DID方法与合成控制法
基于合成控制法的中国城市生活垃圾强制分类政策效果
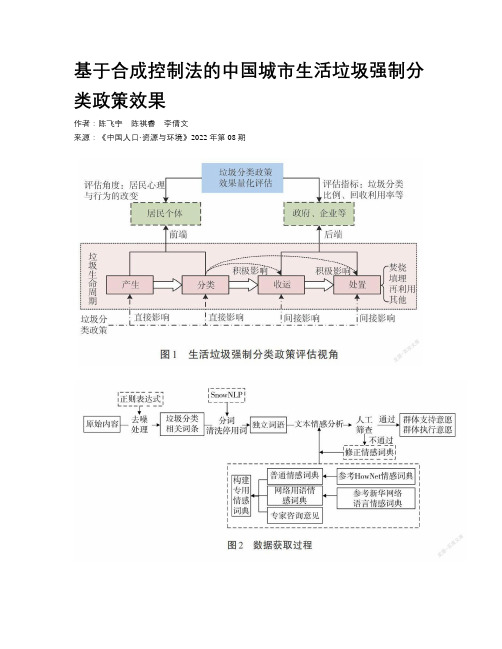
基于合成控制法的中国城市生活垃圾强制分类政策效果作者:陈飞宇陈祺睿李倩文来源:《中国人口·资源与环境》2022年第08期关键词城市生活垃圾;强制分类政策;支持意愿;执行意愿;合成控制法中图分类号 X799.3 文献标志码 A 文章编号 1002-2104(2022)08-0107-11 DOI:10.12062/cpre.20220402为促进生活垃圾分类制度的建成,2019年6月,住建部等9部委联合发布《关于在全国地级及以上城市全面开展生活垃圾分类工作的通知》,明确到2020年,46个重点城市基本建成生活垃圾分类处理系统,到2025年,全国地级及以上城市基本建成生活垃圾分类处理系统。
同年7月1日,上海市正式全面启动生活垃圾强制分类政策。
其中,“强制分类”成为政策执行的主要特征,在这一背景下,考察各城市居民对于生活垃圾强制分类政策的支持和执行情况,并衡量上海市生活垃圾强制分类政策的实施效果,这对相关政策的制定与完善具有重要意义。
1文献综述现有学者针对垃圾分类政策及其分类效果从不同视角进行了评价体系设计,主要体现在结果视角与前端视角两个方面。
在结果视角方面,研究主要通过垃圾分类带来的生态效益、经济效益等方面衡量。
如Yang等提出七维评价体系,将垃圾分类设施覆盖率、垃圾分类收运、环境效益、经济效益、参与范围、居民垃圾分类意识以及荣誉感纳入评价体系之中,同时借助源头分类的数学模型MSSA,对一年内北京市128个城市的生活垃圾集散地的分类效果进行评估。
Aphale等通过评估纽约郊区三个不同回收利用率的废物区的6吨垃圾的分类效果,提出分类效率与回收利用率之间存在一定关系,认为回收率最高的废物区具有最高的分类效率。
此外,Ordonez等对瑞典某处的垃圾分类设施的分类效果进行研究,提出误分发生频率这一指标,指的是一段时间内某类型垃圾桶中出现该类型以外的垃圾的发生次数。
Rousta等同样借助这一指标,探究了瑞典某城市居民区的生活垃圾源头分类效果。
stata 合成控制法 排序检验法

stata 合成控制法排序检验法【如何使用Stata进行合成控制法和排序检验法】一、引言在社会科学研究领域,合成控制法和排序检验法是两个常用的统计方法,它们可以帮助研究者更准确地评估某一政策或干预措施对特定变量的影响。
本文将以Stata为工具,详细介绍如何使用合成控制法和排序检验法进行分析,并分享一些个人观点和理解。
二、合成控制法1. 概述:合成控制法是一种用于估计某一政策对特定结果变量的影响的方法。
它通过将存在干预的观测组样本(Treatment group)与没有干预的对照组样本(Control group)进行比较,来得出干预效果的估计值。
合成控制法的核心思想是通过建立合成对照组,使得观测组和对照组在其他相关变量上的分布趋势趋于一致,从而减少了干预效果被其他混杂因素所掩盖的可能性。
2. Stata操作:a) 加载数据并确保变量的正确性。
使用Stata命令`use`来加载数据集,并使用`describe`命令确保变量的名称和类型是正确的。
b) 接下来,根据合成控制法的特点,选择一些与观测组和对照组相关的变量。
使用`tab`或`summarize`命令来了解这些变量的分布情况。
c) 使用`psmatch2`命令来进行合成控制法分析。
该命令可以通过指定观测组和对照组来计算处理效应的估计值。
d) 使用`psmatch2`命令的输出结果来检验结果的显著性。
可以使用t检验或回归分析等Stata命令来评估处理效应的统计显著性。
3. 个人观点和理解:合成控制法是社会科学研究中一项重要的工具,它通过控制其他混杂因素,有效地评估政策或干预措施的影响。
然而,在使用合成控制法时,我们需要注意选择适用的变量和假设的合理性,以提高研究结果的准确性和可靠性。
三、排序检验法1. 概述:排序检验法是一种用于评估某一政策或干预措施效果的非参数方法。
该方法通过将观测值根据变量值的大小进行排序,然后根据排序结果对处理效应进行检验。
合成控制法与双重差分法

合成控制法与双重差分法
《合成控制法与双重差分法》
一、合成控制法
合成控制法是一种特殊的控制方法,是对已有系统进行拆分、变换等操作,从而获得更佳控制结果的方法。
它有以下特性:
1.合成控制法可以精确地模拟系统,在控制中可以消除误差和干扰,获得更好的控制效果。
2.合成控制法可以将一个大系统拆分成若干小系统,使得一个大的系统变得容易管理和理解。
3.合成控制法可以在控制中消除运动中的稳态误差,改善控制精度。
二、双重差分法
双重差分法是一种改善控制系统性能的方法。
它是利用两个差分信号,对被控系统的运动特性进行分析和改善,以达到改善系统性能的目的。
它的特性有以下几点:
1.双重差分法可以对控制系统的大小、精度、速度、稳定性等多个特性进行改善,使控制系统更具有实用性和可靠性。
2.双重差分法可以降低系统中误差的产生,可以更精确地获得控制信号,从而提高控制效果。
3.双重差分法可以显著提高控制系统的稳定性,使之能够克服受外界环境干扰而产生的失稳的情况。
- 1 -。
合成控制法与双重差分法

合成控制法与双重差分法
合成控制法和双重差分法都是控制工程中常用的方法,它们分别适用于不同的控制系统。
合成控制法是一种针对多变量系统的控制方法,它通过将多个单变量控制器组合起来形成一个整体控制器,实现对多个变量的协同控制。
合成控制法具有结构简单、易于实现、控制精度高等优点。
常见的合成控制法包括模型预测控制、自适应控制、灰色控制等。
双重差分法是一种针对时间变化较慢的系统的控制方法,它利用差分算法对系统的输入输出信号进行处理,从而得到系统的状态空间模型,并通过状态反馈控制来实现对系统的控制。
双重差分法具有简单易懂、适用范围广、控制效果好等优点。
常见的双重差分法包括比例积分控制、比例微分控制、滑模控制等。
需要注意的是,合成控制法和双重差分法并不是互斥的,它们可以在具体的控制系统中根据实际需要进行组合使用。
例如,对于一个多变量系统,可以采用合成控制法对多个变量进行协同控制,同时对其中某个变量采用双重差分法进行控制,以提高控制效果和稳定性。
- 1 -。
基于合成控制法的现代农业园区政策效果评估——以广西壮族自治区为例

孔令孜,宁 夏,黄艳芳,等.基于合成控制法的现代农业园区政策效果评估———以广西壮族自治区为例[J].江苏农业科学,2021,49(4):225-231.doi:10.15889/j.issn.1002-1302.2021.04.040基于合成控制法的现代农业园区政策效果评估———以广西壮族自治区为例孔令孜,宁 夏,黄艳芳,麻小燕,李小红(广西农业科学院农业科技信息研究所,广西南宁530007) 摘要:采用合成控制法,选取广西壮族自治区百色市田阳区、来宾市兴宾区和苍梧县进行合成控制,对现代农业园区对农业经济增长的政策效应进行评估。
结果表明,现代农业园区政策对广西壮族自治区百色市田阳区农业经济发展有显著的促进作用,政策效应明显;对苍梧县为先正效应后负效应;而对兴宾区为负效应。
进一步研究发现,广西壮族自治区百色市田阳区的百色国家农业科技园区在获评国家农业科技园区后,不断完善和提升自身经营管理,而苍梧县和兴宾区的现代农业园区缺乏总体规划,园区自身发展乏力。
因此,应继续贯彻落实现代农业园区先建后补政策,建立、完善园区监督机制和奖惩机制,充分发挥市场经济的杠杆调节机制,通过市场经济来发展、培育园区的自我发展能力,同时探索建立长效的利益联结机制,从而充分发挥现代农业园区的政策效应,促进区域农业经济统筹融合发展。
关键词:现代农业园区;农业经济增长;政策评估;合成控制法 中图分类号:F323 文献标志码:A 文章编号:1002-1302(2021)04-0225-06收稿日期:2020-05-06基金项目:广西哲学社会科学规划(编号:18FGL010);广西农业重点科技计划(编号:Z201924)。
作者简介:孔令孜(1982—),女,广西金秀人,硕士,高级农业经济师,主要从事农业经济与信息化相关研究。
E-mail:litmint@qq.com。
通信作者:麻小燕,副编审,主要从事农业经济管理相关研究工作,E-mail:506812450@qq.com;李小红,硕士,高级农业经济师,主要从事农业经济相关研究,E-mail:421650570@qq.com。
政策效应分析,不可不知的双重差分模型(DID)

政策效应分析,不可不知的双重差分模型(DID)⽬录第⼀部分模型简介1、模型应⽤背景2、模型运⽤前提条件3、稳健性检验第⼆部分经典论⽂分析1、民族地区转移⽀付、公共⽀出差异与经济发展差距2、基于多期双重差分的分位回归及其应⽤第三部分双重差分模型(DID)stata实例操作1、变量构造和基本命令2、平⾏趋势检验第四部分经典论⽂推荐第五部分专题预览估计政策效应常⽤的⽅法有:⼯具变量法、断点回归、倾向得分匹配法、双重差分法、合成控制法等。
我们在这⾥介绍双重差分法。
第⼀部分模型简介1、模型应⽤背景现代计量经济学和统计学的发展为我们的研究提供了可⾏的⼯具。
倍差法来源于计量经济学的综列数据模型,是政策分析和⼯程评估中⼴为使⽤的⼀种计量经济⽅法。
主要是应⽤于在混合截⾯数据集中,评价某⼀事件息,可以计算作⽤组在政策或⼯程实施前后某个指标(如收⼊)的变化量(收⼊增长量),同时计算对照组在政策或⼯程实施前后同⼀指标的变化量。
然后计算上述两个变化量的差值(即所谓的“倍差值”)。
这就是所(2005)。
2、模型运⽤前提条件2.1 使⽤前提(1)政策不能是“⼀⼑切”类型,即存在受政策影响的实验组和不受政策影响的对照组(2)⾄少两年的⾯板数据,如果是截⾯数据⼀般也别考虑了2.2 模型前提(1)平⾏趋势(CT)假设:处理组和对照组有共同趋势,在政策⼲预之前,处理组和控制组的结果效应的趋势应该是⼀样的。
(2)SUTVA条件:政策⼲预只影响处理组,不会对控制组产⽣交互影响,或者政策⼲预不会产⽣外溢效应;(3)线性形式条件:潜在结果变量同处理变量和时间变量满⾜线性条件。
由此可见DID的使⽤条件较为严苛,并不能随意使⽤。
3、稳健性检验为了证明所有的效应是由政策实施所引起的,必须做稳健性检验,主要体现在两个⽅⾯:3.1 平⾏趋势检验如果是多年⾯板数据可以通过画图或者回归的⽅法来检验平⾏趋势假设。
(1)画图:画出实验组时期和对照组时期的时间趋势图,如果两条线的⾛势完全⼀致或基本⼀致,说明CT假设是满⾜的。
合成控制法sigf -回复

合成控制法sigf -回复什么是合成控制法(SIGF)?合成控制法(Synthesis-based Incremental Genetic Fuzzy,SIGF)是一种集合模糊神经网络和基因算法的智能控制方法。
SIGF方法通过使用模糊逻辑规则和基因算法,能够实现对复杂系统的建模和控制。
SIGF方法被广泛用于工业自动化、交通控制、机器人控制等领域,具有良好的控制效果和鲁棒性。
首先,SIGF方法采用模糊逻辑规则对控制对象进行建模。
模糊逻辑规则可以将非精确的输入和输出映射到一组模糊子集上,然后通过模糊推理得到控制对象的输出。
模糊逻辑规则的建立需要利用专家经验和实验数据,通过人工确定模糊规则的形式和参数。
同时,SIGF方法也可以通过利用基因算法自动学习模糊规则,从而提高建模的准确性和适用性。
其次,SIGF方法通过基因算法对模糊规则进行优化和选择。
基因算法是一种模拟生物进化过程的全局搜索优化算法。
基因算法通过遗传操作(交叉、变异等)对候选解进行改进和优化,从而寻找最优解。
在SIGF方法中,基因算法可以根据某种适应度函数对模糊规则进行评估和选择,优化模糊规则,提高控制的效果和鲁棒性。
SIGF方法的特点在于其能够实现增量式的学习和控制。
传统的模糊控制方法在控制对象发生改变时需要重新设计模糊规则,耗时耗力。
而SIGF方法通过基因算法的优化和选择,可以实现对模糊规则的增量式学习和更新,从而保持对控制对象的适应性和控制能力。
这使得SIGF方法在实际应用中具有良好的鲁棒性和适应性。
除了以上的特点,SIGF方法还具有一些其他的优点。
首先,SIGF方法可以处理复杂的非线性控制问题,具有较强的建模和控制能力。
其次,SIGF 方法可以通过人工设定控制目标和约束,实现对控制过程的灵活性和可调节性。
最后,SIGF方法还可以利用传感器和执行器的实时反馈信息,进行在线控制和调整,提高控制精度和响应速度。
综上所述,合成控制法(SIGF)是一种集合模糊逻辑规则和基因算法的智能控制方法。
药物合成控制方法和策略

药物合成控制方法和策略
第11页
3.选择性酰化试剂活性次序 常见酰化剂反应活性大小次序以下: RCOCl ≌ RCH=C=O > (RCO)2O > RCO2Ph > RCO2R¹ > RCOOH > RCONHR¹ 当两种酰基共存于同一分子时,活性较高酰基优先反应。若想让活性较低酰基反应,需先把它转化为活性更高酰基再进行反应。比如:
药品合成控制问题: 在底物分子特定位置上进行特定反应,即在复杂分子合成过程中,若分子中有两个或多个反应活性中心时,使反应试剂按预期构想只进攻某一部位或官能团。
药物合成控制方法和策略
第1页
使药品合成反应含有控制性三种策略: 一、选择性反应利用; 二、导向基应用,包含活化基、钝化基、阻断基和保护基 等导向基应用; 三、潜在官能团应用。
药物合成控制方法和策略
第6页
药物合成控制方法和策略
第7页
2.常见官能团选择还原
各种官能团被还原活性次序为:
次序
官能团
还原产物
1
RCOCl
→RCHO
2
RNO2
RNH2
3
RC≡R’
RCH=CHR’
4
RCHO
RCH2OH
5
RCH=CHR¹RCH2CHFra bibliotekR¹6
RCOR¹
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
������������ ������������ + ������������
������=������
������������ ������������ +
������=������
������������ ������������������
������+������
������+������
数 据
2010 年 6 月 ~2012 年 2 月 40 个大中城市的平衡面板数据, 40个城市中包括所有省会城市(除拉萨、港澳地区),同 时考虑到重庆没有实行限购政策,选择了一些与重庆房价
差别不大,尚未实施限购政策或限购政策实施较晚的城市,
包括:北海、大连、惠州、泉州等。
变 量
预测控制变量: 土地成交均价、人均GDP、人口密度、限购变量、第三产业比重 被解释变量: 城市住宅均价作为当地房价的代理变量 关系: (1)土地成交均价的影响房地产市场的供给,地价上涨会导致房地 产商开放成本上升,从而会使房价上涨; (2)人均GDP和人口密度影响房地产市场的需求,人均GDP越高的 城市,其房价也会越高,而人口密度越大的城市,会导致房地产市 场的需求增长大于供给增长,所以房价也会越高; (3)限购政策则在一定程度上抑制了房地产市场的购买需求,从而 抑制了房价的上涨,作为虚拟变量,限购城市赋值为1,未限制城 市赋值为0;
将价格效应进一步分解后,发现不同面积类型的住房价格 走势完全相反,在大面积住房(144平方米以上) 价格下降的同 时,小面积住房 (90 平方米以下 ) 价格反而出现了更大幅度的 上涨 这至少说明两个问题:一是住房平均价格的下降主要是 由大面积住房导致的;二是房产税政策将大面积住房市场需 求挤出到小面积住房市场,导致这些类型的住房价格增长更 快。 “结构性扭曲” 形成原因: 1.与现阶段试点的“窄税基”房产税政策有关 2.与户籍制度直接相关。
������=������
������������
������=������
������′������ ������������
������′������ ������������������ − ������������������ −
������=������
������+������
������∗ ������ (������������������ − ������������������ )
(2)房产税改革的免税条款对住房市场产生挤出效应,由 于房产税改革主要针对的是大面积住房,在房产税政策 免税条款的影响下,导致房产税挤出的需求会进一步抬 高小户型住房的价格,因此房产税还将产生结构效应
三、估计方法
1、倍差法(DID法,双重差分法)
概念:对比房产税改革之后试点城市房价水平的变化和其他地 区房价的变化,两者之间的差距就反映了房产税改革对试点城 市房价的影响。 处理组:试点城市(2011年2月之后) 对照组:国内其他城市 障碍:(会造成偏误) (1)对照组的选取具有主观性和随意性,不具有说服力 (2)政策是内生的,试点城市与其他城市之间有系统性差别, 而这种差别恰好是该城市成为试点城市的原因。
本 文 采 用 ABADIE 和 GARDEAZABAL(2003) 提 出 的 合 成 控 制 法 (SYNTHETIC CONTROL METHODS)来估计房产税政策的影响,合成控制 法弥补了DID方法的上述缺陷,充分考虑到处理组的特殊性,通过其 他城市的加权平均来构造一个“反事实”的参照组,真实房价水平 与反事实房价之间的差距则是该政策的作用。 基于 2010 年 6 月至 2012 年 2 月40 个大中城市的月度平衡面板数据, 在控制了土地价格、经济发展水平、人口密度、限购政策及产业结 构等因素后,我们发现房产税使得试点城市房价相对于潜在房价下 降幅度达5.27%,并且通过了一系列稳健性检验。
第六部分是全文的结论
二 、理论分析及研究假说
由于资本的流动性一般都比较高,因此资本并不承担任 何税负,房产税最终会转嫁给消费者,从而以更高的房 价表现出来(SIMON,1943;NETZER,1966)。 以 TIEBOUT(1956) 为代表的财政学文献开始将房产税与公 共服务联系起来,认为在劳动力自由流动的情况下, “用脚投票”的机制会匹配辖区的房产税与公共服务, 那些提供更多公共服务的地区所制定的房产税税负更重, 反之亦然 房产税是一种收益税,影响当地的公共支出,不直接影 响住房价格和资源配置 (TIEBOUT , 1956 ; HAMILTON , 1975 ; FISCHEL,1992、2001)
疑 问
为什么选取重庆来做实证分析而非上海?
合成控制法要求处理组可以通过对照组加权估计,但是 上海地区住宅均价在中国住宅均价中国基本处于第一位 置,并且其他经济特征也比较特殊,无法通过其他城市 进行加权平均,但是重庆符合本方法的要求。 此外,在稳健性检验中,上海在研究地区预测误差的36 倍,因而将上海删除。
2、合成控制法
根据数据选择对照组来研究政策效应的方法
基本思路:根据没有房产税改革的其他地区的加权组合来构造一个 与处理组类似的对照组。
基本特征:知道对照组内每个经济体的权重,即每个经济体根据各 自数据特点的相似性,构成“反事实”事件中所做的贡献,按照事 件发生之前的预测变量来衡量对照组和处理组的相似性。 优点: (1)扩展了传统的倍差法,是一种非参数的方法 (2)构造对照组时,通过数据来决定权重的大小,从而减少了主观 判断;通过所有对照组的数据特征构造“反事实状态”,各自 权重为正数且和为1.(Temple,1999)
杜雪君等(2009)利用中国31个省(市自治区)的数据 资料为研究样本,发现中国房地产税对房价有抑制 作用,而地方公共支出则对房价有促进作用,且后 者的影响较大,因此房地产税负和地方公共支出对 房价的净影响为正 况伟大(2009)的研究表明,在其他条件不变时,开 征房产税将导致房价下降 况伟大(2010)与发达国家不同的是,由于房价的快 速上涨,中国的住房市场不仅是一个消费市场,而 且更是一个投资市场,预期及投机需求对中国城市 房价波动具有较强的解释力。
入选原因
一是两者都是直辖市,在行政上更有利于管理 二是两者的房价具有很好的代表性,上海市作为东 部沿海城市,房价水平是最高的几座城市之一,重 庆作为西部城市,房价处于全国平均水平
区别
检验的假说
(1)房产税改革降低住房价格,试点城市通过对住房征收 房产税,提高了住房的持有成本,进一步抑制住房的投 资性需求,在短期内会抑制房价的上涨
合成控制法应用举例:
西班牙其他地区的组合来模拟没有恐怖活动的巴斯克地区 的潜在经济增长,进而估计恐怖活动对巴斯克地区经济的 影响。 研究加州的控烟法对烟草消费的影响,利用其他州的数据 加权模拟加州在没有该法案时的潜在烟草消费水平。 分析重庆1997年被划分为直辖市对相关地区经济增长的影 响。
虽然不同理论在房产税对房价的影响方面没有得出一 致结论,但是大部分的文献都发现两者是一种负向关系 OATES(1969)通过对美国新泽西州东北部53个城镇的调查发 现房地产价值与财产税呈负相关,与地区的公共支出水平 呈正相关 KENNETH(1982)对北加利福尼亚推出的13号法案对房价影响 的研究发现,在当地公共服务没有下降的情况下,平均每 年下降1美元的财产税相应增加7美元的财产价值 ROSENTHAL(1999)对英国马其赛特郡(MERSEYSIDE)等县市的研 究发现税收对房价有抑制作用Fra bibliotek模型:
������+������
������+������
������+������
������+������
������������ ������������������ = ������������ + ������������
������=������ ������=������
1986 年 9 月 15 日国务院颁布的《中华人民共和国房产 税暂行条例》,不过当时的房产税主要针对商业用房, 个人所有的非营业用房产则免征房产税,因此对房地产 的影响较小。 2010年5月国务院提出要推进房产税改革,扩大原有的 房产税征收范围,将个人所有的居住房产也作为征收对 象 见《关于2010年深化经济体制改革重点工作的意见》 (国发[2010]15号)。 2011年1月国务院开始在部分城市试点房产税的征收, 重庆和上海成为首批试点城市
中国房产税试点的效果评估: 基于合成控制法的研究
作者:刘甲炎 范子英
一、引言
自2000年以来,中国的住房价格平均每年增长8.58%远远超过了 同期的CPI增长率和银行存款利率
消费不足、收入差距、结构失衡、投资泡沫
供给管理:减免税费、调整住房供给结构等 需求管理:限购限贷、提高首付比例、加大对保障性住房的投 入,尝试建立多维度的住房供给结构 长期措施:对房地产的持有环节征税。能够使得投资需求成上升, 降低房地产投资的收益,进而在长期中抑制房价的上 涨,缓解地方政府土地财政困境,规范地方政府的行 为。
������∗ ������ ������������������
������=������
������+������
������������������ = ������������������ −
������=������
������∗ ������ ������������������
四、房产税对房价影响的平均效应
“结构性扭曲”结果:产生了巨大的福利分配效应,由于小面 积住房对应的是城市的中低收入阶层,房产税的本意是要减 轻他们的购房负担,但实际结果却完全相反