多元统计分析原理与基于spss的应用
多元分析与spss 应用
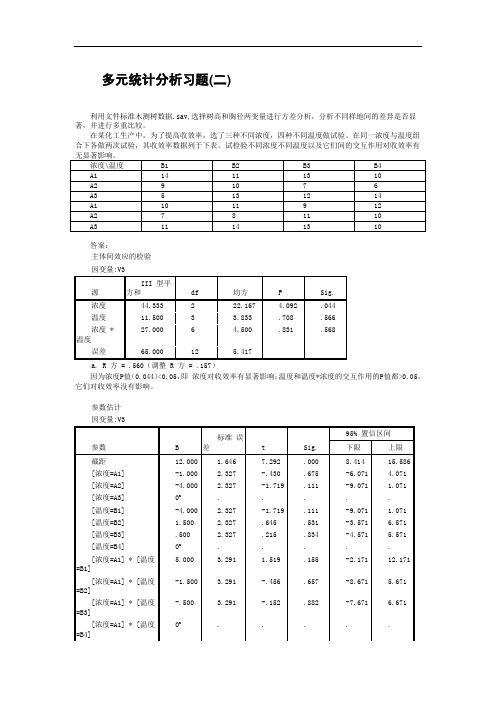
多元统计分析习题(二)
利用文件标准木测树数据.sav,选择树高和胸径两变量进行方差分析,分析不同样地间的差异是否显著,并进行多重比较。
在某化工生产中,为了提高收效率,选了三种不同浓度,四种不同温度做试验。
在同一浓度与温度组合下各做两次试验,其收效率数据列于下表。
试检验不同浓度不同温度以及它们间的交互作用对收效率有
P值都>0.05,它们对收效率没有影响。
A3因素对收效率最好。
通过比较A, B因素的交互作用发现A3对B2组合的均值最大,说明A3对B2组合对收效率最好,因此说A3对B2是最优组合。
多元统计分析与SPSS

3. 点击Save按钮,设置保存在数据文件中的表明聚类结 果的新变量。其中Cluster membership选项用于建立一个 代表聚类结果的变量,默认变量名为qcl_1;Distance from cluster center选项建立一个新变量,代表各观测量 与其所属类中心的欧氏距离。我们将两个复选框都选中, 单击Continue按钮返回。
• 为研究某地区人口死亡状况,已按某种方法将15个已知地 区样品分为3类,指标含义及原始数据如下。试建立判别 函数,并判定另外4个待判地区属于哪类?
X1 : 0岁组死亡概率
X 4 : 55岁组死亡概率
X 2 :1岁组死亡概率
X5 : 80岁组死亡概率
X 3 : 10岁组死亡概率
X6 : 平均预期寿命
图 Plots子对话框
• 4. 点击Method按钮,设置系统聚类的方法选项。Cluster Method下拉列表用于指定聚类的方法,包括组间连接法 、组内连接法、最近距离法、最远距离法等;Measure栏 用于选择对距离和相似性的测度方法;剩下的Transform Values和Transform Measures栏用于选择对原始数据进 行标准化的方法。这里我们仍然均沿用系统默认选项。单 击Continue按钮,返回主界面。
二 在SPSS中利用K均值法进行聚类分析
• 我国各地区2003年三次产业产值如表所示,试根据三次产 业产值利用K均值法对我国31个省、自治区和直辖市进行聚 类分析。
(一)操作步骤 • 1. 在SPSS窗口中选择Analyze→Classify→K-Means
Cluster,调出K均值聚类分析主界面,并将变量—移入 Variables框中,将标志变量Region移入Label Case by框 中。在Method框中选择Iterate classify,即使用K-means 算法不断计算新的类中心,并替换旧的类中心(若选择 Classify only,则根据初始类中心进行聚类,在聚类过程 中不改变类中心)。
多元统计分析及其SPSS应用PPT文档49页

51、没有哪个社会可以制订一部永远 适用的 宪法, 甚至一 条永远 适用的 法律。 ——杰 斐逊 52、法律源于人的自卫本能。——英 格索尔
53、人们通常会发现,法律就是这样 一种的 网,触 犯法律 的人, 小的可 以穿网 而过, 大的可 以破网 而出, 只有中 等的才 会坠入 网中。 ——申 斯通 54、法律就是法律它是一座雄伟的大 夏,庇 护着我 们大家 ;它的 每一块 砖石都 垒在另 一块砖 石上。 ——高 尔斯华 绥 55、今天的法律未必明天仍是法律。 ——罗·伯顿
END
16、业余生活要有意义,不要越轨。——华盛顿 17、一个人即使已登上顶峰,也仍要自强不息。——罗素·贝克 18、最大的挑战和突破在于用人,而用人最大的突破在于信任人。——马云 19、自己活着,就是为了使别人过得更美好。——雷锋 20、要掌握书,莫被书掌握;要为生而读,莫为读而生。——布尔沃
第5部分多元统计分析的SPSS实现课件

5. 单击Save按钮,指定在数据文件中生成代表判别分组结果 和判别得分的新变量,生成的新变量的含义分别为:
Predicted group membership:存放判别样品所属组别的值;
Discriminant scores:存放Fisher判别得分的值,有几个典型 判别函数就有几个判别得分变量;
3
14 54.17 25.03 2.11 25.15 110.14 63.7
3
15 28.07 2.01 0.07 3.02 81.22 68.3
3
待判 50.22 6.66 1.08 22.54 170.6 65.2
.
待判 34.64 7.33 1.11 7.78 95.16 69.3
.
待判 33.42 6.22 1.12 22.95 160.31 68.3
表4.2(b) 组重心处的Fisher判别函数值
4. Classification Function Coefficients(给出Bayes判别函数 系数)
如表4.3所示,GROUP栏中的每一列表示样品判入相应列的 Bayes判别函数系数。在本例中,各类的Bayes判别函数如下: 第一组:
F1 5317.2 143.9X 1 153.1X 2 90.1X3 53.0 X 4 11.0X 5 189.3X 6
2
9
53.04 25.74 4.06 34.87 152.03 63.5
2
10 38.03 11.2 6.07 27.84 146.32 66.8
2
11 34.03 5.41 0.07 5.2 90.1 69.5
3
12 32.11 3.02 0.09 3.14 85.15 70.8
SPSS软件的应用——多元统计分析

多元统计分析学院:理学与信息科学学院专业班级:信息与计算科学 2012级01 班姓名:韩祖良(20125991)****:***2015 年6月1日作业1 方差分析三组贫血患者的血红蛋白浓度(%,X1)及红细胞计数(万/mm3,X2)如下表:1、方差分析的前提条件要求各总体服从正态分布,请给出正态分布的检验结果,另要求各总体方差齐性,给出方差齐性检验结果。
2、检验三组贫血患者的指标x1,x2间是否有显著差异,进行多元方差分析。
如果有显著差异,分析三组患者间x1指标是否有显著差异,x2指标是否有显著差异?3、最后进行两两比较,给出更具体的分析结果。
4. 画出三组患者x1,x2两指标的均值图。
答:1.将所需分析数据输入到SPSS中,首先判断各总体是否服从正态分布:对文件进行拆分:数据→拆分文件→按组组织输出→确定。
然后进行正态性检验:文件→描述统计→探索,在绘制对话框中,选择按因子水平分组和带检验的正态图,最后单击确定按钮。
最后得出结果如图(1),(2),(3)所示:表(1)由表(1)可以看出,A组的X1指标的Sig=0.907,X2的Sig=0.914,在检验标准为0.05的条件下,接受H0,拒绝H1,故得A组服从正态分布。
表(2)由表(2)可以看出,B组的X1指标的Sig=0.406,X2的Sig=0.765,在检验标准为0.05的条件下,接受H0,拒绝H1,故得B组服从正态分布。
表(3)由表(3)可以看出,C组的X1指标的Sig=0.337,X2的Sig=0.839,在检验标准为0.05的条件下,接受H0,拒绝H1,故得C组服从正态分布。
再检验各总体是否满足方差齐性:首先取消文件的拆分,对所有个案进行分析。
然后进行方差齐性检验:分析→一般线性模型→多变量,在选项对话框中,选择方差齐性检验,所得结果如下:表(4)上表是对协方差阵相等的检验,由Sig=0.670>0.05,故在显著性水平为0.05的条件下,接受H0,拒绝H1,即观测到的因变量的协方差矩阵在所有组中均相等,可得三组符合方差齐性。
统计学原理与spss应用

统计学原理与spss应用统计学原理与SPSS应用是统计学中非常重要且常用的两个部分。
统计学原理是统计学的基础理论,而SPSS则是一款常用的统计分析软件。
首先,统计学原理是通过收集、整理、分析和解释数据来研究现象和进行决策的一门学科。
其基本原理包括变量、概率、抽样、假设检验等。
变量指的是研究对象的特征或属性,可以是定量的也可以是定性的;概率则是指某个事件发生的可能性;抽样是指从总体中选择一部分样本进行分析;假设检验则是根据样本数据对总体参数进行推断。
统计学原理的应用非常广泛,例如市场调研、医学研究、社会科学研究等。
通过掌握统计学原理,我们可以对数据进行合理的收集和处理,并通过统计分析方法对数据进行解读和推断。
在研究设计上,统计学原理可以帮助我们选择适当的抽样方法、确定样本容量和处理实验结果。
在统计分析上,统计学原理可以帮助我们选择适当的统计方法,并对得到的结果进行合理的解释和推断。
总之,统计学原理为我们研究现象及决策提供了科学的方法和依据。
而SPSS作为一款专业的统计分析软件,可以帮助研究者更加便捷地进行数据处理和统计分析。
SPSS提供了可视化的数据输入和管理界面,使得数据的输入更加简单和直观。
同时,SPSS还内置了丰富的统计分析方法和功能,用户可以根据不同的研究目的选择适当的方法进行分析。
SPSS可以进行描述性统计、t检验、方差分析、回归分析、因子分析等多种统计方法,同时还可以生成各种图表和报告以直观地展示和解释结果。
在使用SPSS进行数据分析时,我们首先需要导入数据,并对数据进行清洗和预处理,如删除异常值、缺失值的处理等。
之后,我们可以选择适当的统计分析方法进行分析,例如根据变量类型选择描述性统计方法或回归分析方法。
在分析过程中,SPSS会自动计算所需的统计指标,并生成相应的结果报告。
最后,我们可以通过SPSS生成的图表和报告对结果进行解释和展示。
总的来说,统计学原理与SPSS应用相辅相成。
统计学原理为我们提供了科学的方法和理论,而SPSS作为工具则帮助我们更加便捷地实施统计分析。
实验2多元统计分析spss

实验2
练习多元线性回归分析:
(问题描述:用多元回归分析来分析36名员工多个心理变量值z1-z8对员工满意度my的预测效果,测得试验数据见附表所示。
请列出相关的线性函数表达式)
步骤1:在SPSS的数据编辑窗口中打开该数据表,在“分析”菜单的“回归”子菜单中选择“线性Linear”命令。
步骤2:在弹出的对话框中将变量添加到对应的变量框中,把员工满意度设为因变量,8个心理变量设为自变量。
根据问题要求选择右边各选项的对应选项。
步骤3:单击“OK”按钮,即可得到SPSS回归分析的结果。
应用回归分析结果:。
如何使用SPSS进行多元统计分析

如何使用SPSS进行多元统计分析第一章:SPSS简介SPSS(Statistical Package for the Social Sciences)是一种功能强大且广泛使用的统计分析软件。
它能够处理大量数据,进行各种统计分析和数据挖掘,是研究人员和数据分析师常用的工具。
第二章:设置数据在进行多元统计分析之前,首先需要设置数据。
SPSS支持导入外部数据文件,如Excel、CSV等格式。
用户可以在SPSS中创建新的数据集并录入数据,也可以导入已有数据集。
在设置数据时,需要注意数据的变量类型、缺失值处理以及数据的清洗与转换。
第三章:描述统计分析描述统计分析是理解数据的第一步。
SPSS提供了丰富的描述统计方法,包括平均数、标准差、最小值、最大值、频数分布等。
用户可以通过简单的命令或者界面操作来生成各种描述统计结果,并进一步进行数据的可视化展示。
第四章:相关性分析相关性分析是多元统计分析的常用方法之一。
SPSS提供了丰富的相关性分析工具,如Pearson相关系数、Spearman等。
用户可以通过相关分析来检测不同变量之间的关系,并进一步探索变量之间的线性或非线性关系。
第五章:线性回归分析线性回归分析是一种预测性分析方法,在多元统计分析中应用广泛。
SPSS可以进行简单线性回归分析和多元线性回归分析。
用户可以通过线性回归分析来建立模型,预测因变量与自变量之间的关系,并进行参数估计和显著性检验。
第六章:因子分析因子分析是一种常用的降维技术,用于发现隐藏在数据中的潜在变量。
SPSS提供了主成分分析、最大似然因子分析等方法。
用户可以通过因子分析来降低变量的维度,提取数据中的主要信息。
第七章:聚类分析聚类分析是一种用于将数据样本划分成相似组的方法。
SPSS支持多种聚类算法,如K均值聚类、层次聚类等。
用户可以通过聚类分析来识别数据中的固有模式和群体。
第八章:判别分析判别分析是一种用于将样本分类的方法,常用于研究预测变量对分类变量的影响。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
多元统计分析原理与基于SPSS的应用
1. 引言
多元统计分析是统计学中的重要分支,用于研究多个变量之间的关系和模式。
在实际应用中,SPSS是一个流行的统计分析软件,提供了丰富的功能和工具,可以用于多元统计分析。
本文将介绍多元统计分析的原理,并探讨如何利用SPSS进行实际应用。
2. 多元统计分析概述
多元统计分析是一种从多个维度考察数据的统计方法。
它可以帮助研究者发现多个变量之间的模式和关联,从而提供更深入的分析和理解。
常见的多元统计分析方法包括:主成分分析、因子分析、聚类分析、判别分析等。
2.1 主成分分析(PCA)
主成分分析是一种减少数据集维度的方法,它可以将大量的变量转化为少数几个主成分。
通过主成分分析,可以发现数据中的主要模式和结构,从而简化数据集和分析过程。
2.2 因子分析
因子分析是一种确定变量之间潜在关系的方法。
它可以帮助研究者发现共同的因素或维度,并解释变量之间的相关性。
因子分析可用于降维或构造新的变量,进而减少数据集的复杂性。
2.3 聚类分析
聚类分析是一种将观测对象分组或分类的方法。
它可以通过计算对象之间的相似性或距离,将它们划分为不同的类别。
聚类分析可帮助研究者发现数据中的隐藏结构,并进行进一步的分析和解释。
2.4 判别分析
判别分析是一种预测变量类别的方法。
它可以根据已知类别的样本数据,建立预测模型并进行分类。
判别分析可用于识别不同群体或类别之间的差异,并进行进一步的推断和预测。
3. 多元统计分析的应用场景
多元统计分析可以应用于各种领域,如市场调研、社会科学、医学研究等。
以下是一些常见的应用场景:
•市场调研:通过主成分分析和因子分析,可以帮助企业确定消费者需求和消费行为的主要影响因素。
•社会科学:聚类分析可用于对人群进行社会分类,从而提供对人群特征和行为的深入理解。
•医学研究:判别分析可以应用于医学诊断,预测患者是否患有某种疾病或疾病的严重程度。
4. 基于SPSS的多元统计分析应用示例
SPSS是一款功能强大的统计分析软件,提供了多种多元统计分析方法和工具。
以下是一个基于SPSS的多元统计分析应用示例:
4.1 数据准备
首先,需要准备一个包含多个变量的数据集。
可以在SPSS中导入Excel或
CSV文件,并进行数据清洗和预处理。
4.2 主成分分析
在SPSS中,通过选择。