Combining Shared and Distributed Memory Programming Models on Clusters of Symmetric Multipr
memory分离式方案

memory分离式方案随着计算机技术的不断发展,人们对于计算机性能的需求也越来越高。
尤其是在大数据、人工智能等领域的应用中,对于计算机的内存需求也越来越大。
为了满足这种需求,研究人员提出了一种名为memory分离式方案的新技术。
所谓memory分离式方案,即将计算机的内存分为多个层次,每个层次具有不同的特性和性能。
这样一来,就可以根据不同的应用场景和需求,选择合适的内存层次来提供更高效的计算和存储能力。
在memory分离式方案中,通常将内存分为三个层次,分别是L1缓存、主内存和辅助存储器。
L1缓存是位于CPU内部的高速缓存,它具有很高的访问速度,但容量较小。
主内存是计算机中较大的内存空间,可以存储更多的数据,但访问速度相对较慢。
辅助存储器则是指硬盘、固态硬盘等外部存储设备,容量更大,但访问速度更慢。
在memory分离式方案中,数据的访问是按照层次进行的。
首先,CPU会先在L1缓存中查找需要的数据,如果找不到,则会从主内存中获取。
如果主内存中也没有需要的数据,则需要从辅助存储器中读取。
这样一来,就可以充分利用不同层次内存的特性,提高计算机的整体性能。
除了提高计算机性能外,memory分离式方案还具有其他一些优点。
首先,通过将内存分为多个层次,可以节省成本。
因为L1缓存的成本较高,而主内存和辅助存储器的成本相对较低。
通过合理配置内存层次,可以在保证性能的同时降低成本。
其次,memory分离式方案还可以提高能效。
由于L1缓存的访问速度快,可以减少CPU 等待数据的时间,从而提高能效。
然而,memory分离式方案也存在一些挑战和限制。
首先,需要进行复杂的硬件设计和软件优化。
由于涉及到多个层次的内存,需要设计合适的缓存机制和访问策略,以及相应的软件算法和优化方法。
其次,内存的层次划分和数据迁移也需要合理规划。
不同层次的内存之间的数据迁移需要耗费一定的时间和资源,需要合理规划和管理。
memory分离式方案是一种提高计算机性能和能效的重要技术。
memory allocation policy 内存分配策略 -回复

memory allocation policy 内存分配策略-回复什么是内存分配策略?内存分配策略是指计算机系统在运行程序时,将可用的内存资源分配给各个程序或者进程的一种方法。
内存分配策略的合理性直接影响到系统的性能和稳定性。
在设计内存分配策略时,需要考虑多个因素,如程序的内存需求、内存空间的使用效率、内存分配和释放的开销等等。
为什么需要内存分配策略?计算机系统通常具有有限的物理内存,而程序的内存需求往往是不确定的。
如果没有恰当的内存分配策略,系统可能会出现内存不足或者内存浪费的情况。
内存不足会导致程序无法正常运行,甚至导致系统崩溃。
而内存浪费则会导致系统的资源利用率下降,造成性能损失。
常见的内存分配策略有哪些?1. 固定分区分配在固定分区分配策略中,物理内存被分为若干个固定大小的分区,每个分区可以分配给一个程序或者进程使用。
每个分区只能被一个程序独占,即使分区内部有空间未被完全利用,其他程序也无法使用。
这种策略简单且易于实现,但会导致内存浪费和碎片问题。
2. 动态分区分配动态分区分配策略中,物理内存被划分为若干个可变大小的分区,每个分区可以被一个程序使用。
当一个程序需要内存时,系统会根据其大小为其分配合适的分区。
这种策略可以更有效地利用内存空间,但会带来内存碎片的问题。
3. 页式分配在页式分配策略中,物理内存和逻辑内存被划分为固定大小的页。
当一个程序需要内存时,系统会将其逻辑内存划分为若干个页,并将这些页分配给物理内存中的空闲页帧。
这种策略可以有效地管理内存,但会导致内存访问相对较慢。
4. 段式分配在段式分配策略中,程序的内存需求被划分为若干个段,每个段可以被分配到不连续的物理内存空间中。
这种策略可以更好地满足不同程序的内存需求,但会带来外部碎片的问题。
5. 段页式分配段页式分配策略是段式分配策略和页式分配策略的结合,将逻辑内存划分为若干个段,每个段再划分为若干个页。
这种策略综合了段式分配策略和页式分配策略的优点,既可以满足不同程序的内存需求,又可以提高内存管理的效率。
PaperStream Capture Pro 产品说明书

Work better,faster andsmarterOptimise your business processes with our powerful, user-friendly, end-to-end capture solutionFor organisations that depend on paper-based processes, PaperStream Capture Pro is the scanning, extracting and releasing software that enables you to digitise your paper-based data in order to optimise your information flow and knowledge sharing. With PaperStream Capture Pro, you can:• Improve workflows• Increase efficiency• Achieve easier compliance• Gain better visibility• Perform with greater agility• Enhance customer experiencesTHE SMARTER SOLUTIONFOR PROGRESSINGFROM PAPER TO DIGITAL PROCESSESUsed with Fujitsu’s fi Series document scanners, PaperStream Capture Pro enables you to automatically and reliably convert documents to a digital format through a four-step process:• Scanning• Verification• Extracting and indexing• ReleasingOnce in a digital format, you can release the data into a downstream process – targeting archives, knowledge bases or bining comprehensive driver, powerful image optimisation and full featured capture software, PaperStream Capture Pro allows you to:• Manage and control information capture workflows • Automate and streamline processes• Reduce time and manual input to be more costeffective• Improve speed of access to information• Expand sharing of knowledge• Integrate into any workflowIMPROVE YOUR SOLUTION WITH PAPERSTREAM CAPTURE PROThe PaperStream Capture family is designed to meet the needs of every type of application. PaperStream Capture Pro can scale from one to multiple workstations, making it a suitable solution for small and medium sized businesses (SMBs)right up to enterprise clients.The businessadvantage with PaperStream Capture ProCombining PaperStream Capture Pro with Fujitsu’s industry-leading scanner technology puts your business in the fast lane. From simple set up to scanning and releasing, PaperStream Capture Pro enables you to:• Improve productivity with better processesthroughout• Ensure compliance with records securityand accessibility• Decrease paper dependency and increaselocation and outsourcing flexibility• Reduce data entry costs• See and control investment costs witha flat fee perpetual licence scheme• Scale from one to multiple workstationsTHE BENEFITSTHAT STRENGTHENYOUR OPERATIONSaving time, ensuring accuracy and optimising image quality throughout the entire capture process, PaperStream Capture Pro integrates our driver and image enhancement technology – PaperStream IP. This streamlines the process, not just while scanning, but also during the import of legacy files and even after scanning for post-scan corrections.OPTIMAL LICENSINGWITH MAINTENANCESUPPORT INCLUDEDUnlike most other professional capture software, the cost of your software does not increase with your scan volume. Whether you scan 1 million or 50 million documents, your cost remains the same.Best-in-class image processing: Automatic image optimisationPaperStream IP cleans images for improved downstream processingFast review and correctionImages can be adjusted without re-scanning Powerful and intuitive user experience: Create user profilesOne-click operationVersatile batch processingConsolidate images from multiple sources – scan and/or import image filesDocument separation:Basic zonal OCRFixed pageBlank pageBarcodePatch codeData extraction:Manual – Key From Image (KFI)Zonal OCR – machine print (multiple fields) Rubberband OCR for ad-hoc jobs Barcodes (multiple fields)Document and data validation:Regular expression validationRequired fieldsRead-only fieldsDatabase lookupCharacter masking (ODBC)System dataRelease:Creation of TIF, JPEG, PDF and searchable PDF formats(including PDF/A)Releases data as XML, CSV and TXTReleases index data to a folder, network folder or FTPReleases to SharePointLicenses and purchase:No cost-per-click or by volumeSeparate QC/Index and Import licences availableSingle or multi-station operation– /scannersPFU (EMEA) LimitedUKGermanyItalySpainHayes Park Central, Hayes End Road, Hayes, Middlesex UB4 8FE, EnglandFrankfurter Ring 211, 80807 München, GermanyViale Monza 259, 20126 Milano, ItalyCamino Cerro de los Gamos, 1, 28224 Pozuelo de Alarcón, Madrid, Spain+44 (0)20 8573 4444+49 (0)89 32378 0+39 02 2694 1+34 91 784 90 00。
并行计算的基本原理

并行计算的特点
为利用并行计算,通常计算问题表现为以下特征: 为利用并行计算,通常计算问题表现为以下特征: (1)将工作分离成离散部分,有助于同时解决; )将工作分离成离散部分,有助于同时解决; (2)随时并及时地执行多个程序指令; )随时并及时地执行多个程序指令; (3)多计算资源下解决问题的耗时要少于单个计算资源下的耗时。 )多计算资源下解决问题的耗时要少于单个计算资源下的耗时。 并行计算是相对于串行计算来说的, 并行计算是相对于串行计算来说的,所谓并行计算分为时间上的并行和 空间上的并行。 时间上的并行就是指流水线技术, 空间上的并行。 时间上的并行就是指流水线技术,而空间上的并行则是指用 多个处理器并发的执行计术语(2)
Shared Memory(共享内存): ):完全从硬件的视角来描述计算机体系 (共享内存): 结构,所有的处理器直接存取通用的物理内存(基于总线结构)。在 编程的角度上来看,他指出从并行任务看内存是同样的视图,并且能 够直接定位存取相同的逻辑内存位置上的内容,不管物理内存是否真 的存在。 Symmetric Multi-Processor(对称多处理器): ):这种硬件体系结构 (对称多处理器): 是多处理器共享一个地址空间访问所有资源的模型;共享内存计算。 Distributed Memory(分布式存储): ):从硬件的角度来看,基于网络 (分布式存储): 存储的物理内存访问是不常见的。在程序模型中,任务只能看到本地 机器的内存,当任务执行时一定要用通信才能访问其他机器上的内存 空间。 Communication:并行任务都需要交换数据。有几种方法可以完成, : 例如:共享内存总线、网络传输,然而不管用什么方法,真实的数据 交换事件通常与通信相关。 Synchronization:实时并行任务的调度通常与通信相关。总是通过 : 建立一个程序内的同步点来完成,一个任务在这个程序点上等待,直 到另一个任务到达相同的逻辑设备点是才能继续执行。同步至少要等 待一个任务,致使并行程序的执行时间增加。
managed_shared_memory工作原理

managed_shared_memory工作原理managed_shared_memory 是一个内存分配器,允许多个进程在共享内存中动态分配和管理对象。
它提供了一个容器类 managed_shared_memory 来存储和操作对象,使得多个进程可以通过共享内存进行数据交换和共享。
1.创建共享内存:首先,需要调用 create_or_open 函数,以创建或打开一个共享内存对象。
每个进程都可以通过这个函数来获取一个指向共享内存的唯一标识符。
2.分配和释放内存:在共享内存中,可以使用标准的内存分配方式来动态分配和释放内存。
managed_shared_memory 对象提供了 alloc 和 dealloc 函数来完成这些操作。
通过 alloc 函数,可以在共享内存中分配指定大小的内存空间,并返回一个指向该内存空间的指针。
该空间可以存储任意类型的对象。
通过 dealloc 函数,可以释放先前分配的内存空间,并在共享内存中回收这些空间。
管理共享内存对象的最后一个进程负责调用 dealloc函数来释放共享内存。
3.构造和析构对象:在共享内存中,可以调用对象的构造函数和析构函数来创建和销毁对象。
这是通过使用共享内存的分配器来实现的。
通过使用分配器,可以在共享内存中创建对象,并在不同的进程之间共享这些对象。
例如,可以使用共享内存在多个进程中创建一个共享数组,这样所有进程都可以访问和修改这个数组。
4.同步和互斥:在多进程环境中,共享内存的访问需要进行同步和互斥操作,以防止数据的不一致性和竞争条件。
此外,还可以使用条件变量来实现进程之间的通信和同步。
条件变量允许进程在满足特定条件之前等待,并在条件满足后唤醒等待的进程。
总的来说,managed_shared_memory 提供了一种方便的方式来实现多个进程之间的数据共享和交换。
它通过使用共享内存、内存分配、对象构造和析构、同步和互斥机制等核心功能来实现多进程之间的数据共享。
ANSYS GPU加速器支持列表说明书
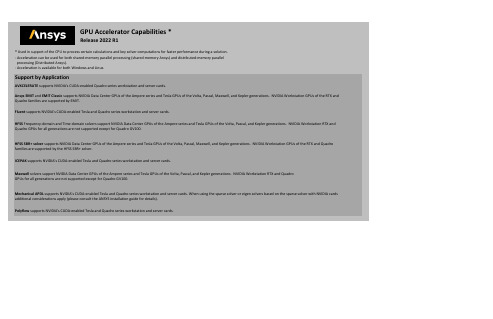
Maxwell solvers support NVIDIA Data Center GPUs of the Ampere series and Tesla GPUs of the Volta, Pascal, and Kepler generations. NVIDIA Workstation RTX and QuadroGPUs for all generations are not supported except for Quadro GV100.Mechanical APDL supports NVIDIA's CUDA-enabled Tesla and Quadro series workstation and server cards. When using the sparse solver or eigen solvers based on the sparse solver with NVIDIA cardsadditional considerations apply (please consult the ANSYS installation guide for details).Polyflow supports NVIDIA's CUDA-enabled Tesla and Quadro series workstation and server cards. **************************GPU Accelerator Capabilities * ***************************Release 2022 R1* Used in support of the CPU to process certain calculations and key solver computations for faster performance during a solution. - Acceleration can be used for both shared-memory parallel processing (shared-memory Ansys) and distributed-memory parallelx processing (Distributed Ansys).- Acceleration is available for both Windows and Linux. Support by ApplicationAVXCELERATE supports NVIDIA's CUDA-enabled Quadro series workstation and server cards.Ansys EMIT and EMIT Classic supports NVIDIA Data Center GPUs of the Ampere series and Tesla GPUs of the Volta, Pascal, Maxwell, and Kepler generations. NVIDIA Workstation GPUs of the RTX andQuadro families are supported by EMIT.Fluent supports NVIDIA's CUDA-enabled Tesla and Quadro series workstation and server cards.HFSS Frequency-domain and Time-domain solvers support NVIDIA Data Center GPUs of the Ampere series and Tesla GPUs of the Volta, Pascal, and Kepler generations. NVIDIA Workstation RTX andQuadro GPUs for all generations are not supported except for Quadro GV100.HFSS SBR+ solver supports NVIDIA Data Center GPUs of the Ampere series and Tesla GPUs of the Volta, Pascal, Maxwell, and Kepler generations. NVIDIA Workstation GPUs of the RTX and Quadrofamilies are supported by the HFSS SBR+ solver.ICEPAK supports NVIDIA's CUDA-enabled Tesla and Quadro series workstation and server cards.Cards Tested **The following NVIDIA Cards have been tested by Ansys, Inc.Application Card / GPU Tested PlatformTested Operating System Version Notes A100Windows x64Windows Server 2019A5000Linux x64Red Hat 7.8A6000Windows x64Windows Server 2019GP100Windows x64Windows 10GV100Linux x64Red Hat 8.2K40M Windows x64Windows Server 2016K80Windows x64Windows Server 2019M4000Winodws x64Windows 10P40Windows x64Windows Server 2019P100Windows x64Windows Server 2016P4000Windows x64Windows 10RTX 6000Windows x64Windows Server 2016RTX 8000Linux x64CentOS 7.7V100Windows x64Windows Server 2019P5200Windows x64Windows 10RTX 5000Windows x64Windows 10RTX 6000Windows x64Windows 10Linux x64CentOS 7.9RTX A5000Windows x64Windows 10GV100Linux x64Red Hat 8.4P4000Windows x64Windows 10Linux x64Red Hat 7.7Red Hat 8.4RTX 4000Windows x64Windows 10Linux x64Red Hat 8.4RTX 6000Windows x64Windows 10Linux x64SLES 12 SP5RTX 8000Windows x64Windows 10RTX A4000Linux x64Red Hat 7.8RTX A6000Linux x64Red Hat 8.3EMIT and EMIT Classic FluentAVXCELERATEA100Windows x64Windows Server 2019Linux x64CentOS 8.3GV100Linux x64CentOS 8.4K80Windows x64Windows Server 2019Linux x64CentOS 7.7 P40Windows x64Windows Server 2016Linux x64CentOS 8.1 P100Windows x64Windows Server 2016Linux x64CentOS 7.9RTX 6000Windows x64Windows Server 2019 RTX A6000Windows x64Windows Server 2019 V100Windows x64Windows Server 2019Linux x64CentOS 8.3A1001Windows x64Windows Server 2019Linux x64CentOS 8.3GV100Linux x64CentOS 8.4K80Windows x64Windows Server 2019Linux x64CentOS 7.7 P40Windows x64Windows Server 2016Linux x64CentOS 8.1 P100Windows x64Windows Server 2016Linux x64CentOS 7.9P4000Linux x64CentOS 8.1RTX 6000Windows x64Windows Server 2019 RTX 8000Linux x64CentOS 7.7RTX A6000Windows x64Windows Server 2019 V100Windows x64Windows Server 2019Linux x64CentOS 8.31 Incompatible with surface roughness solver.HFSS (Frequency-domain solver, Time-domainsolver)HFSS SBR+ solverGV100Linux x64Red Hat 8.2K80Windows x64Windows Server 2019K4000Windows x64Windows 10M4000Windows x64Windows 10Linux x64CentOS 7.9P40Windows x64Windows Server 2019P100Windows x64Windows Server 2016RTX 6000Linux x64SLES 15 SP1RTX A6000Windows x64Windows Server 2019V100Windows x64Windows Server 2019Linux x64CentOS 7.7A100Windows x64Windows Server 2019Linux x64CentOS 8.3GV100Linux x64CentOS 8.4K80Windows x64Windows Server 2019Linux x64CentOS 7.7P40Windows x64Windows Server 2016Linux x64CentOS 8.1P100Windows x64Windows Server 2016Linux x64CentOS 7.9RTX A6000Windows x64Windows Server 2019RTX 6000Windows x64Windows Server 2019V100Windows x64Windows Server 2019Linux x64CentOS 8.3A30Linux x64Red Hat 7.8A100Windows x64Windows Server 2019Linux x64Red Hat 7.8A4000Linux x64Red Hat 7.8A5000Linux x64Red Hat 7.8A6000Windows x64Windows Server 2019P100Windows x64Windows 10Linux x64CentOS 7.9V100Windows x64Windows Server 2016Maxwell Mechanical APDL IcepakGV100Windows x64Windows 10Linux x64Red Hat 7.9M4000Linux x64SLES 12 SP5P4000Linux x64CentOS 8.1Red Hat 8.3SLES 15 SP2P6000 (Dual)Windows x64Windows 10RTX 3090Linux x64Red Hat 7.8RTX 4000Windows x64Windows 10Linux x64Red Hat 7.9SLES 12 SP522051** The performance benefit of using a GPU Accelerator will depend on the card selected and the overall system configuration.Polyflow。
qualcomm平台的share memory
Qualcomm Share MemoryQUALCOMM的AP与MODEM之间的share memory通过把共享内存空间分成N个不定长数据块,其中SMEM_HEAP_INFO记录每个数据块的地址信息,是否已经分配等,(只能一个宿主先分配),当然SMEM_HEAP_INFO本身也是一个数据块。
各个宿主CPU用这些数据块依照对应的数据结构通信,包括PROC_COMM, smem_find,以及建立在特定数据块上的循环缓冲区smd通道,还有建立在特定通道的函数调用RPC。
(共享内存2个基本点:1在本身内存内记录分配信息2互斥访问或数据一致性;3(可选).如果要快速响应的必须加相互中断通知)地址空间的映射与管理:SMEM_HEAP:(该图版本较老)typedef enum{ SMEM_MEM_FIRST,SMEM_PROC_COMM = SMEM_MEM_FIRST,SMEM_FIRST_FIXED_BUFFER = SMEM_PROC_COMM,SMEM_HEAP_INFO,……} smem_mem_type;将1M得share memory分为N个条目。
最终实际固定了每个条目的起始地址和长度。
(详见AP端linux kernel的smd.c的smem_alloc2分配函数,可知不能通常意义的malloc,只是简单的动态的在尾部增长数据块,不能正真意义的回收内存空间;总共是1M的共享内存,其中64个SMD通道占用64×8K了大部分空间)struct smem_shared {struct smem_proc_comm proc_comm[4];unsigned version[32];struct smem_heap_info heap_info;struct smem_heap_entry heap_toc[SMD_HEAP_SIZE]; // SMD_HEAP_SIZE=512};//这个结构对齐到share memory 的起始地址,就是1M共享内存空间的映射。
AppH
Introduction Interprocessor Communication: The Critical Performance Issue Characteristics of Scientific Applications Synchronization: Scaling Up Performance of Scientific Applications on Shared-Memory Multiprocessors Performance Measurement of Parallel Processors with Scientific Applications Implementing Cache Coherence The Custom Cluster Approach: Blue Gene/L Concluding Remarks
H.2
Interprocessor Communication: The Critical Performance Issue
I
H-3
cessor node. By using a custom node design, Blue Gene achieves a significant reduction in the cost, physical size, and power consumption of a node. Blue Gene/L, a 64K-node version, is the world’s fastest computer in 2006, as measured by the linear algebra benchmark, Linpack.
H-2 H-3 H-6 H-12 H-21 H-33 H-34 H-41 H-44
replicatedmergetree+distributed的集群模式
replicatedmergetree+distributed的集群模式1. 引言1.1 概述在当今信息化时代,数据的处理和管理成为了各个行业的重要任务。
随着数据量不断增长,传统的单机方式已经无法满足海量数据的处理需求。
因此,分布式系统逐渐成为了解决大规模数据处理和存储的有效方法。
本文将主要介绍ReplicatedMergeTree算法与Distributed集群模式相结合的集群架构。
ReplicatedMergeTree是一种可靠存储引擎,可以实现高效地对分布式数据进行复制、归并和同步。
而Distributed则是一个基于分片和副本机制的弹性伸缩的分布式数据库系统。
1.2 文章结构本文将依次介绍ReplicatedMergeTree算法以及其原理、数据同步策略和容错机制。
接下来将详细讨论Distributed集群模式,包括分布式架构介绍、集群规模与扩展性以及数据分发与负载均衡等方面内容。
然后将通过实现与应用案例来更加具体地说明集群部署和配置、数据一致性保证措施以及高可用性和故障恢复策略等关键问题。
最后通过总结研究成果和应用价值以及展望未来发展趋势和改进方向,对本文的研究进行归纳总结。
1.3 目的本文的目的是介绍ReplicatedMergeTree与Distributed集群模式相结合的集群架构,并说明其在大规模数据处理和存储领域中的应用价值。
通过深入分析算法原理、数据同步策略和容错机制,读者能够更好地理解ReplicatedMergeTree 算法。
同时,本文将详细讨论Distributed集群模式的架构特点、扩展性以及负载均衡等问题,读者可以了解分布式系统设计和管理的关键考虑因素。
通过实现与应用案例,读者将掌握集群部署和配置、数据一致性保证措施以及高可用性和故障恢复策略等关键技术,从而为日后的实际项目应用提供参考。
最后,通过对研究成果进行总结和展望未来发展趋势与改进方向,使读者在该领域内能够有所启示并有新的思考。
share memory协议
share memory协议1.1 合同主体甲方:____________________________法定代表人:____________________________地址:____________________________联系方式:____________________________乙方:____________________________法定代表人:____________________________地址:____________________________联系方式:____________________________1.11 合同标的本协议旨在规范甲、乙双方关于“Share Memory”(共享内存)的相关事宜。
具体包括但不限于共享内存的范围、用途、使用方式、访问权限等。
1.12 权利义务1.121 甲方的权利义务甲方有权按照本协议约定的方式和范围使用共享内存。
甲方有义务遵守相关法律法规和本协议的规定,不得利用共享内存从事违法活动。
甲方应保证其对共享内存的使用不会损害乙方的合法权益。
甲方应按照约定的时间和方式向乙方支付相关费用(如有)。
1.122 乙方的权利义务乙方有权对共享内存进行管理和维护,确保其正常运行。
乙方有义务按照本协议约定向甲方提供共享内存,并保证其质量和性能符合约定标准。
乙方应保守甲方在使用共享内存过程中的商业秘密和个人隐私(如有)。
乙方应在甲方提出合理需求时,提供必要的技术支持和服务。
1.13 违约责任1.131 若甲方违反本协议约定,擅自扩大共享内存的使用范围、改变使用方式或从事违法活动,应承担相应的法律责任,并向乙方支付违约金。
违约金的数额为甲方因违约行为所获得的利益或者给乙方造成的损失的[具体倍数或金额]。
1.132 若乙方未按照本协议约定提供共享内存,或共享内存的质量和性能不符合约定标准,应负责及时修复或更换,并向甲方支付违约金。
违约金的数额为甲方因此所遭受的损失的[具体倍数或金额]。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
2
Architecture overview of the target clusters
The experiments described in this note have been performed on three different clusters of SMPs namely 1. A cluster of eight bi-processors Pentium PC running Linux. The characteristics of the nodes on PC cluster are the following: - Processor: 2 Intel Pentium III, 933 MHz, 16 KB L1-cache, 256 KB L2-cache, peak performance 933 MFlops. - Memory: 1 GB of RAM shared by two processors. The processors share the memory access through one 64-bit 133 MHz memory path giving a bandwidth of around 1 GB/s. - Network: Myrinet network using DMA through a PCI card, latency 9 µsec, 250 MB/s peak bandwidth each way in full-duplex, - Compiler: Portland Group Fortran 90. 2. A cluster of two bi-processors Alinka Itanium PC running Linux. The characteristics of the nodes on PC cluster are the following: - Processor: 2 Itanium, 733 MHz, 16 KB L1-cache, 96 KB L2-cache, 2 MB L3cache, peak performance 2.93 GFlops. - Memory: 1 GB of RAM shared by two processors. The interleaved memory is accessed through a sophisticated memory path enabling a transfer rate of 4.27 GB/s. - Network: 100 Mbit Ethernet, - Compiler: Intel or SGI Fortran 90 compiler. 3. A cluster of four ES40 Alphaserver Compaq. The characteristics of nodes on the Compaq computer are as follows: - Processor: 4 Alpha EV 6.7, 667 MHz, 64 KB 2-way associative L1-cache, 8 MB direct mapped L2-cache, peak performance 1.33 GFlops. - Memory: 4 GB of RAM shared by four processors through two 256-bit 88 MHz memory path giving a peak memory bandwidth of 5.2 GB/s. - Network: Fat tree Quadrics network with Elan card, 3 µsec latency and 200 MB/s peak bandwidth each way in full-duplex, - Compiler: Compaq Fortran 90.
CERFACS Tech. Rep.: WN/PA/01/19
Abstract This note presents some experiments on different clusters of SMPs, where both distributed and shared memory parallel programming paradigms can be naturally combined. Although the platforms exhibit the same macroscopic memory organization, it appears that their individual overall performance is closely dependent on the ability of their hardware to efficiently exploit the local shared memory within the nodes. In that context, cache blocking strategy appear to be very important not only to get good performance out of each individual processor but mainly good performance out of the overall computing node since sharing memory locally might become a severe bottleneck. On a simple benchmark, representative of many large simulation codes, we show through numerical experiments that mixing the two programming models enables to get attractive speed-ups that compete with a pure distributed memory approach. This open promising perspectives for smoothly moving large insdustrial codes developed on distributed vector computers with moderate number of processors on these emerging platforms for intensive scientific computing that are the clusters of SMPs. Keywords: Cluster of Pentium PCs, cluster Alinka Itanium, Compaq Alphaserver, shared memory, distributed memory, OpenMP, MPI, performance evaluation.
3
Hale Waihona Puke If we compute σ= Peak processor (MFlop/s) Peak Memory bandwidth (Mw/s)
where the memory bandwidth is expressed in Mwords per second with a word being 64 bits, we obtain the figures displayed in Table 1. It can be seen that this ratio on the Pentium based platform is the lowest and that the Compaq is the computer that exhibits the best balance between memory bandwidth and processor speed. Cluster Pentium Alinka Itanium Alphaserver Compaq Peak processor (MFlop/s) 933 2930 1330 Peak Mem. Bandwidth (Mw/s) 128 546 665 σ processor 0.137 0.187 0.5 σ node 0.069 0.094 0.125
1
Introduction
In the recent years, new parallel computer architectures have appeared that combined disjoint memory address space between groups of processors and a global memory address space within each group of processors. This kind of computer architecture, promoted by the US-ASCI project, is usually called “Cluster of SMPs (Symmetric Multi-Processors)”. This physical memory organization perfectly matches the requirements of parallel algorithms that can exploit two levels of parallelism. The outer/coarser is implemented between the SMPs and the inner/finer within each SMP. In that respect the parallel programming paradigms are message passing at the coarser level and loop level parallelism at the finer. In this note we intend to investigate such programming combination through a very simple numerical algorithm, namely the explicit solution of the heat equation in a square.