基于半连接的分布式数据库查询优化研究.
转载:SqlServer数据库性能优化详解

转载:SqlServer数据库性能优化详解本⽂转载⾃:性能调节的⽬的是通过将⽹络流通、磁盘 I/O 和 CPU 时间减到最⼩,使每个查询的响应时间最短并最⼤限度地提⾼整个数据库服务器的吞吐量。
为达到此⽬的,需要了解应⽤程序的需求和数据的逻辑和物理结构,并在相互冲突的数据库使⽤之间(如联机事务处理 (OLTP) 与决策⽀持)权衡。
对性能问题的考虑应贯穿于开发阶段的全过程,不应只在最后实现系统时才考虑性能问题。
许多使性能得到显著提⾼的性能事宜可通过开始时仔细设计得以实现。
为最有效地优化 Microsoft? SQL Server? 2000 的性能,必须在极为多样化的情形中识别出会使性能提升最多的区域,并对这些区域集中分析。
虽然其它系统级性能问题(如内存、硬件等)也是研究对象,但经验表明从这些⽅⾯获得的性能收益通常会增长。
通常情况下,SQL Server ⾃动管理可⽤的硬件资源,从⽽减少对⼤量的系统级⼿动调节任务的需求(以及从中所得的收益)。
设计联合数据库服务器为达到⼤型 Web 站点所需的⾼性能级别,多层系统⼀般在多个服务器之间平衡每⼀层的处理负荷。
Microsoft? SQL Server? 2000通过对SQL Server 数据进⾏⽔平分区,在⼀组服务器之间分摊数据库处理负荷。
这些服务器相互独⽴,但也可以相互协作以处理来⾃应⽤程序的数据库请求;这样的⼀组协作服务器称为联合体。
只有当应⽤程序将每个 SQL 语句发送到拥有该语句所需的⼤部分数据的成员服务器时,联合数据库层才可以达到⾮常⾼的性能级别。
这称为使⽤语句所需的数据配置 SQL 语句。
使⽤所需的数据配置 SQL 语句不是联合服务器所独有的要求;在群集系统中同样有此要求。
虽然服务器联合体与单个数据库服务器呈现给应⽤程序的图像相同,但在实现数据库服务层的⽅式上存在内部差异。
单个服务器层联合服务器层⽣产服务器上有⼀个 SQL Server 实例。
数据库-精品文档

以图形结构形式存储数据,适用于社交网络、推 荐系统和路由协议等领域。
非关系型数据库的适用场景
应对大量数据的存储和查询需求,非关系型数据 库具有更高的并发写入和读取性能。
数据结构不固定或非结构化数据较多,非关系型 数据库可以更好地应对数据格式的变化和数据的 动态扩展。
需要高可用性和容灾能力,非关系型数据库具有 更好的分布式架构和数据备份能力。
药物管理和处方记 录
通过数据库管理药物信息和处 方记录,实现处方的电子化存 储和管理,提高医疗工作效率 和药品使用安全性。
病历管理和数据分 析
存储和管理病人病历信息,进 行数据分析,以便医生和研究 人员更好地了解疾病发生和发 展趋势,为临床决策提供支持 。
THANKS
确保只有经过授权的用户可以访问敏感数据。
数据库性能优化
01
02
03
索引设计
通过合理使用索引,提高 数据查询和操作的速度。
数据库查询优化
使用合适的查询语句和参 数,避免不必要的连接和 嵌套查询。
数据分区
将数据按照逻辑关系进行 分区,提高数据查询和管 理效率。
数据库安全性
访问控制
通过身份认证和权限管理 ,防止未经授权的访问和 恶意攻击。
商品管理和库存控制
建立商品信息数据库,实现商品库存 的实时更新和调整,提高库存周转率 和客户满意度。
订单和物流管理
通过数据库管理客户的订单信息,实 现订单状态的实时查询和物流信息的 跟踪,提高订单处理效率和客户购物 体验。
在线教育和远程工作
人员信息管理
在线课程和资源管理
远程协作和沟通
建立教职员工和学生数据库,管理个 人信息和成绩记录,方便数据查询和 统计分析。
论Oracle数据库的性能优化问题

马 红 云
( 中国民用航 空大连 空中交通管理站 辽宁大连 1 1 6 0 3 3 )
摘要 : Or a c l e 数 据库作 为 目前适 用性 最好 的关 系数据库 引擎之 一, 能够 支持 各种业 务形式 、 处理各 种复 杂事务 , 得 到极 为广泛 的应 用。
1对数据库服务器 内存分配的调整
由于对服务器 内存参数 的调整对o r a c l e 的性能影响显著 , 它成 为O r a c l e  ̄据库性能调 优的首选对象。 服务器 内存参数 的调整主要 是对数据库系统全局 区的调整 , 系统全局 区包括共享池、 数据缓冲 区、 日志缓冲区 。 其 中最主要的是对数据缓冲区和共享池 的参数调
3 . 2表 的分 区和 并行 技 术
如果必须要在数据库运行特别耗时的操作。 应尽量地把这样的 操作分解 , 严格 限制操作所涉及的记录数 , 并设法使操作并行 , 充分 地提高 执行效率 。 ( 1 ) 使用分区 分区技术有两个潜在的好处: 提高查询性能和提 高数据 库可用性 。 数据库查询 时, 优化器知道那些分区包含查询所 要的数据 。 而其它分 区数据将不会被读取 , 从而查询 任务将更快完 成。 许 多 管 理 工 作 可 在 只 一个 分 区上 进 行 , 而 不 影 响 其它 分 区 的数 据。 例 如 可 以选 择 只 删 除一 个 表 分 区 中 的数 据 。 可对 表 分 区进 行 再 分割 , 把一个表分区迁移到不同的表 空间上 。 可只对 一个表分 区进 行分析 统计 。 表分区的这 些特性 。 ( 2 ) 使用并行 。 Or a c l e 数据库 中几乎 所有的操作都 支持 并行 特 性, 包括查询、 插入 、 和数据加载。 并行选项可 以使多个处理器 同时 处理一条命令 , 在创建库数据库对象 时可以设定 并行参数 , 也可在 查询语句 中重新设 。
数据库行业智能化数据库设计与优化方案

数据库行业智能化数据库设计与优化方案第一章智能化数据库设计概述 (2)1.1 智能化数据库设计理念 (2)1.2 智能化数据库设计流程 (2)1.3 智能化数据库设计关键技术与挑战 (3)第二章数据库智能建模 (3)2.1 数据库模型的选择与优化 (4)2.2 数据库模型的智能化调整 (4)2.3 数据库模型的自适应优化 (4)第三章数据库智能索引设计 (5)3.1 索引类型的选择与优化 (5)3.2 智能索引设计方法 (5)3.3 索引的智能化调整与维护 (6)第四章数据库智能分区策略 (7)4.1 分区策略的选择与优化 (7)4.2 智能分区策略设计 (7)4.3 分区策略的智能化调整与优化 (8)第五章数据库智能缓存管理 (8)5.1 缓存策略的选择与优化 (8)5.2 智能缓存管理方法 (9)5.3 缓存管理策略的智能化调整 (9)第六章数据库智能负载均衡 (10)6.1 负载均衡策略的选择与优化 (10)6.1.1 常见负载均衡策略 (10)6.1.2 负载均衡策略优化 (10)6.2 智能负载均衡方法 (10)6.2.1 基于机器学习的负载均衡方法 (11)6.2.2 基于深度学习的负载均衡方法 (11)6.2.3 基于遗传算法的负载均衡方法 (11)6.3 负载均衡策略的智能化调整 (11)6.3.1 数据采集与处理 (11)6.3.2 模型建立与训练 (11)6.3.3 策略自适应调整 (11)6.3.4 系统监控与评估 (11)第七章数据库智能数据压缩 (11)7.1 数据压缩方法的选择与优化 (11)7.1.1 数据压缩方法概述 (11)7.1.2 数据压缩方法的选择 (12)7.1.3 数据压缩方法的优化 (12)7.2 智能数据压缩策略 (12)7.2.1 智能数据压缩概述 (12)7.2.2 基于机器学习的数据压缩策略 (12)7.2.3 基于深度学习的数据压缩策略 (12)7.3 数据压缩的智能化调整与优化 (13)7.3.1 数据压缩参数的智能化调整 (13)7.3.2 数据压缩过程的智能化优化 (13)第八章数据库智能备份与恢复 (13)8.1 备份与恢复策略的选择与优化 (13)8.2 智能备份与恢复方法 (14)8.3 备份与恢复策略的智能化调整 (14)第九章数据库智能安全与隐私保护 (14)9.1 安全与隐私保护策略的选择与优化 (14)9.2 智能安全与隐私保护方法 (15)9.3 安全与隐私保护策略的智能化调整 (15)第十章数据库智能化运维与监控 (16)10.1 运维与监控策略的选择与优化 (16)10.2 智能化运维与监控方法 (16)10.3 运维与监控策略的智能化调整与优化 (17),第一章智能化数据库设计概述1.1 智能化数据库设计理念大数据、云计算和人工智能技术的迅猛发展,数据库行业正面临着前所未有的变革。
DB2数据库设计及优化技术研究

0 .引 言
信 息时代 的到 来 , 让我们 的生 活和 工作 中都有 着大 量 的信 息 和数 据 可以 使用 和处 理 , 大地 丰 富 了人 们 的生 活 , 大 了 极 扩 人 们的 视野 。如此 海量 的数 据 , 何组 织存储 和快 速读 取 已成 如 为 一个非 常关 键 的问题 。 些海 量数据 通 常是通 过各 式各样 的 这
o t i t n r s ac e . p mz i er e rh d i ao a e
【 ew rs】 B;a bs s n a bs ot i tnraoadt ae K y od D 2dt ae ei ; t ae pm ao; li la bs a d g da iz i e tn a
个 D 2数据 库系 统可 以 同时激 活 上千个 活 动进程 ,支持 同时 B 连接 十几万 个远 程 的分布 用户 , 非常适 用于 大型 的分 布式 应用
系统 。
大型数据库或数据库集群来管理的。 数据库实际上是按照一定
的 数据 结 构来 组 织 、 储 和管 理 数据 的 仓库 , 们 可 以将相 关 存 人
s rg . i p p rd tb s e i n o eo t z t ntc n u s r rs ac e a e n eD 2 a b s . o l f a b s e i n t a e I t s a e a a ed s na ds m pi a o h i e ee e rh db s d B t a S mer e o t a d s n d o nh a g mi i e q a ot h da e u s da e ga
的数据放入到这种仓库中 ,并根据管理 的需要进行相应的处
表连接优化
浓密树 它连接的两个输入可能都不是表,这种树的结构是完全自由的,查询优化 器只有在没有其他选择的情况下才会选择他。他常会出现在有无法合并的 视图或者子查询的时候。
连接的类型 两种写法 1、SQL-86 2、oracle9i开始支持SQL-92 我们下面来看看连接类型 1、交叉连接(笛卡尔连接) 将一张表的所有记录与另一张表的所有记录进行组合的操作。
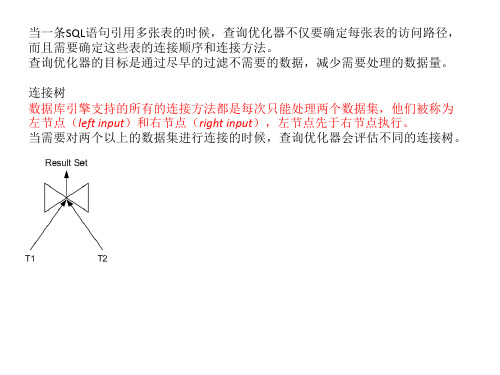
当一条SQL语句引用多张表的时候,查询优化器不仅要确定每张表的访问路径, 而且需要确定这些表的连接顺序和连接方法。 查询优化器的目标是通过尽早的过滤不需要的数据,减少需要处理的数据量。
连接树 数据库引擎支持的所有的连接方法都是每次只能处理两个数据集,他们被称为 左节点(left input)和右节点(right input),左节点先于右节点执行。 当需要对两个以上的数据集进行连接的时候,查询优化器会评估不同的连接树。
连接条件 限制条件
从实现的角度看,查询优化器误用限制条件与连接条件也是正常的,一 方面,连接条件可用来过滤数据,另一方面,为了最大程度的降低连接 使用的数据量,限制条件可能会在连接条件之前进行过滤。
首先执行的是限制条件 然后进行表连接
嵌套循环连接 嵌套循环连接处理的两个数据集被称为外部循环(outer loop,也就是驱动 数据源,driving row source)和内部循环(inner loop)。 外部循环作为左子节点,内部循环作为右子节点。 当外部循环执行一次的时候,内部循环需要针对外部循环返回的每条记录 执行一次。
注意:无法控制块预取功能的使用,如何以及是否使用块预取是数据库引擎自行 决定的。
其他可选的执行计划 只有当内部循环或者外部循环是 基于唯一索引扫描的时候才会使 用这种类型的执行计划。
分布式数据库总结
%%%%%%%%%%%%%%%第一章:分布式数据库系统概述数据库:长期存储在计算机内的有组织的,可共享的相关数据的集合。
数据库管理系统:DBMS是介于用户与操作系统之间的一层数据管理软件。
为用户或应用程序提供访问DB的方法,包括DB的建立、查询、更新及各种数据控制。
DBMS基于某种数据模型。
数据库系统:数据库系统(DBS)通常是指带有数据库的计算机应用系统。
包括数据库、相应的硬件、软件和各类人员。
数据库技术:数据库技术是研究数据库的结构、存储、设计、管理和使用的一门软件学科;是一门综合性较强的学科。
数据抽象:视图抽象——外模式;概念抽象——概念模式;物理抽象——内模式数据模型:数据模型三要素:数据结构;数据操作;完整性约束模式/内模式映象:该映象存在于模式与内模式之间,用于定义模式与内模式之间的对应性。
本映象一般在内模式中描述。
外模式/模式映象:该映象存在于外模式与模式之间,用于定义外模式和模式之间的对应性。
本映象一般在外模式中描述。
物理独立性:在数据库系统的三级模式结构中,存在模式/内模式的映象,当内模式发生变化时,只要修改模式/内模式的映象,就可以保持模式不变,从而保证程序与数据的物理独立性。
逻辑独立性:在数据库系统的三级模式结构中,存在外模式/模式的映象,当模式发生变化时,只要修改外模式/模式的映象,即可保持外模式不变,从而保证程序和数据的逻辑独立性。
DDBS具有如下四个基本特点:物理分布性逻辑整体性场地自治性场地之间协作性计算机网络:定义为相互联接、彼此独立的计算机系统的集合。
相互联接指两台或多台计算机通过信道互连,从而可进行通信;彼此独立则强调在网络中,计算机之间不存在明显的主从关系,即网络中的计算机不具备控制其他计算机的能力,每台计算机都具有独立的操作系统。
计算机网络的组成:通信子网和资源子网分布式数据库定义:物理上分散而逻辑上集中的系统,它使用计算机网络将地理位置分散而管理和控制又需要不同程度集中的多个逻辑单位(通常是集中式数据库系统)连接起来,共同组成一个统一的数据库系统。
semi join 的特点与方法
semi join 的特点与方法摘要:一、引言二、Semi Join的定义与作用1.定义2.作用三、Semi Join的特点1.基于谓词的连接2.保留连接结果中的重复行3.连接条件可以是软连接和硬连接四、Semi Join的方法1.使用INNER JOIN进行等值连接2.使用LEFT JOIN进行左连接3.使用RIGHT JOIN进行右连接4.使用FULL OUTER JOIN进行全外连接五、Semi Join在实际应用中的案例与优化1.案例介绍2.优化方案六、总结正文:一、引言在数据库查询中,连接(Join)操作是一项重要的技术。
连接分为内连接(Inner Join)、左连接(Left Join)、右连接(Right Join)和全外连接(Full Outer Join)。
本文将介绍一种特殊的连接操作——Semi Join,并探讨其在数据库查询中的应用与优化。
二、Semi Join的定义与作用1.定义Semi Join,又称为半连接,是一种基于谓词(Predicate)的连接操作。
它根据某个条件筛选出两个表中满足条件的元组,然后将这些元组连接在一起。
2.作用Semi Join的主要作用是在保证连接条件成立的同时,保留连接结果中的重复行。
换句话说,Semi Join可以看作是一种“保留重复行”的连接操作。
三、Semi Join的特点1.基于谓词的连接Semi Join是基于谓词的连接,这意味着连接条件必须是一个谓词(如条件表达式、逻辑运算符等)。
只有当两个表中的记录满足连接条件时,才会被纳入连接结果中。
2.保留连接结果中的重复行与Inner Join不同,Semi Join在连接过程中不会去除重复行。
这意味着,如果连接结果中存在重复行,Semi Join会将这些重复行全部保留下来。
3.连接条件可以是软连接和硬连接Semi Join既支持软连接(基于谓词的连接),也支持硬连接(基于等值的连接)。
这使得Semi Join在实际应用中具有较高的灵活性。
第九章_分布式数据库
26
习 题:
P.215
9.3 9.7 ---- 9.9 9.12---9.15
27
DB1 计算机1 □ T1 □ T2 □ T3
DB2 计算机2
场地1 场地1:
场地2 场地2:
□ T1 □ T2 □ T3
通信网络
DB3 计算机3
场地3
□ T1 □ T2 □ T3
4
分布式数据库的数据分散在各个场地上,但这些数据 在逻辑上都是一个整体,如同一个集中式数据库。 分布式数据库包括:局部数据库和全局数据库两个概念。 分布式数据库的“逻辑整体性”特点: 局部数据库是从各个场地的角度;
24
DDBMS的一般功能结构:
用户查询
查询处理模块
查询分析
需要的数据
完整性 处理模块
数据定位
系统 DD
优化算法 局部处 理命令 LDBMS 分布策略 调度处理模块
实际的数据 可靠性 处理模块 错误 对网络的 监视信息
数据 DB
计算机
网 络
25
§5
自学:
分布式查询处理
查询代价的估算方法
具有半联接的优化策略
全局数据库是从整个系统角度出发研究问题。
5
二、分布式数据库系统(DDBS)的定义
定义一:DDBS是物理上分散、逻辑上集中的数据库系统,系统中 的数据分布存放在计算机网络的不同场地的计算机中,每一场地 都有自治处理(即独立处理)能力并能完成局部应用,而每一场 地也参与(至少一种)全局应用,程序通过网络通信子系统执行 全局应用。
人员易于管理,便于完成大型任务;
数据集中管理,减少了数据冗余; 较高的数据独立性。
随着数据库应用的不断发展,规模不断扩大,集中式系统存在如下 缺点: 大型DBS的设计和操作较复杂;
分布式习题
数据库控制和通信子系统的组成和功能。 7. 分布式数据库系统潜在的优点是什么?存在哪些技术问题?
第二章习题
2.1 概述分布式数据库的创建方法、方法特点和适用范围。 2.2 分布式数据库设计的主要目标是什么? 2.3 概述分布式数据库设计的关键问题及解决方法。 2.4 考虑为局域网设计的分布式数据库系统和为广域网设计的分布式数
假定关系employee按plant-number水平分片,且每个片段本地存放在 它所对应的工厂站点;关系machine没有被分片,整个关系存放在 Armonk站点(整个系统站点的个数等于工厂的个数+1),并且假定 存放machine关系的Armonk站点就是提出查询和需要结果的站点。 请为下列的查询设计一个好的处理策略:
3
3.6 设有关系R,S,T 如图3.13所示。
(1)设计连接R∞S ∞T。
(2)计算半连接R ∝S, S ∝R,S∝T,T ∝R,T
∝S,
R ∝AT。
R
B
C
S
T
B
C
D DEI
2
3
5
3
5
6
669
5
3
6
3
5
9
878
1
6
8
6
8
3
856
3
4
6
5
9
6
389
5
3
5
4
1
6
2
6
8
5
8
4
图3.13 习题3.6中的三个关系 4
48为什么说两阶段提交协议在不丢失运行日志信息的情况下可以从任何故障恢49分布式数据库系统中对多副本数据更新通常采用什么方法
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
基于半连接的分布式数据库查询优化研究 余 弋 (安徽工程大学计算机与信息学院,芜湖 241000 关键词:分布式数据库;查询优化;半连接操作 收稿日期:2010-06-23 修稿日期:2010-07-23 作者简介:余弋(1985-,女,安徽芜湖人,硕士研究生,研究方向为分布式数据库 分布式数据库系统的分布和冗余使查询处理复杂化,因此分布式查询处理的优化显得尤为
重要。半连接操作是查询技术中的非常有效和重要的技术。分析分布式数据库中半连接操作的过程以及执行代价,比较两种半连接操作的执行代价评估,介绍SDD-1算法。
摘 要:0引言 分布式数据库是把数据分布在不同的站点上,但 这些数据片是建立在统一的逻辑框架上的,并有高级的数据库管理系统进行统一控制,它是统一性与自治性的完美结合。分布式查询处理是用户和分布式数据库的接口,是分布式数据库的一项关键技术。由于数据的分布使得分布式数据库系统中的查询问题比集中式数据库要复杂得多。不同的查询处理方法可能导致不同的通 信费用、并行时间以及响应时间。要获得最小的查询开销,就要对数据进行合理分布、查询优化。
1分布式查询优化目标 在集中式数据库系统中,由于系统大都运行在单个 处理器的计算机上,所以查询总代价为CPU 代价+I/O 代价,查询优化的目标是磁盘存取数,即要求产生最小磁盘数的查询执行计划。
在分布式数据库系统中,由于数据的分布和冗余,使得查询处理除了考虑CPU 代价和I/O 代价之外,还需要考虑在网络上传输数据的时间开销以及多个节点并行执行带来性能的提高,总代价=CPU 代价+I/O 代价+通信代价,查询执行时使其通信代价最省是分布式数据库查询优化的目标之一,另一种目标是以每个查询的相应时间最短为标准。
在分布式查询优化中经常同时使用这两个标准。根据系统应用的不同,一种作为主要标准,一种作为次
要标准。 2半连接查询优化的基本方法 在分布式数据库中,查询优化包括两个方面:查询 策略优化和局部处理优化,而分布式查询策略优化尤为重要。在分布式数据库中,查询的执行策略有很多种,不同的执行策略,系统资源耗费和响应时间也不同。
查询优化有两种基本方法:①查询转化,即以不同顺序执行关系操作;②查询映射,以一系列高效算法访问各种设备和实现关系操作。目前,对查询处理出现了许多优化算法,例如适用于多站点连接的基于半连接的优化算法和基于直接连接的优化算法等。 2.1基本原理 采用半连接操作,在网络中只传输参与连接的数据,数据在网络中传输时,都是以整个关系(也可以是片段传输,显然这是一种冗余的方法。在一个关系传输到另一场地后,并非每个数据都参与连接操作或都有用。因此,不参与连接的数据或无用的数据不必在网络中来回传输。
用半连接技术实现连接操作的程序,即用一组具有半连接与连接的操作映射出具有与等连接相同结果的过程。
2.2操作过程 (1半连接操作 半连接操作是由投影和连接操作导出的一种关系代数操作。假定有两个关系R 和S ,在属性R.A=S.B 上做半连接操作可表示为:
R ∝S=∏R (R ∞S (1R ∝S=R ∞(∏B (S (2 (2采用半连接操作表示连接操作的过程
图1半连接方法表示连接操作过程 (1在站点2作关系S 在R 和S 公共属性集B 上的投影∏B (S ; (2把∏B (S 结果送到站点1,代价为C 0+C 1×size (B ×val (B[s]; (3在站点1上计算半连接,设置其结果为R',则 R'=R ∝A=B S ; (4把R'从站点1送到站点2的代价是:C 0+C 1×size (R'×card (R'; (5在站点2上执行连接操作:R'∝A=B S 2.3费用估计 基于半连接程序的查询优化的主要目标是减少站点间的通信代价。通信代价与分布式数据库所依附的计算机网络模型及其性能有关。对于不同的计算机网络应该根据实际情况,设计对应的费用估计侧率和方法。
如果假设网络中站点之间传递相同信息量的数据所花费的代价是相同并且忽略站点之间的差异以及路由选择等费用,那么一个站点发送X 个字节的信息到另一个站点所花费的费用可以描述为C[X]=C 0+C 1×X,其中C 0和C 1是网络性能相关的参数。
利用这个公式可以估计各种查询方案对应的传输费用。例如,对于全连接操作R ∞A=B S ,假如现在用下面的三种方案来解决。
(1采用S ∞A=B (R ∝A=B (∏B S 对应的半连接程序,费用有: ①在本地把S 投影到B :假设∏B S 结果为X B 个字节,投影费用为P B ; ②把X B 个字节发送给R 所在站点:费用为C B =C 0+C 1×X B ; ③和R 执行半连接运算:假设结果为X RB 个字节,半连接费用为S B ; ④把X RB 个字节送到S 所在的站点:费用为C RB = C 0+C 1×X RB ; ⑤和S 执行连接运算:假设连接费用为J SRB ,那么总的费用为:COST 1=P B +C B +S B +C RB +J SRB =(P B +S B +J SRB +
(2C 0+C 1×(X B +X RB =COST 11+COST 12。 其中COST 11为本地运算费用,COST 12为站点传输费用。 (2采用R ∞A=B (S ∝A=B (∏B R 对应的半连接程序,费用有: ①在本地把R 投影到A :假设∏A R 结果为X A 个字节,投影费用为P A ; ②把X A 个字节发送给S 所在站点:费用为C A =C 0+C 1×X A ; ③和S 执行半连接运算:假设结果为X SA 个字节,半连接费用为S A ; ④把X SA 个字节送到R 所在的站点:费用为C SA =C 0+C 1×X SA ; ⑤和S 执行连接运算:假设连接费用为J SRB ,那么总的费用为:COST 2=P A +C A +S A +J RSA =(P A +S A +J RSA +(2C 0+
C 1×(X A +X SA =COST 21+COST 22。 其中COST 21为本地运算费用,COST 22为站点传输费用。 (3直接采用全连接R ∞A=B S 连接程序,一种可能解决办法和费用如下。 ①把R 全部发送给S 所在站点:假设R 为X R 个字节,费用C R =C 0+C 1×X R ; ②和S 执行连接运算:假设连接费用为J RS ,那么,总的费用为COST 3=C R +J RS =J RS +(C 0+C 1×X R =COST 31+
COST 32。 其中COST 31为本地运算费用,COST 32为站点传输费用。 另外一种可能的方案是把S 全部发送给R 所在的站点并和R 进行全连接,那么对应费用为COST 4=J SR +(C 0×X S =COST 41+COST 42,其中COST 41为本地运算费用,
,,,,,,,,, ,,,,,,, ,,,,Á,,,,,,,Á COST42为站点传输费用。 比较上面的COST1、COST2、COST3和COST4,可以选取代价最小的加以执行。
点之间传递相同信息量的数据所花费的代价是相同的,这个假设在站点之间的距离和发送/接收性能相当的情况下是合理的。如果站点之间以及路由选择等费用差异很大时,需要重新考虑相关因素的影响因子,缺点合理的费用评估方法。
2.4SDD-1算法 SDD-1算法有两部分组成:一是基本算法,根据评估缩减程序的费用、效益、收益估算几个因素,给出全部的半连接缩减程序集,决定一个最有益的(收益的执行策略,但效率不一定高;另一个是后优化,将基本算法得到的解进行修正,以得到更合理的执行策略。
(1基本算法 ①基础:已有了从查询数转换的优化模型且所有关系已完成局部缩减。 ②方法: ●根据已得到的缩减关系的静态特性表,构造可能的半连接缩减程序; ●按半连接缩减程序的静态特性表分别计算其费用和收益,从一组可能的静态特性表中选取一个半连接程序,设为M;
●以M完成缩减后,又将产生一组新的静态特性表再进行计算,再从一组可取的静态特性表中选一个半连接程序,但是每个半连接程序只做一次(避免导致缩减程序太长,效率不高; ●反复直到无半连接缩减程序为止。 ③结束:以若干次迭代以后的最后缩减关系的静态特性表为基础,进行场地选择(费用计算,决定执行查询的场地(可能与原查询要求的场地不同。
(2后优化 在基本算法中,每次迭代时只考虑本次迭代时的改善,这种改善不一定最好。后优化有两种修正:
①若最后一次半连接程序缩减关系的所在场地恰好是被选中的查询执行场地,则最后一次半连接可以取消;
②对基本算法的主迭代所构成的半连接程序的流程图进行修正。因为一开始的(或某一个半连接缩减程序的代价很高,例如有R+S。这时可以把S缩减后在进行半连接缩减,即可修正半连接的操作程序。
3结语 本文重点讨论基于半连接的查询优化技术在分布式数据库中的应用,证明了查询策略的好坏将直接影响计算机网络资源的耗费。但分布式数据库系统的建立环境和技术内容复杂,对于查询优化技术,还有许多问题有待进一步研究和解决。相信随着计算机网络技术的飞速发展,分布式数据库技术也必将迅猛发展,并日趋完善。
参考文献 [1]陈建荣,严隽永,叶天荣.布式数据库设计导论(第一版 [M].清华大学出版社,2002:20~78
[2]Bell D,Crimson J.Distributed Database System[M].New Jer-sey:Addison Wesley Publishing,2004:5~79
[3]邵佩英.布式数据库系统及其应用[M].科学出版社2006, 1:3~41