编译原理Chapt2
编译原理PPT课件

教学目的与要求:
编译程序是现代计算机系统的基本组成部
分之一。本课程重点讲述编译程序的设计
原理和常用实现技术。通过课程的学习和
实验的完成,应该清楚的理解一个编译程
序是如何工作的;如果在以后遇到了任何
一个程序设计语言,应该知道如何实现这
个语言的多数机制;应具有一定的使用编
译构造工具开发编译程序的经验;会将所
参考书:《程序设计语言 编译原理》(第3 版),陈火旺、刘春林等,国防工业出版社 2000
等等
2021/3/7
CHENLI
2
教学内容
1 编译程序概述 编译程序是现代计算机系统的基本组成部分之 一.编译程序一般由词法分析程序,语法分析程 序,语义分析程序,中间代码生成程序,目标 代码生成程序,代码优化程序,符号表管理程 序和错误处理程序等成分构成。本章概要介绍 编译成分的主要功能以及编译阶段的逻辑关系。
教学内容
5 语法分析程序的构造
自顶向下的语法分析。可以看作是为一个输入串寻找 一个最左推导的过程,也等价于从根开始,按前序生成 结点,为输入串构造分析树的过程。讨论一种有效的 无回溯的自顶向下分析程序,这种分析程序称为预测 分析程序。介绍对于一个文法类:LL(1)文法, 如 何自动的构造预测分析程序。
2 PL/0 编译程序剖析 给出一个简单的类Pascal语言,其编译程序用 高级语言(C和Pascal)实现。通过剖析该高 级语言程序以理解各编译成分的功能及手工实 现方法。
2021/3/7
CHENLI
3
教学内容
3 高级语言的认识
要学习和构造编译程序,理解和定义程序设计语言
是必不可少的。每个程序设计语言都有一定的规则用 以规定合适程序的语法结构,也需要有对一个程序的 含义的描述。上下文无关文法给出程序设计语言的精 确的,易于理解的语法说明。尚没有公认的形式系统 描述程序含义,但也有流行的描述语义规则的方法— 属性文法。
编译原理第二版作业答案_第2章
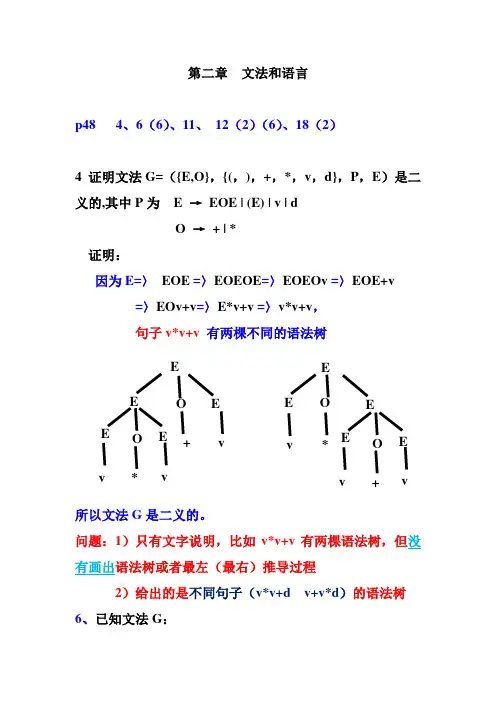
第二章 文法和语言p48 4、6(6)、11、 12(2)(6)、18(2)4 证明文法G=({E,O},{(,),+,*,v ,d},P ,E )是二义的,其中P 为 E → EOE | (E) | v | d O → + | * 证明:因为E=〉 EOE =〉EOEOE =〉EOEOv =〉EOE+v=〉EOv+v =〉E*v+v =〉v*v+v , 句子v*v+v 有两棵不同的语法树所以文法G 是二义的。
问题:1)只有文字说明,比如v*v+v 有两棵语法树,但没有画出语法树或者最左(最右)推导过程2)给出的是不同句子(v*v+d v+v*d )的语法树 6、已知文法G :EEEE OO v*v+ vE EE E O O v+v* v〈表达式〉∷=〈项〉|〈表达式〉+〈项〉〈项〉∷=〈因子〉|〈项〉*〈因子〉〈因子〉∷=(〈表达式〉)| i试给出下述表达式的推导及语法树(6)i+i*i推导过程:〈表达式〉=〉〈表达式〉+〈项〉E=〉E+T =〉〈表达式〉+〈项〉*〈因子〉=〉E+ T*F=〉〈表达式〉+〈项〉* i =〉E+ T*i=〉〈表达式〉+ 〈因子〉* i =〉E+F*i=〉〈表达式〉+ i* i =〉E+i*i=〉〈项〉+ i* i =〉T +i*i=〉〈因子〉+ i* i =〉F +i*i=〉i +i*i =〉i +i*i 共8步推导语法树:〈表达式〉+〈因子〉〈项〉i 〈因子〉i〈项〉〈项〉〈因子〉i*11、一个上下文无关文法生成句子abbaa的推导树如下:(1)给出该句子相应的最左推导和最右推导(2)该文法的产生式集合P可能有哪些元素?(3)找出该句子的所有短语、简单短语、句柄。
(1)最左推导:S=〉ABS=〉aBS=〉aSBBS=〉aBBS=〉abBS=〉abbS =〉abbAa=〉abbaa最右推导:S =〉ABS=〉ABAa=〉ABaa=〉ASBBaa=〉ASBbaa=〉ASbbaa=〉Abbaa=〉abbaa(2)该文法的产生式集合P可能有下列元素:S→ABS | Aa|εA→a B→SBB|b(3)因为字符串中的各字符有相对的位置关系,为了能相互区别,给相同的字符标上不同的数字。
编译原理第二章

上一页
下一页
11
▪ 符号串的术语
设s是符号串 前缀:移走s的尾部的零个或多于零个符号 后缀:删去s的头部的零个或多于零个符号 子串:从s中删去一个前缀和一个后缀 子序列:从s中删去零个或多于零个符号(这些符号不要求是连续的) 逆转:将S中的符号按相反次序写出而得到的符号串。 长度:是该符号串中的符号的数目。例如|aab|=3,|ε|=0。 真前缀,真后缀,真子串: x≠sx ≠ 例子:符号串s=banana 前缀:,b,ba,ban,bana,banan,banana 后缀:banana,anana,nana,ana,na,a, 子串:banana,anana,banan,anan,…, 子序列: baa(这些符号不要求是连续的) 逆转(用SR表示):ananab 长度:banana=6
β ε +T +T +T
ε ε
上一页
下一页
23
3.3 最左推导与最右推导
对于推导αβ,如果每一步都是对α中的最左非终结符进行替换 的,则我们称这种推导为最左推导,如果每一步都是对α中的最 右非终结符进行替换的,则我们称这种替换为最右推导。
例2-2:对于文法:E→E+ E|E*E|(E)|i 我们看对于(i*i+i)的推导 最左推导:E (E) (E+E) (E*E+E) (i*E+E) (i*i+E) (i*i+i) 最右推导:E (E) (E+E) (E+i) (E*E+i) (E*i+i) (i*i+i)
编译原理

课程地位:编译理论与方法
计算机科学与技术中理论和实践相结合的最好典范 ACM 图灵奖,授予在计算机技术领域作出突出贡献的 科学家
程序设计语言、编译理论与方法约占1/3
程序的构造方法
1.1 什么是编译程序
编译程序与程序员的关系? 回顾程序执行的方式
解释型,如:BASIC 编译型,如:C 混合型,如:JAVA
1. 词法分析
任务: 对源程序字符流进行扫描和分解,识别出一 个个单词符号。 依循原则:构词规则 描述工具:有限自动机 例: Z := X + 6 * Y z : = x + 6 * y
可识别为下列单词(记号): 标识符z 赋值 := 标识符x 加号+ 数字6 乘号* 标识符y
2. 语法分析
任务:在词法分析的基础上,根据语言的语法规则把单词 符号串分解成各类语法单位。 依循的原则:语法规则 描述工具:上下文无关文法、语法树和抽象语法树 例(PASCAL): VAR Z,X,Y:real; E Z := X + 6* Y :=
PROCEDURE INCWAP(M,N:INTEGER); LABEL START; VAR K:INTEGER; BEGIN START: K:=M+1; M:=N+4; N:=K; END.
5
PROCEDURE INCWAP(M,N:INTEGER); LABEL START; VAR K:INTEGER; BEGIN START: K:=M+1; 表 0.1 符号名表 SNT M:=N+4; NAME INFORMATION N:=K; END. M 形式参数,整 型,值参数 N 形式参数,整 型,值参数 K 整型,变量
《编译原理》课后习题答案第二章

有代表性的符号串:a,a0,aa,a00,a0a,aa0
习题2
3.(1)E T T/F F/F (E)/F (E+T)/F (T+T)/F (F+F)/F (i+i)/i
(2)E E+T E+T+T E+T*F+F E+T*F+i E+T*T*F+i
M:M(0,a)=1 M(0,b)=2
M(1,a)=1 M(1,b)=4
M(2,a)=1 M(2,b)=3
M(3,a)=3 M(3,b)=2
M(4,a)=0 M(4,b)=5
M(5,a)=5 M(5,b)=1
化简:
1.分化
① {0,1} {2,3,4,5}
② {0,1} {2,4} {3,5}
2.合并
=M(M(D,1),1011)
=M(M(C,1),011)
=M(M(F,0),11)
=M(M(E,1),1)
=M(C,1)
=F
∴DFA D能接受字符串0011011
8.解:将状态转换图列表,即:
由左图可知,该状态转换图直接对应的是确定有穷状态自动机DFA
DFA D=({0,1,2,3,4,5},{a,b},M,0,{0,1})
A::=bc|bAc
(2)Z::=AB
A::=ab|aAb
B::=b|Bb
7. 解:题中要求文法是:
Z::=1|3|5|7|9|Z1|Z3|Z5|Z7|Z9|A1|A3|A5|A7|A9
A::=2|4|6|8|A0|A2|A4|A6|A8|Z0|Z2|Z4|Z6|Z8
编译原理简明教程第二版

编译原理简明教程第二版什么是编译原理?编译原理是计算机科学中的一门重要课程,它研究的是如何将高级程序设计语言(如C、Java)编写的程序转化为机器能够理解和执行的指令。
编译原理主要包括以下几个方面的内容:1.词法分析:将源代码转化为一系列的词法单元,例如标识符、关键字、运算符等。
2.语法分析:通过创建语法树,检查源代码是否符合语法规则。
3.语义分析:对语法树进行分析,检查程序中的语义错误。
4.优化技术:对源代码进行优化,提高程序的执行效率。
5.目标代码6.:将优化后的源代码转化为与目标机器相关的指令,7.可执行文件。
编译过程编译过程可以分为三个阶段:前端、优化和后端。
前端前端负责词法分析、语法分析和语义分析等工作。
具体过程如下:1.词法分析:将源代码划分为一个个词法单元。
这些词法单元是编程语言中的基本语义单位,例如标识符、关键字、运算符等。
词法分析的结果是一个词法单元序列。
2.语法分析:根据语法规则检查词法单元序列是否符合语法。
语法分析的结果是一个语法树。
3.语义分析:对语法树进行静态语义检查,确保程序的语义正确。
语义分析的结果是一个语义树。
优化优化阶段对语义树进行优化,提高程序的执行效率。
常见的优化技术包括常量折叠、循环展开和死代码删除等。
优化的目标是提高程序的执行速度、减少程序的内存占用和提高程序的可读性。
后端后端负责目标代码目标代码是针对具体的目标机器的,可以是汇编代码、机器码,或者是中间表示形式(如LLVM的字节码)。
目标代码的过程中,需要进行寄存器分配、指令选择和代码布局等工作。
编译器的实现编译器的实现可以基于手写的,也可以使用编译器工具(例如Flex和Bison)辅助完成。
手写实现编译器的优点是可以更好地理解和掌握编译原理的各个方面。
而使用编译器工具可以减少编写代码的工作量,提高编译器的开发效率。
无论是手写实现还是使用编译器工具,编译器的核心功能都是通过前端、优化和后端三个阶段来完成的。
编译原理第二章 文法和语言资料
第二章文法和语言本章讲述目前广泛使用的上下文无关文法。
即用上下文无关文法作为程序设计语言语法的描述工具。
阐明语法的一个工具是文法。
本章将介绍文法和语言的概念。
本章重点:上下文无关文法及其句型分析中的有关问题。
第一节文法的直观概念当我们表述一种语言时,无非是说明这种语言的句子,如果语言只含有有穷多个句子,则只需列出句子的有穷集就行了,但对于有无穷句子的语言来讲,存在着如何给出它的有穷表示的问题。
以自然语言为例,人们无法列出全部句子,但是人们可以给出一些规则,用这些规则来说明(或者定义)句子的组成结构,比如:“我是大学生”。
是汉语的一个句子。
汉语句子可以是由主语后随谓语而成,构成谓语的是动词和直接宾语,我们采用EBNF来表示这种句子的构成规则:〈句子〉∷=〈主语〉〈谓语〉〈主语〉∷=〈代词〉|〈名词〉〈代词〉∷=我|你|他〈名词〉∷=王明|大学生|工人|英语〈谓语〉∷=〈动词〉〈直接宾语〉〈动词〉∷=是|学习〈直接宾语〉∷=〈代词〉|〈名词〉“我是大学生”的构成符合上述规则,而“我大学生是”不符合上述规则,我们说它不是句子。
这些规则成为我们判别句子结构合法与否的依据。
一旦有了一组规则以后,我们可以按照如下方式用它们去推导或产生句子。
我们开始去找∷=左端的带有〈句子〉的规则并把它表示成∷=右端的符号串,这个动作表示成:〈句子〉⇒〈主语〉〈谓语〉,然后在得到的串〈主语〉〈谓语〉中,选取〈主语〉或〈谓语〉,再用相应的规则∷=右端代替之。
比如,选取了〈主语〉,并采用规则〈主语〉∷=〈代词〉,那么得到:〈主语〉〈谓语〉⇒〈代词〉〈谓语〉,重复做下去,我们得到句子:“我是大学生”的全部动作过程是:〈句子〉⇒〈主语〉〈谓语〉⇒〈代词〉〈谓语〉⇒我〈谓语〉⇒我〈动词〉〈直接宾语〉⇒我是〈直接宾语〉⇒我是〈名词〉⇒我是大学生符号⇒的含义是,使用一条规则,代替⇒左边的某个符号,产生⇒右端的符号串。
显然,按照上述办法,不仅生成“我是大学生”这样的句子,还可以生成“王明是大学生”,“王明学习英语”,“我学习英语”,“他学习英语”,“你是工人”,“你学习王明”等几十个句子。
编译原理第二章习题答案
第2章习题解答1.文法G[S]为:S->Ac|aBA->abB->bc写出L(G[S])的全部元素。
[答案]S=>Ac=>abc或S=>aB=>abc所以L(G[S])={abc}==============================================2. 文法G[N]为:N->D|NDD->0|1|2|3|4|5|6|7|8|9G[N]的语言是什么?[答案]G[N]的语言是V+。
V={0,1,2,3,4,5,6,7,8,9}N=>ND=>NDD.... =>NDDDD...D=>D......D===============================================3.已知文法G[S]:S→dAB A→aA|a B→ε|bB问:相应的正规式是什么?G[S]能否改写成为等价的正规文法?[答案]正规式是daa*b*;相应的正规文法为(由自动机化简来):G[S]:S→dA A→a|aB B→aB|a|b|bC C→bC|b也可为(观察得来):G[S]:S→dA A→a|aA|aB B→bB|ε===================================================================== ==========4.已知文法G[Z]:Z->aZb|ab写出L(G[Z])的全部元素。
[答案]Z=>aZb=>aaZbb=>aaa..Z...bbb=> aaa..ab...bbbL(G[Z])={a n b n|n>=1}===================================================================== =========5.给出语言{a n b n c m|n>=1,m>=0}的上下文无关文法。
编译原理(第2版)陈意云张昱编著课后答案
Use as a study resource to enhance comprehension and retention of the material.
编译原理概述
1 Definition
Study of translating source code into machine-readable format.
A tool that performs lexical analysis by scanning and tokenizing the source code.
结论和要点
Key Takeaways
1. Understanding compilation principles is essential for software development.
3 Group Study
Collaborate with classmates to compare and discuss solutions.
第一章:引论
1
Introduction to Compilation
Overview of the compilation process and its importance.
2 Importance
Essential for understanding software development and building compilers.
3 Topics Covered
Lexical analysis, syntax analysis, semantic analysis, code generation, and optimization.
课后答案的使用方法
1 Reference Guide
编译原理-国防科技大学课件Chapt3
国防科技大学计算机系602教研室
输出的单词符号的表示形式:
(单词种别,单词自身的值)
单词种别通常用整数编码表示。
若一个种别只有一个单词符号,则种别编 码就代表该单词符号。假定基本字、运算 符和界符都是一符一种。
表示。有些也要超前搜索。 5.EQ.M 5.E08
4 算符和界符的识别 把多个字符符合而成的算符和界符拼合成
一个单一单词符号。 :=, **, .EQ. , ++,--,>=
国防科技大学计算机系602教研室
三、状态转换图
1 概念
状态转换图是一张有限方向图。
结点代表状态,用圆圈表示。 X
状态之间用箭弧连结,箭弧 1
扫描缓冲区
↑
↑
起点 搜索
指示器 指示器
国防科技大学计算机系602教研室
WhatALong…Word
…rd WhatALong…Wo
… WhatALong…Wo rd
rd
… WhatALong…Wo
国防科技大学计算机系602教研室
二、单词符号的识别:超前搜索
1 基本字识别: 例如: DO99K=1,10
开始符S至少必须在某个产生式的左部出现一次。
国防科技大学计算机系602教研室
复习:程序语言的语法描述
定义:称A直接推出,即
A 仅当A 是一个产生式, 且, (VT VN)* 。
如果1 2 n,则我们称这个序 列是从1到n的一个推导。若存在一个从 1到n的推导,则称1可以推导出n 。
国防科技大学计算机系602教研室?全局变量与过程1ch字符变量存放最新读入的源程序字符2strtoken字符数组存放构成单词符号的字符串3getchar子程序过程3getchar子程序过程把下一个字符读入到ch中4getbc子程序过程跳过空白符直至ch中读入一非空白符5concat子程序把ch中的字符连接到strtoken把下一个字符国防科技大学计算机系602教研室6isletter和isdisgital布尔函数判断ch中字符是否为字母和数字7reserve整型函数对于strtoken中的字符串查找保留字表若它实保留字则给出它的编码否则回送08retract子程序把搜索指针回调一个字符位置个字符位置9insertid整型函数将strtoken中的标识符插入符号表返回符号表指针10insertconst整型函数过程将strtoken中的常数插入常数表返回常数表指针