基于特征的空间数据相似性查询研究
地理空间数据相似度计算方法研究与实现

地理空间数据相似度计算方法研究与实现地理空间数据相似度计算方法研究与实现摘要:地理空间数据相似度计算是地理信息系统中非常重要的一项任务,它可以用于地理信息的分类、聚类、模式识别等多个研究领域。
本文针对地理空间数据相似度计算方法展开研究,从传统方法到基于距离度量、拓扑结构和聚类方法等多个角度进行探索与分析。
在此基础上,通过案例实例验证,实现了一种基于相似度计算的地理信息聚类算法,并进行了性能评估和对比分析。
1. 引言地理空间数据是地理信息系统(GIS)的核心内容之一,其包括点、线、面、体等多种形式,并广泛应用于各个地理学领域。
在处理地理空间数据时,常常需要利用相似度计算方法对地理数据进行比较、聚类、分类等操作,以挖掘出其中的规律和特征。
2. 传统方法传统的地理空间数据相似度计算方法通常基于距离度量,如欧式距离、曼哈顿距离等。
这些方法计算简单,易于实现,但忽略了地理数据内部的拓扑结构和空间关系。
对于地理数据而言,其空间位置信息是不可或缺的,因此需要在相似度计算中考虑地理数据的拓扑关系和空间关联性。
3. 基于距离度量的方法基于距离度量的地理空间数据相似度计算方法从距离和角度两个维度刻画了地理数据的相似性。
通过计算地理数据在空间上的相对位置和方向,可以得到更加准确和全面的相似度计算结果。
此外,还可以借助不同的距离度量方法,如最近邻距离、最短路径距离等,来描述地理数据的相似程度。
4. 基于拓扑结构的方法基于拓扑结构的地理空间数据相似度计算方法主要关注地理数据的拓扑关系,即地理数据之间的连接、相交和相邻等关系。
通过对地理数据的拓扑结构进行抽象和建模,可以计算地理数据的相似度,并据此进行进一步的分析和处理。
常用的拓扑结构方法包括拓扑关系图、拓扑关系矩阵等。
5. 基于聚类方法的方法基于聚类方法的地理空间数据相似度计算方法将地理数据划分为若干簇,同一簇内的地理数据具有较高的相似度,而不同簇之间的地理数据相似度较低。
一种基于特征融合的图像检索方法

Z
测试 集 . 是从 C rl图像 库 中抽取 的 10 它 oe 0 0幅 图
像 ,分 为建 筑物 ( ulig 、公共汽 车 ( u ) bi n ) d b s 、恐 龙 ( ioa r 、火象 ( l h n ) dn su ) ee a t、花 卉 ( o e ) p l f w r、 马 ( os ) 人( u n 、 h re 、 h ma )海滨 (e s e 、 山(o u ) sai )雪 d jk 1、
个 分量 对 于 图像 检 索尤 为重要 【. 5 J 小波 变换 ( vl asom)也是一 种常用 的 wae trnfr et 纹理 分 析 方法 【.小 波变 换 指 的是将 信 号分 解 为一 5 1
系列 的基本 函数 () x.这些 基本 函数可 以通 过对
对 于 Tmua纹理采用 前 三个特 征 ,即粗糙 度 a r (casns orees)、 对 比 度 (cnr t) 方 向 度 ot s a 、
向上的特,I . 怔 给定 一幅 图像 Ix ) (, ,提 取不 同 的特 征表 示如
下:
m 是 矩 阵 中每 行元素 之和 , 是矩 阵 中每 列 元 素之 和.相 关量 用来 描述 矩 阵 中行 或列元 素之 间 灰度 的相 似程 度 . Tmua1 理特 征是基 于 人类对 纹理 的视 觉感 a r[纹 4
日() , .: i } k:0 l , l ,…. L—
, z
() 1
式 中 ,k表示 图像 的特 征 取值 ,三 表示特 征 可取值 的个 数 , 表 示 图像 中具 体特 征值 为 k的像 素 个数 , F表示 图像像 素 总个数 . /
1 颜色特征
根据 人 的视 觉特 点 ,彩 色 图像 中的颜 色具 有独 有 的特 点 ,是视觉 最容 易注 意到 的特征 ,且稳 定性
基于多特征融合的图像检索技术研究与实现
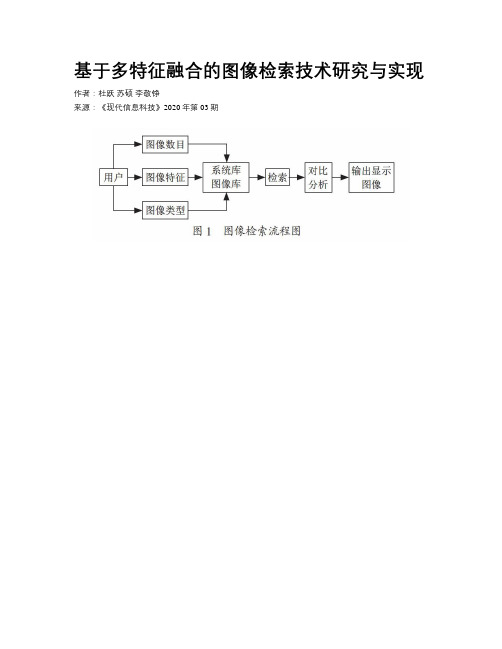
基于多特征融合的图像检索技术研究与实现作者:杜跃苏硕李敬铮来源:《现代信息科技》2020年第03期摘; 要:为了满足精准、智能、高效的图像检索方式,提出了一种基于多特征融合图像检索方法,多特征图像检索技术实现的图像检索使用了图像自身的多特征作为图像检索的依据,提高了图像搜索的精准性和高效性。
通过测试,实验结果证实了多特征融合图像检索技术利用了图像的颜色和纹理等作为检索的特征,多特征融合图像检索系统具有一定的学术意义和现实价值,能够大幅度提高图像检索的精确性,满足了用户的需求,具有良好的实用价值。
关键词:多特征融合;图像检索;纹理;图像特征中图分类号:TP391.41; ; ; ;文献标识码:A 文章编号:2096-4706(2020)03-0083-003Abstract:In order to meet the requirements of accurate,intelligent and efficient image retrieval,a method of image retrieval based on multi feature fusion is proposed. The image retrieval realized by multi feature image retrieval technology uses the multi feature of image itself as the basis of image retrieval,which improves the accuracy and efficiency of image retrieval. Through the test,the experimental results confirm that the multi feature fusion image retrieval technology uses the color and texture of the image as the retrieval features. The multi feature fusion image retrieval system has certain academic significance and practical value,can greatly improve the accuracy of image retrieval,meet the needs of users,and has good practical value.0; 引; 言当前,随着科学技术的发展,互联网技术不断发展,但是图像检索的效率仍然过于低下,互联网的高速发展给人们提供了大量的信息资源,但是不断增加的数据资源也给人们带来了一定的困难,即如何在海量数据资源中实现对信息的检索,提高用户的查询效率,因此目前急需一种更加精准、高效、智能的图像检索技术。
基于SIFT特征的图像检索技术研究

然而,现有的基于SIFT特征的图像检索方法还存在一些挑战和问题,如特征 选择的不准确性和跨域性问题等。未来的研究可以针对这些问题展开深入探讨, 进一步提高图像检索的准确性和效率。此外,随着深度学习技术的快速发展,研 究者可以尝试将深度学习与基于SIFT特征的图像检索技术相结合,探索更有效的 图像特征表达和匹配方法。
1、图像特征提取
图像特征提取是图像检索的核心,它通过一定的算法从图像中提取出能够代 表图像内容的关键信息,如颜色、纹理、形状等。这些特征可以有效地描述图像 的内容和特征,为后续的图像比较和分析提供基础。常用的特征提取方法包括 SIFT、SURF、ORB等。
2、相似度比较
在提取出图像的特征之后,我们需要对这些特征进行比较,以确定两幅图像 的相似度。常用的相似度比较方法包括欧氏距离、余弦相似度、交叉相关等。这 些方法通过计算特征向量之间的距离或者相关系数,来评估两幅图像的相似程度。
3、检索算法
基于特征的图像检索技术中常用的检索算法包括基于内容的检索、基于神经 网络的检索和基于深度学习的检索等。其中,基于内容的检索通过比较查询图像 和库中图像的特征,找出最相似的图像;基于神经网络的检索通过训练神经网络 来学习图像特征和标签之间的关系,从而对新的图像进行分类和检索;基于深度 学习的检索通过构建深度神经网络模型,对图像进行深度特征提取和分类,从而 实现高精度的图像检索。
SIFT特征最早由David Lowe在1999年提出,具有尺度不变性、旋转不变性、 亮度不变性等优点。自提出以来,SIFT特征在计算机视觉领域得到了广泛应用, 包括目标识别、图像配准、图像检索等。在图像检索领域,SIFT特征可以有效地 表达图像的内容和特征,提高检索准确率。然而,现有的基于SIFT特征的图像检 索方法还存在一些问题,如特征选择不准确、匹配效率低等。
虚拟现场数字证据搜索技术综述

虚拟现场数字证据搜索技术综述廖根为【摘要】在虚拟犯罪现场固定数字证据前,需要在大量数据中搜索和定位与案件事实相关联的数字证据.为了及时准确定位数字证据,必须依赖计算机相关技术,虚拟现场常采用的搜索技术包括基于字符串的搜索技术、基于特征码的搜索技术、基于数字指纹的搜索技术、基于痕迹信息的搜索技术等.【期刊名称】《犯罪研究》【年(卷),期】2010(000)006【总页数】5页(P26-30)【关键词】数字证据;搜索技术;特征码;数字指纹;痕迹信息【作者】廖根为【作者单位】华东政法大学【正文语种】中文当互联网中发生与网络相关的犯罪时,需要从虚拟的犯罪现场中固定与案件事实相关的证据。
由于数字证据是以数字化形式存在的,具有无形性、技术性、隐蔽性、复杂性等特点,对其固定与传统证据有较明显的区别,无法通过肉眼直观判断数字证据的有无和具体位置。
由于在虚拟空间中,存储着大量的杂乱无章的数据。
在这些数据中,只有很少的一部分数据是与案件相关的。
在犯罪调查取证中,只需要收集这些与案件相关部分的证据。
因此,需要事先通过搜索或检查等方法过滤掉无用的数据,确定与案件相关的数字证据。
搜索可以通过人工手段也可以通过计算机自动处理进行有限或者全部处理。
通过人工方法在虚拟现场中寻找案件相关证据是难以想象的。
一方面,案件调查需要在有限的时间内完成;另一方面,很多数据必须借助特定的工具才能够被人所理解。
因此,通过技术方法进行自动收集案件事实相关证据是网络犯罪或相关犯罪调查取证必不可少的。
在虚拟的犯罪现场搜索数字证据,目的是为了从大量杂乱无章的数据中快速且准确地找出确实与案件事实相关的数字证据。
良好的搜索技术能够快速定位与案件事实相关的证据,又不过多地将一些无关证据搜索出来。
在虚拟现场中搜索数字证据的技术有很多,但都需要根据一定的预测信息从现场中获取。
根据预测信息的方式不同,大体可将虚拟空间搜索数字证据的方式分为基于字符串的搜索技术、基于特征码的搜索技术、基于数字指纹的搜索技术、基于痕迹信息的搜索技术。
基于特征的GIS空间数据质量控制的探讨

4 空 间数据 的质 量控制
关键词
GI 空 间数 据 S
基 本 特征
空间数据库
质 量 控 制
文 章 编 号 :6 2—4 9 (0 1 O 一0 2 —0 17 072 1)l 03 3
中 图分 类 号 :2 8 I0 =
文献标识码 : A
l 引 言
GI ( o rp i Ifr t n S se 与 其 他 S Ge g a hc nomai y tm) o
其它产 品一 样 , 无 法 得 到 用 户 的 信 任 。 因 此 , 将 空
间数据 质 量 的优 劣 将 决 定 系 统 分 析 质 量 乃 至 整 个
系统应 用 的成败 。
3 空 问数据 的质量 标准
空 间数据 质量 是指 空 间数 据 的可 靠性 和精 度 ,
通常 用空 间 数 据 的 误 差 来 度 量 。空 间 数 据 的质 量 控制 是针 对空 间数 据 的基 本 特 征 来 进行 的 , 以概 可
不 同 点 , 空 间数 据 的 内容 与基 本特 征 出发 , 析 了空 间 数 据 的 质 量 标 准 , 出 了按 其 三 个 基 本 特 征 的 范畴 实施 质 从 分 提
量控 制 , 对 空 间数 据 进 行 了质 量 评 价 , 而达 到 了 G S空 间数 据 质 量 控 制 的 目的 。 并 从 I
征 、 间特征 和专 题特 征 。 时 ( )空 间特 征 : 称 为定位 特 征 , 指 空 间物 体 1 也 是
间特征 精度 之外 的 精 度 , 要 包 括属 性 精 度 和 元 数 主
据精 度 等 。
的位 置 、 形状 和大 小 等几 何 特 征 以及 与 相 邻 物 体 的
基于特征的空间数据相似性查询研究

基于特征的空间数据相似性查询研究
夏宇;朱欣焰;周春辉
【期刊名称】《计算机工程与应用》
【年(卷),期】2007(043)025
【摘要】针对目前空间数据相似性查询的广泛应用需求和实际应用情况,提出基于特征的空间数据相似性查询(Feature Based Spatial Data Similarity
Query,FBSDQ)的概念,并给出了形式化定义,分析指出了FBSDQ的特点.提出了统一的FBSDQ处理框架及其实现的关键技术,以典型的度量空间高维索引结构VP树为例,讨论了基于距离的度量空间高维索引技术,为空间数据相似性查询的研究提供了技术支持.
【总页数】4页(P15-17,47)
【作者】夏宇;朱欣焰;周春辉
【作者单位】武汉大学,遥感信息工程学院,武汉,430079;武汉大学,测绘遥感信息工程国家重点实验室,武汉,430079;武汉大学,测绘遥感信息工程国家重点实验室,武汉,430079
【正文语种】中文
【中图分类】P208
【相关文献】
1.空间数据几何相似性度量理论方法与应用研究 [J], 安晓亚
2.基于特征的空间数据访问控制模型研究 [J], 於光灿;李瑞轩;卢正鼎;宋伟;唐卓
3.基于特征的空间数据模型研究 [J], 李文娟;李宏伟;梁汝鹏;刘静
4.水文时间序列相似性查询的分析与研究——以漯河站、何口站汛期降雨量相似性查询为例 [J], 李薇;孙洪林
5.基于特征的空间数据模型研究 [J], 王斌
因版权原因,仅展示原文概要,查看原文内容请购买。
基于签到数据的用户空间出行相似性度量方法研究

27
地理信息世界
理论研究
数据进行分析之前,首先对签到数 据进行了预处理,排除假签数据同 时将每个签到点映射到所属的网格 gxy∈G中。
黑色的点代表用户不同时间的签到 位置,虚线代表用户的签到顺序。 如图1所示,User1和User2都签到 了A ,B ,C ,D ,E 以及G 。我们以时 间顺序分别得到User1和User2的签 到序列User1:<A ,B ,C ,D ,E ,F ,G >, User2:<A ,B ,C ,D ,E ,F ,>(A 代表1×1km 的网格,同时可以被表示为g2,1)。 考 虑 到不 同 的 签 到 地 点 的 签 到 时 间 , 我 们 用 Δt i 来 表 示 两 次 签 到 之间的时间间隔,这样,User1和 User2的签到序列可以被表示为: User 1:
1 用户空间出行相似性 度量过程与方法
本文的目的是探索一种基于 签到数据的用户相似性度量方法, 从 而 对 用 户 进 行 相 似 性的比较。 Waldo Tobler提出的地理学第一 定律“everything is related to everything else, but near things are more related than distant things”以及E.Cho和S.A. Myers等 在2011年提出的地理与社会关系的 约束关系理论是我们进行用户相似 性分析的理论基础。如果两个用户 的签到位置都是北京大学,则认为 他们具有一定的相似性;如果他们 在北京大学的签到次数都非常高, 那么认为他们具有更高的相似性, 文章充分考虑了地理位置的临近性 以及回访次数对两个用户进行相似 性判断与度量。 由于基于位置的社交网络服务 并不验证用户签到的真实性,所以用 户可能会产生假签行为。假签常规意 义上是指某用户身在A地点,却签到 了B地点。考虑到用户可能在到达目 标地点之前就进行签到,本文把假签 定义为:用户实际签到位置与签到 地点位置之间的距离大于1 km。在对
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
基 于 特 征 的 空 间 数 据 相 似 性 查 询 的 关 键 技 术 :( 1) 特 征 提
取: 选择有效的特征描述和特征提取算法是保证查询结果正确
性前提。在遥感影像相似性检索中, 可以提取纹理、形状等特征
作为检索依据; 在矢量相似性检索中, 可以提取空间关系等特
征作为相似性检索依据。( 2) 高维索引: FBSDSQ 中提取的特征 一般都要用高维特征向量来表达, 为有效地进行特征之间的相 似性匹配, 必须建立高效的高维索引结构。( 3) 相关反馈: 由于 特征并不能完全表达空间数据库对象的语义信息, 与人对空间 数据库对象的理解存在差异, 因此, 通过人机交互方式的相关 反馈技术能够有效地解决该问题。
XIA Yu, ZHU Xin - yan, ZHOU Chun - hui.Resear ch on featur e based spatial data similar ity quer y.Computer Engineer ing and Applications, 2007, 43( 25) : 15- 17.
离计算代价( CPU 代价) 较高。例如, 计算两个 n 维特征向量的
距离, 不妨设采用欧氏距离作为度量, 不考虑乘方根计算, 需要
做( n- 1) 次加法运算, n 次乘法运算。如果相似性匹配的特征向
m
量个数为 m, 则需要做 n 次乘法运算, 对于高维特征向量, n 值
达几十甚至几百上千, m 值取决于所使用的索引结构, 一般
{f1, f2, …, fn}。其中, f1=F( S1) , f2=F( S2) , …, fn=F( Sn) 。且任意
两个对 象 S1、S2 的 相 似 性 Sim( S1 , S2) 可 以 转 化 为 两 个 对 象 特 征值之间的相似性 Sim( f1, f2) , 对象特征值之间 的 相 似 性 可 以
虽然以上这些研究工作都为空间数据相似性查询做出了贡献, 但空间数据相似性查询涉及空间数据库、人工智能等诸多领 域, 是一个比较复杂的问题, 因此, 从空间数据库角度对空间数 据相似性查询的基础性问题进行研究具有重要的理论价值和 现实意义。
2 基于特征的空间数据相似性查询
空间数据相似性查询从技术实现角度可以分为三个层次: 数 据 层 、特 征 层 和 语 义 层 。 从 数 据 层 上 直 接 进 行 相 似 性 查 询 计 算量大, 效率低; 从语义层上进行相似性查询在目前计算机视 觉和空间数据挖掘等相关学科的发展水平下还存在很大的困 难 。目 前 可 行 的 方 法 是 通 过 提 取 空 间 数 据 的 特 征 来 实 现 空 间 数 据 相 似 性 查 询 。下 面 给 出 基 于 特 征 的 空 间 数 据 相 似 性 查 询 的 形 式化定义。
CPU 代价较高。
基于特征的空间数据相似性查询一般先从查询对象提取
特征向量( 称为查询向量) , 然后将查询向量与预处理好的特征
库进行特征匹配, 检索出候选结果集, 经过相关反馈得到最终
查 询 结 果 集 返 回 给 用 户 。基 于 特 征 的 空 间 数 据 相 似 性 查 询 的 统
一处理框架如图 1 所示。
通 过 特 征 向 量 之 间 的 距 离 d( f1, f2) 来 度 量 。 因 此 , 查 询 对 象 q
的 K 个最相似的对象为: Q( q, k) ={S0 …Sk- 1 ∈S|#e∈S, d( F( Si) , F( q) ) ≤d( F( e) , F( q) ) , 0≤i≤k- 1}, 这 种 查 询 即 称 为 基 于 特 征
Abstr act: Aiming at the general demand of spatial data similarity query and the state of its application at present, the concept of “Feature Based Spatial Data Similarity Query”has been proposed in this paper, and then the formal definition has been giv- en, at the same time the features of FBSDSQ have been proposed and analyzed.The uniform framework and the key technologies of FBSDSQ have been given.In particular, with an example of high dimensional index structure in metric spaces, called VP tree, distance based high dimensional indexing in metric spaces has been discussed which provides technical support for spatial data similarity query. Key wor ds: spatial data; similarity query; metric space; high dimensional index
摘 要: 针对目前空间数据相似性查询的广泛应用需求和实际应用情况, 提出基于特征的空间数据相似性查询 ( Feature Based Spatial Data Similarity Query, FBSDQ) 的概念, 并给出了形式化定义, 分析指出了 FBSDQ 的特点。提出了统一的 FBSDQ 处理框架 及其实现的关键技术, 以典型的度量空间高维索引结构 VP 树为例, 讨论了基于距离的度量空间高维索引技术, 为空间数据相似性 查询的研究提供了技术支持。 关键词: 空间数据; 相似性查询; 度量空间; 高维索引 文章编号: 1002- 8331( 2007) 25- 0015- 03 文献标识码: A 中图分类号: P208
的空间数据相似性查询。
由上述定义可以看出, 相似性查询实质上是 K 近邻查询,
当 k=1 时 , 称 为 “ 最 近 邻 查 询 ”。 实 际 上 , 范 围 查 询( Range
Query) 也属于相似性查询的范畴, 可以认为范围查询是 K 近邻
查 询 的 另 一 种 表 述 方 式 , 不 过 是 通 过 精 确 的 查 询 范 围 阈 值( 这
Computer Engineering and Applications 计算机工程与应用
2007, 43( 25) 15
基于特征的空间数据相似性查询研究
夏 宇 1, 朱欣焰 2, 周春辉 2 XIA Yu1, ZHU Xin- yan2, ZHOU Chun- hui2
1.武汉大学 遥感信息工程学院, 武汉 430079 2.武汉大学 测绘遥感信息工程国家重点实验室, 武汉 430079 1.School of Remote Sensing and Information Engineering, Wuhan University, Wuhan 430079, China 2.State Key Lab of Information Engineering in Surveying, Mapping and Remote Sensing, Wuhan University, Wuhan 430079, China E- mail: geoxy@126.com
马氏( Mahalanobis) 距离、斜交空间距离等。其中, 明氏距离第 i
1
&% ’ p
q
q
个向量和第 j 个向量的距离定义为 di(j q) =
xik - xjk
。当
k=1
q=1 时 , 称 为 绝 对 值 距 离 ; 当 q=2 时 , 称 为 欧 氏 距 离 ; 当 q=∞
时, 称为切比雪夫距离。特征向量间的距离值越小, 向量之间的
服务等方面研究; 周春辉, 男, 博士生。
16 2007, 43( 25)
Computer Engineering and Applications 计算机工程与应用
任一数据库对象 Sk 可以表达为一个 m 维 的 特 征 向 量 , 即 F: Sk
m
→R , 则 数 据 库 对 象 集 S 对 应 的 特 征 向 量 集 可 以 表 达 为 F=
都 可 能 导 致 相 似 性 查 询 结 果 的 不 同 。例 如 对 于 纹 理 图 像 就 比 较
适合于选择纹理特征作为检索依据, 而选择同质纹理描述子、
纹理浏览描述子或者边缘直方图描述子等不同的方法, 检索结
果会有差异。( 2) FBSDSQ 中的特 征 一 般 用 高 维 特 征 向 量 来 表
定 义 1 基 于 特 征 的 空 间 数 据 相 似 性 查 询 ( Feature Based Spatial Data Similarity Query)
设 数 据 库 对 象 集 S={S1 , S2 , … , Sn }, 查 询 对 象 为 q, 不 妨 设
基金项目: 国家重点基础研究发展规划( 973)( the National Grand Funrogram of China under Grant No.2006CB701305) 。 作者简介: 夏宇( 1981- ) , 男, 博士生, 主要从事空间数据库、遥感影像处理等方面研究; 朱欣焰, 男, 教授, 主要从事空间数据库, 网络 GIS, 空间信息
里即为距离值) , 限制相似性对象的个数, 然而实际相似性查询
中, 常常用户并不用关心查询的距离阈值, 所以最常用的相似
性查询还是集中在 K 近邻查询上。
基于特征的相似性查询中, 特征向量之间的距离定义有:
明 考 夫 斯 基( Minkowski) 距 离 、兰 氏( Lance 和 Williams) 距 离 、