基于HMM的连续语音识别
百度百科—语音识别

语音识别与机器进行语音交流,让机器明白你说什么,这是人们长期以来梦寐以求的事情。
语音识别技术就是让机器通过识别和理解过程把语音信号转变为相应的文本或命令的高技术。
语音识别技术主要包括特征提取技术、模式匹配准则及模型训练技术三个方面。
任务分类和应用根据识别的对象不同,语音识别任务大体可分为3类,即孤立词识别(isolated word recognition),关键词识别(或称关键词检出,keyword spotting)和连续语音识别。
其中,孤立词识别的任务是识别事先已知的孤立的词,如“开机”、“关机”等;连续语音识别的任务则是识别任意的连续语音,如一个句子或一段话;连续语音流中的关键词检测针对的是连续语音,但它并不识别全部文字,而只是检测已知的若干关键词在何处出现,如在一段话中检测“计算机”、“世界”这两个词。
根据针对的发音人,可以把语音识别技术分为特定人语音识别和非特定人语音识别,前者只能识别一个或几个人的语音,而后者则可以被任何人使用。
显然,非特定人语音识别系统更符合实际需要,但它要比针对特定人的识别困难得多。
另外,根据语音设备和通道,可以分为桌面(PC)语音识别、电话语音识别和嵌入式设备(手机、PDA等)语音识别。
不同的采集通道会使人的发音的声学特性发生变形,因此需要构造各自的识别系统。
语音识别的应用领域非常广泛,常见的应用系统有:语音输入系统,相对于键盘输入方法,它更符合人的日常习惯,也更自然、更高效;语音控制系统,即用语音来控制设备的运行,相对于手动控制来说更加快捷、方便,可以用在诸如工业控制、语音拨号系统、智能家电、声控智能玩具等许多领域;智能对话查询系统,根据客户的语音进行操作,为用户提供自然、友好的数据库检索服务,例如家庭服务、宾馆服务、旅行社服务系统、订票系统、医疗服务、银行服务、股票查询服务等等。
语音识别方法语音识别方法主要是模式匹配法。
在训练阶段,用户将词汇表中的每一词依次说一遍,并且将其特征矢量作为模板存入模板库。
隐马尔可夫模型在语音识别中的应用

隐马尔可夫模型在语音识别中的应用一、引言隐马尔可夫模型(Hidden Markov Model,HMM)是一种基于概率统计的模型,由于其灵活性、通用性和有效性,使其成为自然语言处理、语音识别等领域中重要的工具之一。
语音识别是指通过计算机对语音信号进行处理和分析,从而转换成文本的过程。
本文将探讨隐马尔可夫模型在语音识别中的应用,以及其在该领域中的局限性和发展方向。
二、隐马尔可夫模型的原理隐马尔可夫模型是一种马尔可夫过程,其特点是其状态不是直接观察到的,而是通过观察到的输出来间接推断。
其由状态转移概率矩阵A、观测概率矩阵B和初始状态概率向量π三部分组成。
1.状态转移概率矩阵A状态转移概率矩阵A表示从一个状态转移到另一个状态的概率。
设隐马尔可夫模型中有N个状态,状态集合为{S1,S2,...,SN},则状态转移概率矩阵A为:A=[aij]N×N其中,aij表示从Si转移到Sj的概率。
2.观测概率矩阵B观测概率矩阵B表示在某个状态下产生某个观测值的概率。
设观测值的集合为{O1,O2,...,OM},则观测概率矩阵B为:B=[bj(k)]N×M其中,bj(k)表示在状态Sj下,观察到Ok的概率。
3.初始状态概率向量π初始状态概率向量π表示模型从某个状态开始的概率分布。
设初始状态的集合为{S1,S2,...,SN},则π为:π=[π1,π2,...,πN]其中,πi表示从状态Si开始的初始概率。
三、隐马尔可夫模型在语音识别中的应用在语音识别中,隐马尔可夫模型被广泛应用,其主要应用场景包括:1.语音信号的建模在语音识别中,将语音信号建模为声学特征流是一个核心问题。
而声学特征流是通过将语音信号划分为小时间窗进行采样获得的。
在隐马尔可夫模型中,状态对应着声学特征流的各个时间窗,而观测值则对应着该时间窗的声学特征。
因此,通过隐马尔可夫模型对声学特征流进行建模,可以从语音信号中提取出关键的声学特征,并进行语音识别。
HTK2

识别结果评估: N −D−S ×100% Correct= N
Accuracy = N −D−S−I × 100 % N
应用HTK建立连续语音识别的实例
数据准备 创建模型及学习
单音素模型 三音素模型 状态捆绑 增加高斯混合模型的个数
识别及评估
数据准备
训练及待识别语音文件(.wav) 训练语音包含的所有词(wlist) 训练语音的词级标注文件(.lab 或 word.mlf) wlist中词的发音词典dict(见附)
可根据实际问题需要适当增加高斯模型个数
识别及评估
识别HVite
HVite -H hmm15/macros -H hmm15/hmmdefs -S test.scp -l ’*’ -i recout.mlf -w wdnet -p 0.0 -s 5.0 dict tiedlist 词级、音素级、三音素级识别结果
应用HTK建立连续语音识别系统
------------王风娜
基本内容
知识回顾
HTK工具包 基于HMM的连续语音识别
应用HTK建立连续语音识别系统实例
知识回顾
HTK工具包
数据准备工具
HDMan、HCopy、HLEd、HSGen、HBuild、HLStats 、HParse
模型训练及优化工具
HERest、HInit、HRest、HHEd、HCompV
识别工具
HVite
性能评估工具
HResults、HRec
基于HMM的连续语音识别系统
HMM
三个基本问题:推理、学习、识别
模型初始状态 转移矩阵
ห้องสมุดไป่ตู้
λ ={π, A, B}
状态产生观测向 量的概率分布
语音识别技术

基于DTW的语音识别
• DTW算法通过局部优化的方法实现加权距离和最小,即
D ( i , j ) = m in
C
∑
N
n=1
d x , y Wn i n j n ( ) ( )
(
)
∑W
n =1
N
n
Wn 为加权函数,需考虑两个因素: ⑴ 根据第n对匹配点前一步局部路径的走向来选取; ⑵ 考虑语音各部分给予不同权值,以加强某些区别特征。
• 对于孤立词(或命令)识别,DTW算法与HMM算法在相同的 环境下,识别效果相差不大。 • 优点: -可靠性强 -复杂度低 • 关于DTW理论已作介绍
基于matlab的DTW识别算 法实现
• 实验模板:”a,b,c,d,e,你好“的wav文件(8k采样, 单声道,精度8位) • DTW算法采用两步约束:
・ 说话人识别常用参数分类:
(1) 线性预测参数及其判生参数 (2) 语音频谱直接导出的参数 (3) 混合参数 (4) 其他鲁棒性参数
说话人识别与语种辨识
・ 模式匹配的方法: (1) 概率统计方法; (2) 动态时间规整方法(DTW) (3) 矢量量化方法(VQ) (4) 隐马尔可夫模型方法(HMM) (5) 人工神经网络方法(ANN)
语音识别的概述
语音识别系统的分类
分类依据 语音的发音 方式 孤立词语音 识别系 统 连接字语音 识别系 统 非特定人语 音识别系 统 说话人 词汇量的大 小 小词汇量 (10-100) 识别的方法 动态时间规 整(DTW) 矢量量化 (VQ) 隐马尔可夫 模型 (HMM ) 隐马尔可夫 模型 (HMM)、 人工神经 网络 (ANN) 应用场合
y y
yk =
Y = y1 , y2 ,L , yTy , k = 1, 2,L , Ty
隐马尔可夫模型算法及其在语音识别中的应用

隐马尔可夫模型算法及其在语音识别中的应用隐马尔可夫模型(Hidden Markov Model,HMM)算法是一种经典的统计模型,常被用于对序列数据的建模与分析。
目前,在语音识别、生物信息学、自然语言处理等领域中,HMM算法已经得到广泛的应用。
本文将阐述HMM算法的基本原理及其在语音识别中的应用。
一、HMM算法的基本原理1.概率有限状态自动机HMM算法是一种概率有限状态自动机(Probabilistic Finite State Automata,PFSA)。
PFSA是一种用于描述随机序列的有限状态自动机,在描述序列数据的时候可以考虑序列的概率分布。
PFSA主要包括以下几个部分:(1)一个有限状态的集合S={s_1,s_2,…,s_N},其中s_i表示第i个状态。
(2)一个有限的输出字母表A={a_1,a_2,…,a_K},其中a_i表示第i个输出字母。
(3)一个大小为N×N的转移概率矩阵Ψ={ψ_ij},其中ψ_ij表示在状态s_i的前提下,转移到状态s_j的概率。
(4)一个大小为N×K的输出概率矩阵Φ={φ_ik},其中φ_ik 表示在状态s_i的前提下,输出字母a_k的概率。
2. 隐藏状态在HMM中,序列的具体生成过程是由一个隐藏状态序列和一个观测序列组成的。
隐藏状态是指对于每个观测值而言,在每个时刻都存在一个对应的隐藏状态,但这个隐藏状态对于观测者来说是不可见的。
这就是所谓的“隐藏”状态。
隐藏状态和观测序列中的每个观测值都有一定的概率联系。
3. HMM模型在HMM模型中,隐藏状态和可观察到的输出状态是联合的,且它们都服从马尔可夫过程。
根据不同的模型,HMM模型可以划分为左-右模型、符合模型、环模型等。
其中最常见的是左-右模型。
在这种模型中,隐藏状态之间存在着马尔可夫链的转移。
在任何隐藏状态上,当前状态接下来可以转移到最多两个状态:向右移动一格或不变。
4. HMM的三个问题在HMM模型中,有三个基本问题:概率计算问题、状态路径问题和参数训练问题。
基于短时平均幅度和HMM的语音识别系统研究

5人 ×1 0次 的语 音 数 据 进 行 隐 马 尔 可 夫 模 型 训
识别 ( 指 纹识 别 、 手纹 识别 及 眼纹 识别 等 ) 和声 纹 识别 ( 特 殊 口令及 语 音识 别 等 ) , 这两 大 类 方 法各
自存 在 相应 的优 、 缺点 , 其 中声 音识 别最 大 的问
根 据声 音信 号 自身 的非 平 稳 特 征 , 预 处 理 过
程 中采用 加窗 函数 及 短 时平 均 幅 度 的方 法 , 实 现
发音样本 体 系, 提 出 了使 用音 频 波段 检 测 的 思路 。基 于 短 时 平 均 幅 度优 化 获得 音 频 信 号 , 进 而用 隐马尔
可 夫模 型进 行 识 别 , 设 计 了语 音 识 别 系 统 。 实验 结 果表 明 : 每人采集 1 O组 样 本 训 练 , 针 对 五 人 的 不 同样
题 在 于识别 分辨 率不 够高 , 存在 安全 隐患 , 怎 样提
高识 别 分 辨 率 成 为 制 约 这 种 方 法 应 用 的核 心 内 容。
笔 者通 过一 些 基 础 实 验研 究 , 确定 不 同 人 发
零率 3种 预处 理 方 法 , 发 现 短 时平 均 能 量 方法 因对 电平 值过 于 敏 感 而 不够 稳 定 , 短 时平 均过 零
率不 能够 有效 表 征 信 号 特征 , 因 而选 用 短 时平 均
幅度 的预处 理方 式 , 进 行 有 效 的特 征 提 取 和 有效
对齐。
声 的音 频 区别 , 研究语 音 的基本 特 征 , 并 针对 语 音 考 勤这 一 具 体 对 象 , 设 计 基 于 短 时 平 均 幅 度 和 HMM 的语 音识 别 系统 的总体 方案 , 最终 实 现通 过 音 频方 法 对 不 同人 单 个 词 “ 到” 发 声 的判 别 。系 统 研究 过程 中 , 通 过 从 硬 件 到 软件 的研 究 思 路 进 行 逐 步测试 与 改进 , 最终 确定 先用 检测 方案 , 并 达 到有 效 区分 的 目标 。首 先 , 通 过不 同传 感 器 的测
语音识别算法及其在嵌入式系统中的应用
电子技术与软件工程Electronic Technology & Software Engineering电子技术Electronic Technology语音识别算法及其在嵌入式系统中的应用李青云(晋中信息学院信息工程学院山西省晋中市030800 )摘要:本文简单概述了语音识别算法,对不同的嵌入式语音识别系统进行了比较和分析,最后详细介绍了嵌入式语音识别系统的 构建。
关键词:语音识别;识别算法;嵌入式系统;算法运用近年以来,国内的社会经济实现了快速的发展和推进,其重要 表现之一就是计算机技术的飞速发展,目前计算机己经成为了现代 社会大众日常工作和生活中必不可少的一部分,然而人机交互水平 与计算机技术发展水平不相符合,影响了现代社会大众对于计算机 系统的应用。
在这种情况下,就需要实现高水平的语音识别算法在 嵌入式系统中的应用,使得计嵌入式系统的语音识别性能得到提升,这样才能实现复杂的语音识别,嵌入式系统也才能实现智能化发展。
而且语音识别算法及其在嵌入式系统中的应用也更加符合现代社会 大众的使用习惯和切实需求,因此语音识别算法的运用是具有充分 的可行性和必要性的,对于各个社会领域的发展也是极为重要的。
1语音识别算法在社会大众的显示工作和生活当中,语音识别系统应用范围比 较广,并且这种交互方式是人类自身最自然的一种交互方式,使用 起来符合人类自身的习惯,同时嵌入式设备自身的小型化对于语音 识别算法的应用也大有裨益。
目前所应用的嵌入式设备通常情况下 是针对特定的应用进行设计的,只需要对几十个词的语音命令进行 识别,属于小型的语音识别系统,一旦遇到大词汇量和连续的语音 识别,其应用的局限性就会变得尤其明显,难以满足当代社会大众 对于嵌入式设备的要求和需求。
而在实际的语音识别算法及其在嵌 入式系统中的应用过程中,还具有很多其他的因素需要进行综合性 的考量,这样才能达到理想的语音识别效果,并且可以在显示社会 发展过程中进行对应的应用其中成本因素就是需要考量的因素之一,因为未来的语言识别系统的应用将是十分广泛的,其成本投 入过大的情况下,不能形成良好的性价比。
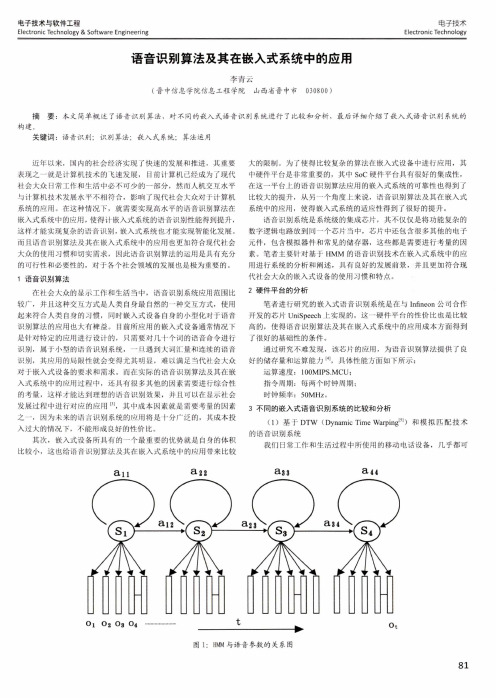
基于HMM的连续小词量语音识别系统的研究

基于HMM的连续小词量语音识别系统的研究高建【摘要】The research based on the principle of speech recognition and chips of UDA1314TS DPS and ARM S3C2410,the acoustic models of HMM and Viterbi algorithm model was used for training model and recognition, and a speech recogni tion system of continuous and small vocabulary was designed. Examples show that the speech recognition system has a good practical and transplantation. The laboratory and outside recognition rate reach as high as 95. 6% and 92. 3%.%为了提高语音识别效率及对环境的依赖性,文章对语音识别算法部分和硬件部分做了分析与改进,采用ARMS3C2410微处理器作为主控制模块,采用UDA1314TS音频处理芯片作为语音识别模块,利用HMM声学模型及Viterbi算法进行模式训练和识别,设计了一种连续的、小词量的语音识别系统.实验证明,该语音识别系统具有较高的识别率和一定程度的鲁棒性,实验室识别率和室外识别率分别达到95.6%,92.3%.【期刊名称】《现代电子技术》【年(卷),期】2011(034)011【总页数】3页(P205-207)【关键词】语音识别;嵌入式系统;Hidden Markov Models;ARM;Viterbi算法【作者】高建【作者单位】辽宁大学计算中心,辽宁沈阳110036【正文语种】中文【中图分类】TN912-340 引言嵌入式语音识别系统是应用各种先进的微处理器在板级或是芯片级用软件或硬件实现的语音识别。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
还望老师同学指正 Thanks!
3.2.7、识别网络
从根节点开始,与每个可能作为句子开始的词节点相连,每个词又 和它可能的相连,以此类推,构建好初始网络如下所示:
初始词网络
分解成三音素的网络
树结构的网络
识别网络中的词串假设 One two four
句子对应的 音素级脚本
特征向量 文件O
w ah1 n t uw1 f ao1 r
1.2.1、数据准备工具
HDMan:利用各种数据源生成发音词典 HCopy:数据文件格式转换 HLEd:编辑标注文件 Hbuild:转换各种不同格式的代表语言模型的文件并输出标HTK 网格格式 HSGen:根据以标准HTK网格格式定义的词,网络自动随机产生 一组句子 HSLab:对语音标注文件进行标注的编辑器
1)、训练
2)、识别
3.2、连续语音识别
3.2.1、面临问题 连续语音句子中每个单词发音没有明显的界限, 分割困难; 协同发音影响; 语音信号随着说话人的语速差异及性别、生理因 素、心理条件、社会因素等等产生很大变化; 语言歧义性和语言结构的随意性。
3.2.2、模型结构
单个HMM模型
q1 o1
q2 o2
通过递归计算前向后向概率得到
2)、学习—如何根据观察序列不断修正模型参数使 得 max{ P (O | λ )} 。
利用经典Baum-Welch算法,即EM算法
3)、 识别---已知观察序列O和模型,如何确定一个合理的状态 序列,使之能最佳地产生O。 Viterbi算法
3、基于HMM的语音识别
3.1孤立词识别
w* = argmax p(w | O) = argmax
w w
p(w) p(O | w) p(O)
式中 w = w 1 , w 2 ,....ቤተ መጻሕፍቲ ባይዱw s 是任意长度的任意词串序列。
p (w)
由统计语言模型提供; 由各单词和相关的三音素的声学模型决定。
p(O| w)
3.2.6、N-gram 语言模型
N:原始脚本文件中词的个数 D:识别结果对应于参考句子脚本中删除的词的个数 S:识别结果对应于参考句子脚本中替换的词的个数 I:识别结果对应于参考句子脚本中插入的词的个数
5、结束语
HMM在语音处理中已得到了广泛应用,它 的双重随机特性,可以很好地描述语音信号的短 时平稳特性和总体非平稳特性,但由于它自身模 型结构的限制,对语音的某些特性仍不能很好地 进行描述,但仍可以作为我们学习新模型的一个 基础。
调入句子的脚本文件 建立 复合 HMM ( λ1,..., λQ ) 利用前向后向算法 计算前项变量和后向 变量值
参数重估
Y
还有训练句子么?
N
参数达到 收敛的结果了么?
N
Y 训 练 好 的 HMM模 型 库
3.2.5、嵌入式识别
识别任务就是在观测向量 O 下,最可能的词串序列 w ,使得p ( w | O ) 最大的词串序列。根据Bayes准则,有
假设 w 是长度为S 的词串序列w = w 1 , w 2 ,.... w s,其发 生 概率 p (w) 可近似假设为
pN{w} = Π p{wi | wi−1, wi−2 ,...,wi−N+1}
i=1
s
此式叫做N-元语言模型,可以通过统计训练数据库的文本得 到。当N很大时,考虑起来比较复杂,所以通常使用二元文法(BiGram)。
计 算 在 复 合 HMM 下 的 概 率 p(O | w)
声学模型 HMMλ1,...,λQ) ( 语言模型
p(w)* p(O| w)
p(w| O)
嵌入式识别流程图
4、利用HTK构建连续语音识别系统
1)、数据准备
对于训练语音库及其词一级标注抄本,准备工作有: a.利用音素发音词典,把词级抄本转换成音素级抄本; b.对语音信号进行特征提取,HTK可以提取的特征有: MFCC、PLP、LPC等;
1.2.3、识别工具
HVite:基于Viterbi算法的词识别器
1.2.4、性能评估工具
HResults:HTK模型性能分析工具 HRec:评估结果输出
2、HMM简述
2.1HMM定义
模型初始状态 转移矩阵
λ ={π, A, B}
状态产生观测向 量的概率分布
2.2、HMM三个基本问题
生此观察序列的概率 P(O| λ) 。 1)、推理---已知观察序列O和模型 λ ,如何计算由此模型产
q3 o3
q4 o4
q5 o5
复合HMM模型
3.2.3 、建模单元
1)、音素:英语中常用的有45个,如ao、b、t、sil等。 2)、三音素:即考虑到当前音素的左半和右半连接音素。 例如:Beat it 音素级抄本为: sil b iy t ih t sil 三音素级抄本为: sil sil-b+iy b-iy+t iy-t+ih t-ih+t ih-t+sil sil 词间三音素、词内三音素
2)、HMM训练
HTK提供一种逐步细化的建模过程,先建立单音素的 HMM,再考虑因素上下文,扩展到三音素HMM,最后进行状 态捆绑,并逐步增加高斯混合概率密度函数的个数,直至模型 复杂度达到一定程度,或系统性能达到一定指标。
3)、结果测试
HTK利用构建的识别网络,可以把语音识别为带有起始和持续 时间的单词序列,并可以利用HTK对齐工具,把结果翻译成相应的音 素序列,语言模型在词层和音素层都应用了双元文法,并在搜索过程
基于HMM的连续语音识别
----------王风娜
HTK工具包 HMM简述 基于HMM的连续语音识别 利用HTK构建连续语音识别系统
1、HTK 工具包
1.1、工具包框架
1.2、工具分类
HTK工具包是由若干带有特定执行功能的程序组 成。按照工具所完成功能的性质,可以将整个工具包分成 四个部分: 数据准备工具 模型训练和优化工具 识别工具 性能评估工具
1.2.2、模型训练和优化工具
HCompV:统计训练数据中的全局均值和方差 HERest:利用Baum-Welch算法对HMM模型进行嵌入式训练 HINit:HMM模型初始化 HRest:利用Baum-Welch算法对HMM模型进行一次训练 HHEd:直接对HMM进行各种编辑和优化操作.例如改变模型类型,上 下文相关建模,构造决策树,增加高司混合数等.
中应用了一些裁减策略(动态规划)。
4)、结果分析
对于识别结果,HTK应用动态规划的方法,将其与参考序列进 行最优对齐,计算它们之间的替代、删除、插入误差。
评测标准
1)、词正确识别率
Correct = N − D − S × 100 % N
2)、识别精度
Accuracy = N −D−S−I × 100 % N
4)、计算复合HMM的前向-后向概率。 5)、用前向-后向概率来计算每帧语音 的状态占有概率及其累计和。 6)、重复过程2直至训练结束。 训练流程如右图所示: 在训练过程中采用逐步细化的建模过 成,先建立单音素的HMM,然后考虑音 素上下文,扩展到三音素HMM,最后进 行状态捆绑,还可逐步增加混合高斯变 量数目,最终得到鲁棒性较高的连续语 音识别HMM
3)、三音素捆绑
状态捆绑示意图
状态捆绑决策树
3.2.4、嵌入式训练
要求:收集训练语音时,必须有训练语句的抄本。 算法流程: 1)、对所有音素或三音素的HMM进行初始化。 2)、输入新的训练语句。 3)、通过连接训练句子抄本中各符号所对应的HMM,构建 一个符合HMM,如下图所示:
初始化模型参数