⽴db linkimpdp wly/wly directory=wly_dump network_link=remote_link remap_schema=wly:wly2。
Navicat for Oracle 如何导入数据泵
Navicat for Oracle 如何导入数据泵在运行Navicat for Oracle 数据泵导入前,点击“生成SQL”按钮检查SQL,然后点击运行按钮运行它,勾选“显示高级选项”框,显示隐藏的选项卡(高级选项)。
Navicat for Oracle 数据泵导入主要涉及到的知识点有:网络、筛选、重新映射、重新映射对象、常规属性和高级属性。
下面将由Navicat官网详细介绍Navicat for Oracle 如何导入数据泵。
Navicat for Oracle网络数据库链接:远程数据库的数据库链接名,这将是当前工作的数据和元数据源。
估计:指定开始工作之前,表大小运行的估计方法。
闪回SCN:系统改变编号(SCN)作为读取用户数据事务上的一致点。
闪回时间:决定读取用户数据的一致点的日期和时间或TO_TIMESTAMP(...)格式的字符串。
可传输:在一组选定的表空间,为表(和它们相依的对象)操作元数据来运行一个可传输的表空间导出。
数据文件路径:为在可传输的表空间集的数据文件指定完整文件的路径。
筛选包含或排除:从导入作业中选择“包含”或“排除”对象,选择“对象类型”并指定“名子句”。
查询:指定一个子查询添加到表SELECT 语句中的尾部,如果在子查询中指定WHERE 子句,可以限制要选择的行。
重新映射重新映射栏位描述表模式包含要重新映射的列的模式。
表名包含要重新映射的列的表。
列名要重新映射的列的名。
包模式包的模式。
包名包的名。
包函数一个PL/SQL包函数,用于指定列修改数据。
重新映射数据文件:指定一个应用到对象的重新映射,因为它们是在指定的工作中处理。
输入“源数据文件”和“目标数据文件”。
重新映射对象重新映射模式:指定一个应用到模式的重新映射,在指定的工作中处理。
输入“源模式”,选择“目标模式”。
重新映射表空间:指定一个应用到表空间的重新映射,在指定的工作中处理。
输入“源表空间”,选择“目标表空间”。
oracle数据泵导入导出命令
oracle数据泵导⼊导出命令1.在PL/SQL的界⾯,找到Directories⽂件夹,找到⽬录⽂件的路径2.通过SSH进⼊服务器找到相应的路径 cd /u01/oracle/dpdir输⼊指令df -h 查看资源使⽤量su – oracle 进⼊系统的oracle⽤户3.导出数据库⽂件expdp userid=hbcxjm/oracle directory=dpdir dumpfile=hbcxjm.dmp job_name=hbcxjm logfile=hbcxjmlog parallel=2 schemas=hbcxjmPS:其中userid是要导出的⽬标库的⽤户名密码,directory是建⽴的路径名称,dumpfile是⽬标⽂件名称4.新建数据库⽤户PS:注意表空间问题,确保表空间充⾜,否则导⼊会报错5.导⼊数据impdp hbcxjm/oracle directory=dpdir dumpfile=hbcxjm.dmp REMAP_SCHEMA=hbcxjm:hbcxjmREMAP_TABLESPACE=TP_HBCXJM:TP_HBCXJMtable_exists_action = truncate logfile=hbcxjmimp.log SCHEMAS=hbcxjmPS:REMAP_SCHEMA:导出数据⽤户的名称和导⼊数据⽤户的名称REMAP_TABLESPACE:导出数据⽤户的表空间和导⼊数据⽤户的表空间table_exists_action:如果表中有数据的处理⽅式,此处采⽤truncate处理logfile:⽇志⽂件名称例⼦:⽂件导出:expdp userid=hbcxjm/oracle directory=dpdir dumpfile=hbcxjm.dmp job_name=hbcxjm logfile=hbcxjmlog parallel=2 schemas=hbcxjmexpdp userid=drm_hbcxjm/oracle directory=dpdir dumpfile=drm_hbcxjm.dmp job_name=drm_hbcxjm logfile=drm_hbcxjmlog parallel=2 schemas=drm_hbcxjmexpdp userid=hbcxjm_report/oracle directory=dpdir dumpfile=hbcxjm_report.dmp job_name=hbcxjm_report logfile=hbcxjm_reportlog parallel=2 schemas=hbcxjm_reportexpdp userid=hbcxjm_siif/oracle directory=dpdir dumpfile=hbcxjm_siif.dmp job_name=hbcxjm_siif logfile=hbcxjm_siiflog parallel=2 schemas=hbcxjm_siifexpdp userid=hxpt3dd/oracle directory=dpdir dumpfile=hxpt3dd.dmp job_name=hxpt3dd logfile=hxpt3ddlog parallel=2 schemas=hxpt3dd expdp userid=drm_hxpt3dd/oracle directory=dpdir dumpfile=drm_hxpt3dd.dmp job_name=drm_hxpt3dd logfile=drm_hxpt3ddlog parallel=2 schemas=drm_hxpt3dd⽂件导⼊:impdp hbcxjm/oracle directory=dpdir dumpfile=hbcxjm.dmp REMAP_SCHEMA=hbcxjm:hbcxjmREMAP_TABLESPACE=TP_HBCXJM:TP_HBCXJM table_exists_action = truncate logfile=hbcxjmimp.log SCHEMAS=hbcxjmimpdp drm_hbcxjm/oracle directory=dpdir dumpfile=drm_hbcxjm.dmp REMAP_SCHEMA=drm_hbcxjm:drm_hbcxjmREMAP_TABLESPACE=TP_HBCXJM_DRM:TP_HBCXJM_DRM table_exists_action = truncate logfile=drm_hbcxjmimp.logSCHEMAS=drm_hbcxjmimpdp hbcxjm_report/oracle directory=dpdir dumpfile=hbcxjm_report.dmp REMAP_SCHEMA=hbcxjm_report:hbcxjm_reportREMAP_TABLESPACE=TP_HBCXJM_DRM:TP_HBCXJM_DRM table_exists_action = truncate logfile=hbcxjm_reportimp.logSCHEMAS=hbcxjm_reportimpdp hbcxjm_siif/oracle directory=dpdir dumpfile=hbcxjm_siif.dmp REMAP_SCHEMA=hbcxjm_siif:hbcxjm_siifREMAP_TABLESPACE=TP_HBCXJM:TP_HBCXJM table_exists_action = truncate logfile=hbcxjm_siifimp.log SCHEMAS=hbcxjm_siif impdp hxpt3dd/oracle directory=dpdir dumpfile=hxpt3dd.dmp REMAP_SCHEMA=hxpt3dd:hxpt3ddREMAP_TABLESPACE=TP_HBCXJM_YBDD:TP_HBCXJM_YBDD table_exists_action = truncate logfile=hxpt3ddimp.log SCHEMAS=hxpt3dd impdp drm_hxpt3dd/oracle directory=dpdir dumpfile=drm_hxpt3dd.dmp REMAP_SCHEMA=drm_hxpt3dd:drm_hxpt3ddREMAP_TABLESPACE=TP_HBCXJM_YBDD:TP_HBCXJM_YBDD table_exists_action = truncate logfile=drm_hxpt3ddimp.logSCHEMAS=drm_hxpt3dd。
数据泵导入建表
数据泵导入建表数据泵是Oracle数据库中的一个重要工具,通过该工具可以将数据从一个数据库传输到另一个数据库,同时还可以通过数据泵将数据库中的数据导出,并保存为一个文件,以备日后使用。
数据泵还可以被用来对表进行导入、导出和重建等操作。
在这篇文章中,我们将介绍如何使用数据泵导入建表。
步骤一:导出数据文件在进行数据导入之前,我们需要先将数据从源数据库导出。
可以使用数据泵的expdp命令将数据导出为一个dump文件。
例如,通过以下命令将指定的数据导出到个人电脑的F盘根目录:expdp system/oracle@orcl schemas=scottdumpfile=f:\scott.dmp其中,system/oracle是登录源数据库的用户名和密码;orcl是源数据库的服务名,schemas参数指定了要导出的Schema;dumpfile 指定了dump文件的保存路径和文件名。
步骤二:创建目录导出数据后,我们需要使用Oracle的SQL命令创建一个导入目录,以便在接下来的步骤中使用。
例如:SQL> create directory imp_dir as 'f:\';其中,imp_dir是导入目录的名称,f:\是导出的dump文件的保存路径。
步骤三:导入数据一旦目录被创建之后,我们就可以使用数据泵的impdp命令将数据导入到目标数据库中。
例如:impdp system/oracle@orcl directory=imp_dirdumpfile=scott.dmp schemas=scott remap_schema=scott:scott1 在此命令中,system/oracle是目标数据库的用户名和密码;orcl是目标数据库的服务名;directory指定了导入目录的名称;dumpfile指定了导出的dump文件的名称;schemas参数指定了要导入的schema;remap_schema参数可以让我们将导出时原本的schema名称修改为新的名称。
oracle data pump的一般体系结构
一、介绍Oracle Data Pump是Oracle数据库中用于将数据和元数据从一个数据库导出到另一个数据库的工具。
它是一个非常强大和灵活的工具,可以用来在不同的数据库之间迁移数据,备份和恢复数据,以及进行数据库升级和复制等操作。
二、主要组成部分1. 数据泵作业(Data Pump Job):数据泵作业是数据泵操作的一个实例,它包含了所有需要导出或导入的数据和元数据的信息,以及执行数据泵操作的参数和选项。
2. 数据泵进程(Data Pump Process):数据泵进程是实际执行数据泵操作的进程,它负责读取源数据库中的数据和元数据,并将其写入到目标数据库中。
数据泵进程通常以后台进程的形式存在,可以由数据泵作业来启动和管理。
3. 数据泵引擎(Data Pump Engine):数据泵引擎是数据泵作业的核心组成部分,它负责解析数据泵作业中的参数和选项,调度数据泵进程来执行具体的数据导出和导入操作。
4. 数据泵文件(Data Pump File):数据泵文件是数据泵操作中的重要存储介质,它可以用来存储导出的数据和元数据,以及在导入数据时用作数据源。
数据泵文件通常以二进制格式存储,可以包括数据泵作业的日志、导出的数据文件、导出的元数据文件等。
三、数据泵的工作流程1. 创建数据泵作业:在进行数据泵操作之前,首先需要创建一个数据泵作业,指定需要导出或导入的数据和元数据的信息,以及执行数据泵操作的参数和选项。
2. 启动数据泵作业:一旦数据泵作业创建完成,就可以通过Oracle Data Pump工具或者PL/SQL包来启动数据泵作业,数据泵引擎会根据作业中的参数和选项来调度数据泵进程来执行具体的数据导出和导入操作。
3. 执行数据泵操作:数据泵引擎会根据作业中的参数和选项来调度数据泵进程来执行具体的数据导出和导入操作,数据泵进程会读取源数据库中的数据和元数据,并将其写入到目标数据库中。
4. 完成数据泵作业:一旦所有的数据导出和导入操作全部完成,数据泵作业就会进入完成状态,数据泵引擎会生成数据泵作业的日志,并将其存储到数据泵文件中,以便后续的查看和分析。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
时代朝阳Oracle DBA职业培训课程才能展示(Talent Show) 北京时代朝阳数据库技术中心
character set
编码模式 单字节(7bit) 双字节(8bit) 固定长度多字节 可变长度的单字节 可变长度的多字节 示例 US7ASCII,非IBM系统中oracle默认字符集 YUG7ASCII WE8ISO8859P15,西欧8bit标准字符集 WE8DEC,DEC公司开发 AL16UTF16,双字节的Unicode字符集 UTF8, Unicode字符集,字符为1-4个字节 UTF16,字符为1-6个字节 JA16SIS:基于日语的字符集 ZHT16CCDC:传统中文字符集,最高位指示是单字节还是双字 节 AL32UTF8: 可变的Unicode字符集 图(1)
ORACLE数据泵
5, estimate
指定估算被导出表所占用磁盘空间分方法.默认值是BLOCKS,
6, job_name
指定要导出作用的名称
7,network_link
允许网络导入,就是通过数据库链接连接到预定义的源数据库 除此之外还有很多参数选项,可以输入expdp help=y和impdp help=y查询
时代朝阳Oracle DBA职业培训课程才能展示(Talent Show) :
Windows2003 oracle 10.2.0.1 字符集UTF8,国家字符集AL16UTF16
平台2:
Hp unix oracle 10.2.0.1 字符集ZHS16GBK,国家字符集AL16UTF16
时代朝阳Oracle DBA职业培训课程才能展示(Talent Show) 北京时代朝阳数据库技术中心
数据泵实践操作
9 libmgr用户导完后会报错,角色未创建,需要自己在节点1查询角色权限,然后 手工创建. 10 数据导入后,配置节点2的监听,IP后 在客户端建立服务,用libmgr软件登陆,查看数据,可以看到数据已经传送过 来,能够正常使用
时代朝阳Oracle DBA职业培训课程才能展示(Talent Show) 北京时代朝阳数据库技术中心
ORACLE数据泵
2, content
Expdp提供三种提取数据库的方法 ALL 包括数据库中的元数据和数据 DATA_ONLY 数据库中的数据 METADATA_ONLY 元数据 元数据 – 对象定义(如表和索引的创建语句) 像exp要导出数据库的结构,需要把rows参数设置为n exp system/manager full=y rows=n file=E:\expdp\myfull1.dmp log=E:\expdp\mylog.txt
时代朝阳Oracle DBA职业培训课程才能展示(Talent Show) 北京时代朝阳数据库技术中心
时代朝阳Oracle DBA职业培训课程才能展示(Talent Show) 北京时代朝阳数据库技术中心
character set
时代朝阳Oracle DBA职业培训课程才能展示(Talent Show) 北京时代朝阳数据库技术中心
数据泵实践操作
6 把数据传到平台2 注意这里需要二进制传送,不然会报错,从windows传送到unix还是unix传到 windows都一样 7 在平台二建立目录 create directory pump_dir as '/home/oracle/pump_dir'; 前提操作系统存在这样目录 8 导入平台1生成的完全数据库 impdp system/oracle dumpfile=pump_dir:MYDB_01.DAT nologfile=y job_name=rebert full=y 用户导入 impdp system/oracle dumpfile=pump:LIBMGR_02.DAT schemas=scott 表空间 impdp system/oracle dumpfile=pump_dir:TS_LIBMGR_TBS_01.DAT tablespaces=ts_libmgr table_exists_action=replace
字符集
分单字节 又分7bits,8bits 多字节固定长度多字节 多字节
国家字符集 在8.0版本引入了,是数据库创建阶段所指定的第二 个字符集,存储nvarchar2,nclob,nchar数据类型的数据,在9i 版本后,只能设置AL16UTF16和UTF8两种 Unicode字符集 Unicode标准是用于字符编码的国际标准,包含 任何计算机系统需要的所有字符. 假如要支持多种语言的数据库,可以使用Unicode字符集的数据 库字符集,此时支持选项有UTF8和AL32UTF8
ORACLE数据泵
Chenmo
时代朝阳Oracle DBA职业培训课程才能展示(Talent Show) 北京时代朝阳数据库技术中心
ORACLE数据泵
Oracle数据库迁移方法
1, 移植实用程序(MigrationUtility) 2, Oracle数据移植助理 (OracledataMigrationAssistant) 3,(Export/Import)或者数据泵 4, SQl*Loader工具 5, SQL*PLUSCOPY命令 6, PowerBuilder数据管道工具(Pipeline)
时代朝阳Oracle DBA职业培训课程才能展示(Talent Show) 北京时代朝阳数据库技术中心
ORACLE数据泵
数据泵的作用
1,实现逻辑备份和逻辑恢复. 2,在数据库用户之间移动对象. 3,在数据库之间移动对象. 4,实现表空间迁移.
时代朝阳Oracle DBA职业培训课程才能展示(Talent Show) 北京时代朝阳数据库技术中心
时代朝阳Oracle DBA职业培训课程才能展示(Talent Show) 北京时代朝阳数据库技术中心
数据泵实践操作
5 其它方式导出 导出用户 expdp system/manager dumpfile=pump_dir:libmgr_%U.dat schemas=libmgr nologfile=y job_name=just_libmgr 特定的表 expdp system/manager dumpfile=pump_dir:libmgr_tables_%U.dat tables=libmgr.auths,libmgr.subject nologfile=y 表空间 expdp system/manager dumpfile=pump_dir:ts_libmgr_tbs_%U.dat tablespaces=ts_libmgr nologfile=y job_name=ts_libmgr_tbs_exp
时代朝阳Oracle DBA职业培训课程才能展示(Talent Show) 北京时代朝阳数据库技术中心
ORACLE数据泵
EXPDP部分命令行选项
Expdp help=y寻求命令行帮助 1, attach
该选项用于在客户会话与已存在导出作用之间建立关联.语法如下 ATTACH=[schema_name.]job_name 如果使用ATTACH选项,在命令行除了连接字符串和ATTACH选项外, 不能指定任何其他选项,示例如下 Expdp scott/tiger ATTACH=scott.export_job
4, dumpfile
用于指定转储文件的名称 Expdp scott/tiger DIRECTORY=pump_dir DUMPFILE=dump1.dmp Expdp scott/tiger DUMPFILE=pump_dir:dump1.dmp
时代朝阳Oracle DBA职业培训课程才能展示(Talent Show) 北京时代朝阳数据库技术中心
时代朝阳Oracle DBA职业培训课程才能展示(Talent Show) 北京时代朝阳数据库技术中心
Data Pump的体系结构
用户会话
启动或者监视
DMnn
状态队列
作业 DWnn
控制队列
Data Pump生成的文件具有三种形式
SQL文件,描述指定作业所包含对象的若干DDL语句 转储文件,包含导出的数据 日志文件,作业运行的历史
时代朝阳Oracle DBA职业培训课程才能展示(Talent Show) 北京时代朝阳数据库技术中心
ORACLE数据泵
3, directory
指定转储文件和日志文件所在的目录, 需要先在sqlplus里执行创建命令,然后才能使用目录 create directory pump_dir as 'e:\expdp\pump_dir';
ORACLE数据泵
数据泵的特点与传统导出导入的区别
1, EXP和IMP是客户段工具程序, EXPDP和IMPDP是服务端的 工具程序 2, EXP和IMP效率比较低. EXPDP和IMPDP效率高
直接路径,导入导出在服务器端,可以并行,优化默认参数, 不过数据泵支持 NETWORK_LINK参数
3,数据泵功能强大并行,过滤,转换,压缩,加密,交互等等 4,数据泵不支持9i以前版本, EXP/IMP短期内还是比较适用. 5,同exp/imp数据泵导出包括导出表,导出方案,导出表空间,导 出数据库4种方式.
时代朝阳Oracle DBA职业培训课程才能展示(Talent Show) 北京时代朝阳数据库技术中心
数据泵实践操作
实验一几种数据库导出导入方式的操作
1 从平台1执行libmgr.sql语句,创建libmgr用户和一些表数据等 2 创建目录 create directory pump_dir as 'e:\expdp\pump_dir'; grant read on directory pump_dir to libmgr; 假如有需要可以限制某用户只有读权限,就是只能导入 3 导出的完整数据库 expdp system/manager dumpfile=pump_dir:mydb_%U.dat filesize=100m nologfile=y job_name=rebert full=y 假如不是system用户,导入导出需要权限 grant exp_full_database to libmgr grant imp_full_database to libmgr