基于贝叶斯网络的各种抽样方法比较
基于贝叶斯网络的数据挖掘算法研究

基于贝叶斯网络的数据挖掘算法研究随着信息时代的到来,数据量的飞速增长使得数据挖掘变得越来越重要。
数据挖掘不仅可以帮助人们从海量数据中发现规律和趋势,而且还可以帮助人们更好地做出决策和预测未来。
而在众多的数据挖掘算法中,基于贝叶斯网络的数据挖掘算法因其高效性和准确性而备受研究者的关注。
一、贝叶斯网络的介绍贝叶斯网络又称信念网络或Bayes Net,是一种基于条件概率分布的有向图模型。
贝叶斯网络的节点代表了一个随机变量,而边则代表了不同变量之间的依赖关系。
通过贝叶斯网络的拓扑结构,可以更好地理解变量之间的联系,从而允许我们进行概率推理、决策分析、风险评估等。
二、贝叶斯网络在数据挖掘中的应用在实际应用中,贝叶斯网络常被用于分类、回归、聚类等任务中。
其中,最典型的应用就是分类问题。
通过将分类标签与属性之间的条件概率建立贝叶斯网络,我们可以利用观测数据进行模型参数的学习,然后基于贝叶斯公式进行预测和分类。
一般来说,我们可以基于样本数据的频率来学习网络中各个节点的条件概率分布。
但若数据量较小或属性间存在非线性关系等因素导致概率分布无法准确估计,此时就需要引入先验知识来帮助我们更好地建模。
例如,对于某些问题,我们可能认为某些属性之间存在先验相关性,或者认为某些属性对分类结果的影响较小,此时我们可以通过设定相应的先验概率分布来提高模型的准确性和泛化能力。
三、贝叶斯网络的优势相比其他数据挖掘算法,基于贝叶斯网络的算法有以下几个优势:1. 对不完整和缺失数据具有较好的容错性。
贝叶斯网络中,通过条件概率的乘积求解联合概率分布时,可以容忍缺失数据和不完整数据的情况,而不会导致整个模型无法训练。
2. 能够对因果关系进行建模。
贝叶斯网络中,边的方向表示了变量之间的因果关系,从而可以更好地模拟实际情况下因果关系的影响。
3. 对样本数据的量要求较低。
在样本数据不足的情况下,基于贝叶斯网络的算法通常可以取得较好的效果。
这也主要得益于它的自适应特性和根据先验知识来建模的特点。
贝叶斯网络的近似推断方法

贝叶斯网络的近似推断方法贝叶斯网络是一种用概率图模型来表示随机变量之间依赖关系的工具。
在实际应用中,我们常常需要对贝叶斯网络进行推断,即给定部分变量的取值,推断其他变量的分布。
然而,对于复杂的贝叶斯网络,精确推断往往是不可行的,因此需要采用近似推断方法。
马尔科夫链蒙特卡洛方法(MCMC)是一种常用的近似推断方法。
它通过构建马尔科夫链,利用马尔科夫链的平稳分布来逼近目标分布。
MCMC方法的优点在于能够处理任意形状的分布,但缺点是收敛速度慢,对参数敏感,并且需要大量的样本。
变分推断是另一种常用的近似推断方法。
它通过寻找一个与目标分布“最接近”的分布来逼近目标分布。
变分推断的优点在于收敛速度快,对参数不敏感,但缺点是只能处理一部分的分布形状。
在近年来,由于深度学习的发展,基于神经网络的近似推断方法也越来越受到关注。
变分自动编码器(VAE)就是一种基于神经网络的近似推断方法。
它通过将变分推断和神经网络结合起来,可以处理更加复杂的分布形状。
除了上述方法外,还有一些其他的近似推断方法,比如重要性采样、拉普拉斯近似等。
这些方法各有优缺点,适用于不同的问题和场景。
在实际应用中,选择合适的近似推断方法是非常重要的。
一方面,要考虑到目标分布的形状,是否能够用某种近似推断方法来逼近;另一方面,也要考虑到计算资源和时间的限制,选择合适的方法来平衡计算效率和推断准确度。
总的来说,贝叶斯网络的近似推断方法是一个非常有挑战性的课题,需要综合考虑概率统计、优化方法和计算机科学等多个领域的知识。
随着人工智能和机器学习的不断发展,相信在未来会有更多更好的近似推断方法出现,为贝叶斯网络的应用提供更加强大的支持。
贝叶斯网络和主观贝叶斯方法课件

CHAPTER 06
总结与展望
总结
01
贝叶斯网络是一种基于概率的图形化模型,用于表示随机变量之间的 依赖关系。
02
主观贝叶斯方法是一种基于主观概率的推理方法,它允许人们在缺乏 完整信息的情况下进行推理。
03
贝叶斯网络和主观贝叶斯方法在许多领域都有广泛的应用,如机器学 习、数据挖掘、自然语言处理等。
01
03
随着机器学习和人工智能技术的不断发展,贝叶斯网 络和主观贝叶斯方法在与其他技术的结合方面也将有
更多的创新和应用。
04
未来,贝叶斯网络和主观贝叶斯方法的研究将更加注 重模型的解释性和可解释性,以更好地理解模型的工 作原理和应用效果。
THANKS
[ 感谢观看 ]
主观贝叶斯方法优缺点
优点
主观贝叶斯方法能够结合专家知识和不确定性推理,提供更准确的概率估计。 它还具有灵活性和可解释性,能够清晰地表达和解释不确定性。
缺点
主观贝叶斯方法的准确性取决于专家的判断能力和经验,因此可能存在主观偏 差。此外,构建和验证主观贝叶斯模型需要大量时间和资源,也可能限制其应 用范围。
贝叶斯网络和主观贝叶 斯方法课件
• 贝叶斯网络与主观贝叶斯方法的比较 • 贝叶斯网络和主观贝叶斯方法案例分
CHAPTER 01
贝叶斯网络概述
贝叶斯网络定义
贝叶斯网络是一种概 率图模型,用于表示 随机变量之间的概率 依赖关系。
贝叶斯网络提供了一 种可视化和推理随机 变量之间复杂关系的 方法。
它由一个有向无环图 (DAG)和每个节点 上的概率分布表组成。
法能够更好地处理主观先验知识。
局限性
03
贝叶斯网络在处理大规模数据时可能面临计算瓶颈,而主观贝
贝叶斯网络的参数敏感性分析(五)

贝叶斯网络的参数敏感性分析贝叶斯网络是一种用于建模不确定性和概率推理的强大工具。
它由节点和边组成,节点表示变量,边表示变量之间的关系。
在贝叶斯网络中,参数的选择对于模型的性能和结果具有重要的影响。
因此,对贝叶斯网络的参数敏感性进行分析是非常重要的。
一、贝叶斯网络简介贝叶斯网络是一种图形模型,用于表示变量之间的概率依赖关系。
它可以用来描述变量之间的因果关系,并用于进行概率推理。
贝叶斯网络有两种类型的节点:随机变量节点和参数节点。
随机变量节点表示观察到的变量,参数节点表示概率分布的参数。
边表示变量之间的依赖关系,表示一个变量的值对另一个变量的值有何影响。
贝叶斯网络可以用于解决很多实际问题,比如医学诊断、风险评估、机器学习等。
二、贝叶斯网络的参数敏感性贝叶斯网络的参数有很多,比如概率表、条件概率表等。
这些参数对于模型的性能和结果具有重要的影响。
因此,对贝叶斯网络的参数敏感性进行分析是非常重要的。
参数敏感性分析是指在给定参数的不确定性情况下,对模型的输出结果进行分析。
通过参数敏感性分析,可以确定哪些参数对于模型的结果有重要的影响,进而进行参数调整和优化。
三、参数敏感性分析的方法对于贝叶斯网络的参数敏感性分析,可以采用不同的方法来进行。
一种方法是敏感性分析。
敏感性分析是一种通过改变参数值来评估模型输出结果对参数变化的敏感程度的方法。
另一种方法是Monte Carlo模拟。
Monte Carlo模拟是一种通过随机抽样来评估参数敏感性的方法。
还有一种方法是灵敏度分析。
灵敏度分析是一种通过改变模型输入,来评估模型输出对输入变化的敏感程度的方法。
这些方法可以结合使用,来对贝叶斯网络的参数敏感性进行全面的分析。
四、参数敏感性分析的意义对贝叶斯网络的参数敏感性进行分析,有很多重要的意义。
首先,它可以帮助确定哪些参数对于模型的结果有重要的影响,进而进行参数调整和优化。
其次,它可以帮助评估模型输出对参数变化的敏感程度,从而提高模型的可靠性和稳定性。
贝叶斯网络与朴素贝叶斯方法

贝叶斯网络与朴素贝叶斯方法贝叶斯网络(Bayesian Network)和朴素贝叶斯方法(Naive Bayes)是两种基于贝叶斯定理的统计模型,用于处理分类和预测问题。
虽然它们都围绕贝叶斯推理展开,但在方法和应用上存在一些区别。
首先,让我们了解一下贝叶斯定理。
贝叶斯定理是一种条件概率的推理方法,它可以根据已知的先验概率和新的观测数据更新后验概率。
贝叶斯定理的公式如下:P(A,B)=(P(B,A)*P(A))/P(B)其中,P(A,B)表示在观测到B的条件下发生A的概率,P(B,A)表示在A发生的条件下观测到B的概率,P(A)和P(B)分别表示A和B的先验概率。
贝叶斯网络是一种用有向无环图(DAG)表示的概率图模型,它使用节点和边来表示变量之间的依赖关系,并利用贝叶斯定理进行推理。
每个节点表示一个变量,节点之间的有向边表示变量之间的依赖关系。
贝叶斯网络可以通过定义每个节点的条件概率表(CPT)来描述变量之间的关系。
这些CPT指定了在给定其父节点的条件下,每个节点的概率分布。
通过观测一些节点的值,我们可以使用贝叶斯网络进行概率推理,计算其他未观测节点的后验概率。
贝叶斯网络和朴素贝叶斯方法在实际应用中有各自的特点和用途。
贝叶斯网络可以建模更复杂的依赖关系,并且能够推理未观测节点的后验概率,因此在不确定性推理和决策支持方面具有优势。
然而,贝叶斯网络的构建和推理可能比较复杂,并且在处理大规模数据集时会面临挑战。
朴素贝叶斯方法在文本分类和垃圾邮件过滤等领域得到广泛应用。
它的简单性和高效性使得它成为高维数据集分类问题的首选方法之一、虽然朴素贝叶斯方法忽略了特征之间的相关性,但在实际应用中,它的表现通常仍然很好。
总结一下,贝叶斯网络和朴素贝叶斯方法是基于贝叶斯定理的统计模型,用于处理分类和预测问题。
贝叶斯网络是一种用于建模复杂依赖关系的概率图模型,而朴素贝叶斯方法则是一种简化的贝叶斯网络模型,假设所有特征之间都是条件独立的。
贝叶斯网络结构学习的顺序采样策略优化

贝叶斯网络结构学习的顺序采样策略优化贝叶斯网络是一种概率图模型,被广泛应用于机器学习和人工智能领域。
在贝叶斯网络中,学习网络结构是一个重要的任务,其中顺序采样策略是一种常用的方法。
然而,顺序采样策略存在一些问题,本文将讨论如何优化这种策略。
一、顺序采样策略的介绍顺序采样策略是一种自上而下的学习方法,从网络中的根节点开始逐步生成后续节点。
具体而言,该策略按照特定的顺序,依次采样每个节点的父节点。
通过这种方式,可以逐步生成节点之间的依赖关系,并最终学习到整个网络的结构。
二、顺序采样策略存在的问题尽管顺序采样策略在一定程度上能够学习到网络的结构,但它有一些潜在问题需要解决。
首先,这种策略在采样每个节点的父节点时,往往只能考虑到已经采样的前面节点的父节点,而无法同时考虑到后面节点的父节点。
这样可能导致对网络的结构有一定的偏见,影响结构学习的准确性。
其次,顺序采样策略中可能存在一些节点采样顺序的依赖性,使得网络结构学习的效率变低。
因此,如何优化顺序采样策略,成为研究的重要课题。
三、基于贝叶斯推理的顺序采样策略优化为了解决顺序采样策略存在的问题,一种方法是引入贝叶斯推理的思想进行优化。
贝叶斯推理是一种基于贝叶斯定理的推断方法,可以用于估计未知参数的后验分布。
在贝叶斯网络结构学习中,可以通过贝叶斯推理的方法,根据已有数据来估计网络结构的后验概率,从而指导顺序采样策略的进行。
具体而言,我们可以利用贝叶斯推理来估计每个节点在采样时的先验概率。
通过引入先验概率,可以在采样每个节点时,综合考虑已采样节点和未采样节点的信息,提高结构学习的准确性。
另外,我们还可以结合贝叶斯推理的方法,对节点采样的顺序进行优化。
通过分析节点之间的依赖关系以及采样顺序的影响,可以找到一种能够更高效学习网络结构的采样顺序。
四、实验结果和应用前景为了验证优化后的顺序采样策略的有效性,我们进行了一系列实验。
实验结果表明,与传统的顺序采样策略相比,优化后的策略能够更准确地学习网络结构,并且在时间效率上也有所提升。
比较简单的贝叶斯网络总结
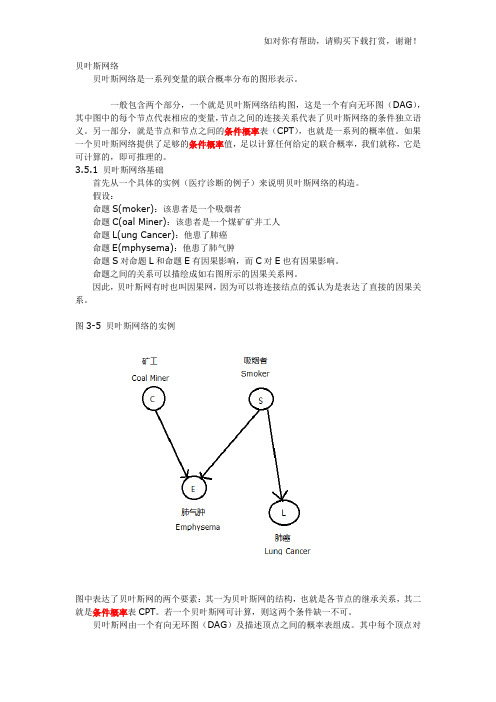
贝叶斯网络贝叶斯网络是一系列变量的联合概率分布的图形表示。
一般包含两个部分,一个就是贝叶斯网络结构图,这是一个有向无环图(DAG),其中图中的每个节点代表相应的变量,节点之间的连接关系代表了贝叶斯网络的条件独立语义。
另一部分,就是节点和节点之间的条件概率表(CPT),也就是一系列的概率值。
如果一个贝叶斯网络提供了足够的条件概率值,足以计算任何给定的联合概率,我们就称,它是可计算的,即可推理的。
3.5.1 贝叶斯网络基础首先从一个具体的实例(医疗诊断的例子)来说明贝叶斯网络的构造。
假设:命题S(moker):该患者是一个吸烟者命题C(oal Miner):该患者是一个煤矿矿井工人命题L(ung Cancer):他患了肺癌命题E(mphysema):他患了肺气肿命题S对命题L和命题E有因果影响,而C对E也有因果影响。
命题之间的关系可以描绘成如右图所示的因果关系网。
因此,贝叶斯网有时也叫因果网,因为可以将连接结点的弧认为是表达了直接的因果关系。
图3-5 贝叶斯网络的实例图中表达了贝叶斯网的两个要素:其一为贝叶斯网的结构,也就是各节点的继承关系,其二就是条件概率表CPT。
若一个贝叶斯网可计算,则这两个条件缺一不可。
贝叶斯网由一个有向无环图(DAG)及描述顶点之间的概率表组成。
其中每个顶点对应一个随机变量。
这个图表达了分布的一系列有条件独立属性:在给定了父亲节点的状态后,每个变量与它在图中的非继承节点在概率上是独立的。
该图抓住了概率分布的定性结构,并被开发来做高效推理和决策。
贝叶斯网络能表示任意概率分布的同时,它们为这些能用简单结构表示的分布提供了可计算优势。
假设对于顶点xi,其双亲节点集为Pai,每个变量xi的条件概率P(xi|Pai)。
则顶点集合X={x1,x2,…,xn}的联合概率分布可如下计算:。
双亲结点。
该结点得上一代结点。
该等式暗示了早先给定的图结构有条件独立语义。
它说明贝叶斯网络所表示的联合分布作为一些单独的局部交互作用模型的结果具有因式分解的表示形式。
距离判别法、贝叶斯判别法和费歇尔判别法的比较分析

距离判别法、贝叶斯判别法和费歇尔判别法的比较分析距离判别法、贝叶斯判别法和费歇尔判别法是三种常见的判别方法,用于对数据进行分类和判别。
本文将对这三种方法进行比较分析,探讨它们的原理、特点和适用范围,以及各自的优势和局限性。
1. 距离判别法距离判别法是一种基于样本间距离的判别方法。
它的核心思想是通过计算待分类样本与各个已知类别样本之间的距离,将待分类样本归入距离最近的类别。
距离判别法常用的距离度量有欧氏距离、曼哈顿距离和马氏距离等。
优势:- 简单直观,易于理解和实现。
- 不依赖于概率模型,适用于各种类型的数据。
- 对异常值不敏感,具有较好的鲁棒性。
局限性:- 忽略了各个特征之间的相关性,仅考虑样本间的距离,可能导致分类效果不佳。
- 对数据的分布假设较强,对非线性分类问题表现较差。
- 对特征空间中的边界定义不明确。
2. 贝叶斯判别法贝叶斯判别法是一种基于贝叶斯理论的判别方法。
它通过建立样本的概率模型,计算待分类样本的后验概率,将其归入后验概率最大的类别。
贝叶斯判别法常用的模型包括朴素贝叶斯和高斯混合模型等。
优势:- 考虑了样本的先验概率和类条件概率,能够更准确地对样本进行分类。
- 可以灵活应用不同的概率模型,适用范围广。
- 在样本量不充足时,具有较好的鲁棒性和泛化能力。
局限性:- 对特征分布的假设较强,对非线性和非正态分布的数据表现较差。
- 需要估计大量的模型参数,对数据量要求较高。
- 对特征空间中的边界定义不明确。
3. 费歇尔判别法费歇尔判别法是一种基于特征选择的判别方法。
它通过选择能够最好地区分不同类别的特征,建立判别函数进行分类。
费歇尔判别法常用的特征选择准则有卡方检验、信息增益和互信息等。
优势:- 基于特征选择,能够提取最具有判别性的特征,减少了特征维度,提高了分类性能。
- 不对数据分布做假设,适用于各种类型的数据。
- 可以灵活选择不同的特征选择准则,满足不同的需求。
局限性:- 特征选择的结果可能受到特征相关性和重要性的影响,选择不准确会导致分类效果下降。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
1
基于贝叶斯网络的各种抽样方法的比较
摘要: 本文主要介绍了贝叶斯网的基本概念以及重要性抽样方法的基本理论和概率推理, 重点介绍了两种重要的抽样方法, 即逻辑抽样方法和似然加权法, 并且比较了它们的优缺点 关键词: 贝叶斯网 抽样法 无偏估计
1.引言 英国学者T.贝叶斯1763年在《论有关机遇问题的求解》中提出一种归纳推理的理论, 后被一些统计学者发展为一种系统的统计推断方法, 称为贝叶斯方法.采用这种方法作统计推断所得的全部结果, 构成贝叶斯统计的内容.认为贝叶斯方法是唯一合理的统计推断方法的统计学者, 组成数理统计学中的贝叶斯学派, 其形成可追溯到 20世纪 30 年代.到50~60年代, 已发展为一个有影响的学派.Zhang和Poole首先提出了变量消元法, 其原理自关于不定序动态规划的研究(Bertele and Brioschi,1972).相近的工作包括D`Ambrosio(1991)、Shachter(1994)、Shenoy(1992)等人的研究.近期关于变量消元法的研究可参见有关文献【1】由于变量消元法不考虑步骤共享, 故引进了团树传播法, 如Hugin方法.在实际应用中, 网络节点往往是众多的, 精确推理算法是不适用的, 因而近似推理有了进一步的发展. 重要性抽样法(Rubinstein, 1981)是蒙特尔洛积分中降低方差的一种手段, Henrion(1988)提出了逻辑抽样, 它是最简单也是最先被用于贝叶斯网近似推理的重要性抽样算法. Fung和Chang(1989)、Shachter和Peot(1989)同时提出了似然加权算法. Shachter和Peot(1989)还提出了自重要性抽样和启发式重要性抽样算法. Fung和Favero(1994)提出了逆序抽样(backward sam-pling), 它也是重要性抽样的一个特例. Cheng和Druzdzel(2000)提出了自适应重要性抽样算法, 同时也给出了重要性抽样算法的通用框架, 这就是各种抽样方法的发展状况. 本文就近似推理阐述了两种重要的抽样方法即逻辑抽样方法和似然加权法, 并比较了它们的优缺点.
2. 基本概念 2.1 贝叶斯网络的基本概念 贝叶斯网络是一种概率网络, 用来表示变量之间的依赖关系, 是带有概率分布标注的有向无环图, 能够图形化地表示一组变量间的联合概率分布函数. 贝叶斯网络模型结构由随机变量(可以是离散或连续)集组成的网络节点, 具有因果关系的网络节点对的有向边集合和用条件概率分布表示节点之间的影响等组成.其中节点表示了随机变量, 是对过程、事件、状态等实体的某些特征的描述; 边则表示变量间的概率依赖关系.起因的假设和结果的数据均用节点表示, 各变量之间的因果关系由节点之间的有向边表示, 一个变量影响到另一个变量的程度用数字编码形式描述.因此贝叶斯网络可以将现实世界的各种状态或变量画成各种比例, 进行建模.
2.2重要性抽样法基本理论 2
设()fX是一组变量X在其定义域nXR上的可积函数.考虑积分 ()()XIfXdX (2.2.1)
为了近似计算这一积分, 重要性抽样方法将上式改写为如下形式: ()()()()XfXIPXdXPX (2.2.2)
这里, X被看成是一组随机变量, ()PX是X的一个联合分布, 称为重要性分布, 它满足以下条件: 对X的任意取值x, 如果()0fXx, 那么()0PXx. 接下来, 重要性抽样方法()PX从独立地抽取m个样本12,,...,,mDDD并基于这些样本来对积分I进行估计:
1()1.()mimiifDImPD (2.2.3)
可以证明, mI是I的一个无偏估计, 且根据强大数定律, 当样本量m趋于无穷时, mI几乎收敛于I. 重要性抽样法的性能主要从两个方面来衡量: 一个是算法复杂度, 另一个是近似解的精度.因此, 人们用计算mI所需的时间t和mI的方差var()mI之积var()mtI来度量重要性抽样法的效率:var()mtI越小, 算法的效率越高, 收敛速度也就越快, 从而获得高精度近似所需的样本量不大.这里, 方差可用下式计算:
221()var()()()XmfX
IdXImPX
(2.2.4)
重要性分布的选择是提高算法效率的关键.由于重要性分布的选择对时间复杂度的影响不大, 因此为了提高算法的效率, 应该选用使得方差var()mI尽可能小的重要性分布.根据式(2.2.4),若被积函数()0fx, 则最优重要性分布为*()()/PXfXI.此时var()0mI, 样本被集中在()fX值较大的"重要"区域.由于I本身是未知的, 在实
际中很少能够从*()PX抽样, 只能寻找与*()PX尽量接近的分布.重要性分布与最优分布*()PX越接近, 方差var()mI就越小. 2.3重要性抽样法的概率推理 考虑一个贝叶斯网, 用X记其中所有变量的集合,()PX记所表示的联合概率分布.设观测到证据Ee.下面将讨论如何近似计算一组查询变量Q取某值q的后验概率(|)PQqEe. 设W是一些变量的集合, Y是的W一个子集合, \ZWY, 并设y为Y的一个取值.定义函数
1,()(,)0,YyYyYyWYZ若若Yy (2.3.1)
按条件概率的定义, 有 (,)(|)()PQqEePQqEePEe
.
(2.3.2) 3
根据式(2.3.1)(,)PQqEe和()PEe可以分别表示成如下形式: (,)()()(),QqEeXPQqEeXXPX (2.3.3)
()()()EeXPEeXPX. (2.3.4)
于是可以利用重要性抽样法来对它们进行近似. 对于近似的一般性质, 有一点需要注意.根据以上讨论, 利用重要性抽样法获得的对(,)PQqEe和()PEe的估计是无偏的.
3. 重要性抽样方法 3.1逻辑抽样法 要用重要性抽样法解决式(2.3.3)和式(2.3.4)的问题, 首先需要选择一个重要性分布.一个很自然的想法就是选用联合分布()PX本身来作为重要性分布, 其中12,,...,nXXXX, 这样就得到了逻辑抽样.
逻辑抽样法首先从()PX分布中抽取样本.注意到()PX分解为 ()(|()),XXXXPXP
其中()X表示那些在拓扑序排列中那些在节点X之前的节点12,,...,iXXX的一个集合.因此可以按照贝叶斯网的拓扑序对其中的变量逐个进行抽样: 对待抽样变量iX,若它是根节点, 则按分布()iPX进行抽样; 若是非根节点, 则按分布是(|())iiPXXr进行抽样, 这里()iXr是父节点的抽样结果, 在对iX抽样时是已知的, 为顺序抽样, 此过程需要从一些单变量概率分布随即抽样.
(图1) 对图1所示的贝叶斯网, 用逻辑抽样法计算(|E)PQqe, 逻辑抽样法生成一个样本的过程如下: 假设对()PX顺序抽样过程获得了m个独立样本12,DD…mD, 其中满足Ee的有em个, 而在这em个样本中, 进一步满足Qq的有,qem个.根据式(2.2.3)和式(2.3.3) , 有
Cloudy(C) WetGrass(W) Sprinkler(S) Rain(R) 4
1()()()1(,)()mQqiEeiiiiDDPDPQqEemPD 11()()mQqiEeiiDDm ,.qemm
类似地, 根据式(2.2.3)和(2.3.4)可得
11()()mEeiiPEeDm
=emm. 将上面两式代入式(2.3.2), 可得 ,(|)qee
m
PQqEem, (4.1.1)
这就是通过逻辑抽样法获得的对后验概率的近似, 它是在所有满足Ee的样本中, 进一步满足Qq的样本比例. 逻辑抽样法所产生与证据Ee不一致的那些样本相当于被舍弃.因此, 逻辑抽样有时也称为舍选抽样. 3.2似然加权法 似然加权法是重要性抽样的一个特例, 提出它的一个主要目的是避免逻辑抽样因舍弃样本而造成浪费. 在抽样过程中, 它按拓扑序对每个变量进iX行抽样: 当iX不是证据变量时, 抽样方法与逻辑方法一致; 而当是iX证据变量时, 则以的iX观测值作为抽样结果.这样保证了每一个样本都与证据Ee一致, 从而可以利用, 不必舍弃. 对图1所示的贝叶斯网, 用似然加权法计算(|)PRtSt, 似然加权法生成一个样本的过程如下: (1)对根节点C, 从()PC抽样, 假设得到Ct; (2)对节点S, 因为SE是证据变量, 所以抽样结果被视为它的观测值t; (3)对节点R, 抽样分布为(|)PRCt, 假设得到Rt; (4)最后对叶节点W抽样, 抽样分布为(|,)PWRtSt,假设得到Wt.最后产生的样本为D={,,,CtRtStWt}. 设12,DD,…mD是通过上述过程抽得的m个样本.下面讨论怎样基于它们对(,)PQqEe和()PEe进行近似.
设Y是X的一个子集.对任一Y的函数()hY, 用()|iDhY表示当变量Y取iD中的值时, 这个函数的函数值.对任一XX, (|())XXP是X中一些变量的函数.于是, (|())|iDXXP是当变量取iD中的值时, 这个函数的函数值.
用Z记所有非证据变量的集合, 即\ZXE,设'()PX是似然加权法所使用的重要性分布.不难看出, '()()EePEE, 而